 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Design and Deployment of an Autonomous Unmanned Ground Vehicle for Urban Firefighting Scenarios
Jul 08, 2021


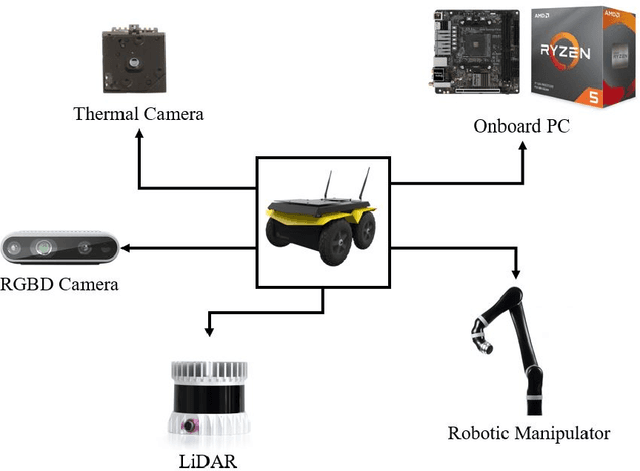
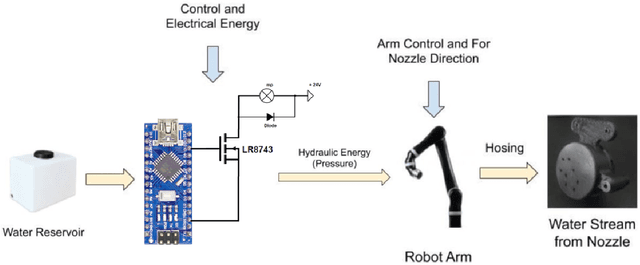
Autonomous mobile robots have the potential to solve missions that are either too complex or dangerous to be accomplished by humans. In this paper, we address the design and autonomous deployment of a ground vehicle equipped with a robotic arm for urban firefighting scenarios. We describe the hardware design and algorithm approaches for autonomous navigation, planning, fire source identification and abatement in unstructured urban scenarios. The approach employs on-board sensors for autonomous navigation and thermal camera information for source identification. A custom electro{mechanical pump is responsible to eject water for fire abatement. The proposed approach is validated through several experiments, where we show the ability to identify and abate a sample heat source in a building. The whole system was developed and deployed during the Mohamed Bin Zayed International Robotics Challenge (MBZIRC) 2020, for Challenge No. 3 Fire Fighting Inside a High-Rise Building and during the Grand Challenge where our approach scored the highest number of points among all UGV solutions and was instrumental to win the first place.
Act Like a Radiologist: Towards Reliable Multi-view Correspondence Reasoning for Mammogram Mass Detection
May 21, 2021



Mammogram mass detection is crucial for diagnosing and preventing the breast cancers in clinical practice. The complementary effect of multi-view mammogram images provides valuable information about the breast anatomical prior structure and is of great significance in digital mammography interpretation. However, unlike radiologists who can utilize the natural reasoning ability to identify masses based on multiple mammographic views, how to endow the existing object detection models with the capability of multi-view reasoning is vital for decision-making in clinical diagnosis but remains the boundary to explore. In this paper, we propose an Anatomy-aware Graph convolutional Network (AGN), which is tailored for mammogram mass detection and endows existing detection methods with multi-view reasoning ability. The proposed AGN consists of three steps. Firstly, we introduce a Bipartite Graph convolutional Network (BGN) to model the intrinsic geometric and semantic relations of ipsilateral views. Secondly, considering that the visual asymmetry of bilateral views is widely adopted in clinical practice to assist the diagnosis of breast lesions, we propose an Inception Graph convolutional Network (IGN) to model the structural similarities of bilateral views. Finally, based on the constructed graphs, the multi-view information is propagated through nodes methodically, which equips the features learned from the examined view with multi-view reasoning ability. Experiments on two standard benchmarks reveal that AGN significantly exceeds the state-of-the-art performance. Visualization results show that AGN provides interpretable visual cues for clinical diagnosis.
Adaptive Denoising via GainTuning
Jul 27, 2021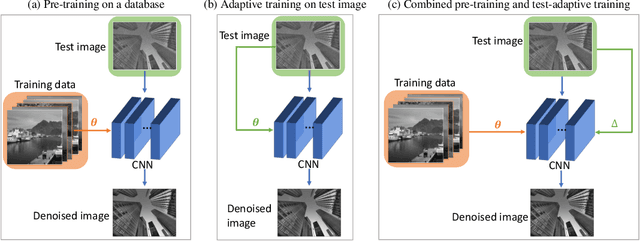
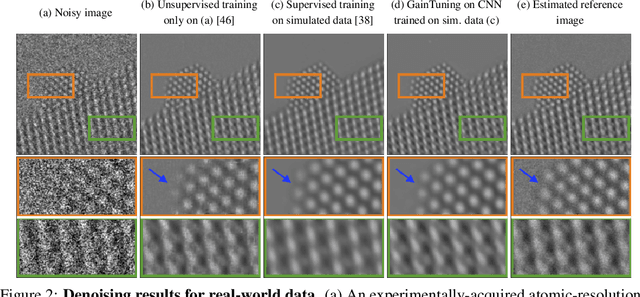

Deep convolutional neural networks (CNNs) for image denoising are usually trained on large datasets. These models achieve the current state of the art, but they have difficulties generalizing when applied to data that deviate from the training distribution. Recent work has shown that it is possible to train denoisers on a single noisy image. These models adapt to the features of the test image, but their performance is limited by the small amount of information used to train them. Here we propose "GainTuning", in which CNN models pre-trained on large datasets are adaptively and selectively adjusted for individual test images. To avoid overfitting, GainTuning optimizes a single multiplicative scaling parameter (the "Gain") of each channel in the convolutional layers of the CNN. We show that GainTuning improves state-of-the-art CNNs on standard image-denoising benchmarks, boosting their denoising performance on nearly every image in a held-out test set. These adaptive improvements are even more substantial for test images differing systematically from the training data, either in noise level or image type. We illustrate the potential of adaptive denoising in a scientific application, in which a CNN is trained on synthetic data, and tested on real transmission-electron-microscope images. In contrast to the existing methodology, GainTuning is able to faithfully reconstruct the structure of catalytic nanoparticles from these data at extremely low signal-to-noise ratios.
Explainable Artificial Intelligence (XAI) for Increasing User Trust in Deep Reinforcement Learning Driven Autonomous Systems
Jun 07, 2021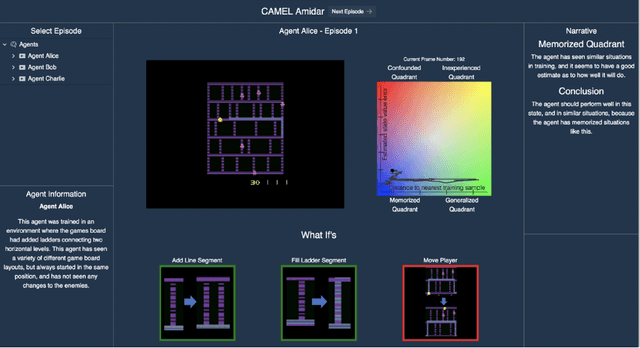
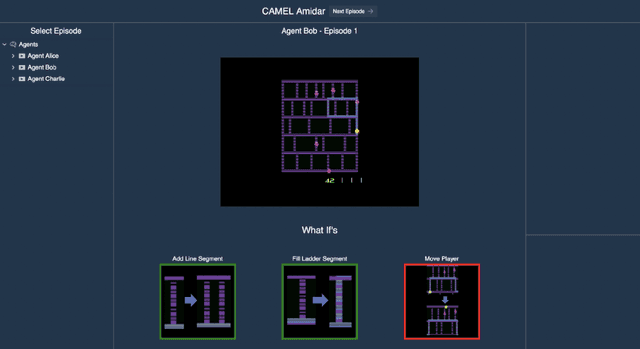
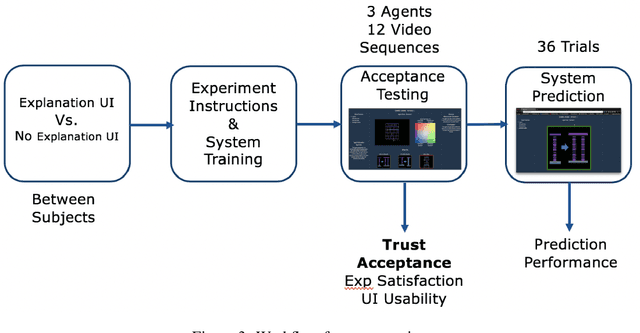
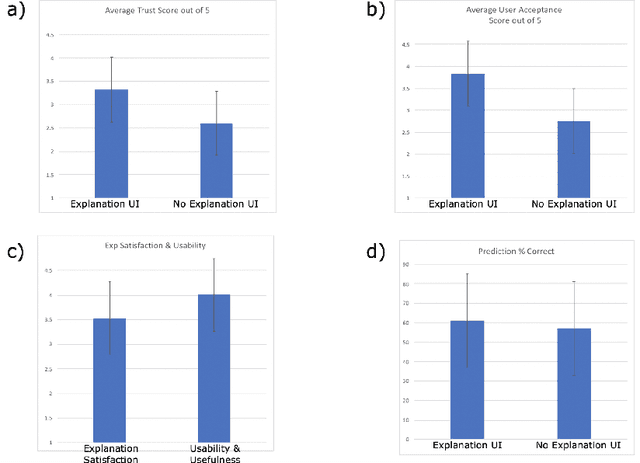
We consider the problem of providing users of deep Reinforcement Learning (RL) based systems with a better understanding of when their output can be trusted. We offer an explainable artificial intelligence (XAI) framework that provides a three-fold explanation: a graphical depiction of the systems generalization and performance in the current game state, how well the agent would play in semantically similar environments, and a narrative explanation of what the graphical information implies. We created a user-interface for our XAI framework and evaluated its efficacy via a human-user experiment. The results demonstrate a statistically significant increase in user trust and acceptance of the AI system with explanation, versus the AI system without explanation.
Multi-modal Residual Perceptron Network for Audio-Video Emotion Recognition
Jul 21, 2021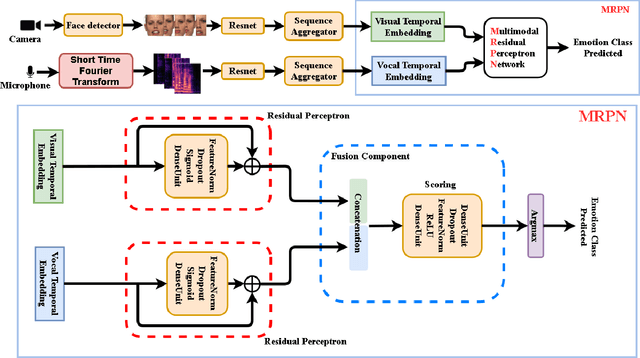
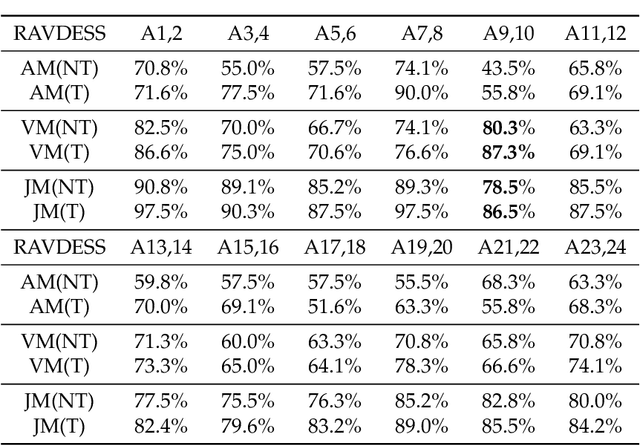

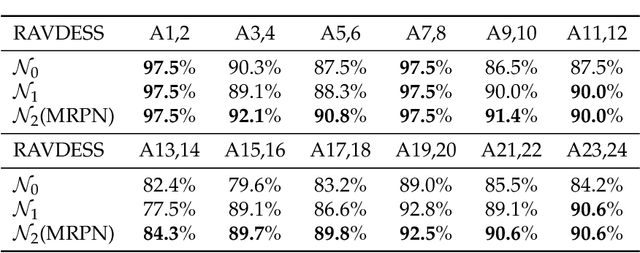
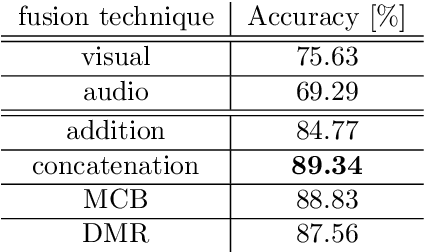
Emotion recognition is an important research field for Human-Computer Interaction(HCI). Audio-Video Emotion Recognition (AVER) is now attacked with Deep Neural Network (DNN) modeling tools. In published papers, as a rule, the authors show only cases of the superiority of multi modalities over audio-only or video-only modalities. However, there are cases superiority in single modality can be found. In our research, we hypothesize that for fuzzy categories of emotional events, the higher noise of one modality can amplify the lower noise of the second modality represented indirectly in the parameters of the modeling neural network. To avoid such cross-modal information interference we define a multi-modal Residual Perceptron Network (MRPN) which learns from multi-modal network branches creating deep feature representation with reduced noise. For the proposed MRPN model and the novel time augmentation for streamed digital movies, the state-of-art average recognition rate was improved to 91.4% for The Ryerson Audio-Visual Database of Emotional Speech and Song(RAVDESS) dataset and to 83.15% for Crowd-sourced Emotional multi-modal Actors Dataset(Crema-d). Moreover, the MRPN concept shows its potential for multi-modal classifiers dealing with signal sources not only of optical and acoustical type.
Learning Zero-Shot Multifaceted Visually Grounded Word Embeddingsvia Multi-Task Training
Apr 15, 2021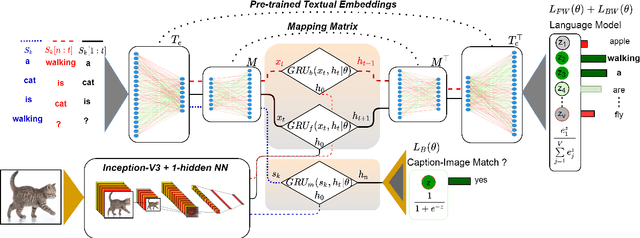
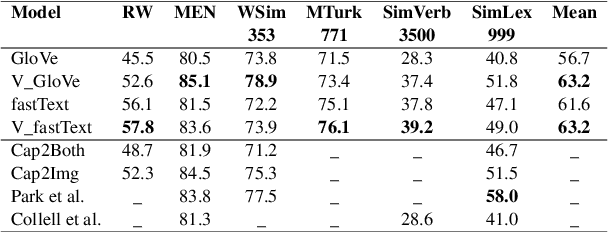

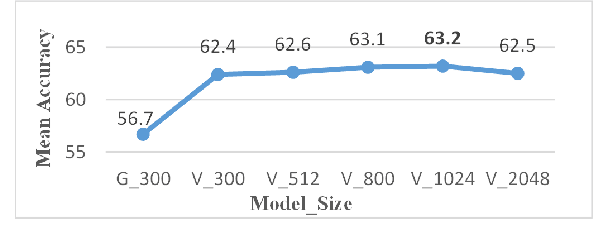
Language grounding aims at linking the symbolic representation of language (e.g., words) into the rich perceptual knowledge of the outside world. The general approach is to embed both textual and visual information into a common space -the grounded space-confined by an explicit relationship between both modalities. We argue that this approach sacrifices the abstract knowledge obtained from linguistic co-occurrence statistics in the process of acquiring perceptual information. The focus of this paper is to solve this issue by implicitly grounding the word embeddings. Rather than learning two mappings into a joint space, our approach integrates modalities by determining a reversible grounded mapping between the textual and the grounded space by means of multi-task learning. Evaluations on intrinsic and extrinsic tasks show that our embeddings are highly beneficial for both abstract and concrete words. They are strongly correlated with human judgments and outperform previous works on a wide range of benchmarks. Our grounded embeddings are publicly available here.
Claim Detection in Biomedical Twitter Posts
Apr 23, 2021
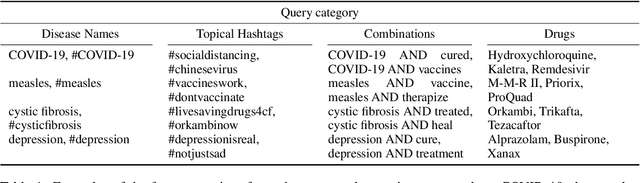
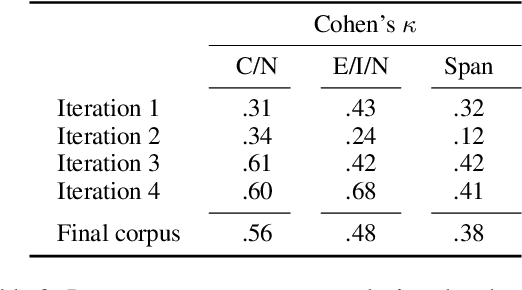
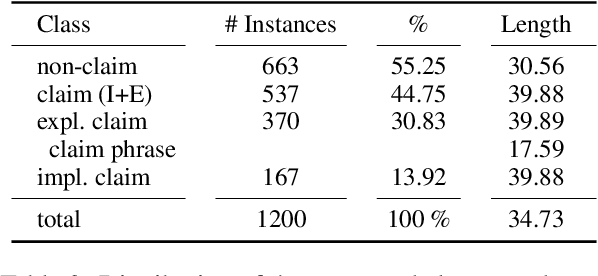
Social media contains unfiltered and unique information, which is potentially of great value, but, in the case of misinformation, can also do great harm. With regards to biomedical topics, false information can be particularly dangerous. Methods of automatic fact-checking and fake news detection address this problem, but have not been applied to the biomedical domain in social media yet. We aim to fill this research gap and annotate a corpus of 1200 tweets for implicit and explicit biomedical claims (the latter also with span annotations for the claim phrase). With this corpus, which we sample to be related to COVID-19, measles, cystic fibrosis, and depression, we develop baseline models which detect tweets that contain a claim automatically. Our analyses reveal that biomedical tweets are densely populated with claims (45 % in a corpus sampled to contain 1200 tweets focused on the domains mentioned above). Baseline classification experiments with embedding-based classifiers and BERT-based transfer learning demonstrate that the detection is challenging, however, shows acceptable performance for the identification of explicit expressions of claims. Implicit claim tweets are more challenging to detect.
Unsupervised Remote Sensing Super-Resolution via Migration Image Prior
May 08, 2021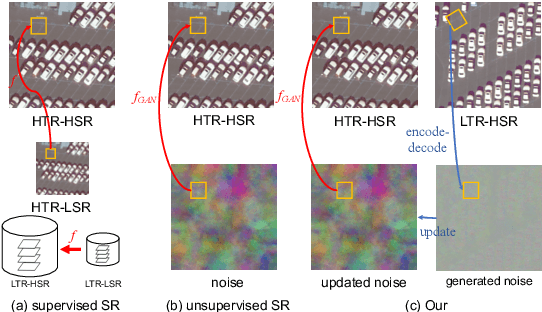
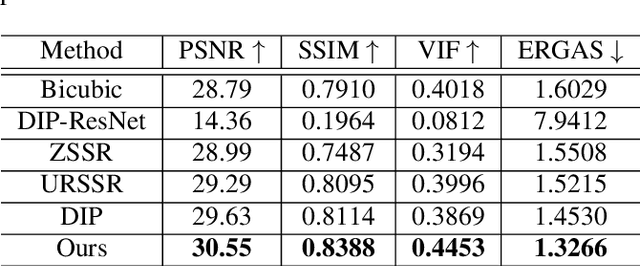
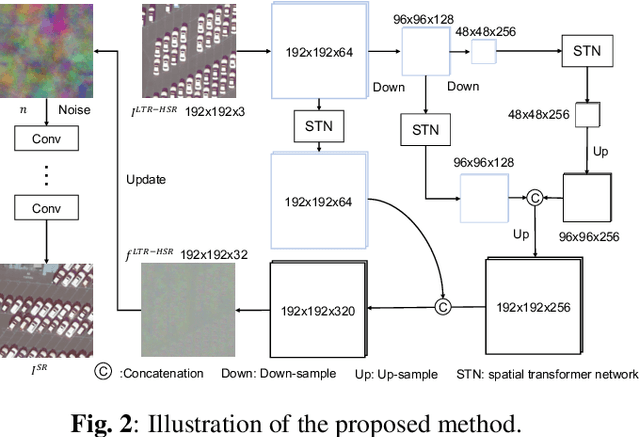
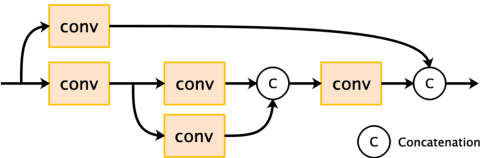
Recently, satellites with high temporal resolution have fostered wide attention in various practical applications. Due to limitations of bandwidth and hardware cost, however, the spatial resolution of such satellites is considerably low, largely limiting their potentials in scenarios that require spatially explicit information. To improve image resolution, numerous approaches based on training low-high resolution pairs have been proposed to address the super-resolution (SR) task. Despite their success, however, low/high spatial resolution pairs are usually difficult to obtain in satellites with a high temporal resolution, making such approaches in SR impractical to use. In this paper, we proposed a new unsupervised learning framework, called "MIP", which achieves SR tasks without low/high resolution image pairs. First, random noise maps are fed into a designed generative adversarial network (GAN) for reconstruction. Then, the proposed method converts the reference image to latent space as the migration image prior. Finally, we update the input noise via an implicit method, and further transfer the texture and structured information from the reference image. Extensive experimental results on the Draper dataset show that MIP achieves significant improvements over state-of-the-art methods both quantitatively and qualitatively. The proposed MIP is open-sourced at http://github.com/jiaming-wang/MIP.
Multi-level Attention Fusion Network for Audio-visual Event Recognition
Jun 12, 2021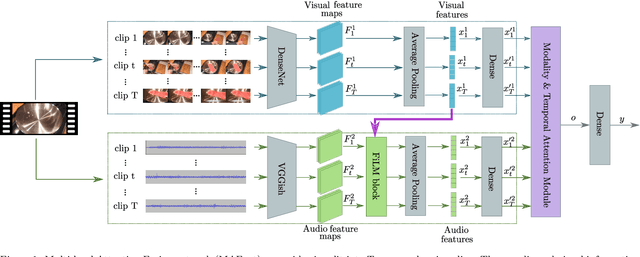
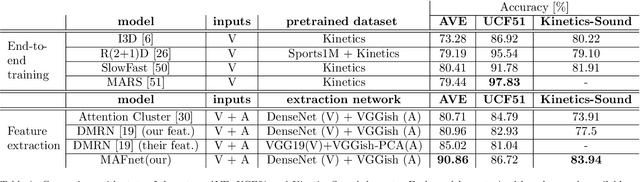
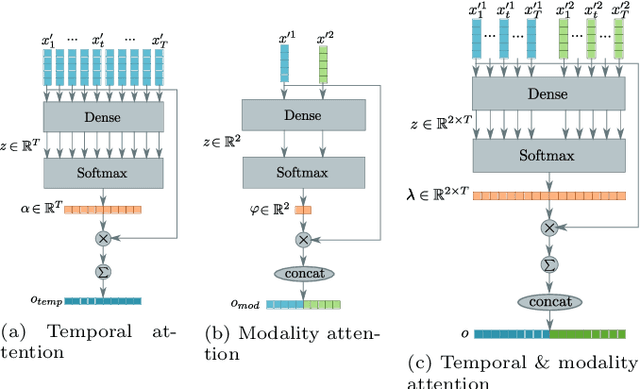
Event classification is inherently sequential and multimodal. Therefore, deep neural models need to dynamically focus on the most relevant time window and/or modality of a video. In this study, we propose the Multi-level Attention Fusion network (MAFnet), an architecture that can dynamically fuse visual and audio information for event recognition. Inspired by prior studies in neuroscience, we couple both modalities at different levels of visual and audio paths. Furthermore, the network dynamically highlights a modality at a given time window relevant to classify events. Experimental results in AVE (Audio-Visual Event), UCF51, and Kinetics-Sounds datasets show that the approach can effectively improve the accuracy in audio-visual event classification. Code is available at: https://github.com/numediart/MAFnet
Hierarchical Architectures in Reservoir Computing Systems
May 14, 2021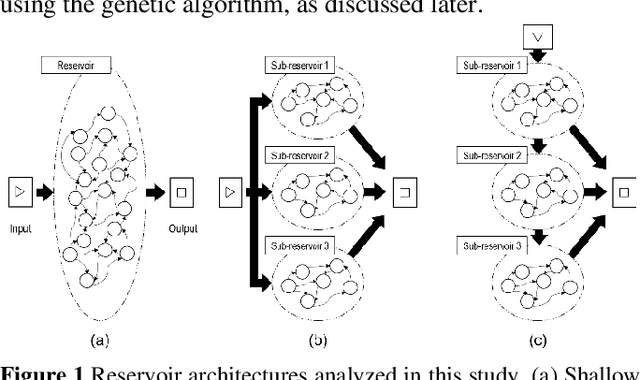
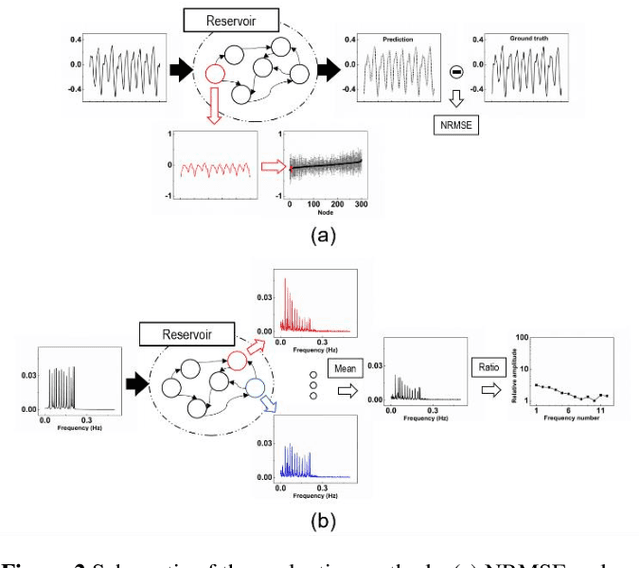
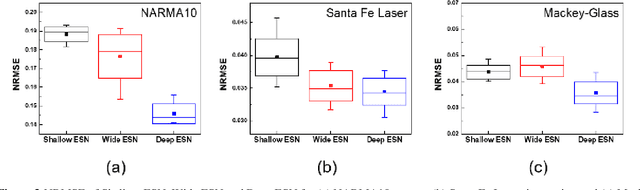
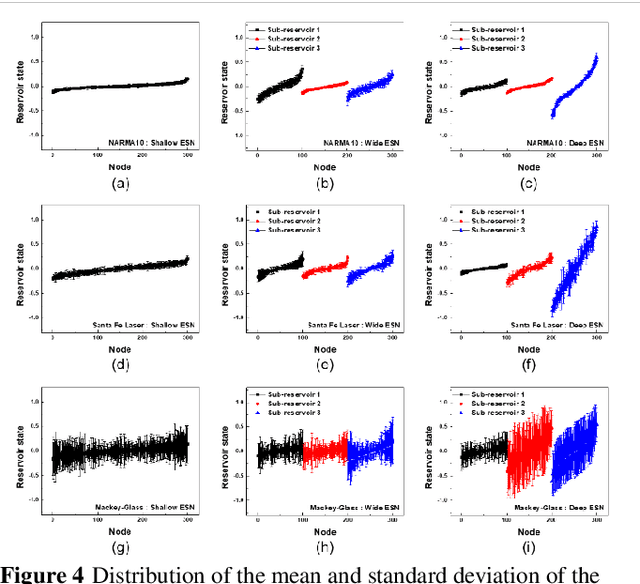
Reservoir computing (RC) offers efficient temporal data processing with a low training cost by separating recurrent neural networks into a fixed network with recurrent connections and a trainable linear network. The quality of the fixed network, called reservoir, is the most important factor that determines the performance of the RC system. In this paper, we investigate the influence of the hierarchical reservoir structure on the properties of the reservoir and the performance of the RC system. Analogous to deep neural networks, stacking sub-reservoirs in series is an efficient way to enhance the nonlinearity of data transformation to high-dimensional space and expand the diversity of temporal information captured by the reservoir. These deep reservoir systems offer better performance when compared to simply increasing the size of the reservoir or the number of sub-reservoirs. Low frequency components are mainly captured by the sub-reservoirs in later stage of the deep reservoir structure, similar to observations that more abstract information can be extracted by layers in the late stage of deep neural networks. When the total size of the reservoir is fixed, tradeoff between the number of sub-reservoirs and the size of each sub-reservoir needs to be carefully considered, due to the degraded ability of individual sub-reservoirs at small sizes. Improved performance of the deep reservoir structure alleviates the difficulty of implementing the RC system on hardware systems.