 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
ERICA: An Empathetic Android Companion for Covid-19 Quarantine
Jun 04, 2021
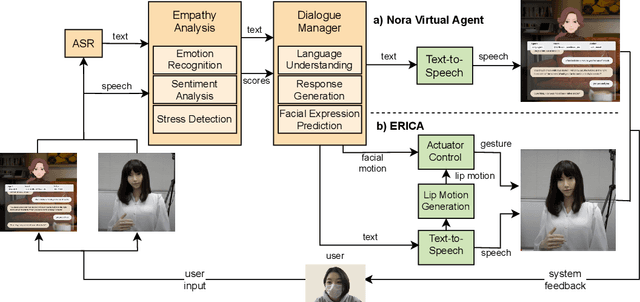
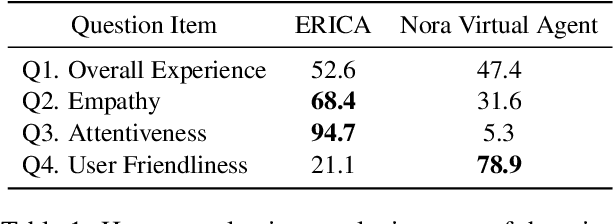
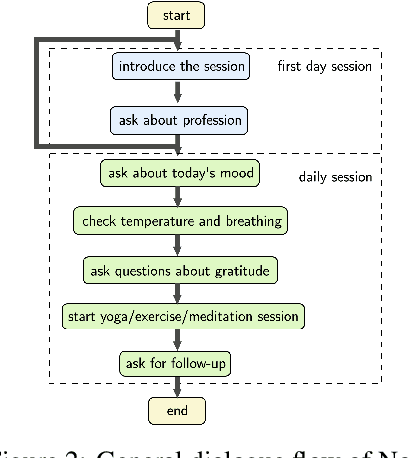

Over the past year, research in various domains, including Natural Language Processing (NLP), has been accelerated to fight against the COVID-19 pandemic, yet such research has just started on dialogue systems. In this paper, we introduce an end-to-end dialogue system which aims to ease the isolation of people under self-quarantine. We conduct a control simulation experiment to assess the effects of the user interface, a web-based virtual agent called Nora vs. the android ERICA via a video call. The experimental results show that the android offers a more valuable user experience by giving the impression of being more empathetic and engaging in the conversation due to its nonverbal information, such as facial expressions and body gestures.
Spatial-Phase Shallow Learning: Rethinking Face Forgery Detection in Frequency Domain
Mar 10, 2021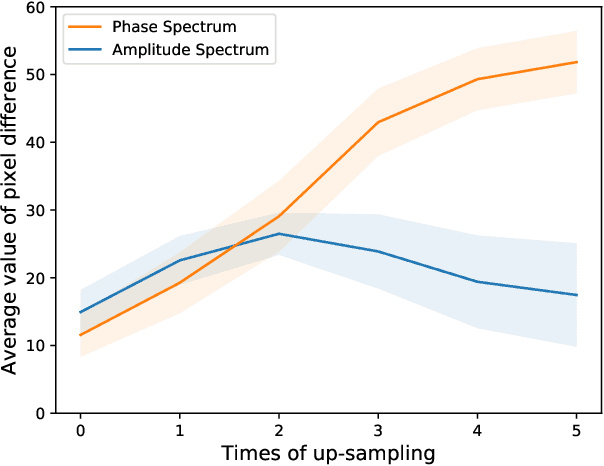
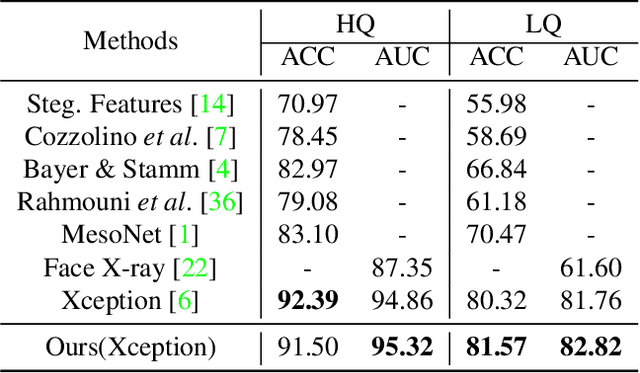
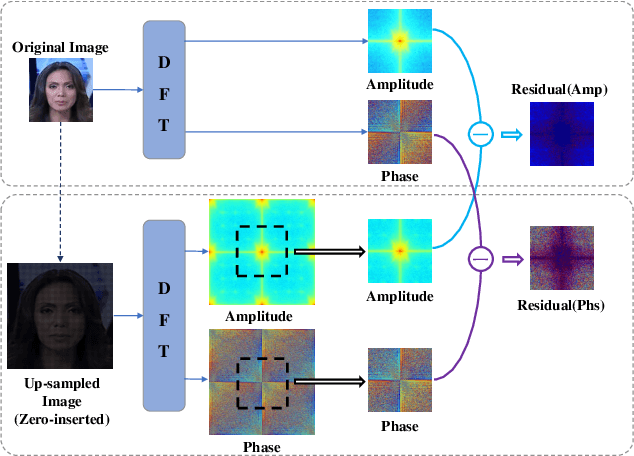
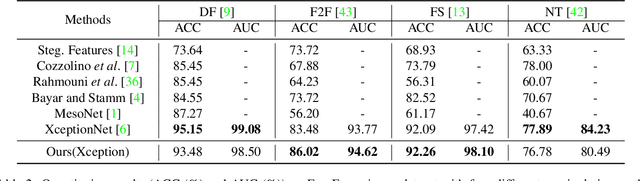
The remarkable success in face forgery techniques has received considerable attention in computer vision due to security concerns. We observe that up-sampling is a necessary step of most face forgery techniques, and cumulative up-sampling will result in obvious changes in the frequency domain, especially in the phase spectrum. According to the property of natural images, the phase spectrum preserves abundant frequency components that provide extra information and complement the loss of the amplitude spectrum. To this end, we present a novel Spatial-Phase Shallow Learning (SPSL) method, which combines spatial image and phase spectrum to capture the up-sampling artifacts of face forgery to improve the transferability, for face forgery detection. And we also theoretically analyze the validity of utilizing the phase spectrum. Moreover, we notice that local texture information is more crucial than high-level semantic information for the face forgery detection task. So we reduce the receptive fields by shallowing the network to suppress high-level features and focus on the local region. Extensive experiments show that SPSL can achieve the state-of-the-art performance on cross-datasets evaluation as well as multi-class classification and obtain comparable results on single dataset evaluation.
A LiDAR-Guided Framework for Video Enhancement
Mar 15, 2021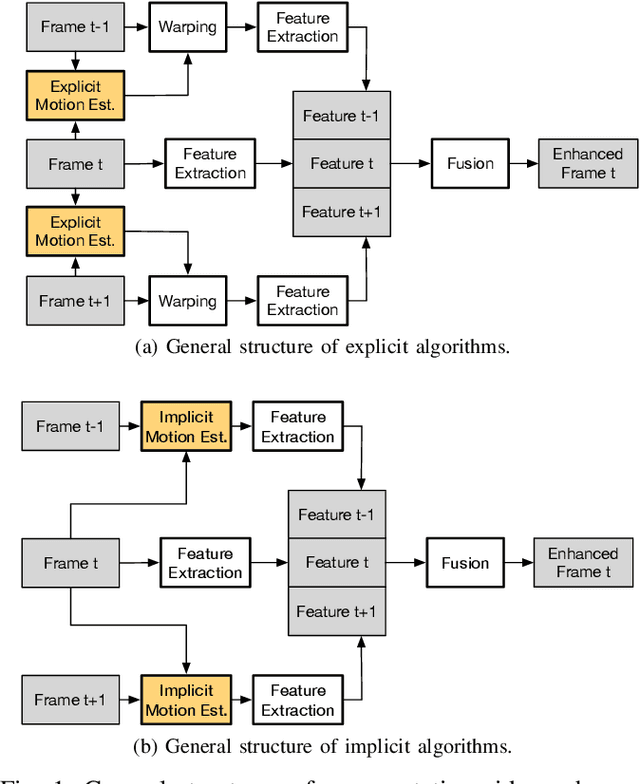

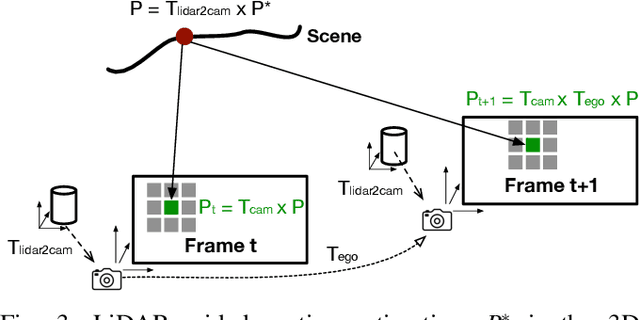

This paper presents a general framework that simultaneously improves the quality and the execution speed of a range of video enhancement tasks, such as super-sampling, deblurring, and denoising. The key to our framework is a pixel motion estimation algorithm that generates accurate motion from low-quality videos while being computationally very lightweight. Our motion estimation algorithm leverages point cloud information, which is readily available in today's autonomous devices and will only become more common in the future. We demonstrate a generic framework that leverages the motion information to guide high-quality image reconstruction. Experiments show that our framework consistently outperforms the state-of-the-art video enhancement algorithms while improving the execution speed by an order of magnitude.
Improving Information Extraction from Images with Learned Semantic Models
Aug 27, 2018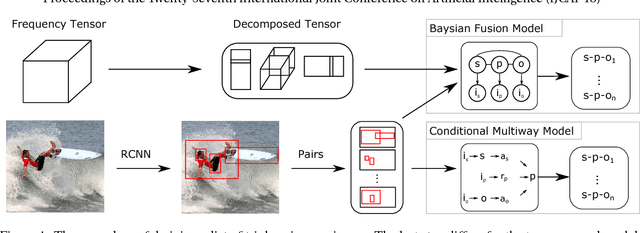
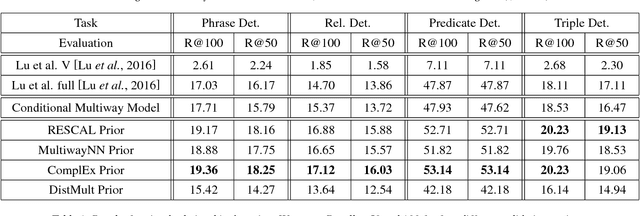
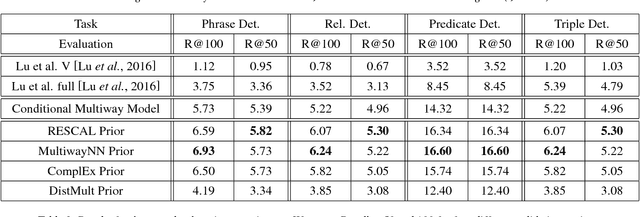
Many applications require an understanding of an image that goes beyond the simple detection and classification of its objects. In particular, a great deal of semantic information is carried in the relationships between objects. We have previously shown that the combination of a visual model and a statistical semantic prior model can improve on the task of mapping images to their associated scene description. In this paper, we review the model and compare it to a novel conditional multi-way model for visual relationship detection, which does not include an explicitly trained visual prior model. We also discuss potential relationships between the proposed methods and memory models of the human brain.
Two-way Spectrum Pursuit for CUR Decomposition and Its Application in Joint Column/Row Subset Selection
Jun 13, 2021
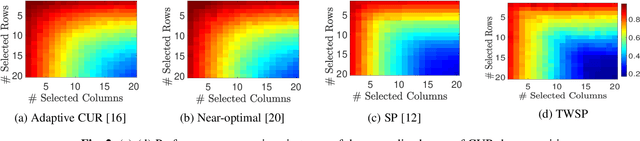
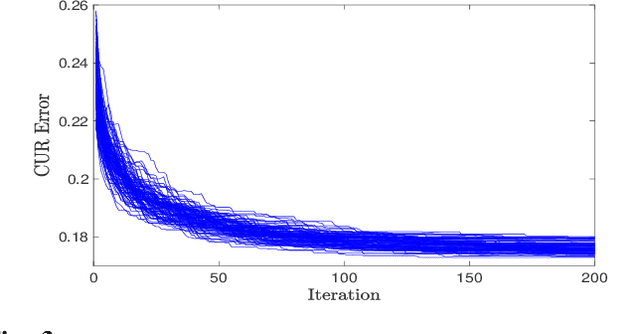
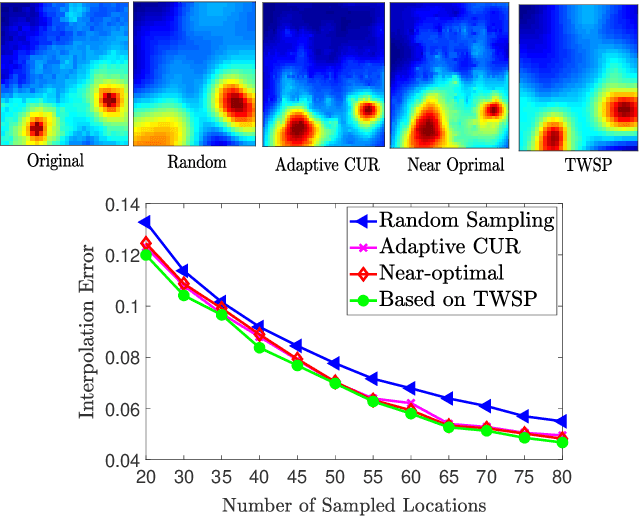
The problem of simultaneous column and row subset selection is addressed in this paper. The column space and row space of a matrix are spanned by its left and right singular vectors, respectively. However, the singular vectors are not within actual columns/rows of the matrix. In this paper, an iterative approach is proposed to capture the most structural information of columns/rows via selecting a subset of actual columns/rows. This algorithm is referred to as two-way spectrum pursuit (TWSP) which provides us with an accurate solution for the CUR matrix decomposition. TWSP is applicable in a wide range of applications since it enjoys a linear complexity w.r.t. number of original columns/rows. We demonstrated the application of TWSP for joint channel and sensor selection in cognitive radio networks, informative users and contents detection, and efficient supervised data reduction.
On exploring practical potentials of quantum auto-encoder with advantages
Jun 29, 2021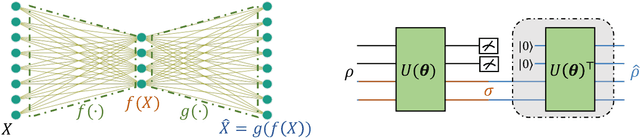
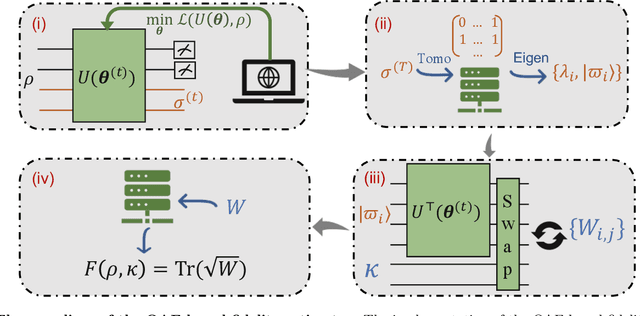
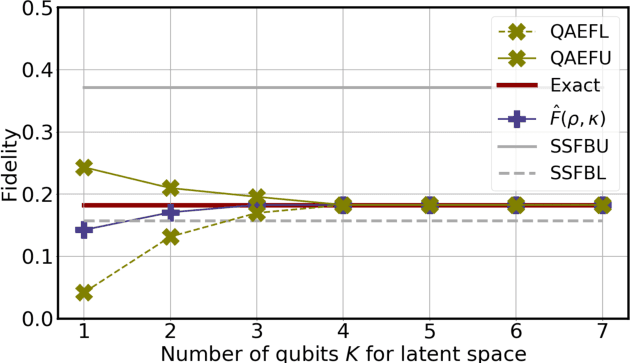
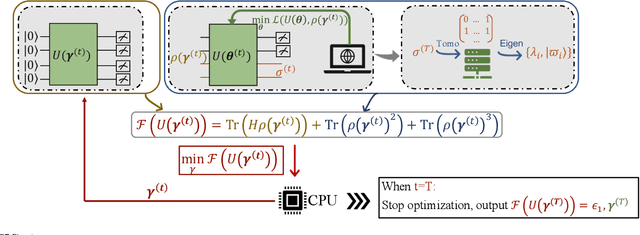
Quantum auto-encoder (QAE) is a powerful tool to relieve the curse of dimensionality encountered in quantum physics, celebrated by the ability to extract low-dimensional patterns from quantum states living in the high-dimensional space. Despite its attractive properties, little is known about the practical applications of QAE with provable advantages. To address these issues, here we prove that QAE can be used to efficiently calculate the eigenvalues and prepare the corresponding eigenvectors of a high-dimensional quantum state with the low-rank property. With this regard, we devise three effective QAE-based learning protocols to solve the low-rank state fidelity estimation, the quantum Gibbs state preparation, and the quantum metrology tasks, respectively. Notably, all of these protocols are scalable and can be readily executed on near-term quantum machines. Moreover, we prove that the error bounds of the proposed QAE-based methods outperform those in previous literature. Numerical simulations collaborate with our theoretical analysis. Our work opens a new avenue of utilizing QAE to tackle various quantum physics and quantum information processing problems in a scalable way.
Lyapunov-based uncertainty-aware safe reinforcement learning
Jul 29, 2021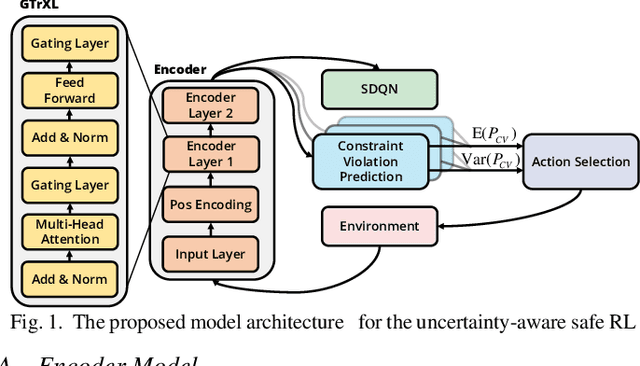
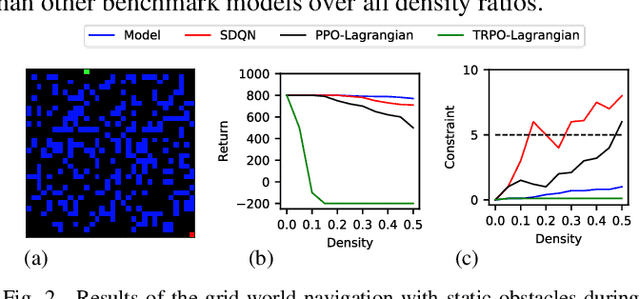
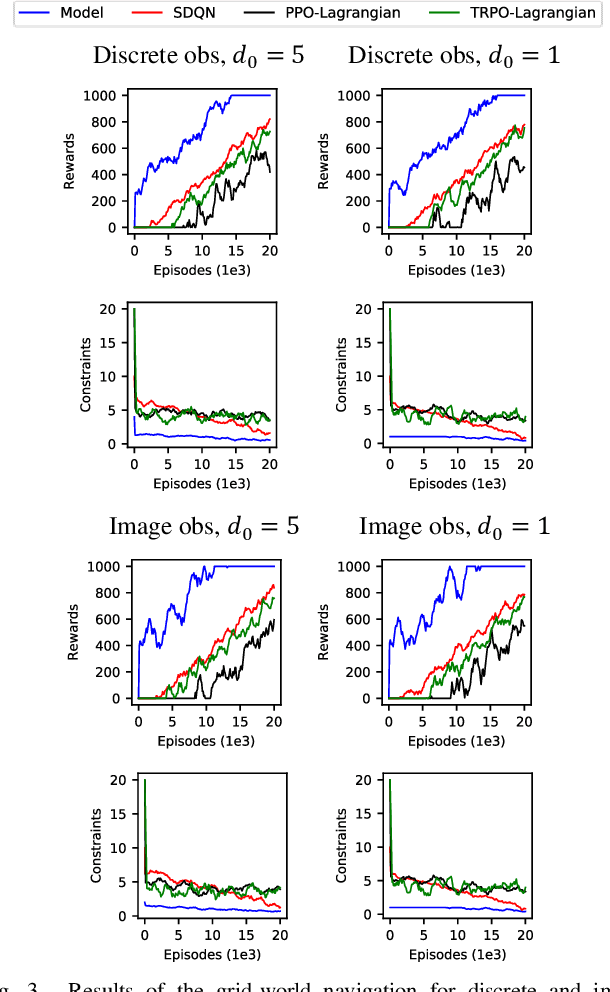
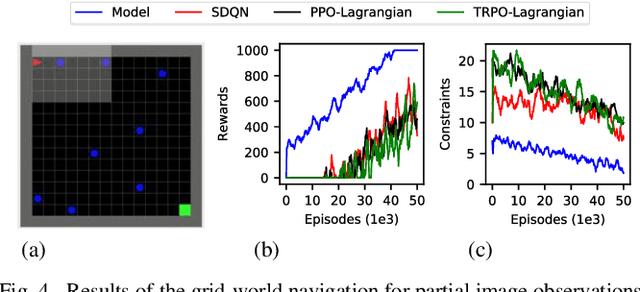
Reinforcement learning (RL) has shown a promising performance in learning optimal policies for a variety of sequential decision-making tasks. However, in many real-world RL problems, besides optimizing the main objectives, the agent is expected to satisfy a certain level of safety (e.g., avoiding collisions in autonomous driving). While RL problems are commonly formalized as Markov decision processes (MDPs), safety constraints are incorporated via constrained Markov decision processes (CMDPs). Although recent advances in safe RL have enabled learning safe policies in CMDPs, these safety requirements should be satisfied during both training and in the deployment process. Furthermore, it is shown that in memory-based and partially observable environments, these methods fail to maintain safety over unseen out-of-distribution observations. To address these limitations, we propose a Lyapunov-based uncertainty-aware safe RL model. The introduced model adopts a Lyapunov function that converts trajectory-based constraints to a set of local linear constraints. Furthermore, to ensure the safety of the agent in highly uncertain environments, an uncertainty quantification method is developed that enables identifying risk-averse actions through estimating the probability of constraint violations. Moreover, a Transformers model is integrated to provide the agent with memory to process long time horizons of information via the self-attention mechanism. The proposed model is evaluated in grid-world navigation tasks where safety is defined as avoiding static and dynamic obstacles in fully and partially observable environments. The results of these experiments show a significant improvement in the performance of the agent both in achieving optimality and satisfying safety constraints.
Multi-Pretext Attention Network for Few-shot Learning with Self-supervision
Mar 10, 2021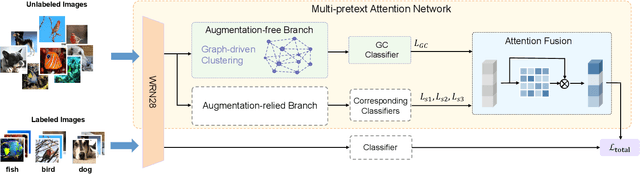
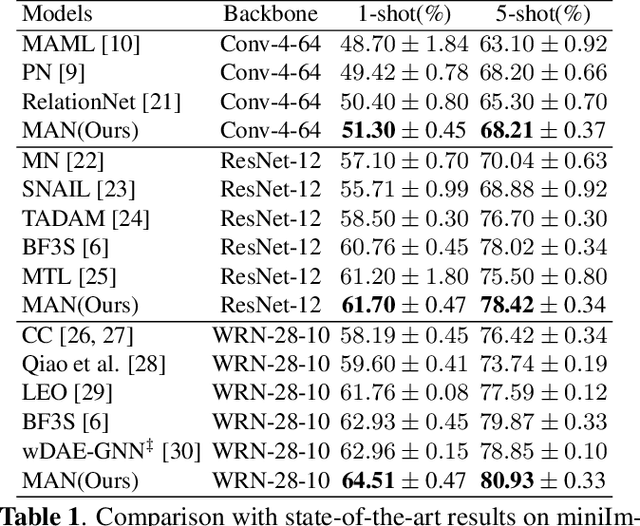
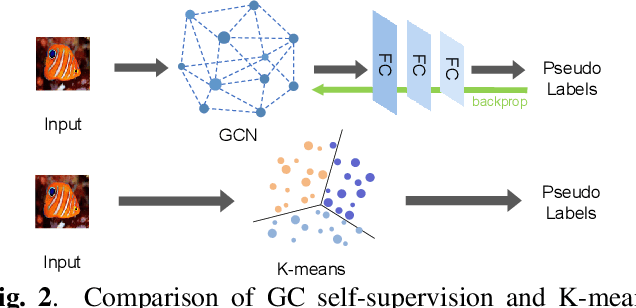
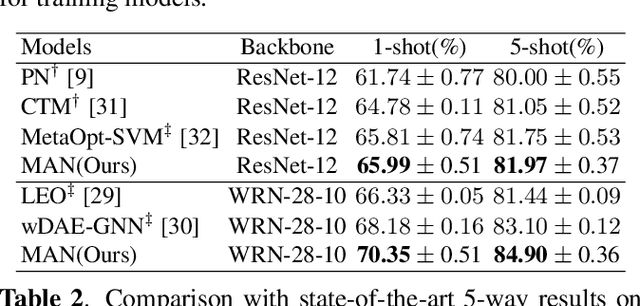
Few-shot learning is an interesting and challenging study, which enables machines to learn from few samples like humans. Existing studies rarely exploit auxiliary information from large amount of unlabeled data. Self-supervised learning is emerged as an efficient method to utilize unlabeled data. Existing self-supervised learning methods always rely on the combination of geometric transformations for the single sample by augmentation, while seriously neglect the endogenous correlation information among different samples that is the same important for the task. In this work, we propose a Graph-driven Clustering (GC), a novel augmentation-free method for self-supervised learning, which does not rely on any auxiliary sample and utilizes the endogenous correlation information among input samples. Besides, we propose Multi-pretext Attention Network (MAN), which exploits a specific attention mechanism to combine the traditional augmentation-relied methods and our GC, adaptively learning their optimized weights to improve the performance and enabling the feature extractor to obtain more universal representations. We evaluate our MAN extensively on miniImageNet and tieredImageNet datasets and the results demonstrate that the proposed method outperforms the state-of-the-art (SOTA) relevant methods.
Gone Fishing: Neural Active Learning with Fisher Embeddings
Jun 17, 2021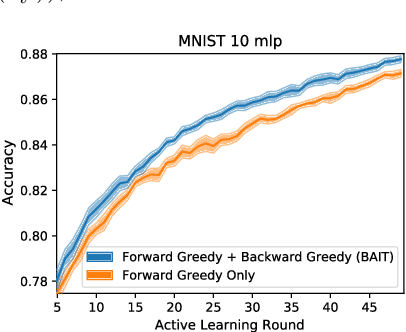
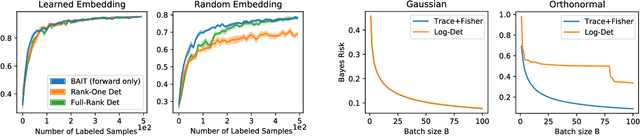
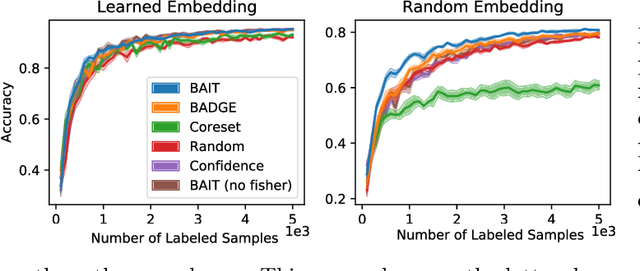
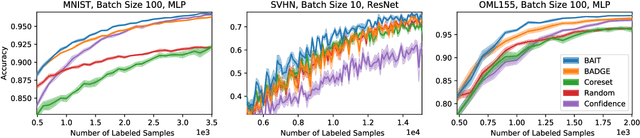
There is an increasing need for effective active learning algorithms that are compatible with deep neural networks. While there are many classic, well-studied sample selection methods, the non-convexity and varying internal representation of neural models make it unclear how to extend these approaches. This article introduces BAIT, a practical, tractable, and high-performing active learning algorithm for neural networks that addresses these concerns. BAIT draws inspiration from the theoretical analysis of maximum likelihood estimators (MLE) for parametric models. It selects batches of samples by optimizing a bound on the MLE error in terms of the Fisher information, which we show can be implemented efficiently at scale by exploiting linear-algebraic structure especially amenable to execution on modern hardware. Our experiments show that BAIT outperforms the previous state of the art on both classification and regression problems, and is flexible enough to be used with a variety of model architectures.
Understanding Object Dynamics for Interactive Image-to-Video Synthesis
Jun 21, 2021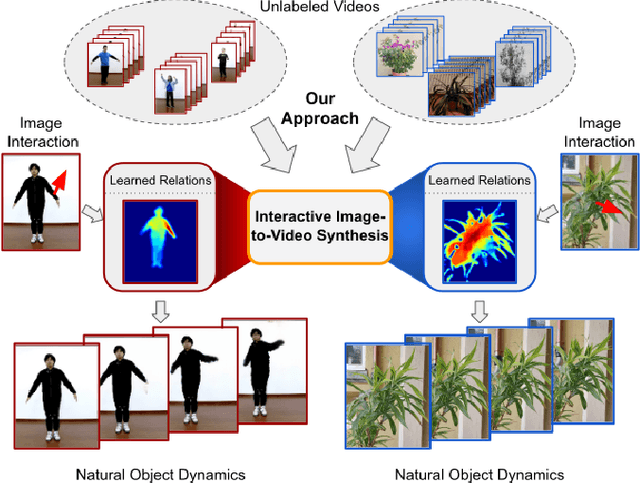
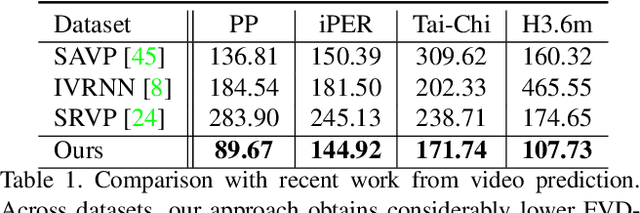
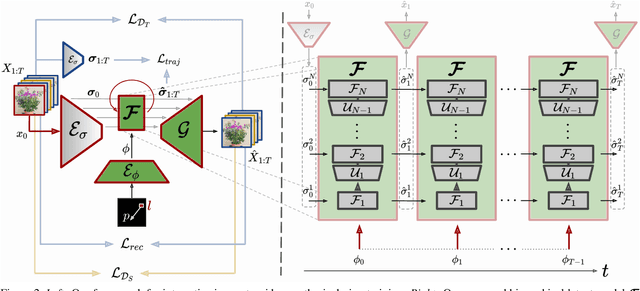

What would be the effect of locally poking a static scene? We present an approach that learns naturally-looking global articulations caused by a local manipulation at a pixel level. Training requires only videos of moving objects but no information of the underlying manipulation of the physical scene. Our generative model learns to infer natural object dynamics as a response to user interaction and learns about the interrelations between different object body regions. Given a static image of an object and a local poking of a pixel, the approach then predicts how the object would deform over time. In contrast to existing work on video prediction, we do not synthesize arbitrary realistic videos but enable local interactive control of the deformation. Our model is not restricted to particular object categories and can transfer dynamics onto novel unseen object instances. Extensive experiments on diverse objects demonstrate the effectiveness of our approach compared to common video prediction frameworks. Project page is available at https://bit.ly/3cxfA2L .