 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Heterogeneous Data Fusion Considering Spatial Correlations using Graph Convolutional Networks and its Application in Air Quality Prediction
May 24, 2021
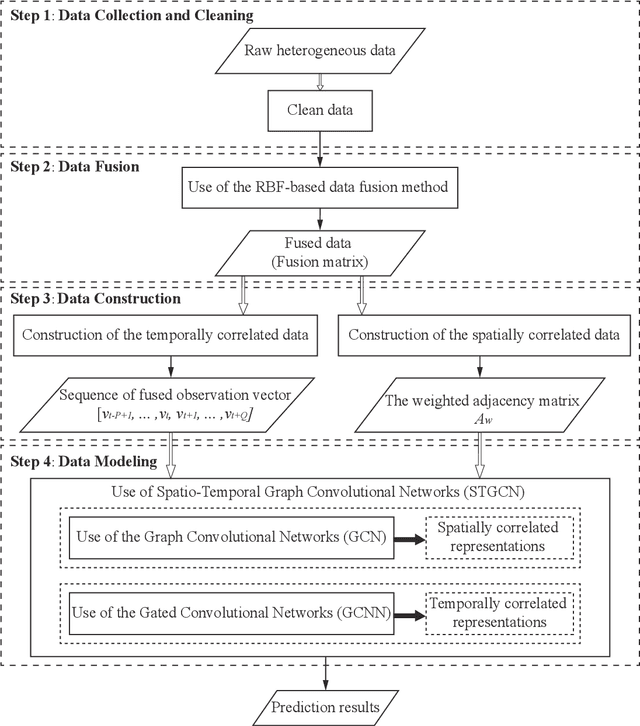
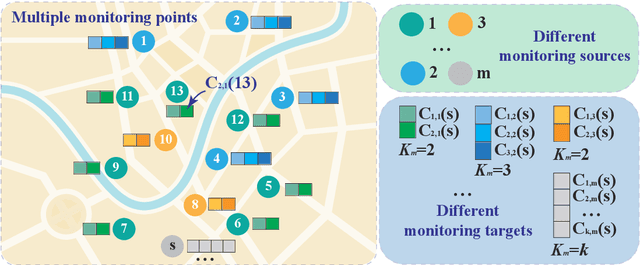

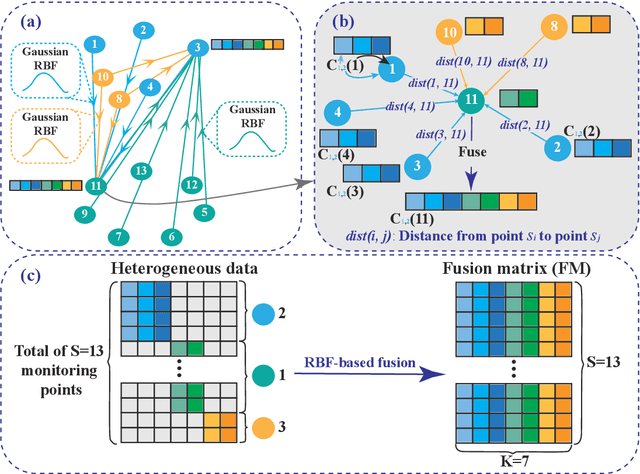
Heterogeneous data are commonly adopted as the inputs for some models that predict the future trends of some observations. Existing predictive models typically ignore the inconsistencies and imperfections in heterogeneous data while also failing to consider the (1) spatial correlations among monitoring points or (2) predictions for the entire study area. To address the above problems, this paper proposes a deep learning method for fusing heterogeneous data collected from multiple monitoring points using graph convolutional networks (GCNs) to predict the future trends of some observations and evaluates its effectiveness by applying it in an air quality predictions scenario. The essential idea behind the proposed method is to (1) fuse the collected heterogeneous data based on the locations of the monitoring points with regard to their spatial correlations and (2) perform prediction based on global information rather than local information. In the proposed method, first, we assemble a fusion matrix using the proposed RBF-based fusion approach; second, based on the fused data, we construct spatially and temporally correlated data as inputs for the predictive model; finally, we employ the spatiotemporal graph convolutional network (STGCN) to predict the future trends of some observations. In the application scenario of air quality prediction, it is observed that (1) the fused data derived from the RBF-based fusion approach achieve satisfactory consistency; (2) the performances of the prediction models based on fused data are better than those based on raw data; and (3) the STGCN model achieves the best performance when compared to those of all baseline models. The proposed method is applicable for similar scenarios where continuous heterogeneous data are collected from multiple monitoring points scattered across a study area.
DIR-ST$^2$: Delineation of Imprecise Regions Using Spatio--Temporal--Textual Information
Jun 09, 2018
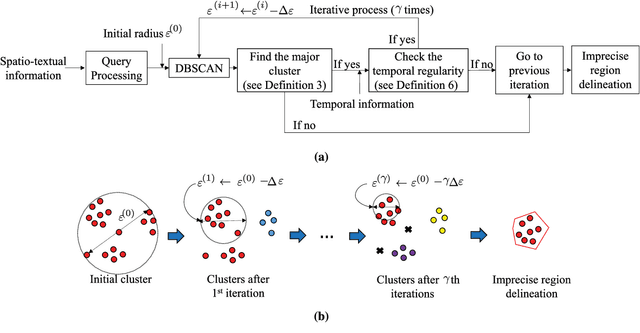
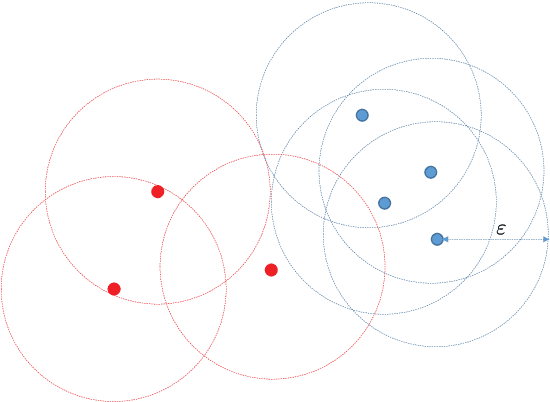
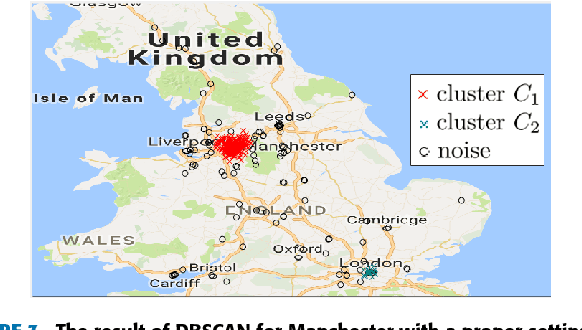
An imprecise region is referred to as a geographical area without a clearly-defined boundary in the literature. Previous clustering-based approaches exploit spatial information to find such regions. However, the prior studies suffer from the following two problems: the subjectivity in selecting clustering parameters and the inclusion of a large portion of the undesirable region (i.e., a large number of noise points). To overcome these problems, we present DIR-ST$^2$, a novel framework for delineating an imprecise region by iteratively performing density-based clustering, namely DBSCAN, along with not only spatio--textual information but also temporal information on social media. Specifically, we aim at finding a proper radius of a circle used in the iterative DBSCAN process by gradually reducing the radius for each iteration in which the temporal information acquired from all resulting clusters are leveraged. Then, we propose an efficient and automated algorithm delineating the imprecise region via hierarchical clustering. Experiment results show that by virtue of the significant noise reduction in the region, our DIR-ST$^2$ method outperforms the state-of-the-art approach employing one-class support vector machine in terms of the $\mathcal{F}_1$ score from comparison with precisely-defined regions regarded as a ground truth, and returns apparently better delineation of imprecise regions. The computational complexity of DIR-ST$^2$ is also analytically and numerically shown.
High-Frequency aware Perceptual Image Enhancement
May 25, 2021
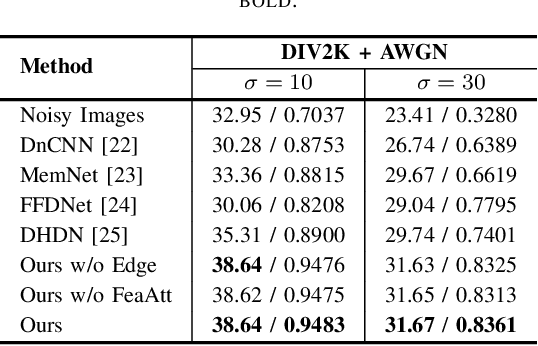
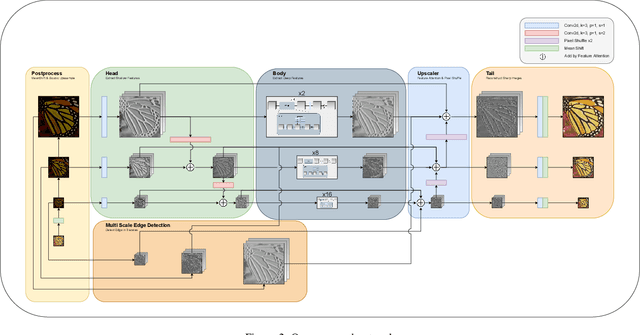
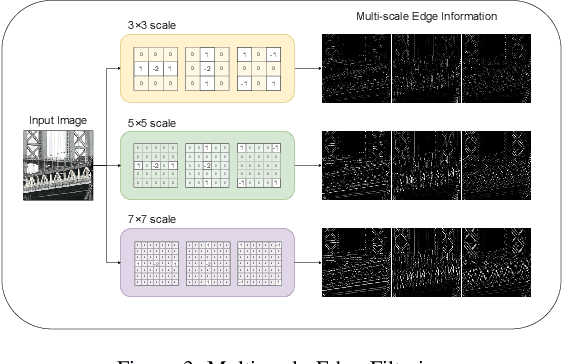
In this paper, we introduce a novel deep neural network suitable for multi-scale analysis and propose efficient model-agnostic methods that help the network extract information from high-frequency domains to reconstruct clearer images. Our model can be applied to multi-scale image enhancement problems including denoising, deblurring and single image super-resolution. Experiments on SIDD, Flickr2K, DIV2K, and REDS datasets show that our method achieves state-of-the-art performance on each task. Furthermore, we show that our model can overcome the over-smoothing problem commonly observed in existing PSNR-oriented methods and generate more natural high-resolution images by applying adversarial training.
Experience Report: Deep Learning-based System Log Analysis for Anomaly Detection
Jul 13, 2021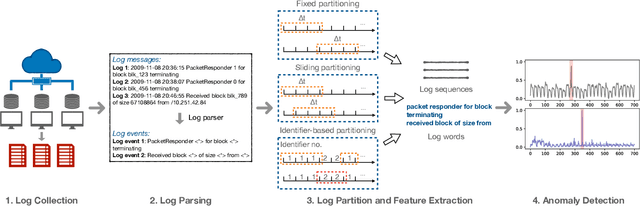

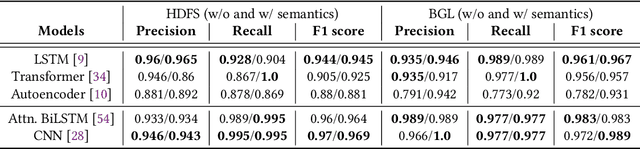
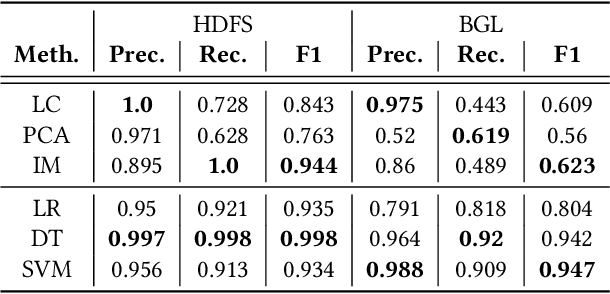
Logs have been an imperative resource to ensure the reliability and continuity of many software systems, especially large-scale distributed systems. They faithfully record runtime information to facilitate system troubleshooting and behavior understanding. Due to the large scale and complexity of modern software systems, the volume of logs has reached an unprecedented level. Consequently, for log-based anomaly detection, conventional methods of manual inspection or even traditional machine learning-based methods become impractical, which serve as a catalyst for the rapid development of deep learning-based solutions. However, there is currently a lack of rigorous comparison among the representative log-based anomaly detectors which resort to neural network models. Moreover, the re-implementation process demands non-trivial efforts and bias can be easily introduced. To better understand the characteristics of different anomaly detectors, in this paper, we provide a comprehensive review and evaluation on five popular models used by six state-of-the-art methods. Particularly, four of the selected methods are unsupervised and the remaining two are supervised. These methods are evaluated with two publicly-available log datasets, which contain nearly 16 millions log messages and 0.4 million anomaly instances in total. We believe our work can serve as a basis in this field and contribute to the future academic researches and industrial applications.
Multi-compartment diffusion MRI, T2 relaxometry and myelin water imaging as neuroimaging descriptors for anomalous tissue detection
Apr 15, 2021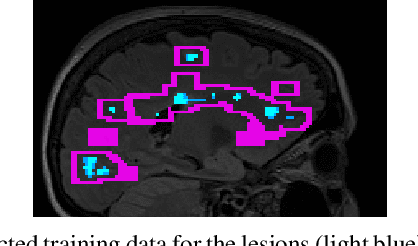
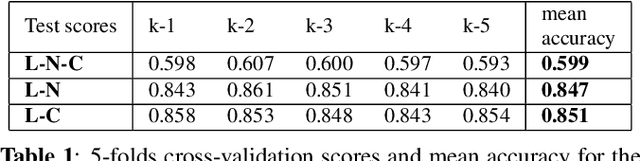
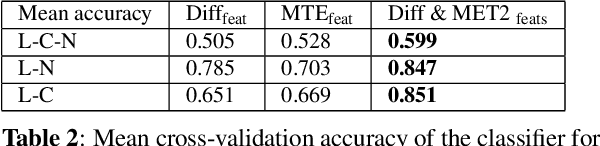
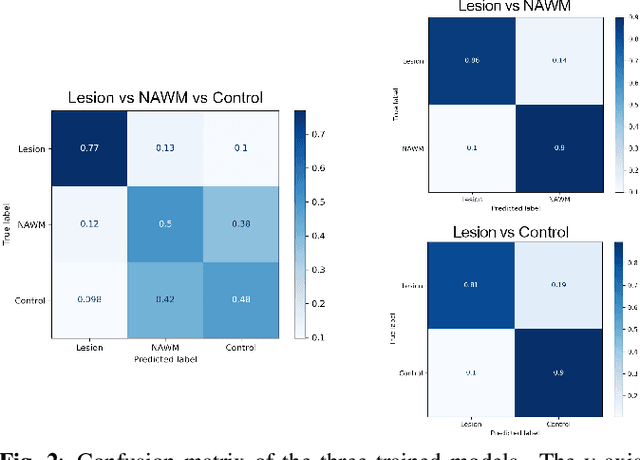
Multiple sclerosis (MS) is an inflammatory and neurodegenerative disease characterized by diffuse and focal areas of tissue loss. Conventional MRI techniques such as T1-weighted and T2-weighted scans are generally used in the diagnosis and prognosis of the disease. Yet, these methods are limited by the lack of specificity between lesions, their perilesional area and non-lesional tissue. Alternative MRI techniques exhibit a higher level of sensitivity to focal and diffuse MS pathology than conventional MRI acquisitions. However, they still suffer from limited specificity when considered alone. In this work, we have combined tissue microstructure information derived from multicompartment diffusion MRI and T2 relaxometry models to explore the voxel-based prediction power of a machine learning model in a cohort of MS patients and healthy controls. Our results show that the combination of multi-modal features, together with a boosting enhanced decision-tree based classifier, which combines a set of weak classifiers to form a strong classifier via a voting mechanism, is able to utilise the complementary information for the classification of abnormal tissue.
LeViT-UNet: Make Faster Encoders with Transformer for Medical Image Segmentation
Jul 19, 2021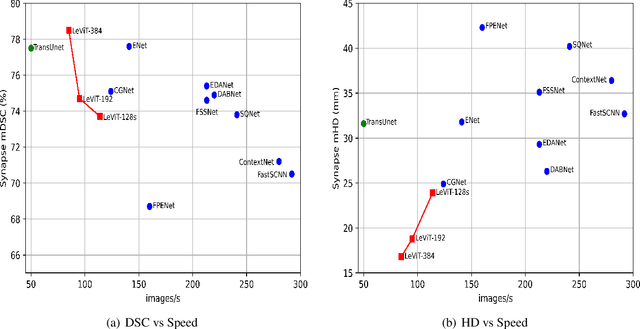
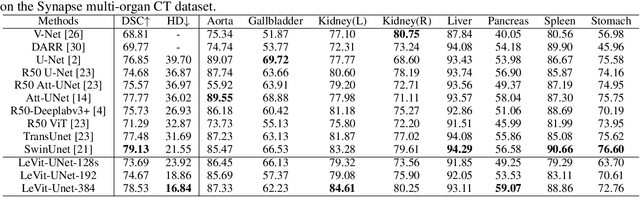
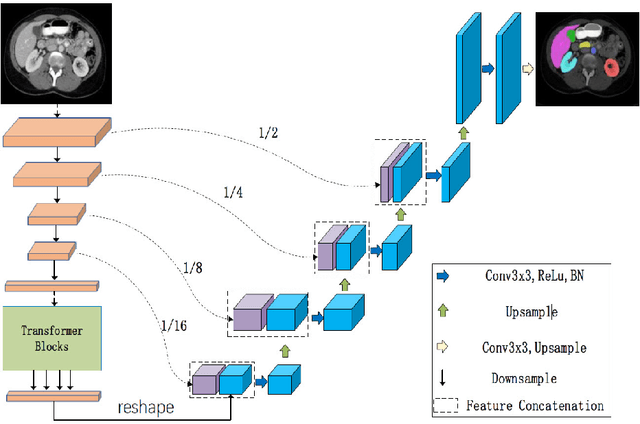
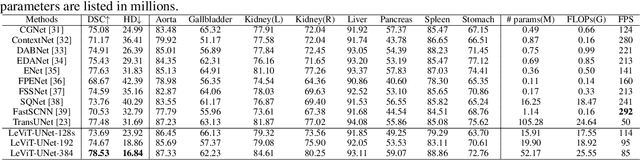
Medical image segmentation plays an essential role in developing computer-assisted diagnosis and therapy systems, yet still faces many challenges. In the past few years, the popular encoder-decoder architectures based on CNNs (e.g., U-Net) have been successfully applied in the task of medical image segmentation. However, due to the locality of convolution operations, they demonstrate limitations in learning global context and long-range spatial relations. Recently, several researchers try to introduce transformers to both the encoder and decoder components with promising results, but the efficiency requires further improvement due to the high computational complexity of transformers. In this paper, we propose LeViT-UNet, which integrates a LeViT Transformer module into the U-Net architecture, for fast and accurate medical image segmentation. Specifically, we use LeViT as the encoder of the LeViT-UNet, which better trades off the accuracy and efficiency of the Transformer block. Moreover, multi-scale feature maps from transformer blocks and convolutional blocks of LeViT are passed into the decoder via skip-connection, which can effectively reuse the spatial information of the feature maps. Our experiments indicate that the proposed LeViT-UNet achieves better performance comparing to various competing methods on several challenging medical image segmentation benchmarks including Synapse and ACDC. Code and models will be publicly available at https://github.com/apple1986/LeViT_UNet.
SA-LOAM: Semantic-aided LiDAR SLAM with Loop Closure
Jun 22, 2021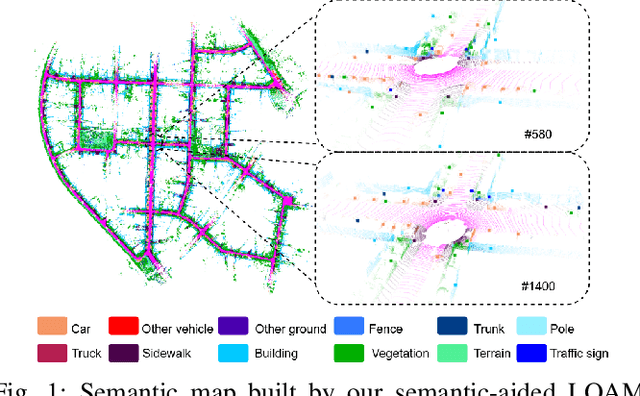
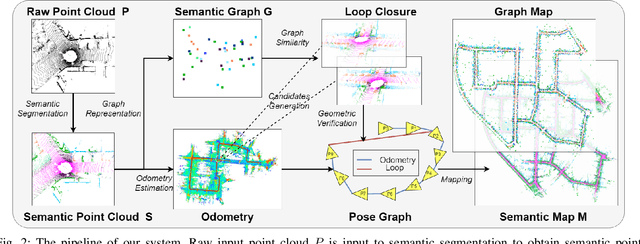

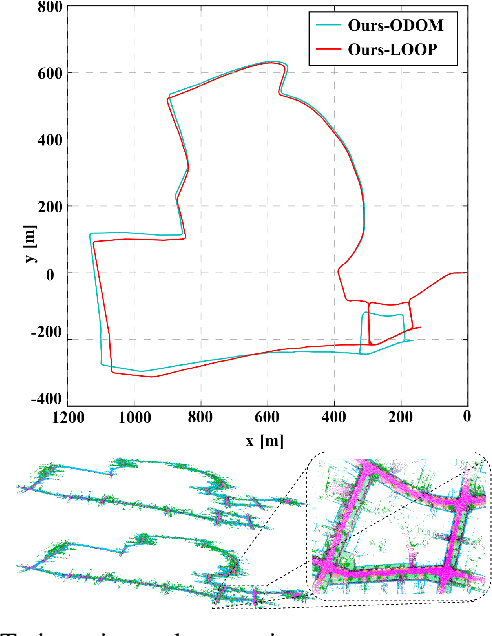
LiDAR-based SLAM system is admittedly more accurate and stable than others, while its loop closure detection is still an open issue. With the development of 3D semantic segmentation for point cloud, semantic information can be obtained conveniently and steadily, essential for high-level intelligence and conductive to SLAM. In this paper, we present a novel semantic-aided LiDAR SLAM with loop closure based on LOAM, named SA-LOAM, which leverages semantics in odometry as well as loop closure detection. Specifically, we propose a semantic-assisted ICP, including semantically matching, downsampling and plane constraint, and integrates a semantic graph-based place recognition method in our loop closure detection module. Benefitting from semantics, we can improve the localization accuracy, detect loop closures effectively, and construct a global consistent semantic map even in large-scale scenes. Extensive experiments on KITTI and Ford Campus dataset show that our system significantly improves baseline performance, has generalization ability to unseen data and achieves competitive results compared with state-of-the-art methods.
An Accurate Non-accelerometer-based PPG Motion Artifact Removal Technique using CycleGAN
Jun 22, 2021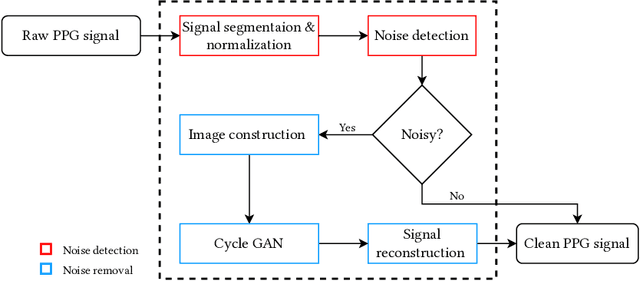
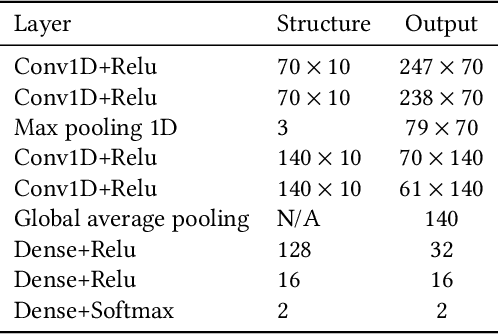
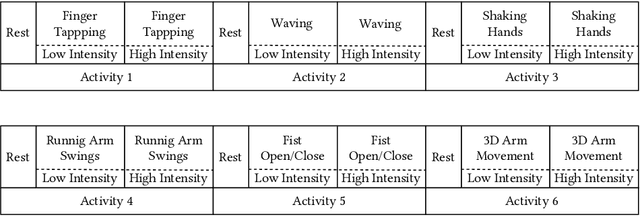
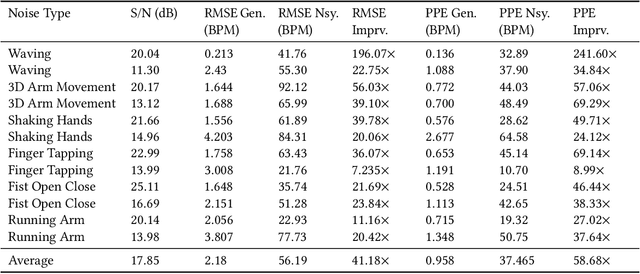
A photoplethysmography (PPG) is an uncomplicated and inexpensive optical technique widely used in the healthcare domain to extract valuable health-related information, e.g., heart rate variability, blood pressure, and respiration rate. PPG signals can easily be collected continuously and remotely using portable wearable devices. However, these measuring devices are vulnerable to motion artifacts caused by daily life activities. The most common ways to eliminate motion artifacts use extra accelerometer sensors, which suffer from two limitations: i) high power consumption and ii) the need to integrate an accelerometer sensor in a wearable device (which is not required in certain wearables). This paper proposes a low-power non-accelerometer-based PPG motion artifacts removal method outperforming the accuracy of the existing methods. We use Cycle Generative Adversarial Network to reconstruct clean PPG signals from noisy PPG signals. Our novel machine-learning-based technique achieves 9.5 times improvement in motion artifact removal compared to the state-of-the-art without using extra sensors such as an accelerometer.
Spatial-Phase Shallow Learning: Rethinking Face Forgery Detection in Frequency Domain
Mar 10, 2021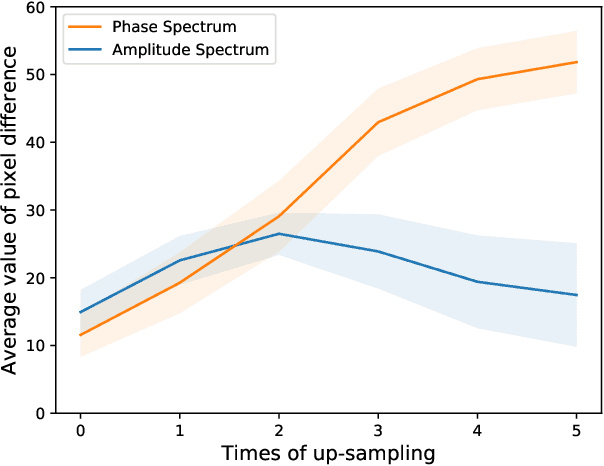
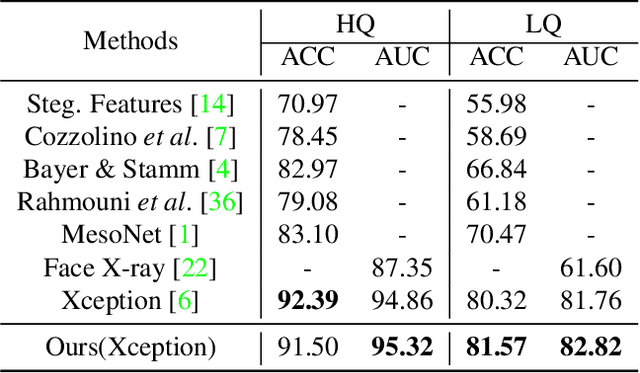
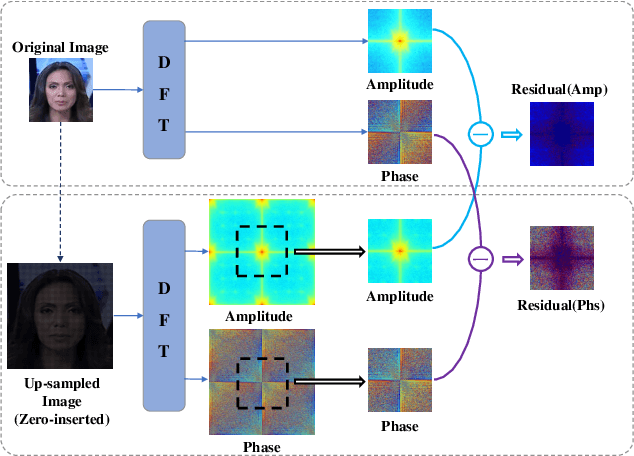
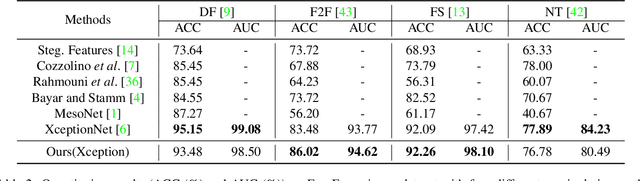
The remarkable success in face forgery techniques has received considerable attention in computer vision due to security concerns. We observe that up-sampling is a necessary step of most face forgery techniques, and cumulative up-sampling will result in obvious changes in the frequency domain, especially in the phase spectrum. According to the property of natural images, the phase spectrum preserves abundant frequency components that provide extra information and complement the loss of the amplitude spectrum. To this end, we present a novel Spatial-Phase Shallow Learning (SPSL) method, which combines spatial image and phase spectrum to capture the up-sampling artifacts of face forgery to improve the transferability, for face forgery detection. And we also theoretically analyze the validity of utilizing the phase spectrum. Moreover, we notice that local texture information is more crucial than high-level semantic information for the face forgery detection task. So we reduce the receptive fields by shallowing the network to suppress high-level features and focus on the local region. Extensive experiments show that SPSL can achieve the state-of-the-art performance on cross-datasets evaluation as well as multi-class classification and obtain comparable results on single dataset evaluation.
A LiDAR-Guided Framework for Video Enhancement
Mar 15, 2021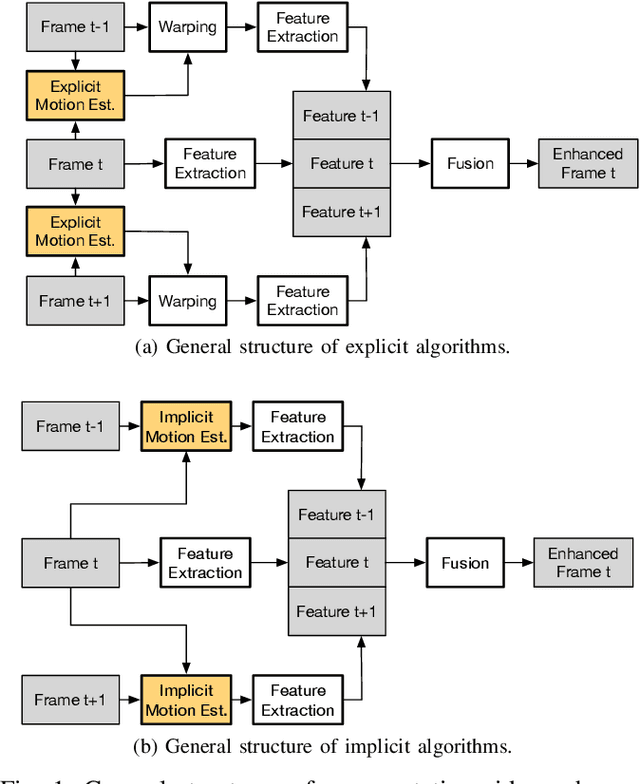

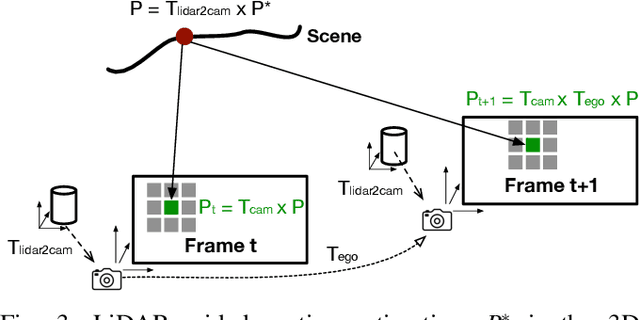

This paper presents a general framework that simultaneously improves the quality and the execution speed of a range of video enhancement tasks, such as super-sampling, deblurring, and denoising. The key to our framework is a pixel motion estimation algorithm that generates accurate motion from low-quality videos while being computationally very lightweight. Our motion estimation algorithm leverages point cloud information, which is readily available in today's autonomous devices and will only become more common in the future. We demonstrate a generic framework that leverages the motion information to guide high-quality image reconstruction. Experiments show that our framework consistently outperforms the state-of-the-art video enhancement algorithms while improving the execution speed by an order of magnitude.