 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
TopicTracker: A Platform for Topic Trajectory Identification and Visualisation
Mar 02, 2021
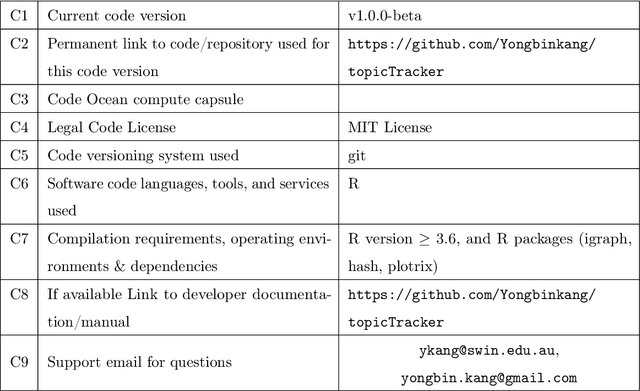
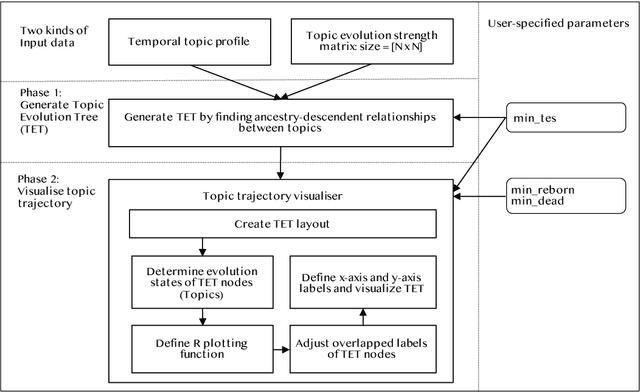
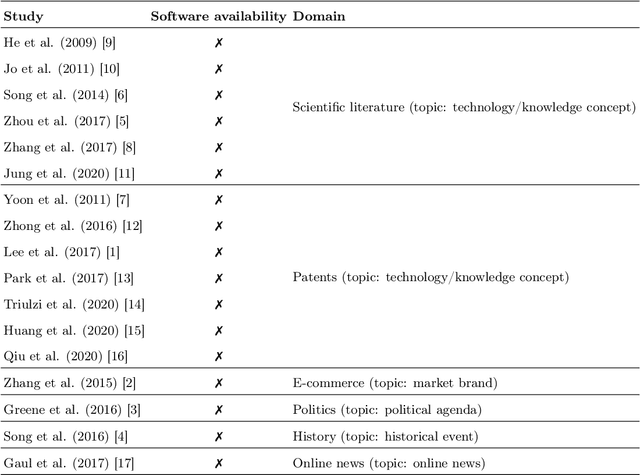
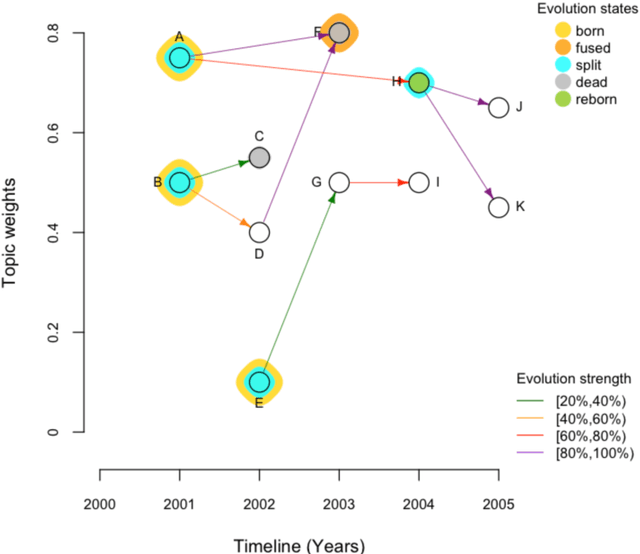
Topic trajectory information provides crucial insight into the dynamics of topics and their evolutionary relationships over a given time. Also, this information can help to improve our understanding on how new topics have emerged or formed through a sequential or interrelated events of emergence, modification and integration of prior topics. Nevertheless, the implementation of the existing methods for topic trajectory identification is rarely available as usable software. In this paper, we present TopicTracker, a platform for topic trajectory identification and visualisation. The key of Topic Tracker is that it can represent the three facets of information together, given two kinds of input: a time-stamped topic profile consisting of the set of the underlying topics over time, and the evolution strength matrix among them: evolutionary pathways of dynamic topics, evolution states of the topics, and topic importance. TopicTracker is a publicly available software implemented using the R software.
Prior-Guided Multi-View 3D Head Reconstruction
Jul 09, 2021
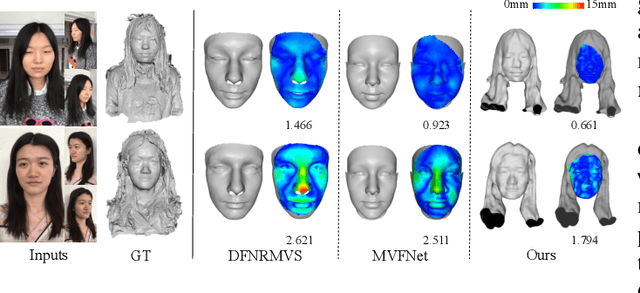


Recovering a 3D head model including the complete face and hair regions is still a challenging problem in computer vision and graphics. In this paper, we consider this problem with a few multi-view portrait images as input. Previous multi-view stereo methods, either based on the optimization strategies or deep learning techniques, suffer from low-frequency geometric structures such as unclear head structures and inaccurate reconstruction in hair regions. To tackle this problem, we propose a prior-guided implicit neural rendering network. Specifically, we model the head geometry with a learnable signed distance field (SDF) and optimize it via an implicit differentiable renderer with the guidance of some human head priors, including the facial prior knowledge, head semantic segmentation information and 2D hair orientation maps. The utilization of these priors can improve the reconstruction accuracy and robustness, leading to a high-quality integrated 3D head model. Extensive ablation studies and comparisons with state-of-the-art methods demonstrate that our method could produce high-fidelity 3D head geometries with the guidance of these priors.
Stochastic Natural Language Generation Using Dependency Information
Jan 12, 2020
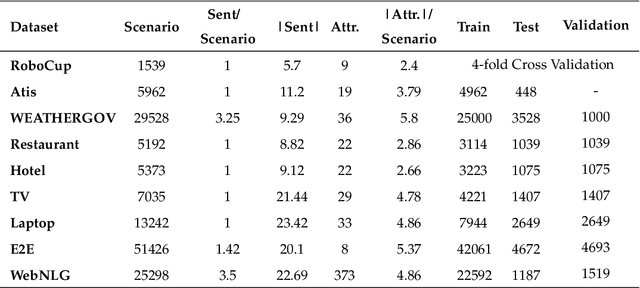
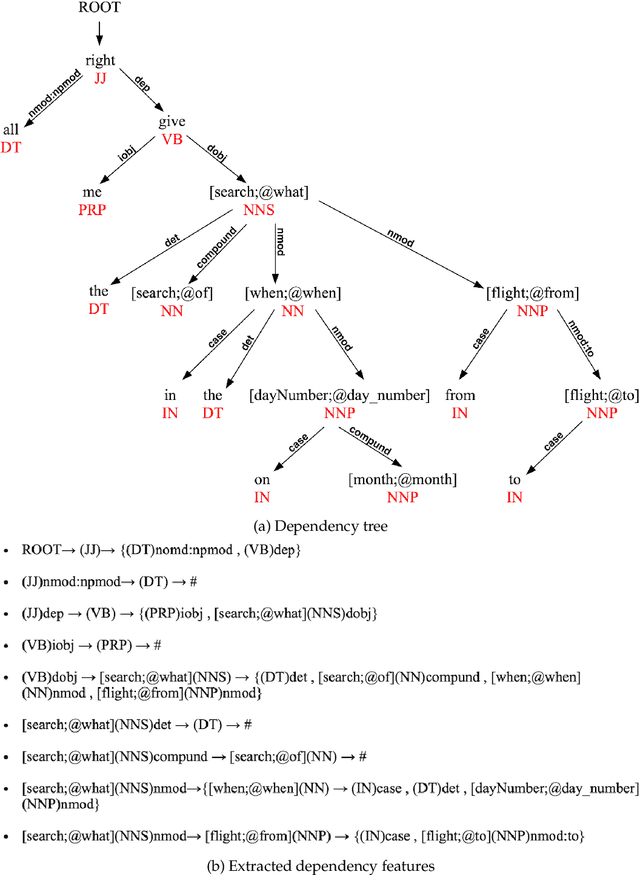

This article presents a stochastic corpus-based model for generating natural language text. Our model first encodes dependency relations from training data through a feature set, then concatenates these features to produce a new dependency tree for a given meaning representation, and finally generates a natural language utterance from the produced dependency tree. We test our model on nine domains from tabular, dialogue act and RDF format. Our model outperforms the corpus-based state-of-the-art methods trained on tabular datasets and also achieves comparable results with neural network-based approaches trained on dialogue act, E2E and WebNLG datasets for BLEU and ERR evaluation metrics. Also, by reporting Human Evaluation results, we show that our model produces high-quality utterances in aspects of informativeness and naturalness as well as quality.
Differentially Private Densest Subgraph Detection
Jun 18, 2021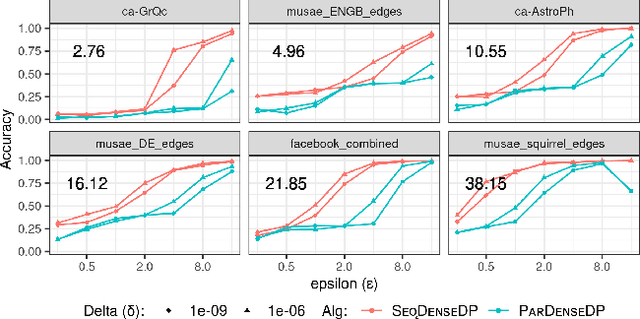

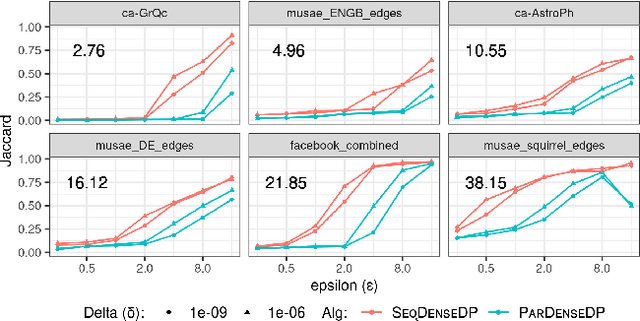

Densest subgraph detection is a fundamental graph mining problem, with a large number of applications. There has been a lot of work on efficient algorithms for finding the densest subgraph in massive networks. However, in many domains, the network is private, and returning a densest subgraph can reveal information about the network. Differential privacy is a powerful framework to handle such settings. We study the densest subgraph problem in the edge privacy model, in which the edges of the graph are private. We present the first sequential and parallel differentially private algorithms for this problem. We show that our algorithms have an additive approximation guarantee. We evaluate our algorithms on a large number of real-world networks, and observe a good privacy-accuracy tradeoff when the network has high density.
TransSC: Transformer-based Shape Completion for Grasp Evaluation
Jul 01, 2021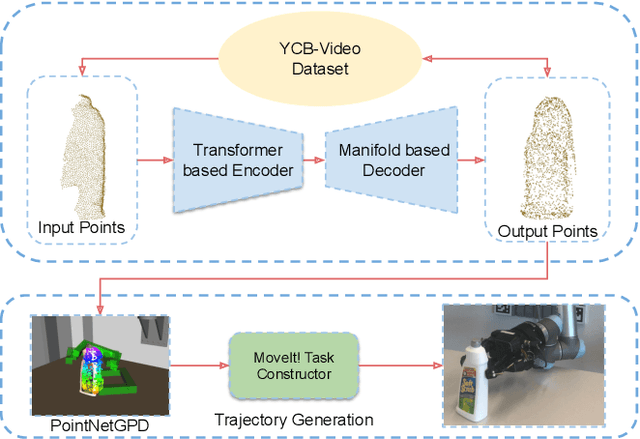
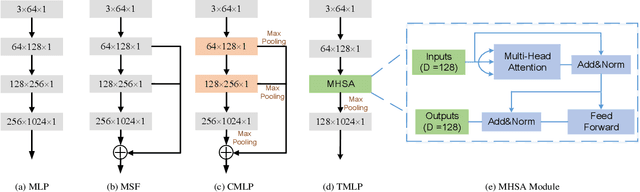
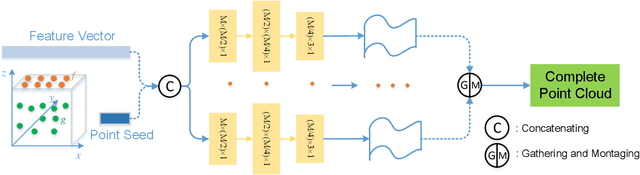
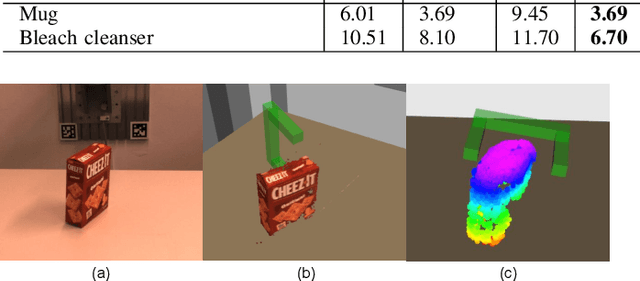
Currently, robotic grasping methods based on sparse partial point clouds have attained a great grasping performance on various objects while they often generate wrong grasping candidates due to the lack of geometric information on the object. In this work, we propose a novel and robust shape completion model (TransSC). This model has a transformer-based encoder to explore more point-wise features and a manifold-based decoder to exploit more object details using a partial point cloud as input. Quantitative experiments verify the effectiveness of the proposed shape completion network and demonstrate it outperforms existing methods. Besides, TransSC is integrated into a grasp evaluation network to generate a set of grasp candidates. The simulation experiment shows that TransSC improves the grasping generation result compared to the existing shape completion baselines. Furthermore, our robotic experiment shows that with TransSC the robot is more successful in grasping objects that are randomly placed on a support surface.
Deep Monocular 3D Human Pose Estimation via Cascaded Dimension-Lifting
Apr 08, 2021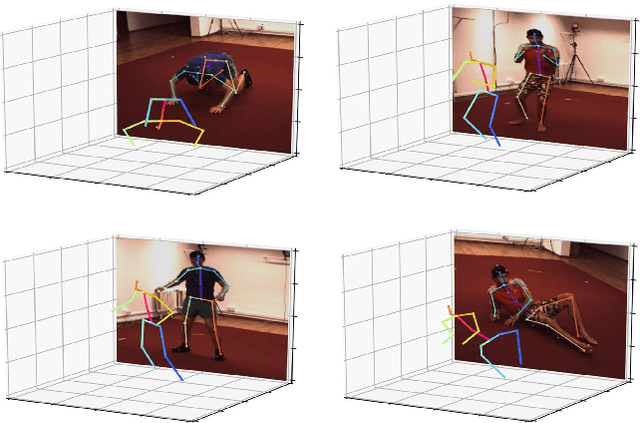
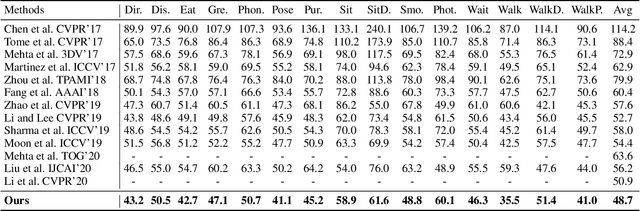
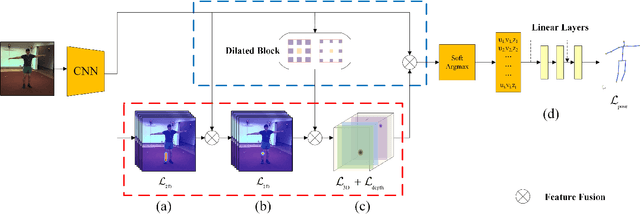
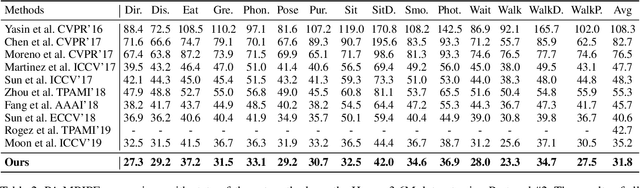
The 3D pose estimation from a single image is a challenging problem due to depth ambiguity. One type of the previous methods lifts 2D joints, obtained by resorting to external 2D pose detectors, to the 3D space. However, this type of approaches discards the contextual information of images which are strong cues for 3D pose estimation. Meanwhile, some other methods predict the joints directly from monocular images but adopt a 2.5D output representation $P^{2.5D} = (u,v,z^{r}) $ where both $u$ and $v$ are in the image space but $z^{r}$ in root-relative 3D space. Thus, the ground-truth information (e.g., the depth of root joint from the camera) is normally utilized to transform the 2.5D output to the 3D space, which limits the applicability in practice. In this work, we propose a novel end-to-end framework that not only exploits the contextual information but also produces the output directly in the 3D space via cascaded dimension-lifting. Specifically, we decompose the task of lifting pose from 2D image space to 3D spatial space into several sequential sub-tasks, 1) kinematic skeletons \& individual joints estimation in 2D space, 2) root-relative depth estimation, and 3) lifting to the 3D space, each of which employs direct supervisions and contextual image features to guide the learning process. Extensive experiments show that the proposed framework achieves state-of-the-art performance on two widely used 3D human pose datasets (Human3.6M, MuPoTS-3D).
The Many Dimensions of Truthfulness: Crowdsourcing Misinformation Assessments on a Multidimensional Scale
Aug 03, 2021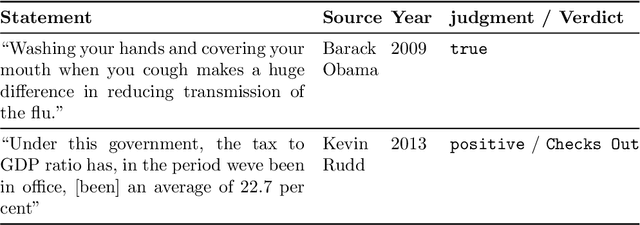
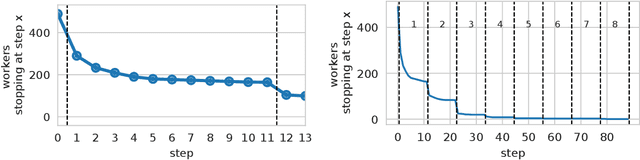
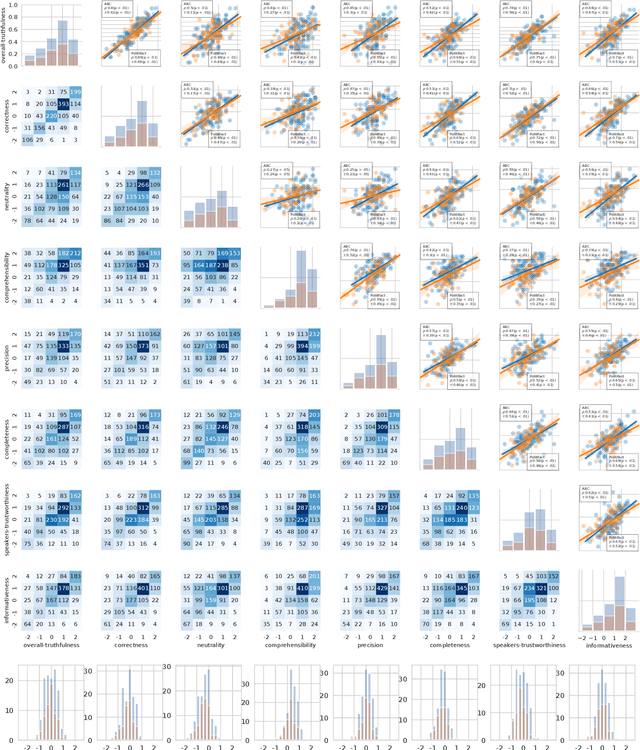
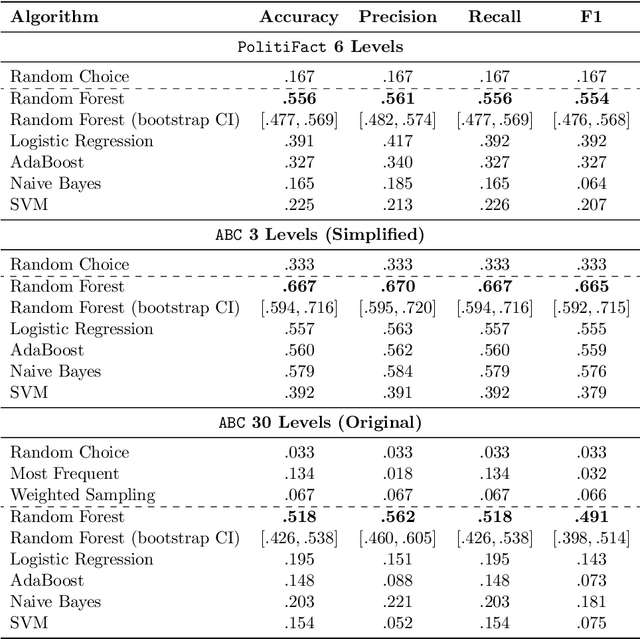
Recent work has demonstrated the viability of using crowdsourcing as a tool for evaluating the truthfulness of public statements. Under certain conditions such as: (1) having a balanced set of workers with different backgrounds and cognitive abilities; (2) using an adequate set of mechanisms to control the quality of the collected data; and (3) using a coarse grained assessment scale, the crowd can provide reliable identification of fake news. However, fake news are a subtle matter: statements can be just biased ("cherrypicked"), imprecise, wrong, etc. and the unidimensional truth scale used in existing work cannot account for such differences. In this paper we propose a multidimensional notion of truthfulness and we ask the crowd workers to assess seven different dimensions of truthfulness selected based on existing literature: Correctness, Neutrality, Comprehensibility, Precision, Completeness, Speaker's Trustworthiness, and Informativeness. We deploy a set of quality control mechanisms to ensure that the thousands of assessments collected on 180 publicly available fact-checked statements distributed over two datasets are of adequate quality, including a custom search engine used by the crowd workers to find web pages supporting their truthfulness assessments. A comprehensive analysis of crowdsourced judgments shows that: (1) the crowdsourced assessments are reliable when compared to an expert-provided gold standard; (2) the proposed dimensions of truthfulness capture independent pieces of information; (3) the crowdsourcing task can be easily learned by the workers; and (4) the resulting assessments provide a useful basis for a more complete estimation of statement truthfulness.
Entropy of the Conditional Expectation under Gaussian Noise
Jun 08, 2021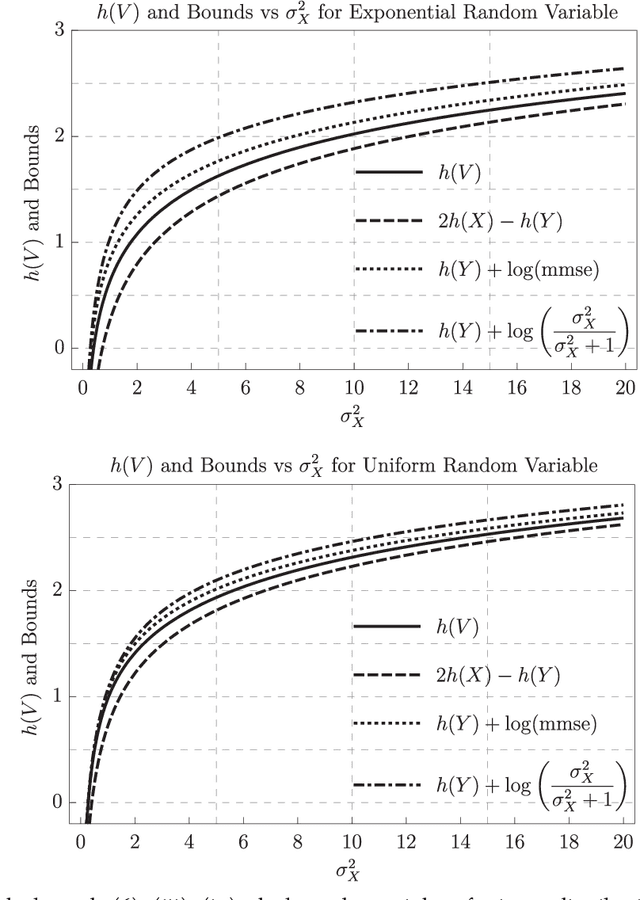
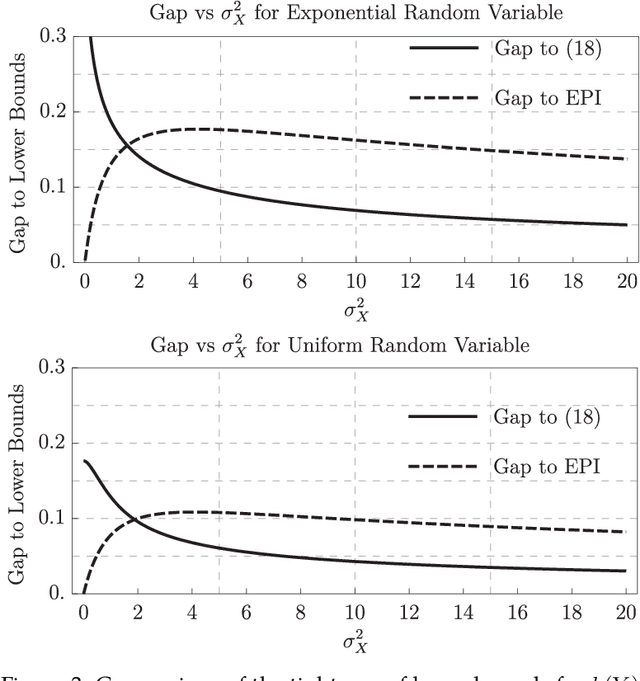
This paper considers an additive Gaussian noise channel with arbitrarily distributed finite variance input signals. It studies the differential entropy of the minimum mean-square error (MMSE) estimator and provides a new lower bound which connects the entropy of the input, output, and conditional mean. That is, the sum of entropies of the conditional mean and output is always greater than or equal to twice the input entropy. Various other properties such as upper bounds, asymptotics, Taylor series expansion, and connection to Fisher Information are obtained. An application of the lower bound in the remote-source coding problem is discussed, and extensions of the lower and upper bounds to the vector Gaussian channel are given.
Bringing Structure into Summaries: a Faceted Summarization Dataset for Long Scientific Documents
Jun 23, 2021
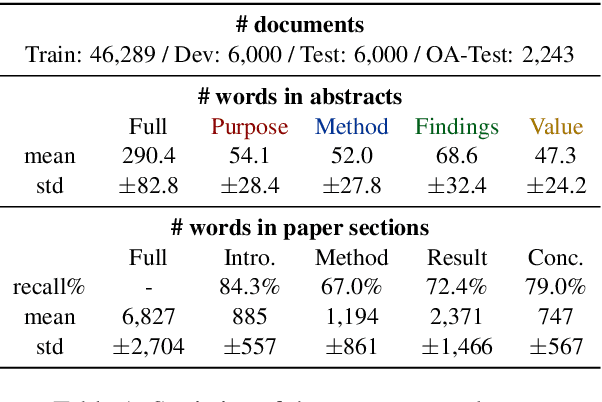

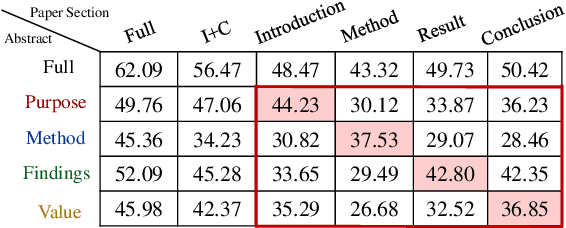
Faceted summarization provides briefings of a document from different perspectives. Readers can quickly comprehend the main points of a long document with the help of a structured outline. However, little research has been conducted on this subject, partially due to the lack of large-scale faceted summarization datasets. In this study, we present FacetSum, a faceted summarization benchmark built on Emerald journal articles, covering a diverse range of domains. Different from traditional document-summary pairs, FacetSum provides multiple summaries, each targeted at specific sections of a long document, including the purpose, method, findings, and value. Analyses and empirical results on our dataset reveal the importance of bringing structure into summaries. We believe FacetSum will spur further advances in summarization research and foster the development of NLP systems that can leverage the structured information in both long texts and summaries.
Case-based similar image retrieval for weakly annotated large histopathological images of malignant lymphoma using deep metric learning
Jul 09, 2021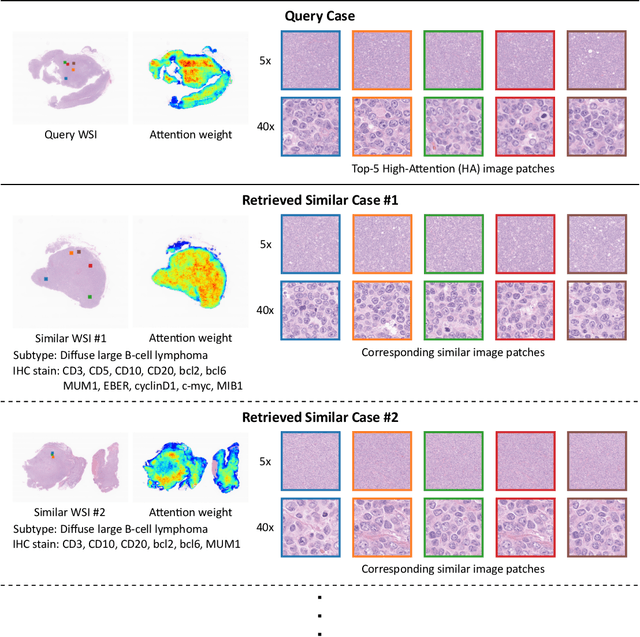
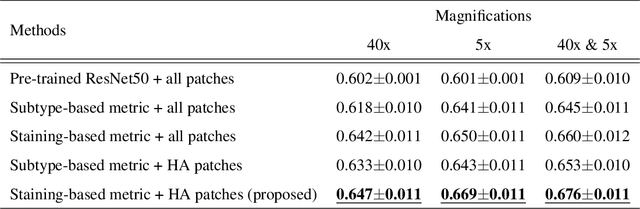
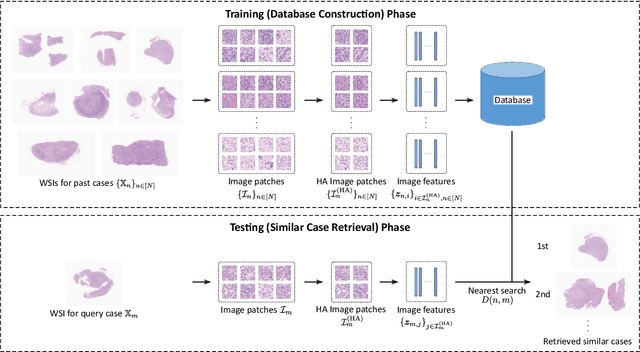
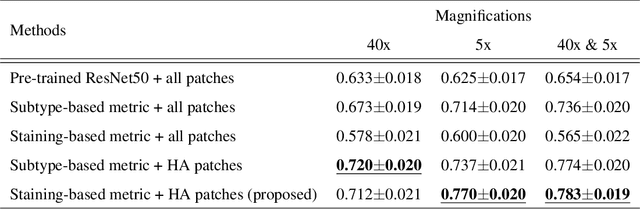
In the present study, we propose a novel case-based similar image retrieval (SIR) method for hematoxylin and eosin (H&E)-stained histopathological images of malignant lymphoma. When a whole slide image (WSI) is used as an input query, it is desirable to be able to retrieve similar cases by focusing on image patches in pathologically important regions such as tumor cells. To address this problem, we employ attention-based multiple instance learning, which enables us to focus on tumor-specific regions when the similarity between cases is computed. Moreover, we employ contrastive distance metric learning to incorporate immunohistochemical (IHC) staining patterns as useful supervised information for defining appropriate similarity between heterogeneous malignant lymphoma cases. In the experiment with 249 malignant lymphoma patients, we confirmed that the proposed method exhibited higher evaluation measures than the baseline case-based SIR methods. Furthermore, the subjective evaluation by pathologists revealed that our similarity measure using IHC staining patterns is appropriate for representing the similarity of H&E-stained tissue images for malignant lymphoma.