 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Face Recognition as a Method of Authentication in a Web-Based System
Mar 28, 2021
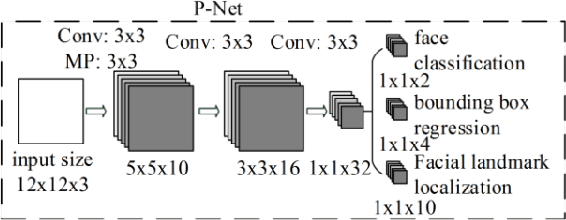
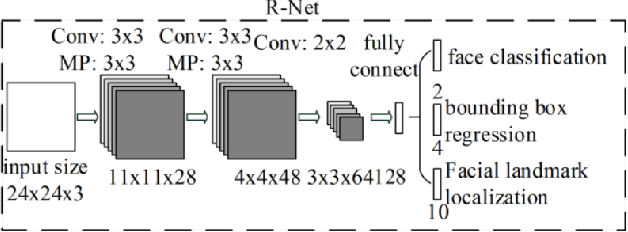


Online information systems currently heavily rely on the username and password traditional method for protecting information and controlling access. With the advancement in biometric technology and popularity of fields like AI and Machine Learning, biometric security is becoming increasingly popular because of the usability advantage. This paper reports how machine learning based face recognition can be integrated into a web-based system as a method of authentication to reap the benefits of improved usability. This paper includes a comparison of combinations of detection and classification algorithms with FaceNet for face recognition. The results show that a combination of MTCNN for detection, Facenet for generating embeddings, and LinearSVC for classification outperforms other combinations with a 95% accuracy. The resulting classifier is integrated into the web-based system and used for authenticating users.
A Deep Learning Approach to Private Data Sharing of Medical Images Using Conditional GANs
Jun 24, 2021Sharing data from clinical studies can facilitate innovative data-driven research and ultimately lead to better public health. However, sharing biomedical data can put sensitive personal information at risk. This is usually solved by anonymization, which is a slow and expensive process. An alternative to anonymization is sharing a synthetic dataset that bears a behaviour similar to the real data but preserves privacy. As part of the collaboration between Novartis and the Oxford Big Data Institute, we generate a synthetic dataset based on COSENTYX (secukinumab) Ankylosing Spondylitis (AS) clinical study. We apply an Auxiliary Classifier GAN (ac-GAN) to generate synthetic magnetic resonance images (MRIs) of vertebral units (VUs). The images are conditioned on the VU location (cervical, thoracic and lumbar). In this paper, we present a method for generating a synthetic dataset and conduct an in-depth analysis on its properties of along three key metrics: image fidelity, sample diversity and dataset privacy.
Lightweight Image Super-Resolution with Hierarchical and Differentiable Neural Architecture Search
May 09, 2021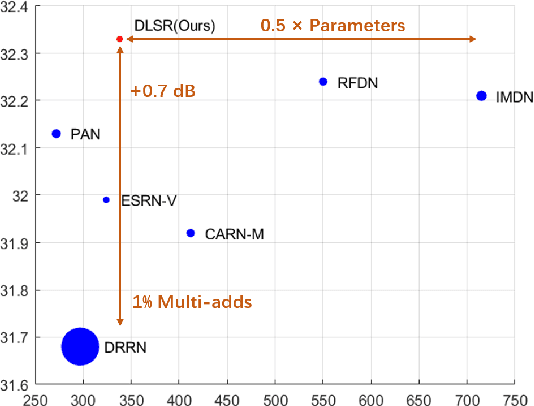
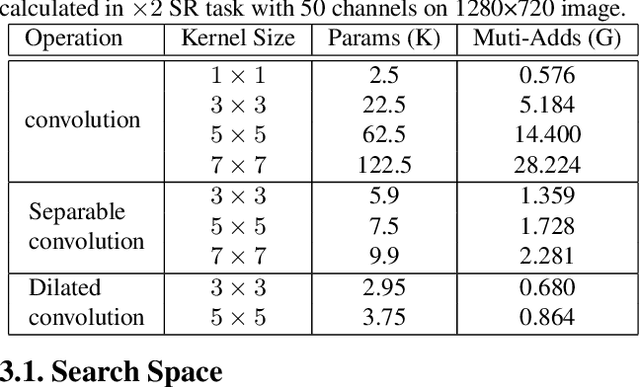
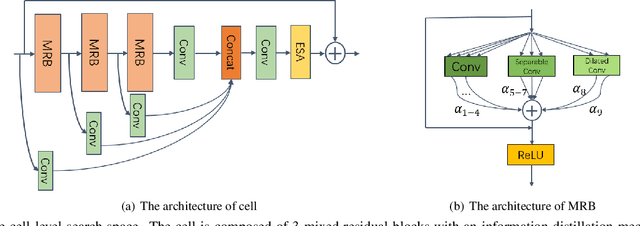
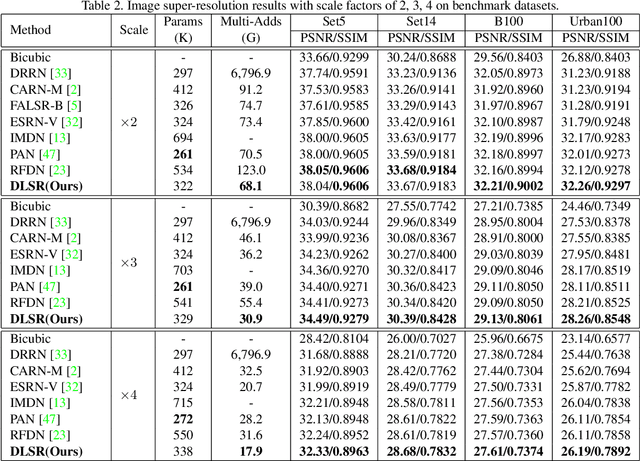
Single Image Super-Resolution (SISR) tasks have achieved significant performance with deep neural networks. However, the large number of parameters in CNN-based methods for SISR tasks require heavy computations. Although several efficient SISR models have been recently proposed, most are handcrafted and thus lack flexibility. In this work, we propose a novel differentiable Neural Architecture Search (NAS) approach on both the cell-level and network-level to search for lightweight SISR models. Specifically, the cell-level search space is designed based on an information distillation mechanism, focusing on the combinations of lightweight operations and aiming to build a more lightweight and accurate SR structure. The network-level search space is designed to consider the feature connections among the cells and aims to find which information flow benefits the cell most to boost the performance. Unlike the existing Reinforcement Learning (RL) or Evolutionary Algorithm (EA) based NAS methods for SISR tasks, our search pipeline is fully differentiable, and the lightweight SISR models can be efficiently searched on both the cell-level and network-level jointly on a single GPU. Experiments show that our methods can achieve state-of-the-art performance on the benchmark datasets in terms of PSNR, SSIM, and model complexity with merely 68G Multi-Adds for $\times 2$ and 18G Multi-Adds for $\times 4$ SR tasks. Code will be available at \url{https://github.com/DawnHH/DLSR-PyTorch}.
Co-GAT: A Co-Interactive Graph Attention Network for Joint Dialog Act Recognition and Sentiment Classification
Dec 24, 2020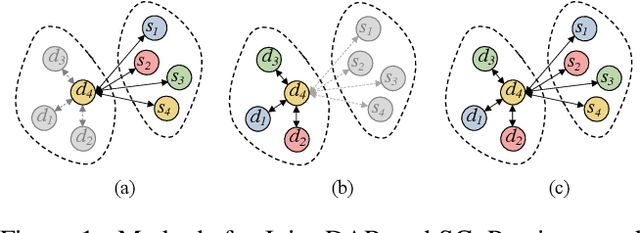
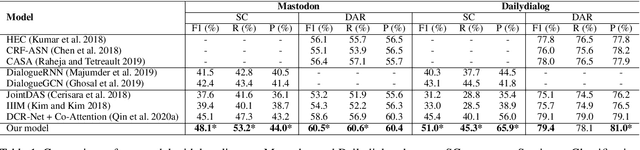

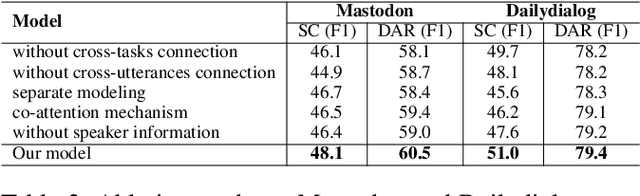
In a dialog system, dialog act recognition and sentiment classification are two correlative tasks to capture speakers intentions, where dialog act and sentiment can indicate the explicit and the implicit intentions separately. The dialog context information (contextual information) and the mutual interaction information are two key factors that contribute to the two related tasks. Unfortunately, none of the existing approaches consider the two important sources of information simultaneously. In this paper, we propose a Co-Interactive Graph Attention Network (Co-GAT) to jointly perform the two tasks. The core module is a proposed co-interactive graph interaction layer where a cross-utterances connection and a cross-tasks connection are constructed and iteratively updated with each other, achieving to consider the two types of information simultaneously. Experimental results on two public datasets show that our model successfully captures the two sources of information and achieve the state-of-the-art performance. In addition, we find that the contributions from the contextual and mutual interaction information do not fully overlap with contextualized word representations (BERT, Roberta, XLNet).
Low-cost Stereovision system (disparity map) for few dollars
Jun 02, 2021


The paper presents an analysis of the latest developments in the field of stereo vision in the low-cost segment, both for prototypes and for industrial designs. We described the theory of stereo vision and presented information about cameras and data transfer protocols and their compatibility with various devices. The theory in the field of image processing for stereo vision processes is considered and the calibration process is described in detail. Ultimately, we presented the developed stereo vision system and provided the main points that need to be considered when developing such systems. The final, we presented software for adjusting stereo vision parameters in real-time in the python language in the Windows operating system.
SalKG: Learning From Knowledge Graph Explanations for Commonsense Reasoning
Apr 18, 2021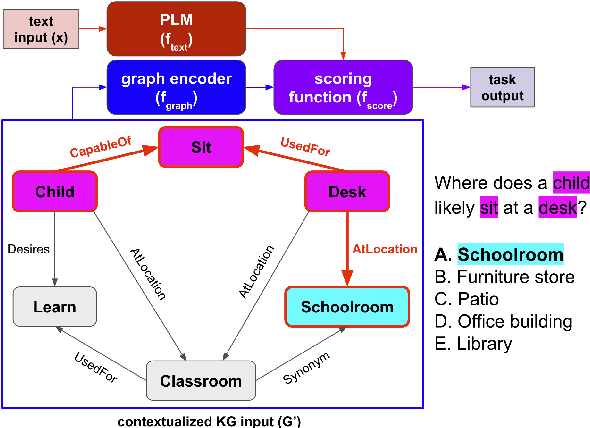

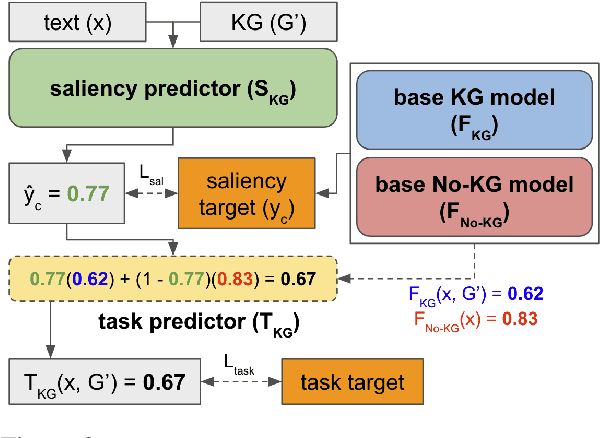
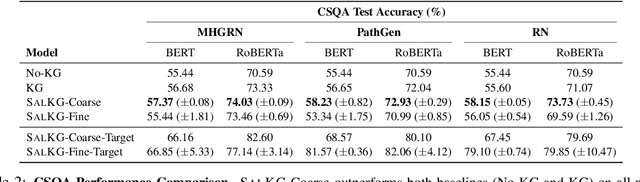
Augmenting pre-trained language models with knowledge graphs (KGs) has achieved success on various commonsense reasoning tasks. Although some works have attempted to explain the behavior of such KG-augmented models by indicating which KG inputs are salient (i.e., important for the model's prediction), it is not always clear how these explanations should be used to make the model better. In this paper, we explore whether KG explanations can be used as supervision for teaching these KG-augmented models how to filter out unhelpful KG information. To this end, we propose SalKG, a simple framework for learning from KG explanations of both coarse (Is the KG salient?) and fine (Which parts of the KG are salient?) granularity. Given the explanations generated from a task's training set, SalKG trains KG-augmented models to solve the task by focusing on KG information highlighted by the explanations as salient. Across two popular commonsense QA benchmarks and three KG-augmented models, we find that SalKG's training process can consistently improve model performance.
Privacy Threats Analysis to Secure Federated Learning
Jun 24, 2021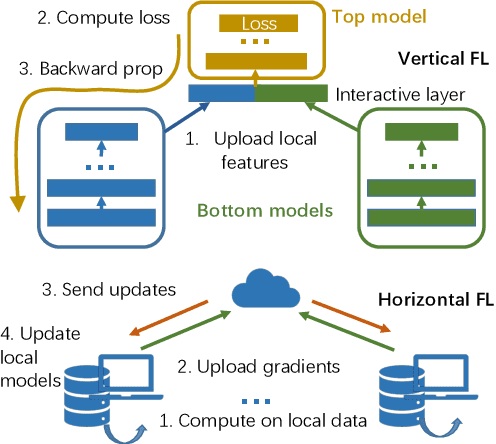
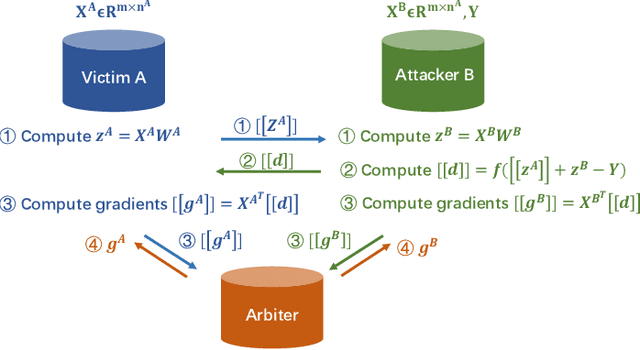
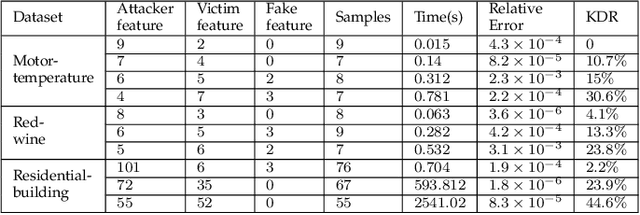
Federated learning is emerging as a machine learning technique that trains a model across multiple decentralized parties. It is renowned for preserving privacy as the data never leaves the computational devices, and recent approaches further enhance its privacy by hiding messages transferred in encryption. However, we found that despite the efforts, federated learning remains privacy-threatening, due to its interactive nature across different parties. In this paper, we analyze the privacy threats in industrial-level federated learning frameworks with secure computation, and reveal such threats widely exist in typical machine learning models such as linear regression, logistic regression and decision tree. For the linear and logistic regression, we show through theoretical analysis that it is possible for the attacker to invert the entire private input of the victim, given very few information. For the decision tree model, we launch an attack to infer the range of victim's private inputs. All attacks are evaluated on popular federated learning frameworks and real-world datasets.
Exploring Self-Identified Counseling Expertise in Online Support Forums
Jun 24, 2021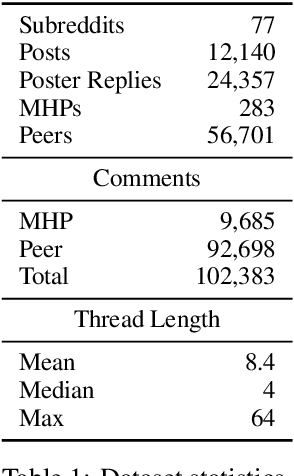
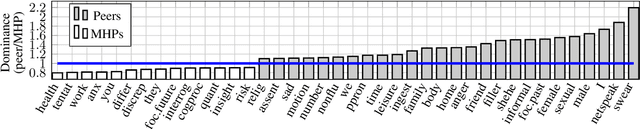

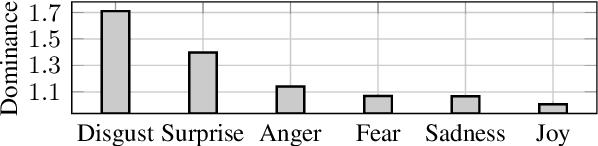
A growing number of people engage in online health forums, making it important to understand the quality of the advice they receive. In this paper, we explore the role of expertise in responses provided to help-seeking posts regarding mental health. We study the differences between (1) interactions with peers; and (2) interactions with self-identified mental health professionals. First, we show that a classifier can distinguish between these two groups, indicating that their language use does in fact differ. To understand this difference, we perform several analyses addressing engagement aspects, including whether their comments engage the support-seeker further as well as linguistic aspects, such as dominant language and linguistic style matching. Our work contributes toward the developing efforts of understanding how health experts engage with health information- and support-seekers in social networks. More broadly, it is a step toward a deeper understanding of the styles of interactions that cultivate supportive engagement in online communities.
Massive Wireless Energy Transfer with Multiple Power Beacons for very large Internet of Things
Jun 24, 2021
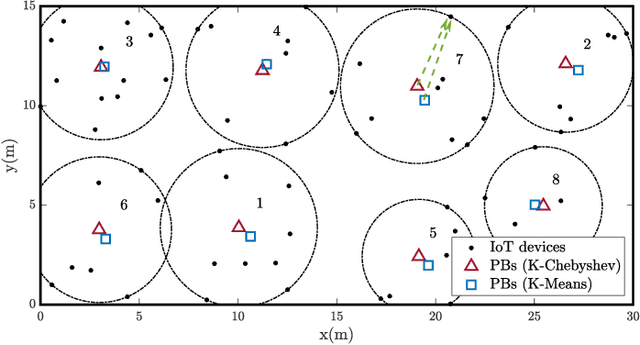
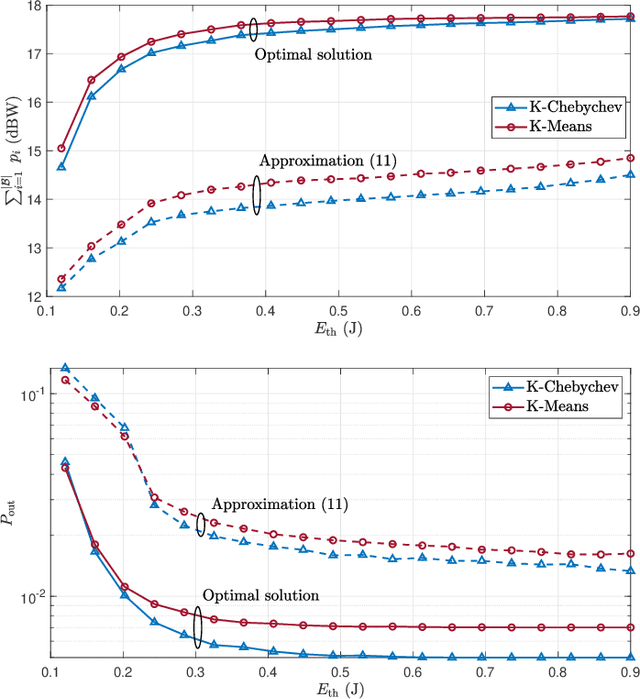
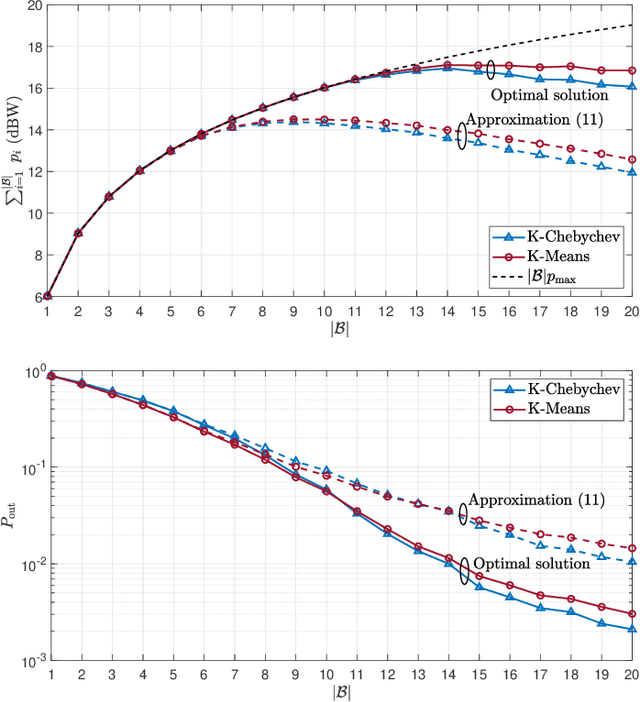
The Internet of Things (IoT) comprises an increasing number of low-power and low-cost devices that autonomously interact with the surrounding environment. As a consequence of their popularity, future IoT deployments will be massive, which demands energy-efficient systems to extend their lifetime and improve the user experience. Radio frequency wireless energy transfer has the potential of powering massive IoT networks, thus eliminating the need for frequent battery replacement by using the so-called power beacons (PBs). In this paper, we provide a framework for minimizing the sum transmit power of the PBs using devices' positions information and their current battery state. Our strategy aims to reduce the PBs' power consumption and to mitigate the possible impact of the electromagnetic radiation on human health. We also present analytical insights for the case of very distant clusters and evaluate their applicability. Numerical results show that our proposed framework reduces the outage probability as the number of PBs and/or the energy demands increase.
Enhancing Network Embedding with Auxiliary Information: An Explicit Matrix Factorization Perspective
Mar 05, 2018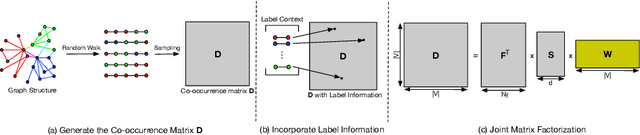
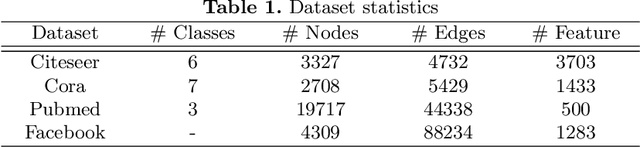
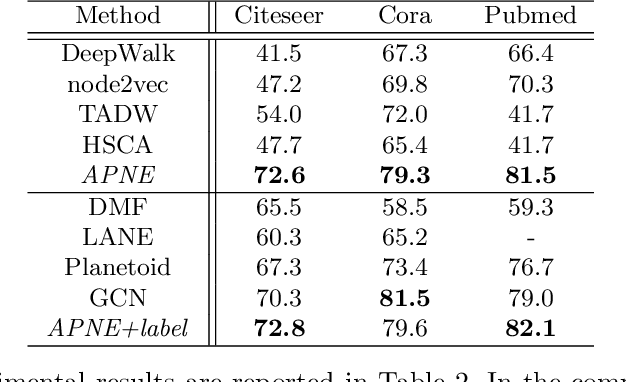
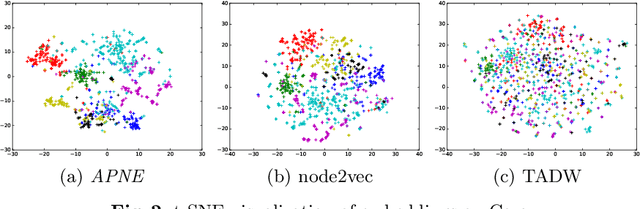
Recent advances in the field of network embedding have shown the low-dimensional network representation is playing a critical role in network analysis. However, most of the existing principles of network embedding do not incorporate auxiliary information such as content and labels of nodes flexibly. In this paper, we take a matrix factorization perspective of network embedding, and incorporate structure, content and label information of the network simultaneously. For structure, we validate that the matrix we construct preserves high-order proximities of the network. Label information can be further integrated into the matrix via the process of random walk sampling to enhance the quality of embedding in an unsupervised manner, i.e., without leveraging downstream classifiers. In addition, we generalize the Skip-Gram Negative Sampling model to integrate the content of the network in a matrix factorization framework. As a consequence, network embedding can be learned in a unified framework integrating network structure and node content as well as label information simultaneously. We demonstrate the efficacy of the proposed model with the tasks of semi-supervised node classification and link prediction on a variety of real-world benchmark network datasets.