 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A High-Performance Adaptive Quantization Approach for Edge CNN Applications
Jul 18, 2021
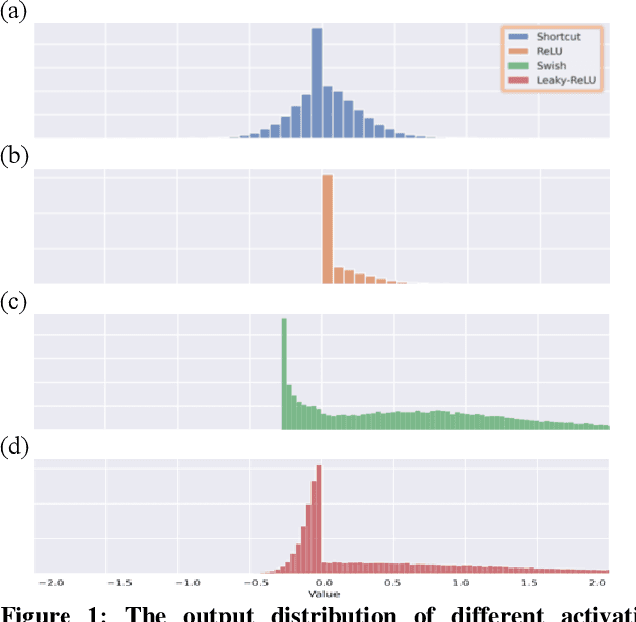
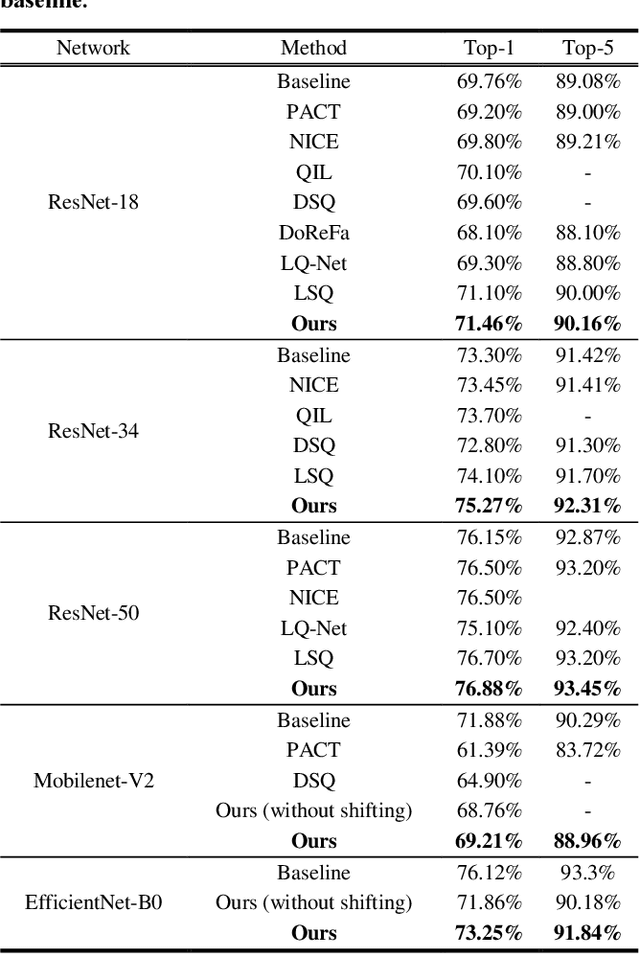
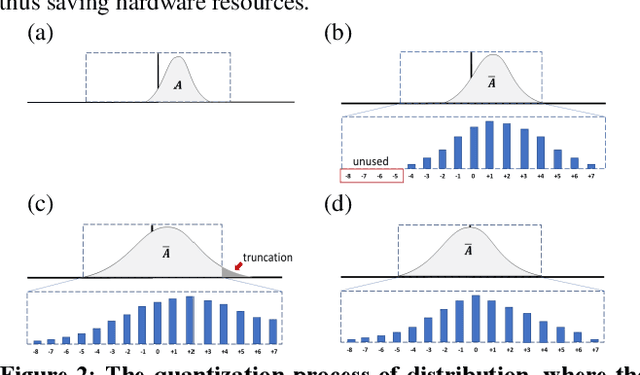

Recent convolutional neural network (CNN) development continues to advance the state-of-the-art model accuracy for various applications. However, the enhanced accuracy comes at the cost of substantial memory bandwidth and storage requirements and demanding computational resources. Although in the past the quantization methods have effectively reduced the deployment cost for edge devices, it suffers from significant information loss when processing the biased activations of contemporary CNNs. In this paper, we hence introduce an adaptive high-performance quantization method to resolve the issue of biased activation by dynamically adjusting the scaling and shifting factors based on the task loss. Our proposed method has been extensively evaluated on image classification models (ResNet-18/34/50, MobileNet-V2, EfficientNet-B0) with ImageNet dataset, object detection model (YOLO-V4) with COCO dataset, and language models with PTB dataset. The results show that our 4-bit integer (INT4) quantization models achieve better accuracy than the state-of-the-art 4-bit models, and in some cases, even surpass the golden full-precision models. The final designs have been successfully deployed onto extremely resource-constrained edge devices for many practical applications.
Accelerated MRI Reconstruction with Separable and Enhanced Low-Rank Hankel Regularization
Jul 24, 2021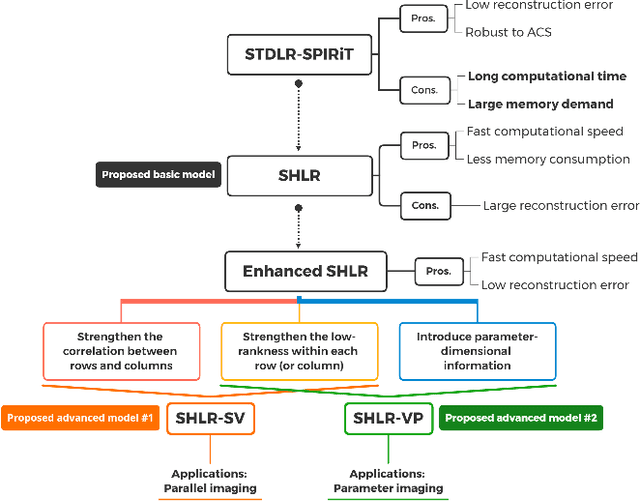
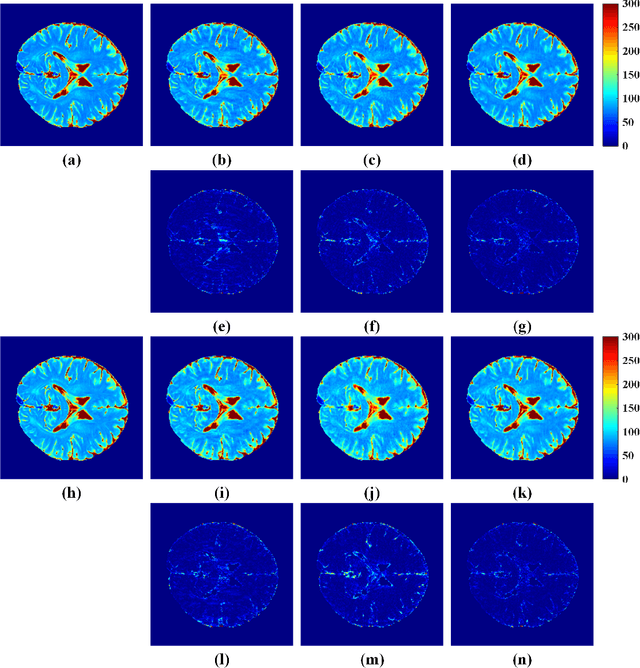
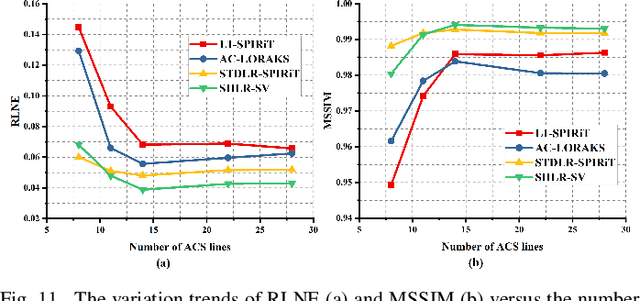
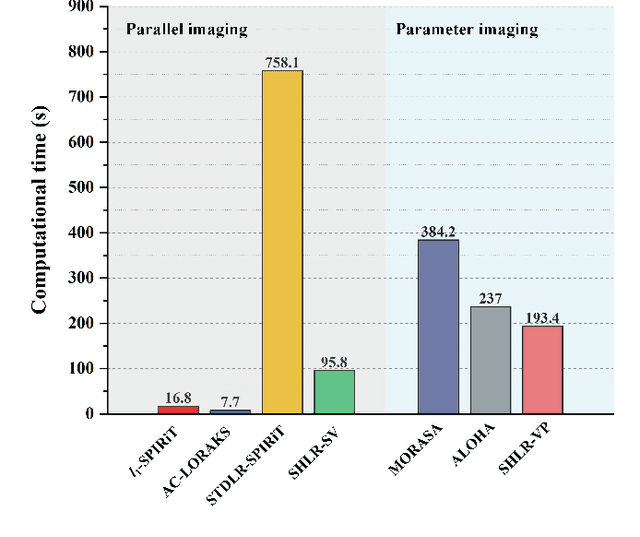
The combination of the sparse sampling and the low-rank structured matrix reconstruction has shown promising performance, enabling a significant reduction of the magnetic resonance imaging data acquisition time. However, the low-rank structured approaches demand considerable memory consumption and are time-consuming due to a noticeable number of matrix operations performed on the huge-size block Hankel-like matrix. In this work, we proposed a novel framework to utilize the low-rank property but meanwhile to achieve faster reconstructions and promising results. The framework allows us to enforce the low-rankness of Hankel matrices constructing from 1D vectors instead of 2D matrices from 1D vectors and thus avoid the construction of huge block Hankel matrix for 2D k-space matrices. Moreover, under this framework, we can easily incorporate other information, such as the smooth phase of the image and the low-rankness in the parameter dimension, to further improve the image quality. We built and validated two models for parallel and parameter magnetic resonance imaging experiments, respectively. Our retrospective in-vivo results indicate that the proposed approaches enable faster reconstructions than the state-of-the-art approaches, e.g., about 8x faster than STDLRSPIRiT, and faithful removal of undersampling artifacts.
Learning Regional Attention over Multi-resolution Deep Convolutional Features for Trademark Retrieval
Apr 15, 2021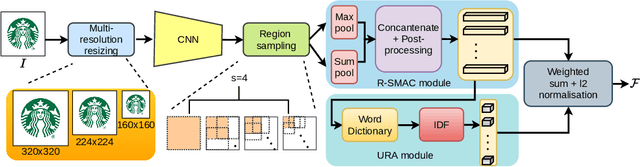
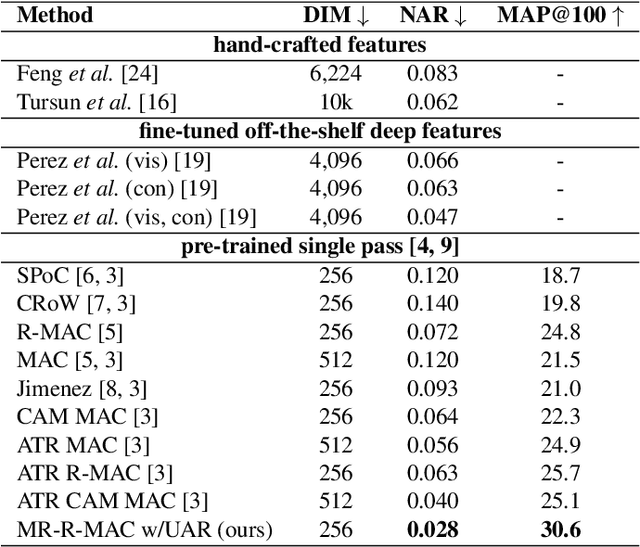

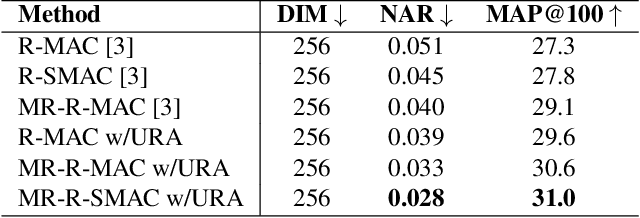
Large-scale trademark retrieval is an important content-based image retrieval task. A recent study shows that off-the-shelf deep features aggregated with Regional-Maximum Activation of Convolutions (R-MAC) achieve state-of-the-art results. However, R-MAC suffers in the presence of background clutter/trivial regions and scale variance, and discards important spatial information. We introduce three simple but effective modifications to R-MAC to overcome these drawbacks. First, we propose the use of both sum and max pooling to minimise the loss of spatial information. We also employ domain-specific unsupervised soft-attention to eliminate background clutter and unimportant regions. Finally, we add multi-resolution inputs to enhance the scale-invariance of R-MAC. We evaluate these three modifications on the million-scale METU dataset. Our results show that all modifications bring non-trivial improvements, and surpass previous state-of-the-art results.
Is Label Smoothing Truly Incompatible with Knowledge Distillation: An Empirical Study
Apr 01, 2021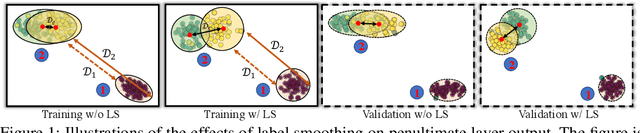
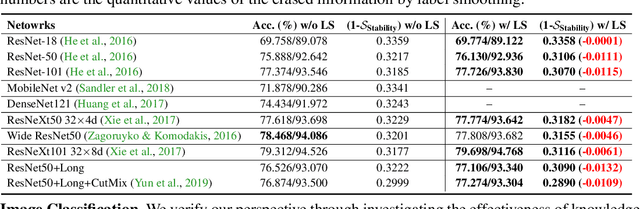
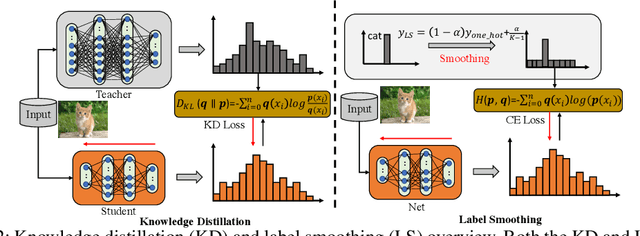
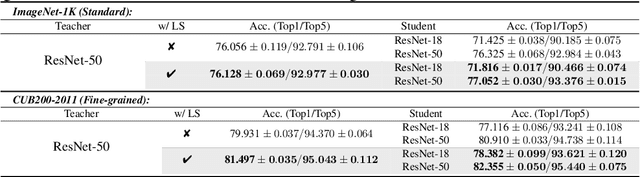
This work aims to empirically clarify a recently discovered perspective that label smoothing is incompatible with knowledge distillation. We begin by introducing the motivation behind on how this incompatibility is raised, i.e., label smoothing erases relative information between teacher logits. We provide a novel connection on how label smoothing affects distributions of semantically similar and dissimilar classes. Then we propose a metric to quantitatively measure the degree of erased information in sample's representation. After that, we study its one-sidedness and imperfection of the incompatibility view through massive analyses, visualizations and comprehensive experiments on Image Classification, Binary Networks, and Neural Machine Translation. Finally, we broadly discuss several circumstances wherein label smoothing will indeed lose its effectiveness. Project page: http://zhiqiangshen.com/projects/LS_and_KD/index.html.
Neurocognitive Informatics Manifesto
Jan 10, 2021Informatics studies all aspects of the structure of natural and artificial information systems. Theoretical and abstract approaches to information have made great advances, but human information processing is still unmatched in many areas, including information management, representation and understanding. Neurocognitive informatics is a new, emerging field that should help to improve the matching of artificial and natural systems, and inspire better computational algorithms to solve problems that are still beyond the reach of machines. In this position paper examples of neurocognitive inspirations and promising directions in this area are given.
Depth Information Guided Crowd Counting for Complex Crowd Scenes
Apr 23, 2018
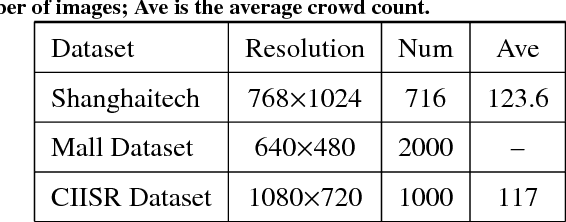
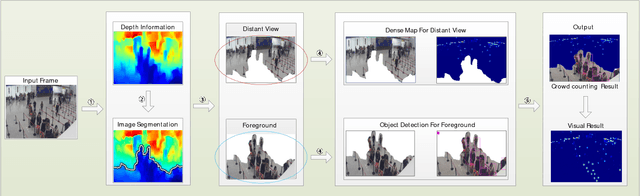
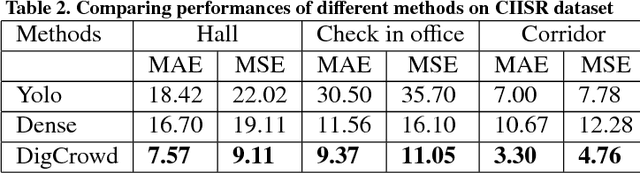
It is important to monitor and analyze crowd events for the sake of city safety. In an EDOF (extended depth of field) image with a crowded scene, the distribution of people is highly imbalanced. People far away from the camera look much smaller and often occlude each other heavily, while people close to the camera look larger. In such a case, it is difficult to accurately estimate the number of people by using one technique. In this paper, we propose a Depth Information Guided Crowd Counting (DigCrowd) method to deal with crowded EDOF scenes. DigCrowd first uses the depth information of an image to segment the scene into a far-view region and a near-view region. Then Digcrowd maps the far-view region to its crowd density map and uses a detection method to count the people in the near-view region. In addition, we introduce a new crowd dataset that contains 1000 images. Experimental results demonstrate the effectiveness of our DigCrowd method
Bias-Robust Bayesian Optimization via Dueling Bandit
May 25, 2021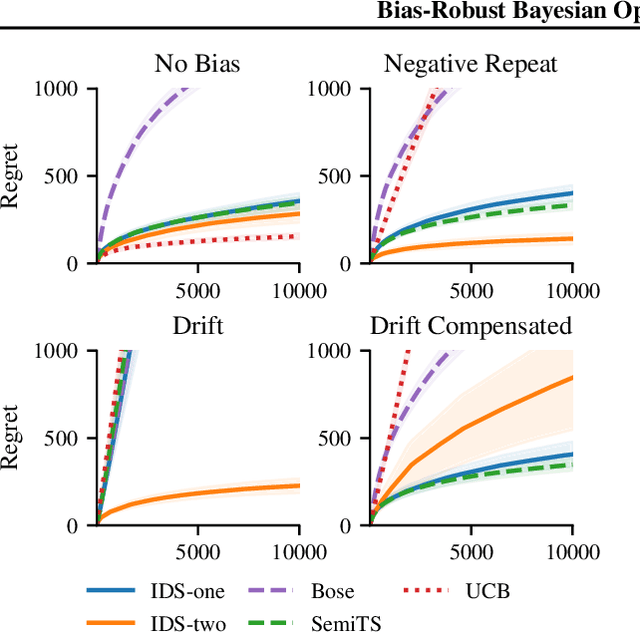
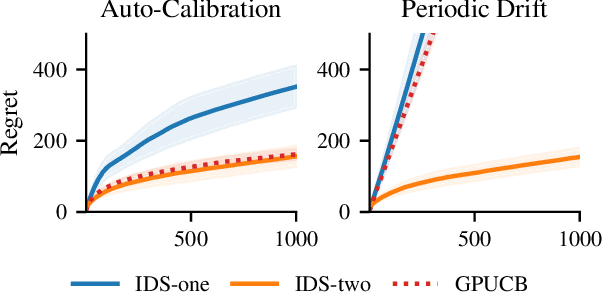
We consider Bayesian optimization in settings where observations can be adversarially biased, for example by an uncontrolled hidden confounder. Our first contribution is a reduction of the confounded setting to the dueling bandit model. Then we propose a novel approach for dueling bandits based on information-directed sampling (IDS). Thereby, we obtain the first efficient kernelized algorithm for dueling bandits that comes with cumulative regret guarantees. Our analysis further generalizes a previously proposed semi-parametric linear bandit model to non-linear reward functions, and uncovers interesting links to doubly-robust estimation.
Privacy-Preserving Machine Learning: Methods, Challenges and Directions
Aug 10, 2021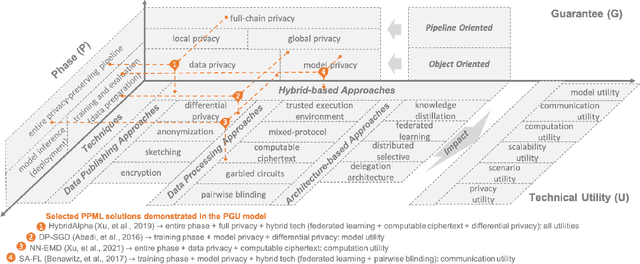
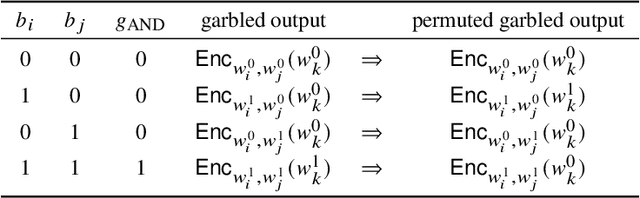
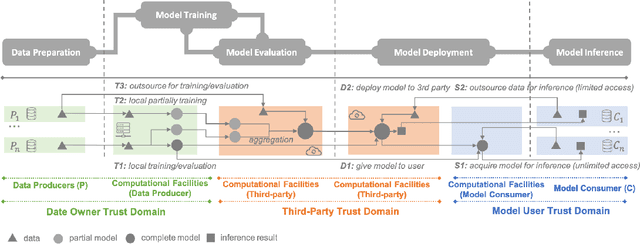

Machine learning (ML) is increasingly being adopted in a wide variety of application domains. Usually, a well-performing ML model, especially, emerging deep neural network model, relies on a large volume of training data and high-powered computational resources. The need for a vast volume of available data raises serious privacy concerns because of the risk of leakage of highly privacy-sensitive information and the evolving regulatory environments that increasingly restrict access to and use of privacy-sensitive data. Furthermore, a trained ML model may also be vulnerable to adversarial attacks such as membership/property inference attacks and model inversion attacks. Hence, well-designed privacy-preserving ML (PPML) solutions are crucial and have attracted increasing research interest from academia and industry. More and more efforts of PPML are proposed via integrating privacy-preserving techniques into ML algorithms, fusing privacy-preserving approaches into ML pipeline, or designing various privacy-preserving architectures for existing ML systems. In particular, existing PPML arts cross-cut ML, system, security, and privacy; hence, there is a critical need to understand state-of-art studies, related challenges, and a roadmap for future research. This paper systematically reviews and summarizes existing privacy-preserving approaches and proposes a PGU model to guide evaluation for various PPML solutions through elaborately decomposing their privacy-preserving functionalities. The PGU model is designed as the triad of Phase, Guarantee, and technical Utility. Furthermore, we also discuss the unique characteristics and challenges of PPML and outline possible directions of future work that benefit a wide range of research communities among ML, distributed systems, security, and privacy areas.
Neuromorphic Algorithm-hardware Codesign for Temporal Pattern Learning
Apr 21, 2021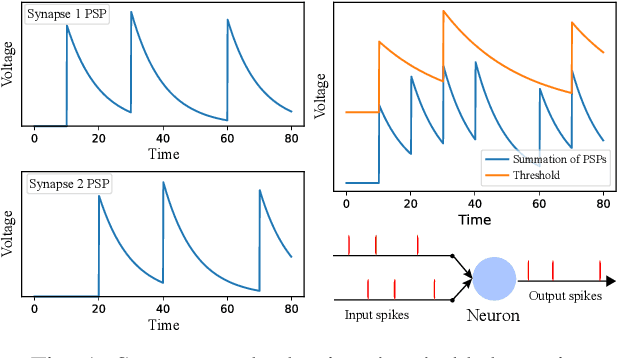
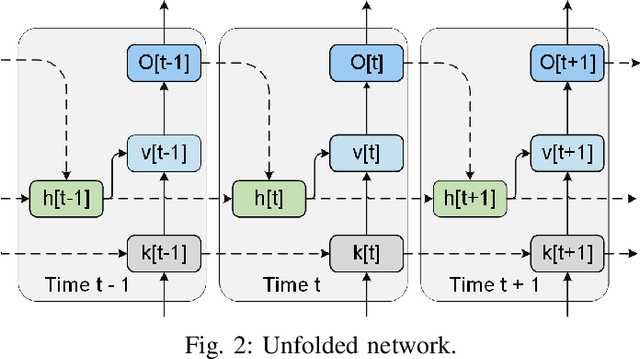
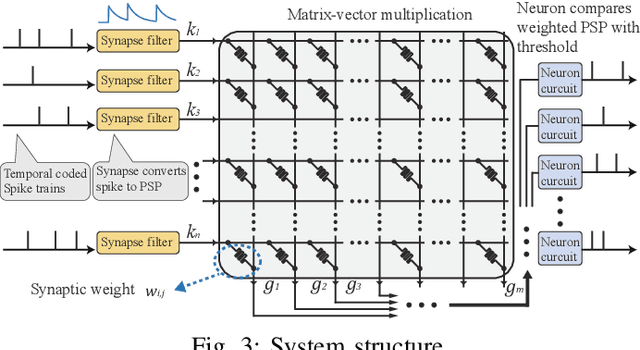
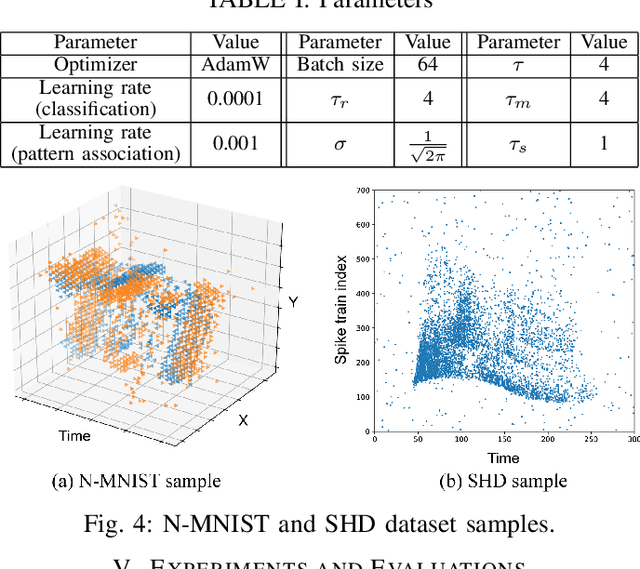
Neuromorphic computing and spiking neural networks (SNN) mimic the behavior of biological systems and have drawn interest for their potential to perform cognitive tasks with high energy efficiency. However, some factors such as temporal dynamics and spike timings prove critical for information processing but are often ignored by existing works, limiting the performance and applications of neuromorphic computing. On one hand, due to the lack of effective SNN training algorithms, it is difficult to utilize the temporal neural dynamics. Many existing algorithms still treat neuron activation statistically. On the other hand, utilizing temporal neural dynamics also poses challenges to hardware design. Synapses exhibit temporal dynamics, serving as memory units that hold historical information, but are often simplified as a connection with weight. Most current models integrate synaptic activations in some storage medium to represent membrane potential and institute a hard reset of membrane potential after the neuron emits a spike. This is done for its simplicity in hardware, requiring only a "clear" signal to wipe the storage medium, but destroys temporal information stored in the neuron. In this work, we derive an efficient training algorithm for Leaky Integrate and Fire neurons, which is capable of training a SNN to learn complex spatial temporal patterns. We achieved competitive accuracy on two complex datasets. We also demonstrate the advantage of our model by a novel temporal pattern association task. Codesigned with this algorithm, we have developed a CMOS circuit implementation for a memristor-based network of neuron and synapses which retains critical neural dynamics with reduced complexity. This circuit implementation of the neuron model is simulated to demonstrate its ability to react to temporal spiking patterns with an adaptive threshold.
Locate Who You Are: Matching Geo-location to Text for Anchor Link Prediction
Apr 19, 2021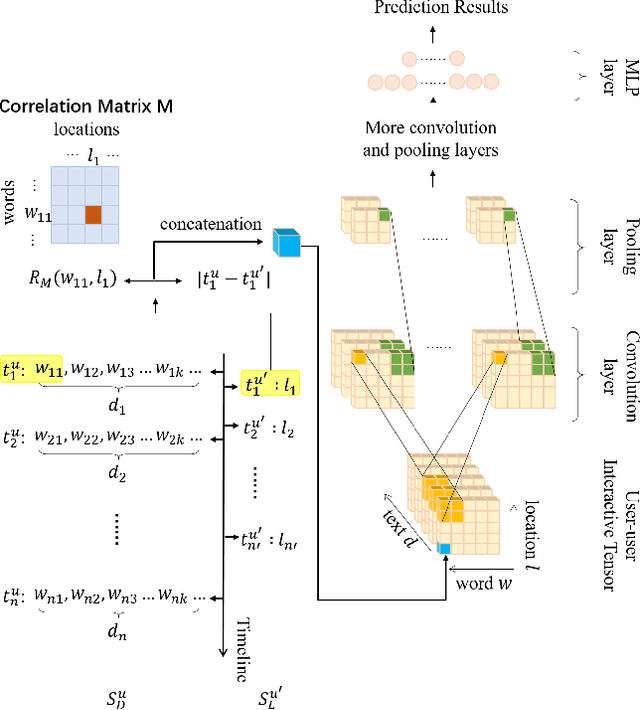
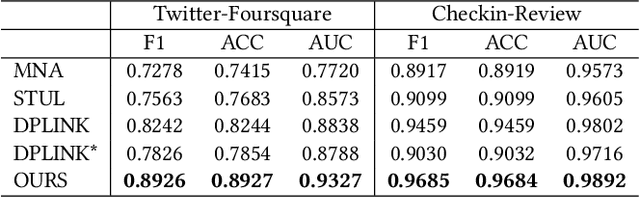
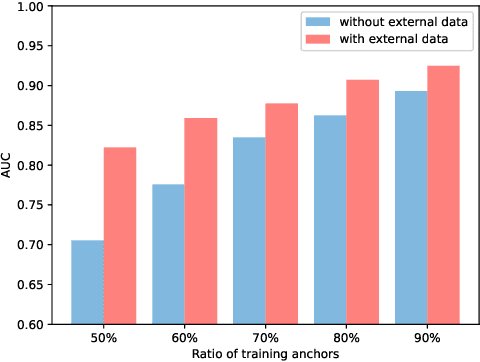
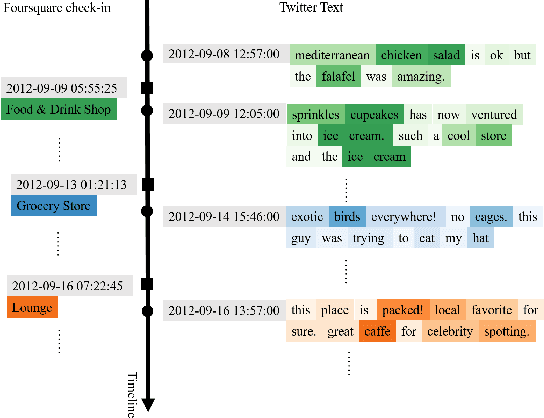
Nowadays, users are encouraged to activate across multiple online social networks simultaneously. Anchor link prediction, which aims to reveal the correspondence among different accounts of the same user across networks, has been regarded as a fundamental problem for user profiling, marketing, cybersecurity, and recommendation. Existing methods mainly address the prediction problem by utilizing profile, content, or structural features of users in symmetric ways. However, encouraged by online services, users would also post asymmetric information across networks, such as geo-locations and texts. It leads to an emerged challenge in aligning users with asymmetric information across networks. Instead of similarity evaluation applied in previous works, we formalize correlation between geo-locations and texts and propose a novel anchor link prediction framework for matching users across networks. Moreover, our model can alleviate the label scarcity problem by introducing external data. Experimental results on real-world datasets show that our approach outperforms existing methods and achieves state-of-the-art results.