 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A nonlinear hidden layer enables actor-critic agents to learn multiple paired association navigation
Jun 25, 2021
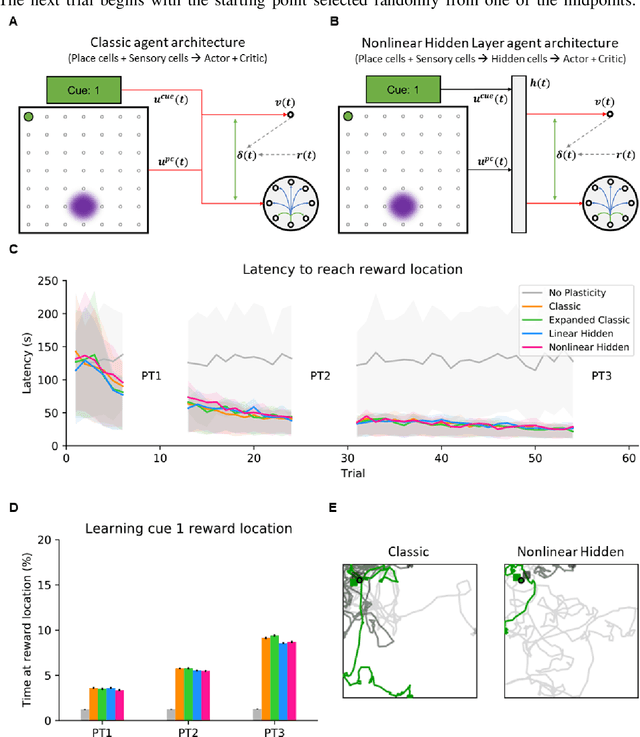
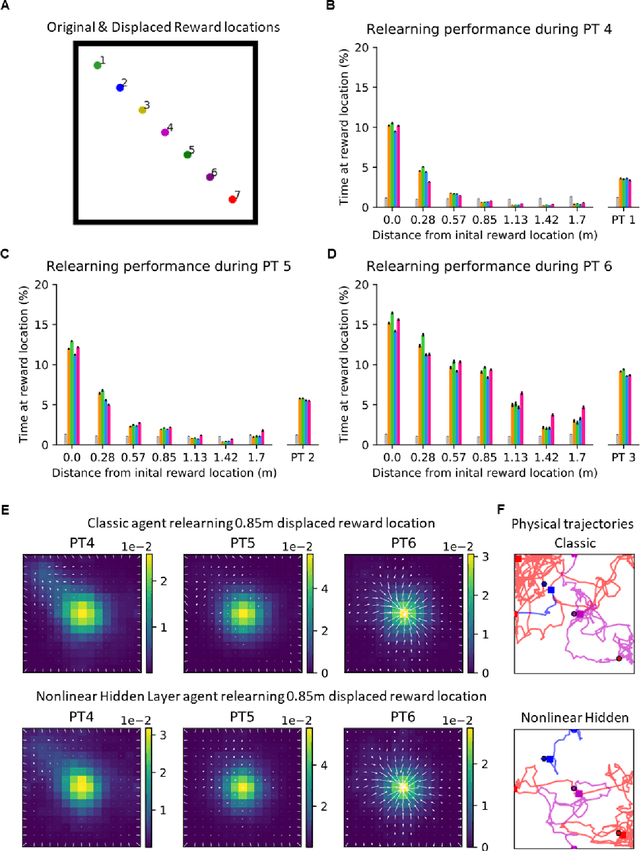
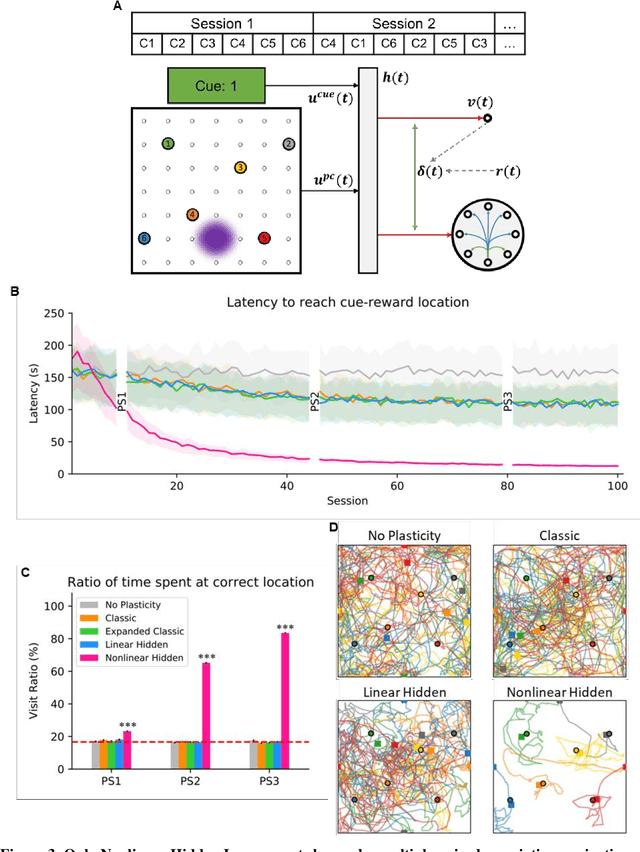

Navigation to multiple cued reward locations has been increasingly used to study rodent learning. Though deep reinforcement learning agents have been shown to be able to learn the task, they are not biologically plausible. Biologically plausible classic actor-critic agents have been shown to learn to navigate to single reward locations, but which biologically plausible agents are able to learn multiple cue-reward location tasks has remained unclear. In this computational study, we show versions of classic agents that learn to navigate to a single reward location, and adapt to reward location displacement, but are not able to learn multiple paired association navigation. The limitation is overcome by an agent in which place cell and cue information are first processed by a feedforward nonlinear hidden layer with synapses to the actor and critic subject to temporal difference error-modulated plasticity. Faster learning is obtained when the feedforward layer is replaced by a recurrent reservoir network.
Learning Hierarchical Graph Neural Networks for Image Clustering
Jul 03, 2021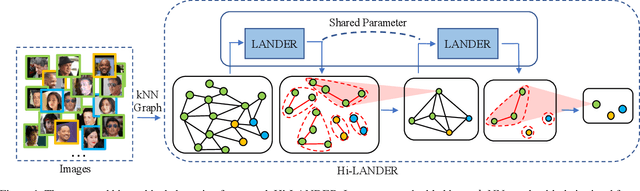
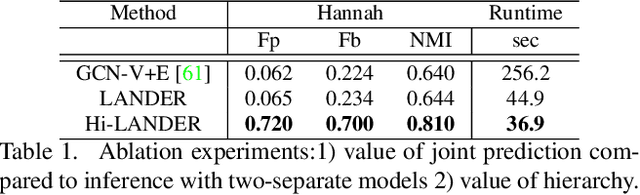
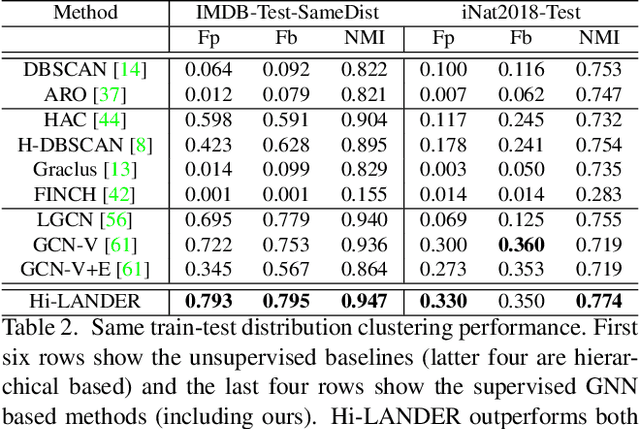
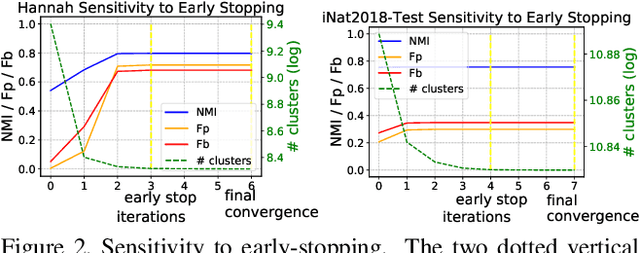
We propose a hierarchical graph neural network (GNN) model that learns how to cluster a set of images into an unknown number of identities using a training set of images annotated with labels belonging to a disjoint set of identities. Our hierarchical GNN uses a novel approach to merge connected components predicted at each level of the hierarchy to form a new graph at the next level. Unlike fully unsupervised hierarchical clustering, the choice of grouping and complexity criteria stems naturally from supervision in the training set. The resulting method, Hi-LANDER, achieves an average of 54% improvement in F-score and 8% increase in Normalized Mutual Information (NMI) relative to current GNN-based clustering algorithms. Additionally, state-of-the-art GNN-based methods rely on separate models to predict linkage probabilities and node densities as intermediate steps of the clustering process. In contrast, our unified framework achieves a seven-fold decrease in computational cost. We release our training and inference code at https://github.com/dmlc/dgl/tree/master/examples/pytorch/hilander.
Post-Radiotherapy PET Image Outcome Prediction by Deep Learning under Biological Model Guidance: A Feasibility Study of Oropharyngeal Cancer Application
May 22, 2021
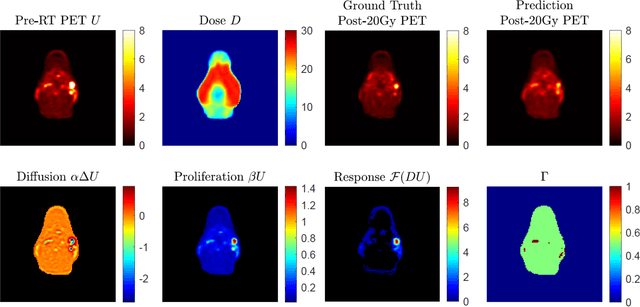
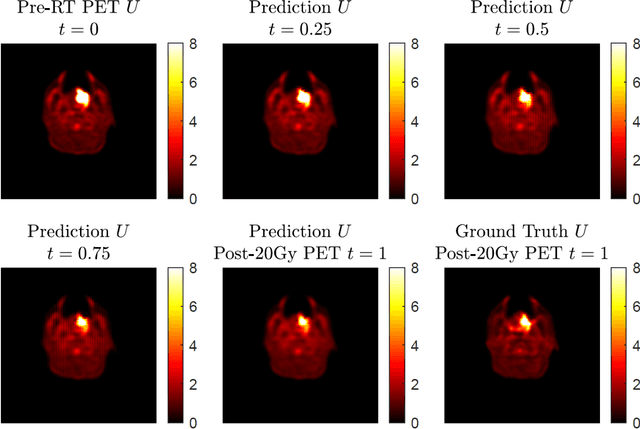
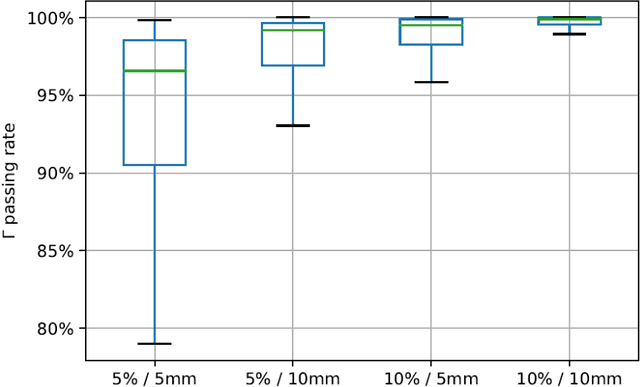
This paper develops a method of biologically guided deep learning for post-radiation FDG-PET image outcome prediction based on pre-radiation images and radiotherapy dose information. Based on the classic reaction-diffusion mechanism, a novel biological model was proposed using a partial differential equation that incorporates spatial radiation dose distribution as a patient-specific treatment information variable. A 7-layer encoder-decoder-based convolutional neural network (CNN) was designed and trained to learn the proposed biological model. As such, the model could generate post-radiation FDG-PET image outcome predictions with possible time-series transition from pre-radiotherapy image states to post-radiotherapy states. The proposed method was developed using 64 oropharyngeal patients with paired FDG-PET studies before and after 20Gy delivery (2Gy/daily fraction) by IMRT. In a two-branch deep learning execution, the proposed CNN learns specific terms in the biological model from paired FDG-PET images and spatial dose distribution as in one branch, and the biological model generates post-20Gy FDG-PET image prediction in the other branch. The proposed method successfully generated post-20Gy FDG-PET image outcome prediction with breakdown illustrations of biological model components. Time-series FDG-PET image predictions were generated to demonstrate the feasibility of disease response rendering. The developed biologically guided deep learning method achieved post-20Gy FDG-PET image outcome predictions in good agreement with ground-truth results. With break-down biological modeling components, the outcome image predictions could be used in adaptive radiotherapy decision-making to optimize personalized plans for the best outcome in the future.
Graph Attention Networks with LSTM-based Path Reweighting
Jun 21, 2021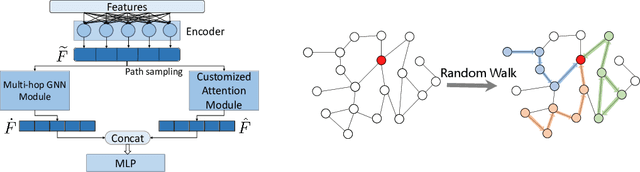


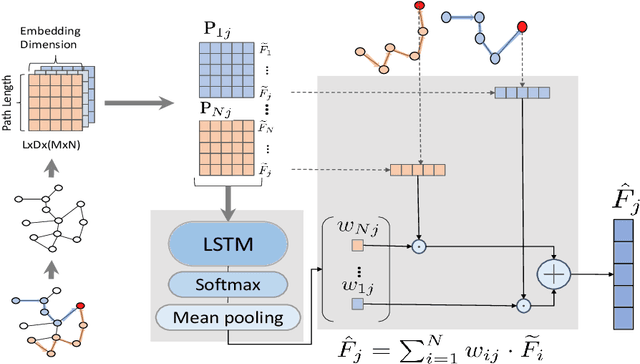
Graph Neural Networks (GNNs) have been extensively used for mining graph-structured data with impressive performance. However, traditional GNNs suffer from over-smoothing, non-robustness and over-fitting problems. To solve these weaknesses, we design a novel GNN solution, namely Graph Attention Network with LSTM-based Path Reweighting (PR-GAT). PR-GAT can automatically aggregate multi-hop information, highlight important paths and filter out noises. In addition, we utilize random path sampling in PR-GAT for data augmentation. The augmented data is used for predicting the distribution of corresponding labels. Finally, we demonstrate that PR-GAT can mitigate the issues of over-smoothing, non-robustness and overfitting. We achieve state-of-the-art accuracy on 5 out of 7 datasets and competitive accuracy for other 2 datasets. The average accuracy of 7 datasets have been improved by 0.5\% than the best SOTA from literature.
Quantification of observed prior and likelihood information in parametric Bayesian modeling
Sep 07, 2017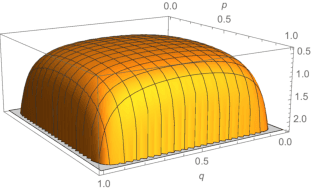
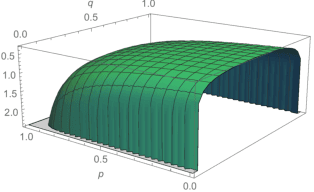
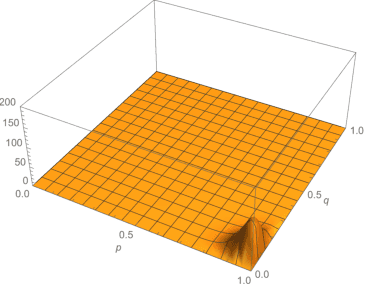
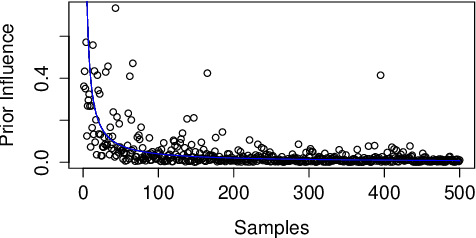
Two data-dependent information metrics are developed to quantify the information of the prior and likelihood functions within a parametric Bayesian model, one of which is closely related to the reference priors from Berger, Bernardo, and Sun, and information measure introduced by Lindley. A combination of theoretical, empirical, and computational support provides evidence that these information-theoretic metrics may be useful diagnostic tools when performing a Bayesian analysis.
Lifelong Teacher-Student Network Learning
Jul 09, 2021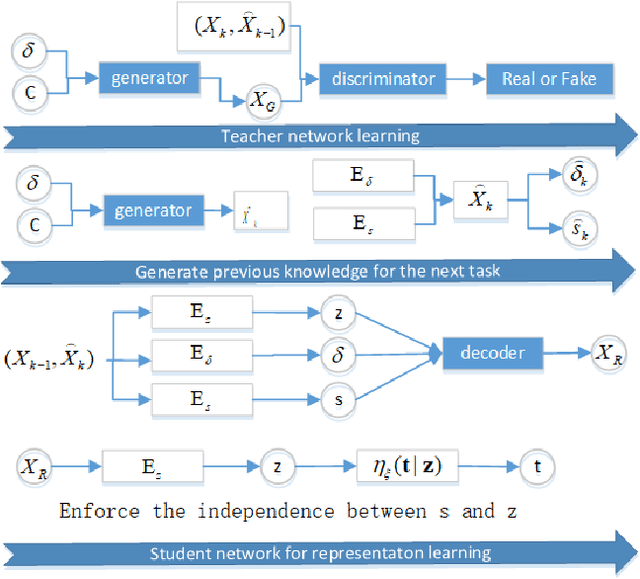

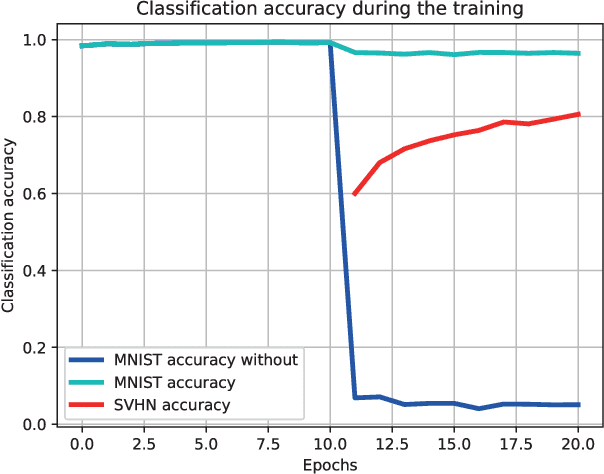
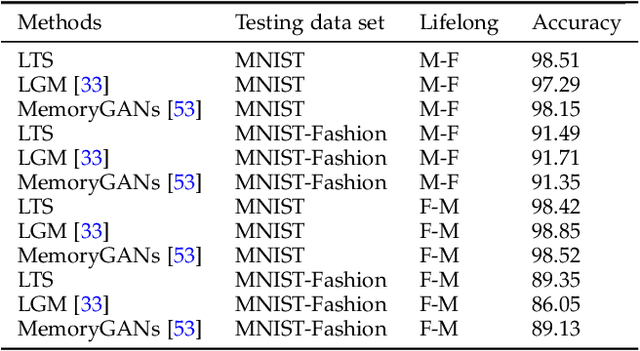
A unique cognitive capability of humans consists in their ability to acquire new knowledge and skills from a sequence of experiences. Meanwhile, artificial intelligence systems are good at learning only the last given task without being able to remember the databases learnt in the past. We propose a novel lifelong learning methodology by employing a Teacher-Student network framework. While the Student module is trained with a new given database, the Teacher module would remind the Student about the information learnt in the past. The Teacher, implemented by a Generative Adversarial Network (GAN), is trained to preserve and replay past knowledge corresponding to the probabilistic representations of previously learn databases. Meanwhile, the Student module is implemented by a Variational Autoencoder (VAE) which infers its latent variable representation from both the output of the Teacher module as well as from the newly available database. Moreover, the Student module is trained to capture both continuous and discrete underlying data representations across different domains. The proposed lifelong learning framework is applied in supervised, semi-supervised and unsupervised training. The code is available~: \url{https://github.com/dtuzi123/Lifelong-Teacher-Student-Network-Learning}
Gradient Augmented Information Retrieval with Autoencoders and Semantic Hashing
Mar 12, 2018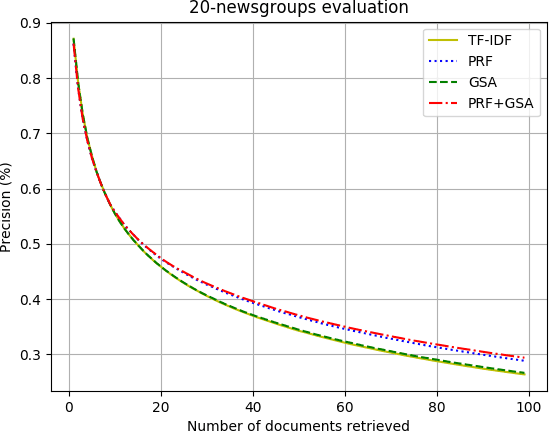
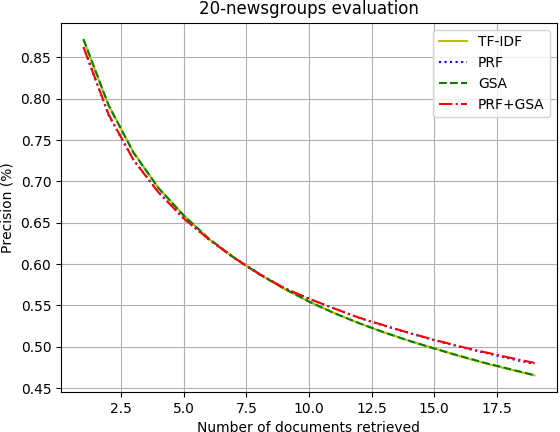
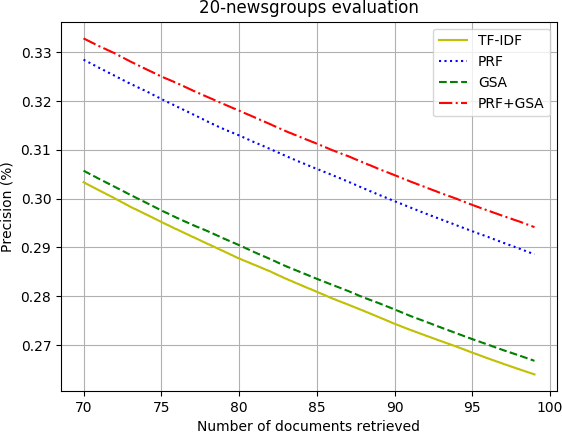
This paper will explore the use of autoencoders for semantic hashing in the context of Information Retrieval. This paper will summarize how to efficiently train an autoencoder in order to create meaningful and low-dimensional encodings of data. This paper will demonstrate how computing and storing the closest encodings to an input query can help speed up search time and improve the quality of our search results. The novel contributions of this paper involve using the representation of the data learned by an auto-encoder in order to augment our search query in various ways. I present and evaluate the new gradient search augmentation (GSA) approach, as well as the more well-known pseudo-relevance-feedback (PRF) adjustment. I find that GSA helps to improve the performance of the TF-IDF based information retrieval system, and PRF combined with GSA works best overall for the systems compared in this paper.
Detecting Bot-Generated Text by Characterizing Linguistic Accommodation in Human-Bot Interactions
Jun 02, 2021
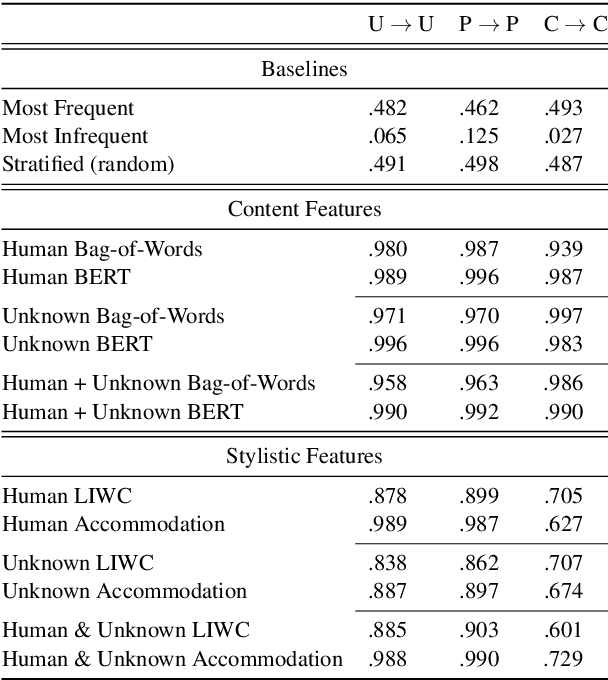
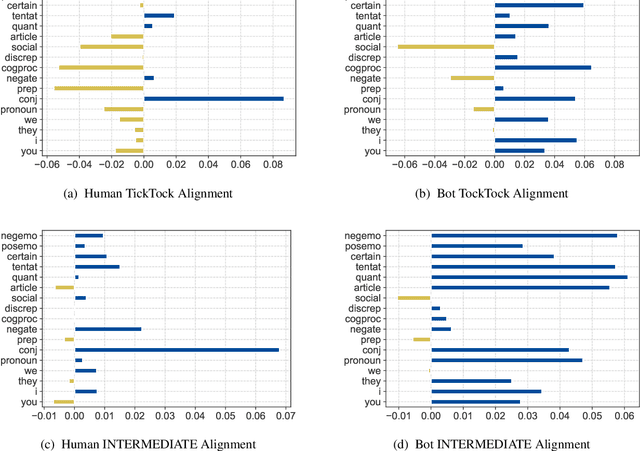
Language generation models' democratization benefits many domains, from answering health-related questions to enhancing education by providing AI-driven tutoring services. However, language generation models' democratization also makes it easier to generate human-like text at-scale for nefarious activities, from spreading misinformation to targeting specific groups with hate speech. Thus, it is essential to understand how people interact with bots and develop methods to detect bot-generated text. This paper shows that bot-generated text detection methods are more robust across datasets and models if we use information about how people respond to it rather than using the bot's text directly. We also analyze linguistic alignment, providing insight into differences between human-human and human-bot conversations.
End-to-End NLP Knowledge Graph Construction
Jun 02, 2021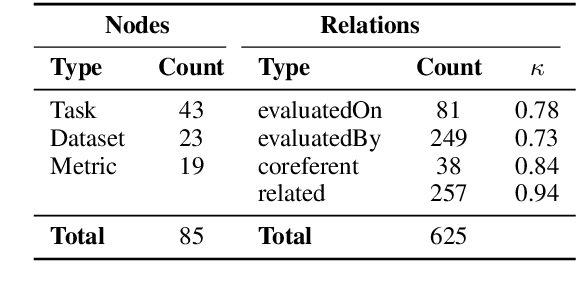
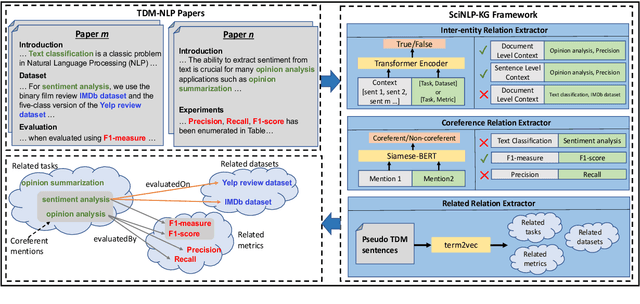
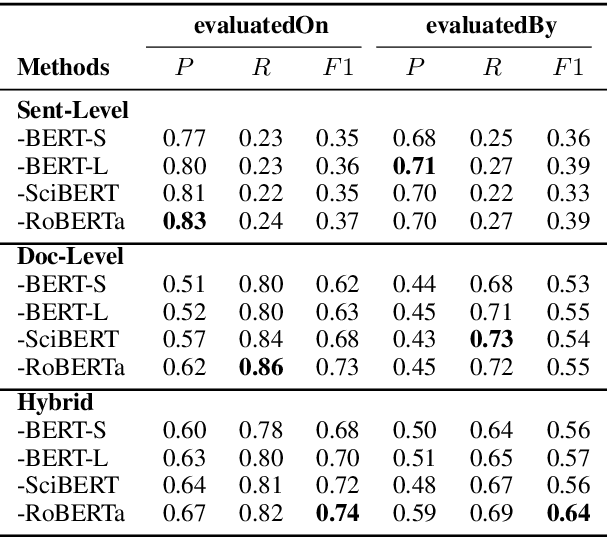
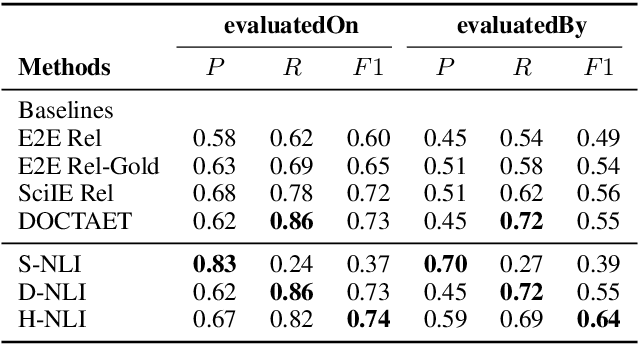
This paper studies the end-to-end construction of an NLP Knowledge Graph (KG) from scientific papers. We focus on extracting four types of relations: evaluatedOn between tasks and datasets, evaluatedBy between tasks and evaluation metrics, as well as coreferent and related relations between the same type of entities. For instance, F1-score is coreferent with F-measure. We introduce novel methods for each of these relation types and apply our final framework (SciNLP-KG) to 30,000 NLP papers from ACL Anthology to build a large-scale KG, which can facilitate automatically constructing scientific leaderboards for the NLP community. The results of our experiments indicate that the resulting KG contains high-quality information.
Improving coreference resolution with automatically predicted prosodic information
Jul 28, 2017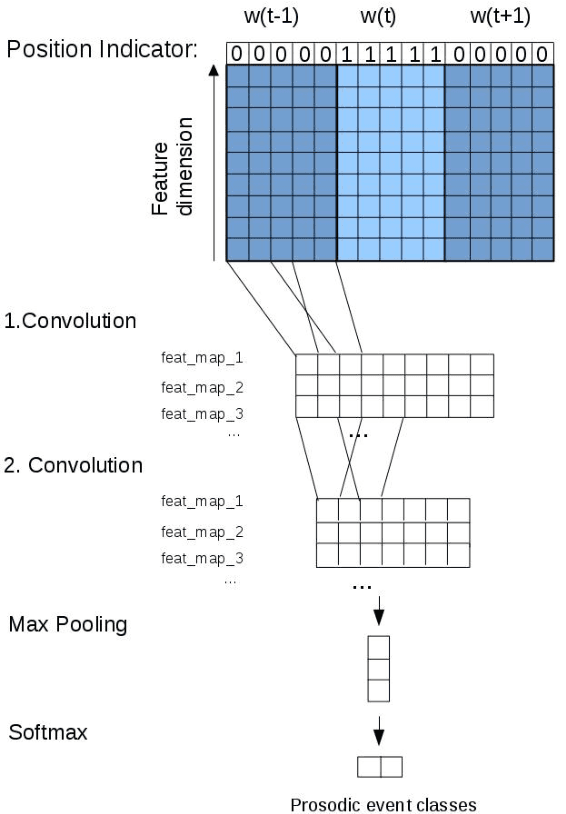
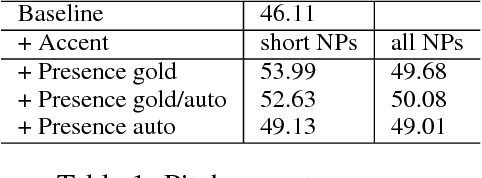
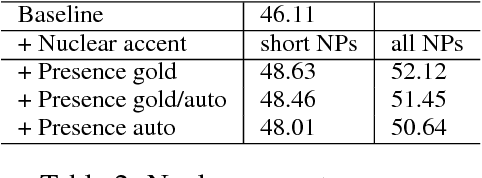
Adding manually annotated prosodic information, specifically pitch accents and phrasing, to the typical text-based feature set for coreference resolution has previously been shown to have a positive effect on German data. Practical applications on spoken language, however, would rely on automatically predicted prosodic information. In this paper we predict pitch accents (and phrase boundaries) using a convolutional neural network (CNN) model from acoustic features extracted from the speech signal. After an assessment of the quality of these automatic prosodic annotations, we show that they also significantly improve coreference resolution.