 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
LeanML: A Design Pattern To Slash Avoidable Wastes in Machine Learning Projects
Jul 16, 2021
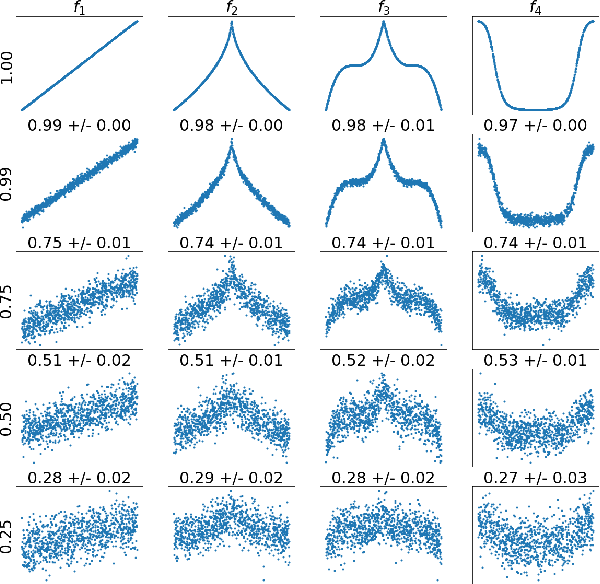
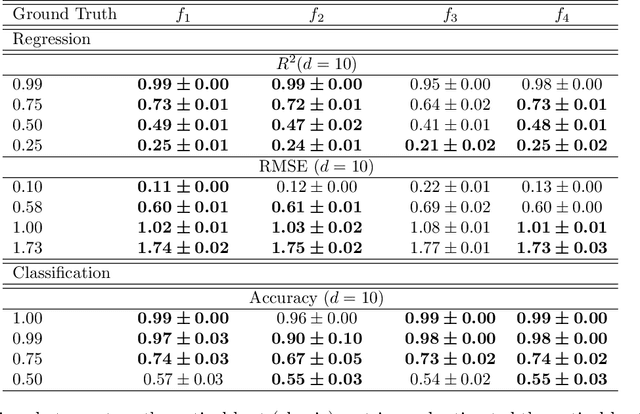
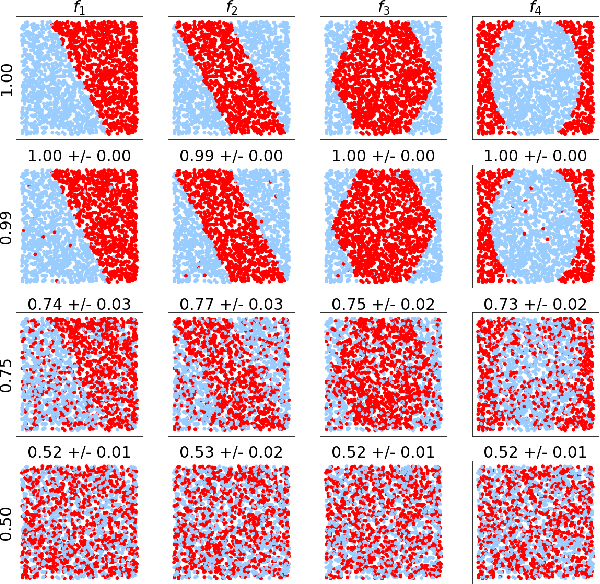

We introduce the first application of the lean methodology to machine learning projects. Similar to lean startups and lean manufacturing, we argue that lean machine learning (LeanML) can drastically slash avoidable wastes in commercial machine learning projects, reduce the business risk in investing in machine learning capabilities and, in so doing, further democratize access to machine learning. The lean design pattern we propose in this paper is based on two realizations. First, it is possible to estimate the best performance one may achieve when predicting an outcome $y \in \mathcal{Y}$ using a given set of explanatory variables $x \in \mathcal{X}$, for a wide range of performance metrics, and without training any predictive model. Second, doing so is considerably easier, faster, and cheaper than learning the best predictive model. We derive formulae expressing the best $R^2$, MSE, classification accuracy, and log-likelihood per observation achievable when using $x$ to predict $y$ as a function of the mutual information $I\left(y; x\right)$, and possibly a measure of the variability of $y$ (e.g. its Shannon entropy in the case of classification accuracy, and its variance in the case regression MSE). We illustrate the efficacy of the LeanML design pattern on a wide range of regression and classification problems, synthetic and real-life.
Image-to-image Transformation with Auxiliary Condition
Jun 25, 2021The performance of image recognition like human pose detection, trained with simulated images would usually get worse due to the divergence between real and simulated data. To make the distribution of a simulated image close to that of real one, there are several works applying GAN-based image-to-image transformation methods, e.g., SimGAN and CycleGAN. However, these methods would not be sensitive enough to the various change in pose and shape of subjects, especially when the training data are imbalanced, e.g., some particular poses and shapes are minor in the training data. To overcome this problem, we propose to introduce the label information of subjects, e.g., pose and type of objects in the training of CycleGAN, and lead it to obtain label-wise transforamtion models. We evaluate our proposed method called Label-CycleGAN, through experiments on the digit image transformation from SVHN to MNIST and the surveillance camera image transformation from simulated to real images.
Jointly Optimizing Query Encoder and Product Quantization to Improve Retrieval Performance
Aug 02, 2021
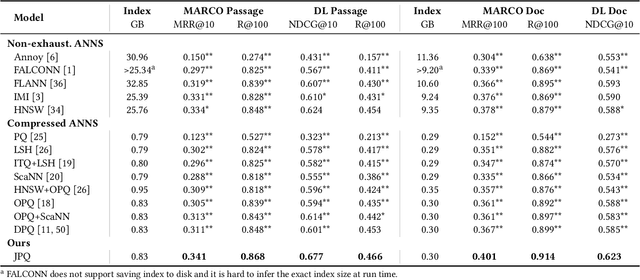
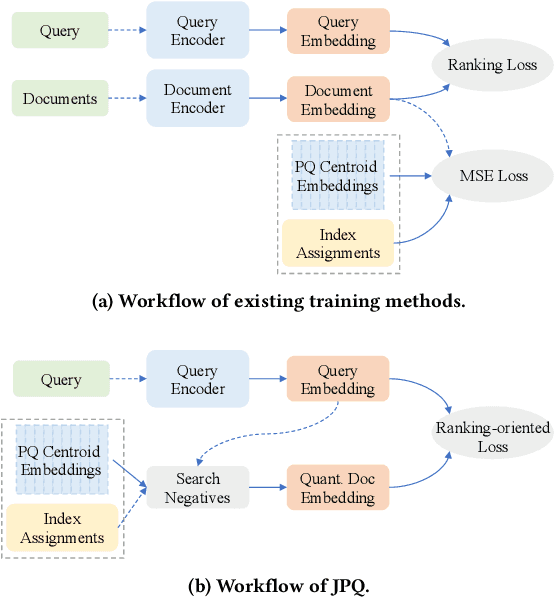
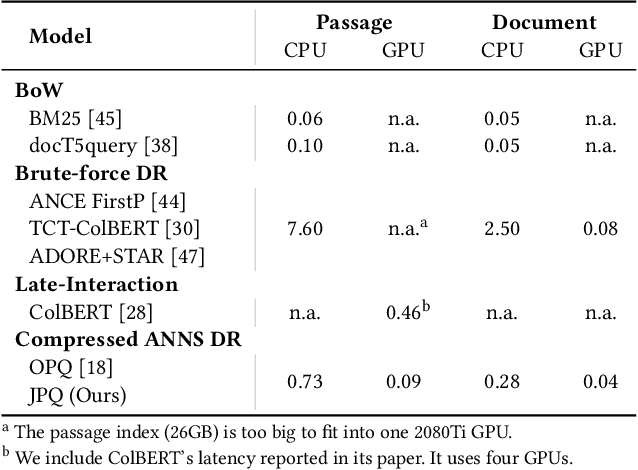
Recently, Information Retrieval community has witnessed fast-paced advances in Dense Retrieval (DR), which performs first-stage retrieval by encoding documents in a low-dimensional embedding space and querying them with embedding-based search. Despite the impressive ranking performance, previous studies usually adopt brute-force search to acquire candidates, which is prohibitive in practical Web search scenarios due to its tremendous memory usage and time cost. To overcome these problems, vector compression methods, a branch of Approximate Nearest Neighbor Search (ANNS), have been adopted in many practical embedding-based retrieval applications. One of the most popular methods is Product Quantization (PQ). However, although existing vector compression methods including PQ can help improve the efficiency of DR, they incur severely decayed retrieval performance due to the separation between encoding and compression. To tackle this problem, we present JPQ, which stands for Joint optimization of query encoding and Product Quantization. It trains the query encoder and PQ index jointly in an end-to-end manner based on three optimization strategies, namely ranking-oriented loss, PQ centroid optimization, and end-to-end negative sampling. We evaluate JPQ on two publicly available retrieval benchmarks. Experimental results show that JPQ significantly outperforms existing popular vector compression methods in terms of different trade-off settings. Compared with previous DR models that use brute-force search, JPQ almost matches the best retrieval performance with 30x compression on index size. The compressed index further brings 10x speedup on CPU and 2x speedup on GPU in query latency.
Simple steps are all you need: Frank-Wolfe and generalized self-concordant functions
May 28, 2021
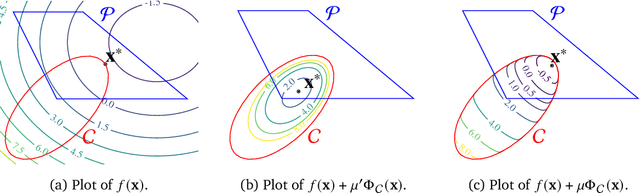


Generalized self-concordance is a key property present in the objective function of many important learning problems. We establish the convergence rate of a simple Frank-Wolfe variant that uses the open-loop step size strategy $\gamma_t = 2/(t+2)$, obtaining a $\mathcal{O}(1/t)$ convergence rate for this class of functions in terms of primal gap and Frank-Wolfe gap, where $t$ is the iteration count. This avoids the use of second-order information or the need to estimate local smoothness parameters of previous work. We also show improved convergence rates for various common cases, e.g., when the feasible region under consideration is uniformly convex or polyhedral.
Blockchain Technology: Bitcoins, Cryptocurrency and Applications
Jul 16, 2021
Blockchain is a decentralized ledger used to securely exchange digital currency, perform deals and transactions efficient manner, each user of the network has access to the least copy of the encrypted ledger so that they can validate a new transaction. The blockchain ledger is a collection of all Bitcoin transactions executed in the past. Basically, it's distributed database that maintains continuously growing tamper-proof data structure blocks that holds batches of individual transactions. The completed blocks are added in a linear and chronological order. Each block contains a timestamp and information link which points to a previous block. Bitcoin is a peer-to-peer permissionless network that allows every user to connect to the network and send new transactions to verify and create new blocks. Satoshi Nakamoto described the design of Bitcoin digital currency in his research paper posted to a cryptography listserv 2008. Nakamoto's suggestion has solved the long-pending problem of cryptography and laid the foundation stone for digital currency. This paper explains the concept of bitcoin, its characteristics, the need for Blockchain, and how Bitcoin works. It attempts to highlight the role of Blockchain in shaping the future of banking , financial services, and the adoption of the Internet of Thinks and future Technologies.
AnonySIGN: Novel Human Appearance Synthesis for Sign Language Video Anonymisation
Jul 22, 2021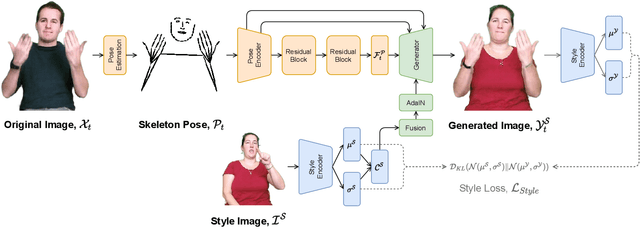
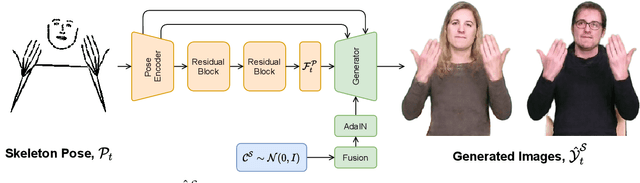


The visual anonymisation of sign language data is an essential task to address privacy concerns raised by large-scale dataset collection. Previous anonymisation techniques have either significantly affected sign comprehension or required manual, labour-intensive work. In this paper, we formally introduce the task of Sign Language Video Anonymisation (SLVA) as an automatic method to anonymise the visual appearance of a sign language video whilst retaining the meaning of the original sign language sequence. To tackle SLVA, we propose AnonySign, a novel automatic approach for visual anonymisation of sign language data. We first extract pose information from the source video to remove the original signer appearance. We next generate a photo-realistic sign language video of a novel appearance from the pose sequence, using image-to-image translation methods in a conditional variational autoencoder framework. An approximate posterior style distribution is learnt, which can be sampled from to synthesise novel human appearances. In addition, we propose a novel \textit{style loss} that ensures style consistency in the anonymised sign language videos. We evaluate AnonySign for the SLVA task with extensive quantitative and qualitative experiments highlighting both realism and anonymity of our novel human appearance synthesis. In addition, we formalise an anonymity perceptual study as an evaluation criteria for the SLVA task and showcase that video anonymisation using AnonySign retains the original sign language content.
Multiple Object Tracking with Mixture Density Networks for Trajectory Estimation
Jun 21, 2021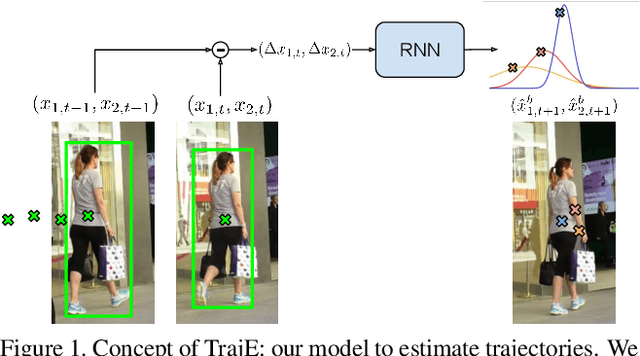
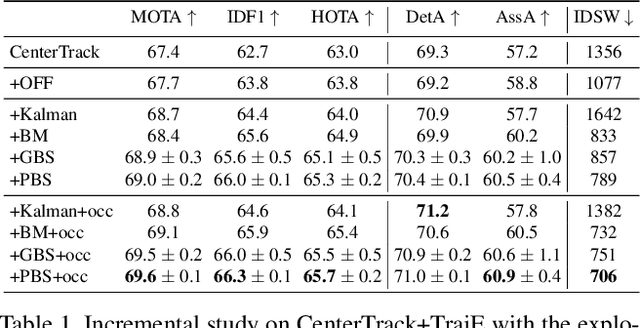

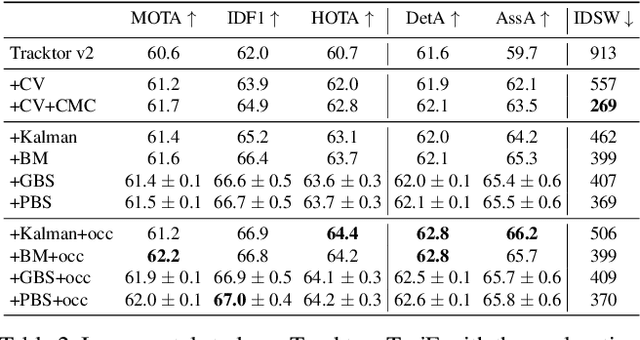
Multiple object tracking faces several challenges that may be alleviated with trajectory information. Knowing the posterior locations of an object helps disambiguating and solving situations such as occlusions, re-identification, and identity switching. In this work, we show that trajectory estimation can become a key factor for tracking, and present TrajE, a trajectory estimator based on recurrent mixture density networks, as a generic module that can be added to existing object trackers. To provide several trajectory hypotheses, our method uses beam search. Also, relying on the same estimated trajectory, we propose to reconstruct a track after an occlusion occurs. We integrate TrajE into two state of the art tracking algorithms, CenterTrack [63] and Tracktor [3]. Their respective performances in the MOTChallenge 2017 test set are boosted 6.3 and 0.3 points in MOTA score, and 1.8 and 3.1 in IDF1, setting a new state of the art for the CenterTrack+TrajE configuration
Multi-Resolution Continuous Normalizing Flows
Jun 17, 2021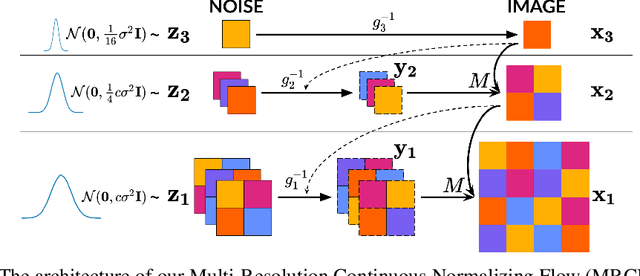
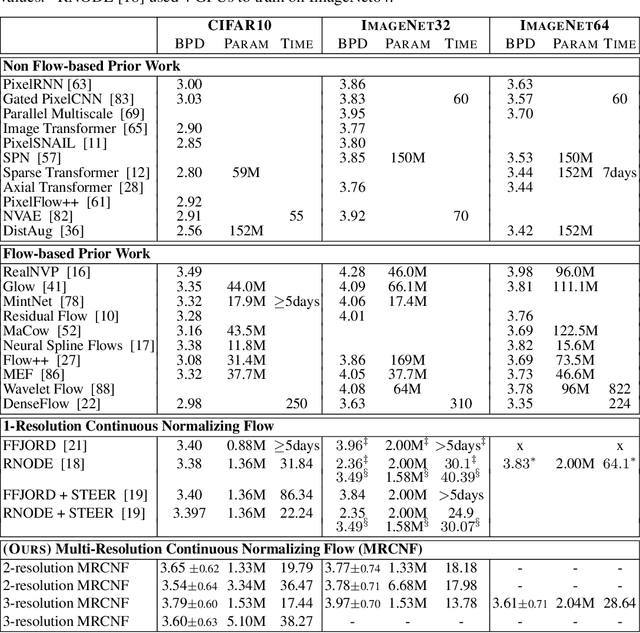
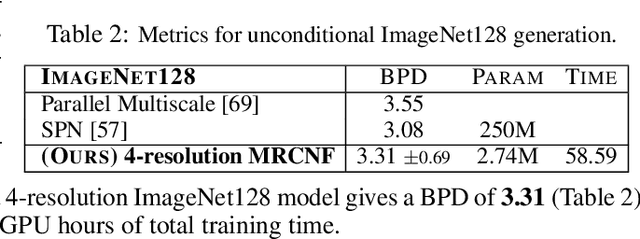

Recent work has shown that Neural Ordinary Differential Equations (ODEs) can serve as generative models of images using the perspective of Continuous Normalizing Flows (CNFs). Such models offer exact likelihood calculation, and invertible generation/density estimation. In this work we introduce a Multi-Resolution variant of such models (MRCNF), by characterizing the conditional distribution over the additional information required to generate a fine image that is consistent with the coarse image. We introduce a transformation between resolutions that allows for no change in the log likelihood. We show that this approach yields comparable likelihood values for various image datasets, with improved performance at higher resolutions, with fewer parameters, using only 1 GPU. Further, we examine the out-of-distribution properties of (Multi-Resolution) Continuous Normalizing Flows, and find that they are similar to those of other likelihood-based generative models.
Post-Radiotherapy PET Image Outcome Prediction by Deep Learning under Biological Model Guidance: A Feasibility Study of Oropharyngeal Cancer Application
May 22, 2021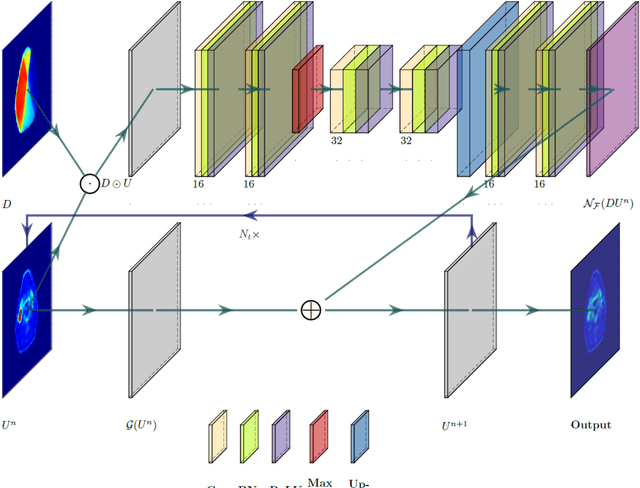
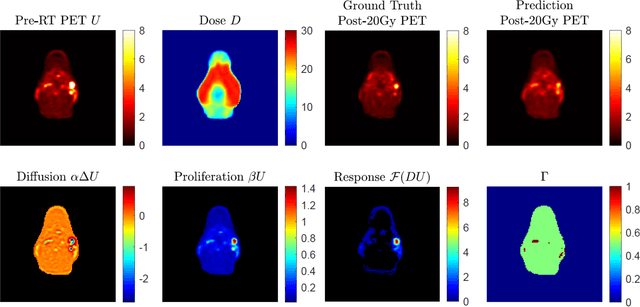
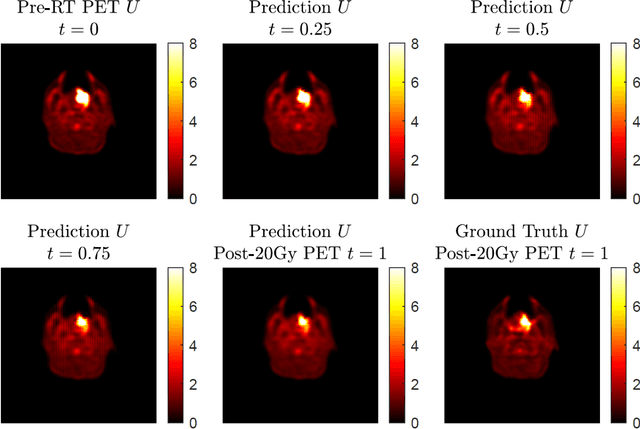
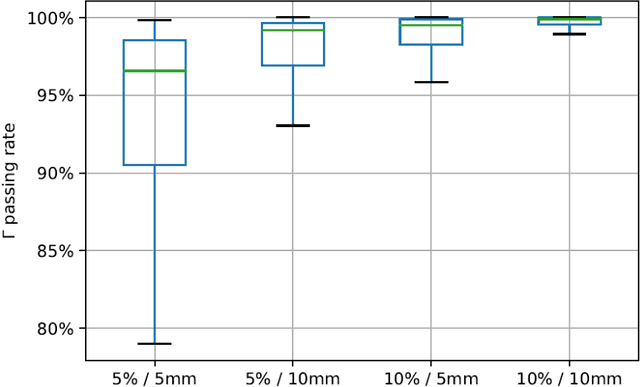
This paper develops a method of biologically guided deep learning for post-radiation FDG-PET image outcome prediction based on pre-radiation images and radiotherapy dose information. Based on the classic reaction-diffusion mechanism, a novel biological model was proposed using a partial differential equation that incorporates spatial radiation dose distribution as a patient-specific treatment information variable. A 7-layer encoder-decoder-based convolutional neural network (CNN) was designed and trained to learn the proposed biological model. As such, the model could generate post-radiation FDG-PET image outcome predictions with possible time-series transition from pre-radiotherapy image states to post-radiotherapy states. The proposed method was developed using 64 oropharyngeal patients with paired FDG-PET studies before and after 20Gy delivery (2Gy/daily fraction) by IMRT. In a two-branch deep learning execution, the proposed CNN learns specific terms in the biological model from paired FDG-PET images and spatial dose distribution as in one branch, and the biological model generates post-20Gy FDG-PET image prediction in the other branch. The proposed method successfully generated post-20Gy FDG-PET image outcome prediction with breakdown illustrations of biological model components. Time-series FDG-PET image predictions were generated to demonstrate the feasibility of disease response rendering. The developed biologically guided deep learning method achieved post-20Gy FDG-PET image outcome predictions in good agreement with ground-truth results. With break-down biological modeling components, the outcome image predictions could be used in adaptive radiotherapy decision-making to optimize personalized plans for the best outcome in the future.
A nonlinear hidden layer enables actor-critic agents to learn multiple paired association navigation
Jun 25, 2021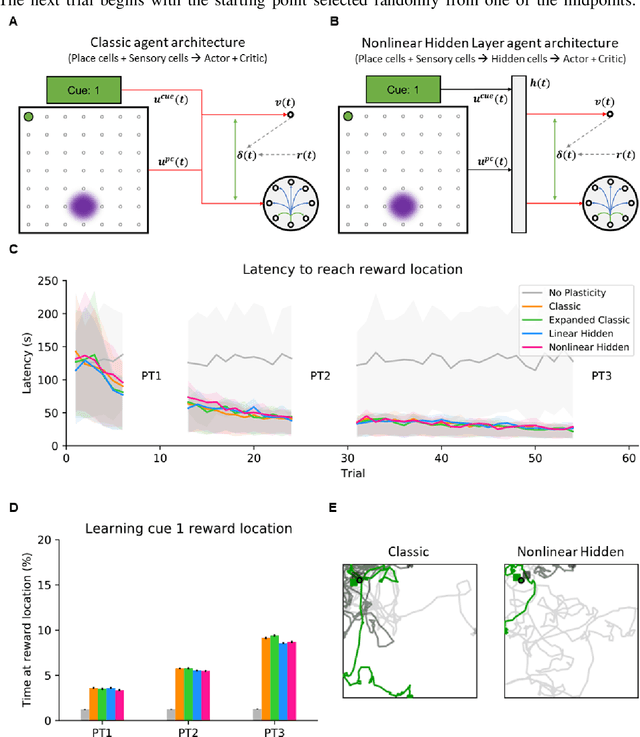
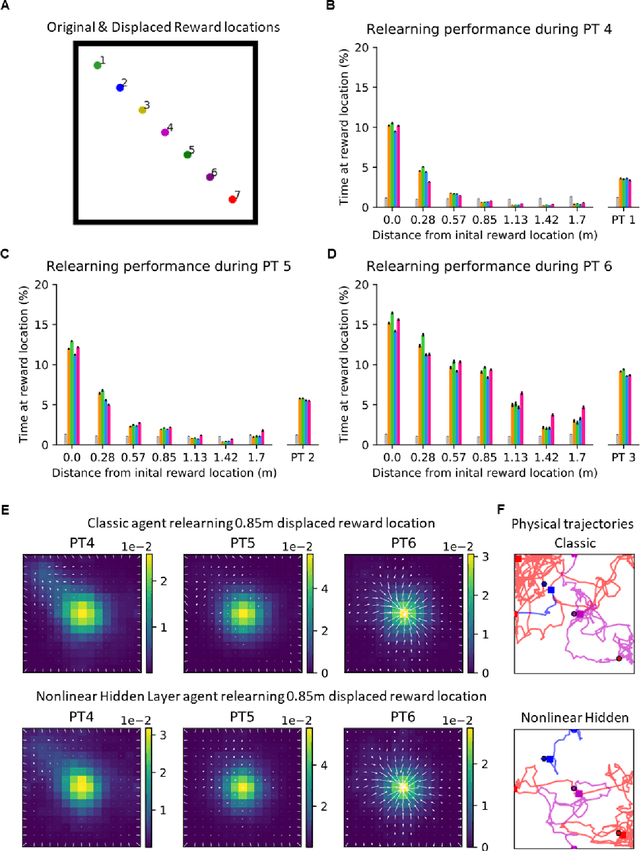
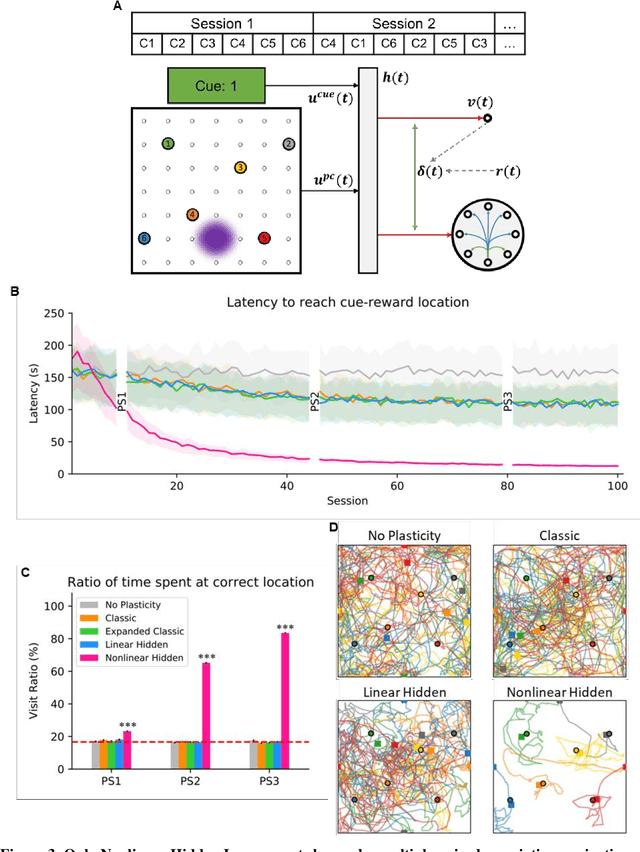

Navigation to multiple cued reward locations has been increasingly used to study rodent learning. Though deep reinforcement learning agents have been shown to be able to learn the task, they are not biologically plausible. Biologically plausible classic actor-critic agents have been shown to learn to navigate to single reward locations, but which biologically plausible agents are able to learn multiple cue-reward location tasks has remained unclear. In this computational study, we show versions of classic agents that learn to navigate to a single reward location, and adapt to reward location displacement, but are not able to learn multiple paired association navigation. The limitation is overcome by an agent in which place cell and cue information are first processed by a feedforward nonlinear hidden layer with synapses to the actor and critic subject to temporal difference error-modulated plasticity. Faster learning is obtained when the feedforward layer is replaced by a recurrent reservoir network.