 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
CrossATNet - A Novel Cross-Attention Based Framework for Sketch-Based Image Retrieval
Apr 20, 2021
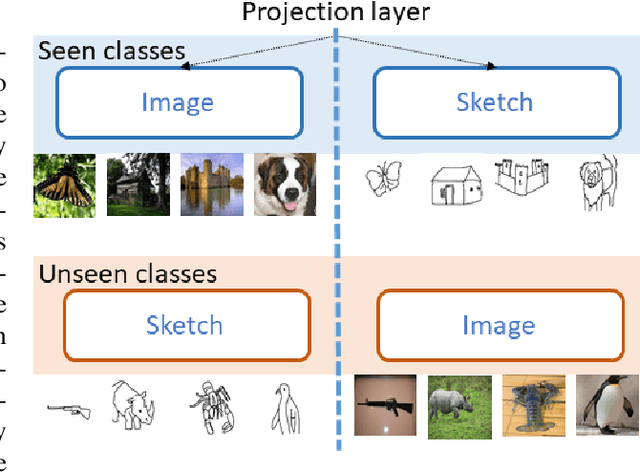
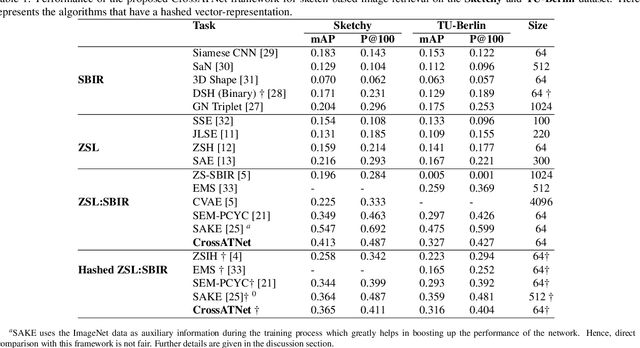
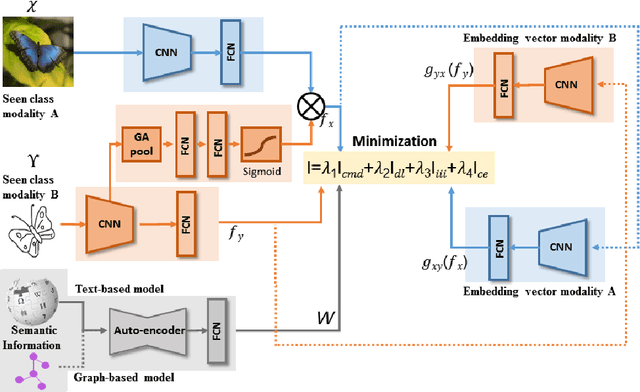
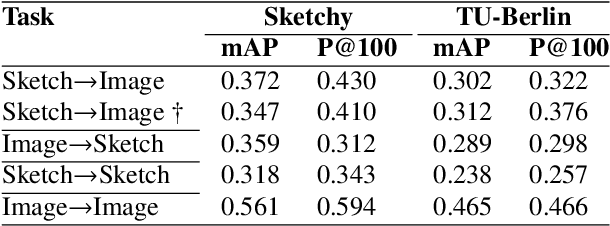
We propose a novel framework for cross-modal zero-shot learning (ZSL) in the context of sketch-based image retrieval (SBIR). Conventionally, the SBIR schema mainly considers simultaneous mappings among the two image views and the semantic side information. Therefore, it is desirable to consider fine-grained classes mainly in the sketch domain using highly discriminative and semantically rich feature space. However, the existing deep generative modeling-based SBIR approaches majorly focus on bridging the gaps between the seen and unseen classes by generating pseudo-unseen-class samples. Besides, violating the ZSL protocol by not utilizing any unseen-class information during training, such techniques do not pay explicit attention to modeling the discriminative nature of the shared space. Also, we note that learning a unified feature space for both the multi-view visual data is a tedious task considering the significant domain difference between sketches and color images. In this respect, as a remedy, we introduce a novel framework for zero-shot SBIR. While we define a cross-modal triplet loss to ensure the discriminative nature of the shared space, an innovative cross-modal attention learning strategy is also proposed to guide feature extraction from the image domain exploiting information from the respective sketch counterpart. In order to preserve the semantic consistency of the shared space, we consider a graph CNN-based module that propagates the semantic class topology to the shared space. To ensure an improved response time during inference, we further explore the possibility of representing the shared space in terms of hash codes. Experimental results obtained on the benchmark TU-Berlin and the Sketchy datasets confirm the superiority of CrossATNet in yielding state-of-the-art results.
Web-Scale Generic Object Detection at Microsoft Bing
Jul 05, 2021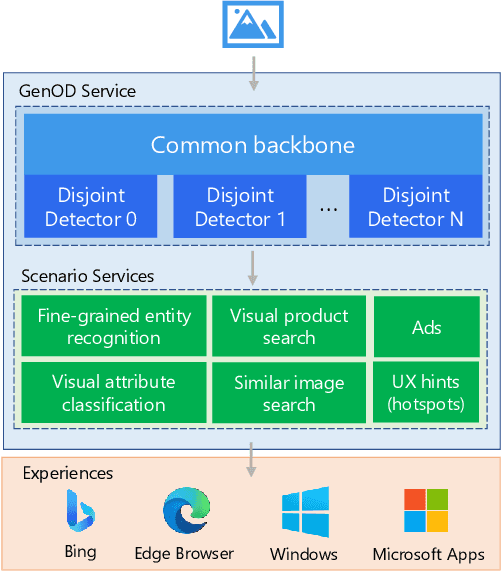

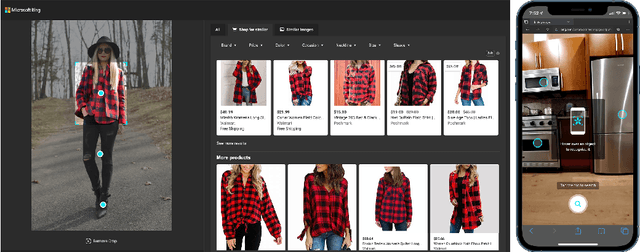

In this paper, we present Generic Object Detection (GenOD), one of the largest object detection systems deployed to a web-scale general visual search engine that can detect over 900 categories for all Microsoft Bing Visual Search queries in near real-time. It acts as a fundamental visual query understanding service that provides object-centric information and shows gains in multiple production scenarios, improving upon domain-specific models. We discuss the challenges of collecting data, training, deploying and updating such a large-scale object detection model with multiple dependencies. We discuss a data collection pipeline that reduces per-bounding box labeling cost by 81.5% and latency by 61.2% while improving on annotation quality. We show that GenOD can improve weighted average precision by over 20% compared to multiple domain-specific models. We also improve the model update agility by nearly 2 times with the proposed disjoint detector training compared to joint fine-tuning. Finally we demonstrate how GenOD benefits visual search applications by significantly improving object-level search relevance by 54.9% and user engagement by 59.9%.
Medical Code Prediction from Discharge Summary: Document to Sequence BERT using Sequence Attention
Jul 05, 2021
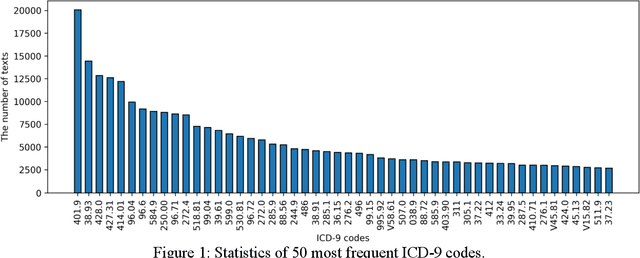
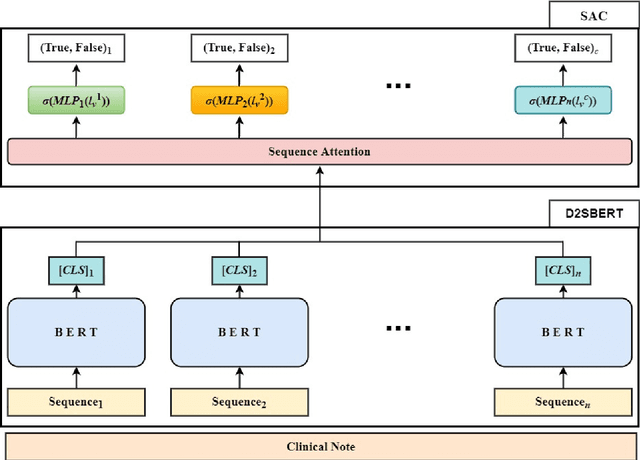

Clinical notes are unstructured text generated by clinicians during patient encounters. Clinical notes are usually accompanied by a set of metadata codes from the International Classification of Diseases(ICD). ICD code is an important code used in various operations, including insurance, reimbursement, medical diagnosis, etc. Therefore, it is important to classify ICD codes quickly and accurately. However, annotating these codes is costly and time-consuming. So we propose a model based on bidirectional encoder representations from transformers (BERT) using the sequence attention method for automatic ICD code assignment. We evaluate our approach on the medical information mart for intensive care III (MIMIC-III) benchmark dataset. Our model achieved performance of macro-averaged F1: 0.62898 and micro-averaged F1: 0.68555 and is performing better than a performance of the state-of-the-art model using the MIMIC-III dataset. The contribution of this study proposes a method of using BERT that can be applied to documents and a sequence attention method that can capture important sequence in-formation appearing in documents.
Data-Driven Online Decision Making with Costly Information Acquisition
Oct 21, 2017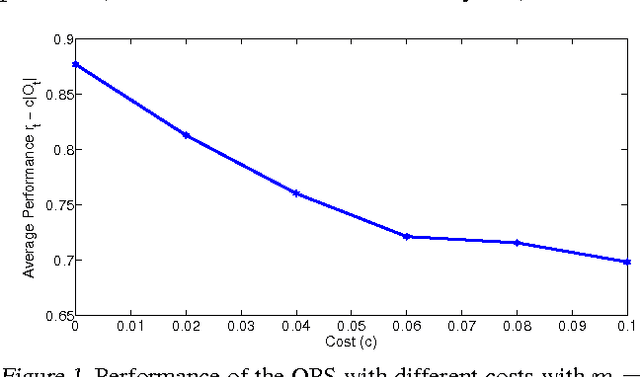
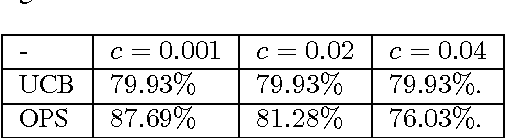
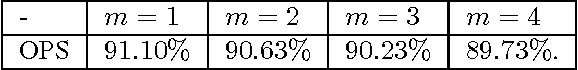
In most real-world settings such as recommender systems, finance, and healthcare, collecting useful information is costly and requires an active choice on the part of the decision maker. The decision-maker needs to learn simultaneously what observations to make and what actions to take. This paper incorporates the information acquisition decision into an online learning framework. We propose two different algorithms for this dual learning problem: Sim-OOS and Seq-OOS where observations are made simultaneously and sequentially, respectively. We prove that both algorithms achieve a regret that is sublinear in time. The developed framework and algorithms can be used in many applications including medical informatics, recommender systems and actionable intelligence in transportation, finance, cyber-security etc., in which collecting information prior to making decisions is costly. We validate our algorithms in a breast cancer example setting in which we show substantial performance gains for our proposed algorithms.
Feature learning for efficient ASR-free keyword spotting in low-resource languages
Aug 13, 2021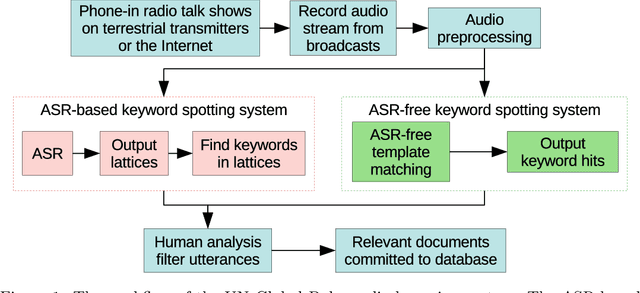
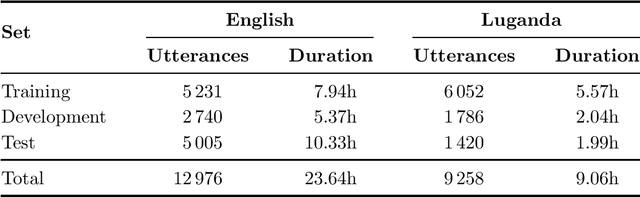

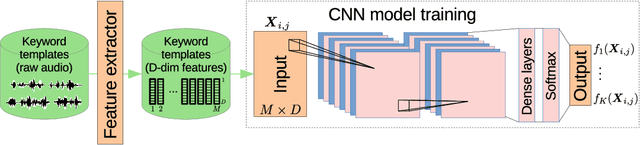
We consider feature learning for efficient keyword spotting that can be applied in severely under-resourced settings. The objective is to support humanitarian relief programmes by the United Nations in parts of Africa in which almost no language resources are available. For rapid development in such languages, we rely on a small, easily-compiled set of isolated keywords. These keyword templates are applied to a large corpus of in-domain but untranscribed speech using dynamic time warping (DTW). The resulting DTW alignment scores are used to train a convolutional neural network (CNN) which is orders of magnitude more computationally efficient and suitable for real-time application. We optimise this neural network keyword spotter by identifying robust acoustic features in this almost zero-resource setting. First, we incorporate information from well-resourced but unrelated languages using a multilingual bottleneck feature (BNF) extractor. Next, we consider features extracted from an autoencoder (AE) trained on in-domain but untranscribed data. Finally, we consider correspondence autoencoder (CAE) features which are fine-tuned on the small set of in-domain labelled data. Experiments in South African English and Luganda, a low-resource language, show that BNF and CAE features achieve a 5% relative performance improvement over baseline MFCCs. However, using BNFs as input to the CAE results in a more than 27% relative improvement over MFCCs in ROC area-under-the-curve (AUC) and more than twice as many top-10 retrievals. We show that, using these features, the CNN-DTW keyword spotter performs almost as well as the DTW keyword spotter while outperforming a baseline CNN trained only on the keyword templates. The CNN-DTW keyword spotter using BNF-derived CAE features represents an efficient approach with competitive performance suited to rapid deployment in a severely under-resourced scenario.
Learnable Compression Network with Transformer for Approximate Nearest Neighbor Search
Jul 30, 2021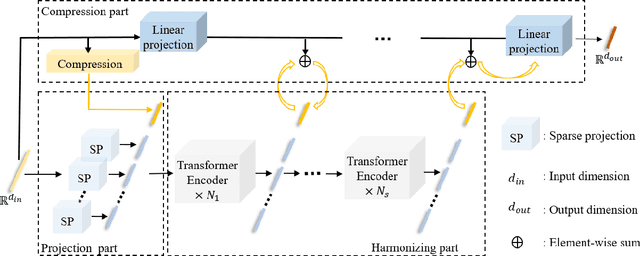
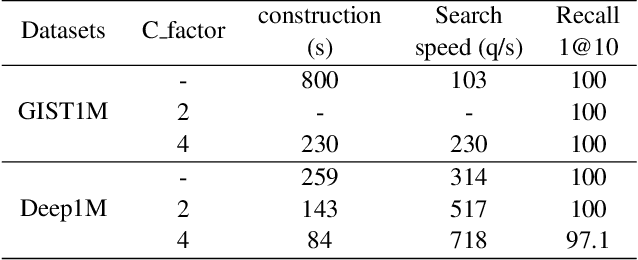
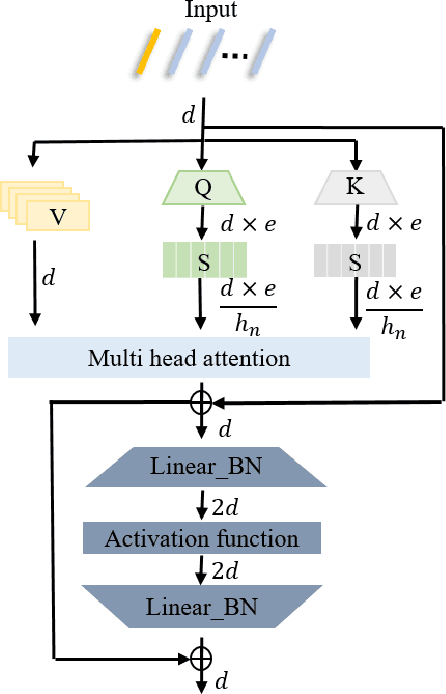
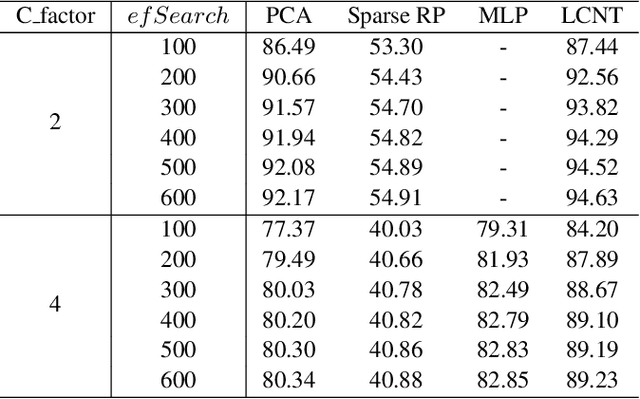
Approximate Nearest neighbor search (ANNS) plays a crucial role in information retrieval, which has a wide range of application scenarios. Therefore, during past several years, a lot of fast ANNS approaches have been proposed. Among these approaches, graph-based methods are one of the most popular type, as they have shown attractive theoretical guarantees and low query latency. In this paper, we propose a learnable compression network with transformer (LCNT), which projects feature vectors from high dimensional space onto low dimensional space, while preserving neighbor relationship. The proposed model can be generalized to existing graph-based methods to accelerate the process of building indexing graph and further reduce query latency. Specifically, the proposed LCNT contains two major parts, projection part and harmonizing part. In the projection part, input vectors are projected into a sequence of subspaces via multi channel sparse projection network. In the harmonizing part, a modified Transformer network is employed to harmonize features in subspaces and combine them to get a new feature. To evaluate the effectiveness of the proposed model, we conduct experiments on two million-scale databases, GIST1M and Deep1M. Experimental results show that the proposed model can improve the speed of building indexing graph to 2-3 times its original speed without sacrificing accuracy significantly. The query latency is reduced by a factor of 1.3 to 2.0. In addition, the proposed model can also be combined with other popular quantization methods.
Learning from Implicit Information in Natural Language Instructions for Robotic Manipulations
Apr 30, 2019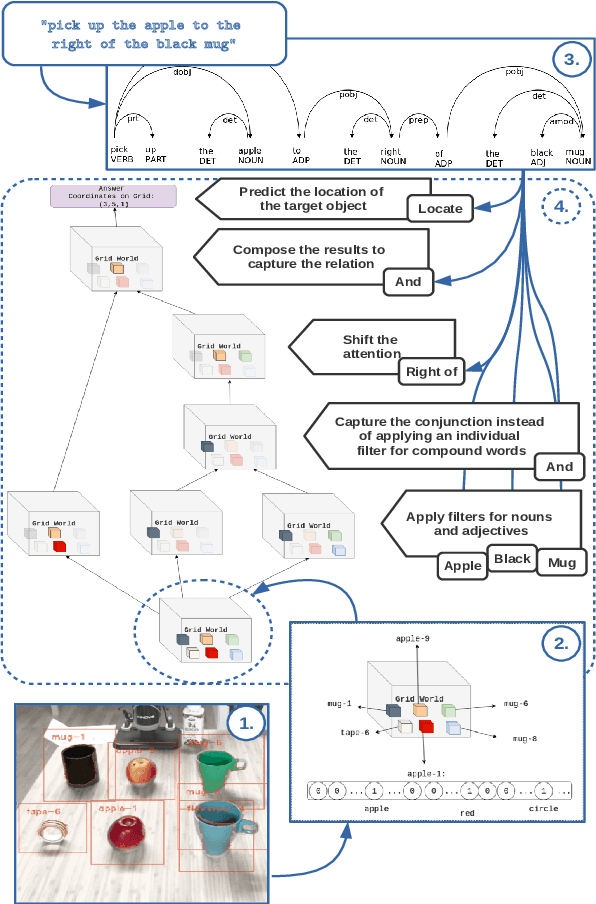
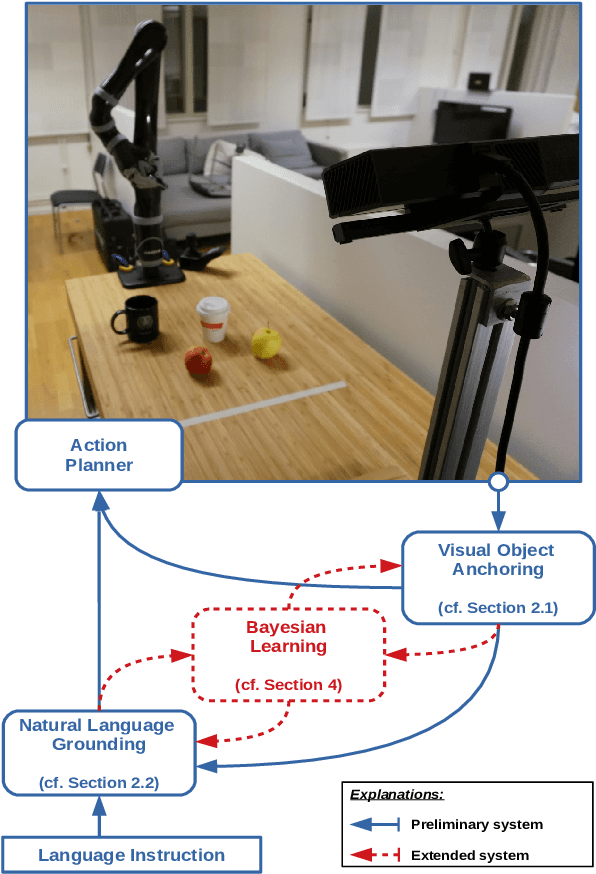

Human-robot interaction often occurs in the form of instructions given from a human to a robot. For a robot to successfully follow instructions, a common representation of the world and objects in it should be shared between humans and the robot so that the instructions can be grounded. Achieving this representation can be done via learning, where both the world representation and the language grounding are learned simultaneously. However, in robotics this can be a difficult task due to the cost and scarcity of data. In this paper, we tackle the problem by separately learning the world representation of the robot and the language grounding. While this approach can address the challenges in getting sufficient data, it may give rise to inconsistencies between both learned components. Therefore, we further propose Bayesian learning to resolve such inconsistencies between the natural language grounding and a robot's world representation by exploiting spatio-relational information that is implicitly present in instructions given by a human. Moreover, we demonstrate the feasibility of our approach on a scenario involving a robotic arm in the physical world.
Compressed Monte Carlo with application in particle filtering
Jul 18, 2021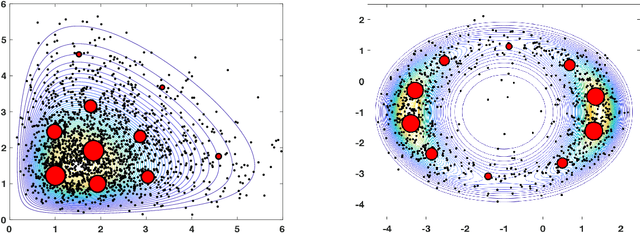
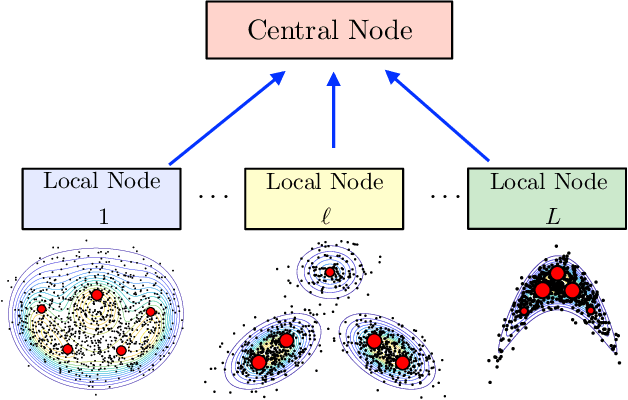
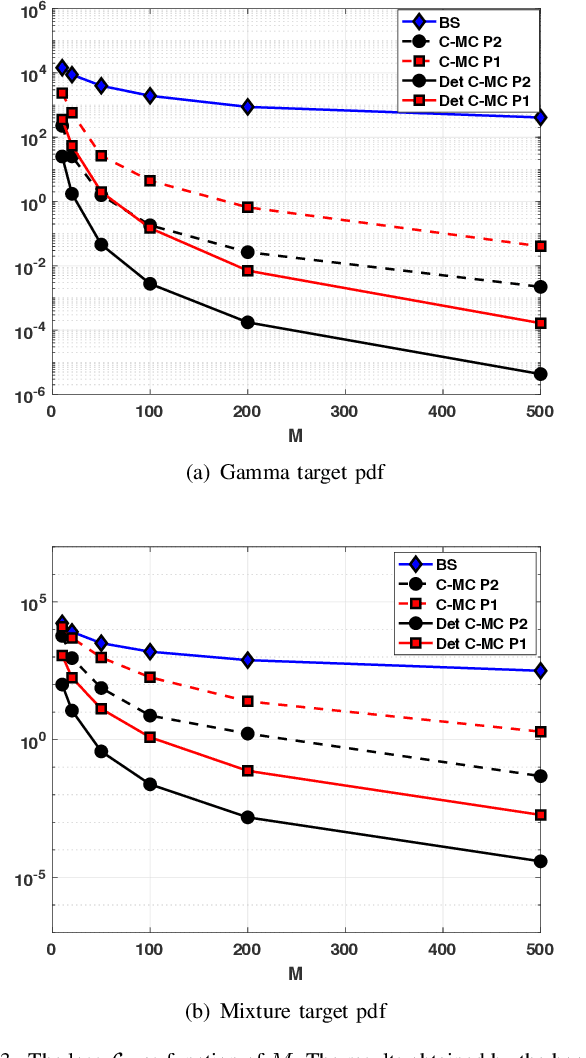
Bayesian models have become very popular over the last years in several fields such as signal processing, statistics, and machine learning. Bayesian inference requires the approximation of complicated integrals involving posterior distributions. For this purpose, Monte Carlo (MC) methods, such as Markov Chain Monte Carlo and importance sampling algorithms, are often employed. In this work, we introduce the theory and practice of a Compressed MC (C-MC) scheme to compress the statistical information contained in a set of random samples. In its basic version, C-MC is strictly related to the stratification technique, a well-known method used for variance reduction purposes. Deterministic C-MC schemes are also presented, which provide very good performance. The compression problem is strictly related to the moment matching approach applied in different filtering techniques, usually called as Gaussian quadrature rules or sigma-point methods. C-MC can be employed in a distributed Bayesian inference framework when cheap and fast communications with a central processor are required. Furthermore, C-MC is useful within particle filtering and adaptive IS algorithms, as shown by three novel schemes introduced in this work. Six numerical results confirm the benefits of the introduced schemes, outperforming the corresponding benchmark methods. A related code is also provided.
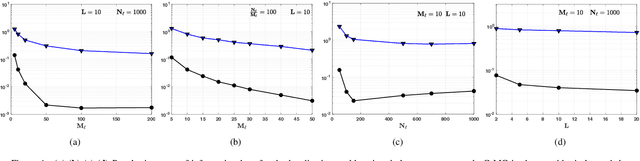
Neighborhood Contrastive Learning Applied to Online Patient Monitoring
Jun 09, 2021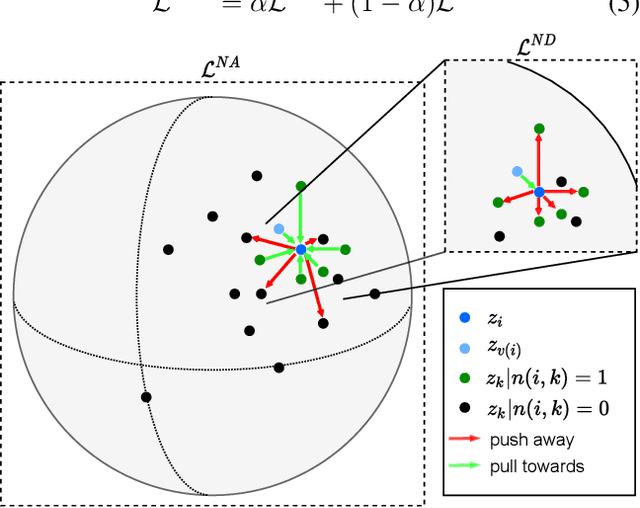
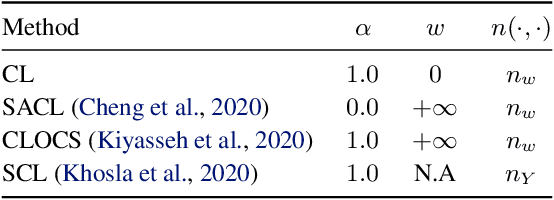
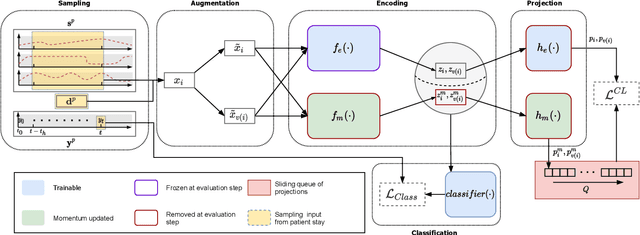
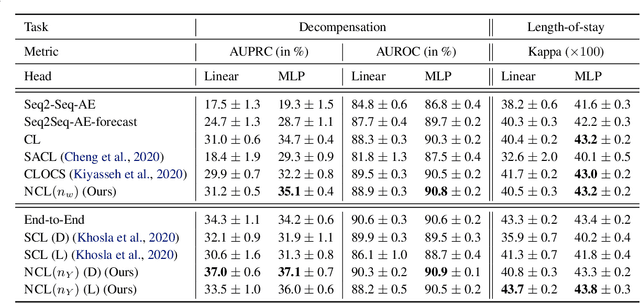
Intensive care units (ICU) are increasingly looking towards machine learning for methods to provide online monitoring of critically ill patients. In machine learning, online monitoring is often formulated as a supervised learning problem. Recently, contrastive learning approaches have demonstrated promising improvements over competitive supervised benchmarks. These methods rely on well-understood data augmentation techniques developed for image data which do not apply to online monitoring. In this work, we overcome this limitation by supplementing time-series data augmentation techniques with a novel contrastive learning objective which we call neighborhood contrastive learning (NCL). Our objective explicitly groups together contiguous time segments from each patient while maintaining state-specific information. Our experiments demonstrate a marked improvement over existing work applying contrastive methods to medical time-series.
Analysis and classification of main risk factors causing stroke in Shanxi Province
May 29, 2021
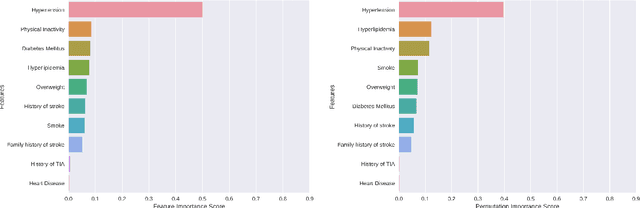
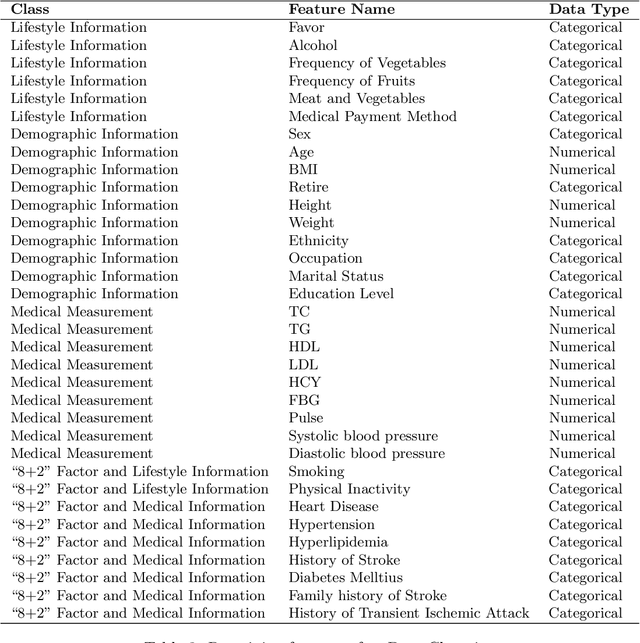
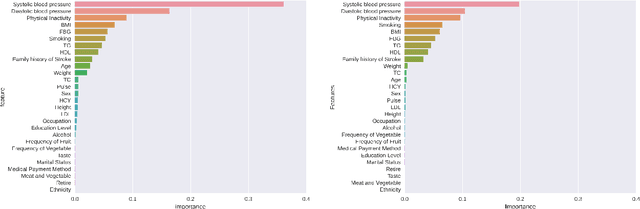
In China, stroke is the first leading cause of death in recent years. It is a major cause of long-term physical and cognitive impairment, which bring great pressure on the National Public Health System. Evaluation of the risk of getting stroke is important for the prevention and treatment of stroke in China. A data set with 2000 hospitalized stroke patients in 2018 and 27583 residents during the year 2017 to 2020 is analyzed in this study. Due to data incompleteness, inconsistency, and non-structured formats, missing values in the raw data are filled with -1 as an abnormal class. With the cleaned features, three models on risk levels of getting stroke are built by using machine learning methods. The importance of "8+2" factors from China National Stroke Prevention Project (CSPP) is evaluated via decision tree and random forest models. Except for "8+2" factors the importance of features and SHAP1 values for lifestyle information, demographic information, and medical measurement are evaluated and ranked via a random forest model. Furthermore, a logistic regression model is applied to evaluate the probability of getting stroke for different risk levels. Based on the census data in both communities and hospitals from Shanxi Province, we investigate different risk factors of getting stroke and their ranking with interpretable machine learning models. The results show that Hypertension (Systolic blood pressure, Diastolic blood pressure), Physical Inactivity (Lack of sports), and Overweight (BMI) are ranked as the top three high-risk factors of getting stroke in Shanxi province. The probability of getting stroke for a person can also be predicted via our machine learning model.