 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Hear Me Out: Fusional Approaches for Audio Augmented Temporal Action Localization
Jul 06, 2021
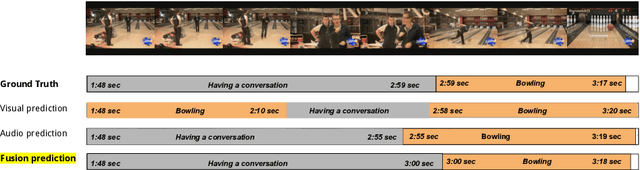
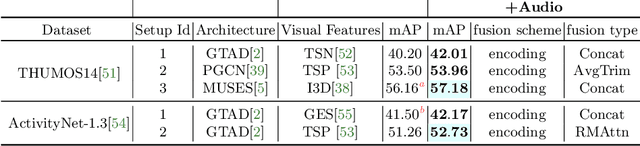
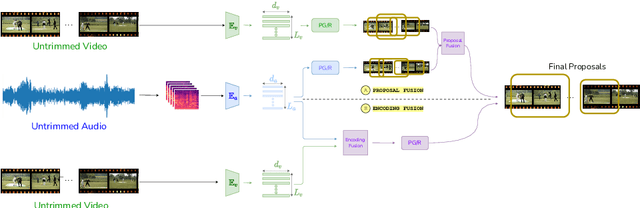

State of the art architectures for untrimmed video Temporal Action Localization (TAL) have only considered RGB and Flow modalities, leaving the information-rich audio modality totally unexploited. Audio fusion has been explored for the related but arguably easier problem of trimmed (clip-level) action recognition. However, TAL poses a unique set of challenges. In this paper, we propose simple but effective fusion-based approaches for TAL. To the best of our knowledge, our work is the first to jointly consider audio and video modalities for supervised TAL. We experimentally show that our schemes consistently improve performance for state of the art video-only TAL approaches. Specifically, they help achieve new state of the art performance on large-scale benchmark datasets - ActivityNet-1.3 (54.34 mAP@0.5) and THUMOS14 (57.18 mAP@0.5). Our experiments include ablations involving multiple fusion schemes, modality combinations and TAL architectures. Our code, models and associated data will be made available.
PiSLTRc: Position-informed Sign Language Transformer with Content-aware Convolution
Jul 27, 2021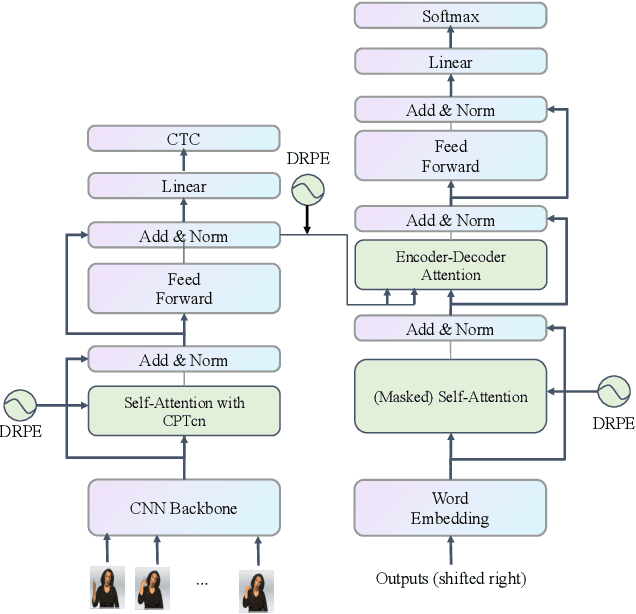
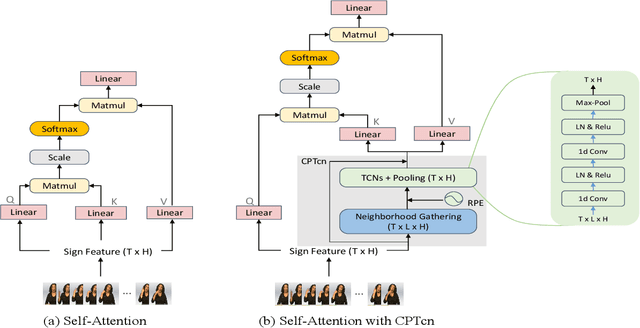


Since the superiority of Transformer in learning long-term dependency, the sign language Transformer model achieves remarkable progress in Sign Language Recognition (SLR) and Translation (SLT). However, there are several issues with the Transformer that prevent it from better sign language understanding. The first issue is that the self-attention mechanism learns sign video representation in a frame-wise manner, neglecting the temporal semantic structure of sign gestures. Secondly, the attention mechanism with absolute position encoding is direction and distance unaware, thus limiting its ability. To address these issues, we propose a new model architecture, namely PiSLTRc, with two distinctive characteristics: (i) content-aware and position-aware convolution layers. Specifically, we explicitly select relevant features using a novel content-aware neighborhood gathering method. Then we aggregate these features with position-informed temporal convolution layers, thus generating robust neighborhood-enhanced sign representation. (ii) injecting the relative position information to the attention mechanism in the encoder, decoder, and even encoder-decoder cross attention. Compared with the vanilla Transformer model, our model performs consistently better on three large-scale sign language benchmarks: PHOENIX-2014, PHOENIX-2014-T and CSL. Furthermore, extensive experiments demonstrate that the proposed method achieves state-of-the-art performance on translation quality with $+1.6$ BLEU improvements.
Semiotic Aggregation in Deep Learning
Apr 22, 2021
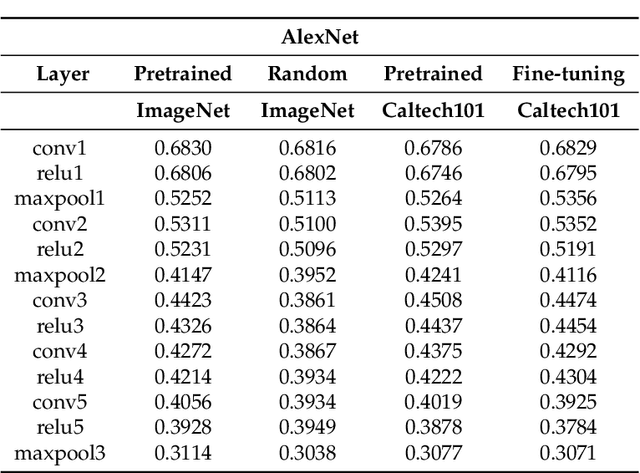
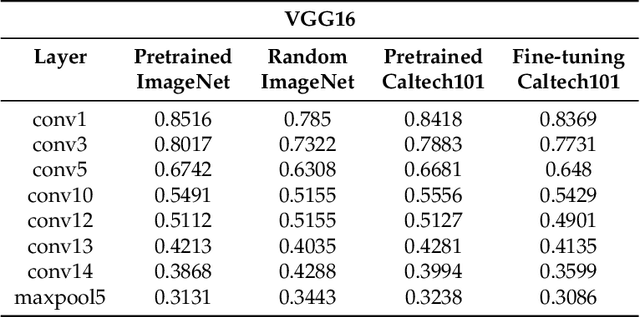
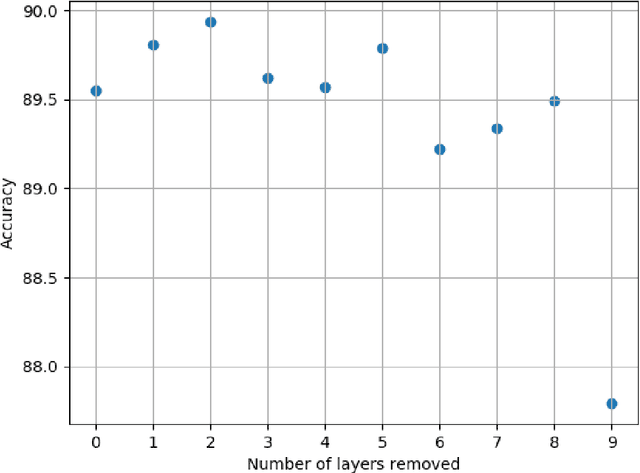
Convolutional neural networks utilize a hierarchy of neural network layers. The statistical aspects of information concentration in successive layers can bring an insight into the feature abstraction process. We analyze the saliency maps of these layers from the perspective of semiotics, also known as the study of signs and sign-using behavior. In computational semiotics, this aggregation operation (known as superization) is accompanied by a decrease of spatial entropy: signs are aggregated into supersign. Using spatial entropy, we compute the information content of the saliency maps and study the superization processes which take place between successive layers of the network. In our experiments, we visualize the superization process and show how the obtained knowledge can be used to explain the neural decision model. In addition, we attempt to optimize the architecture of the neural model employing a semiotic greedy technique. To the extent of our knowledge, this is the first application of computational semiotics in the analysis and interpretation of deep neural networks.
CCGL: Contrastive Cascade Graph Learning
Jul 27, 2021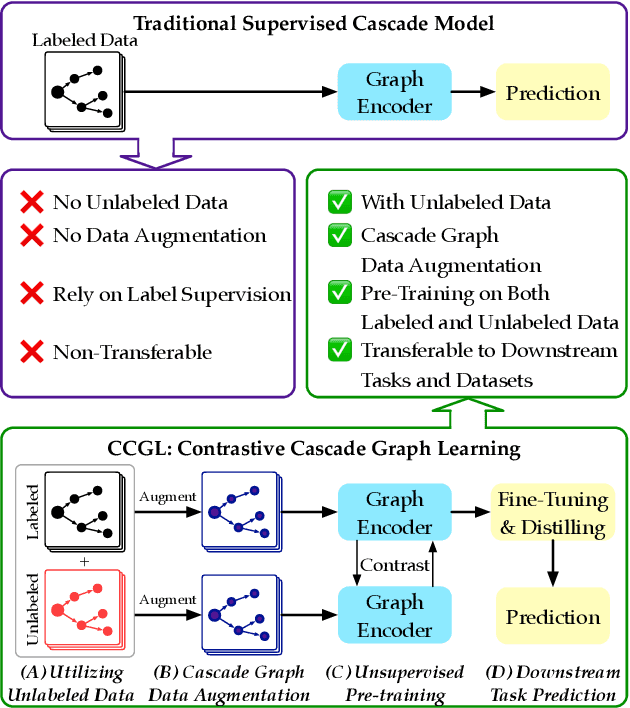
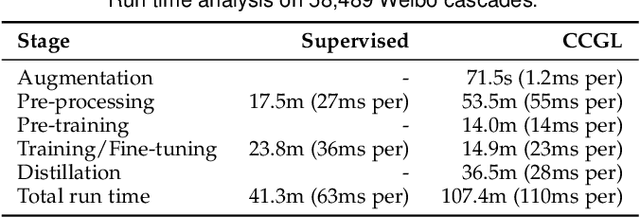
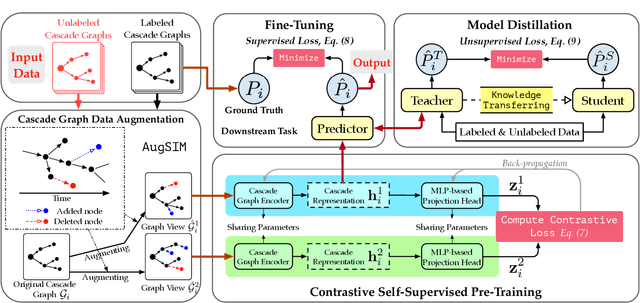
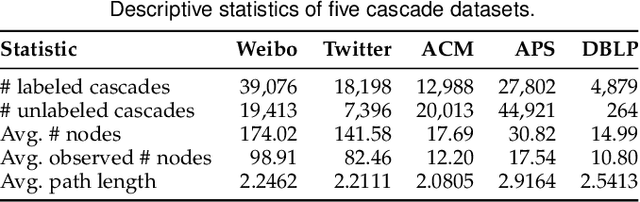
Supervised learning, while prevalent for information cascade modeling, often requires abundant labeled data in training, and the trained model is not easy to generalize across tasks and datasets. Semi-supervised learning facilitates unlabeled data for cascade understanding in pre-training. It often learns fine-grained feature-level representations, which can easily result in overfitting for downstream tasks. Recently, contrastive self-supervised learning is designed to alleviate these two fundamental issues in linguistic and visual tasks. However, its direct applicability for cascade modeling, especially graph cascade related tasks, remains underexplored. In this work, we present Contrastive Cascade Graph Learning (CCGL), a novel framework for cascade graph representation learning in a contrastive, self-supervised, and task-agnostic way. In particular, CCGL first designs an effective data augmentation strategy to capture variation and uncertainty. Second, it learns a generic model for graph cascade tasks via self-supervised contrastive pre-training using both unlabeled and labeled data. Third, CCGL learns a task-specific cascade model via fine-tuning using labeled data. Finally, to make the model transferable across datasets and cascade applications, CCGL further enhances the model via distillation using a teacher-student architecture. We demonstrate that CCGL significantly outperforms its supervised and semi-supervised counterpartsfor several downstream tasks.
A highly scalable repository of waveform and vital signs data from bedside monitoring devices
Jun 07, 2021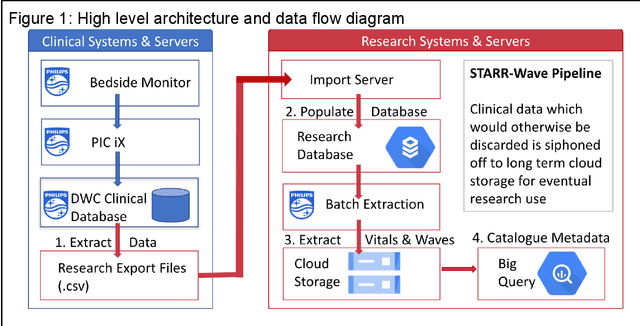
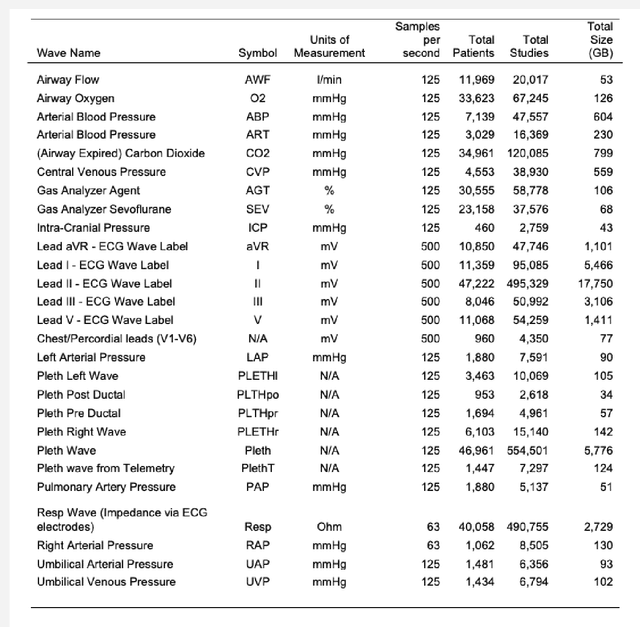
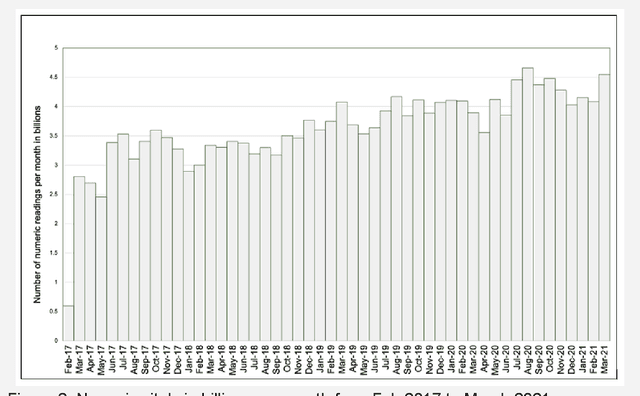
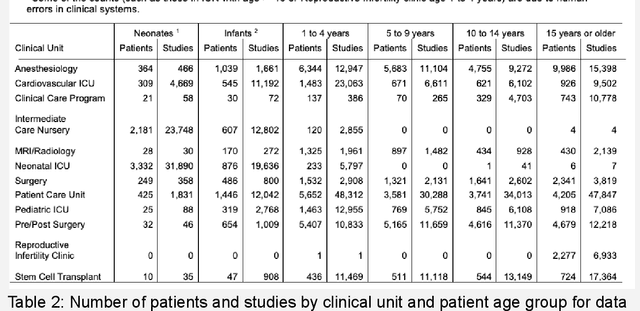
The advent of cost effective cloud computing over the past decade and ever-growing accumulation of high-fidelity clinical data in a modern hospital setting is leading to new opportunities for translational medicine. Machine learning is driving the appetite of the research community for various types of signal data such as patient vitals. Health care systems, however, are ill suited for massive processing of large volumes of data. In addition, due to the sheer magnitude of the data being collected, it is not feasible to retain all of the data in health care systems in perpetuity. This gold mine of information gets purged periodically thereby losing invaluable future research opportunities. We have developed a highly scalable solution that: a) siphons off patient vital data on a nightly basis from on-premises bio-medical systems to a cloud storage location as a permanent archive, b) reconstructs the database in the cloud, c) generates waveforms, alarms and numeric data in a research-ready format, and d) uploads the processed data to a storage location in the cloud ready for research. The data is de-identified and catalogued such that it can be joined with Electronic Medical Records (EMR) and other ancillary data types such as electroencephalogram (EEG), radiology, video monitoring etc. This technique eliminates the research burden from health care systems. This highly scalable solution is used to process high density patient monitoring data aggregated by the Philips Patient Information Center iX (PIC iX) hospital surveillance system for archival storage in the Philips Data Warehouse Connect enterprise-level database. The solution is part of a broader platform that supports a secure high performance clinical data science platform.
Cross-speaker Style Transfer with Prosody Bottleneck in Neural Speech Synthesis
Jul 27, 2021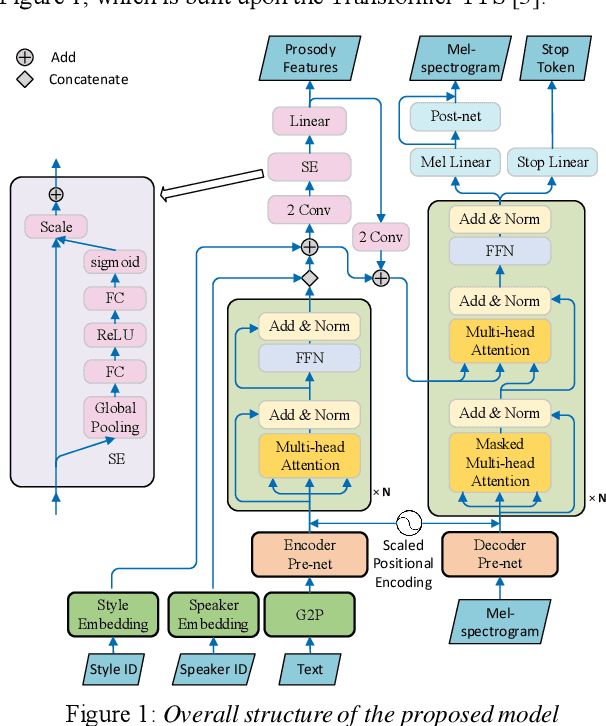
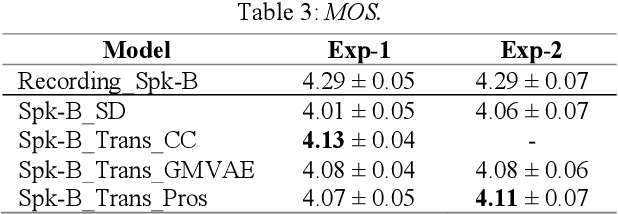
Cross-speaker style transfer is crucial to the applications of multi-style and expressive speech synthesis at scale. It does not require the target speakers to be experts in expressing all styles and to collect corresponding recordings for model training. However, the performances of existing style transfer methods are still far behind real application needs. The root causes are mainly twofold. Firstly, the style embedding extracted from single reference speech can hardly provide fine-grained and appropriate prosody information for arbitrary text to synthesize. Secondly, in these models the content/text, prosody, and speaker timbre are usually highly entangled, it's therefore not realistic to expect a satisfied result when freely combining these components, such as to transfer speaking style between speakers. In this paper, we propose a cross-speaker style transfer text-to-speech (TTS) model with explicit prosody bottleneck. The prosody bottleneck builds up the kernels accounting for speaking style robustly, and disentangles the prosody from content and speaker timbre, therefore guarantees high quality cross-speaker style transfer. Evaluation result shows the proposed method even achieves on-par performance with source speaker's speaker-dependent (SD) model in objective measurement of prosody, and significantly outperforms the cycle consistency and GMVAE-based baselines in objective and subjective evaluations.
Diffeomorphic Particle Image Velocimetry
Aug 17, 2021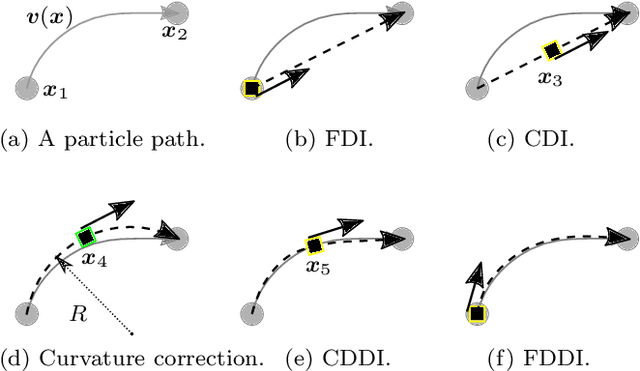
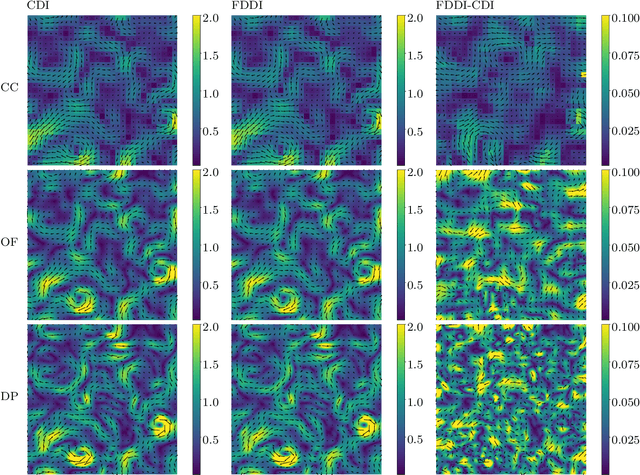
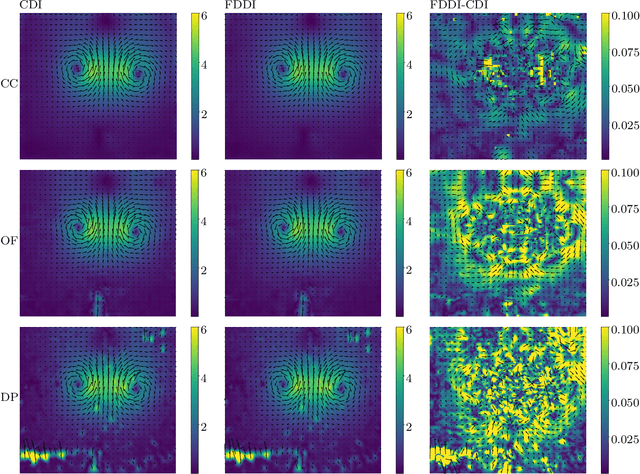
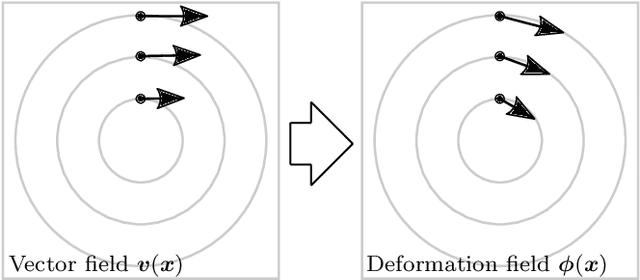
The existing particle image velocimetry (PIV) do not consider the curvature effect of the non-straight particle trajectory, because it seems to be impossible to obtain the curvature information from a pair of particle images. As a result, the computed vector underestimates the real velocity due to the straight-line approximation, that further causes a systematic error for the PIV instrument. In this work, the particle curved trajectory between two recordings is firstly explained with the streamline segment of a steady flow (diffeomorphic transformation) instead of a single vector, and this idea is termed as diffeomorphic PIV. Specifically, a deformation field is introduced to describe the particle displacement, i.e., we try to find the optimal velocity field, of which the corresponding deformation vector field agrees with the particle displacement. Because the variation of the deformation function can be approximated with the variation of the velocity function, the diffeomorphic PIV can be implemented as iterative PIV. That says, the diffeomorphic PIV warps the images with deformation vector field instead of the velocity, and keeps the rest as same as iterative PIVs. Two diffeomorphic deformation schemes -- forward diffeomorphic deformation interrogation (FDDI) and central diffeomorphic deformation interrogation (CDDI) -- are proposed. Tested on synthetic images, the FDDI achieves significant accuracy improvement across different one-pass displacement estimators (cross-correlation, optical flow, deep learning flow). Besides, the results on three real PIV image pairs demonstrate the non-negligible curvature effect for CDI-based PIV, and our FDDI provides larger velocity estimation (more accurate) in the fast curvy streamline areas. The accuracy improvement of the combination of FDDI and accurate dense estimator means that our diffeomorphic PIV paves a new way for complex flow measurement.
Network Representation Learning: From Traditional Feature Learning to Deep Learning
Mar 07, 2021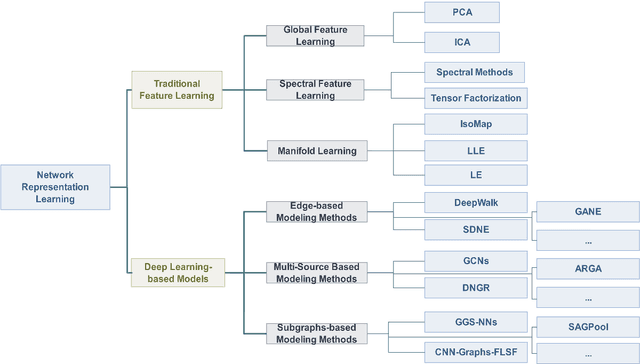
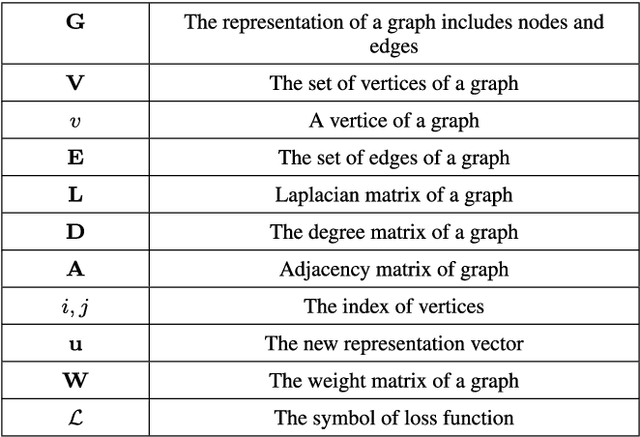
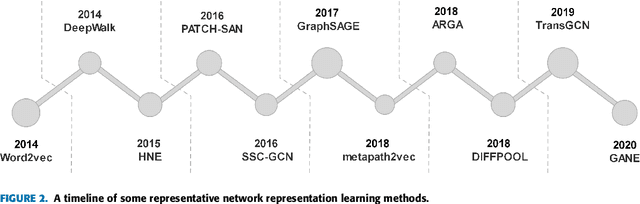
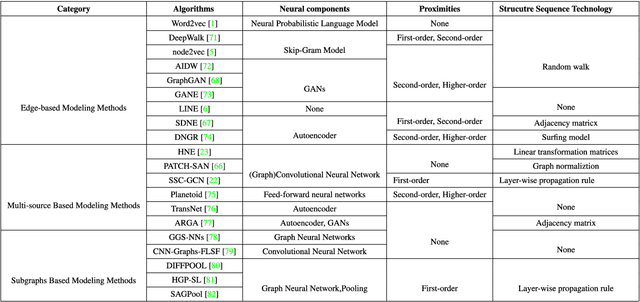
Network representation learning (NRL) is an effective graph analytics technique and promotes users to deeply understand the hidden characteristics of graph data. It has been successfully applied in many real-world tasks related to network science, such as social network data processing, biological information processing, and recommender systems. Deep Learning is a powerful tool to learn data features. However, it is non-trivial to generalize deep learning to graph-structured data since it is different from the regular data such as pictures having spatial information and sounds having temporal information. Recently, researchers proposed many deep learning-based methods in the area of NRL. In this survey, we investigate classical NRL from traditional feature learning method to the deep learning-based model, analyze relationships between them, and summarize the latest progress. Finally, we discuss open issues considering NRL and point out the future directions in this field.
Focusing on Shadows for Predicting Heightmaps from Single Remotely Sensed RGB Images with Deep Learning
Apr 22, 2021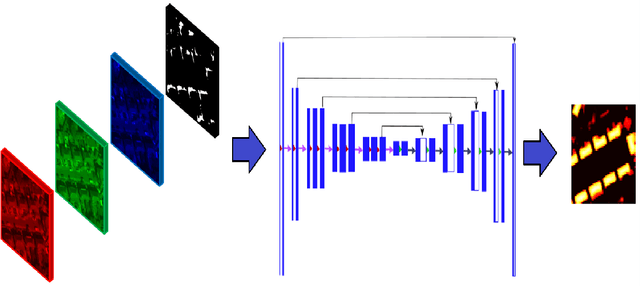

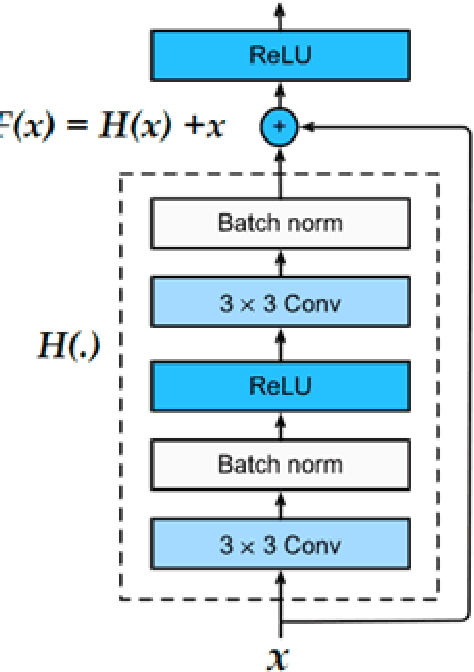
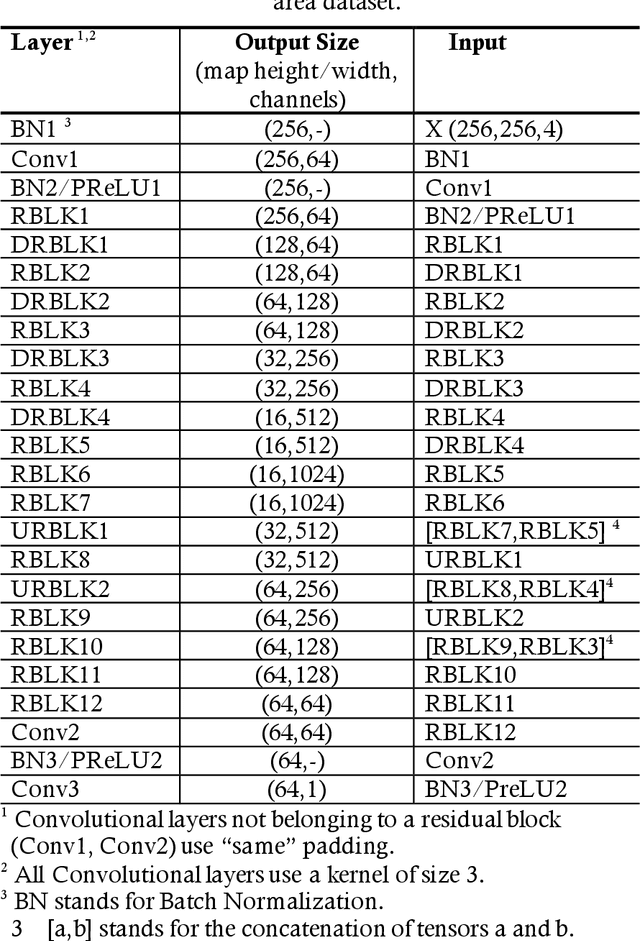
Estimating the heightmaps of buildings and vegetation in single remotely sensed images is a challenging problem. Effective solutions to this problem can comprise the stepping stone for solving complex and demanding problems that require 3D information of aerial imagery in the remote sensing discipline, which might be expensive or not feasible to require. We propose a task-focused Deep Learning (DL) model that takes advantage of the shadow map of a remotely sensed image to calculate its heightmap. The shadow is computed efficiently and does not add significant computation complexity. The model is trained with aerial images and their Lidar measurements, achieving superior performance on the task. We validate the model with a dataset covering a large area of Manchester, UK, as well as the 2018 IEEE GRSS Data Fusion Contest Lidar dataset. Our work suggests that the proposed DL architecture and the technique of injecting shadows information into the model are valuable for improving the heightmap estimation task for single remotely sensed imagery.
Rethinking InfoNCE: How Many Negative Samples Do You Need?
May 27, 2021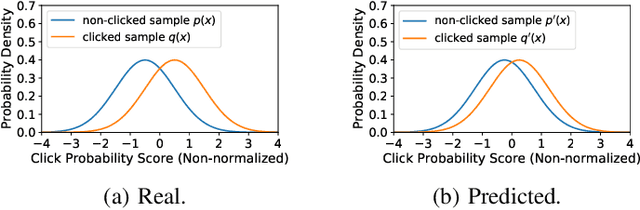
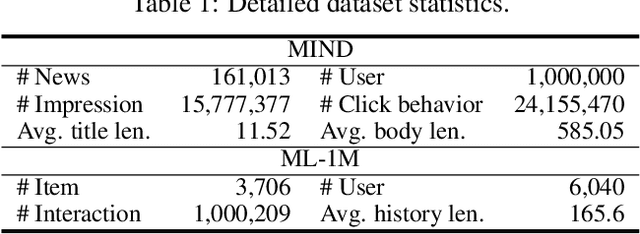
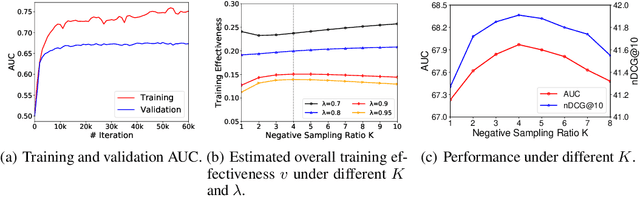
InfoNCE loss is a widely used loss function for contrastive model training. It aims to estimate the mutual information between a pair of variables by discriminating between each positive pair and its associated $K$ negative pairs. It is proved that when the sample labels are clean, the lower bound of mutual information estimation is tighter when more negative samples are incorporated, which usually yields better model performance. However, in many real-world tasks the labels often contain noise, and incorporating too many noisy negative samples for model training may be suboptimal. In this paper, we study how many negative samples are optimal for InfoNCE in different scenarios via a semi-quantitative theoretical framework. More specifically, we first propose a probabilistic model to analyze the influence of the negative sampling ratio $K$ on training sample informativeness. Then, we design a training effectiveness function to measure the overall influence of training samples on model learning based on their informativeness. We estimate the optimal negative sampling ratio using the $K$ value that maximizes the training effectiveness function. Based on our framework, we further propose an adaptive negative sampling method that can dynamically adjust the negative sampling ratio to improve InfoNCE based model training. Extensive experiments on different real-world datasets show our framework can accurately predict the optimal negative sampling ratio in different tasks, and our proposed adaptive negative sampling method can achieve better performance than the commonly used fixed negative sampling ratio strategy.