 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
CBLUE: A Chinese Biomedical Language Understanding Evaluation Benchmark
Jul 06, 2021
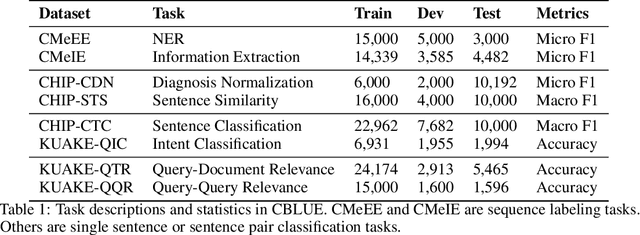
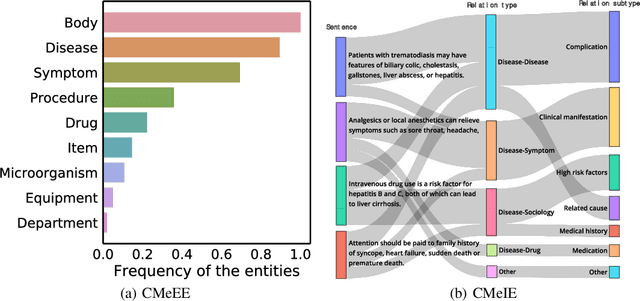
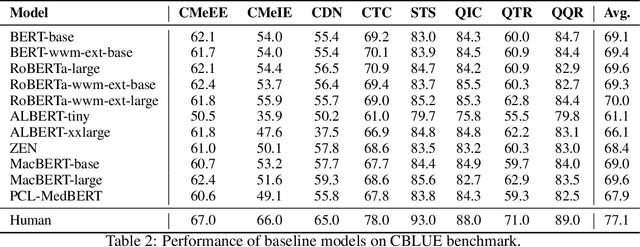
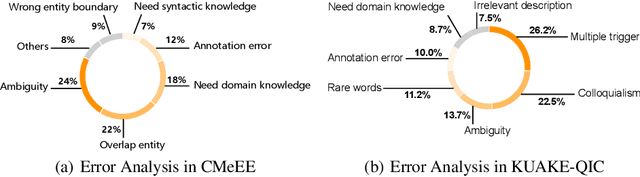
Artificial Intelligence (AI), along with the recent progress in biomedical language understanding, is gradually changing medical practice. With the development of biomedical language understanding benchmarks, AI applications are widely used in the medical field. However, most benchmarks are limited to English, which makes it challenging to replicate many of the successes in English for other languages. To facilitate research in this direction, we collect real-world biomedical data and present the first Chinese Biomedical Language Understanding Evaluation (CBLUE) benchmark: a collection of natural language understanding tasks including named entity recognition, information extraction, clinical diagnosis normalization, single-sentence/sentence-pair classification, and an associated online platform for model evaluation, comparison, and analysis. To establish evaluation on these tasks, we report empirical results with the current 11 pre-trained Chinese models, and experimental results show that state-of-the-art neural models perform by far worse than the human ceiling. Our benchmark is released at \url{https://tianchi.aliyun.com/dataset/dataDetail?dataId=95414&lang=en-us}.
Unsupervised Knowledge-Transfer for Learned Image Reconstruction
Jul 06, 2021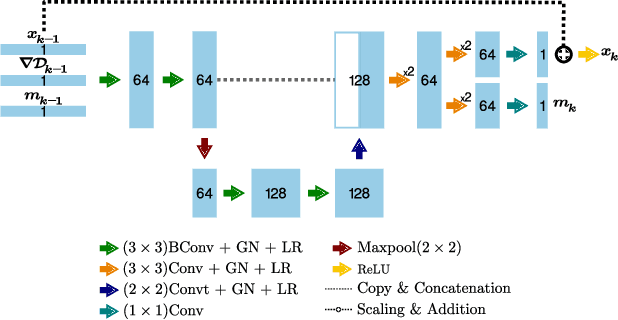
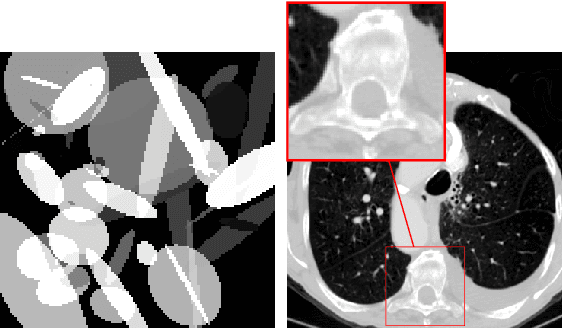
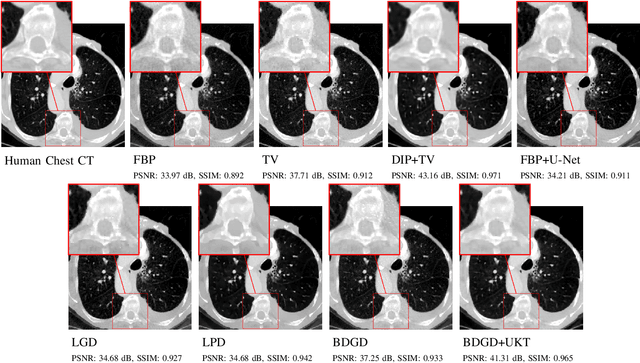
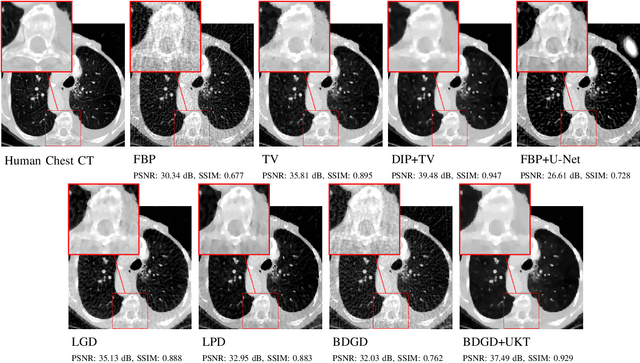
Deep learning-based image reconstruction approaches have demonstrated impressive empirical performance in many imaging modalities. These approaches generally require a large amount of high-quality training data, which is often not available. To circumvent this issue, we develop a novel unsupervised knowledge-transfer paradigm for learned iterative reconstruction within a Bayesian framework. The proposed approach learns an iterative reconstruction network in two phases. The first phase trains a reconstruction network with a set of ordered pairs comprising of ground truth images and measurement data. The second phase fine-tunes the pretrained network to the measurement data without supervision. Furthermore, the framework delivers uncertainty information over the reconstructed image. We present extensive experimental results on low-dose and sparse-view computed tomography, showing that the proposed framework significantly improves reconstruction quality not only visually, but also quantitatively in terms of PSNR and SSIM, and is competitive with several state-of-the-art supervised and unsupervised reconstruction techniques.
Rethinking Positional Encoding
Jul 06, 2021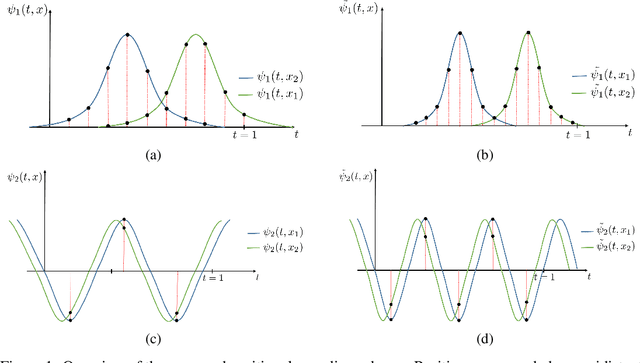
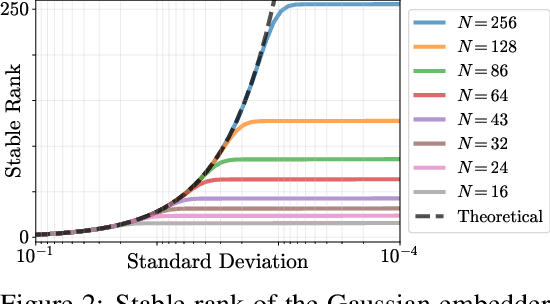
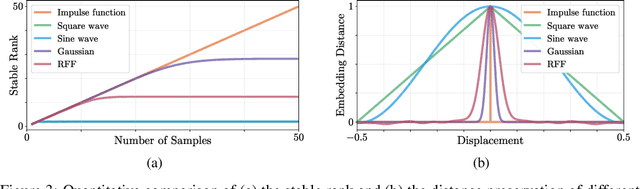
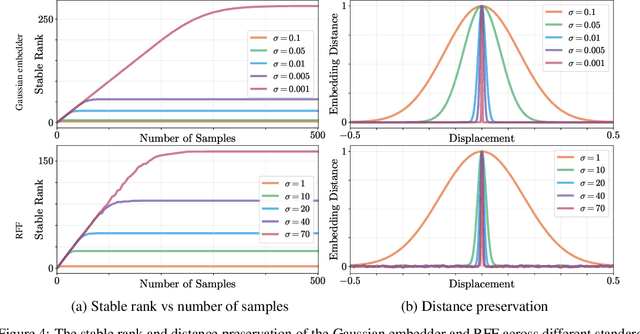
It is well noted that coordinate based MLPs benefit greatly -- in terms of preserving high-frequency information -- through the encoding of coordinate positions as an array of Fourier features. Hitherto, the rationale for the effectiveness of these positional encodings has been solely studied through a Fourier lens. In this paper, we strive to broaden this understanding by showing that alternative non-Fourier embedding functions can indeed be used for positional encoding. Moreover, we show that their performance is entirely determined by a trade-off between the stable rank of the embedded matrix and the distance preservation between embedded coordinates. We further establish that the now ubiquitous Fourier feature mapping of position is a special case that fulfills these conditions. Consequently, we present a more general theory to analyze positional encoding in terms of shifted basis functions. To this end, we develop the necessary theoretical formulae and empirically verify that our theoretical claims hold in practice. Codes available at https://github.com/osiriszjq/Rethinking-positional-encoding.
Predicting Critical Nodes in Temporal Networks by Dynamic Graph Convolutional Networks
Jul 06, 2021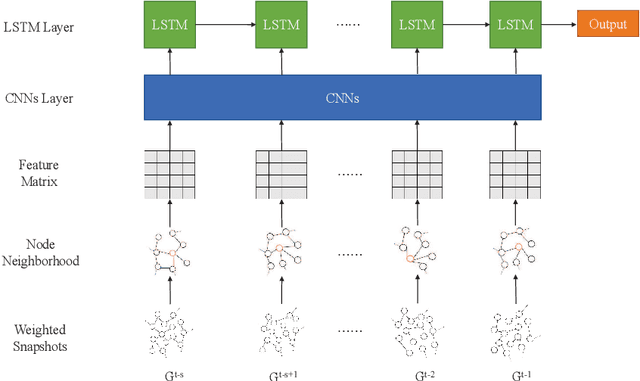
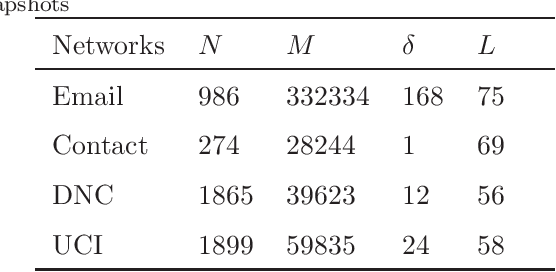
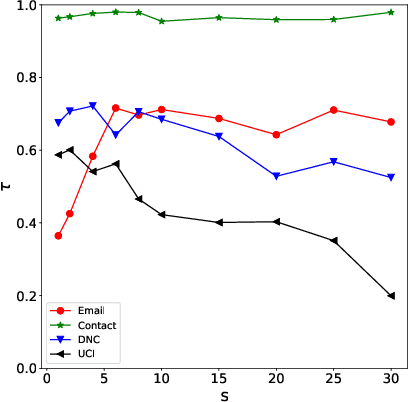

Many real-world systems can be expressed in temporal networks with nodes playing far different roles in structure and function and edges representing the relationships between nodes. Identifying critical nodes can help us control the spread of public opinions or epidemics, predict leading figures in academia, conduct advertisements for various commodities, and so on. However, it is rather difficult to identify critical nodes because the network structure changes over time in temporal networks. In this paper, considering the sequence topological information of temporal networks, a novel and effective learning framework based on the combination of special GCNs and RNNs is proposed to identify nodes with the best spreading ability. The effectiveness of the approach is evaluated by weighted Susceptible-Infected-Recovered model. Experimental results on four real-world temporal networks demonstrate that the proposed method outperforms both traditional and deep learning benchmark methods in terms of the Kendall $\tau$ coefficient and top $k$ hit rate.
Alias-Free Generative Adversarial Networks
Jun 23, 2021
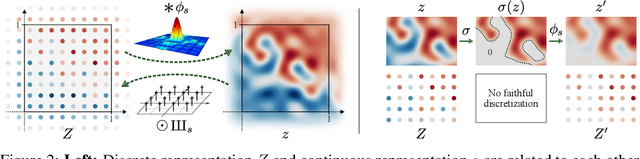
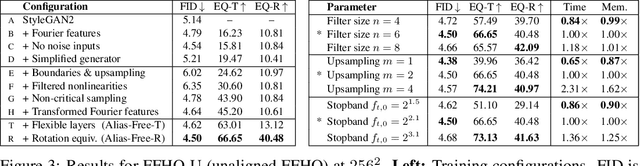
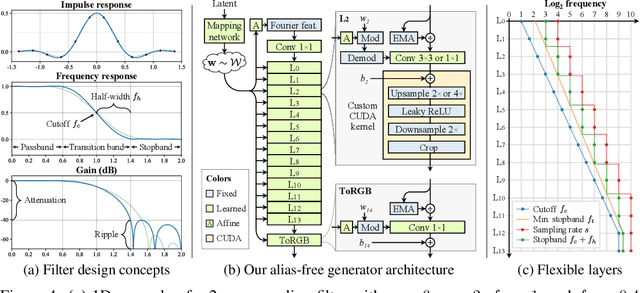
We observe that despite their hierarchical convolutional nature, the synthesis process of typical generative adversarial networks depends on absolute pixel coordinates in an unhealthy manner. This manifests itself as, e.g., detail appearing to be glued to image coordinates instead of the surfaces of depicted objects. We trace the root cause to careless signal processing that causes aliasing in the generator network. Interpreting all signals in the network as continuous, we derive generally applicable, small architectural changes that guarantee that unwanted information cannot leak into the hierarchical synthesis process. The resulting networks match the FID of StyleGAN2 but differ dramatically in their internal representations, and they are fully equivariant to translation and rotation even at subpixel scales. Our results pave the way for generative models better suited for video and animation.
Momentum Contrastive Voxel-wise Representation Learning for Semi-supervised Volumetric Medical Image Segmentation
May 14, 2021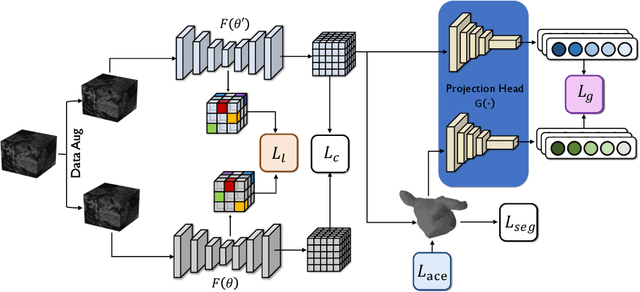
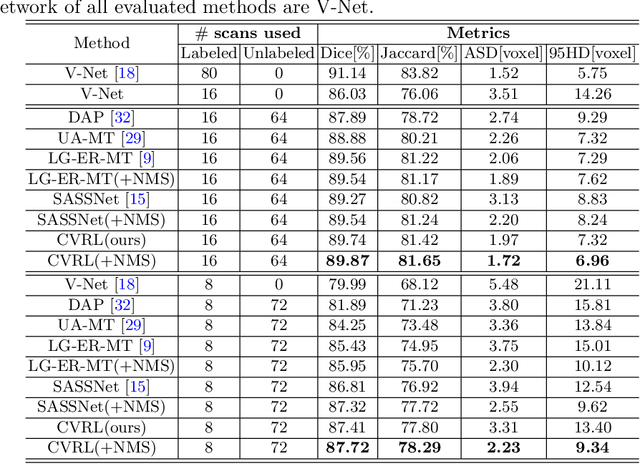
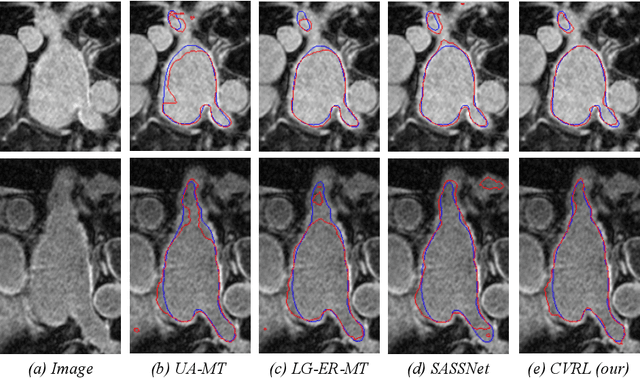
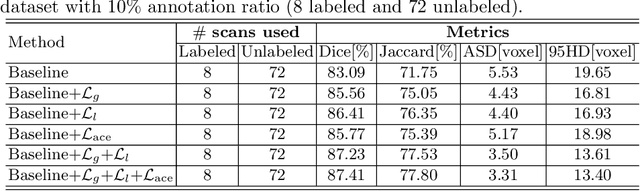
Automated segmentation in medical image analysis is a challenging task that requires a large amount of manually labeled data. However, manually annotating medical data is often laborious, and most existing learning-based approaches fail to accurately delineate object boundaries without effective geometric constraints. Contrastive learning, a sub-area of self-supervised learning, has recently been noted as a promising direction in multiple application fields. In this work, we present a novel Contrastive Voxel-wise Representation Learning (CVRL) method with geometric constraints to learn global-local visual representations for volumetric medical image segmentation with limited annotations. Our framework can effectively learn global and local features by capturing 3D spatial context and rich anatomical information. Specifically, we introduce a voxel-to-volume contrastive algorithm to learn global information from 3D images, and propose to perform local voxel-to-voxel contrast to explicitly make use of local cues in the embedding space. Moreover, we integrate an elastic interaction-based active contour model as a geometric regularization term to enable fast and reliable object delineations in an end-to-end learning manner. Results on the Atrial Segmentation Challenge dataset demonstrate superiority of our proposed scheme, especially in a setting with a very limited number of annotated data.
A Context-Dependent Gated Module for Incorporating Symbolic Semantics into Event Coreference Resolution
Apr 04, 2021
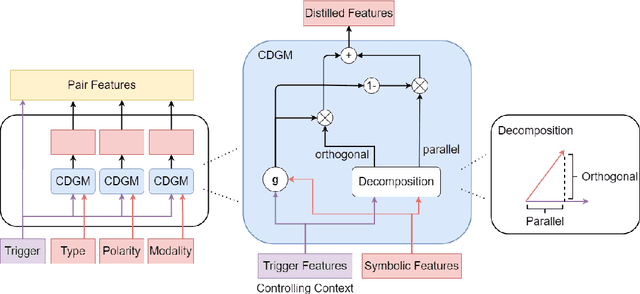
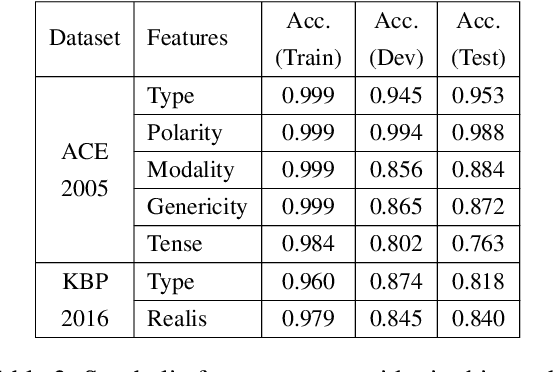
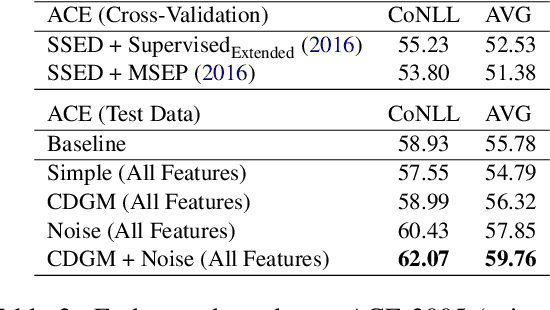
Event coreference resolution is an important research problem with many applications. Despite the recent remarkable success of pretrained language models, we argue that it is still highly beneficial to utilize symbolic features for the task. However, as the input for coreference resolution typically comes from upstream components in the information extraction pipeline, the automatically extracted symbolic features can be noisy and contain errors. Also, depending on the specific context, some features can be more informative than others. Motivated by these observations, we propose a novel context-dependent gated module to adaptively control the information flows from the input symbolic features. Combined with a simple noisy training method, our best models achieve state-of-the-art results on two datasets: ACE 2005 and KBP 2016.
For high-dimensional hierarchical models, consider exchangeability of effects across covariates instead of across datasets
Jul 13, 2021



Hierarchical Bayesian methods enable information sharing across multiple related regression problems. While standard practice is to model regression parameters (effects) as (1) exchangeable across datasets and (2) correlated to differing degrees across covariates, we show that this approach exhibits poor statistical performance when the number of covariates exceeds the number of datasets. For instance, in statistical genetics, we might regress dozens of traits (defining datasets) for thousands of individuals (responses) on up to millions of genetic variants (covariates). When an analyst has more covariates than datasets, we argue that it is often more natural to instead model effects as (1) exchangeable across covariates and (2) correlated to differing degrees across datasets. To this end, we propose a hierarchical model expressing our alternative perspective. We devise an empirical Bayes estimator for learning the degree of correlation between datasets. We develop theory that demonstrates that our method outperforms the classic approach when the number of covariates dominates the number of datasets, and corroborate this result empirically on several high-dimensional multiple regression and classification problems.
Semiotic Aggregation in Deep Learning
Apr 22, 2021
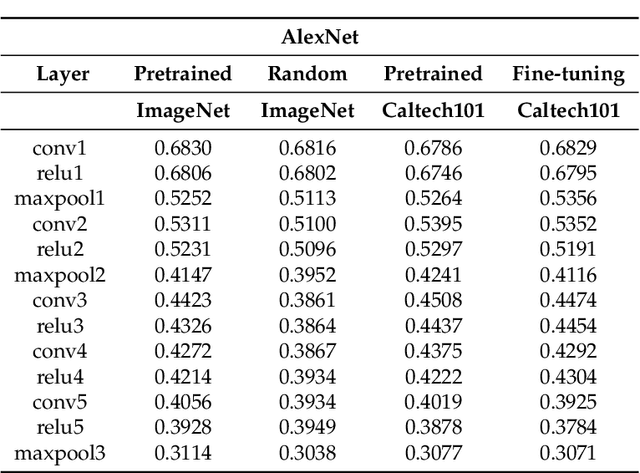
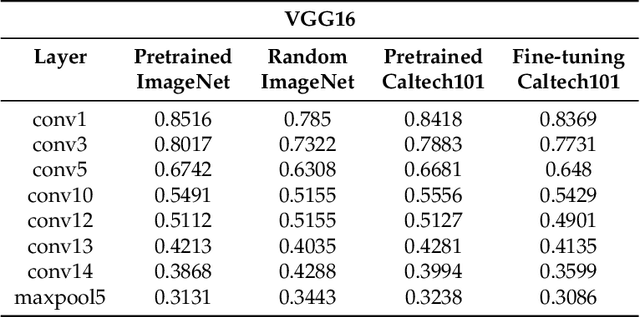
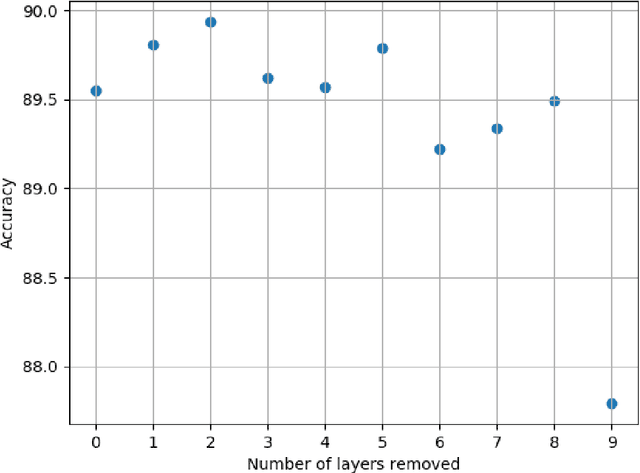
Convolutional neural networks utilize a hierarchy of neural network layers. The statistical aspects of information concentration in successive layers can bring an insight into the feature abstraction process. We analyze the saliency maps of these layers from the perspective of semiotics, also known as the study of signs and sign-using behavior. In computational semiotics, this aggregation operation (known as superization) is accompanied by a decrease of spatial entropy: signs are aggregated into supersign. Using spatial entropy, we compute the information content of the saliency maps and study the superization processes which take place between successive layers of the network. In our experiments, we visualize the superization process and show how the obtained knowledge can be used to explain the neural decision model. In addition, we attempt to optimize the architecture of the neural model employing a semiotic greedy technique. To the extent of our knowledge, this is the first application of computational semiotics in the analysis and interpretation of deep neural networks.
Implicitly Incorporating Morphological Information into Word Embedding
May 08, 2017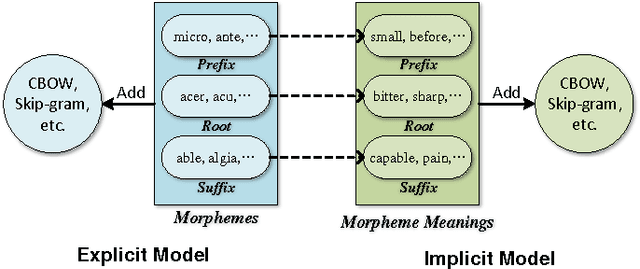
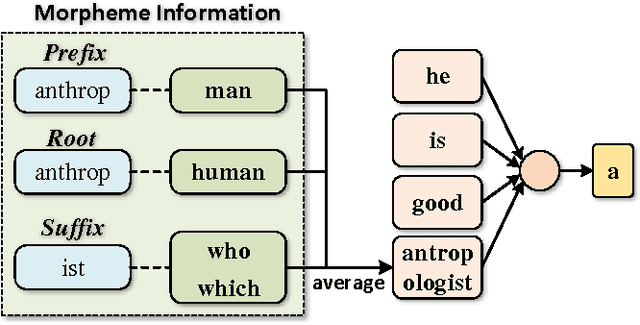
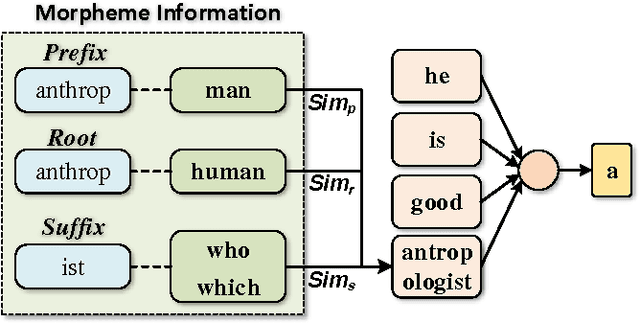
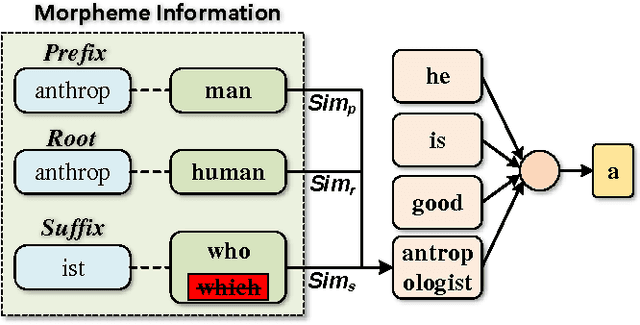
In this paper, we propose three novel models to enhance word embedding by implicitly using morphological information. Experiments on word similarity and syntactic analogy show that the implicit models are superior to traditional explicit ones. Our models outperform all state-of-the-art baselines and significantly improve the performance on both tasks. Moreover, our performance on the smallest corpus is similar to the performance of CBOW on the corpus which is five times the size of ours. Parameter analysis indicates that the implicit models can supplement semantic information during the word embedding training process.