 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
On learning parametric distributions from quantized samples
May 25, 2021
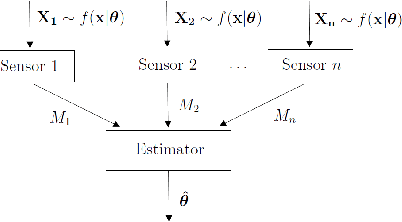
We consider the problem of learning parametric distributions from their quantized samples in a network. Specifically, $n$ agents or sensors observe independent samples of an unknown parametric distribution; and each of them uses $k$ bits to describe its observed sample to a central processor whose goal is to estimate the unknown distribution. First, we establish a generalization of the well-known van Trees inequality to general $L_p$-norms, with $p > 1$, in terms of Generalized Fisher information. Then, we develop minimax lower bounds on the estimation error for two losses: general $L_p$-norms and the related Wasserstein loss from optimal transport.
LightFuse: Lightweight CNN based Dual-exposure Fusion
Jul 05, 2021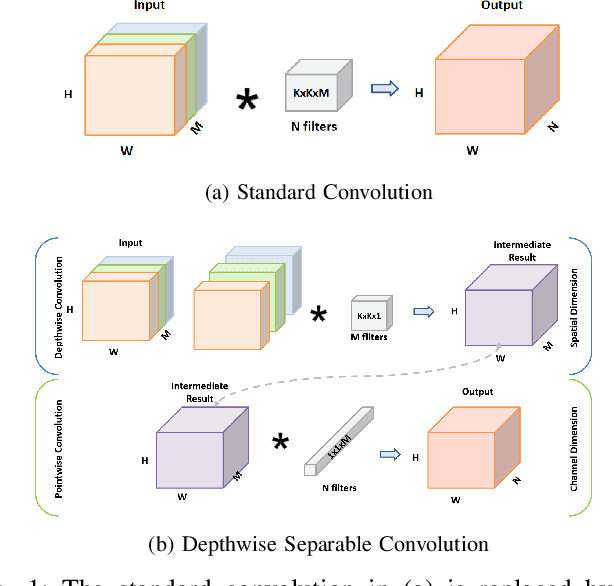
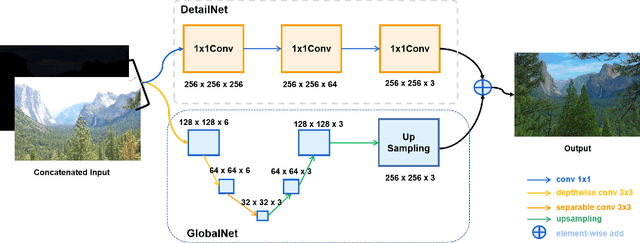


Deep convolutional neural networks (DCNN) aided high dynamic range (HDR) imaging recently received a lot of attention. The quality of DCNN generated HDR images have overperformed the traditional counterparts. However, DCNN is prone to be computationally intensive and power-hungry. To address the challenge, we propose LightFuse, a light-weight CNN-based algorithm for extreme dual-exposure image fusion, which can be implemented on various embedded computing platforms with limited power and hardware resources. Two sub-networks are utilized: a GlobalNet (G) and a DetailNet (D). The goal of G is to learn the global illumination information on the spatial dimension, whereas D aims to enhance local details on the channel dimension. Both G and D are based solely on depthwise convolution (D Conv) and pointwise convolution (P Conv) to reduce required parameters and computations. Experimental results display that the proposed technique could generate HDR images with plausible details in extremely exposed regions. Our PSNR score exceeds the other state-of-the-art approaches by 1.2 to 1.6 times and achieves 1.4 to 20 times FLOP and parameter reduction compared with others.
A Graph Neural Network Approach for Product Relationship Prediction
May 12, 2021
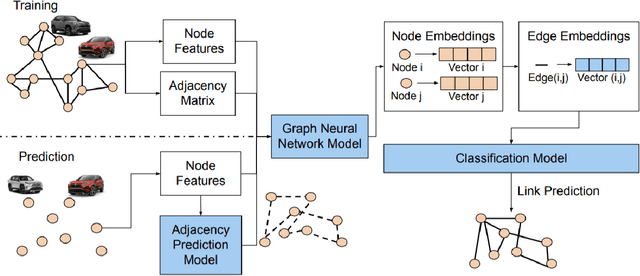
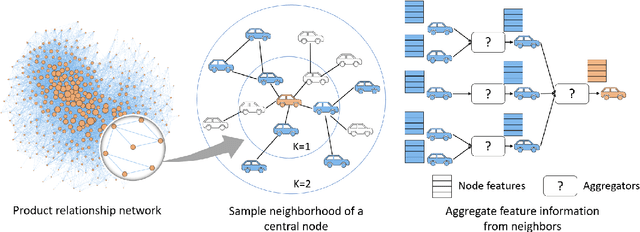
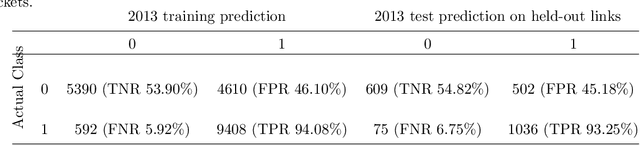
Graph Neural Networks have revolutionized many machine learning tasks in recent years, ranging from drug discovery, recommendation systems, image classification, social network analysis to natural language understanding. This paper shows their efficacy in modeling relationships between products and making predictions for unseen product networks. By representing products as nodes and their relationships as edges of a graph, we show how an inductive graph neural network approach, named GraphSAGE, can efficiently learn continuous representations for nodes and edges. These representations also capture product feature information such as price, brand, or engineering attributes. They are combined with a classification model for predicting the existence of the relationship between products. Using a case study of the Chinese car market, we find that our method yields double the prediction performance compared to an Exponential Random Graph Model-based method for predicting the co-consideration relationship between cars. While a vanilla GraphSAGE requires a partial network to make predictions, we introduce an `adjacency prediction model' to circumvent this limitation. This enables us to predict product relationships when no neighborhood information is known. Finally, we demonstrate how a permutation-based interpretability analysis can provide insights on how design attributes impact the predictions of relationships between products. This work provides a systematic method to predict the relationships between products in many different markets.
Medical Code Prediction from Discharge Summary: Document to Sequence BERT using Sequence Attention
Jun 28, 2021
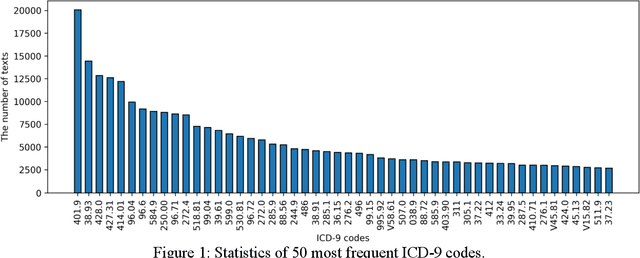
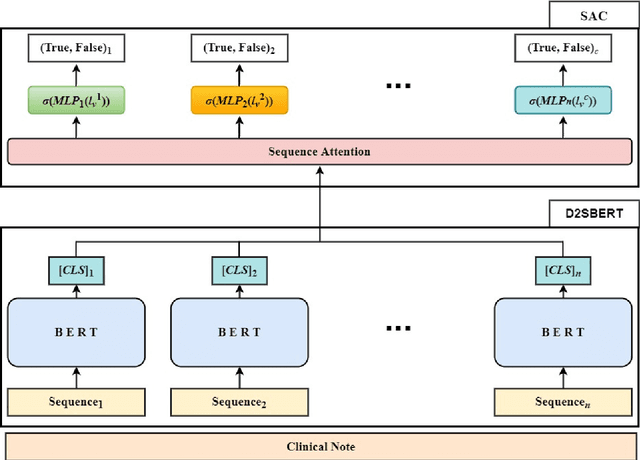

Clinical notes are unstructured text generated by clinicians during patient encounters. Clinical notes are usually accompanied by a set of metadata codes from the international classification of diseases (ICD). ICD code is an important code used in a variety of operations, including insurance, reimbursement, medical diagnosis, etc. Therefore, it is important to classify ICD codes quickly and accurately. However, annotating these codes is costly and time-consuming. So we propose a model based on bidirectional encoder representations from transformer (BERT) using the sequence attention method for automatic ICD code assignment. We evaluate our ap-proach on the MIMIC-III benchmark dataset. Our model achieved performance of Macro-aver-aged F1: 0.62898 and Micro-averaged F1: 0.68555, and is performing better than a performance of the previous state-of-the-art model. The contribution of this study proposes a method of using BERT that can be applied to documents and a sequence attention method that can capture im-portant sequence information appearing in documents.
Second-Order Information in Non-Convex Stochastic Optimization: Power and Limitations
Jun 24, 2020
We design an algorithm which finds an $\epsilon$-approximate stationary point (with $\|\nabla F(x)\|\le \epsilon$) using $O(\epsilon^{-3})$ stochastic gradient and Hessian-vector products, matching guarantees that were previously available only under a stronger assumption of access to multiple queries with the same random seed. We prove a lower bound which establishes that this rate is optimal and---surprisingly---that it cannot be improved using stochastic $p$th order methods for any $p\ge 2$, even when the first $p$ derivatives of the objective are Lipschitz. Together, these results characterize the complexity of non-convex stochastic optimization with second-order methods and beyond. Expanding our scope to the oracle complexity of finding $(\epsilon,\gamma)$-approximate second-order stationary points, we establish nearly matching upper and lower bounds for stochastic second-order methods. Our lower bounds here are novel even in the noiseless case.
Contrast-enhanced MRI Synthesis Using 3D High-Resolution ConvNets
Apr 04, 2021
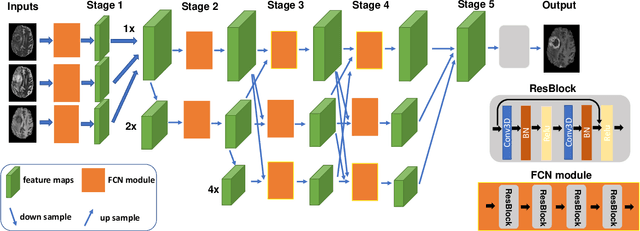
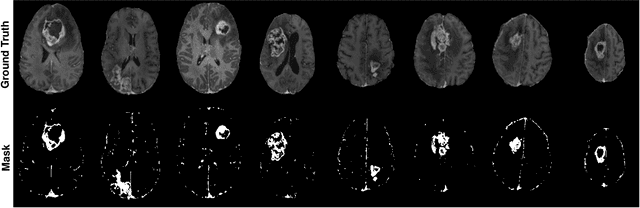
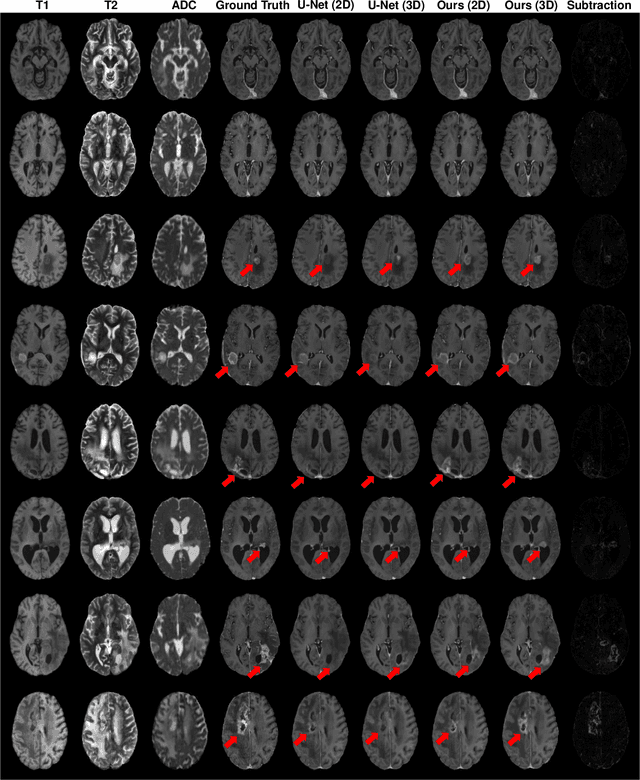
Gadolinium-based contrast agents (GBCAs) have been widely used to better visualize disease in brain magnetic resonance imaging (MRI). However, gadolinium deposition within the brain and body has raised safety concerns about the use of GBCAs. Therefore, the development of novel approaches that can decrease or even eliminate GBCA exposure while providing similar contrast information would be of significant use clinically. For brain tumor patients, standard-of-care includes repeated MRI with gadolinium-based contrast for disease monitoring, increasing the risk of gadolinium deposition. In this work, we present a deep learning based approach for contrast-enhanced T1 synthesis on brain tumor patients. A 3D high-resolution fully convolutional network (FCN), which maintains high resolution information through processing and aggregates multi-scale information in parallel, is designed to map pre-contrast MRI sequences to contrast-enhanced MRI sequences. Specifically, three pre-contrast MRI sequences, T1, T2 and apparent diffusion coefficient map (ADC), are utilized as inputs and the post-contrast T1 sequences are utilized as target output. To alleviate the data imbalance problem between normal tissues and the tumor regions, we introduce a local loss to improve the contribution of the tumor regions, which leads to better enhancement results on tumors. Extensive quantitative and visual assessments are performed, with our proposed model achieving a PSNR of 28.24dB in the brain and 21.2dB in tumor regions. Our results suggests the potential of substituting GBCAs with synthetic contrast images generated via deep learning.
Clear the Fog: Combat Value Assessment in Incomplete Information Games with Convolutional Encoder-Decoders
Nov 30, 2018StarCraft, one of the most popular real-time strategy games, is a compelling environment for artificial intelligence research for both micro-level unit control and macro-level strategic decision making. In this study, we address an eminent problem concerning macro-level decision making, known as the 'fog-of-war', which rises naturally from the fact that information regarding the opponent's state is always provided in the incomplete form. For intelligent agents to play like human players, it is obvious that making accurate predictions of the opponent's status under incomplete information will increase its chance of winning. To reflect this fact, we propose a convolutional encoder-decoder architecture that predicts potential counts and locations of the opponent's units based on only partially visible and noisy information. To evaluate the performance of our proposed method, we train an additional classifier on the encoder-decoder output to predict the game outcome (win or lose). Finally, we designed an agent incorporating the proposed method and conducted simulation games against rule-based agents to demonstrate both effectiveness and practicality. All experiments were conducted on actual game replay data acquired from professional players.
Task Transformer Network for Joint MRI Reconstruction and Super-Resolution
Jul 05, 2021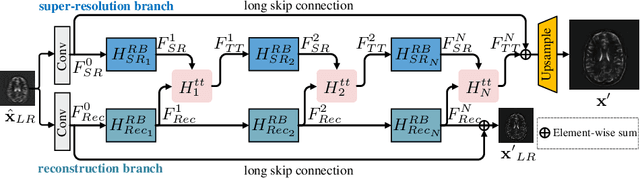
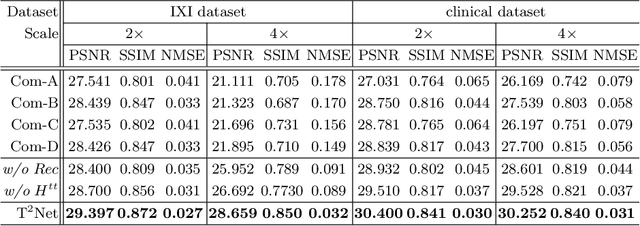
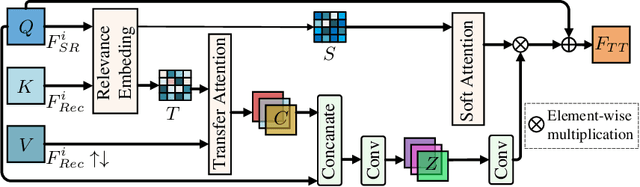
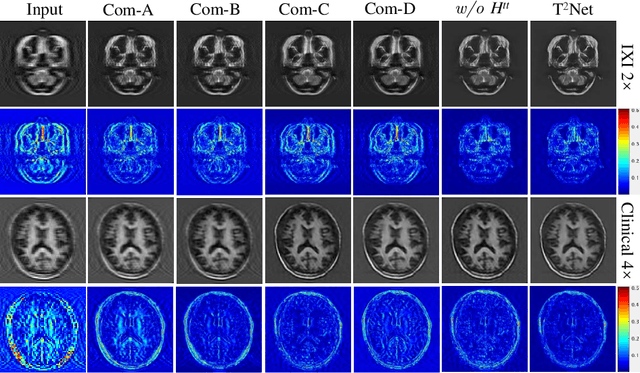
The core problem of Magnetic Resonance Imaging (MRI) is the trade off between acceleration and image quality. Image reconstruction and super-resolution are two crucial techniques in Magnetic Resonance Imaging (MRI). Current methods are designed to perform these tasks separately, ignoring the correlations between them. In this work, we propose an end-to-end task transformer network (T$^2$Net) for joint MRI reconstruction and super-resolution, which allows representations and feature transmission to be shared between multiple task to achieve higher-quality, super-resolved and motion-artifacts-free images from highly undersampled and degenerated MRI data. Our framework combines both reconstruction and super-resolution, divided into two sub-branches, whose features are expressed as queries and keys. Specifically, we encourage joint feature learning between the two tasks, thereby transferring accurate task information. We first use two separate CNN branches to extract task-specific features. Then, a task transformer module is designed to embed and synthesize the relevance between the two tasks. Experimental results show that our multi-task model significantly outperforms advanced sequential methods, both quantitatively and qualitatively.
From Independent Prediction to Re-ordered Prediction: Integrating Relative Position and Global Label Information to Emotion Cause Identification
Jun 04, 2019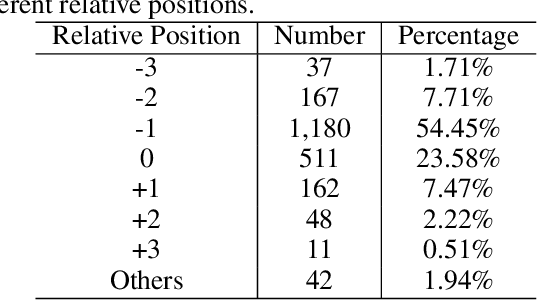
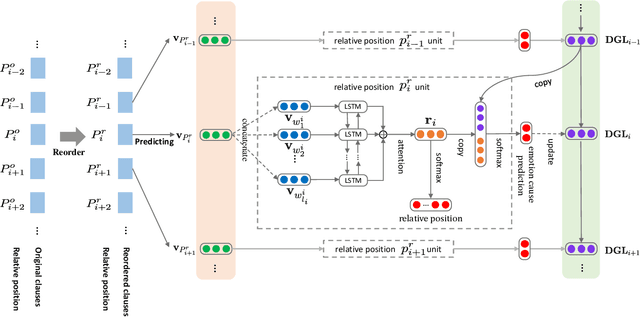

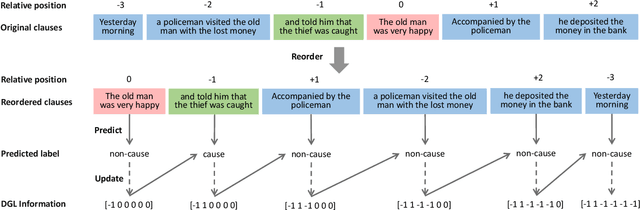
Emotion cause identification aims at identifying the potential causes that lead to a certain emotion expression in text. Several techniques including rule based methods and traditional machine learning methods have been proposed to address this problem based on manually designed rules and features. More recently, some deep learning methods have also been applied to this task, with the attempt to automatically capture the causal relationship of emotion and its causes embodied in the text. In this work, we find that in addition to the content of the text, there are another two kinds of information, namely relative position and global labels, that are also very important for emotion cause identification. To integrate such information, we propose a model based on the neural network architecture to encode the three elements ($i.e.$, text content, relative position and global label), in an unified and end-to-end fashion. We introduce a relative position augmented embedding learning algorithm, and transform the task from an independent prediction problem to a reordered prediction problem, where the dynamic global label information is incorporated. Experimental results on a benchmark emotion cause dataset show that our model achieves new state-of-the-art performance and performs significantly better than a number of competitive baselines. Further analysis shows the effectiveness of the relative position augmented embedding learning algorithm and the reordered prediction mechanism with dynamic global labels.
A CNN-based Prediction-Aware Quality Enhancement Framework for VVC
May 12, 2021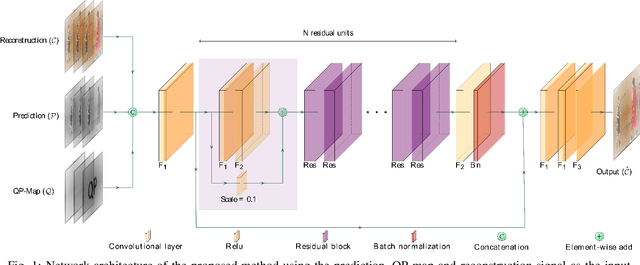
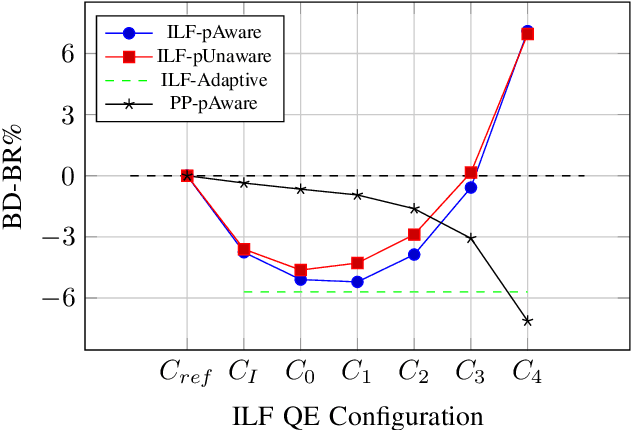
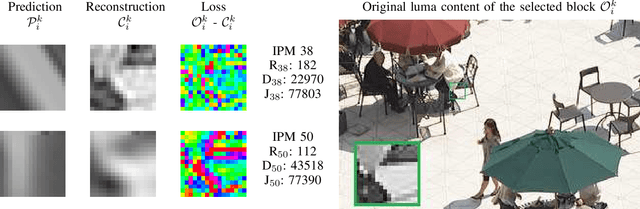
This paper presents a framework for Convolutional Neural Network (CNN)-based quality enhancement task, by taking advantage of coding information in the compressed video signal. The motivation is that normative decisions made by the encoder can significantly impact the type and strength of artifacts in the decoded images. In this paper, the main focus has been put on decisions defining the prediction signal in intra and inter frames. This information has been used in the training phase as well as input to help the process of learning artifacts that are specific to each coding type. Furthermore, to retain a low memory requirement for the proposed method, one model is used for all Quantization Parameters (QPs) with a QP-map, which is also shared between luma and chroma components. In addition to the Post Processing (PP) approach, the In-Loop Filtering (ILF) codec integration has also been considered, where the characteristics of the Group of Pictures (GoP) are taken into account to boost the performance. The proposed CNN-based Quality Enhancement(QE) framework has been implemented on top of the VVC Test Model (VTM-10). Experiments show that the prediction-aware aspect of the proposed method improves the coding efficiency gain of the default CNN-based QE method by 1.52%, in terms of BD-BR, at the same network complexity compared to the default CNN-based QE filter.