 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Task Transformer Network for Joint MRI Reconstruction and Super-Resolution
Jul 05, 2021
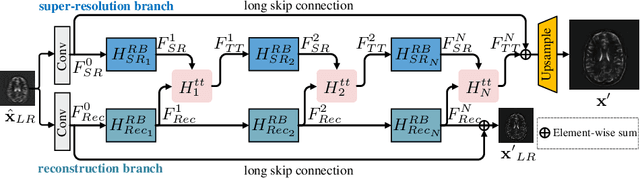
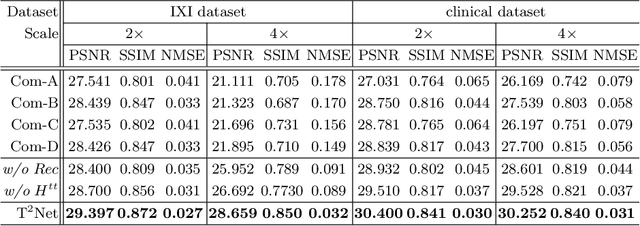
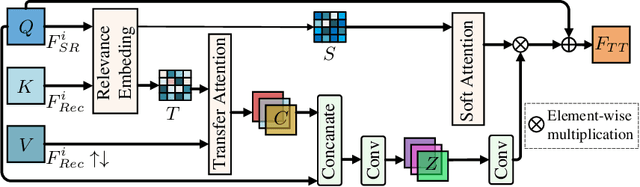
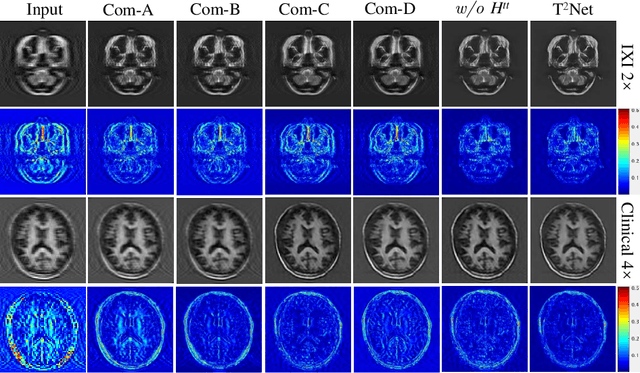
The core problem of Magnetic Resonance Imaging (MRI) is the trade off between acceleration and image quality. Image reconstruction and super-resolution are two crucial techniques in Magnetic Resonance Imaging (MRI). Current methods are designed to perform these tasks separately, ignoring the correlations between them. In this work, we propose an end-to-end task transformer network (T$^2$Net) for joint MRI reconstruction and super-resolution, which allows representations and feature transmission to be shared between multiple task to achieve higher-quality, super-resolved and motion-artifacts-free images from highly undersampled and degenerated MRI data. Our framework combines both reconstruction and super-resolution, divided into two sub-branches, whose features are expressed as queries and keys. Specifically, we encourage joint feature learning between the two tasks, thereby transferring accurate task information. We first use two separate CNN branches to extract task-specific features. Then, a task transformer module is designed to embed and synthesize the relevance between the two tasks. Experimental results show that our multi-task model significantly outperforms advanced sequential methods, both quantitatively and qualitatively.
Medical Code Prediction from Discharge Summary: Document to Sequence BERT using Sequence Attention
Jun 28, 2021
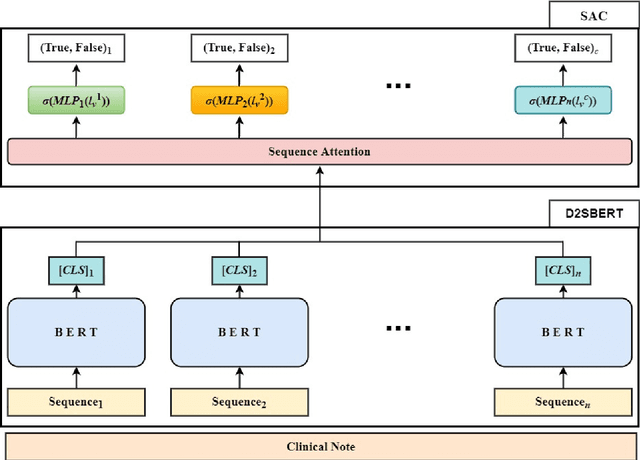

Clinical notes are unstructured text generated by clinicians during patient encounters. Clinical notes are usually accompanied by a set of metadata codes from the international classification of diseases (ICD). ICD code is an important code used in a variety of operations, including insurance, reimbursement, medical diagnosis, etc. Therefore, it is important to classify ICD codes quickly and accurately. However, annotating these codes is costly and time-consuming. So we propose a model based on bidirectional encoder representations from transformer (BERT) using the sequence attention method for automatic ICD code assignment. We evaluate our ap-proach on the MIMIC-III benchmark dataset. Our model achieved performance of Macro-aver-aged F1: 0.62898 and Micro-averaged F1: 0.68555, and is performing better than a performance of the previous state-of-the-art model. The contribution of this study proposes a method of using BERT that can be applied to documents and a sequence attention method that can capture im-portant sequence information appearing in documents.
Optimizing the Long-Term Average Reward for Continuing MDPs: A Technical Report
Apr 14, 2021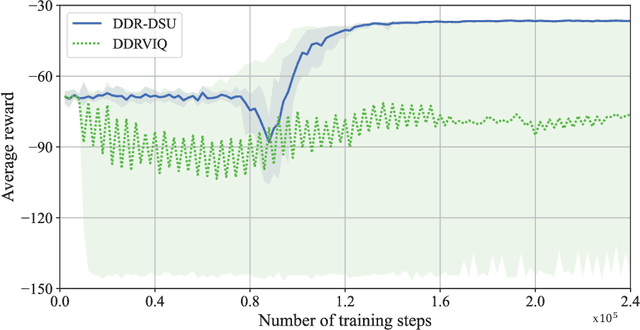
Recently, we have struck the balance between the information freshness, in terms of age of information (AoI), experienced by users and energy consumed by sensors, by appropriately activating sensors to update their current status in caching enabled Internet of Things (IoT) networks [1]. To solve this problem, we cast the corresponding status update procedure as a continuing Markov Decision Process (MDP) (i.e., without termination states), where the number of state-action pairs increases exponentially with respect to the number of considered sensors and users. Moreover, to circumvent the curse of dimensionality, we have established a methodology for designing deep reinforcement learning (DRL) algorithms to maximize (resp. minimize) the average reward (resp. cost), by integrating R-learning, a tabular reinforcement learning (RL) algorithm tailored for maximizing the long-term average reward, and traditional DRL algorithms, initially developed to optimize the discounted long-term cumulative reward rather than the average one. In this technical report, we would present detailed discussions on the technical contributions of this methodology.
End-to-end Multi-modal Video Temporal Grounding
Jul 12, 2021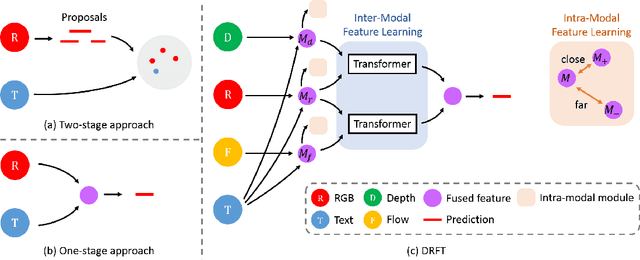

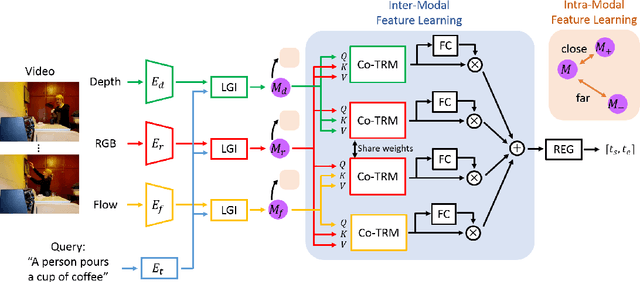
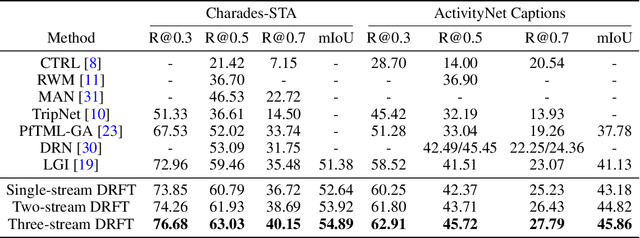
We address the problem of text-guided video temporal grounding, which aims to identify the time interval of certain event based on a natural language description. Different from most existing methods that only consider RGB images as visual features, we propose a multi-modal framework to extract complementary information from videos. Specifically, we adopt RGB images for appearance, optical flow for motion, and depth maps for image structure. While RGB images provide abundant visual cues of certain event, the performance may be affected by background clutters. Therefore, we use optical flow to focus on large motion and depth maps to infer the scene configuration when the action is related to objects recognizable with their shapes. To integrate the three modalities more effectively and enable inter-modal learning, we design a dynamic fusion scheme with transformers to model the interactions between modalities. Furthermore, we apply intra-modal self-supervised learning to enhance feature representations across videos for each modality, which also facilitates multi-modal learning. We conduct extensive experiments on the Charades-STA and ActivityNet Captions datasets, and show that the proposed method performs favorably against state-of-the-art approaches.
Emotions in Macroeconomic News and their Impact on the European Bond Market
Jun 15, 2021
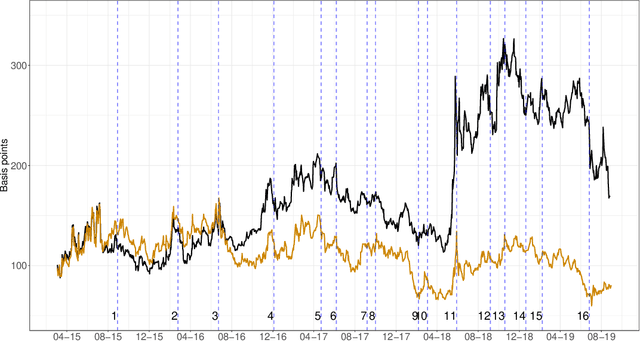
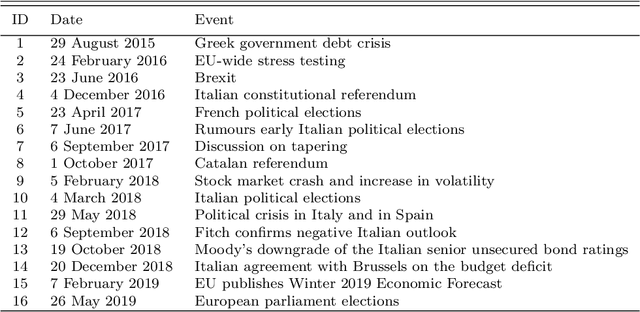
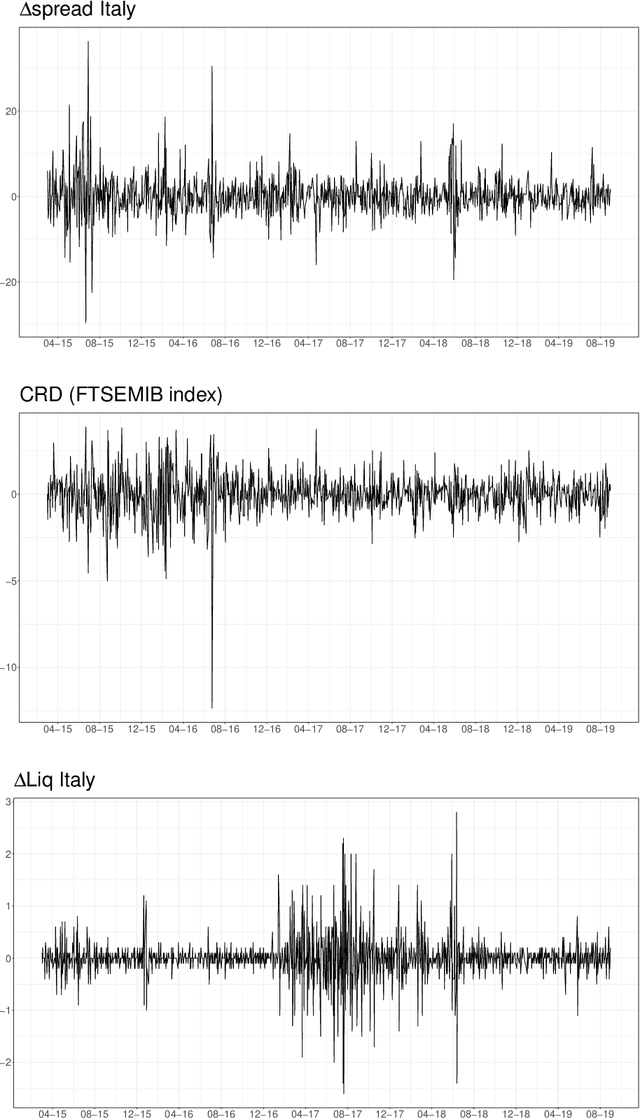
We show how emotions extracted from macroeconomic news can be used to explain and forecast future behaviour of sovereign bond yield spreads in Italy and Spain. We use a big, open-source, database known as Global Database of Events, Language and Tone to construct emotion indicators of bond market affective states. We find that negative emotions extracted from news improve the forecasting power of government yield spread models during distressed periods even after controlling for the number of negative words present in the text. In addition, stronger negative emotions, such as panic, reveal useful information for predicting changes in spread at the short-term horizon, while milder emotions, such as distress, are useful at longer time horizons. Emotions generated by the Italian political turmoil propagate to the Spanish news affecting this neighbourhood market.
Exploiting Heterogeneous Graph Neural Networks with Latent Worker/Task Correlation Information for Label Aggregation in Crowdsourcing
Oct 25, 2020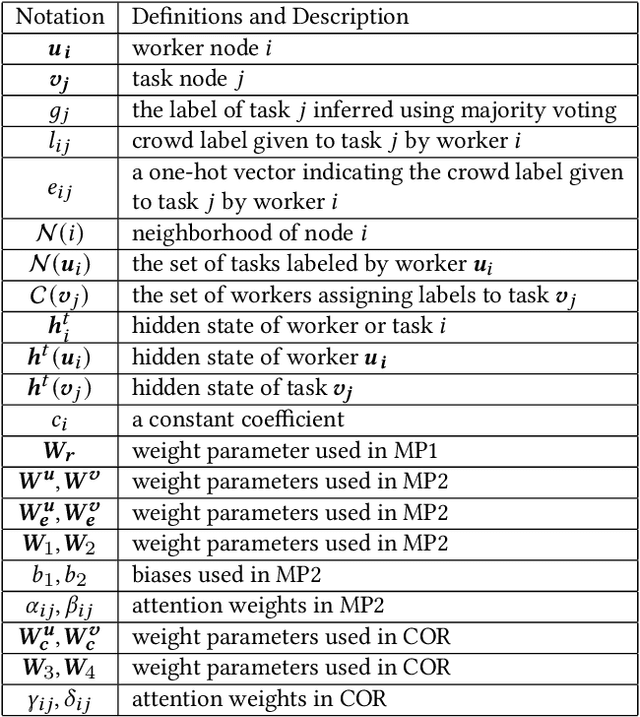

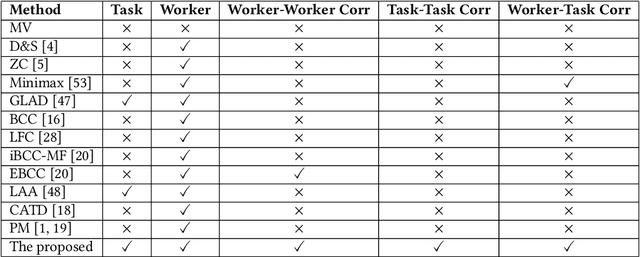
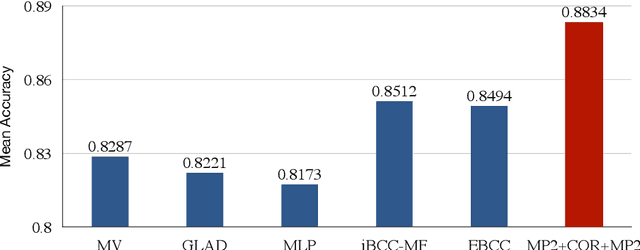
Crowdsourcing has attracted much attention for its convenience to collect labels from non-expert workers instead of experts. However, due to the high level of noise from the non-experts, an aggregation model that learns the true label by incorporating the source credibility is required. In this paper, we propose a novel framework based on graph neural networks for aggregating crowd labels. We construct a heterogeneous graph between workers and tasks and derive a new graph neural network to learn the representations of nodes and the true labels. Besides, we exploit the unknown latent interaction between the same type of nodes (workers or tasks) by adding a homogeneous attention layer in the graph neural networks. Experimental results on 13 real-world datasets show superior performance over state-of-the-art models.
Asynchrony Increases Efficiency: Time Encoding of Videos and Low-Rank Signals
Apr 29, 2021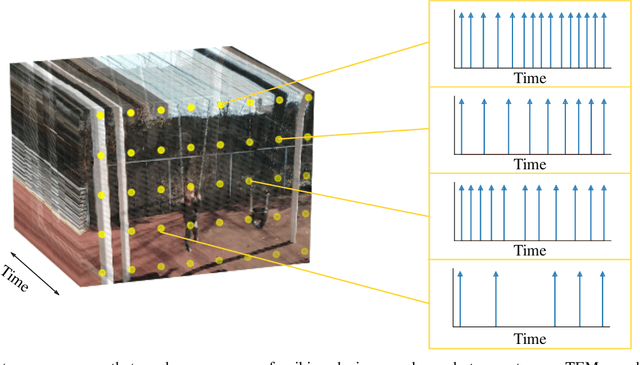
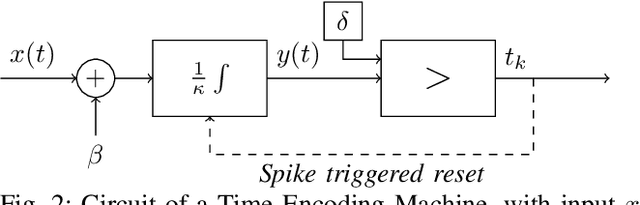
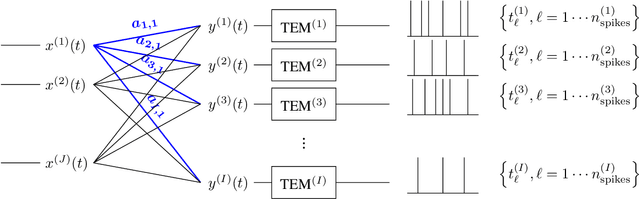
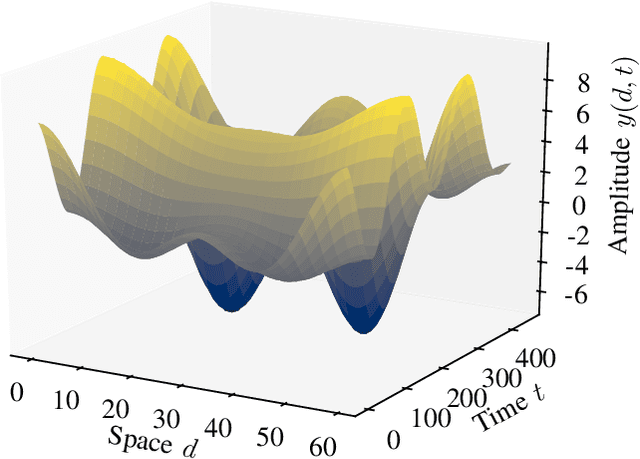
In event-based sensing, many sensors independently and asynchronously emit events when there is a change in their input. Event-based sensing can present significant improvements in power efficiency when compared to traditional sampling, because (1) the output is a stream of events where the important information lies in the timing of the events, and (2) the sensor can easily be controlled to output information only when interesting activity occurs at the input. Moreover, event-based sampling can often provide better resolution than standard uniform sampling. Not only does this occur because individual event-based sensors have higher temporal resolution, it also occurs because the asynchrony of events allows for less redundant and more informative encoding. We would like to explain how such curious results come about. To do so, we use ideal time encoding machines as a proxy for event-based sensors. We explore time encoding of signals with low rank structure, and apply the resulting theory to video. We then see how the asynchronous firing times of the time encoding machines allow for better reconstruction than in the standard sampling case, if we have a high spatial density of time encoding machines that fire less frequently.
End-to-End Learning of Keypoint Representations for Continuous Control from Images
Jun 15, 2021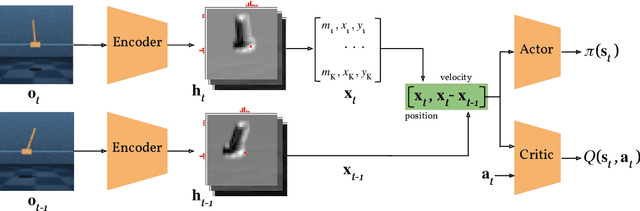
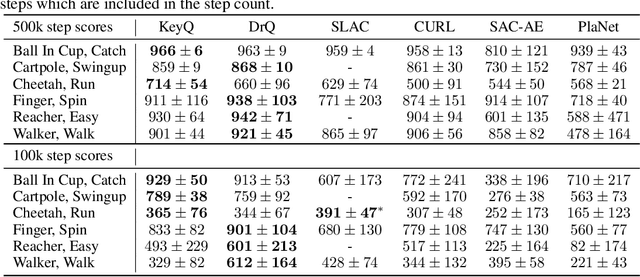


In many control problems that include vision, optimal controls can be inferred from the location of the objects in the scene. This information can be represented using keypoints, which is a list of spatial locations in the input image. Previous works show that keypoint representations learned during unsupervised pre-training using encoder-decoder architectures can provide good features for control tasks. In this paper, we show that it is possible to learn efficient keypoint representations end-to-end, without the need for unsupervised pre-training, decoders, or additional losses. Our proposed architecture consists of a differentiable keypoint extractor that feeds the coordinates of the estimated keypoints directly to a soft actor-critic agent. The proposed algorithm yields performance competitive to the state-of-the art on DeepMind Control Suite tasks.
A data-driven personalized smart lighting recommender system
Apr 05, 2021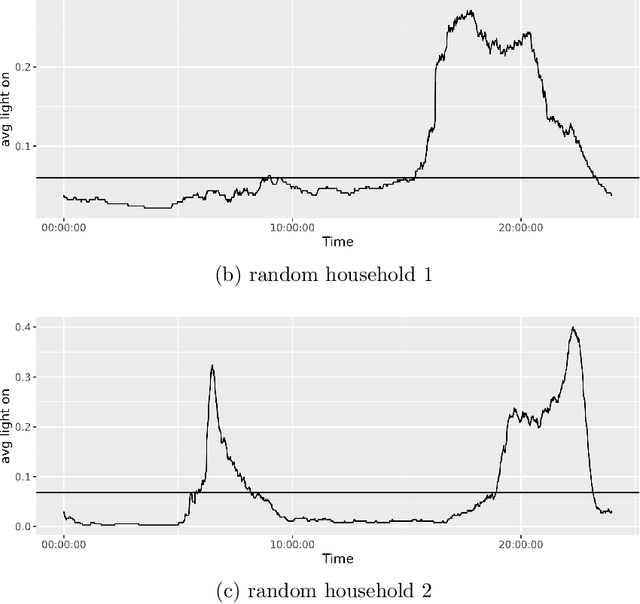
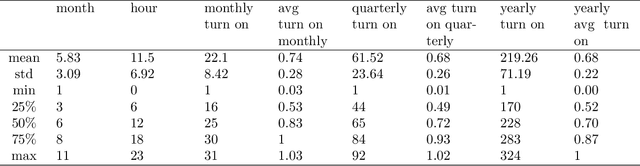
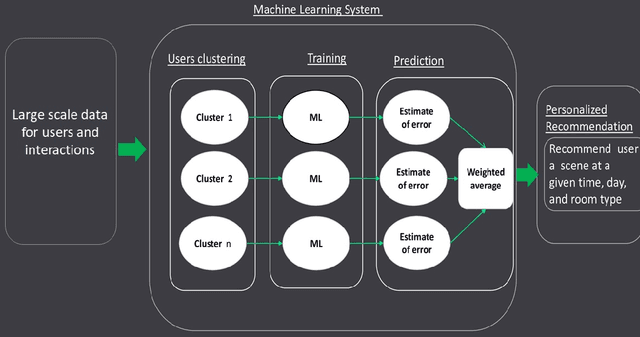
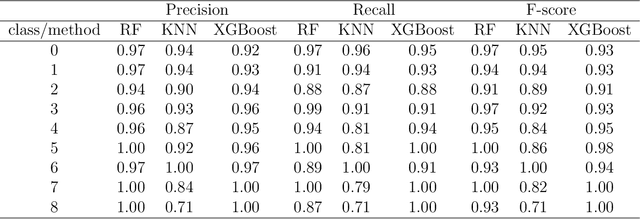
Recommender systems attempts to identify and recommend the most preferable item (product-service) to an individual user. These systems predict user interest in items based on related items, users, and the interactions between items and users. We aim to build an auto-routine and color scheme recommender system that leverages a wealth of historical data and machine learning methods. We introduce an unsupervised method to recommend a routine for lighting. Moreover, by analyzing users' daily logs, geographical location, temporal and usage information we understand user preference and predict their preferred color for lights. To do so, we cluster users based on their geographical information and usage distribution. We then build and train a predictive model within each cluster and aggregate the results. Results indicate that models based on similar users increases the prediction accuracy, with and without prior knowledge about user preferences.
Feature learning for efficient ASR-free keyword spotting in low-resource languages
Aug 13, 2021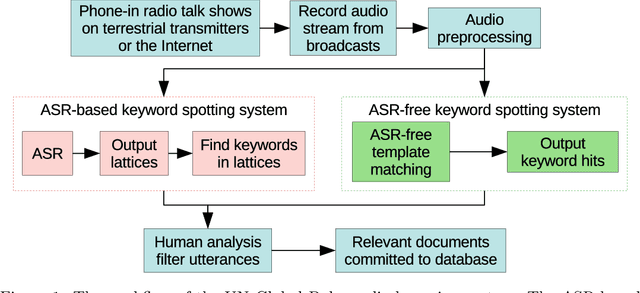
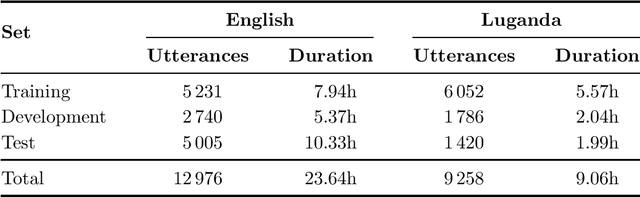

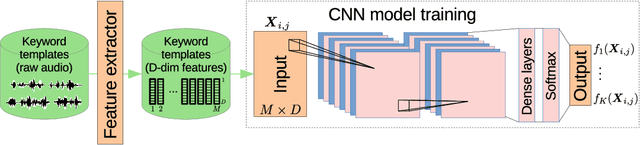
We consider feature learning for efficient keyword spotting that can be applied in severely under-resourced settings. The objective is to support humanitarian relief programmes by the United Nations in parts of Africa in which almost no language resources are available. For rapid development in such languages, we rely on a small, easily-compiled set of isolated keywords. These keyword templates are applied to a large corpus of in-domain but untranscribed speech using dynamic time warping (DTW). The resulting DTW alignment scores are used to train a convolutional neural network (CNN) which is orders of magnitude more computationally efficient and suitable for real-time application. We optimise this neural network keyword spotter by identifying robust acoustic features in this almost zero-resource setting. First, we incorporate information from well-resourced but unrelated languages using a multilingual bottleneck feature (BNF) extractor. Next, we consider features extracted from an autoencoder (AE) trained on in-domain but untranscribed data. Finally, we consider correspondence autoencoder (CAE) features which are fine-tuned on the small set of in-domain labelled data. Experiments in South African English and Luganda, a low-resource language, show that BNF and CAE features achieve a 5% relative performance improvement over baseline MFCCs. However, using BNFs as input to the CAE results in a more than 27% relative improvement over MFCCs in ROC area-under-the-curve (AUC) and more than twice as many top-10 retrievals. We show that, using these features, the CNN-DTW keyword spotter performs almost as well as the DTW keyword spotter while outperforming a baseline CNN trained only on the keyword templates. The CNN-DTW keyword spotter using BNF-derived CAE features represents an efficient approach with competitive performance suited to rapid deployment in a severely under-resourced scenario.