 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Overview of BioASQ 2020: The eighth BioASQ challenge on Large-Scale Biomedical Semantic Indexing and Question Answering
Jun 28, 2021
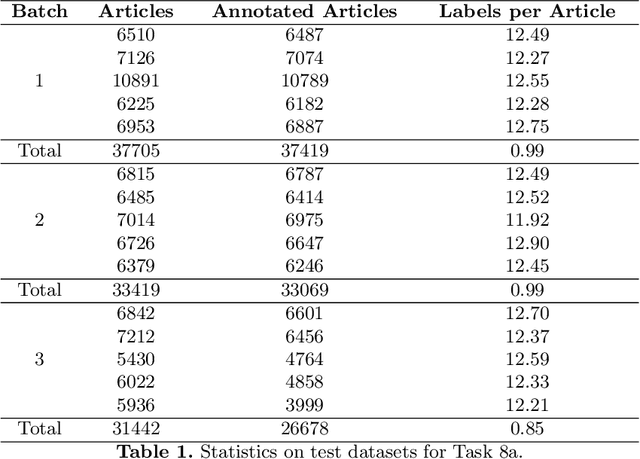

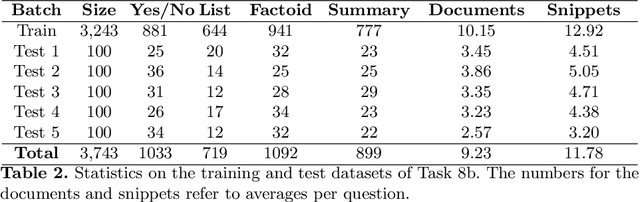
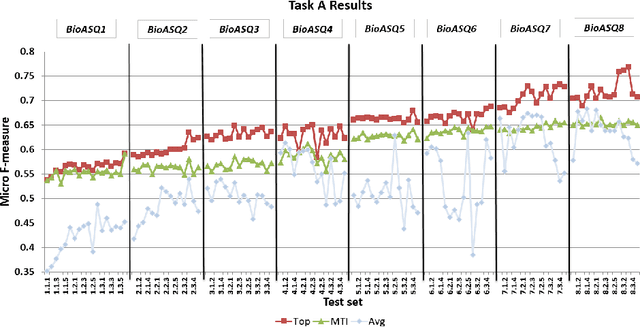
In this paper, we present an overview of the eighth edition of the BioASQ challenge, which ran as a lab in the Conference and Labs of the Evaluation Forum (CLEF) 2020. BioASQ is a series of challenges aiming at the promotion of systems and methodologies for large-scale biomedical semantic indexing and question answering. To this end, shared tasks are organized yearly since 2012, where different teams develop systems that compete on the same demanding benchmark datasets that represent the real information needs of experts in the biomedical domain. This year, the challenge has been extended with the introduction of a new task on medical semantic indexing in Spanish. In total, 34 teams with more than 100 systems participated in the three tasks of the challenge. As in previous years, the results of the evaluation reveal that the top-performing systems managed to outperform the strong baselines, which suggests that state-of-the-art systems keep pushing the frontier of research through continuous improvements.
* 21 pages, 10 tables, 3 figures
RockGPT: Reconstructing three-dimensional digital rocks from single two-dimensional slice from the perspective of video generation
Aug 05, 2021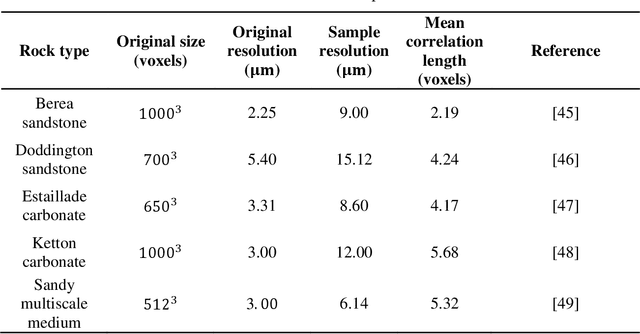
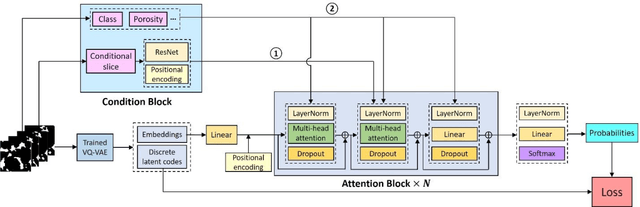

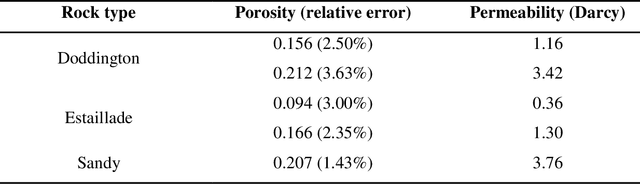
Random reconstruction of three-dimensional (3D) digital rocks from two-dimensional (2D) slices is crucial for elucidating the microstructure of rocks and its effects on pore-scale flow in terms of numerical modeling, since massive samples are usually required to handle intrinsic uncertainties. Despite remarkable advances achieved by traditional process-based methods, statistical approaches and recently famous deep learning-based models, few works have focused on producing several kinds of rocks with one trained model and allowing the reconstructed samples to satisfy certain given properties, such as porosity. To fill this gap, we propose a new framework, named RockGPT, which is composed of VQ-VAE and conditional GPT, to synthesize 3D samples based on a single 2D slice from the perspective of video generation. The VQ-VAE is utilized to compress high-dimensional input video, i.e., the sequence of continuous rock slices, to discrete latent codes and reconstruct them. In order to obtain diverse reconstructions, the discrete latent codes are modeled using conditional GPT in an autoregressive manner, while incorporating conditional information from a given slice, rock type, and porosity. We conduct two experiments on five kinds of rocks, and the results demonstrate that RockGPT can produce different kinds of rocks with the same model, and the reconstructed samples can successfully meet certain specified porosities. In a broader sense, through leveraging the proposed conditioning scheme, RockGPT constitutes an effective way to build a general model to produce multiple kinds of rocks simultaneously that also satisfy user-defined properties.
Channel-wise Gated Res2Net: Towards Robust Detection of Synthetic Speech Attacks
Jul 19, 2021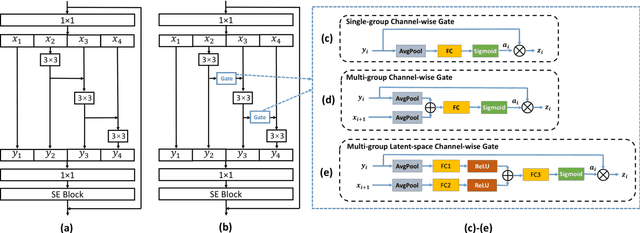
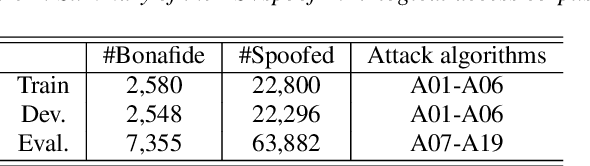
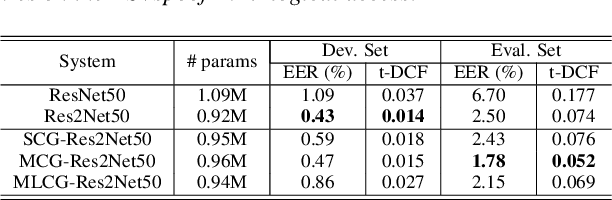
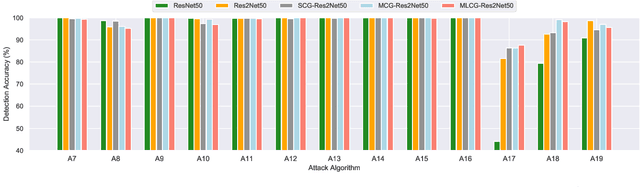
Existing approaches for anti-spoofing in automatic speaker verification (ASV) still lack generalizability to unseen attacks. The Res2Net approach designs a residual-like connection between feature groups within one block, which increases the possible receptive fields and improves the system's detection generalizability. However, such a residual-like connection is performed by a direct addition between feature groups without channel-wise priority. We argue that the information across channels may not contribute to spoofing cues equally, and the less relevant channels are expected to be suppressed before adding onto the next feature group, so that the system can generalize better to unseen attacks. This argument motivates the current work that presents a novel, channel-wise gated Res2Net (CG-Res2Net), which modifies Res2Net to enable a channel-wise gating mechanism in the connection between feature groups. This gating mechanism dynamically selects channel-wise features based on the input, to suppress the less relevant channels and enhance the detection generalizability. Three gating mechanisms with different structures are proposed and integrated into Res2Net. Experimental results conducted on ASVspoof 2019 logical access (LA) demonstrate that the proposed CG-Res2Net significantly outperforms Res2Net on both the overall LA evaluation set and individual difficult unseen attacks, which also outperforms other state-of-the-art single systems, depicting the effectiveness of our method.
SSMix: Saliency-Based Span Mixup for Text Classification
Jun 15, 2021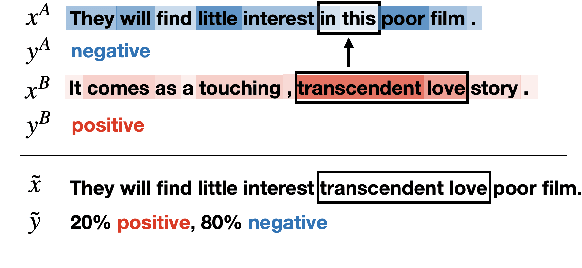
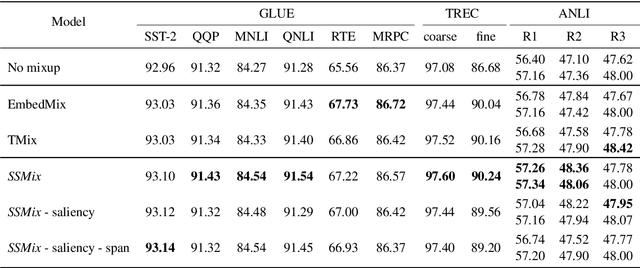
Data augmentation with mixup has shown to be effective on various computer vision tasks. Despite its great success, there has been a hurdle to apply mixup to NLP tasks since text consists of discrete tokens with variable length. In this work, we propose SSMix, a novel mixup method where the operation is performed on input text rather than on hidden vectors like previous approaches. SSMix synthesizes a sentence while preserving the locality of two original texts by span-based mixing and keeping more tokens related to the prediction relying on saliency information. With extensive experiments, we empirically validate that our method outperforms hidden-level mixup methods on a wide range of text classification benchmarks, including textual entailment, sentiment classification, and question-type classification. Our code is available at https://github.com/clovaai/ssmix.
Artificial Intelligence and Asymmetric Information Theory
Oct 14, 2015When human agents come together to make decisions, it is often the case that one human agent has more information than the other. This phenomenon is called information asymmetry and this distorts the market. Often if one human agent intends to manipulate a decision in its favor the human agent can signal wrong or right information. Alternatively, one human agent can screen for information to reduce the impact of asymmetric information on decisions. With the advent of artificial intelligence, signaling and screening have been made easier. This paper studies the impact of artificial intelligence on the theory of asymmetric information. It is surmised that artificial intelligent agents reduce the degree of information asymmetry and thus the market where these agents are deployed become more efficient. It is also postulated that the more artificial intelligent agents there are deployed in the market the less is the volume of trades in the market. This is because for many trades to happen the asymmetry of information on goods and services to be traded should exist, creating a sense of arbitrage.
Recurrent neural network transducer for Japanese and Chinese offline handwritten text recognition
Jun 28, 2021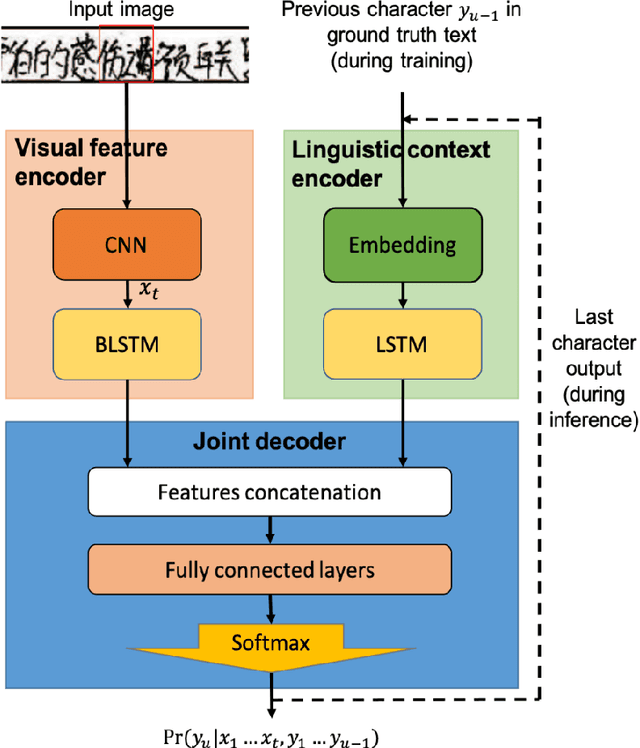


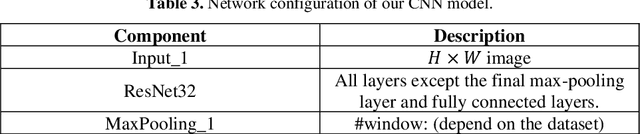
In this paper, we propose an RNN-Transducer model for recognizing Japanese and Chinese offline handwritten text line images. As far as we know, it is the first approach that adopts the RNN-Transducer model for offline handwritten text recognition. The proposed model consists of three main components: a visual feature encoder that extracts visual features from an input image by CNN and then encodes the visual features by BLSTM; a linguistic context encoder that extracts and encodes linguistic features from the input image by embedded layers and LSTM; and a joint decoder that combines and then decodes the visual features and the linguistic features into the final label sequence by fully connected and softmax layers. The proposed model takes advantage of both visual and linguistic information from the input image. In the experiments, we evaluated the performance of the proposed model on the two datasets: Kuzushiji and SCUT-EPT. Experimental results show that the proposed model achieves state-of-the-art performance on all datasets.
Emotions in Macroeconomic News and their Impact on the European Bond Market
Jun 15, 2021
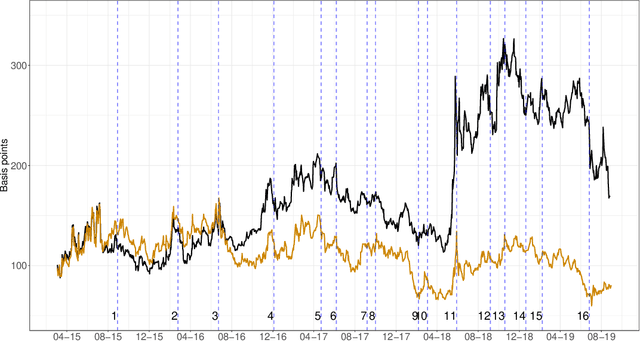
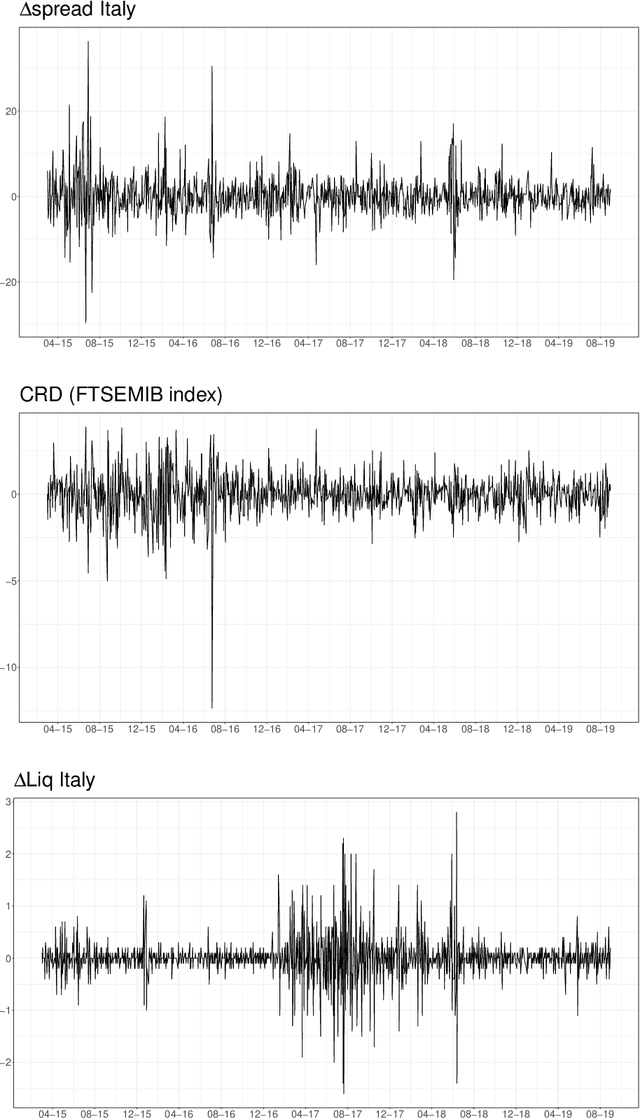
We show how emotions extracted from macroeconomic news can be used to explain and forecast future behaviour of sovereign bond yield spreads in Italy and Spain. We use a big, open-source, database known as Global Database of Events, Language and Tone to construct emotion indicators of bond market affective states. We find that negative emotions extracted from news improve the forecasting power of government yield spread models during distressed periods even after controlling for the number of negative words present in the text. In addition, stronger negative emotions, such as panic, reveal useful information for predicting changes in spread at the short-term horizon, while milder emotions, such as distress, are useful at longer time horizons. Emotions generated by the Italian political turmoil propagate to the Spanish news affecting this neighbourhood market.
Patterns for Learning with Side Information
Feb 10, 2016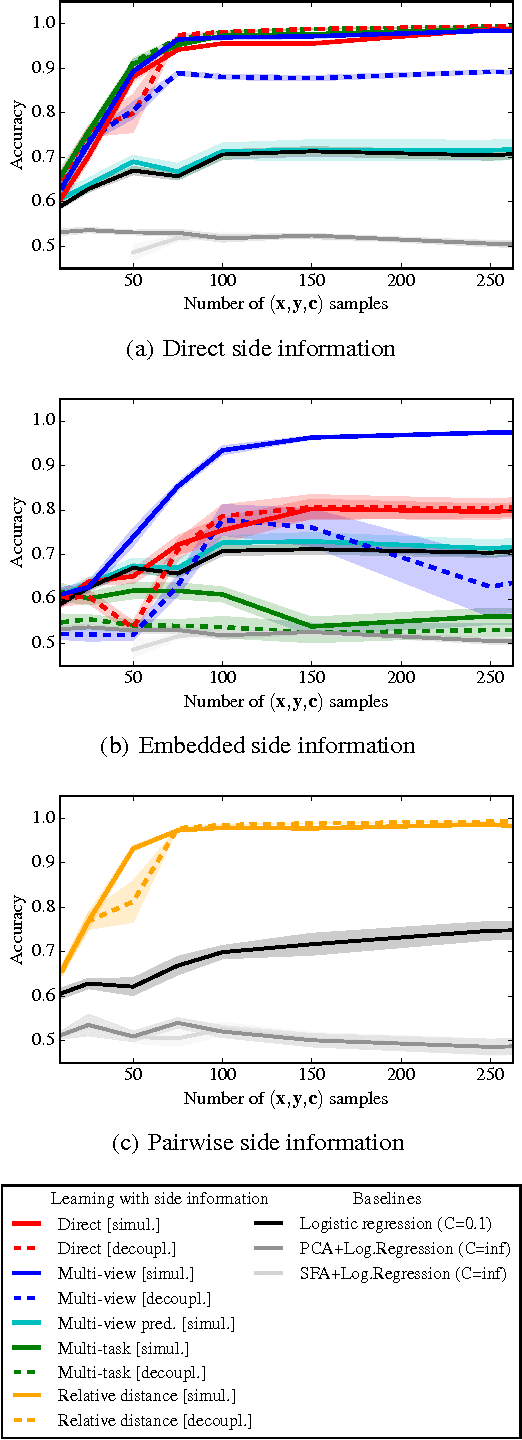

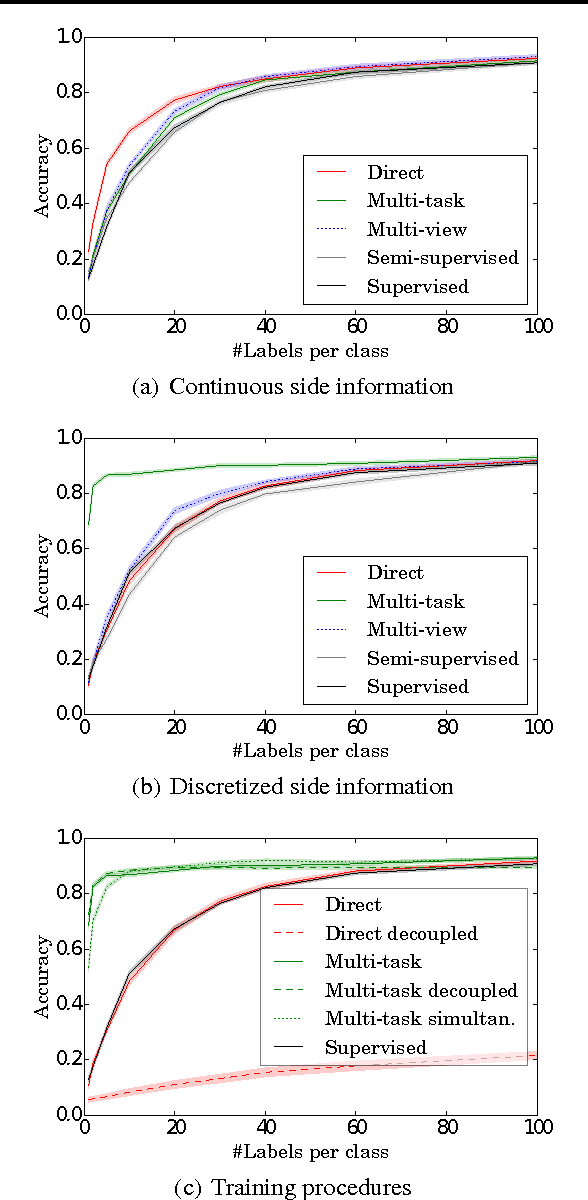
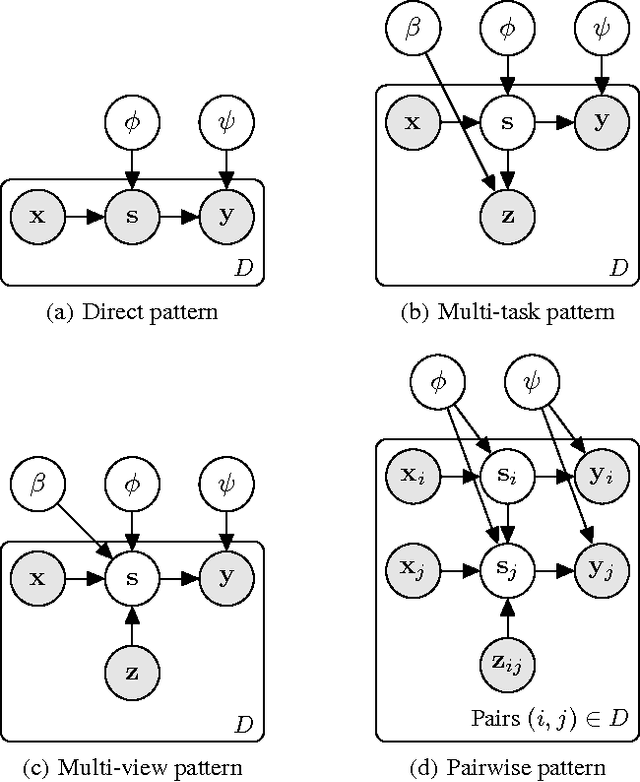
Supervised, semi-supervised, and unsupervised learning estimate a function given input/output samples. Generalization of the learned function to unseen data can be improved by incorporating side information into learning. Side information are data that are neither from the input space nor from the output space of the function, but include useful information for learning it. In this paper we show that learning with side information subsumes a variety of related approaches, e.g. multi-task learning, multi-view learning and learning using privileged information. Our main contributions are (i) a new perspective that connects these previously isolated approaches, (ii) insights about how these methods incorporate different types of prior knowledge, and hence implement different patterns, (iii) facilitating the application of these methods in novel tasks, as well as (iv) a systematic experimental evaluation of these patterns in two supervised learning tasks.
Analysis of GraphSum's Attention Weights to Improve the Explainability of Multi-Document Summarization
May 19, 2021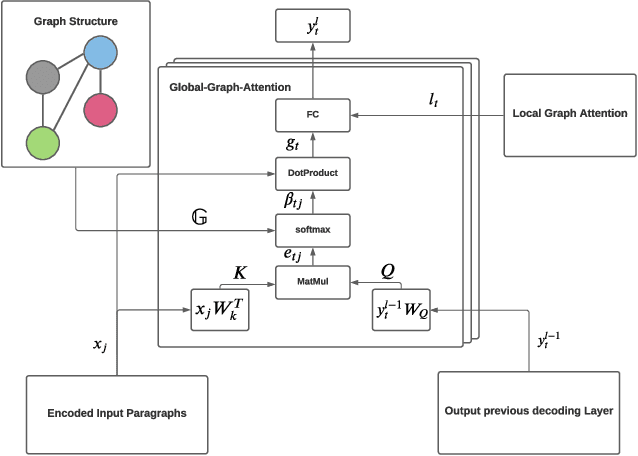
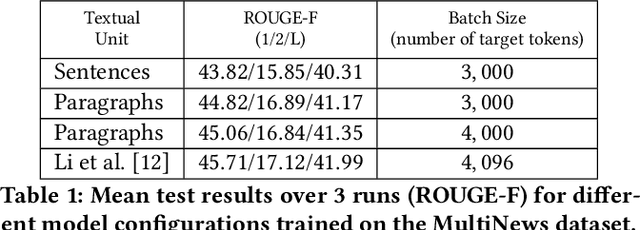
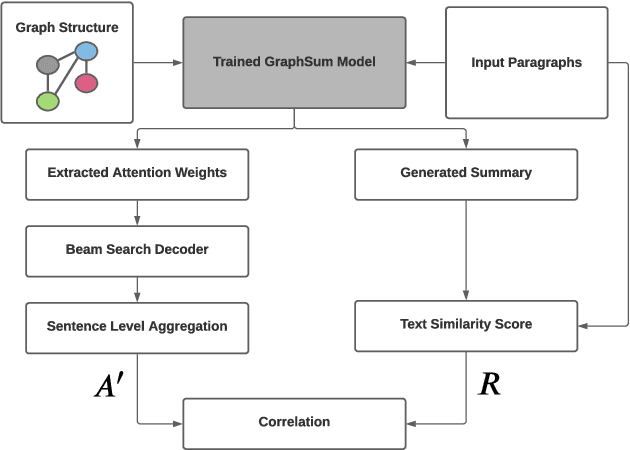
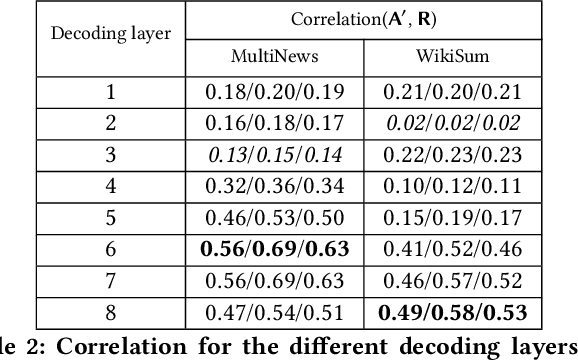
Modern multi-document summarization (MDS) methods are based on transformer architectures. They generate state of the art summaries, but lack explainability. We focus on graph-based transformer models for MDS as they gained recent popularity. We aim to improve the explainability of the graph-based MDS by analyzing their attention weights. In a graph-based MDS such as GraphSum, vertices represent the textual units, while the edges form some similarity graph over the units. We compare GraphSum's performance utilizing different textual units, i. e., sentences versus paragraphs, on two news benchmark datasets, namely WikiSum and MultiNews. Our experiments show that paragraph-level representations provide the best summarization performance. Thus, we subsequently focus oAnalysisn analyzing the paragraph-level attention weights of GraphSum's multi-heads and decoding layers in order to improve the explainability of a transformer-based MDS model. As a reference metric, we calculate the ROUGE scores between the input paragraphs and each sentence in the generated summary, which indicate source origin information via text similarity. We observe a high correlation between the attention weights and this reference metric, especially on the the later decoding layers of the transformer architecture. Finally, we investigate if the generated summaries follow a pattern of positional bias by extracting which paragraph provided the most information for each generated summary. Our results show that there is a high correlation between the position in the summary and the source origin.
LightFuse: Lightweight CNN based Dual-exposure Fusion
Jul 05, 2021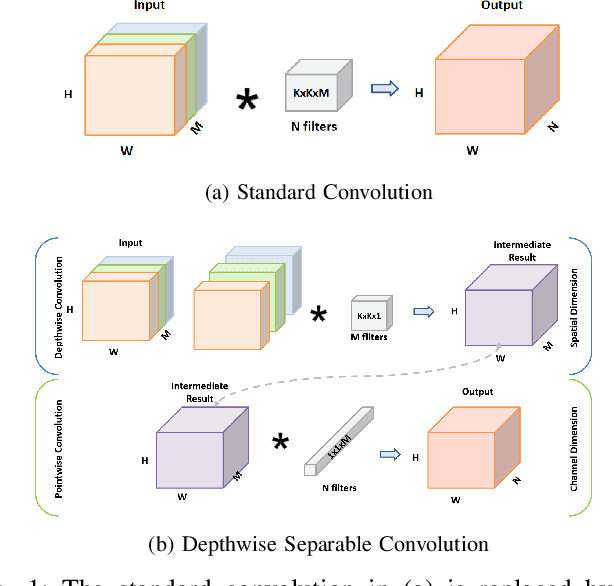
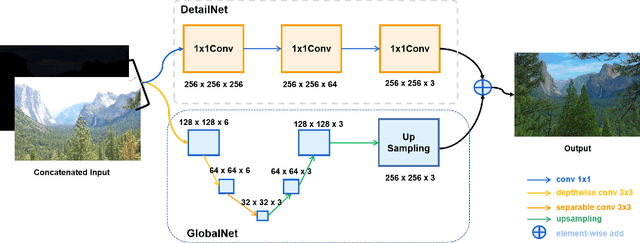


Deep convolutional neural networks (DCNN) aided high dynamic range (HDR) imaging recently received a lot of attention. The quality of DCNN generated HDR images have overperformed the traditional counterparts. However, DCNN is prone to be computationally intensive and power-hungry. To address the challenge, we propose LightFuse, a light-weight CNN-based algorithm for extreme dual-exposure image fusion, which can be implemented on various embedded computing platforms with limited power and hardware resources. Two sub-networks are utilized: a GlobalNet (G) and a DetailNet (D). The goal of G is to learn the global illumination information on the spatial dimension, whereas D aims to enhance local details on the channel dimension. Both G and D are based solely on depthwise convolution (D Conv) and pointwise convolution (P Conv) to reduce required parameters and computations. Experimental results display that the proposed technique could generate HDR images with plausible details in extremely exposed regions. Our PSNR score exceeds the other state-of-the-art approaches by 1.2 to 1.6 times and achieves 1.4 to 20 times FLOP and parameter reduction compared with others.