 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Predicting the Future from First Person (Egocentric) Vision: A Survey
Jul 28, 2021

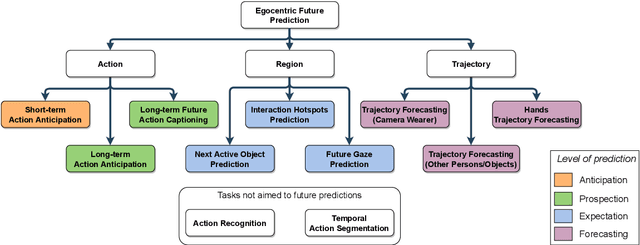
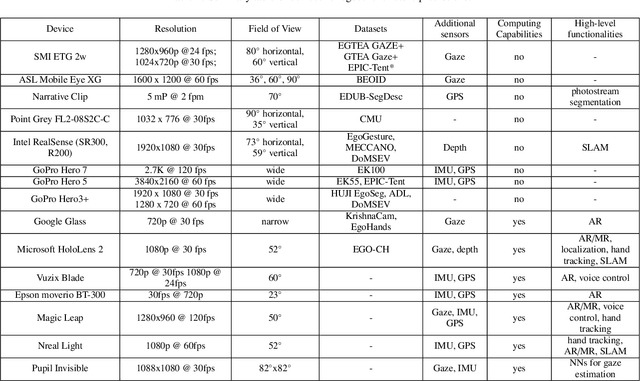
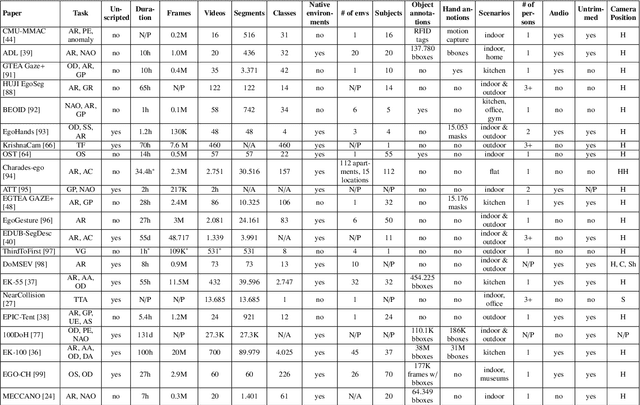
Egocentric videos can bring a lot of information about how humans perceive the world and interact with the environment, which can be beneficial for the analysis of human behaviour. The research in egocentric video analysis is developing rapidly thanks to the increasing availability of wearable devices and the opportunities offered by new large-scale egocentric datasets. As computer vision techniques continue to develop at an increasing pace, the tasks related to the prediction of future are starting to evolve from the need of understanding the present. Predicting future human activities, trajectories and interactions with objects is crucial in applications such as human-robot interaction, assistive wearable technologies for both industrial and daily living scenarios, entertainment and virtual or augmented reality. This survey summarises the evolution of studies in the context of future prediction from egocentric vision making an overview of applications, devices, existing problems, commonly used datasets, models and input modalities. Our analysis highlights that methods for future prediction from egocentric vision can have a significant impact in a range of applications and that further research efforts should be devoted to the standardisation of tasks and the proposal of datasets considering real-world scenarios such as the ones with an industrial vocation.
Anarchic Federated Learning
Aug 23, 2021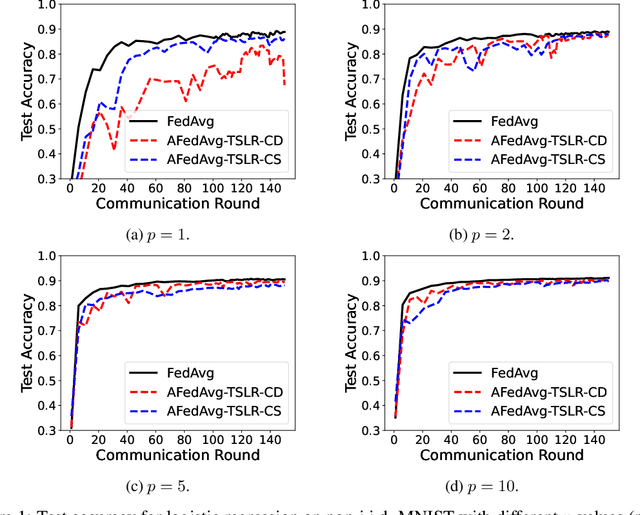

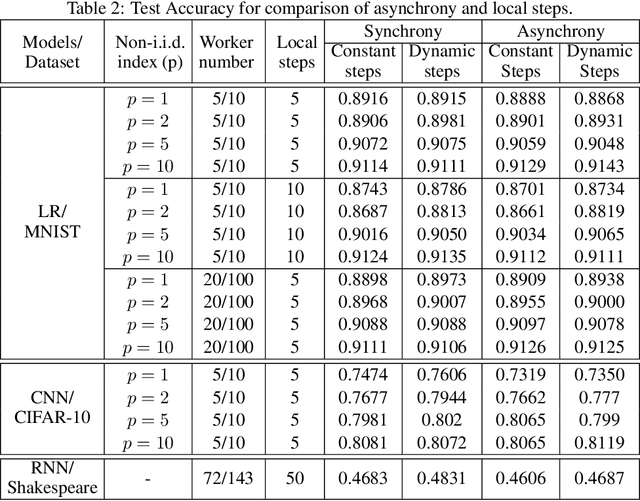
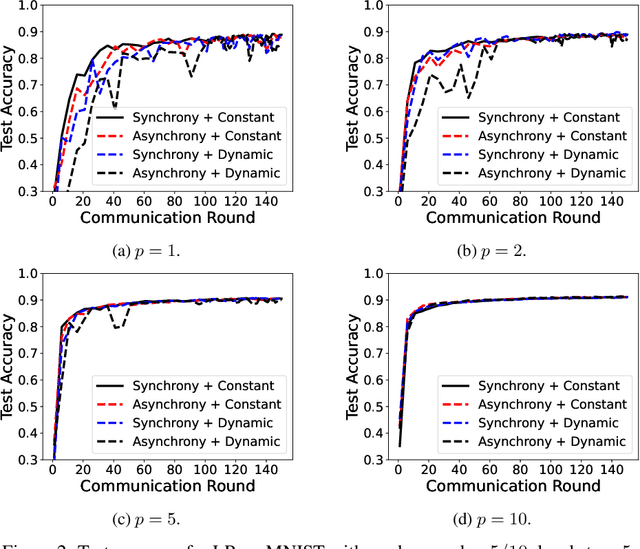
Present-day federated learning (FL) systems deployed over edge networks have to consistently deal with a large number of workers with high degrees of heterogeneity in data and/or computing capabilities. This diverse set of workers necessitates the development of FL algorithms that allow: (1) flexible worker participation that grants the workers' capability to engage in training at will, (2) varying number of local updates (based on computational resources) at each worker along with asynchronous communication with the server, and (3) heterogeneous data across workers. To address these challenges, in this work, we propose a new paradigm in FL called ``Anarchic Federated Learning'' (AFL). In stark contrast to conventional FL models, each worker in AFL has complete freedom to choose i) when to participate in FL, and ii) the number of local steps to perform in each round based on its current situation (e.g., battery level, communication channels, privacy concerns). However, AFL also introduces significant challenges in algorithmic design because the server needs to handle the chaotic worker behaviors. Toward this end, we propose two Anarchic FedAvg-like algorithms with two-sided learning rates for both cross-device and cross-silo settings, which are named AFedAvg-TSLR-CD and AFedAvg-TSLR-CS, respectively. For general worker information arrival processes, we show that both algorithms retain the highly desirable linear speedup effect in the new AFL paradigm. Moreover, we show that our AFedAvg-TSLR algorithmic framework can be viewed as a {\em meta-algorithm} for AFL in the sense that they can utilize advanced FL algorithms as worker- and/or server-side optimizers to achieve enhanced performance under AFL. We validate the proposed algorithms with extensive experiments on real-world datasets.
Unsupervised Learning of Fine Structure Generation for 3D Point Clouds by 2D Projection Matching
Aug 08, 2021



Learning to generate 3D point clouds without 3D supervision is an important but challenging problem. Current solutions leverage various differentiable renderers to project the generated 3D point clouds onto a 2D image plane, and train deep neural networks using the per-pixel difference with 2D ground truth images. However, these solutions are still struggling to fully recover fine structures of 3D shapes, such as thin tubes or planes. To resolve this issue, we propose an unsupervised approach for 3D point cloud generation with fine structures. Specifically, we cast 3D point cloud learning as a 2D projection matching problem. Rather than using entire 2D silhouette images as a regular pixel supervision, we introduce structure adaptive sampling to randomly sample 2D points within the silhouettes as an irregular point supervision, which alleviates the consistency issue of sampling from different view angles. Our method pushes the neural network to generate a 3D point cloud whose 2D projections match the irregular point supervision from different view angles. Our 2D projection matching approach enables the neural network to learn more accurate structure information than using the per-pixel difference, especially for fine and thin 3D structures. Our method can recover fine 3D structures from 2D silhouette images at different resolutions, and is robust to different sampling methods and point number in irregular point supervision. Our method outperforms others under widely used benchmarks. Our code, data and models are available at https://github.com/chenchao15/2D\_projection\_matching.
XFL: eXtreme Function Labeling
Jul 28, 2021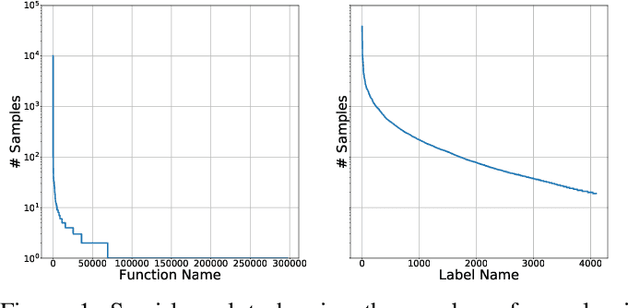
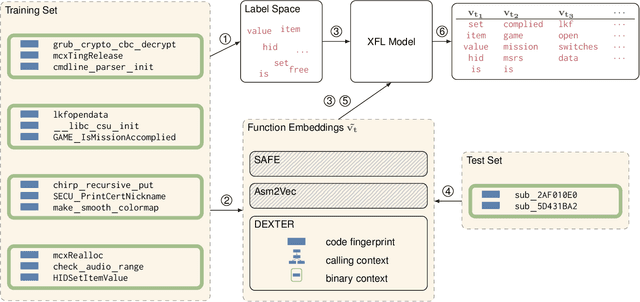
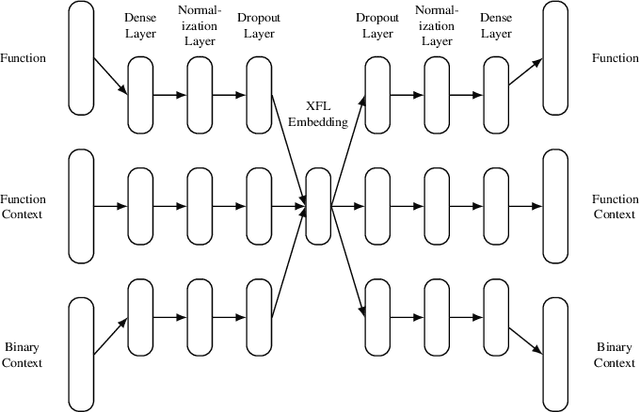
Reverse engineers would benefit from identifiers like function names, but these are usually unavailable in binaries. Training a machine learning model to predict function names automatically is promising but fundamentally hard due to the enormous number of classes. In this paper, we introduce eXtreme Function Labeling (XFL), an extreme multi-label learning approach to selecting appropriate labels for binary functions. XFL splits function names into tokens, treating each as an informative label akin to the problem of tagging texts in natural language. To capture the semantics of binary code, we introduce DEXTER, a novel function embedding that combines static analysis-based features with local context from the call graph and global context from the entire binary. We demonstrate that XFL outperforms state-of-the-art approaches to function labeling on a dataset of over 10,000 binaries from the Debian project, achieving a precision of 82.5%. We also study combinations of XFL with different published embeddings for binary functions and show that DEXTER consistently improves over the state of the art in information gain. As a result, we are able to show that binary function labeling is best phrased in terms of multi-label learning, and that binary function embeddings benefit from moving beyond just learning from syntax.
Graph Constrained Data Representation Learning for Human Motion Segmentation
Jul 28, 2021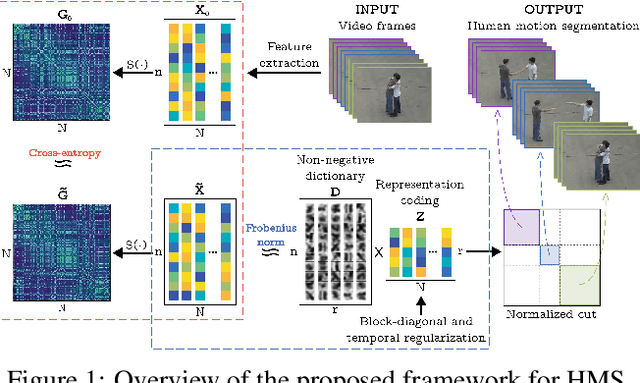
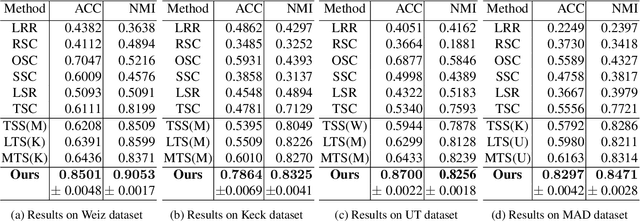

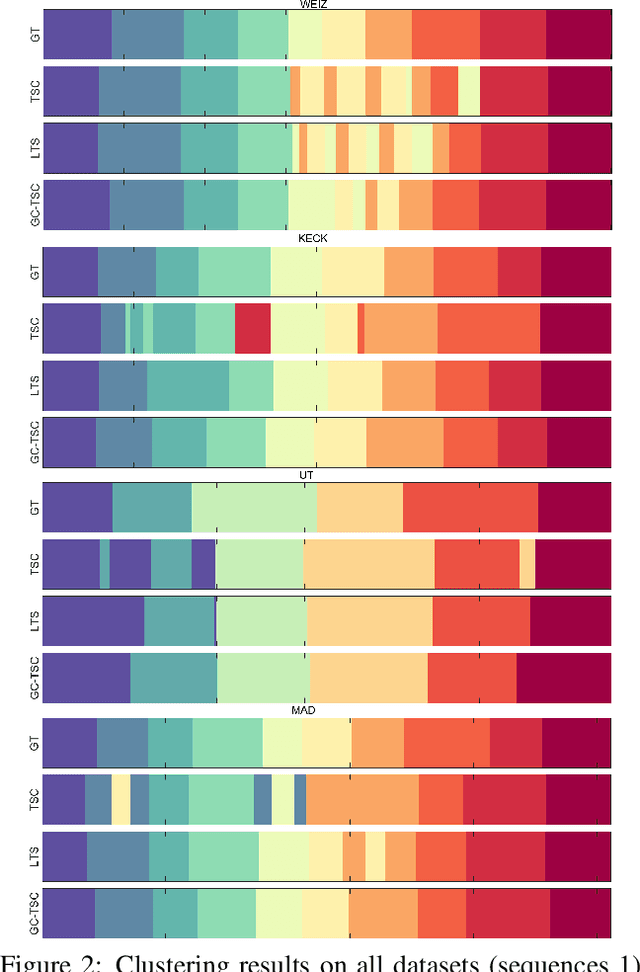
Recently, transfer subspace learning based approaches have shown to be a valid alternative to unsupervised subspace clustering and temporal data clustering for human motion segmentation (HMS). These approaches leverage prior knowledge from a source domain to improve clustering performance on a target domain, and currently they represent the state of the art in HMS. Bucking this trend, in this paper, we propose a novel unsupervised model that learns a representation of the data and digs clustering information from the data itself. Our model is reminiscent of temporal subspace clustering, but presents two critical differences. First, we learn an auxiliary data matrix that can deviate from the initial data, hence confer more degrees of freedom to the coding matrix. Second, we introduce a regularization term for this auxiliary data matrix that preserves the local geometrical structure present in the high-dimensional space. The proposed model is efficiently optimized by using an original Alternating Direction Method of Multipliers (ADMM) formulation allowing to learn jointly the auxiliary data representation, a nonnegative dictionary and a coding matrix. Experimental results on four benchmark datasets for HMS demonstrate that our approach achieves significantly better clustering performance then state-of-the-art methods, including both unsupervised and more recent semi-supervised transfer learning approaches.
Nearest Neighborhood-Based Deep Clustering for Source Data-absent Unsupervised Domain Adaptation
Aug 03, 2021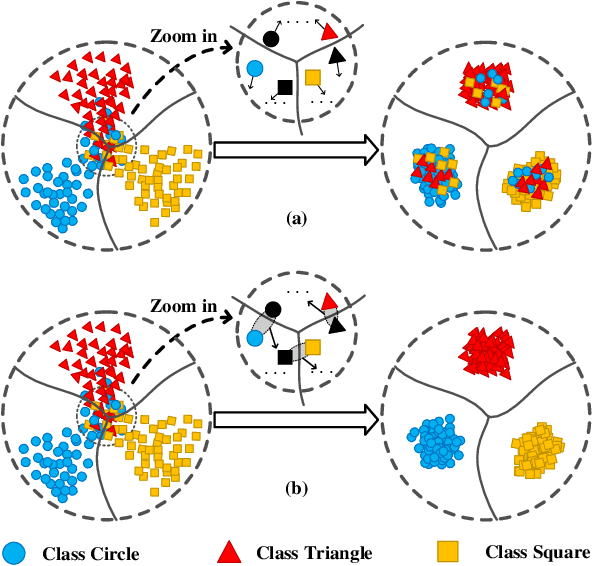
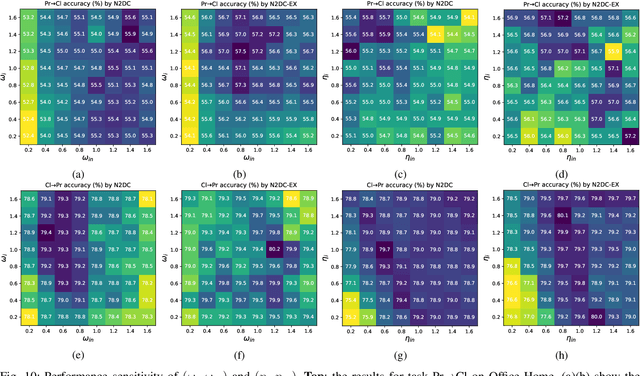
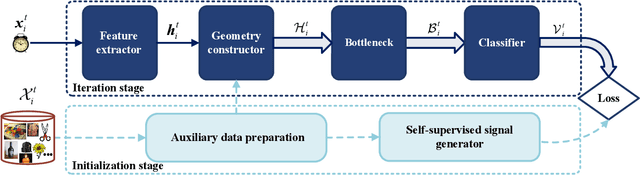
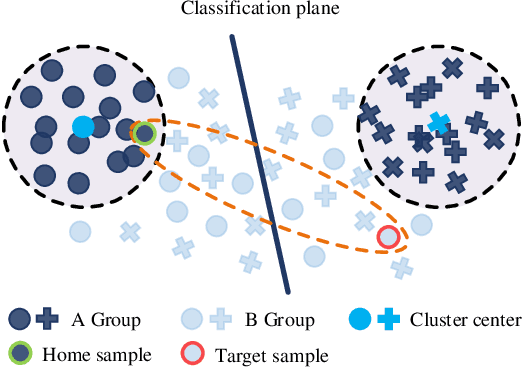
In the classic setting of unsupervised domain adaptation (UDA), the labeled source data are available in the training phase. However, in many real-world scenarios, owing to some reasons such as privacy protection and information security, the source data is inaccessible, and only a model trained on the source domain is available. This paper proposes a novel deep clustering method for this challenging task. Aiming at the dynamical clustering at feature-level, we introduce extra constraints hidden in the geometric structure between data to assist the process. Concretely, we propose a geometry-based constraint, named semantic consistency on the nearest neighborhood (SCNNH), and use it to encourage robust clustering. To reach this goal, we construct the nearest neighborhood for every target data and take it as the fundamental clustering unit by building our objective on the geometry. Also, we develop a more SCNNH-compliant structure with an additional semantic credibility constraint, named semantic hyper-nearest neighborhood (SHNNH). After that, we extend our method to this new geometry. Extensive experiments on three challenging UDA datasets indicate that our method achieves state-of-the-art results. The proposed method has significant improvement on all datasets (as we adopt SHNNH, the average accuracy increases by over 3.0% on the large-scaled dataset). Code is available at https://github.com/tntek/N2DCX.
Effective and scalable clustering of SARS-CoV-2 sequences
Aug 18, 2021
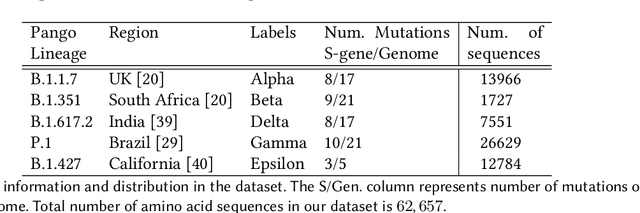
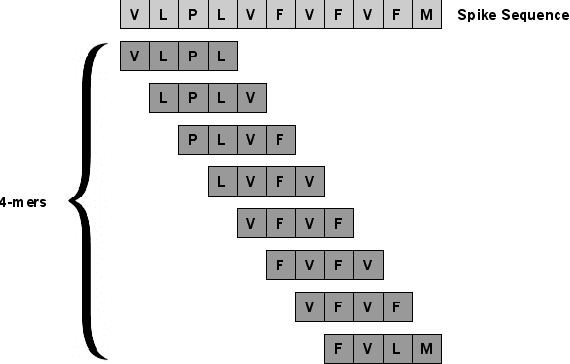
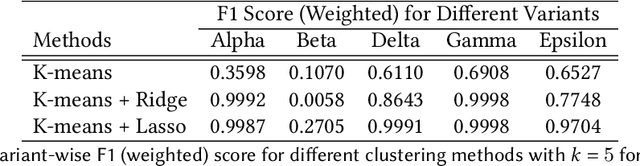
SARS-CoV-2, like any other virus, continues to mutate as it spreads, according to an evolutionary process. Unlike any other virus, the number of currently available sequences of SARS-CoV-2 in public databases such as GISAID is already several million. This amount of data has the potential to uncover the evolutionary dynamics of a virus like never before. However, a million is already several orders of magnitude beyond what can be processed by the traditional methods designed to reconstruct a virus's evolutionary history, such as those that build a phylogenetic tree. Hence, new and scalable methods will need to be devised in order to make use of the ever increasing number of viral sequences being collected. Since identifying variants is an important part of understanding the evolution of a virus, in this paper, we propose an approach based on clustering sequences to identify the current major SARS-CoV-2 variants. Using a $k$-mer based feature vector generation and efficient feature selection methods, our approach is effective in identifying variants, as well as being efficient and scalable to millions of sequences. Such a clustering method allows us to show the relative proportion of each variant over time, giving the rate of spread of each variant in different locations -- something which is important for vaccine development and distribution. We also compute the importance of each amino acid position of the spike protein in identifying a given variant in terms of information gain. Positions of high variant-specific importance tend to agree with those reported by the USA's Centers for Disease Control and Prevention (CDC), further demonstrating our approach.
DensePASS: Dense Panoramic Semantic Segmentation via Unsupervised Domain Adaptation with Attention-Augmented Context Exchange
Aug 13, 2021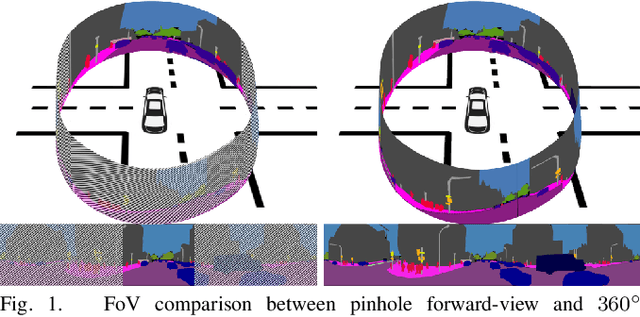
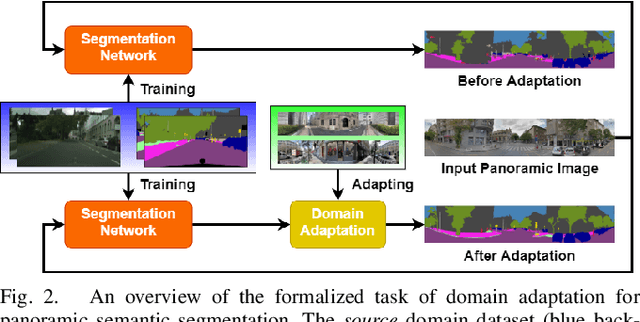
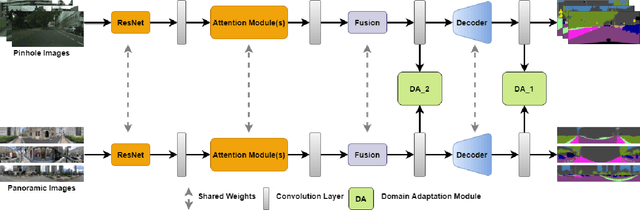
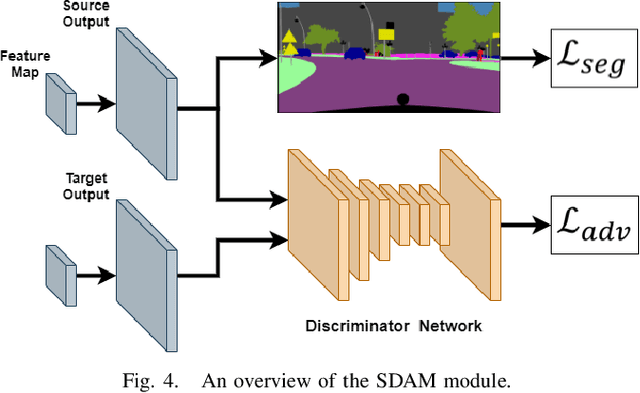
Intelligent vehicles clearly benefit from the expanded Field of View (FoV) of the 360-degree sensors, but the vast majority of available semantic segmentation training images are captured with pinhole cameras. In this work, we look at this problem through the lens of domain adaptation and bring panoramic semantic segmentation to a setting, where labelled training data originates from a different distribution of conventional pinhole camera images. First, we formalize the task of unsupervised domain adaptation for panoramic semantic segmentation, where a network trained on labelled examples from the source domain of pinhole camera data is deployed in a different target domain of panoramic images, for which no labels are available. To validate this idea, we collect and publicly release DensePASS - a novel densely annotated dataset for panoramic segmentation under cross-domain conditions, specifically built to study the Pinhole-to-Panoramic transfer and accompanied with pinhole camera training examples obtained from Cityscapes. DensePASS covers both, labelled- and unlabelled 360-degree images, with the labelled data comprising 19 classes which explicitly fit the categories available in the source domain (i.e. pinhole) data. To meet the challenge of domain shift, we leverage the current progress of attention-based mechanisms and build a generic framework for cross-domain panoramic semantic segmentation based on different variants of attention-augmented domain adaptation modules. Our framework facilitates information exchange at local- and global levels when learning the domain correspondences and improves the domain adaptation performance of two standard segmentation networks by 6.05% and 11.26% in Mean IoU.
Claim Detection in Biomedical Twitter Posts
May 01, 2021
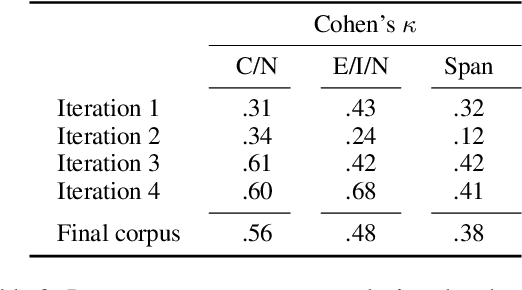
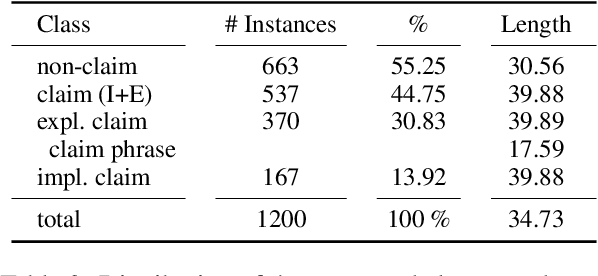
Social media contains unfiltered and unique information, which is potentially of great value, but, in the case of misinformation, can also do great harm. With regards to biomedical topics, false information can be particularly dangerous. Methods of automatic fact-checking and fake news detection address this problem, but have not been applied to the biomedical domain in social media yet. We aim to fill this research gap and annotate a corpus of 1200 tweets for implicit and explicit biomedical claims (the latter also with span annotations for the claim phrase). With this corpus, which we sample to be related to COVID-19, measles, cystic fibrosis, and depression, we develop baseline models which detect tweets that contain a claim automatically. Our analyses reveal that biomedical tweets are densely populated with claims (45 % in a corpus sampled to contain 1200 tweets focused on the domains mentioned above). Baseline classification experiments with embedding-based classifiers and BERT-based transfer learning demonstrate that the detection is challenging, however, shows acceptable performance for the identification of explicit expressions of claims. Implicit claim tweets are more challenging to detect.
Dataset and Performance Comparison of Deep Learning Architectures for Plum Detection and Robotic Harvesting
May 09, 2021

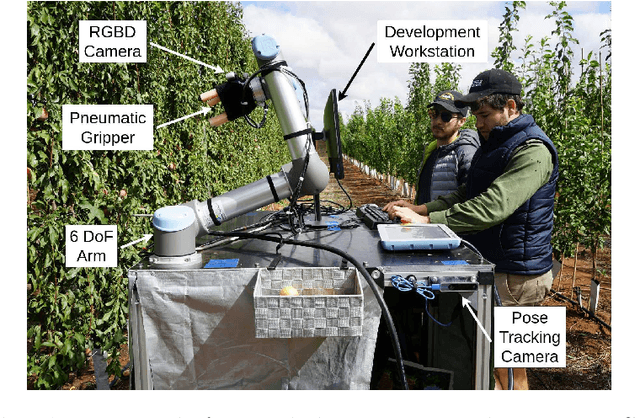
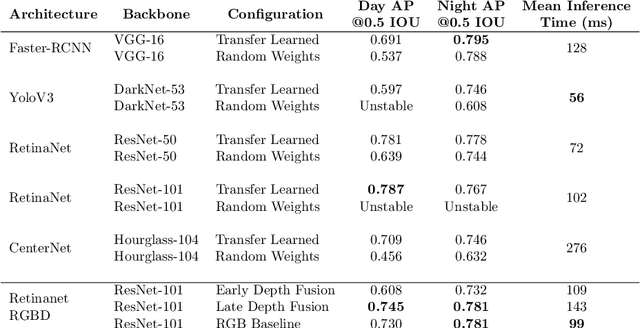
Many automated operations in agriculture, such as weeding and plant counting, require robust and accurate object detectors. Robotic fruit harvesting is one of these, and is an important technology to address the increasing labour shortages and uncertainty suffered by tree crop growers. An eye-in-hand sensing setup is commonly used in harvesting systems and provides benefits to sensing accuracy and flexibility. However, as the hand and camera move from viewing the entire trellis to picking a specific fruit, large changes in lighting, colour, obscuration and exposure occur. Object detection algorithms used in harvesting should be robust to these challenges, but few datasets for assessing this currently exist. In this work, two new datasets are gathered during day and night operation of an actual robotic plum harvesting system. A range of current generation deep learning object detectors are benchmarked against these. Additionally, two methods for fusing depth and image information are tested for their impact on detector performance. Significant differences between day and night accuracy of different detectors is found, transfer learning is identified as essential in all cases, and depth information fusion is assessed as only marginally effective. The dataset and benchmark models are made available online.