 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
MoCL: Contrastive Learning on Molecular Graphs with Multi-level Domain Knowledge
Jun 05, 2021
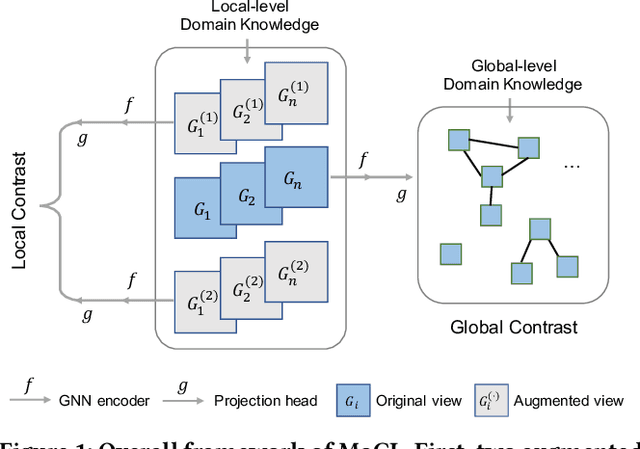
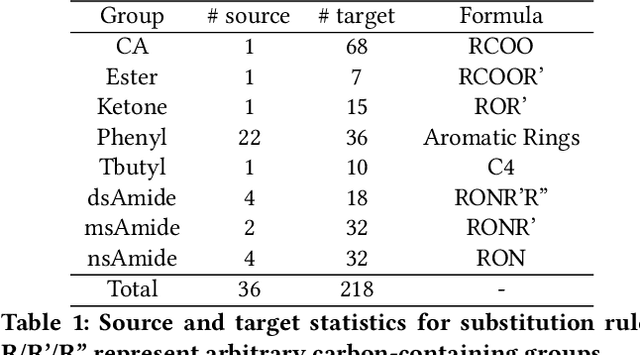
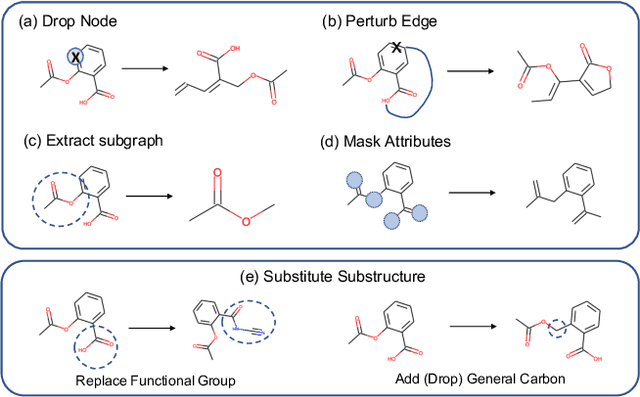
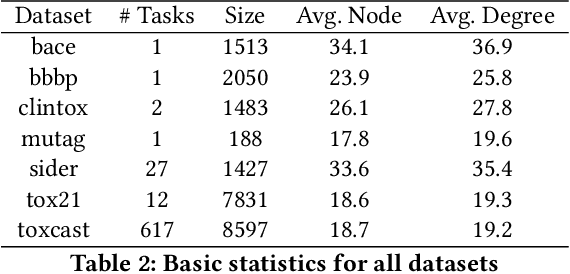
Recent years have seen a rapid growth of utilizing graph neural networks (GNNs) in the biomedical domain for tackling drug-related problems. However, like any other deep architectures, GNNs are data hungry. While requiring labels in real world is often expensive, pretraining GNNs in an unsupervised manner has been actively explored. Among them, graph contrastive learning, by maximizing the mutual information between paired graph augmentations, has been shown to be effective on various downstream tasks. However, the current graph contrastive learning framework has two limitations. First, the augmentations are designed for general graphs and thus may not be suitable or powerful enough for certain domains. Second, the contrastive scheme only learns representations that are invariant to local perturbations and thus does not consider the global structure of the dataset, which may also be useful for downstream tasks. Therefore, in this paper, we study graph contrastive learning in the context of biomedical domain, where molecular graphs are present. We propose a novel framework called MoCL, which utilizes domain knowledge at both local- and global-level to assist representation learning. The local-level domain knowledge guides the augmentation process such that variation is introduced without changing graph semantics. The global-level knowledge encodes the similarity information between graphs in the entire dataset and helps to learn representations with richer semantics. The entire model is learned through a double contrast objective. We evaluate MoCL on various molecular datasets under both linear and semi-supervised settings and results show that MoCL achieves state-of-the-art performance.
Enhancing Social Relation Inference with Concise Interaction Graph and Discriminative Scene Representation
Jul 30, 2021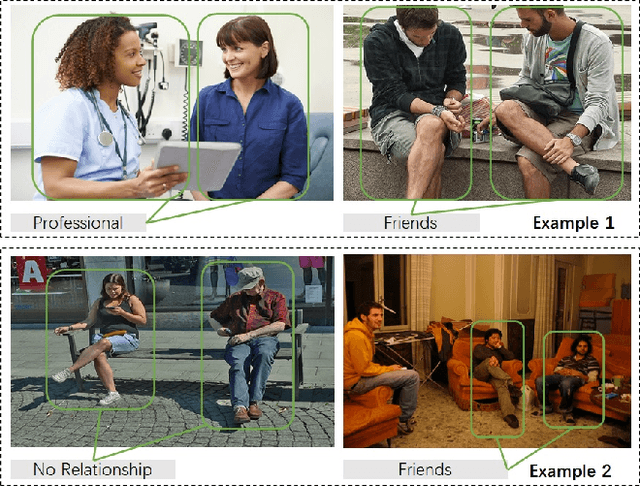
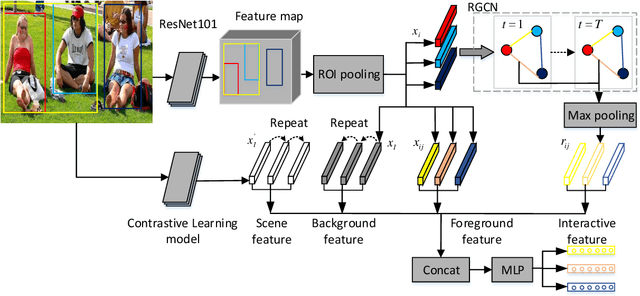
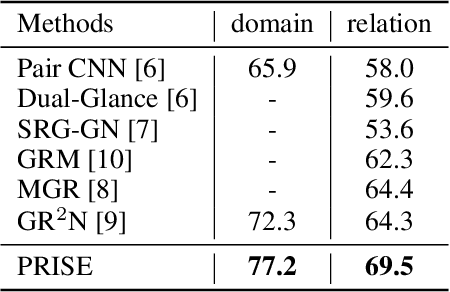
There has been a recent surge of research interest in attacking the problem of social relation inference based on images. Existing works classify social relations mainly by creating complicated graphs of human interactions, or learning the foreground and/or background information of persons and objects, but ignore holistic scene context. The holistic scene refers to the functionality of a place in images, such as dinning room, playground and office. In this paper, by mimicking human understanding on images, we propose an approach of \textbf{PR}actical \textbf{I}nference in \textbf{S}ocial r\textbf{E}lation (PRISE), which concisely learns interactive features of persons and discriminative features of holistic scenes. Technically, we develop a simple and fast relational graph convolutional network to capture interactive features of all persons in one image. To learn the holistic scene feature, we elaborately design a contrastive learning task based on image scene classification. To further boost the performance in social relation inference, we collect and distribute a new large-scale dataset, which consists of about 240 thousand unlabeled images. The extensive experimental results show that our novel learning framework significantly beats the state-of-the-art methods, e.g., PRISE achieves 6.8$\%$ improvement for domain classification in PIPA dataset.
Beyond Farthest Point Sampling in Point-Wise Analysis
Jul 09, 2021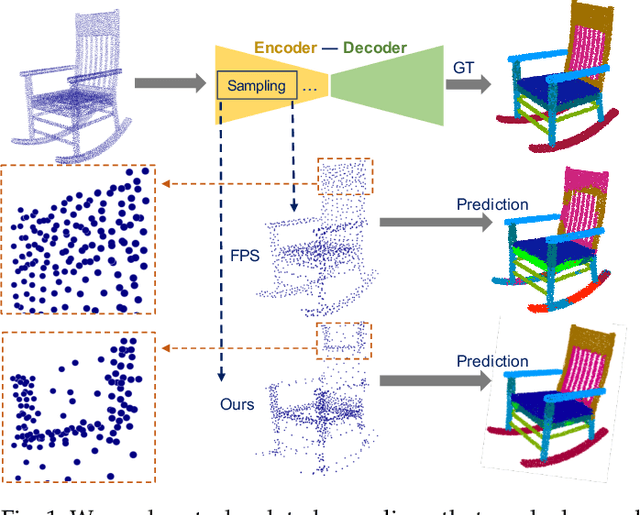
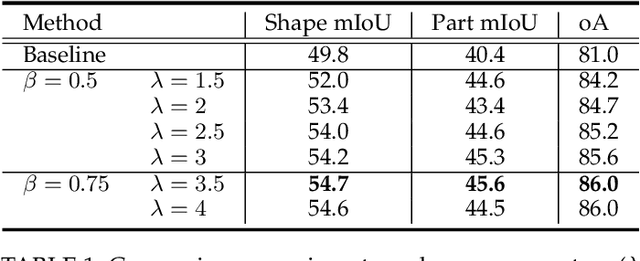
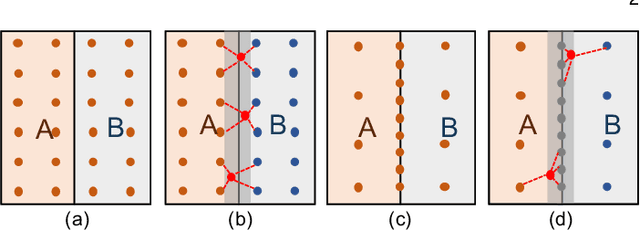
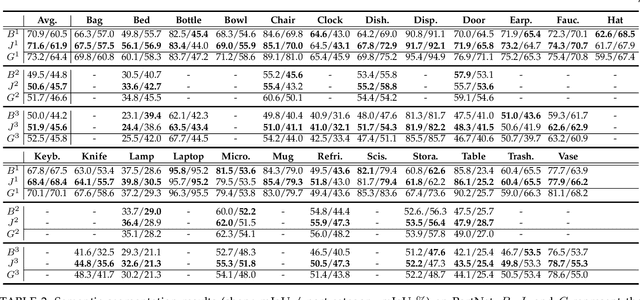
Sampling, grouping, and aggregation are three important components in the multi-scale analysis of point clouds. In this paper, we present a novel data-driven sampler learning strategy for point-wise analysis tasks. Unlike the widely used sampling technique, Farthest Point Sampling (FPS), we propose to learn sampling and downstream applications jointly. Our key insight is that uniform sampling methods like FPS are not always optimal for different tasks: sampling more points around boundary areas can make the point-wise classification easier for segmentation. Towards the end, we propose a novel sampler learning strategy that learns sampling point displacement supervised by task-related ground truth information and can be trained jointly with the underlying tasks. We further demonstrate our methods in various point-wise analysis architectures, including semantic part segmentation, point cloud completion, and keypoint detection. Our experiments show that jointly learning of the sampler and task brings remarkable improvement over previous baseline methods.
DAGN: Discourse-Aware Graph Network for Logical Reasoning
Apr 08, 2021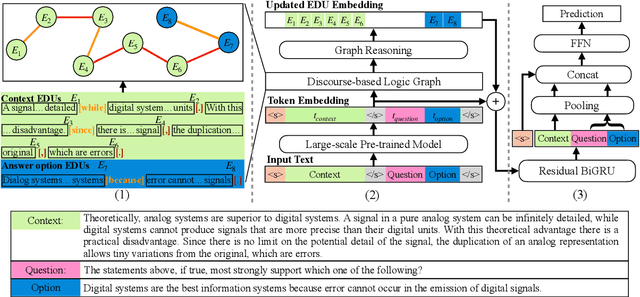
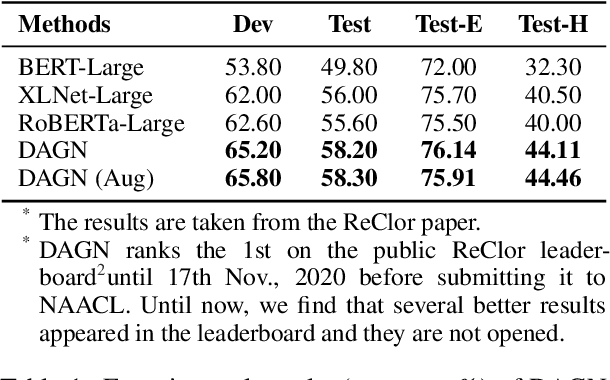
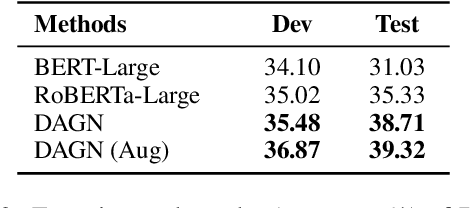

Recent QA with logical reasoning questions requires passage-level relations among the sentences. However, current approaches still focus on sentence-level relations interacting among tokens. In this work, we explore aggregating passage-level clues for solving logical reasoning QA by using discourse-based information. We propose a discourse-aware graph network (DAGN) that reasons relying on the discourse structure of the texts. The model encodes discourse information as a graph with elementary discourse units (EDUs) and discourse relations, and learns the discourse-aware features via a graph network for downstream QA tasks. Experiments are conducted on two logical reasoning QA datasets, ReClor and LogiQA, and our proposed DAGN achieves competitive results. The source code is available at https://github.com/Eleanor-H/DAGN.
Self-Supervised Regional and Temporal Auxiliary Tasks for Facial Action Unit Recognition
Jul 30, 2021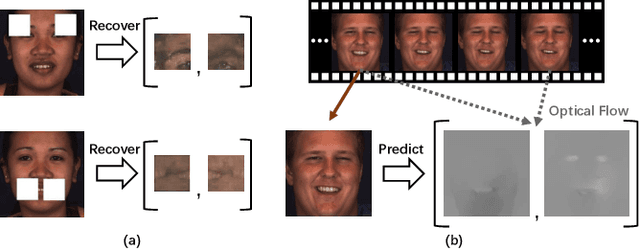
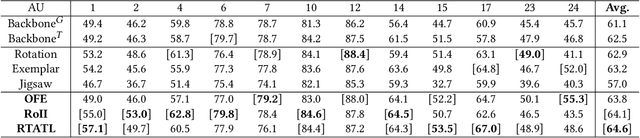
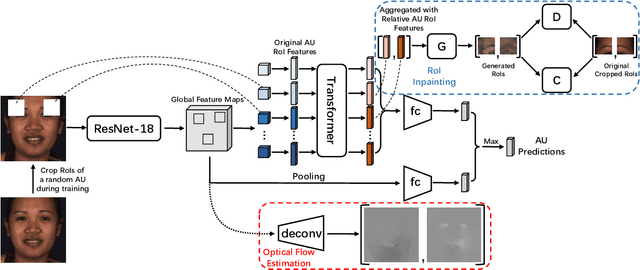
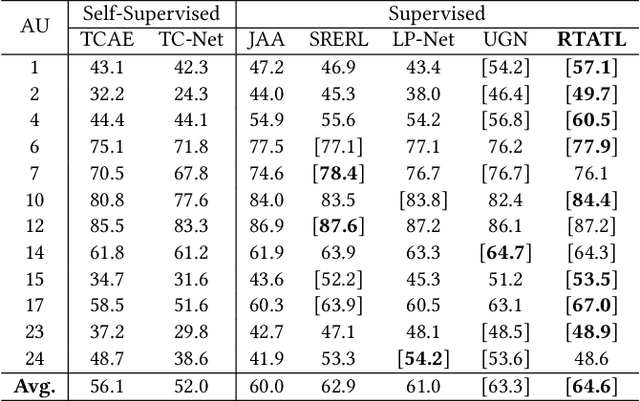
Automatic facial action unit (AU) recognition is a challenging task due to the scarcity of manual annotations. To alleviate this problem, a large amount of efforts has been dedicated to exploiting various methods which leverage numerous unlabeled data. However, many aspects with regard to some unique properties of AUs, such as the regional and relational characteristics, are not sufficiently explored in previous works. Motivated by this, we take the AU properties into consideration and propose two auxiliary AU related tasks to bridge the gap between limited annotations and the model performance in a self-supervised manner via the unlabeled data. Specifically, to enhance the discrimination of regional features with AU relation embedding, we design a task of RoI inpainting to recover the randomly cropped AU patches. Meanwhile, a single image based optical flow estimation task is proposed to leverage the dynamic change of facial muscles and encode the motion information into the global feature representation. Based on these two self-supervised auxiliary tasks, local features, mutual relation and motion cues of AUs are better captured in the backbone network with the proposed regional and temporal based auxiliary task learning (RTATL) framework. Extensive experiments on BP4D and DISFA demonstrate the superiority of our method and new state-of-the-art performances are achieved.
Unsupervised Domain Adaptive 3D Detection with Multi-Level Consistency
Jul 23, 2021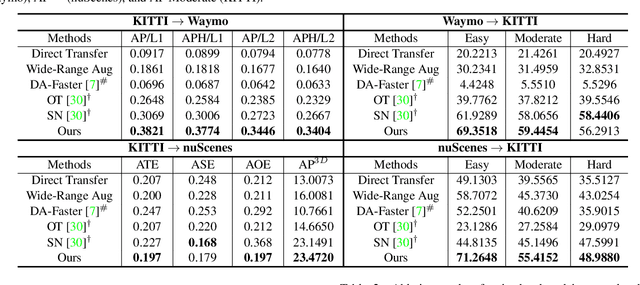
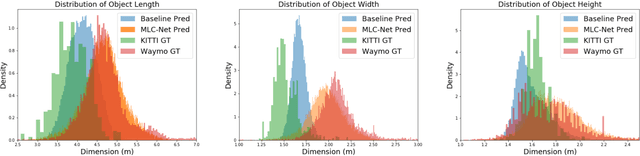
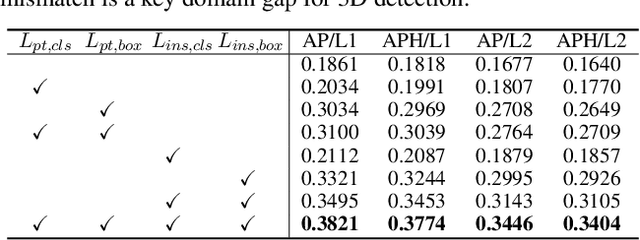
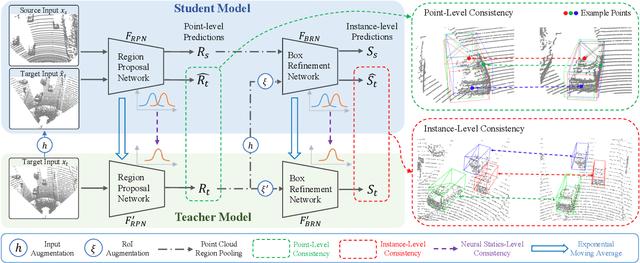
Deep learning-based 3D object detection has achieved unprecedented success with the advent of large-scale autonomous driving datasets. However, drastic performance degradation remains a critical challenge for cross-domain deployment. In addition, existing 3D domain adaptive detection methods often assume prior access to the target domain annotations, which is rarely feasible in the real world. To address this challenge, we study a more realistic setting, unsupervised 3D domain adaptive detection, which only utilizes source domain annotations. 1) We first comprehensively investigate the major underlying factors of the domain gap in 3D detection. Our key insight is that geometric mismatch is the key factor of domain shift. 2) Then, we propose a novel and unified framework, Multi-Level Consistency Network (MLC-Net), which employs a teacher-student paradigm to generate adaptive and reliable pseudo-targets. MLC-Net exploits point-, instance- and neural statistics-level consistency to facilitate cross-domain transfer. Extensive experiments demonstrate that MLC-Net outperforms existing state-of-the-art methods (including those using additional target domain information) on standard benchmarks. Notably, our approach is detector-agnostic, which achieves consistent gains on both single- and two-stage 3D detectors.
Dynamic Knowledge Distillation with A Single Stream Structure for RGB-D Salient Object Detection
Jun 30, 2021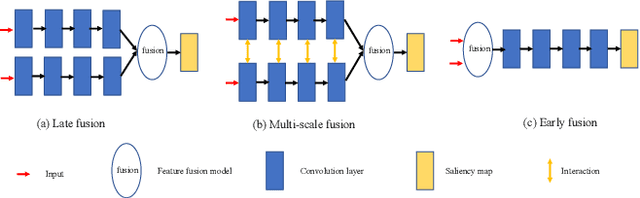
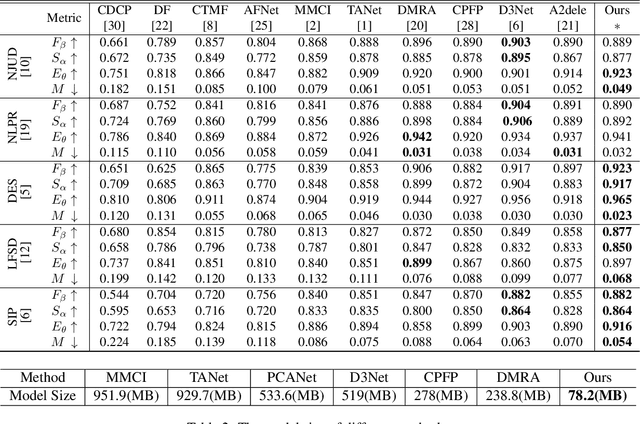
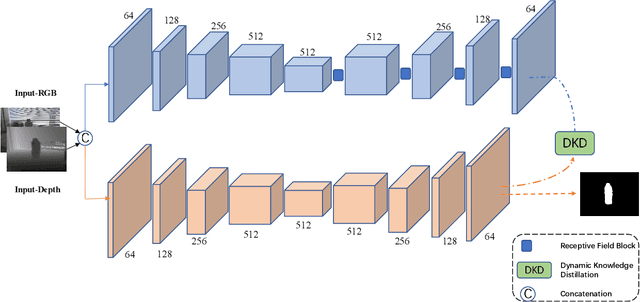

RGB-D salient object detection(SOD) demonstrates its superiority on detecting in complex environments due to the additional depth information introduced in the data. Inevitably, an independent stream is introduced to extract features from depth images, leading to extra computation and parameters. This methodology which sacrifices the model size to improve the detection accuracy may impede the practical application of SOD problems. To tackle this dilemma, we propose a dynamic distillation method along with a lightweight framework, which significantly reduces the parameters. This method considers the factors of both teacher and student performance within the training stage and dynamically assigns the distillation weight instead of applying a fixed weight on the student model. Extensive experiments are conducted on five public datasets to demonstrate that our method can achieve competitive performance compared to 10 prior methods through a 78.2MB lightweight structure.
Large Scale Long-tailed Product Recognition System at Alibaba
Feb 09, 2021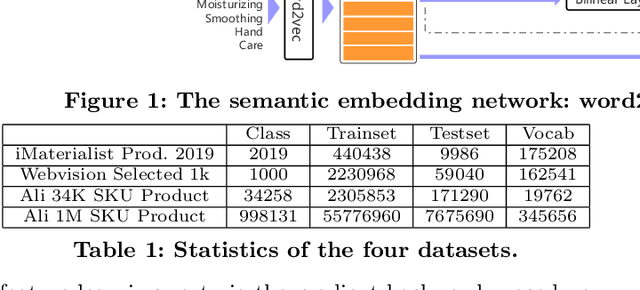

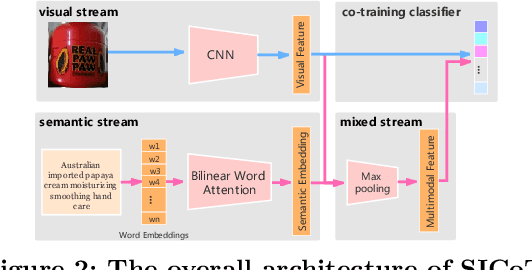
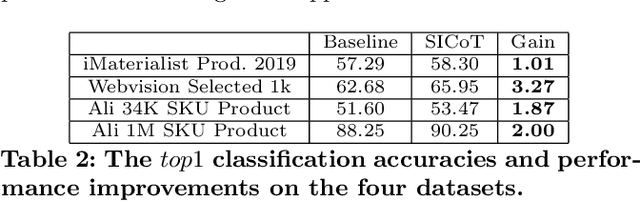
A practical large scale product recognition system suffers from the phenomenon of long-tailed imbalanced training data under the E-commercial circumstance at Alibaba. Besides product images at Alibaba, plenty of image related side information (e.g. title, tags) reveal rich semantic information about images. Prior works mainly focus on addressing the long tail problem in visual perspective only, but lack of consideration of leveraging the side information. In this paper, we present a novel side information based large scale visual recognition co-training~(SICoT) system to deal with the long tail problem by leveraging the image related side information. In the proposed co-training system, we firstly introduce a bilinear word attention module aiming to construct a semantic embedding over the noisy side information. A visual feature and semantic embedding co-training scheme is then designed to transfer knowledge from classes with abundant training data (head classes) to classes with few training data (tail classes) in an end-to-end fashion. Extensive experiments on four challenging large scale datasets, whose numbers of classes range from one thousand to one million, demonstrate the scalable effectiveness of the proposed SICoT system in alleviating the long tail problem. In the visual search platform Pailitao\footnote{http://www.pailitao.com} at Alibaba, we settle a practical large scale product recognition application driven by the proposed SICoT system, and achieve a significant gain of unique visitor~(UV) conversion rate.
* Acccepted by CIKM 2020
Zeroth-Order Methods for Convex-Concave Minmax Problems: Applications to Decision-Dependent Risk Minimization
Jun 16, 2021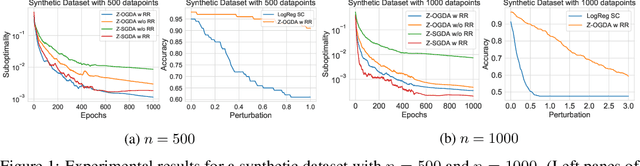

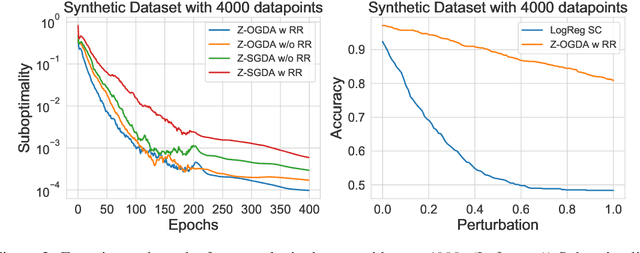
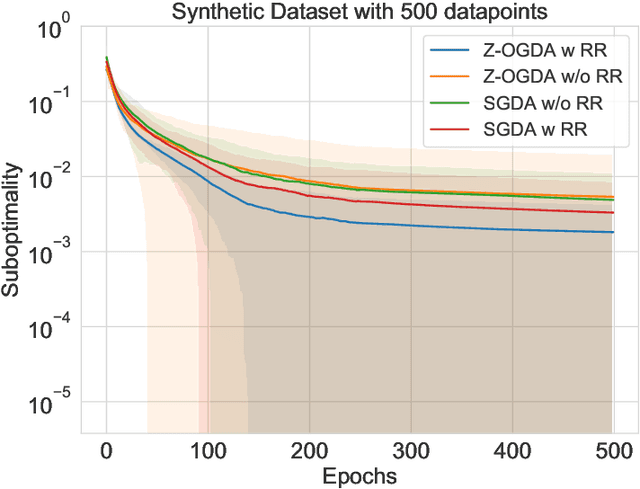
Min-max optimization is emerging as a key framework for analyzing problems of robustness to strategically and adversarially generated data. We propose a random reshuffling-based gradient free Optimistic Gradient Descent-Ascent algorithm for solving convex-concave min-max problems with finite sum structure. We prove that the algorithm enjoys the same convergence rate as that of zeroth-order algorithms for convex minimization problems. We further specialize the algorithm to solve distributionally robust, decision-dependent learning problems, where gradient information is not readily available. Through illustrative simulations, we observe that our proposed approach learns models that are simultaneously robust against adversarial distribution shifts and strategic decisions from the data sources, and outperforms existing methods from the strategic classification literature.
OpenSync: An opensource platform for synchronizing multiple measures in neuroscience experiments
Jul 29, 2021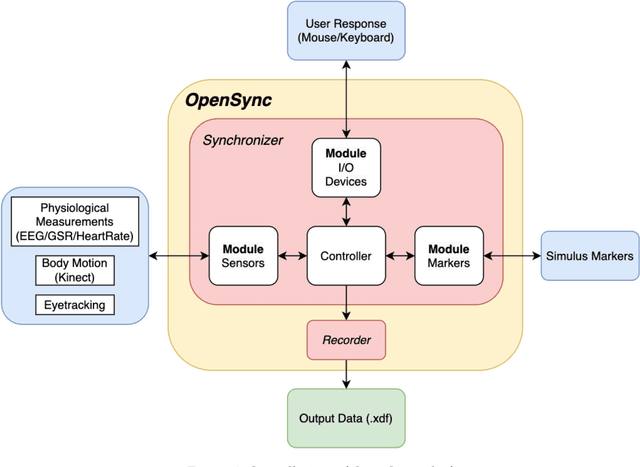


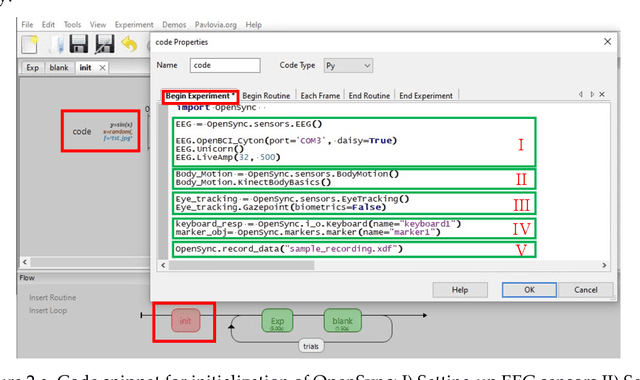
Background: The human mind is multimodal. Yet most behavioral studies rely on century-old measures such as task accuracy and latency. To create a better understanding of human behavior and brain functionality, we should introduce other measures and analyze behavior from various aspects. However, it is technically complex and costly to design and implement the experiments that record multiple measures. To address this issue, a platform that allows synchronizing multiple measures from human behavior is needed. Method: This paper introduces an opensource platform named OpenSync, which can be used to synchronize multiple measures in neuroscience experiments. This platform helps to automatically integrate, synchronize and record physiological measures (e.g., electroencephalogram (EEG), galvanic skin response (GSR), eye-tracking, body motion, etc.), user input response (e.g., from mouse, keyboard, joystick, etc.), and task-related information (stimulus markers). In this paper, we explain the structure and details of OpenSync, provide two case studies in PsychoPy and Unity. Comparison with existing tools: Unlike proprietary systems (e.g., iMotions), OpenSync is free and it can be used inside any opensource experiment design software (e.g., PsychoPy, OpenSesame, Unity, etc., https://pypi.org/project/OpenSync/ and https://github.com/moeinrazavi/OpenSync_Unity). Results: Our experimental results show that the OpenSync platform is able to synchronize multiple measures with microsecond resolution.