 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Inferring a Continuous Distribution of Atom Coordinates from Cryo-EM Images using VAEs
Jun 26, 2021

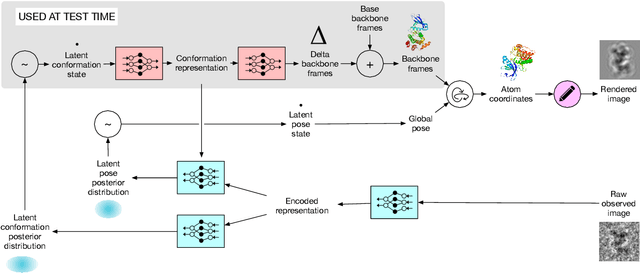
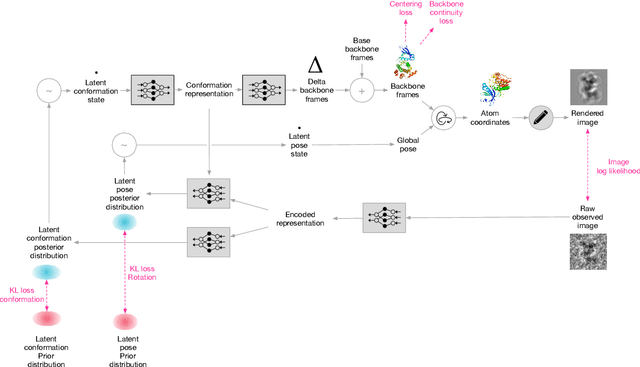
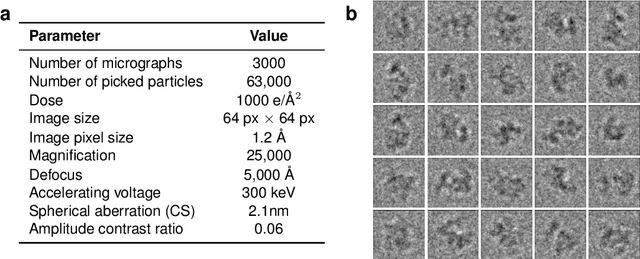
Cryo-electron microscopy (cryo-EM) has revolutionized experimental protein structure determination. Despite advances in high resolution reconstruction, a majority of cryo-EM experiments provide either a single state of the studied macromolecule, or a relatively small number of its conformations. This reduces the effectiveness of the technique for proteins with flexible regions, which are known to play a key role in protein function. Recent methods for capturing conformational heterogeneity in cryo-EM data model it in volume space, making recovery of continuous atomic structures challenging. Here we present a fully deep-learning-based approach using variational auto-encoders (VAEs) to recover a continuous distribution of atomic protein structures and poses directly from picked particle images and demonstrate its efficacy on realistic simulated data. We hope that methods built on this work will allow incorporation of stronger prior information about protein structure and enable better understanding of non-rigid protein structures.
Discovering Hypernymy in Text-Rich Heterogeneous Information Network by Exploiting Context Granularity
Sep 04, 2019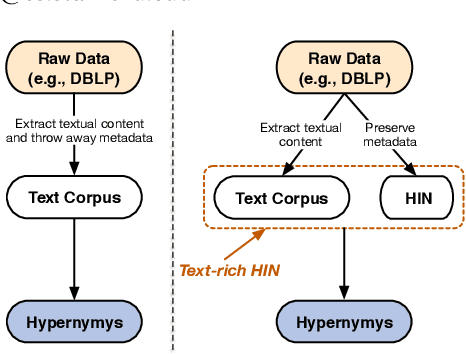

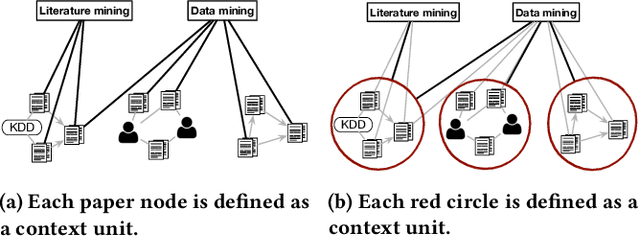

Text-rich heterogeneous information networks (text-rich HINs) are ubiquitous in real-world applications. Hypernymy, also known as is-a relation or subclass-of relation, lays in the core of many knowledge graphs and benefits many downstream applications. Existing methods of hypernymy discovery either leverage textual patterns to extract explicitly mentioned hypernym-hyponym pairs, or learn a distributional representation for each term of interest based its context. These approaches rely on statistical signals from the textual corpus, and their effectiveness would therefore be hindered when the signals from the corpus are not sufficient for all terms of interest. In this work, we propose to discover hypernymy in text-rich HINs, which can introduce additional high-quality signals. We develop a new framework, named HyperMine, that exploits multi-granular contexts and combines signals from both text and network without human labeled data. HyperMine extends the definition of context to the scenario of text-rich HIN. For example, we can define typed nodes and communities as contexts. These contexts encode signals of different granularities and we feed them into a hypernymy inference model. HyperMine learns this model using weak supervision acquired based on high-precision textual patterns. Extensive experiments on two large real-world datasets demonstrate the effectiveness of HyperMine and the utility of modeling context granularity. We further show a case study that a high-quality taxonomy can be generated solely based on the hypernymy discovered by HyperMine.
Navigate-and-Seek: a Robotics Framework for People Localization in Agricultural Environments
Jul 08, 2021
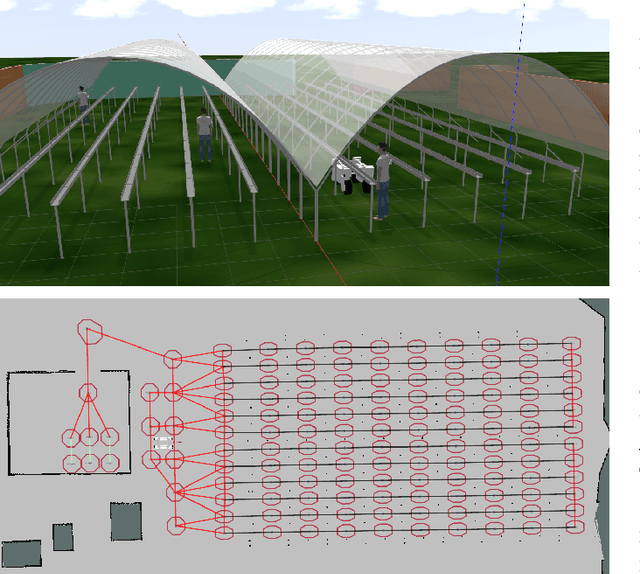
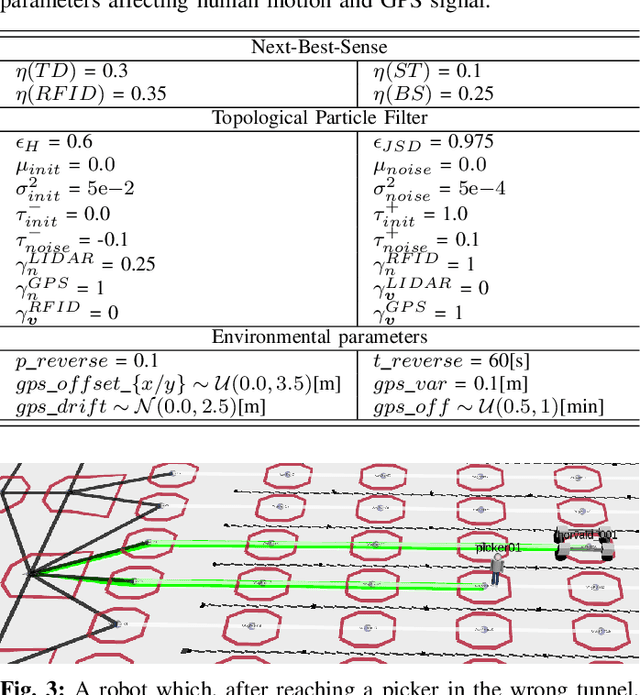
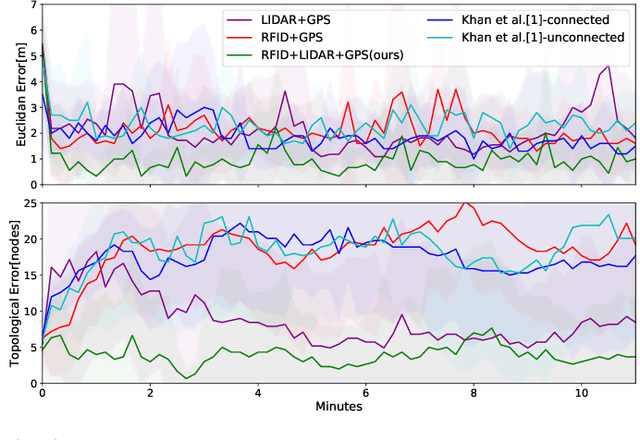
The agricultural domain offers a working environment where many human laborers are nowadays employed to maintain or harvest crops, with huge potential for productivity gains through the introduction of robotic automation. Detecting and localizing humans reliably and accurately in such an environment, however, is a prerequisite to many services offered by fleets of mobile robots collaborating with human workers. Consequently, in this paper, we expand on the concept of a topological particle filter (TPF) to accurately and individually localize and track workers in a farm environment, integrating information from heterogeneous sensors and combining local active sensing (exploiting a robot's onboard sensing employing a Next-Best-Sense planning approach) and global localization (using affordable IoT GNSS devices). We validate the proposed approach in topologies created for the deployment of robotics fleets to support fruit pickers in a real farm environment. By combining multi-sensor observations on the topological level complemented by active perception through the NBS approach, we show that we can improve the accuracy of picker localization in comparison to prior work.
TopicTracker: A Platform for Topic Trajectory Identification and Visualisation
Mar 02, 2021
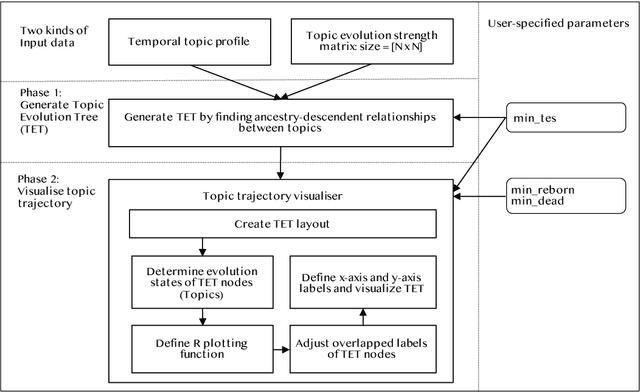
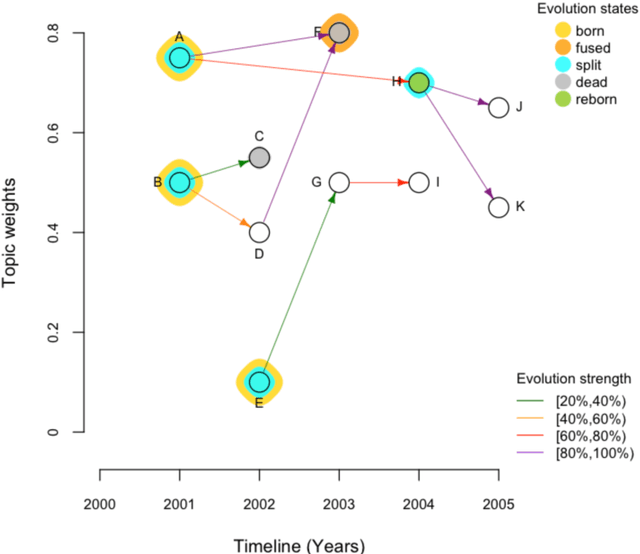
Topic trajectory information provides crucial insight into the dynamics of topics and their evolutionary relationships over a given time. Also, this information can help to improve our understanding on how new topics have emerged or formed through a sequential or interrelated events of emergence, modification and integration of prior topics. Nevertheless, the implementation of the existing methods for topic trajectory identification is rarely available as usable software. In this paper, we present TopicTracker, a platform for topic trajectory identification and visualisation. The key of Topic Tracker is that it can represent the three facets of information together, given two kinds of input: a time-stamped topic profile consisting of the set of the underlying topics over time, and the evolution strength matrix among them: evolutionary pathways of dynamic topics, evolution states of the topics, and topic importance. TopicTracker is a publicly available software implemented using the R software.
Drowned out by the noise: Evidence for Tracking-free Motion Prediction
Apr 16, 2021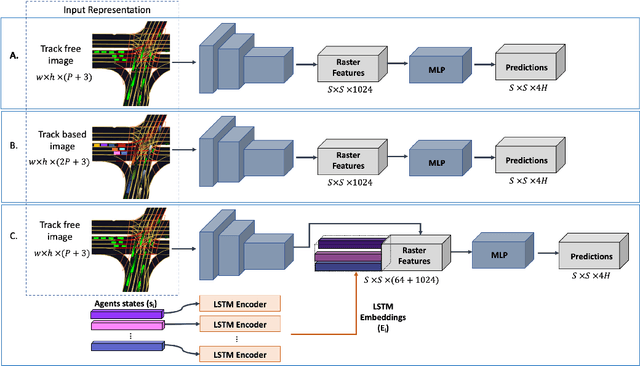
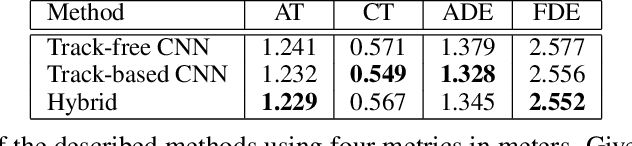

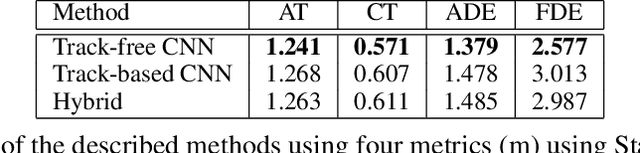
Autonomous driving consists of a multitude of interacting modules, where each module must contend with errors from the others. Typically, the motion prediction module depends on a robust tracking system to capture each agent's past movement. In this work, we systematically explore the importance of the tracking module for the motion prediction task and ultimately conclude that the tracking module is detrimental to overall motion prediction performance when the module is imperfect (with as low as 1% error). We explicitly compare models that use tracking information to models that do not across multiple scenarios and conditions. We find that the tracking information only improves performance in noise-free conditions. A noise-free tracker is unlikely to remain noise-free in real-world scenarios, and the inevitable noise will subsequently negatively affect performance. We thus argue future work should be mindful of noise when developing and testing motion/tracking modules, or that they should do away with the tracking component entirely.
Learning without Knowing: Unobserved Context in Continuous Transfer Reinforcement Learning
Jun 07, 2021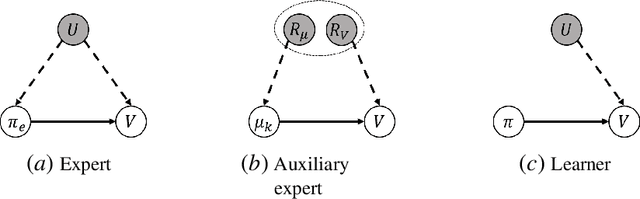
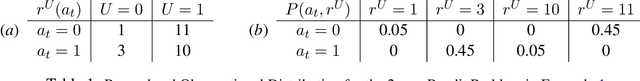
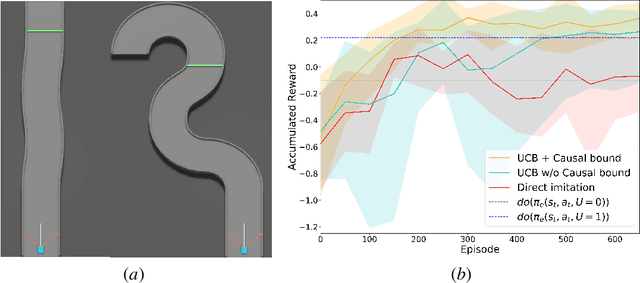

In this paper, we consider a transfer Reinforcement Learning (RL) problem in continuous state and action spaces, under unobserved contextual information. For example, the context can represent the mental view of the world that an expert agent has formed through past interactions with this world. We assume that this context is not accessible to a learner agent who can only observe the expert data. Then, our goal is to use the context-aware expert data to learn an optimal context-unaware policy for the learner using only a few new data samples. Such problems are typically solved using imitation learning that assumes that both the expert and learner agents have access to the same information. However, if the learner does not know the expert context, using the expert data alone will result in a biased learner policy and will require many new data samples to improve. To address this challenge, in this paper, we formulate the learning problem as a causal bound-constrained Multi-Armed-Bandit (MAB) problem. The arms of this MAB correspond to a set of basis policy functions that can be initialized in an unsupervised way using the expert data and represent the different expert behaviors affected by the unobserved context. On the other hand, the MAB constraints correspond to causal bounds on the accumulated rewards of these basis policy functions that we also compute from the expert data. The solution to this MAB allows the learner agent to select the best basis policy and improve it online. And the use of causal bounds reduces the exploration variance and, therefore, improves the learning rate. We provide numerical experiments on an autonomous driving example that show that our proposed transfer RL method improves the learner's policy faster compared to existing imitation learning methods and enjoys much lower variance during training.
Adaptive Denoising via GainTuning
Jul 27, 2021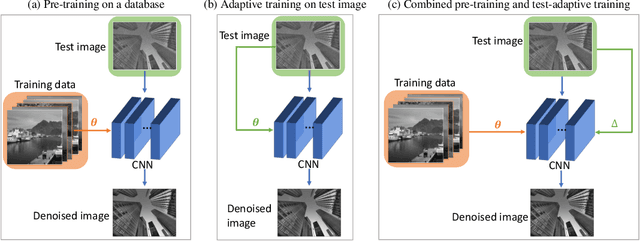
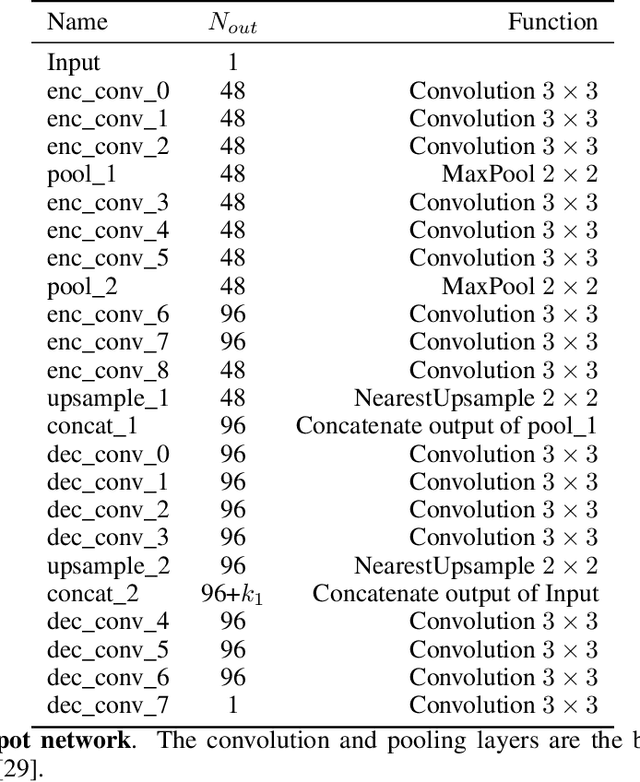
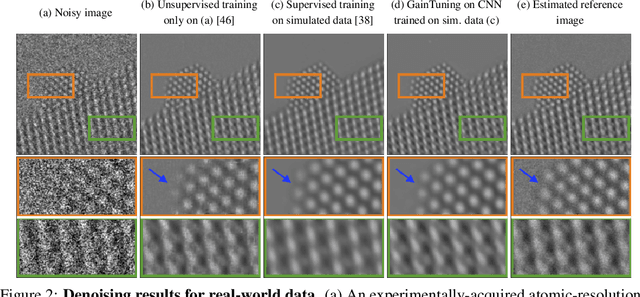

Deep convolutional neural networks (CNNs) for image denoising are usually trained on large datasets. These models achieve the current state of the art, but they have difficulties generalizing when applied to data that deviate from the training distribution. Recent work has shown that it is possible to train denoisers on a single noisy image. These models adapt to the features of the test image, but their performance is limited by the small amount of information used to train them. Here we propose "GainTuning", in which CNN models pre-trained on large datasets are adaptively and selectively adjusted for individual test images. To avoid overfitting, GainTuning optimizes a single multiplicative scaling parameter (the "Gain") of each channel in the convolutional layers of the CNN. We show that GainTuning improves state-of-the-art CNNs on standard image-denoising benchmarks, boosting their denoising performance on nearly every image in a held-out test set. These adaptive improvements are even more substantial for test images differing systematically from the training data, either in noise level or image type. We illustrate the potential of adaptive denoising in a scientific application, in which a CNN is trained on synthetic data, and tested on real transmission-electron-microscope images. In contrast to the existing methodology, GainTuning is able to faithfully reconstruct the structure of catalytic nanoparticles from these data at extremely low signal-to-noise ratios.
MathBERT: A Pre-Trained Model for Mathematical Formula Understanding
May 02, 2021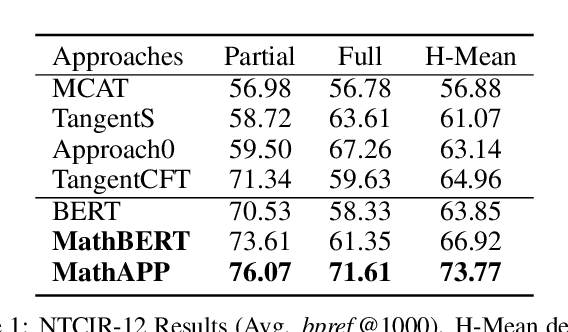
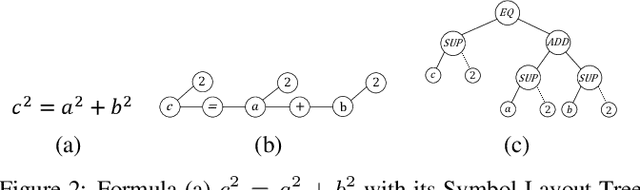
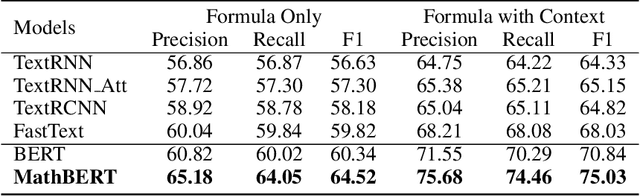
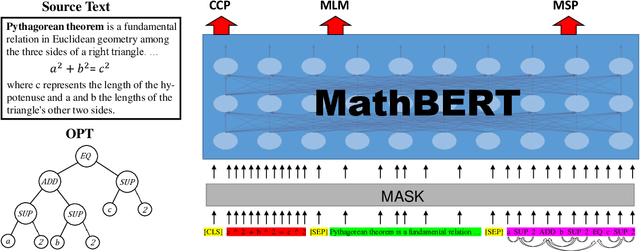
Large-scale pre-trained models like BERT, have obtained a great success in various Natural Language Processing (NLP) tasks, while it is still a challenge to adapt them to the math-related tasks. Current pre-trained models neglect the structural features and the semantic correspondence between formula and its context. To address these issues, we propose a novel pre-trained model, namely \textbf{MathBERT}, which is jointly trained with mathematical formulas and their corresponding contexts. In addition, in order to further capture the semantic-level structural features of formulas, a new pre-training task is designed to predict the masked formula substructures extracted from the Operator Tree (OPT), which is the semantic structural representation of formulas. We conduct various experiments on three downstream tasks to evaluate the performance of MathBERT, including mathematical information retrieval, formula topic classification and formula headline generation. Experimental results demonstrate that MathBERT significantly outperforms existing methods on all those three tasks. Moreover, we qualitatively show that this pre-trained model effectively captures the semantic-level structural information of formulas. To the best of our knowledge, MathBERT is the first pre-trained model for mathematical formula understanding.
Case-based similar image retrieval for weakly annotated large histopathological images of malignant lymphoma using deep metric learning
Jul 08, 2021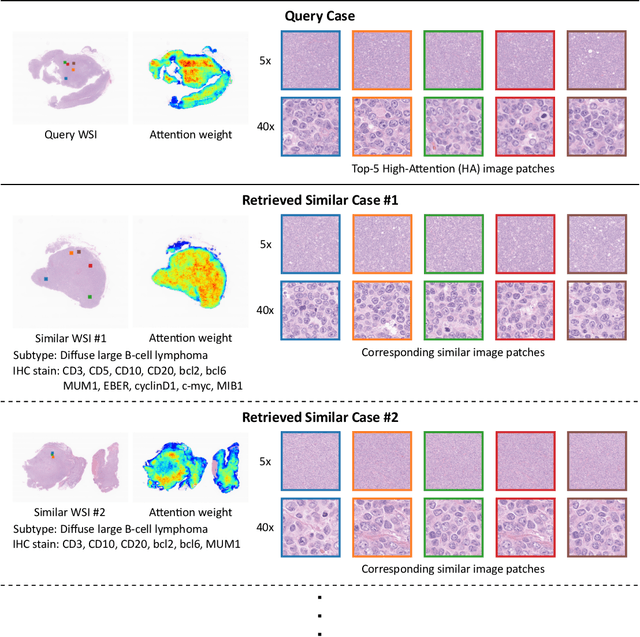
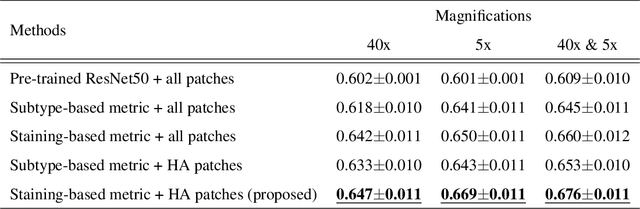
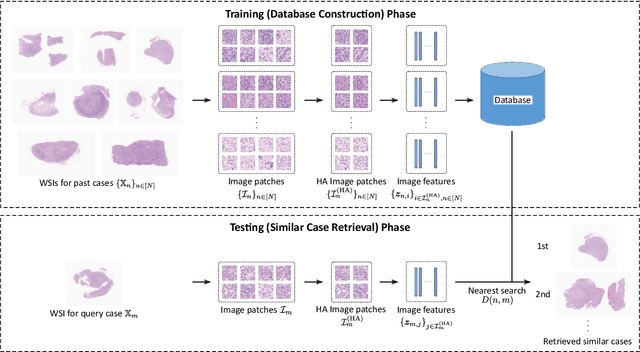
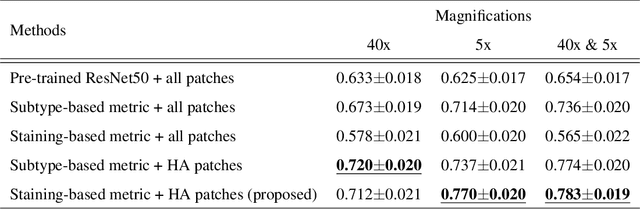
In the present study, we propose a novel case-based similar image retrieval (SIR) method for hematoxylin and eosin (H&E)-stained histopathological images of malignant lymphoma. When a whole slide image (WSI) is used as an input query, it is desirable to be able to retrieve similar cases by focusing on image patches in pathologically important regions such as tumor cells. To address this problem, we employ attention-based multiple instance learning, which enables us to focus on tumor-specific regions when the similarity between cases is computed. Moreover, we employ contrastive distance metric learning to incorporate immunohistochemical (IHC) staining patterns as useful supervised information for defining appropriate similarity between heterogeneous malignant lymphoma cases. In the experiment with 249 malignant lymphoma patients, we confirmed that the proposed method exhibited higher evaluation measures than the baseline case-based SIR methods. Furthermore, the subjective evaluation by pathologists revealed that our similarity measure using IHC staining patterns is appropriate for representing the similarity of H&E-stained tissue images for malignant lymphoma.
No-frills Dynamic Planning using Static Planners
Jun 17, 2021

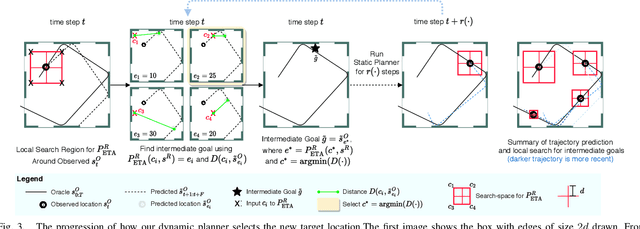
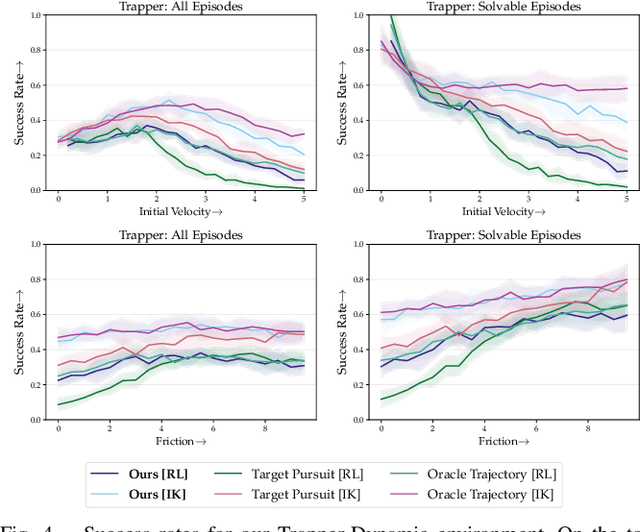
In this paper, we address the task of interacting with dynamic environments where the changes in the environment are independent of the agent. We study this through the context of trapping a moving ball with a UR5 robotic arm. Our key contribution is an approach to utilize a static planner for dynamic tasks using a Dynamic Planning add-on; that is, if we can successfully solve a task with a static target, then our approach can solve the same task when the target is moving. Our approach has three key components: an off-the-shelf static planner, a trajectory forecasting network, and a network to predict robot's estimated time of arrival at any location. We demonstrate the generalization of our approach across environments. More information and videos at https://mlevy2525.github.io/DynamicAddOn.