 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Dynamic 3D Spontaneous Micro-expression Database: Establishment and Evaluation
Jul 31, 2021
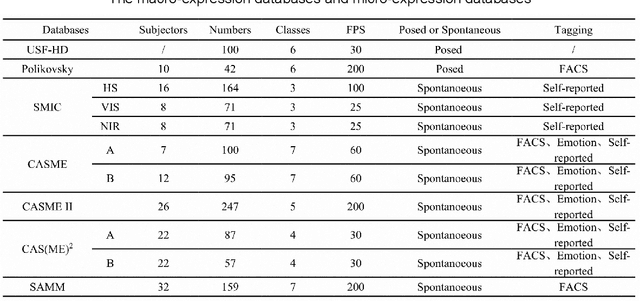
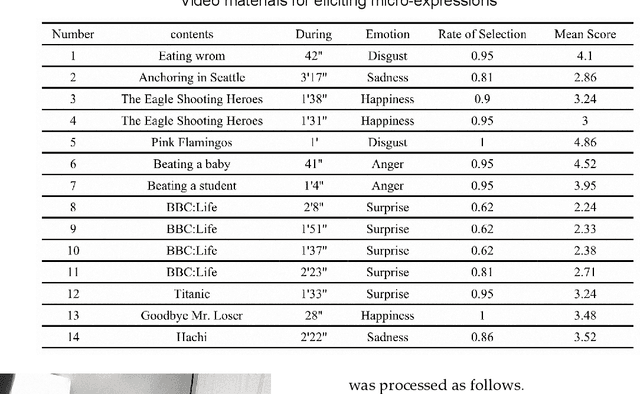


Micro-expressions are spontaneous, unconscious facial movements that show people's true inner emotions and have great potential in related fields of psychological testing. Since the face is a 3D deformation object, the occurrence of an expression can arouse spatial deformation of the face, but limited by the available databases are 2D videos, which lack the description of 3D spatial information of micro-expressions. Therefore, we proposed a new micro-expression database containing 2D video sequences and 3D point clouds sequences. The database includes 259 micro-expressions sequences, and these samples were classified using the objective method based on facial action coding system, as well as the non-objective method that combines video contents and participants' self-reports. We extracted facial 2D and 3D features using local binary patterns on three orthogonal planes and curvature descriptors, respectively, and performed baseline evaluations of the two features and their fusion results with leave-one-subject-out(LOSO) and 10-fold cross-validation methods. The best fusion performances were 58.84% and 73.03% for non-objective classification and 66.36% and 77.42% for objective classification, both of which have improved performance compared to using LBP-TOP features only.The database offers original and cropped micro-expression samples, which will facilitate the exploration and research on 3D Spatio-temporal features of micro-expressions.
Multi-Scale Context Aggregation Network with Attention-Guided for Crowd Counting
Apr 06, 2021
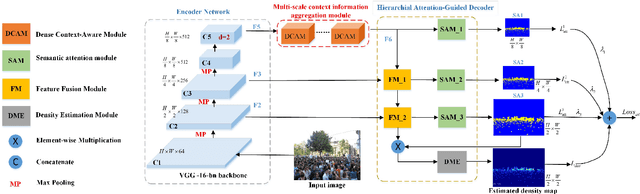
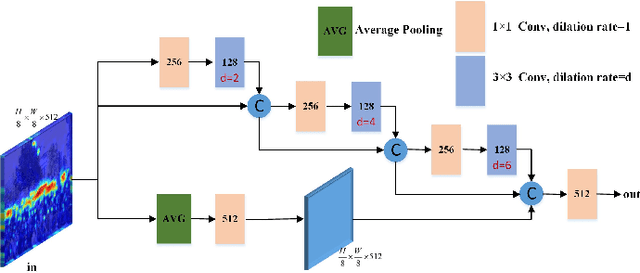
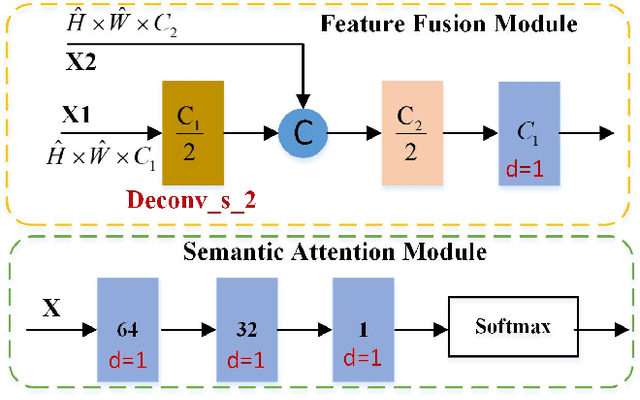
Crowd counting aims to predict the number of people and generate the density map in the image. There are many challenges, including varying head scales, the diversity of crowd distribution across images and cluttered backgrounds. In this paper, we propose a multi-scale context aggregation network (MSCANet) based on single-column encoder-decoder architecture for crowd counting, which consists of an encoder based on a dense context-aware module (DCAM) and a hierarchical attention-guided decoder. To handle the issue of scale variation, we construct the DCAM to aggregate multi-scale contextual information by densely connecting the dilated convolution with varying receptive fields. The proposed DCAM can capture rich contextual information of crowd areas due to its long-range receptive fields and dense scale sampling. Moreover, to suppress the background noise and generate a high-quality density map, we adopt a hierarchical attention-guided mechanism in the decoder. This helps to integrate more useful spatial information from shallow feature maps of the encoder by introducing multiple supervision based on semantic attention module (SAM). Extensive experiments demonstrate that the proposed approach achieves better performance than other similar state-of-the-art methods on three challenging benchmark datasets for crowd counting. The code is available at https://github.com/KingMV/MSCANet
Learning Heterogeneous Temporal Patterns of User Preference for Timely Recommendation
Apr 29, 2021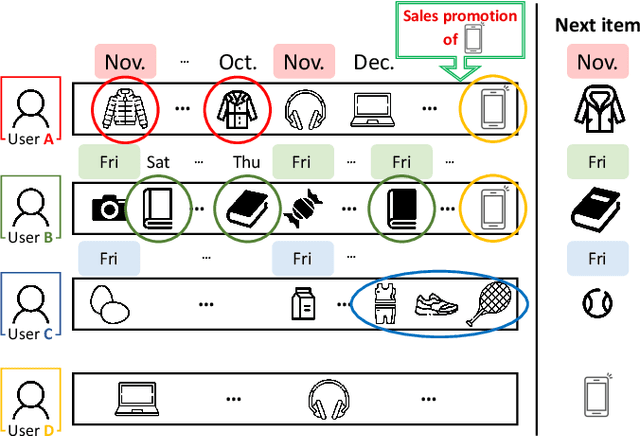
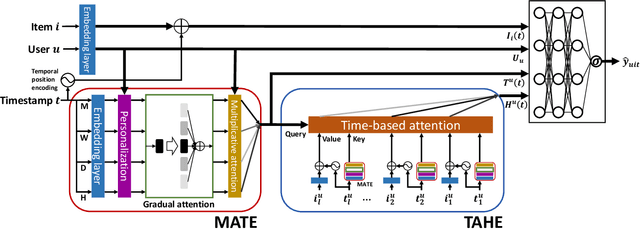
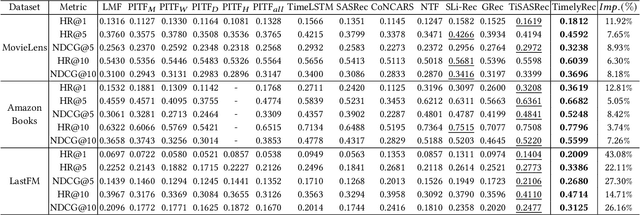
Recommender systems have achieved great success in modeling user's preferences on items and predicting the next item the user would consume. Recently, there have been many efforts to utilize time information of users' interactions with items to capture inherent temporal patterns of user behaviors and offer timely recommendations at a given time. Existing studies regard the time information as a single type of feature and focus on how to associate it with user preferences on items. However, we argue they are insufficient for fully learning the time information because the temporal patterns of user preference are usually heterogeneous. A user's preference for a particular item may 1) increase periodically or 2) evolve over time under the influence of significant recent events, and each of these two kinds of temporal pattern appears with some unique characteristics. In this paper, we first define the unique characteristics of the two kinds of temporal pattern of user preference that should be considered in time-aware recommender systems. Then we propose a novel recommender system for timely recommendations, called TimelyRec, which jointly learns the heterogeneous temporal patterns of user preference considering all of the defined characteristics. In TimelyRec, a cascade of two encoders captures the temporal patterns of user preference using a proposed attention module for each encoder. Moreover, we introduce an evaluation scenario that evaluates the performance on predicting an interesting item and when to recommend the item simultaneously in top-K recommendation (i.e., item-timing recommendation). Our extensive experiments on a scenario for item recommendation and the proposed scenario for item-timing recommendation on real-world datasets demonstrate the superiority of TimelyRec and the proposed attention modules.
On Parameter Optimization and Reach Enhancement for the Improved Soft-Aided Staircase Decoder
May 12, 2021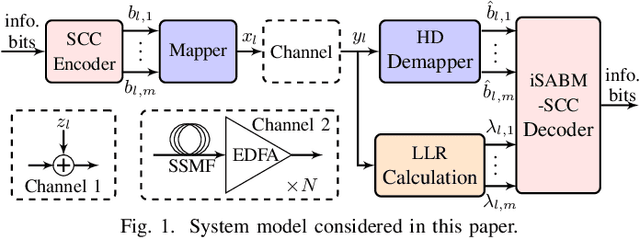
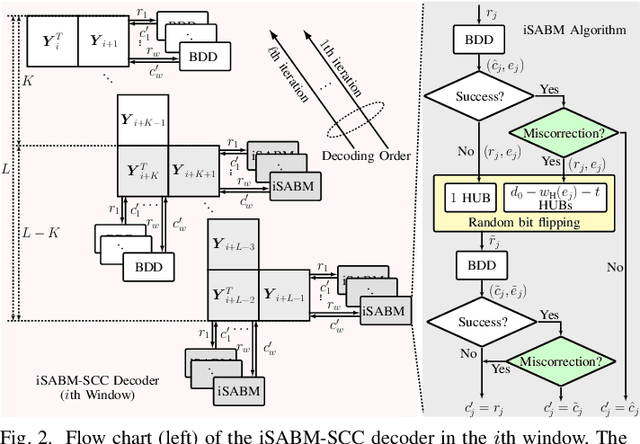
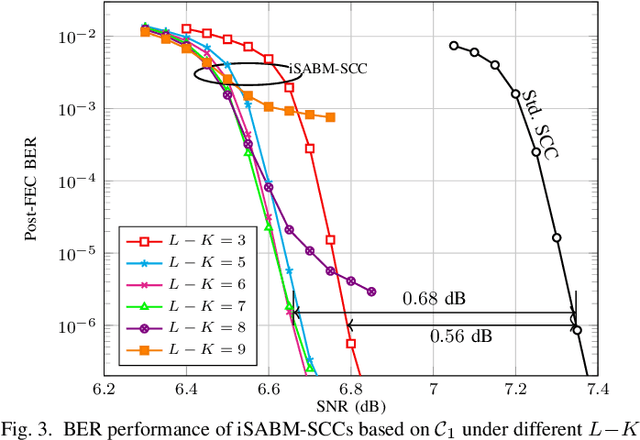
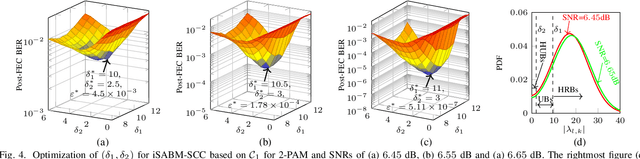
The so-called improved soft-aided bit-marking algorithm was recently proposed for staircase codes (SCCs) in the context of fiber optical communications. This algorithm is known as iSABM-SCC. With the help of channel soft information, the iSABM-SCC decoder marks bits via thresholds to deal with both miscorrections and failures of hard-decision (HD) decoding. In this paper, we study iSABM-SCC focusing on the parameter optimization of the algorithm and its performance analysis, in terms of the gap to the achievable information rates (AIRs) of HD codes and the fiber reach enhancement. We show in this paper that the marking thresholds and the number of modified component decodings heavily affect the performance of iSABM-SCC, and thus, they need to be carefully optimized. By replacing standard decoding with the optimized iSABM-SCC decoding, the gap to the AIRs of HD codes can be reduced to 0.26-1.02 dB for code rates of 0.74-0.87 in the additive white Gaussian noise channel with 8-ary pulse amplitude modulation. The obtained reach increase is up to 22% for data rates between 401 Gbps and 468 Gbps in an optical fiber channel.
Neural Architecture Search From Fréchet Task Distance
Mar 25, 2021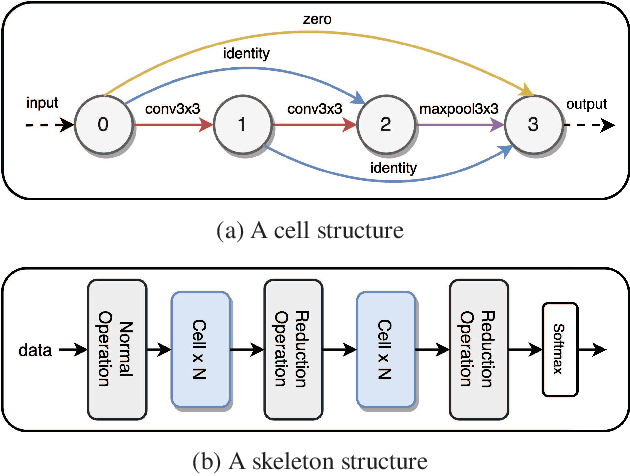
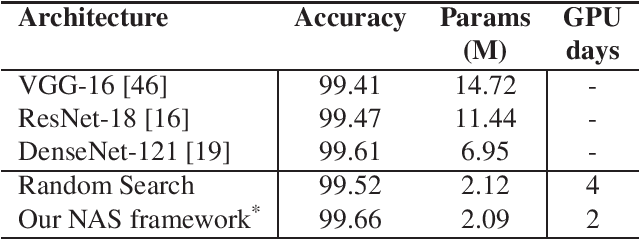
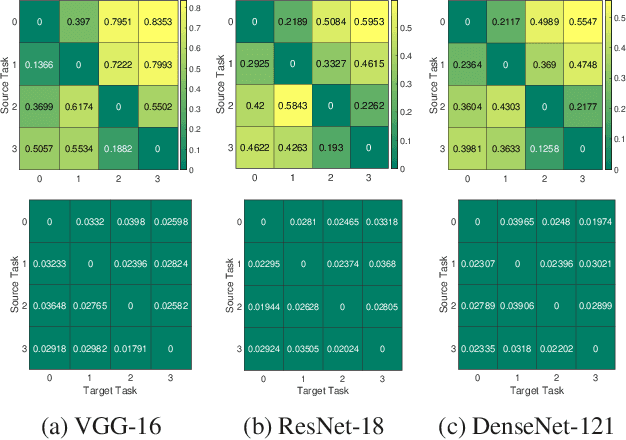
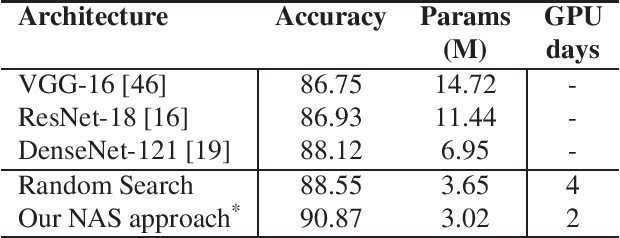
We formulate a Fr\'echet-type asymmetric distance between tasks based on Fisher Information Matrices. We show how the distance between a target task and each task in a given set of baseline tasks can be used to reduce the neural architecture search space for the target task. The complexity reduction in search space for task-specific architectures is achieved by building on the optimized architectures for similar tasks instead of doing a full search without using this side information. Experimental results demonstrate the efficacy of the proposed approach and its improvements over the state-of-the-art methods.
Physics-informed Dyna-Style Model-Based Deep Reinforcement Learning for Dynamic Control
Jul 31, 2021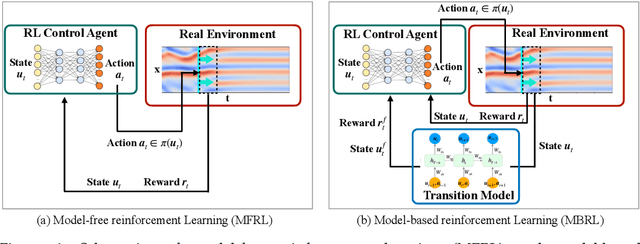

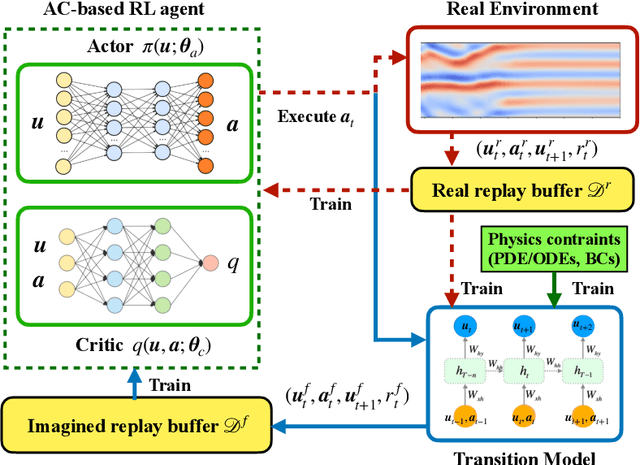

Model-based reinforcement learning (MBRL) is believed to have much higher sample efficiency compared to model-free algorithms by learning a predictive model of the environment. However, the performance of MBRL highly relies on the quality of the learned model, which is usually built in a black-box manner and may have poor predictive accuracy outside of the data distribution. The deficiencies of the learned model may prevent the policy from being fully optimized. Although some uncertainty analysis-based remedies have been proposed to alleviate this issue, model bias still poses a great challenge for MBRL. In this work, we propose to leverage the prior knowledge of underlying physics of the environment, where the governing laws are (partially) known. In particular, we developed a physics-informed MBRL framework, where governing equations and physical constraints are utilized to inform the model learning and policy search. By incorporating the prior information of the environment, the quality of the learned model can be notably improved, while the required interactions with the environment are significantly reduced, leading to better sample efficiency and learning performance. The effectiveness and merit have been demonstrated over a handful of classic control problems, where the environments are governed by canonical ordinary/partial differential equations.
Reservoir Stack Machines
May 04, 2021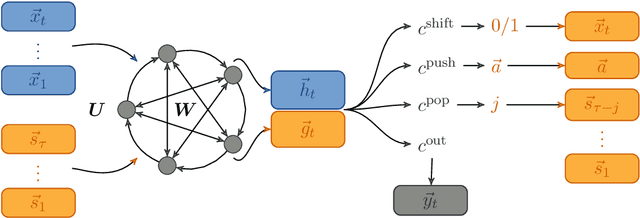

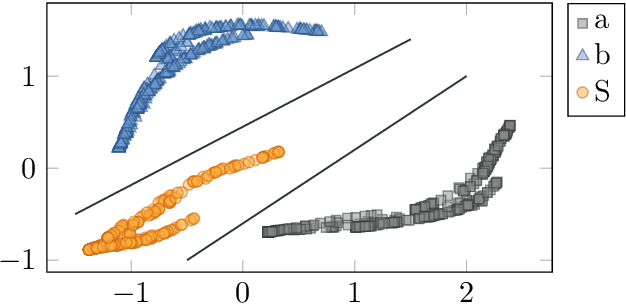
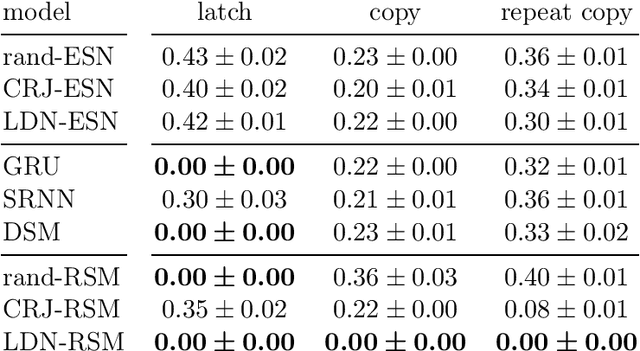
Memory-augmented neural networks equip a recurrent neural network with an explicit memory to support tasks that require information storage without interference over long times. A key motivation for such research is to perform classic computation tasks, such as parsing. However, memory-augmented neural networks are notoriously hard to train, requiring many backpropagation epochs and a lot of data. In this paper, we introduce the reservoir stack machine, a model which can provably recognize all deterministic context-free languages and circumvents the training problem by training only the output layer of a recurrent net and employing auxiliary information during training about the desired interaction with a stack. In our experiments, we validate the reservoir stack machine against deep and shallow networks from the literature on three benchmark tasks for Neural Turing machines and six deterministic context-free languages. Our results show that the reservoir stack machine achieves zero error, even on test sequences longer than the training data, requiring only a few seconds of training time and 100 training sequences.
Supervised Neural Networks for Illiquid Alternative Asset Cash Flow Forecasting
Aug 05, 2021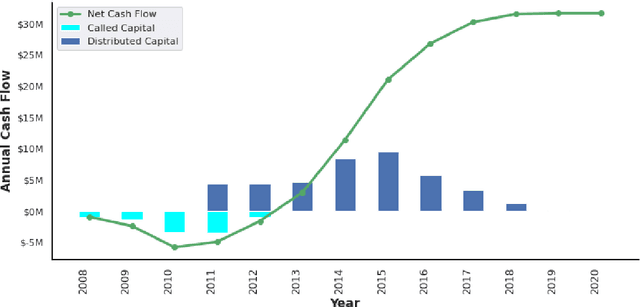
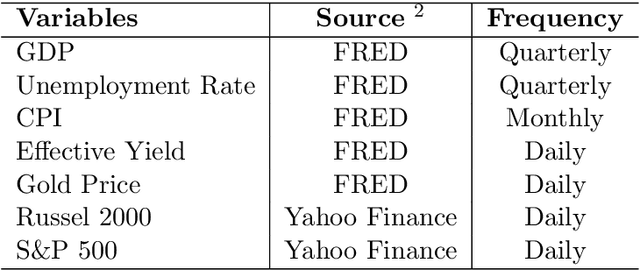
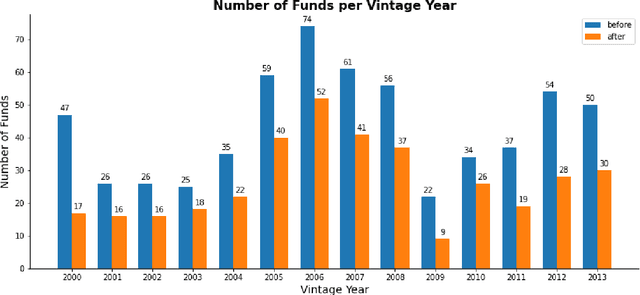
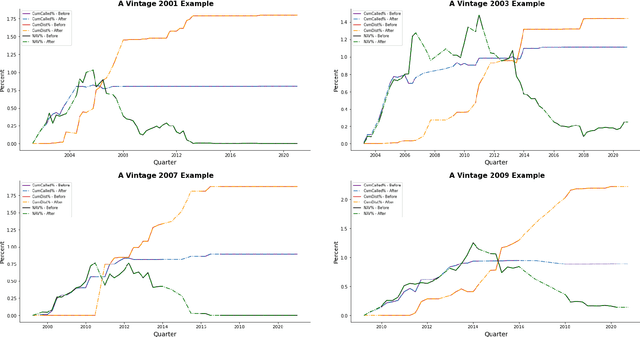
Institutional investors have been increasing the allocation of the illiquid alternative assets such as private equity funds in their portfolios, yet there exists a very limited literature on cash flow forecasting of illiquid alternative assets. The net cash flow of private equity funds typically follow a J-curve pattern, however the timing and the size of the contributions and distributions depend on the investment opportunities. In this paper, we develop a benchmark model and present two novel approaches (direct vs. indirect) to predict the cash flows of private equity funds. We introduce a sliding window approach to apply on our cash flow data because different vintage year funds contain different lengths of cash flow information. We then pass the data to an LSTM/ GRU model to predict the future cash flows either directly or indirectly (based on the benchmark model). We further integrate macroeconomic indicators into our data, which allows us to consider the impact of market environment on cash flows and to apply stress testing. Our results indicate that the direct model is easier to implement compared to the benchmark model and the indirect model, but still the predicted cash flows align better with the actual cash flows. We also show that macroeconomic variables improve the performance of the direct model whereas the impact is not obvious on the indirect model.
Efficient Vision Transformers via Fine-Grained Manifold Distillation
Jul 06, 2021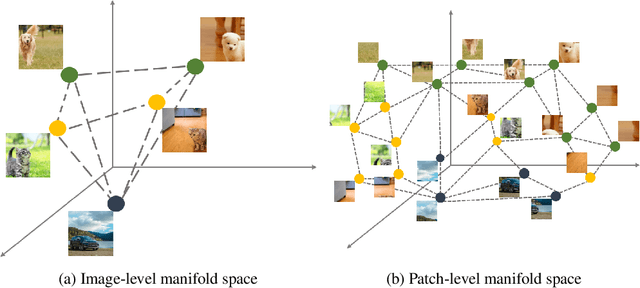
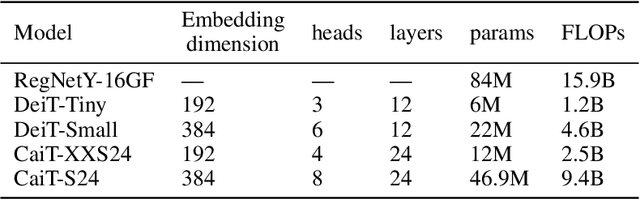
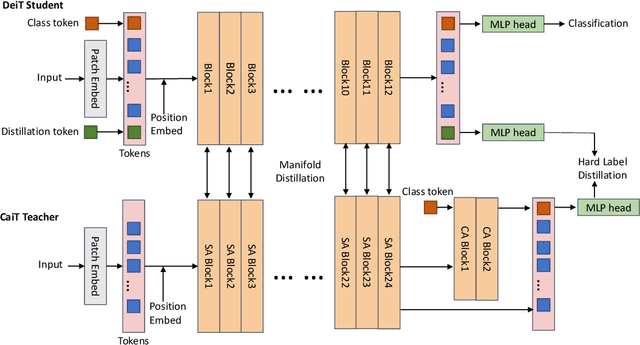
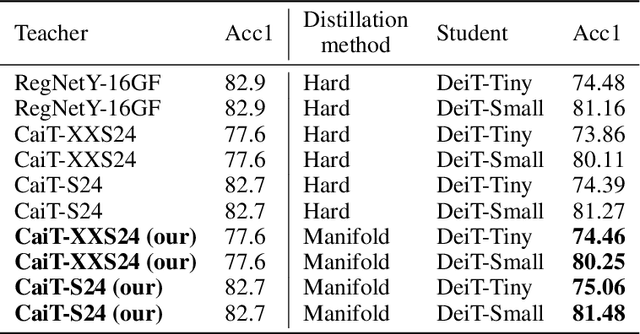
This paper studies the model compression problem of vision transformers. Benefit from the self-attention module, transformer architectures have shown extraordinary performance on many computer vision tasks. Although the network performance is boosted, transformers are often required more computational resources including memory usage and the inference complexity. Compared with the existing knowledge distillation approaches, we propose to excavate useful information from the teacher transformer through the relationship between images and the divided patches. We then explore an efficient fine-grained manifold distillation approach that simultaneously calculates cross-images, cross-patch, and random-selected manifolds in teacher and student models. Experimental results conducted on several benchmarks demonstrate the superiority of the proposed algorithm for distilling portable transformer models with higher performance. For example, our approach achieves 75.06% Top-1 accuracy on the ImageNet-1k dataset for training a DeiT-Tiny model, which outperforms other ViT distillation methods.
Coded Federated Learning Framework for AI-Based Mobile Application Services with Privacy-Awareness
Jun 17, 2021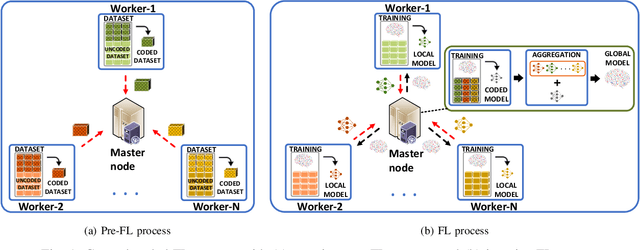
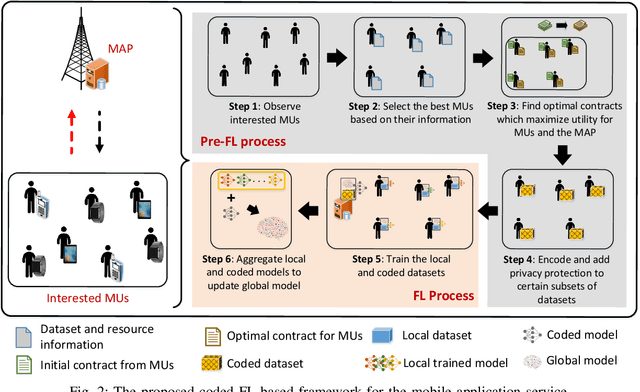
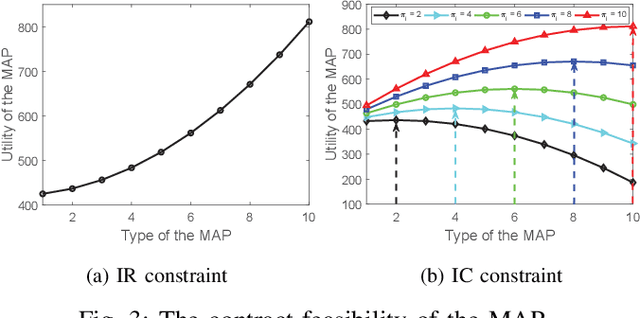
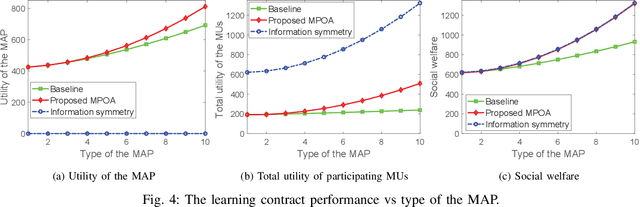
By encoding computing tasks, coded computing can not only mitigate straggling problems in federated learning (FL), but also preserve privacy of sensitive data uploaded/contributed by participating mobile users (MUs) to the centralized server, owned by a mobile application provider (MAP). However, these advantages come with extra coding cost/complexity and communication overhead (referred to as \emph{privacy cost}) that must be considered given the limited computing/communications resources at MUs/MAP, the rationality and incentive competition among MUs in contributing data to the MAP. This article proposes a novel coded FL-based framework for a privacy-aware mobile application service to address these challenges. In particular, the MAP first determines a set of the best MUs for the FL process based on MUs' provided information/features. Then, each selected MU can propose a contract to the MAP according to its expected trainable local data and privacy-protected coded data. To find the optimal contracts that can maximize utilities of the MAP and all the participating MUs while maintaining high learning quality of the whole system, we first develop a multi-principal one-agent contract-based problem leveraging coded FL-based multiple utility functions under the MUs' privacy cost, the MAP's limited computing resource, and asymmetric information between the MAP and MUs. Then, we transform the problem into an equivalent low-complexity problem and develop an iterative algorithm to solve it. Experiments with a real-world dataset show that our framework can speed up training time up to 49% and improve prediction accuracy up to 4.6 times while enhancing network's social welfare, i.e., total utility of all participating entities, up to 114% under the privacy cost consideration compared with those of baseline methods.