 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
TeCANet: Temporal-Contextual Attention Network for Environment-Aware Speech Dereverberation
Mar 31, 2021
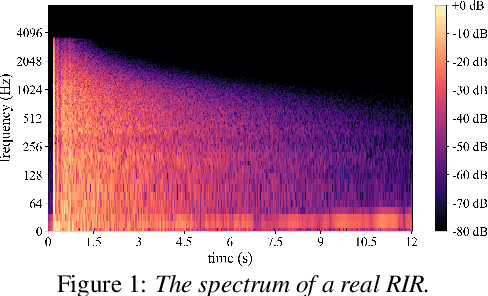
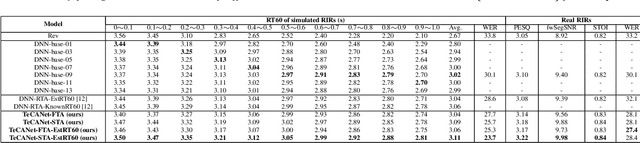
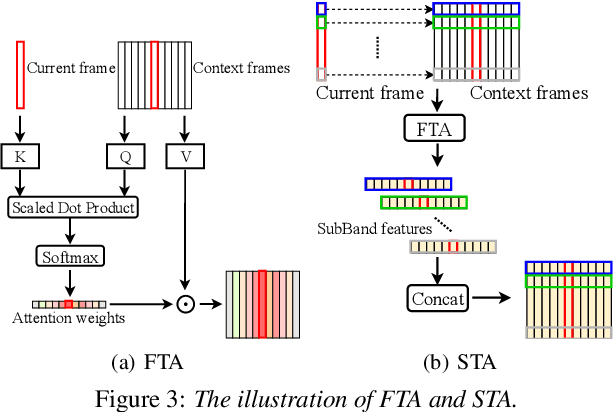
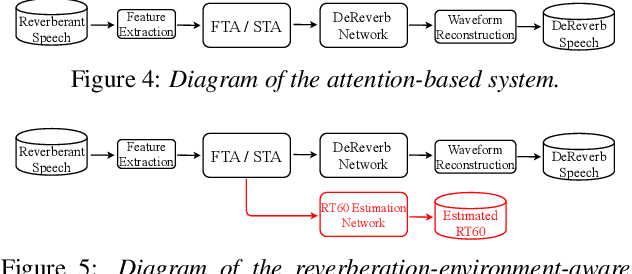
In this paper, we exploit the effective way to leverage contextual information to improve the speech dereverberation performance in real-world reverberant environments. We propose a temporal-contextual attention approach on the deep neural network (DNN) for environment-aware speech dereverberation, which can adaptively attend to the contextual information. More specifically, a FullBand based Temporal Attention approach (FTA) is proposed, which models the correlations between the fullband information of the context frames. In addition, considering the difference between the attenuation of high frequency bands and low frequency bands (high frequency bands attenuate faster than low frequency bands) in the room impulse response (RIR), we also propose a SubBand based Temporal Attention approach (STA). In order to guide the network to be more aware of the reverberant environments, we jointly optimize the dereverberation network and the reverberation time (RT60) estimator in a multi-task manner. Our experimental results indicate that the proposed method outperforms our previously proposed reverberation-time-aware DNN and the learned attention weights are fully physical consistent. We also report a preliminary yet promising dereverberation and recognition experiment on real test data.
High-resolution Depth Maps Imaging via Attention-based Hierarchical Multi-modal Fusion
Apr 13, 2021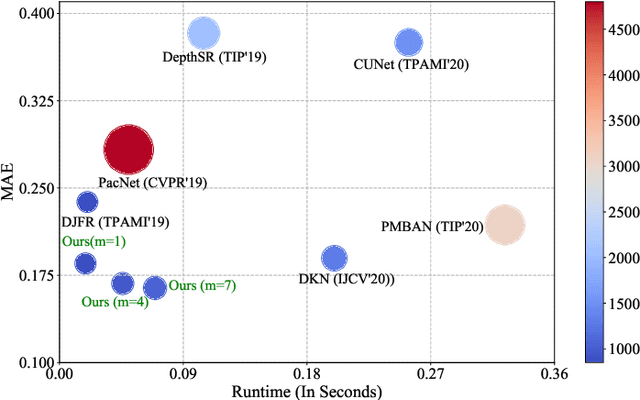

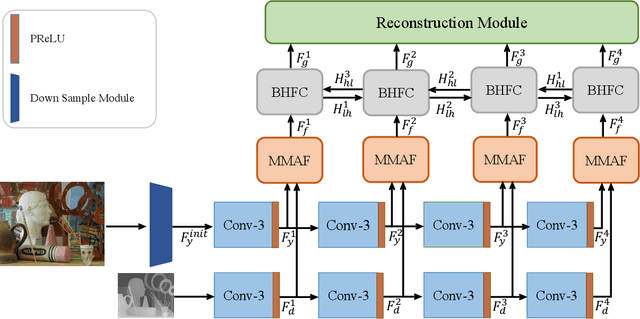
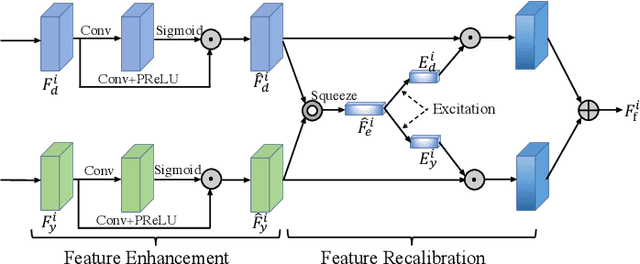
Depth map records distance between the viewpoint and objects in the scene, which plays a critical role in many real-world applications. However, depth map captured by consumer-grade RGB-D cameras suffers from low spatial resolution. Guided depth map super-resolution (DSR) is a popular approach to address this problem, which attempts to restore a high-resolution (HR) depth map from the input low-resolution (LR) depth and its coupled HR RGB image that serves as the guidance. The most challenging problems for guided DSR are how to correctly select consistent structures and propagate them, and properly handle inconsistent ones. In this paper, we propose a novel attention-based hierarchical multi-modal fusion (AHMF) network for guided DSR. Specifically, to effectively extract and combine relevant information from LR depth and HR guidance, we propose a multi-modal attention based fusion (MMAF) strategy for hierarchical convolutional layers, including a feature enhance block to select valuable features and a feature recalibration block to unify the similarity metrics of modalities with different appearance characteristics. Furthermore, we propose a bi-directional hierarchical feature collaboration (BHFC) module to fully leverage low-level spatial information and high-level structure information among multi-scale features. Experimental results show that our approach outperforms state-of-the-art methods in terms of reconstruction accuracy, running speed and memory efficiency.
Exploring the Diversity and Invariance in Yourself for Visual Pre-Training Task
Jun 01, 2021
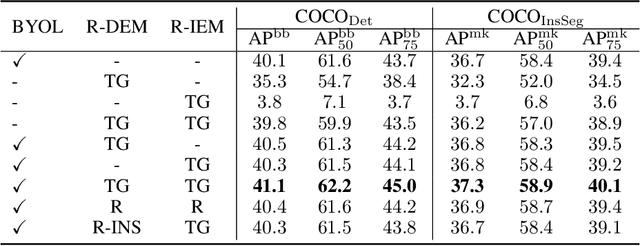
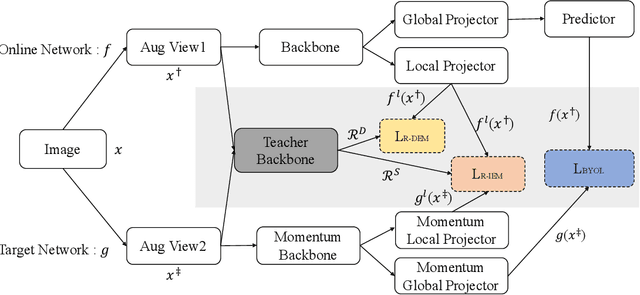
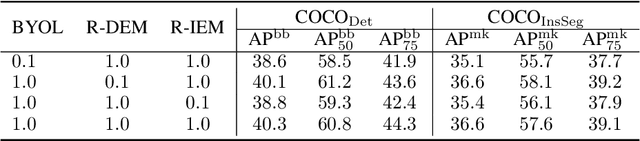
Recently, self-supervised learning methods have achieved remarkable success in visual pre-training task. By simply pulling the different augmented views of each image together or other novel mechanisms, they can learn much unsupervised knowledge and significantly improve the transfer performance of pre-training models. However, these works still cannot avoid the representation collapse problem, i.e., they only focus on limited regions or the extracted features on totally different regions inside each image are nearly the same. Generally, this problem makes the pre-training models cannot sufficiently describe the multi-grained information inside images, which further limits the upper bound of their transfer performance. To alleviate this issue, this paper introduces a simple but effective mechanism, called Exploring the Diversity and Invariance in Yourself E-DIY. By simply pushing the most different regions inside each augmented view away, E-DIY can preserve the diversity of extracted region-level features. By pulling the most similar regions from different augmented views of the same image together, E-DIY can ensure the robustness of region-level features. Benefited from the above diversity and invariance exploring mechanism, E-DIY maximally extracts the multi-grained visual information inside each image. Extensive experiments on downstream tasks demonstrate the superiority of our proposed approach, e.g., there are 2.1% improvements compared with the strong baseline BYOL on COCO while fine-tuning Mask R-CNN with the R50-C4 backbone and 1X learning schedule.
Graph-Based Topological Exploration Planning in Large-Scale 3D Environments
Mar 31, 2021
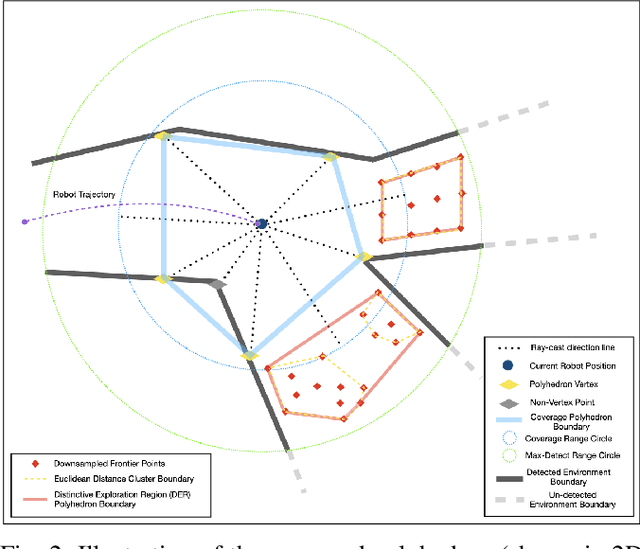
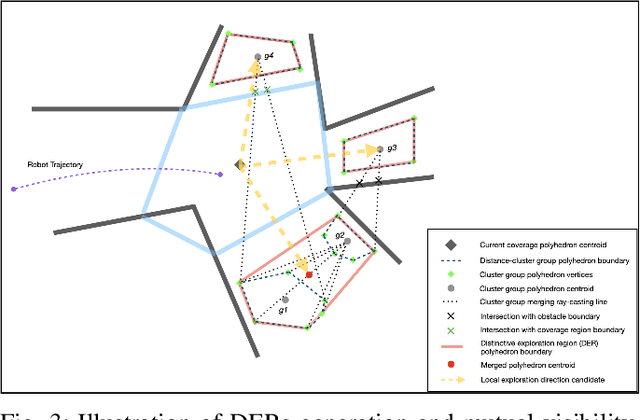
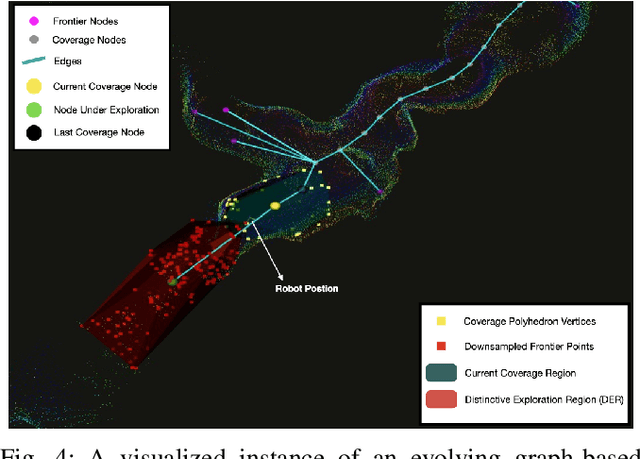
Currently, state-of-the-art exploration methods maintain high-resolution map representations in order to optimize exploration goals in each step that maximizes information gain. However, during exploring, those "optimal" selections could quickly become obsolete due to the influx of new information, especially in large-scale environments, and result in high-frequency re-planning that hinders the overall exploration efficiency. In this paper, we propose a graph-based topological planning framework, building a sparse topological map in three-dimensional (3D) space to guide exploration steps with high-level intents so as to render consistent exploration maneuvers. Specifically, this work presents a novel method to estimate 3D space's geometry with convex polyhedrons. Then, the geometry information is utilized to group space into distinctive regions. And those regions are added as nodes into the topological map, directing the exploration process. We compared our method with the state-of-the-art in simulated environments. The proposed method achieves higher space coverage and outperforms exploration efficiency by more than 40% during experiments. Finally, a field experiment was conducted to further evaluate the applicability of our method to empower efficient and robust exploration in real-world environments.
BasicVSR++: Improving Video Super-Resolution with Enhanced Propagation and Alignment
Apr 27, 2021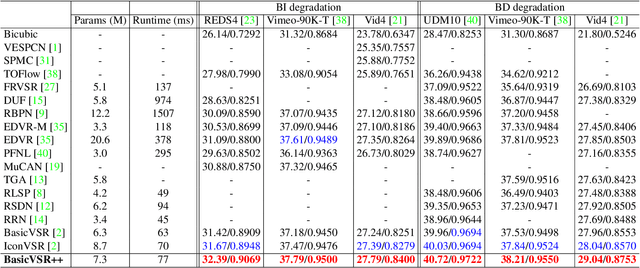
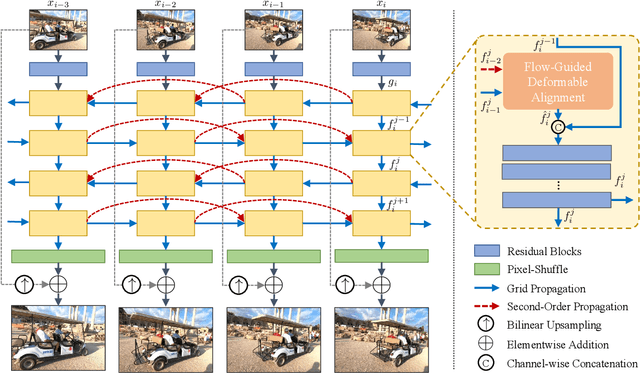

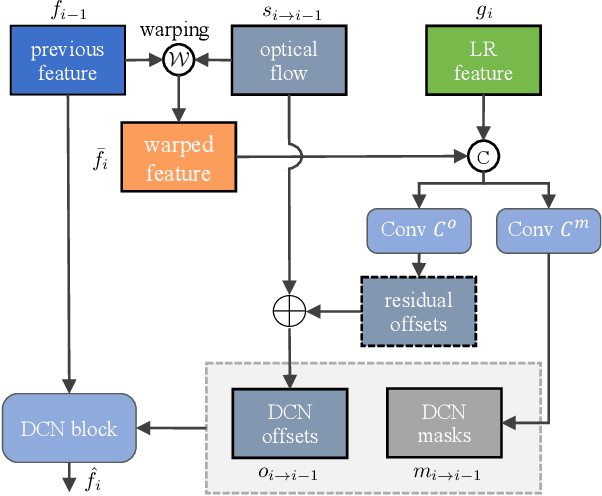
A recurrent structure is a popular framework choice for the task of video super-resolution. The state-of-the-art method BasicVSR adopts bidirectional propagation with feature alignment to effectively exploit information from the entire input video. In this study, we redesign BasicVSR by proposing second-order grid propagation and flow-guided deformable alignment. We show that by empowering the recurrent framework with the enhanced propagation and alignment, one can exploit spatiotemporal information across misaligned video frames more effectively. The new components lead to an improved performance under a similar computational constraint. In particular, our model BasicVSR++ surpasses BasicVSR by 0.82 dB in PSNR with similar number of parameters. In addition to video super-resolution, BasicVSR++ generalizes well to other video restoration tasks such as compressed video enhancement. In NTIRE 2021, BasicVSR++ obtains three champions and one runner-up in the Video Super-Resolution and Compressed Video Enhancement Challenges. Codes and models will be released to MMEditing.
Study of Joint Activity Detection and Channel Estimation Based on Message Passing with RBP Scheduling for MTC
Jun 13, 2021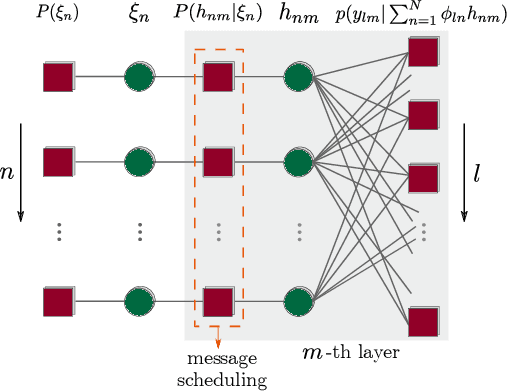
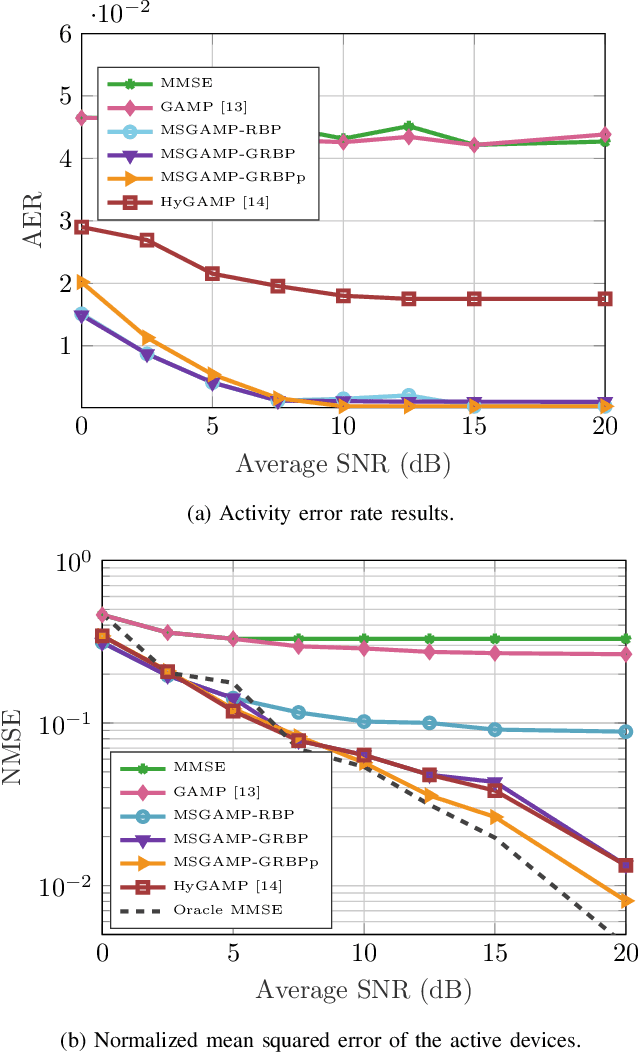
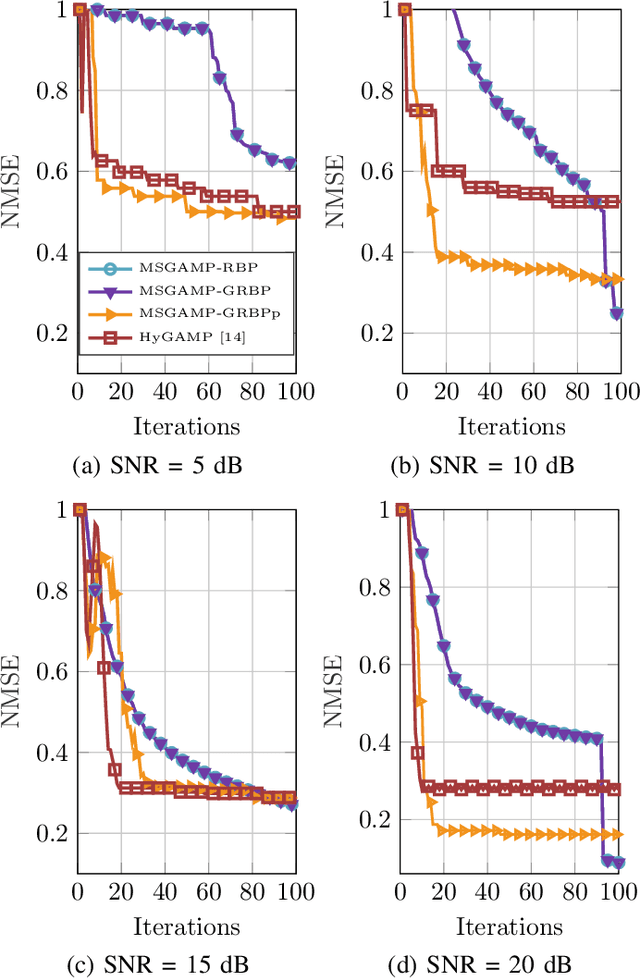
In this work, based on the hybrid generalized approximate message passing (HyGAMP) algorithm, we propose the message-scheduling GAMP (MSGAMP) algorithm in order to address the problem of joint active device detection and channel estimation in an uplink grant-free massive MIMO system scenario. In MSGAMP, we apply three different scheduling techniques based on the Residual Belief Propagation (RBP) in which messages are generated using the latest available information. With a much lower computational cost than the state-of-the-art algorithms, MSGAMP-type schemes exhibits good performance in terms of activity error rate and normalized mean squared error, requiring a small number of iterations for convergence. %
Joint Characterization of Spatiotemporal Data Manifolds
Aug 21, 2021Spatiotemporal (ST) image data are increasingly common and often high-dimensional (high-D). Modeling ST data can be a challenge due to the plethora of independent and interacting processes which may or may not contribute to the measurements. Characterization can be considered the complement to modeling by helping guide assumptions about generative processes and their representation in the data. Dimensionality reduction (DR) is a frequently implemented type of characterization designed to mitigate the "curse of dimensionality" on high-D signals. For decades, Principal Component (PC) and Empirical Orthogonal Function (EOF) analysis has been used as a linear, invertible approach to DR and ST analysis. Recent years have seen the additional development of a suite of nonlinear DR algorithms, frequently categorized as "manifold learning". Here, we explore the idea of joint characterization of ST data manifolds using PCs/EOFs alongside two nonlinear DR approaches: Laplacian Eigenmaps (LE) and t-distributed stochastic neighbor embedding (t-SNE). Starting with a synthetic example and progressing to global, regional, and field scale ST datasets spanning roughly 5 orders of magnitude in space and 2 in time, we show these three DR approaches can yield complementary information about ST manifold topology. Compared to the relatively diffuse TFS produced by PCs/EOFs, the nonlinear approaches yield more compact manifolds with decreased ambiguity in temporal endmembers (LE) and/or in spatiotemporal clustering (t-SNE). These properties are compensated by the greater interpretability, significantly lower computational demand and diminished sensitivity to spatial aliasing for PCs/EOFs than LE or t-SNE. Taken together, we find joint characterization using the three complementary DR approaches capable of greater insight into generative ST processes than possible using any single approach alone.
Generalized Visual Information Analysis via Tensorial Algebra
Jan 31, 2020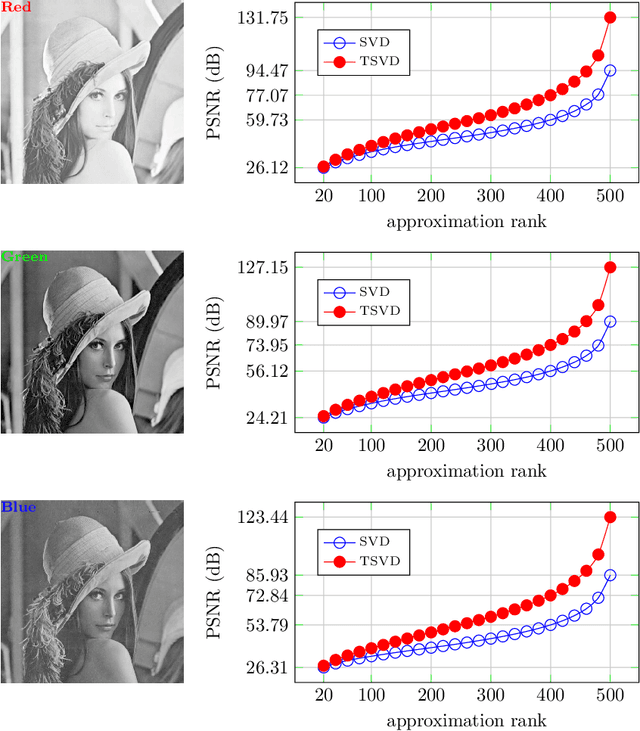
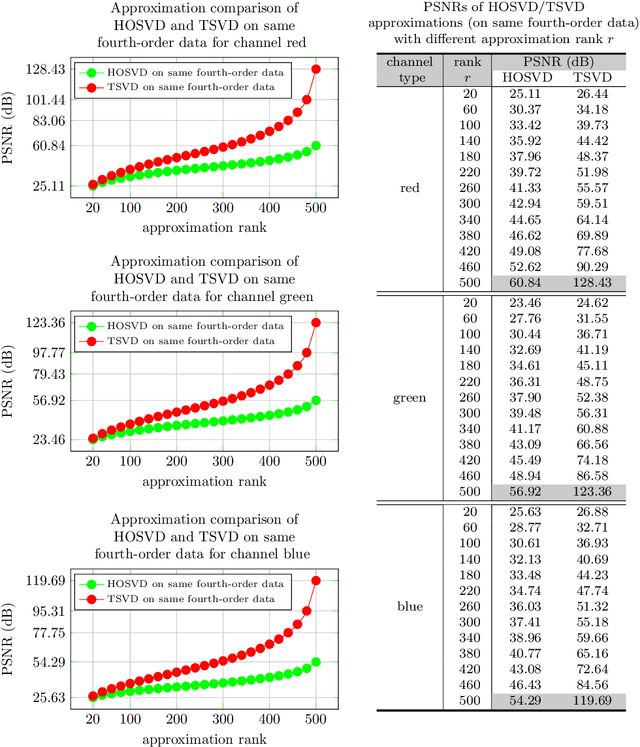
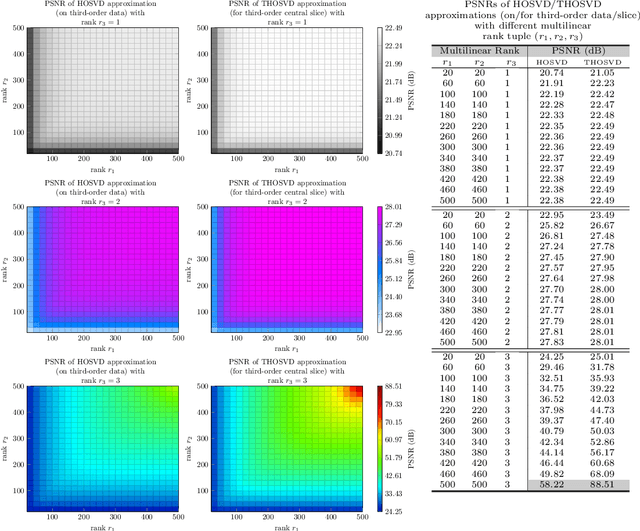
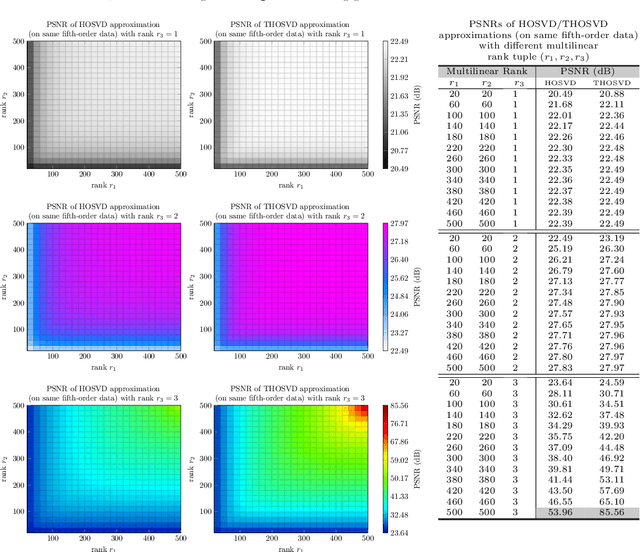
High order data is modeled using matrices whose entries are numerical arrays of a fixed size. These arrays, called t-scalars, form a commutative ring under the convolution product. Matrices with elements in the ring of t-scalars are referred to as t-matrices. The t-matrices can be scaled, added and multiplied in the usual way. There are t-matrix generalizations of positive matrices, orthogonal matrices and Hermitian symmetric matrices. With the t-matrix model, it is possible to generalize many well-known matrix algorithms. In particular, the t-matrices are used to generalize the SVD (Singular Value Decomposition), HOSVD (High Order SVD), PCA (Principal Component Analysis), 2DPCA (Two Dimensional PCA) and GCA (Grassmannian Component Analysis). The generalized t-matrix algorithms, namely TSVD, THOSVD,TPCA, T2DPCA and TGCA, are applied to low-rank approximation, reconstruction,and supervised classification of images. Experiments show that the t-matrix algorithms compare favorably with standard matrix algorithms.
Unsupervised Deep Clustering for Source Separation: Direct Learning from Mixtures using Spatial Information
Nov 05, 2018



We present a monophonic source separation system that is trained by only observing mixtures with no ground truth separation information. We use a deep clustering approach which trains on multi-channel mixtures and learns to project spectrogram bins to source clusters that correlate with various spatial features. We show that using such a training process we can obtain separation performance that is as good as making use of ground truth separation information. Once trained, this system is capable of performing sound separation on monophonic inputs, despite having learned how to do so using multi-channel recordings.
Wiki-Reliability: A Large Scale Dataset for Content Reliability on Wikipedia
Jun 01, 2021

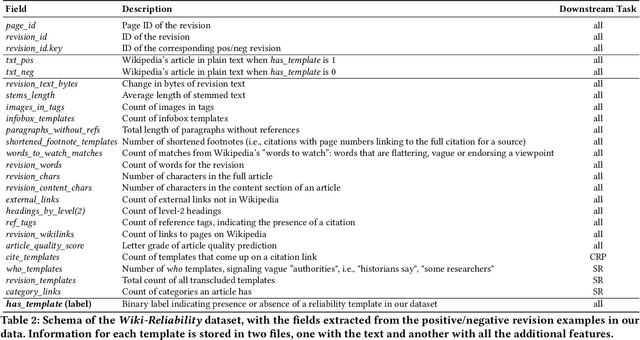
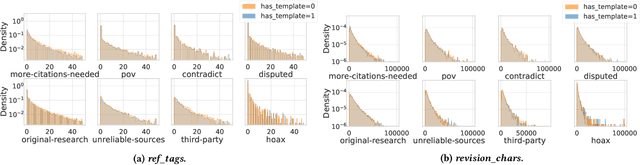
Wikipedia is the largest online encyclopedia, used by algorithms and web users as a central hub of reliable information on the web. The quality and reliability of Wikipedia content is maintained by a community of volunteer editors. Machine learning and information retrieval algorithms could help scale up editors' manual efforts around Wikipedia content reliability. However, there is a lack of large-scale data to support the development of such research. To fill this gap, in this paper, we propose Wiki-Reliability, the first dataset of English Wikipedia articles annotated with a wide set of content reliability issues. To build this dataset, we rely on Wikipedia "templates". Templates are tags used by expert Wikipedia editors to indicate content issues, such as the presence of "non-neutral point of view" or "contradictory articles", and serve as a strong signal for detecting reliability issues in a revision. We select the 10 most popular reliability-related templates on Wikipedia, and propose an effective method to label almost 1M samples of Wikipedia article revisions as positive or negative with respect to each template. Each positive/negative example in the dataset comes with the full article text and 20 features from the revision's metadata. We provide an overview of the possible downstream tasks enabled by such data, and show that Wiki-Reliability can be used to train large-scale models for content reliability prediction. We release all data and code for public use.