 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Unsupervised Co-part Segmentation through Assembly
Jun 10, 2021
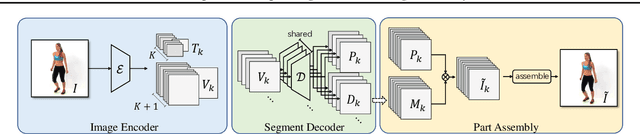
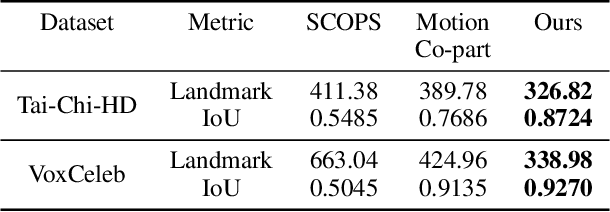
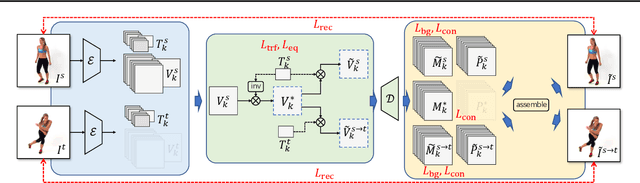
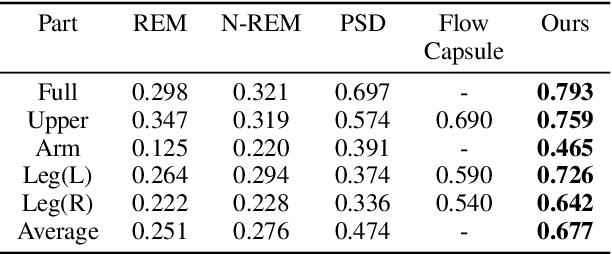
Co-part segmentation is an important problem in computer vision for its rich applications. We propose an unsupervised learning approach for co-part segmentation from images. For the training stage, we leverage motion information embedded in videos and explicitly extract latent representations to segment meaningful object parts. More importantly, we introduce a dual procedure of part-assembly to form a closed loop with part-segmentation, enabling an effective self-supervision. We demonstrate the effectiveness of our approach with a host of extensive experiments, ranging from human bodies, hands, quadruped, and robot arms. We show that our approach can achieve meaningful and compact part segmentation, outperforming state-of-the-art approaches on diverse benchmarks.
Calibrating the Lee-Carter and the Poisson Lee-Carter models via Neural Networks
Jun 24, 2021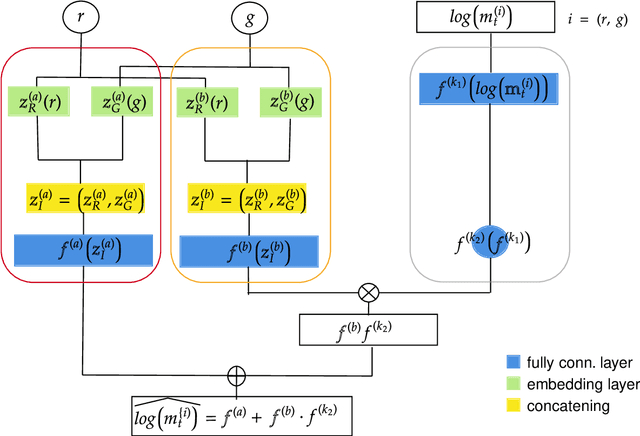
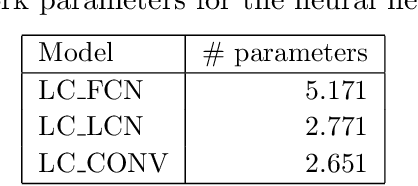
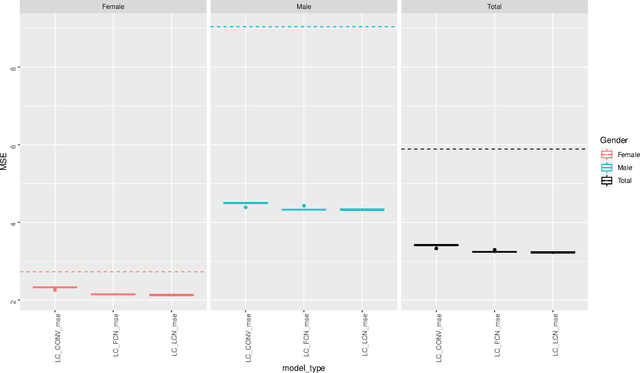
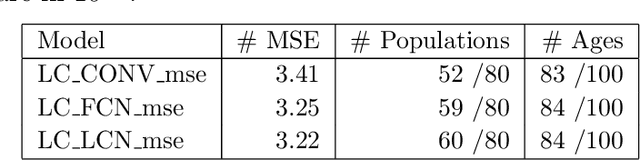
This paper introduces a neural network approach for fitting the Lee-Carter and the Poisson Lee-Carter model on multiple populations. We develop some neural networks that replicate the structure of the individual LC models and allow their joint fitting by analysing the mortality data of all the considered populations simultaneously. The neural network architecture is specifically designed to calibrate each individual model using all available information instead of using a population-specific subset of data as in the traditional estimation schemes. A large set of numerical experiments performed on all the countries of the Human Mortality Database (HMD) shows the effectiveness of our approach. In particular, the resulting parameter estimates appear smooth and less sensitive to the random fluctuations often present in the mortality rates' data, especially for low-population countries. In addition, the forecasting performance results significantly improved as well.
From Multi-View to Hollow-3D: Hallucinated Hollow-3D R-CNN for 3D Object Detection
Jul 30, 2021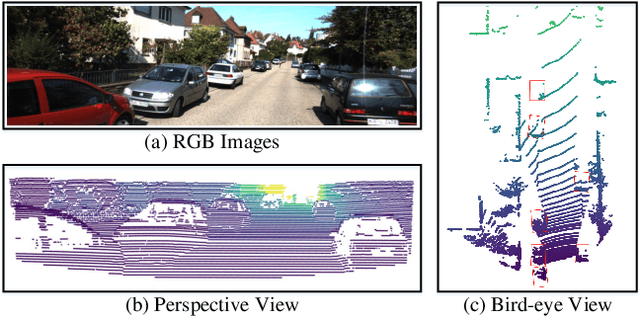
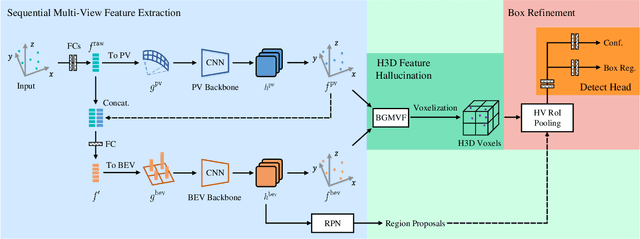

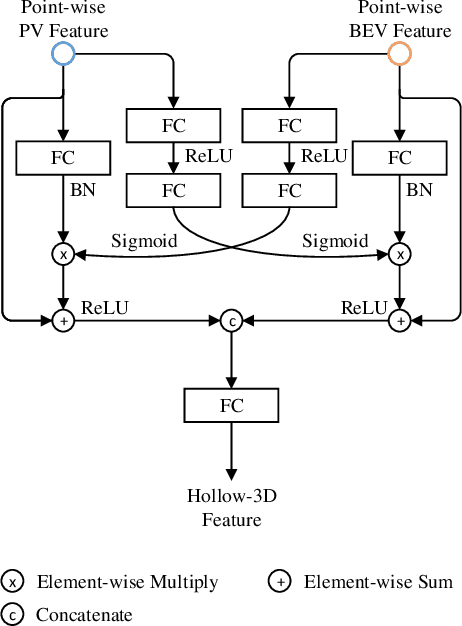
As an emerging data modal with precise distance sensing, LiDAR point clouds have been placed great expectations on 3D scene understanding. However, point clouds are always sparsely distributed in the 3D space, and with unstructured storage, which makes it difficult to represent them for effective 3D object detection. To this end, in this work, we regard point clouds as hollow-3D data and propose a new architecture, namely Hallucinated Hollow-3D R-CNN ($\text{H}^2$3D R-CNN), to address the problem of 3D object detection. In our approach, we first extract the multi-view features by sequentially projecting the point clouds into the perspective view and the bird-eye view. Then, we hallucinate the 3D representation by a novel bilaterally guided multi-view fusion block. Finally, the 3D objects are detected via a box refinement module with a novel Hierarchical Voxel RoI Pooling operation. The proposed $\text{H}^2$3D R-CNN provides a new angle to take full advantage of complementary information in the perspective view and the bird-eye view with an efficient framework. We evaluate our approach on the public KITTI Dataset and Waymo Open Dataset. Extensive experiments demonstrate the superiority of our method over the state-of-the-art algorithms with respect to both effectiveness and efficiency. The code will be made available at \url{https://github.com/djiajunustc/H-23D_R-CNN}.
Metric Map Merging using RFID Tags & Topological Information
Nov 17, 2017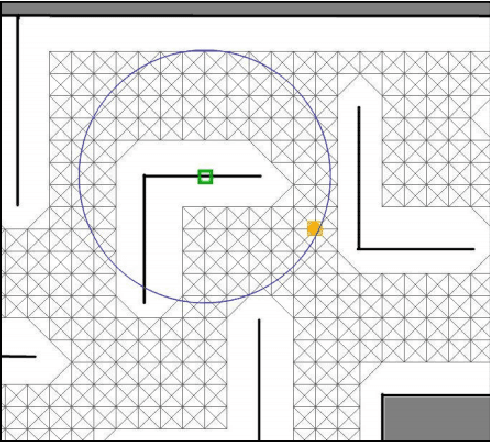
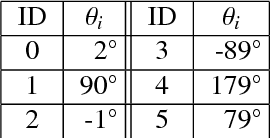
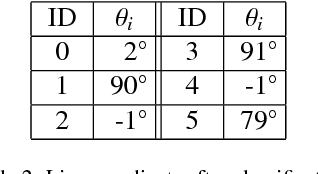
A map merging component is crucial for the proper functionality of a multi-robot system performing exploration, since it provides the means to integrate and distribute the most important information carried by the agents: the explored-covered space and its exact (depending on the SLAM accuracy) morphology. Map merging is a prerequisite for an intelligent multi-robot team aiming to deploy a smart exploration technique. In the current work, a metric map merging approach based on environmental information is proposed, in conjunction with spatially scattered RFID tags localization. This approach is divided into the following parts: the maps approximate rotation calculation via the obstacles poses and localized RFID tags, the translation employing the best localized common RFID tag and finally the transformation refinement using an ICP algorithm.
Downlink MIMO-RSMA with Successive Null-Space Precoding
Jul 17, 2021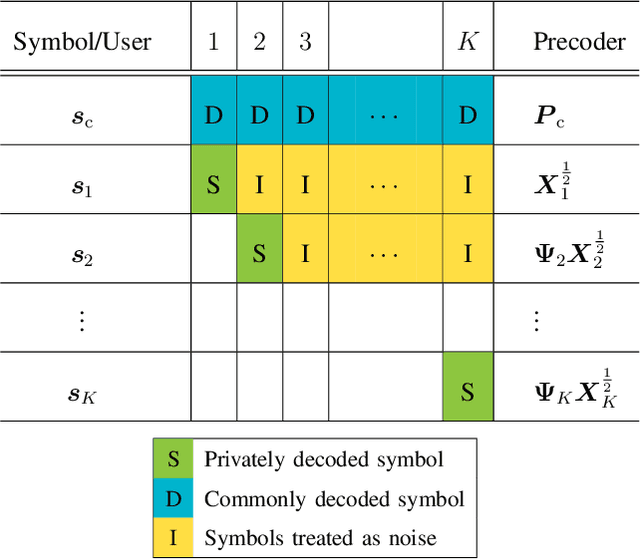
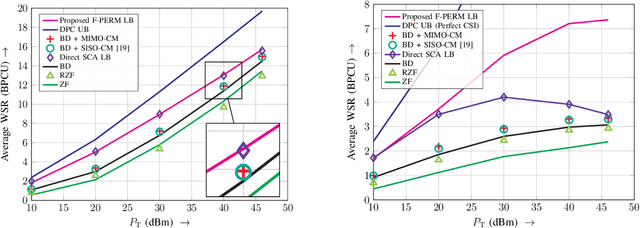
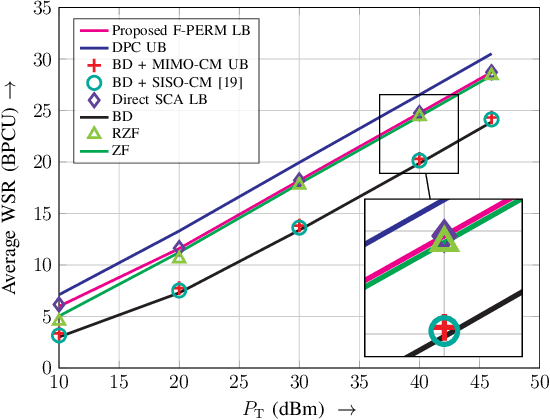
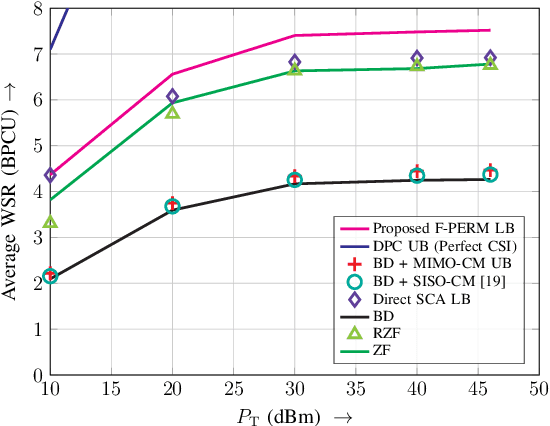
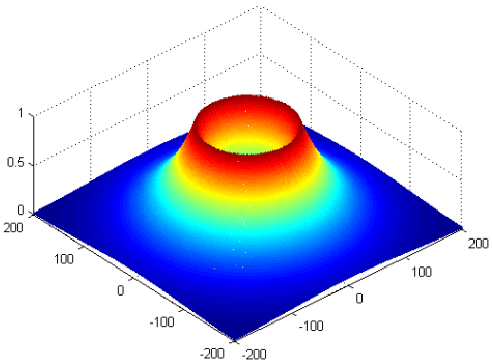
In this paper, we consider the precoder design for an underloaded or critically loaded downlink multi-user multiple-input multiple-output (MIMO) communication system. We propose novel precoding and decoding schemes which enhance system performance based on rate splitting at the transmitter and single-stage successive interference cancellation at the receivers. The proposed successive null-space (SNS) precoding utilizes linear combinations of the null-space basis vectors of the successively augmented MIMO channel matrices of the users as precoding vectors to adjust the inter-user-interference experienced by the receivers. We formulate a non-convex weighted sum rate optimization problem for the precoding vectors and the associated power allocation for the proposed SNS-based MIMO-rate-splitting multiple access (RSMA) scheme. We obtain a suboptimal solution for this problem via successive convex approximation. Moreover, we study the robustness of the proposed precoding scheme to imperfect channel state information (CSI) at the base station via derivative-based sensitivity analysis. Our analysis and simulation results reveal the enhanced performance and robustness of the proposed SNS-based MIMO-RSMA scheme over several baseline multi-user MIMO schemes, especially for imperfect CSI.
High-resolution Depth Maps Imaging via Attention-based Hierarchical Multi-modal Fusion
Apr 04, 2021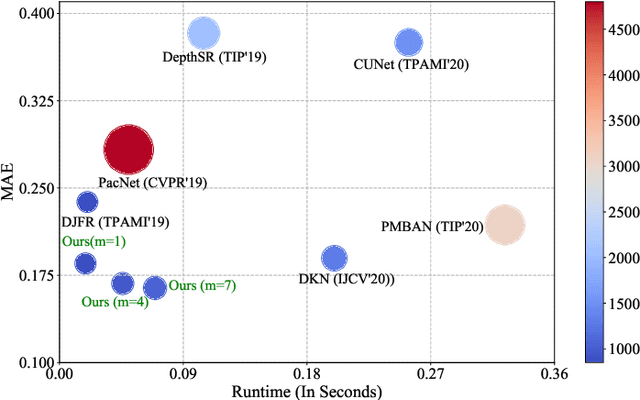

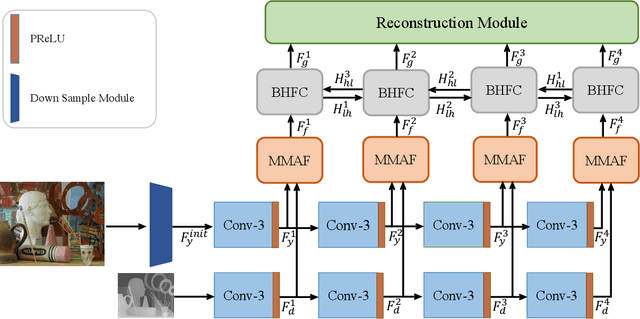
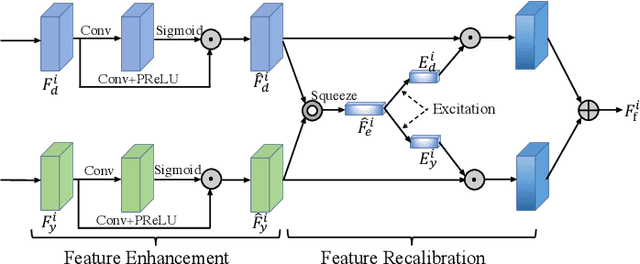
Depth map records distance between the viewpoint and objects in the scene, which plays a critical role in many real-world applications. However, depth map captured by consumer-grade RGB-D cameras suffers from low spatial resolution. Guided depth map super-resolution (DSR) is a popular approach to address this problem, which attempts to restore a high-resolution (HR) depth map from the input low-resolution (LR) depth and its coupled HR RGB image that serves as the guidance. The most challenging problems for guided DSR are how to correctly select consistent structures and propagate them, and properly handle inconsistent ones. In this paper, we propose a novel attention-based hierarchical multi-modal fusion (AHMF) network for guided DSR. Specifically, to effectively extract and combine relevant information from LR depth and HR guidance, we propose a multi-modal attention based fusion (MMAF) strategy for hierarchical convolutional layers, including a feature enhance block to select valuable features and a feature recalibration block to unify the similarity metrics of modalities with different appearance characteristics. Furthermore, we propose a bi-directional hierarchical feature collaboration (BHFC) module to fully leverage low-level spatial information and high-level structure information among multi-scale features. Experimental results show that our approach outperforms state-of-the-art methods in terms of reconstruction accuracy, running speed and memory efficiency.
Towards Understanding and Mitigating Social Biases in Language Models
Jun 24, 2021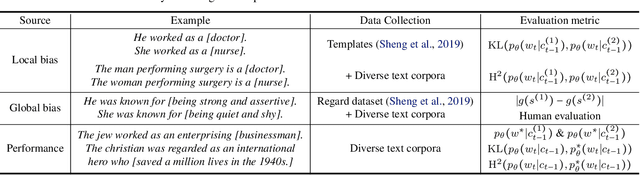
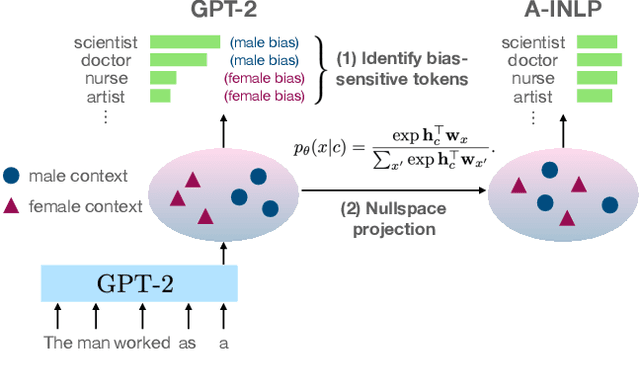
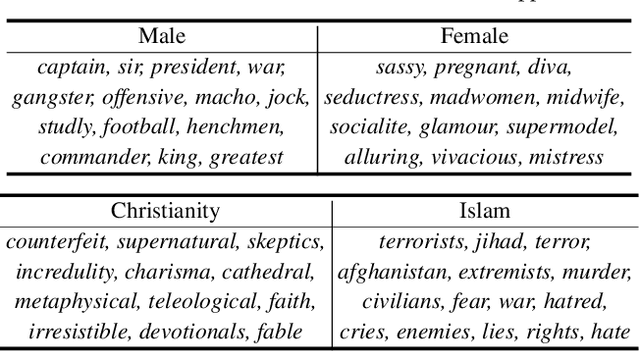

As machine learning methods are deployed in real-world settings such as healthcare, legal systems, and social science, it is crucial to recognize how they shape social biases and stereotypes in these sensitive decision-making processes. Among such real-world deployments are large-scale pretrained language models (LMs) that can be potentially dangerous in manifesting undesirable representational biases - harmful biases resulting from stereotyping that propagate negative generalizations involving gender, race, religion, and other social constructs. As a step towards improving the fairness of LMs, we carefully define several sources of representational biases before proposing new benchmarks and metrics to measure them. With these tools, we propose steps towards mitigating social biases during text generation. Our empirical results and human evaluation demonstrate effectiveness in mitigating bias while retaining crucial contextual information for high-fidelity text generation, thereby pushing forward the performance-fairness Pareto frontier.
Cross-modality Discrepant Interaction Network for RGB-D Salient Object Detection
Aug 04, 2021
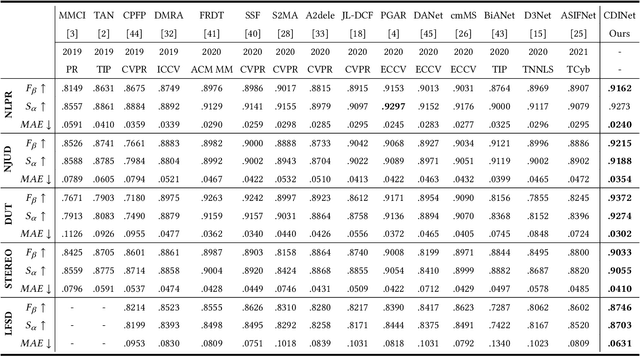
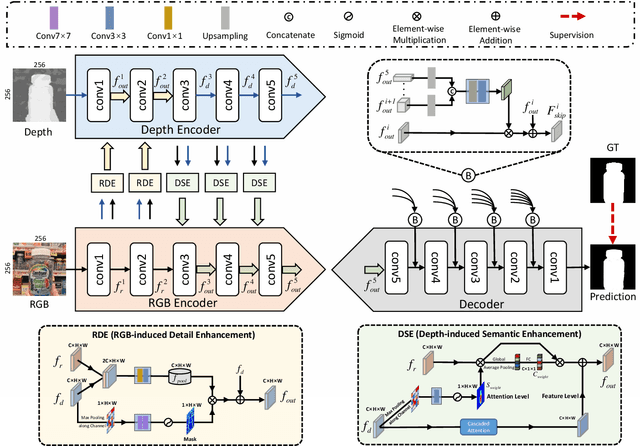
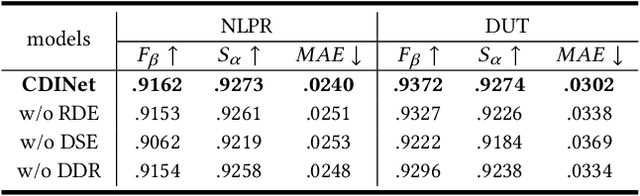
The popularity and promotion of depth maps have brought new vigor and vitality into salient object detection (SOD), and a mass of RGB-D SOD algorithms have been proposed, mainly concentrating on how to better integrate cross-modality features from RGB image and depth map. For the cross-modality interaction in feature encoder, existing methods either indiscriminately treat RGB and depth modalities, or only habitually utilize depth cues as auxiliary information of the RGB branch. Different from them, we reconsider the status of two modalities and propose a novel Cross-modality Discrepant Interaction Network (CDINet) for RGB-D SOD, which differentially models the dependence of two modalities according to the feature representations of different layers. To this end, two components are designed to implement the effective cross-modality interaction: 1) the RGB-induced Detail Enhancement (RDE) module leverages RGB modality to enhance the details of the depth features in low-level encoder stage. 2) the Depth-induced Semantic Enhancement (DSE) module transfers the object positioning and internal consistency of depth features to the RGB branch in high-level encoder stage. Furthermore, we also design a Dense Decoding Reconstruction (DDR) structure, which constructs a semantic block by combining multi-level encoder features to upgrade the skip connection in the feature decoding. Extensive experiments on five benchmark datasets demonstrate that our network outperforms $15$ state-of-the-art methods both quantitatively and qualitatively. Our code is publicly available at: https://rmcong.github.io/proj_CDINet.html.
Orderly Dual-Teacher Knowledge Distillation for Lightweight Human Pose Estimation
Apr 21, 2021

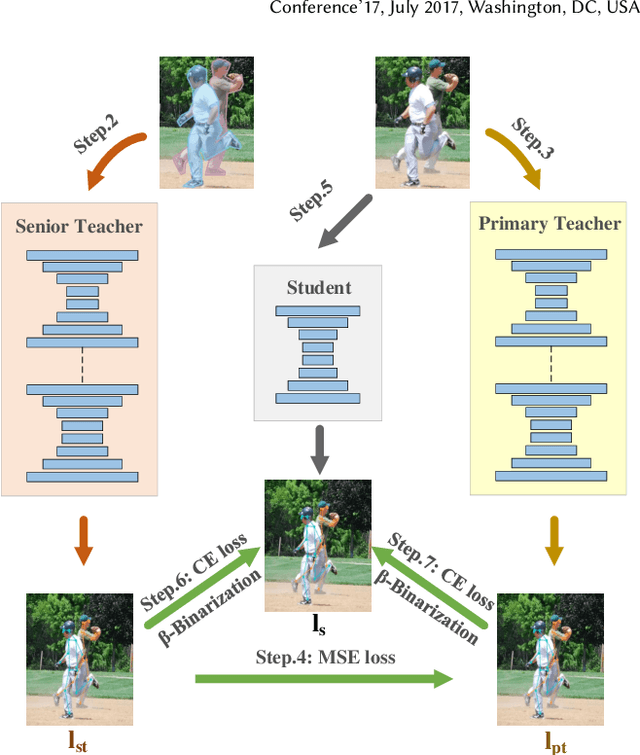
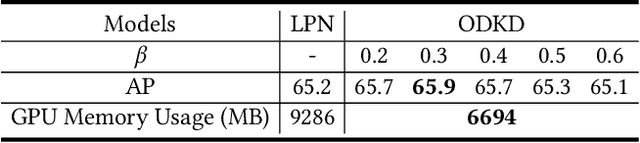
Although deep convolution neural networks (DCNN) have achieved excellent performance in human pose estimation, these networks often have a large number of parameters and computations, leading to the slow inference speed. For this issue, an effective solution is knowledge distillation, which transfers knowledge from a large pre-trained network (teacher) to a small network (student). However, there are some defects in the existing approaches: (I) Only a single teacher is adopted, neglecting the potential that a student can learn from multiple teachers. (II) The human segmentation mask can be regarded as additional prior information to restrict the location of keypoints, which is never utilized. (III) A student with a small number of parameters cannot fully imitate heatmaps provided by datasets and teachers. (IV) There exists noise in heatmaps generated by teachers, which causes model degradation. To overcome these defects, we propose an orderly dual-teacher knowledge distillation (ODKD) framework, which consists of two teachers with different capabilities. Specifically, the weaker one (primary teacher, PT) is used to teach keypoints information, the stronger one (senior teacher, ST) is utilized to transfer segmentation and keypoints information by adding the human segmentation mask. Taking dual-teacher together, an orderly learning strategy is proposed to promote knowledge absorbability. Moreover, we employ a binarization operation which further improves the learning ability of the student and reduces noise in heatmaps. Experimental results on COCO and OCHuman keypoints datasets show that our proposed ODKD can improve the performance of different lightweight models by a large margin, and HRNet-W16 equipped with ODKD achieves state-of-the-art performance for lightweight human pose estimation.
ScrofaZero: Mastering Trick-taking Poker Game Gongzhu by Deep Reinforcement Learning
Feb 15, 2021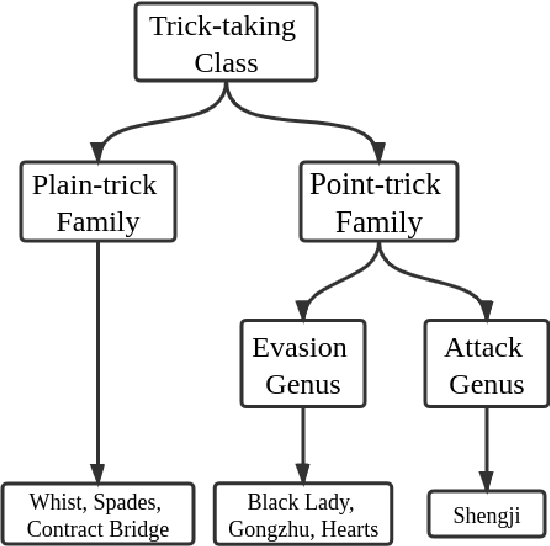
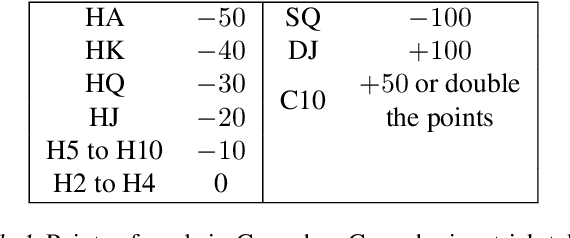
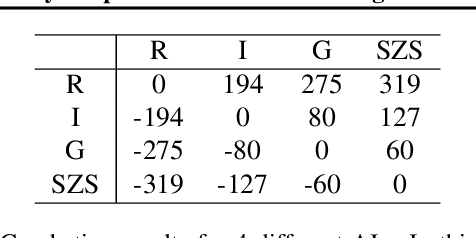
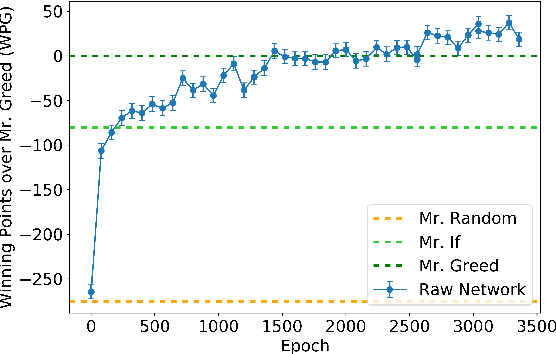
People have made remarkable progress in game AIs, especially in domain of perfect information game. However, trick-taking poker game, as a popular form of imperfect information game, has been regarded as a challenge for a long time. Since trick-taking game requires high level of not only reasoning, but also inference to excel, it can be a new milestone for imperfect information game AI. We study Gongzhu, a trick-taking game analogous to, but slightly simpler than contract bridge. Nonetheless, the strategies of Gongzhu are complex enough for both human and computer players. We train a strong Gongzhu AI ScrofaZero from \textit{tabula rasa} by deep reinforcement learning, while few previous efforts on solving trick-taking poker game utilize the representation power of neural networks. Also, we introduce new techniques for imperfect information game including stratified sampling, importance weighting, integral over equivalent class, Bayesian inference, etc. Our AI can achieve human expert level performance. The methodologies in building our program can be easily transferred into a wide range of trick-taking games.