 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Exploiting the relationship between visual and textual features in social networks for image classification with zero-shot deep learning
Jul 08, 2021
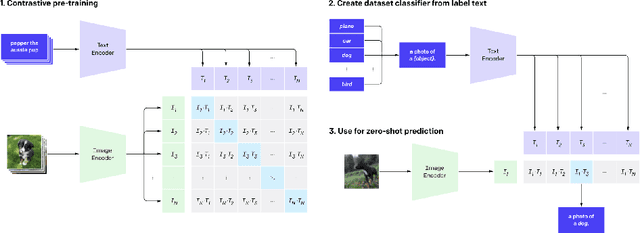


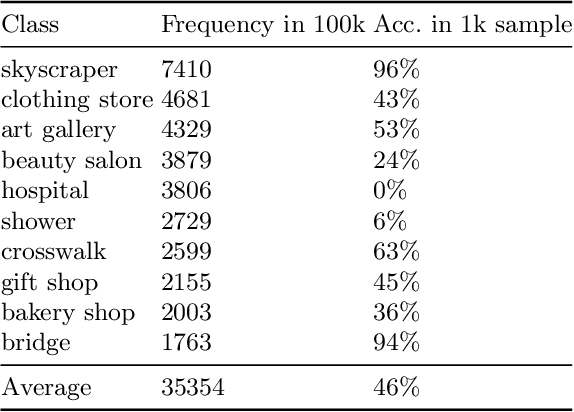
One of the main issues related to unsupervised machine learning is the cost of processing and extracting useful information from large datasets. In this work, we propose a classifier ensemble based on the transferable learning capabilities of the CLIP neural network architecture in multimodal environments (image and text) from social media. For this purpose, we used the InstaNY100K dataset and proposed a validation approach based on sampling techniques. Our experiments, based on image classification tasks according to the labels of the Places dataset, are performed by first considering only the visual part, and then adding the associated texts as support. The results obtained demonstrated that trained neural networks such as CLIP can be successfully applied to image classification with little fine-tuning, and considering the associated texts to the images can help to improve the accuracy depending on the goal. The results demonstrated what seems to be a promising research direction.
Measuring the impact of spammers on e-mail and Twitter networks
May 21, 2021
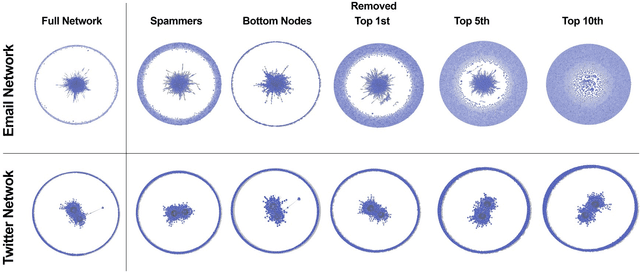

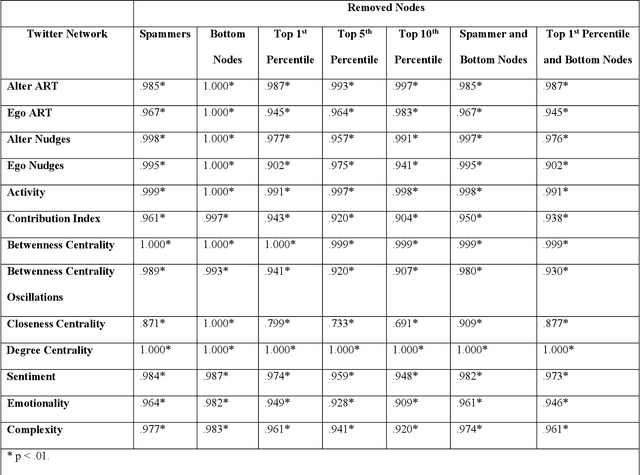
This paper investigates the research question if senders of large amounts of irrelevant or unsolicited information - commonly called "spammers" - distort the network structure of social networks. Two large social networks are analyzed, the first extracted from the Twitter discourse about a big telecommunication company, and the second obtained from three years of email communication of 200 managers working for a large multinational company. This work compares network robustness and the stability of centrality and interaction metrics, as well as the use of language, after removing spammers and the most and least connected nodes. The results show that spammers do not significantly alter the structure of the information-carrying network, for most of the social indicators. The authors additionally investigate the correlation between e-mail subject line and content by tracking language sentiment, emotionality, and complexity, addressing the cases where collecting email bodies is not permitted for privacy reasons. The findings extend the research about robustness and stability of social networks metrics, after the application of graph simplification strategies. The results have practical implication for network analysts and for those company managers who rely on network analytics (applied to company emails and social media data) to support their decision-making processes.
Multi-Scale Spectrogram Modelling for Neural Text-to-Speech
Jun 29, 2021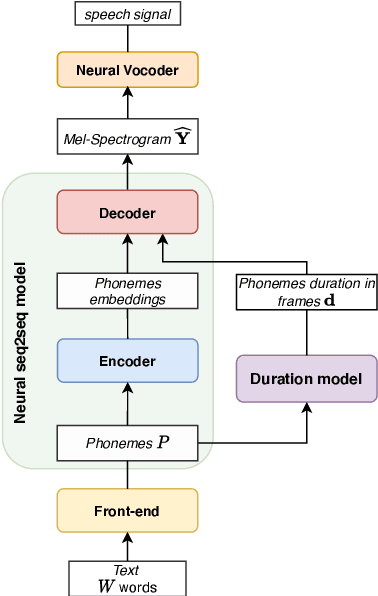
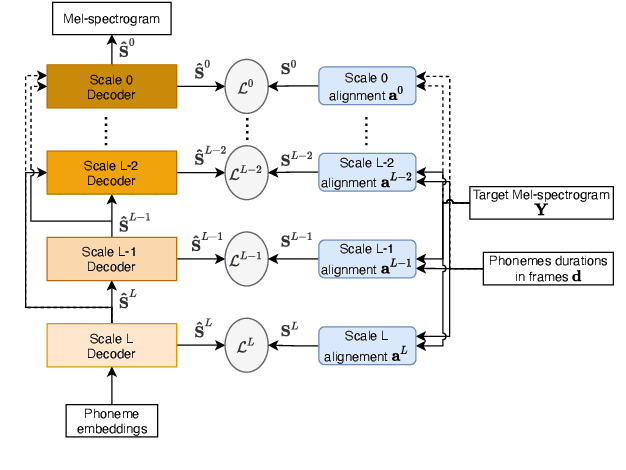
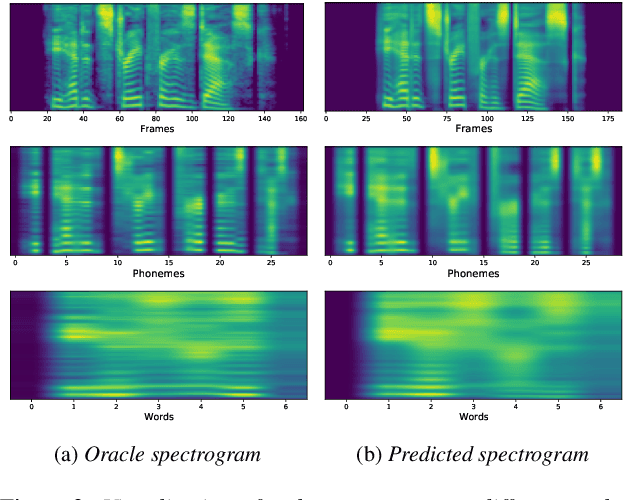
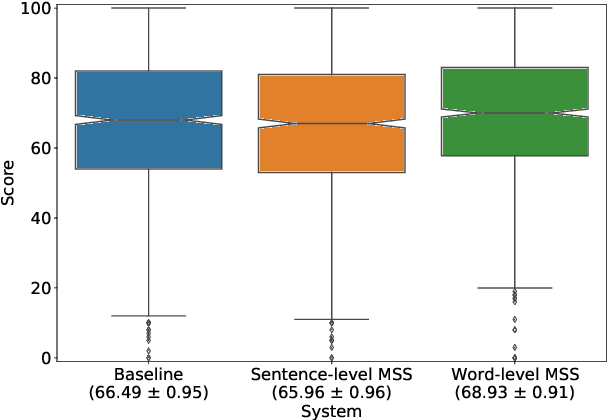
We propose a novel Multi-Scale Spectrogram (MSS) modelling approach to synthesise speech with an improved coarse and fine-grained prosody. We present a generic multi-scale spectrogram prediction mechanism where the system first predicts coarser scale mel-spectrograms that capture the suprasegmental information in speech, and later uses these coarser scale mel-spectrograms to predict finer scale mel-spectrograms capturing fine-grained prosody. We present details for two specific versions of MSS called Word-level MSS and Sentence-level MSS where the scales in our system are motivated by the linguistic units. The Word-level MSS models word, phoneme, and frame-level spectrograms while Sentence-level MSS models sentence-level spectrogram in addition. Subjective evaluations show that Word-level MSS performs statistically significantly better compared to the baseline on two voices.
Sparse-to-dense Feature Matching: Intra and Inter domain Cross-modal Learning in Domain Adaptation for 3D Semantic Segmentation
Aug 02, 2021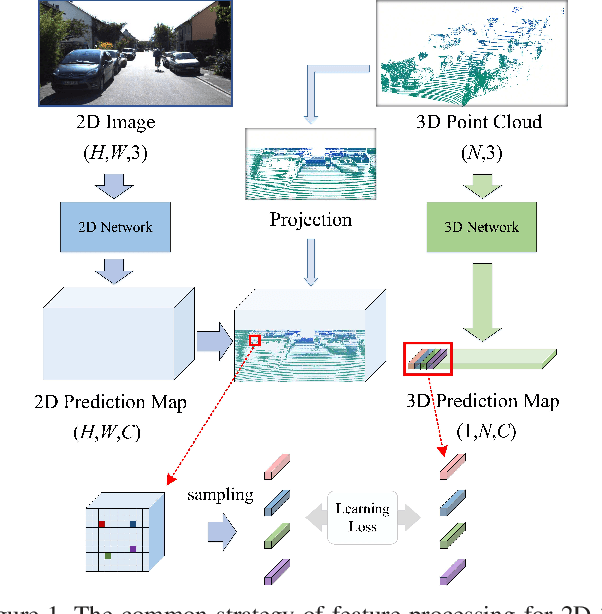
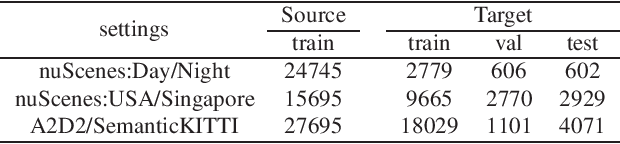
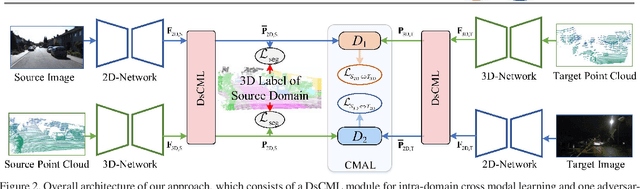
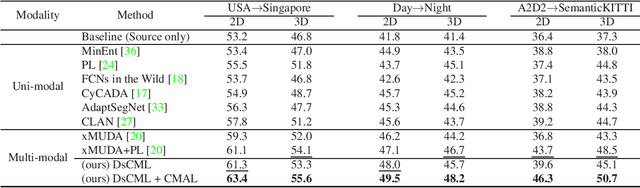
Domain adaptation is critical for success when confronting with the lack of annotations in a new domain. As the huge time consumption of labeling process on 3D point cloud, domain adaptation for 3D semantic segmentation is of great expectation. With the rise of multi-modal datasets, large amount of 2D images are accessible besides 3D point clouds. In light of this, we propose to further leverage 2D data for 3D domain adaptation by intra and inter domain cross modal learning. As for intra-domain cross modal learning, most existing works sample the dense 2D pixel-wise features into the same size with sparse 3D point-wise features, resulting in the abandon of numerous useful 2D features. To address this problem, we propose Dynamic sparse-to-dense Cross Modal Learning (DsCML) to increase the sufficiency of multi-modality information interaction for domain adaptation. For inter-domain cross modal learning, we further advance Cross Modal Adversarial Learning (CMAL) on 2D and 3D data which contains different semantic content aiming to promote high-level modal complementarity. We evaluate our model under various multi-modality domain adaptation settings including day-to-night, country-to-country and dataset-to-dataset, brings large improvements over both uni-modal and multi-modal domain adaptation methods on all settings.
Deep 3D-to-2D Watermarking: Embedding Messages in 3D Meshes and Extracting Them from 2D Renderings
Apr 29, 2021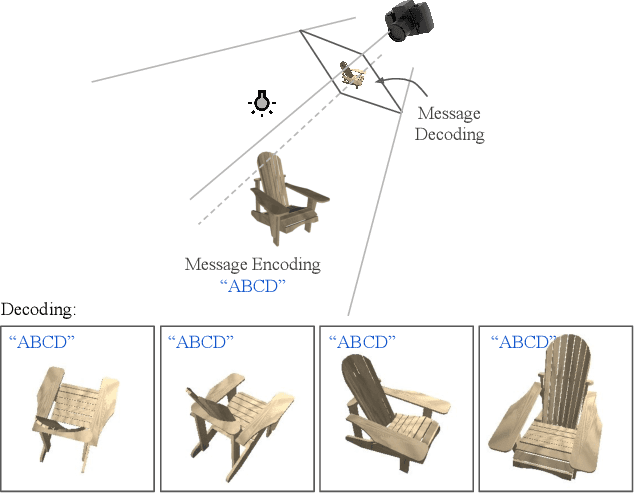
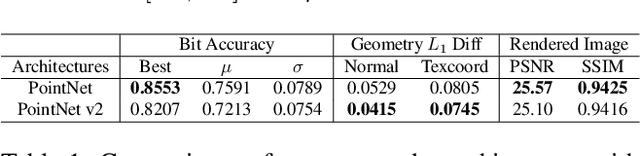
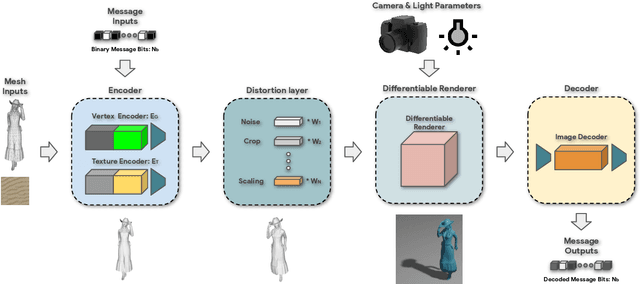

Digital watermarking is widely used for copyright protection. Traditional 3D watermarking approaches or commercial software are typically designed to embed messages into 3D meshes, and later retrieve the messages directly from distorted/undistorted watermarked 3D meshes. Retrieving messages from 2D renderings of such meshes, however, is still challenging and underexplored. We introduce a novel end-to-end learning framework to solve this problem through: 1) an encoder to covertly embed messages in both mesh geometry and textures; 2) a differentiable renderer to render watermarked 3D objects from different camera angles and under varied lighting conditions; 3) a decoder to recover the messages from 2D rendered images. From extensive experiments, we show that our models learn to embed information visually imperceptible to humans, and to reconstruct the embedded information from 2D renderings robust to 3D distortions. In addition, we demonstrate that our method can be generalized to work with different renderers, such as ray tracers and real-time renderers.
Ranking Clarifying Questions Based on Predicted User Engagement
Mar 18, 2021
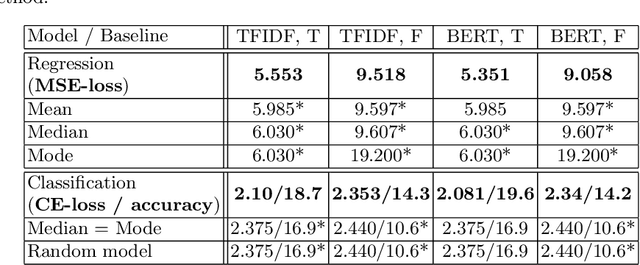
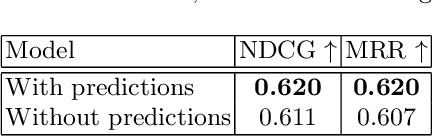
To improve online search results, clarification questions can be used to elucidate the information need of the user. This research aims to predict the user engagement with the clarification pane as an indicator of relevance based on the lexical information: query, question, and answers. Subsequently, the predicted user engagement can be used as a feature to rank the clarification panes. Regression and classification are applied for predicting user engagement and compared to naive heuristic baselines (e.g. mean) on the new MIMICS dataset [20]. An ablation study is carried out using a RankNet model to determine whether the predicted user engagement improves clarification pane ranking performance. The prediction models were able to improve significantly upon the naive baselines, and the predicted user engagement feature significantly improved the RankNet results in terms of NDCG and MRR. This research demonstrates the potential for ranking clarification panes based on lexical information only and can serve as a first neural baseline for future research to improve on. The code is available online.
Conversational Question Answering: A Survey
Jun 03, 2021

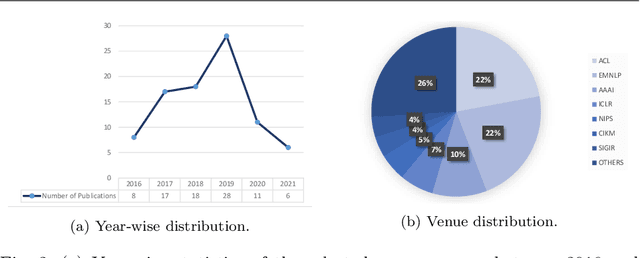
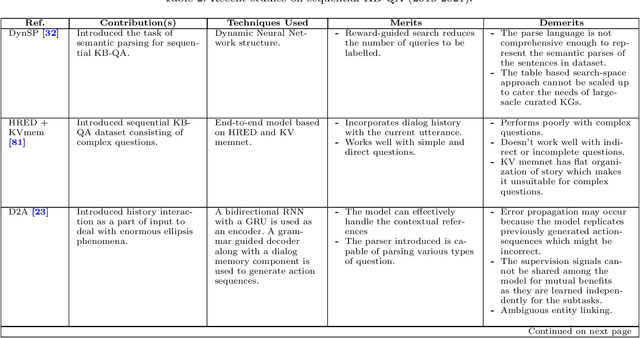
Question answering (QA) systems provide a way of querying the information available in various formats including, but not limited to, unstructured and structured data in natural languages. It constitutes a considerable part of conversational artificial intelligence (AI) which has led to the introduction of a special research topic on Conversational Question Answering (CQA), wherein a system is required to understand the given context and then engages in multi-turn QA to satisfy the user's information needs. Whilst the focus of most of the existing research work is subjected to single-turn QA, the field of multi-turn QA has recently grasped attention and prominence owing to the availability of large-scale, multi-turn QA datasets and the development of pre-trained language models. With a good amount of models and research papers adding to the literature every year recently, there is a dire need of arranging and presenting the related work in a unified manner to streamline future research. This survey, therefore, is an effort to present a comprehensive review of the state-of-the-art research trends of CQA primarily based on reviewed papers from 2016-2021. Our findings show that there has been a trend shift from single-turn to multi-turn QA which empowers the field of Conversational AI from different perspectives. This survey is intended to provide an epitome for the research community with the hope of laying a strong foundation for the field of CQA.
Investigating Attention Mechanism in 3D Point Cloud Object Detection
Aug 02, 2021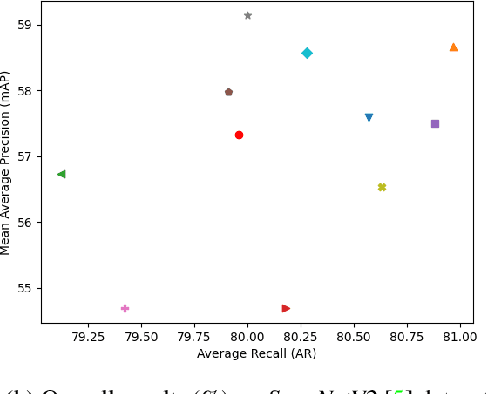
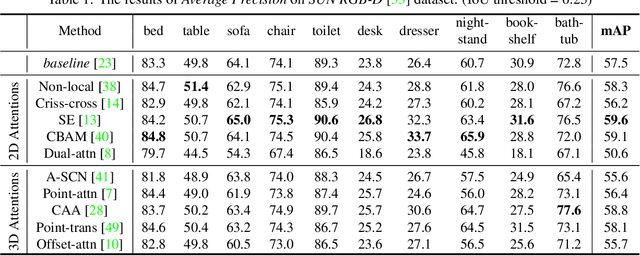
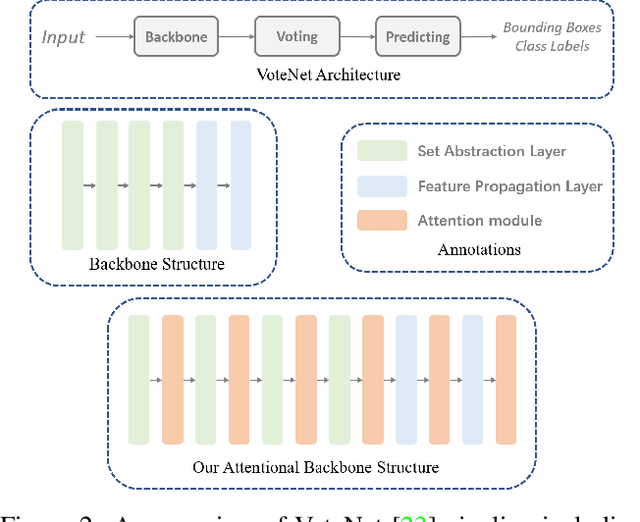
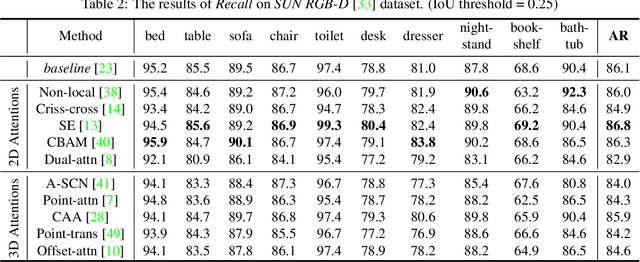
Object detection in three-dimensional (3D) space attracts much interest from academia and industry since it is an essential task in AI-driven applications such as robotics, autonomous driving, and augmented reality. As the basic format of 3D data, the point cloud can provide detailed geometric information about the objects in the original 3D space. However, due to 3D data's sparsity and unorderedness, specially designed networks and modules are needed to process this type of data. Attention mechanism has achieved impressive performance in diverse computer vision tasks; however, it is unclear how attention modules would affect the performance of 3D point cloud object detection and what sort of attention modules could fit with the inherent properties of 3D data. This work investigates the role of the attention mechanism in 3D point cloud object detection and provides insights into the potential of different attention modules. To achieve that, we comprehensively investigate classical 2D attentions, novel 3D attentions, including the latest point cloud transformers on SUN RGB-D and ScanNetV2 datasets. Based on the detailed experiments and analysis, we conclude the effects of different attention modules. This paper is expected to serve as a reference source for benefiting attention-embedded 3D point cloud object detection. The code and trained models are available at: https://github.com/ShiQiu0419/attentions_in_3D_detection.
Multimodal Remote Sensing Benchmark Datasets for Land Cover Classification with A Shared and Specific Feature Learning Model
May 21, 2021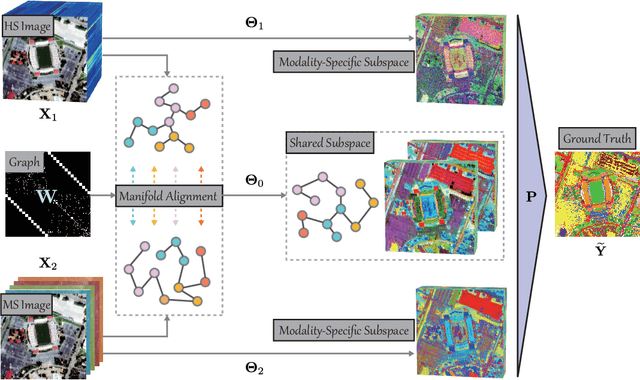

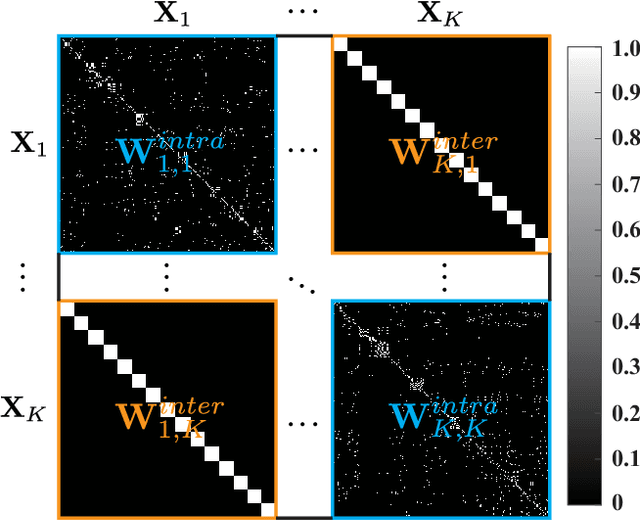
As remote sensing (RS) data obtained from different sensors become available largely and openly, multimodal data processing and analysis techniques have been garnering increasing interest in the RS and geoscience community. However, due to the gap between different modalities in terms of imaging sensors, resolutions, and contents, embedding their complementary information into a consistent, compact, accurate, and discriminative representation, to a great extent, remains challenging. To this end, we propose a shared and specific feature learning (S2FL) model. S2FL is capable of decomposing multimodal RS data into modality-shared and modality-specific components, enabling the information blending of multi-modalities more effectively, particularly for heterogeneous data sources. Moreover, to better assess multimodal baselines and the newly-proposed S2FL model, three multimodal RS benchmark datasets, i.e., Houston2013 -- hyperspectral and multispectral data, Berlin -- hyperspectral and synthetic aperture radar (SAR) data, Augsburg -- hyperspectral, SAR, and digital surface model (DSM) data, are released and used for land cover classification. Extensive experiments conducted on the three datasets demonstrate the superiority and advancement of our S2FL model in the task of land cover classification in comparison with previously-proposed state-of-the-art baselines. Furthermore, the baseline codes and datasets used in this paper will be made available freely at https://github.com/danfenghong/ISPRS_S2FL.
Group-based Bi-Directional Recurrent Wavelet Neural Networks for Video Super-Resolution
Jun 14, 2021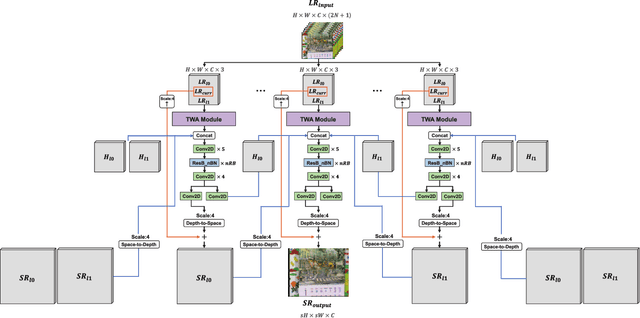
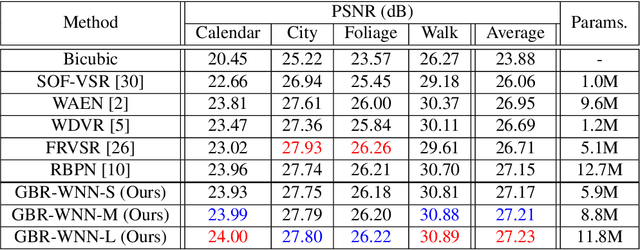
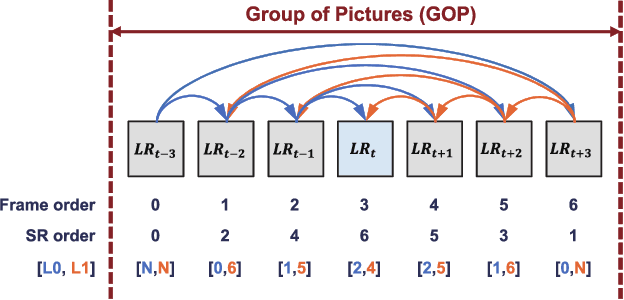
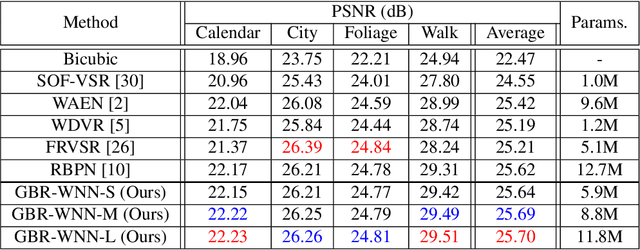
Video super-resolution (VSR) aims to estimate a high-resolution (HR) frame from a low-resolution (LR) frames. The key challenge for VSR lies in the effective exploitation of spatial correlation in an intra-frame and temporal dependency between consecutive frames. However, most of the previous methods treat different types of the spatial features identically and extract spatial and temporal features from the separated modules. It leads to lack of obtaining meaningful information and enhancing the fine details. In VSR, there are three types of temporal modeling frameworks: 2D convolutional neural networks (CNN), 3D CNN, and recurrent neural networks (RNN). Among them, the RNN-based approach is suitable for sequential data. Thus the SR performance can be greatly improved by using the hidden states of adjacent frames. However, at each of time step in a recurrent structure, the RNN-based previous works utilize the neighboring features restrictively. Since the range of accessible motion per time step is narrow, there are still limitations to restore the missing details for dynamic or large motion. In this paper, we propose a group-based bi-directional recurrent wavelet neural networks (GBR-WNN) to exploit the sequential data and spatio-temporal information effectively for VSR. The proposed group-based bi-directional RNN (GBR) temporal modeling framework is built on the well-structured process with the group of pictures (GOP). We propose a temporal wavelet attention (TWA) module, in which attention is adopted for both spatial and temporal features. Experimental results demonstrate that the proposed method achieves superior performance compared with state-of-the-art methods in both of quantitative and qualitative evaluations.