 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Predicting Distant Metastases in Soft-Tissue Sarcomas from PET-CT scans using Constrained Hierarchical Multi-Modality Feature Learning
Apr 23, 2021
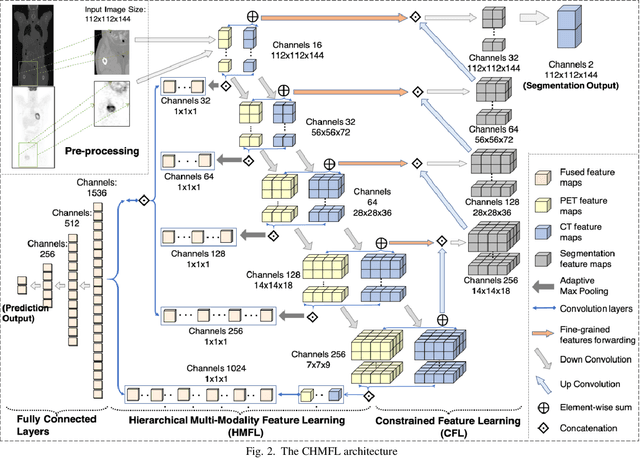
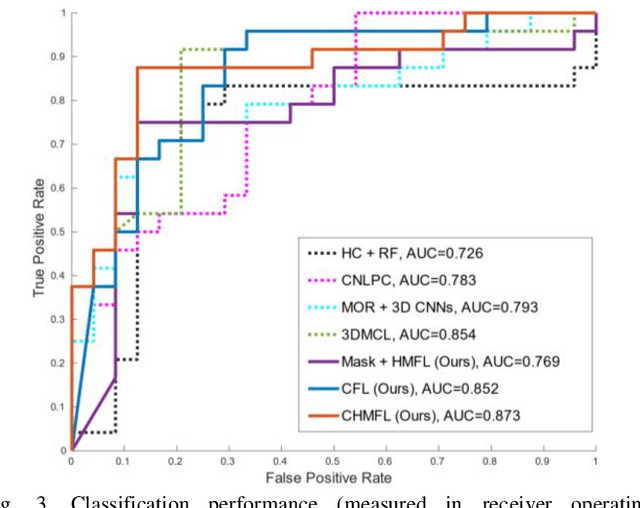
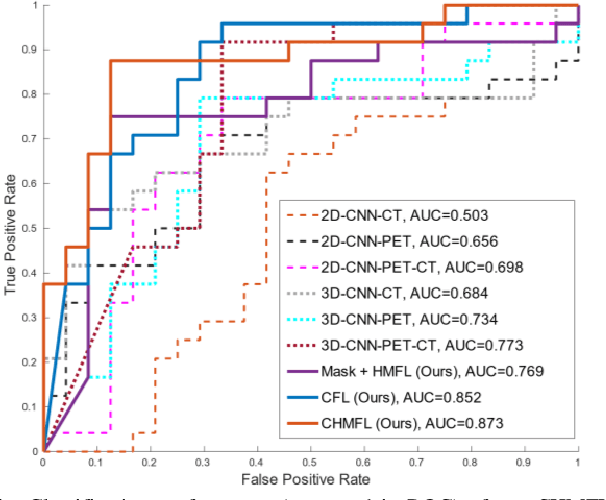
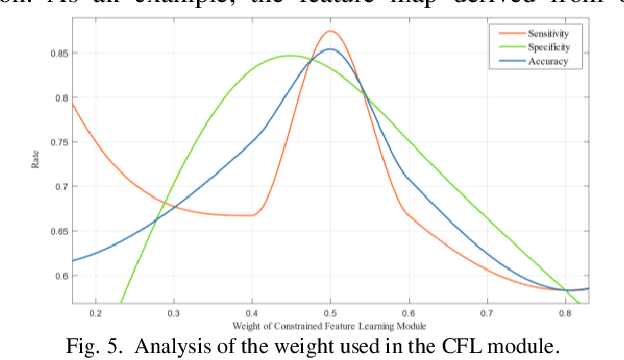
Distant metastases (DM) refer to the dissemination of tumors, usually, beyond the organ where the tumor originated. They are the leading cause of death in patients with soft-tissue sarcomas (STSs). Positron emission tomography-computed tomography (PET-CT) is regarded as the imaging modality of choice for the management of STSs. It is difficult to determine from imaging studies which STS patients will develop metastases. 'Radiomics' refers to the extraction and analysis of quantitative features from medical images and it has been employed to help identify such tumors. The state-of-the-art in radiomics is based on convolutional neural networks (CNNs). Most CNNs are designed for single-modality imaging data (CT or PET alone) and do not exploit the information embedded in PET-CT where there is a combination of an anatomical and functional imaging modality. Furthermore, most radiomic methods rely on manual input from imaging specialists for tumor delineation, definition and selection of radiomic features. This approach, however, may not be scalable to tumors with complex boundaries and where there are multiple other sites of disease. We outline a new 3D CNN to help predict DM in STS patients from PET-CT data. The 3D CNN uses a constrained feature learning module and a hierarchical multi-modality feature learning module that leverages the complementary information from the modalities to focus on semantically important regions. Our results on a public PET-CT dataset of STS patients show that multi-modal information improves the ability to identify those patients who develop DM. Further our method outperformed all other related state-of-the-art methods.
Full interpretable machine learning in 2D with inline coordinates
Jul 03, 2021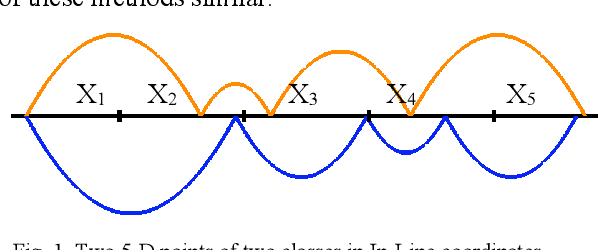
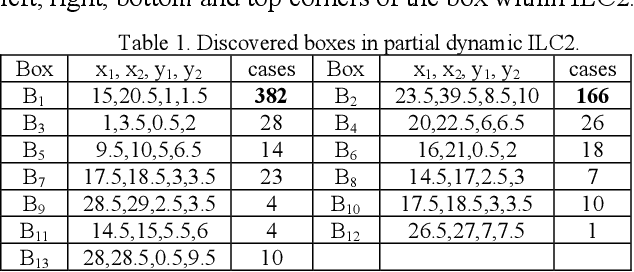
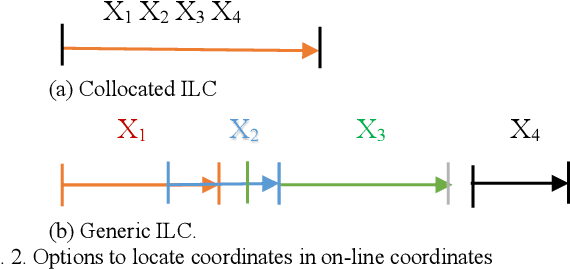
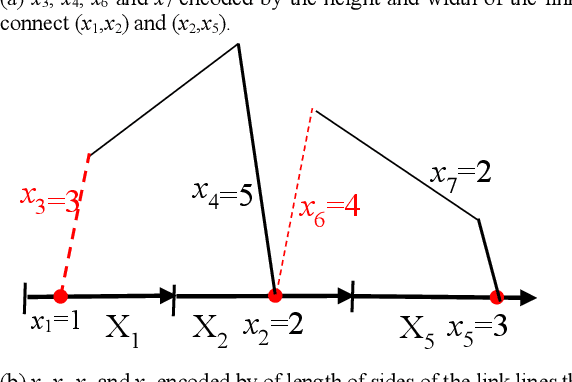
This paper proposed a new methodology for machine learning in 2-dimensional space (2-D ML) in inline coordinates. It is a full machine learning approach that does not require to deal with n-dimensional data in n-dimensional space. It allows discovering n-D patterns in 2-D space without loss of n-D information using graph representations of n-D data in 2-D. Specifically, it can be done with the inline based coordinates in different modifications, including static and dynamic ones. The classification and regression algorithms based on these inline coordinates were introduced. A successful case study based on a benchmark data demonstrated the feasibility of the approach. This approach helps to consolidate further a whole new area of full 2-D machine learning as a promising ML methodology. It has advantages of abilities to involve actively the end-users into the discovering of models and their justification. Another advantage is providing interpretable ML models.
On-Line Audio-to-Lyrics Alignment Based on a Reference Performance
Jul 30, 2021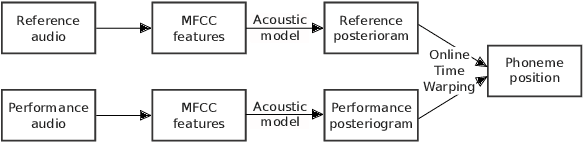
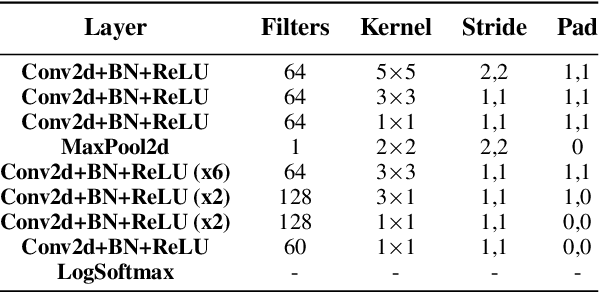
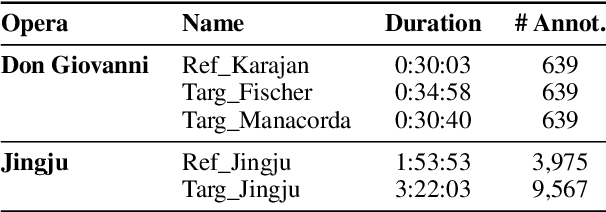

Audio-to-lyrics alignment has become an increasingly active research task in MIR, supported by the emergence of several open-source datasets of audio recordings with word-level lyrics annotations. However, there are still a number of open problems, such as a lack of robustness in the face of severe duration mismatches between audio and lyrics representation; a certain degree of language-specificity caused by acoustic differences across languages; and the fact that most successful methods in the field are not suited to work in real-time. Real-time lyrics alignment (tracking) would have many useful applications, such as fully automated subtitle display in live concerts and opera. In this work, we describe the first real-time-capable audio-to-lyrics alignment pipeline that is able to robustly track the lyrics of different languages, without additional language information. The proposed model predicts, for each audio frame, a probability vector over (European) phoneme classes, using a very small temporal context, and aligns this vector with a phoneme posteriogram matrix computed beforehand from another recording of the same work, which serves as a reference and a proxy to the written-out lyrics. We evaluate our system's tracking accuracy on the challenging genre of classical opera. Finally, robustness to out-of-training languages is demonstrated in an experiment on Jingju (Beijing opera).
Efficient Spatialtemporal Context Modeling for Action Recognition
Apr 06, 2021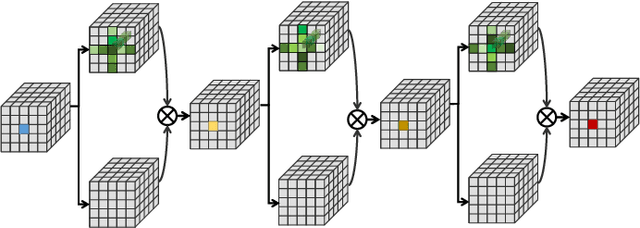
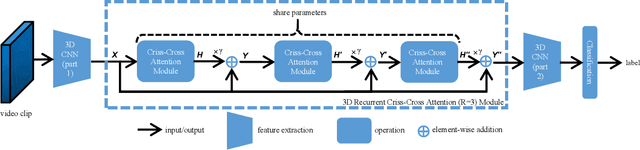
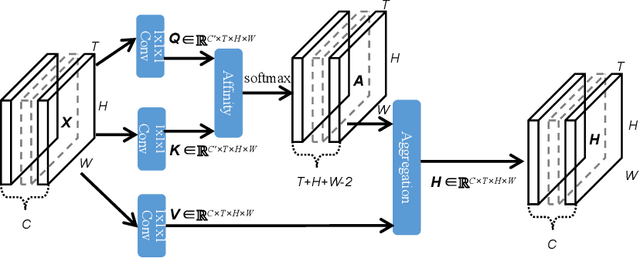
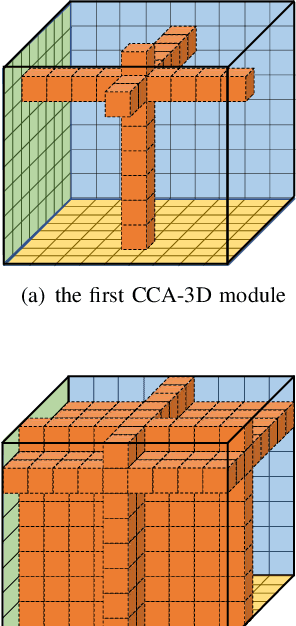
Contextual information plays an important role in action recognition. Local operations have difficulty to model the relation between two elements with a long-distance interval. However, directly modeling the contextual information between any two points brings huge cost in computation and memory, especially for action recognition, where there is an additional temporal dimension. Inspired from 2D criss-cross attention used in segmentation task, we propose a recurrent 3D criss-cross attention (RCCA-3D) module to model the dense long-range spatiotemporal contextual information in video for action recognition. The global context is factorized into sparse relation maps. We model the relationship between points in the same line along the direction of horizon, vertical and depth at each time, which forms a 3D criss-cross structure, and duplicate the same operation with recurrent mechanism to transmit the relation between points in a line to a plane finally to the whole spatiotemporal space. Compared with the non-local method, the proposed RCCA-3D module reduces the number of parameters and FLOPs by 25% and 30% for video context modeling. We evaluate the performance of RCCA-3D with two latest action recognition networks on three datasets and make a thorough analysis of the architecture, obtaining the optimal way to factorize and fuse the relation maps. Comparisons with other state-of-the-art methods demonstrate the effectiveness and efficiency of our model.
Automated Olfactory Bulb Segmentation on High Resolutional T2-Weighted MRI
Aug 09, 2021

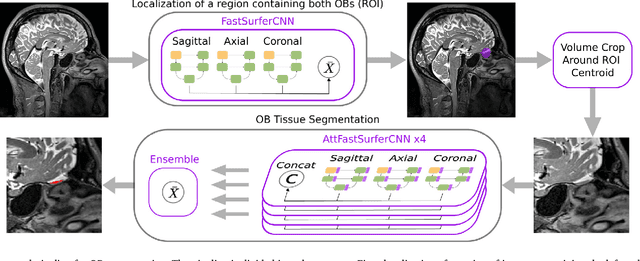
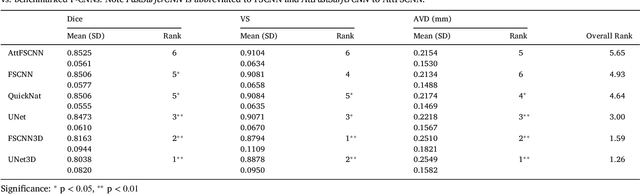
The neuroimage analysis community has neglected the automated segmentation of the olfactory bulb (OB) despite its crucial role in olfactory function. The lack of an automatic processing method for the OB can be explained by its challenging properties. Nonetheless, recent advances in MRI acquisition techniques and resolution have allowed raters to generate more reliable manual annotations. Furthermore, the high accuracy of deep learning methods for solving semantic segmentation problems provides us with an option to reliably assess even small structures. In this work, we introduce a novel, fast, and fully automated deep learning pipeline to accurately segment OB tissue on sub-millimeter T2-weighted (T2w) whole-brain MR images. To this end, we designed a three-stage pipeline: (1) Localization of a region containing both OBs using FastSurferCNN, (2) Segmentation of OB tissue within the localized region through four independent AttFastSurferCNN - a novel deep learning architecture with a self-attention mechanism to improve modeling of contextual information, and (3) Ensemble of the predicted label maps. The OB pipeline exhibits high performance in terms of boundary delineation, OB localization, and volume estimation across a wide range of ages in 203 participants of the Rhineland Study. Moreover, it also generalizes to scans of an independent dataset never encountered during training, the Human Connectome Project (HCP), with different acquisition parameters and demographics, evaluated in 30 cases at the native 0.7mm HCP resolution, and the default 0.8mm pipeline resolution. We extensively validated our pipeline not only with respect to segmentation accuracy but also to known OB volume effects, where it can sensitively replicate age effects.
Probabilistic DAG Search
Jun 16, 2021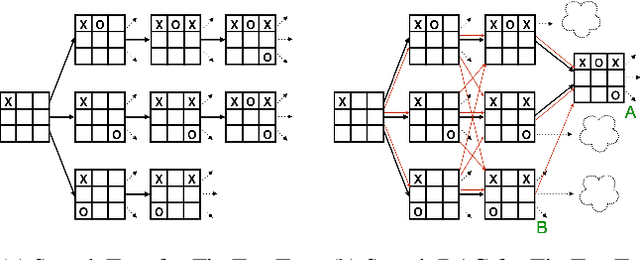
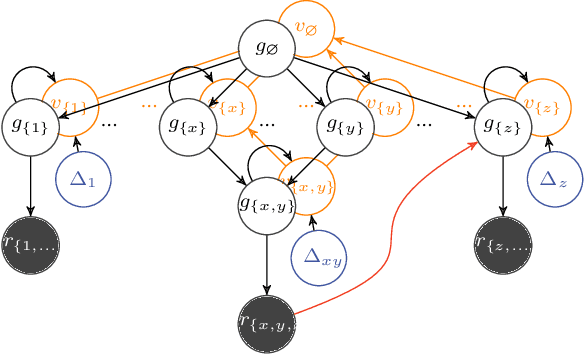
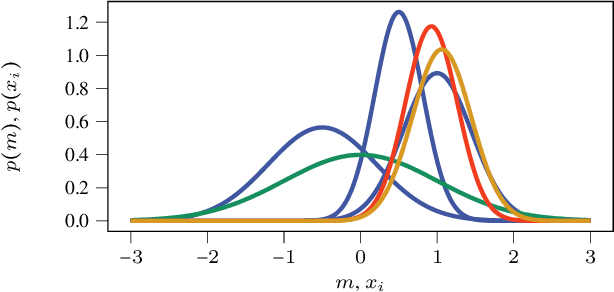
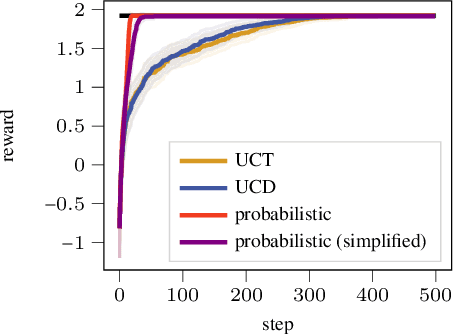
Exciting contemporary machine learning problems have recently been phrased in the classic formalism of tree search -- most famously, the game of Go. Interestingly, the state-space underlying these sequential decision-making problems often posses a more general latent structure than can be captured by a tree. In this work, we develop a probabilistic framework to exploit a search space's latent structure and thereby share information across the search tree. The method is based on a combination of approximate inference in jointly Gaussian models for the explored part of the problem, and an abstraction for the unexplored part that imposes a reduction of complexity ad hoc. We empirically find our algorithm to compare favorably to existing non-probabilistic alternatives in Tic-Tac-Toe and a feature selection application.
Manifold-Aware Synthesis of High Resolution Diffusion from Structural Imaging
Aug 09, 2021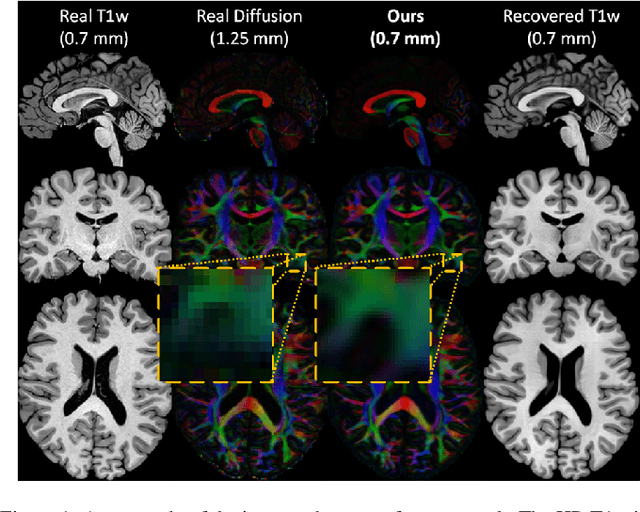
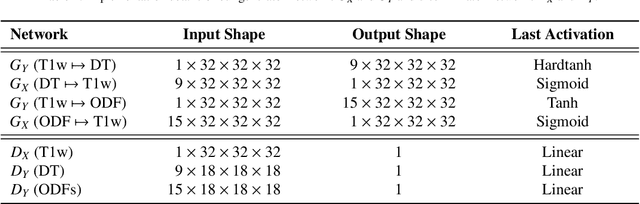
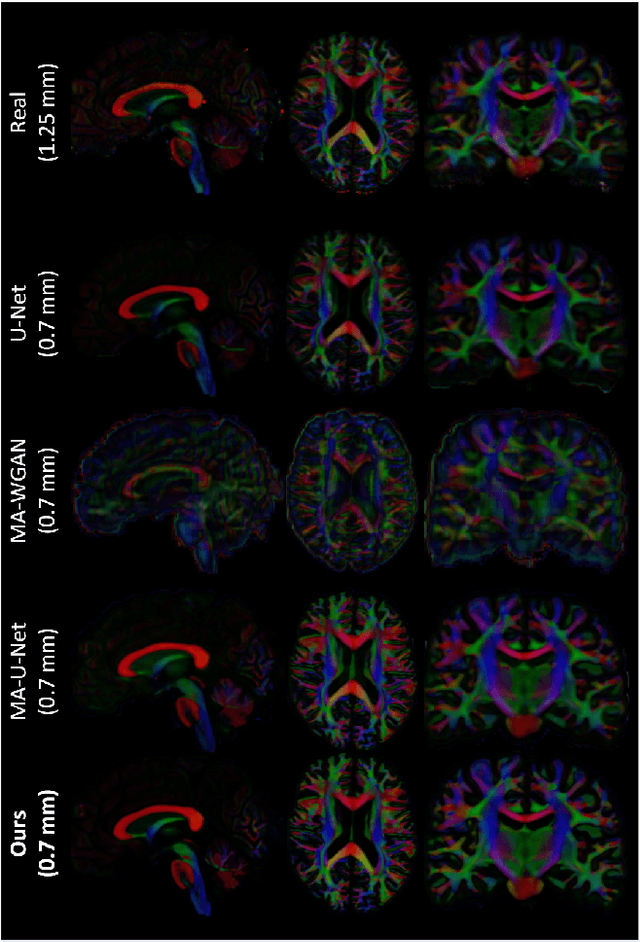
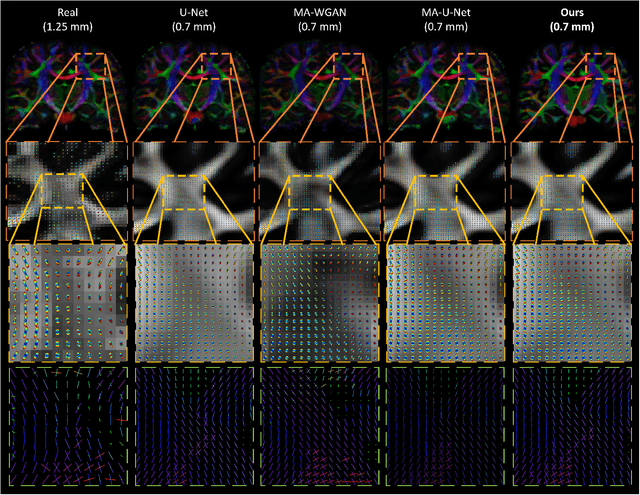
The physical and clinical constraints surrounding diffusion-weighted imaging (DWI) often limit the spatial resolution of the produced images to voxels up to 8 times larger than those of T1w images. Thus, the detailed information contained in T1w imagescould help in the synthesis of diffusion images in higher resolution. However, the non-Euclidean nature of diffusion imaging hinders current deep generative models from synthesizing physically plausible images. In this work, we propose the first Riemannian network architecture for the direct generation of diffusion tensors (DT) and diffusion orientation distribution functions (dODFs) from high-resolution T1w images. Our integration of the Log-Euclidean Metric into a learning objective guarantees, unlike standard Euclidean networks, the mathematically-valid synthesis of diffusion. Furthermore, our approach improves the fractional anisotropy mean squared error (FA MSE) between the synthesized diffusion and the ground-truth by more than 23% and the cosine similarity between principal directions by almost 5% when compared to our baselines. We validate our generated diffusion by comparing the resulting tractograms to our expected real data. We observe similar fiber bundles with streamlines having less than 3% difference in length, less than 1% difference in volume, and a visually close shape. While our method is able to generate high-resolution diffusion images from structural inputs in less than 15 seconds, we acknowledge and discuss the limits of diffusion inference solely relying on T1w images. Our results nonetheless suggest a relationship between the high-level geometry of the brain and the overall white matter architecture.
Machine Learning Characterization of Cancer Patients-Derived Extracellular Vesicles using Vibrational Spectroscopies
Aug 04, 2021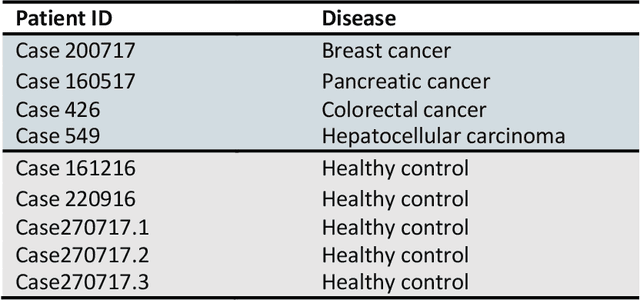
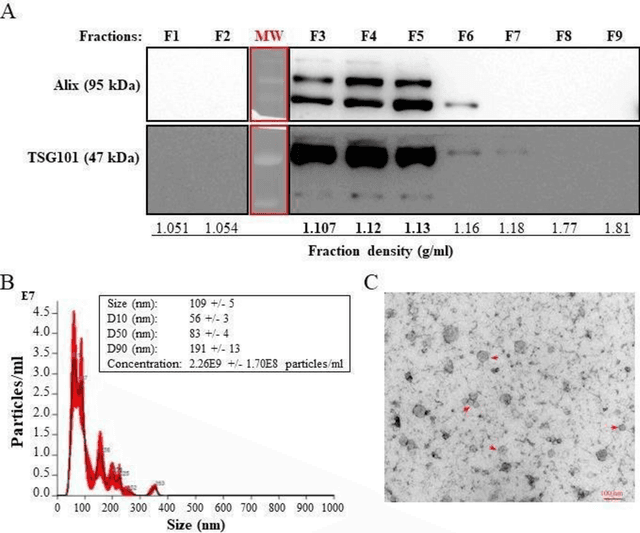
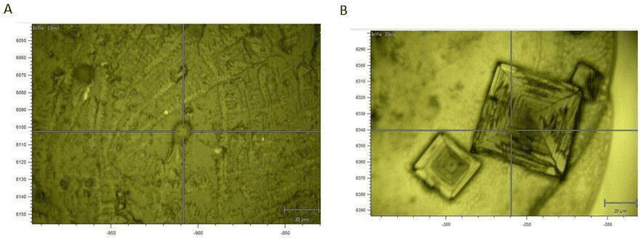
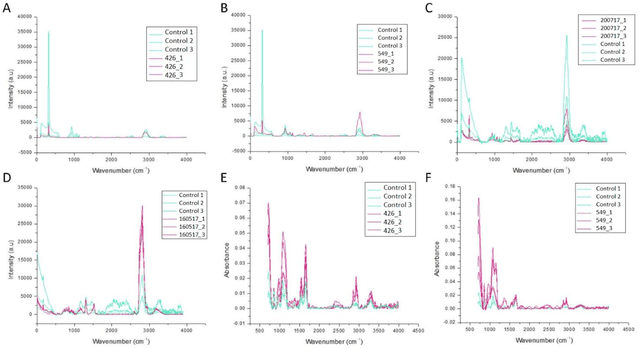
The early detection of cancer is a challenging problem in medicine. The blood sera of cancer patients are enriched with heterogeneous secretory lipid bound extracellular vesicles (EVs), which present a complex repertoire of information and biomarkers, representing their cell of origin, that are being currently studied in the field of liquid biopsy and cancer screening. Vibrational spectroscopies provide non-invasive approaches for the assessment of structural and biophysical properties in complex biological samples. In this study, multiple Raman spectroscopy measurements were performed on the EVs extracted from the blood sera of 9 patients consisting of four different cancer subtypes (colorectal cancer, hepatocellular carcinoma, breast cancer and pancreatic cancer) and five healthy patients (controls). FTIR(Fourier Transform Infrared) spectroscopy measurements were performed as a complementary approach to Raman analysis, on two of the four cancer subtypes. The AdaBoost Random Forest Classifier, Decision Trees, and Support Vector Machines (SVM) distinguished the baseline corrected Raman spectra of cancer EVs from those of healthy controls (18 spectra) with a classification accuracy of greater than 90% when reduced to a spectral frequency range of 1800 to 1940 inverse cm, and subjected to a 0.5 training/testing split. FTIR classification accuracy on 14 spectra showed an 80% classification accuracy. Our findings demonstrate that basic machine learning algorithms are powerful tools to distinguish the complex vibrational spectra of cancer patient EVs from those of healthy patients. These experimental methods hold promise as valid and efficient liquid biopsy for machine intelligence-assisted early cancer screening.
Graph Decoupling Attention Markov Networks for Semi-supervised Graph Node Classification
Apr 28, 2021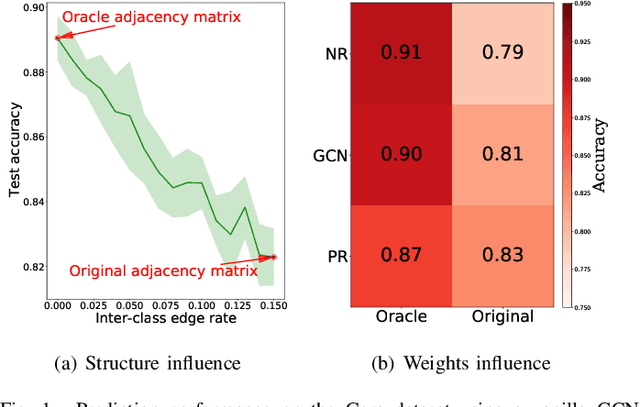
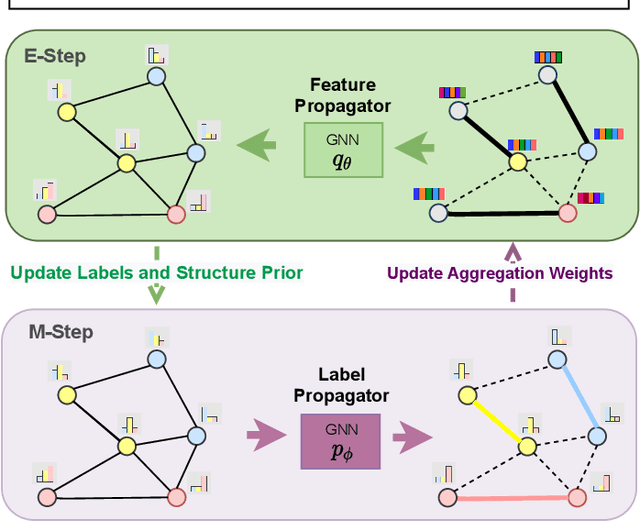
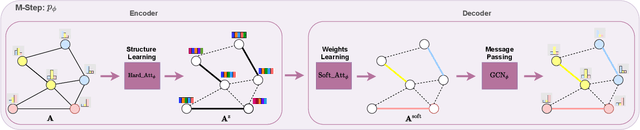
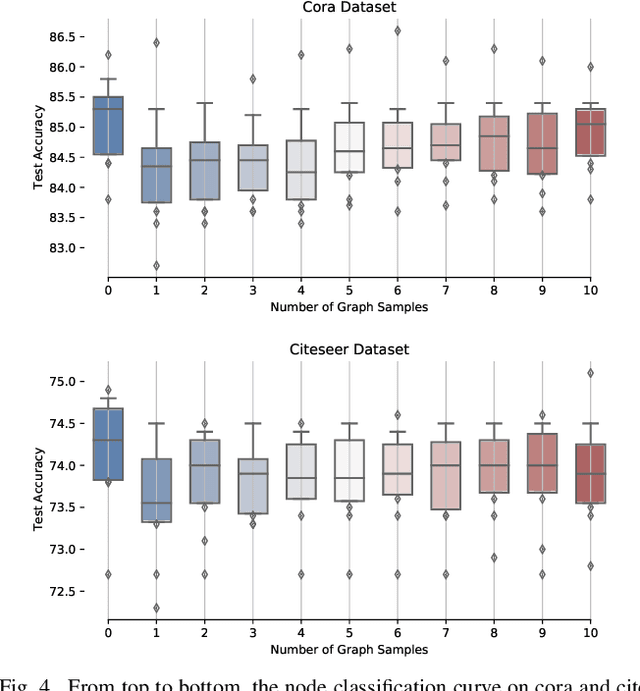
Graph neural networks (GNN) have been ubiquitous in graph learning tasks such as node classification. Most of GNN methods update the node embedding iteratively by aggregating its neighbors' information. However, they often suffer from negative disturbance, due to edges connecting nodes with different labels. One approach to alleviate this negative disturbance is to use attention, but current attention always considers feature similarity and suffers from the lack of supervision. In this paper, we consider the label dependency of graph nodes and propose a decoupling attention mechanism to learn both hard and soft attention. The hard attention is learned on labels for a refined graph structure with fewer inter-class edges. Its purpose is to reduce the aggregation's negative disturbance. The soft attention is learned on features maximizing the information gain by message passing over better graph structures. Moreover, the learned attention guides the label propagation and the feature propagation. Extensive experiments are performed on five well-known benchmark graph datasets to verify the effectiveness of the proposed method.
The Rediscovery Hypothesis: Language Models Need to Meet Linguistics
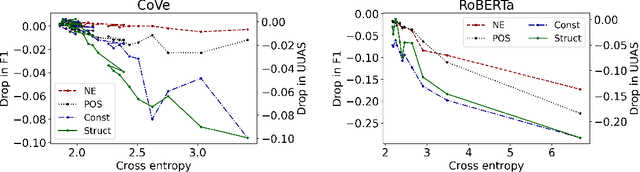
Mar 02, 2021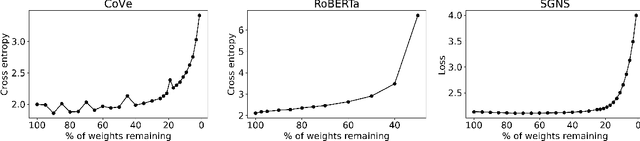


There is an ongoing debate in the NLP community whether modern language models contain linguistic knowledge, recovered through so-called \textit{probes}. In this paper we study whether linguistic knowledge is a necessary condition for good performance of modern language models, which we call the \textit{rediscovery hypothesis}. In the first place we show that language models that are significantly compressed but perform well on their pretraining objectives retain good scores when probed for linguistic structures. This result supports the rediscovery hypothesis and leads to the second contribution of our paper: an information-theoretic framework that relates language modeling objective with linguistic information. This framework also provides a metric to measure the impact of linguistic information on the word prediction task. We reinforce our analytical results with various experiments, both on synthetic and on real tasks.