 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Low-Rank Projections of GCNs Laplacian
Jun 04, 2021
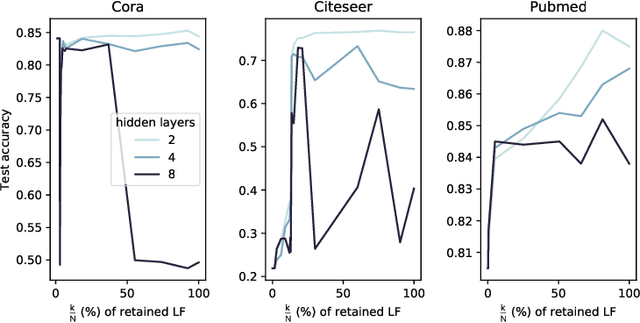
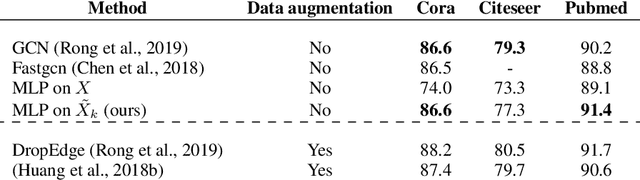
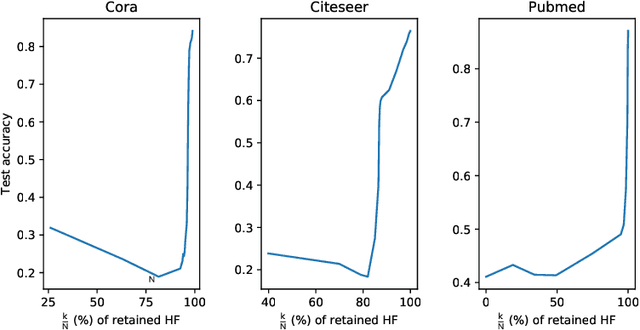

In this work, we study the behavior of standard models for community detection under spectral manipulations. Through various ablation experiments, we evaluate the impact of bandpass filtering on the performance of a GCN: we empirically show that most of the necessary and used information for nodes classification is contained in the low-frequency domain, and thus contrary to images, high frequencies are less crucial to community detection. In particular, it is sometimes possible to obtain accuracies at a state-of-the-art level with simple classifiers that rely only on a few low frequencies.
A novel multi-classifier information fusion based on Dempster-Shafer theory: application to vibration-based fault detection
Dec 04, 2020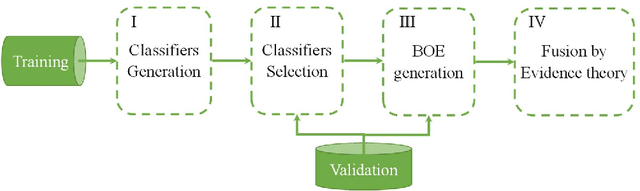
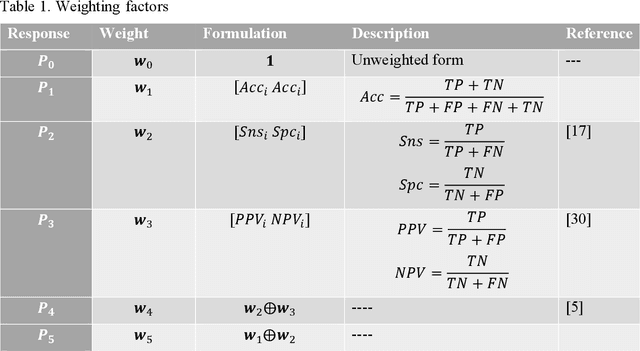
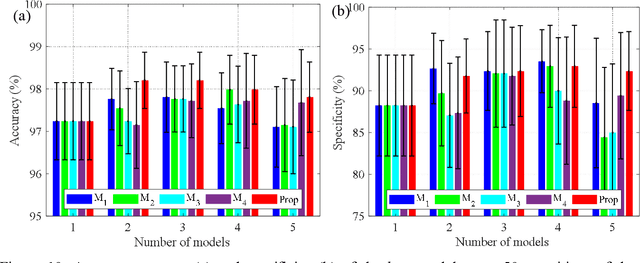
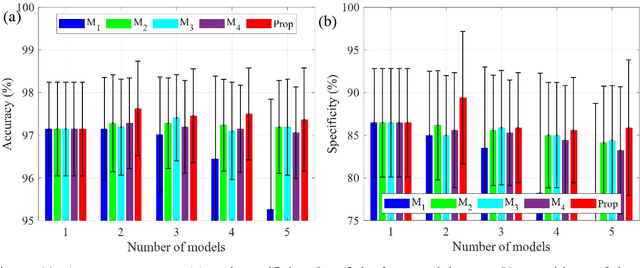
Achieving a high prediction rate is a crucial task in fault detection. Although various classification procedures are available, none of them can give high accuracy in all applications. Therefore, in this paper, a novel multi-classifier fusion approach is developed to boost the performance of the individual classifiers. This is acquired by using Dempster-Shafer theory (DST). However, in cases with conflicting evidences, the DST may give counter-intuitive results. In this regard, a preprocessing technique based on a new metric is devised in order to measure and mitigate the conflict between the evidences. To evaluate and validate the effectiveness of the proposed approach, the method is applied to 15 benchmarks datasets from UCI and KEEL. Further, it is applied for classifying polycrystalline Nickel alloy first-stage turbine blades based on their broadband vibrational response. Through statistical analysis with different levels of noise-to-signal ratio, and by comparing with four state-of-the-art fusion techniques, it is shown that that the proposed method improves the classification accuracy and outperforms the individual classifiers.
Distributed Attention for Grounded Image Captioning
Aug 02, 2021
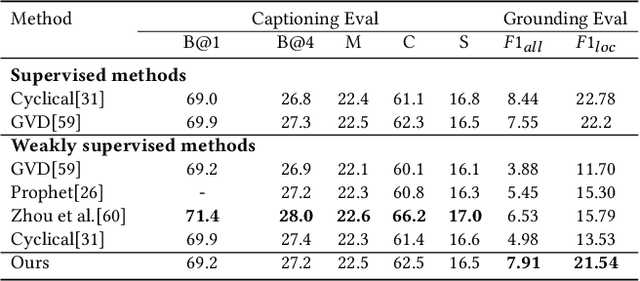
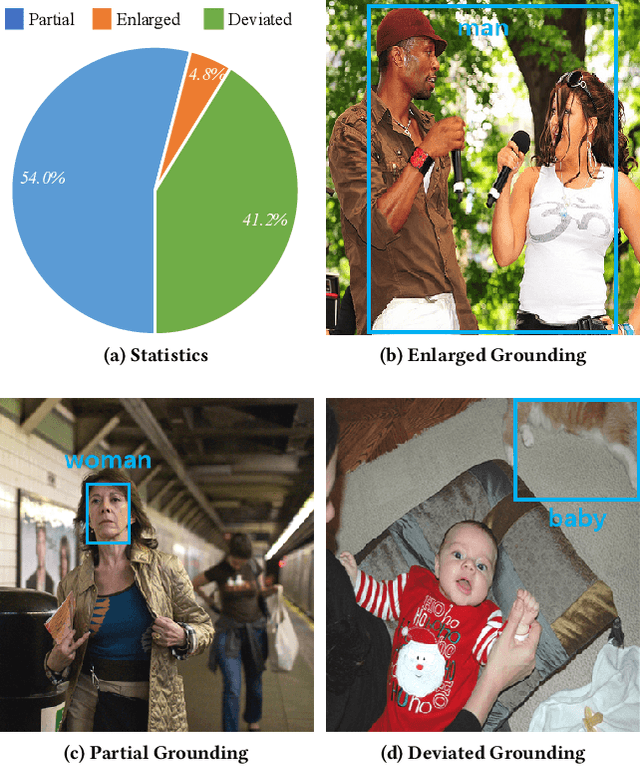
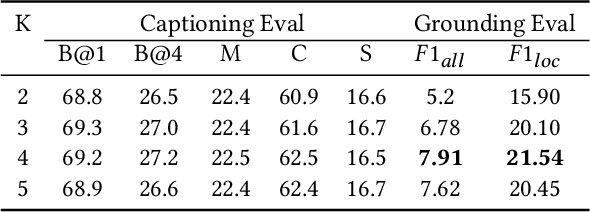
We study the problem of weakly supervised grounded image captioning. That is, given an image, the goal is to automatically generate a sentence describing the context of the image with each noun word grounded to the corresponding region in the image. This task is challenging due to the lack of explicit fine-grained region word alignments as supervision. Previous weakly supervised methods mainly explore various kinds of regularization schemes to improve attention accuracy. However, their performances are still far from the fully supervised ones. One main issue that has been ignored is that the attention for generating visually groundable words may only focus on the most discriminate parts and can not cover the whole object. To this end, we propose a simple yet effective method to alleviate the issue, termed as partial grounding problem in our paper. Specifically, we design a distributed attention mechanism to enforce the network to aggregate information from multiple spatially different regions with consistent semantics while generating the words. Therefore, the union of the focused region proposals should form a visual region that encloses the object of interest completely. Extensive experiments have demonstrated the superiority of our proposed method compared with the state-of-the-arts.
GeoCLR: Georeference Contrastive Learning for Efficient Seafloor Image Interpretation
Aug 13, 2021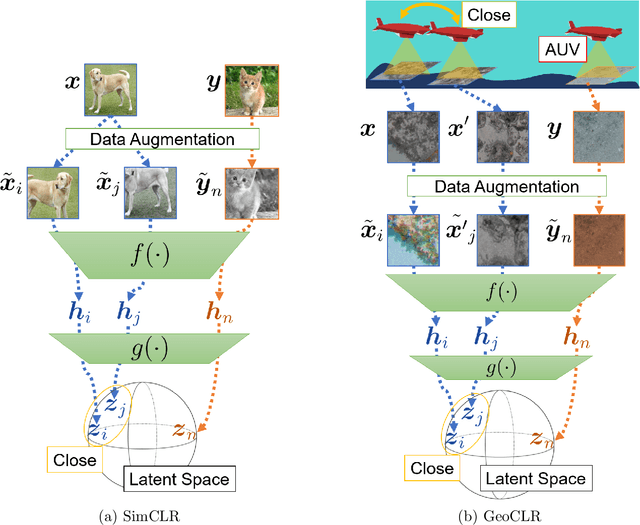
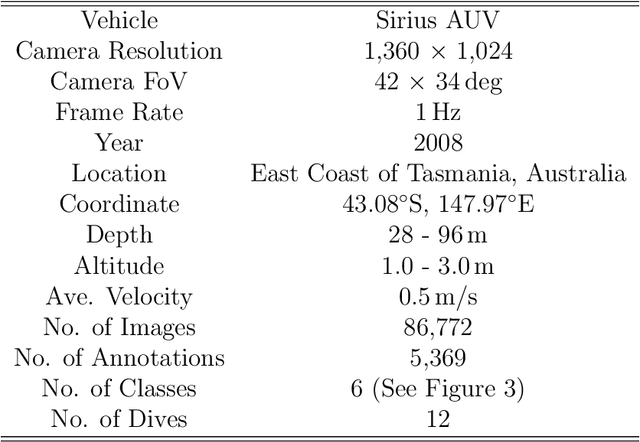
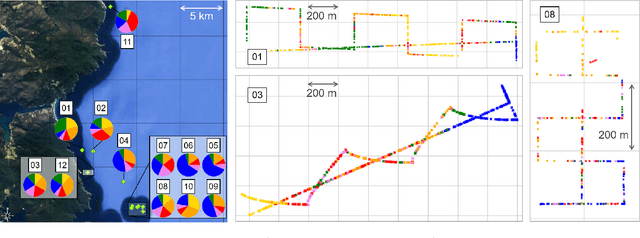
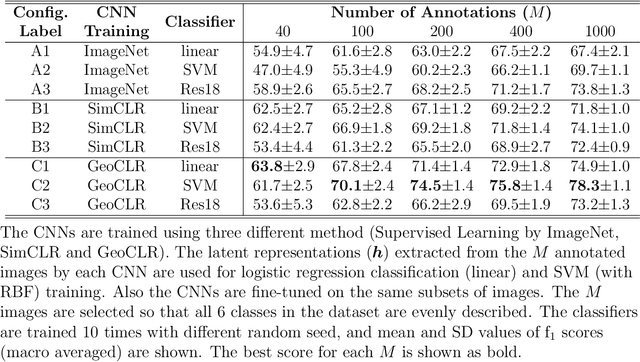
This paper describes Georeference Contrastive Learning of visual Representation (GeoCLR) for efficient training of deep-learning Convolutional Neural Networks (CNNs). The method leverages georeference information by generating a similar image pair using images taken of nearby locations, and contrasting these with an image pair that is far apart. The underlying assumption is that images gathered within a close distance are more likely to have similar visual appearance, where this can be reasonably satisfied in seafloor robotic imaging applications where image footprints are limited to edge lengths of a few metres and are taken so that they overlap along a vehicle's trajectory, whereas seafloor substrates and habitats have patch sizes that are far larger. A key advantage of this method is that it is self-supervised and does not require any human input for CNN training. The method is computationally efficient, where results can be generated between dives during multi-day AUV missions using computational resources that would be accessible during most oceanic field trials. We apply GeoCLR to habitat classification on a dataset that consists of ~86k images gathered using an Autonomous Underwater Vehicle (AUV). We demonstrate how the latent representations generated by GeoCLR can be used to efficiently guide human annotation efforts, where the semi-supervised framework improves classification accuracy by an average of 11.8 % compared to state-of-the-art transfer learning using the same CNN and equivalent number of human annotations for training.
Lazy-CFR: a fast regret minimization algorithm for extensive games with imperfect information
Oct 10, 2018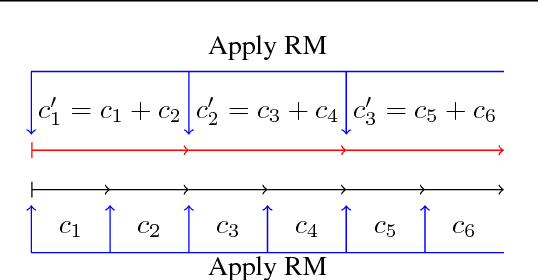
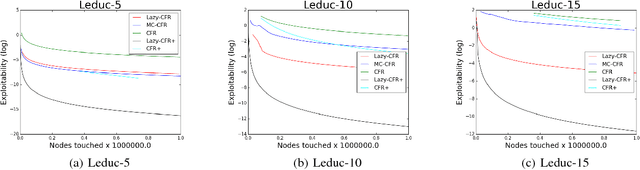
In this paper, we focus on solving two-player zero-sum extensive games with imperfect information. Counterfactual regret minimization (CFR) is the most popular algorithm on solving such games and achieves state-of-the-art performance in practice. However, the performance of CFR is not fully understood, since empirical results on the regret are much better than the upper bound proved in \cite{zinkevich2008regret}. Another issue of CFR is that CFR has to traverse the whole game tree in each round, which is not tolerable in large scale games. In this paper, we present a novel technique, lazy update, which can avoid traversing the whole game tree in CFR. Further, we present a novel analysis on the CFR with lazy update. Our analysis can also be applied to the vanilla CFR, which results in a much tighter regret bound than that proved in \cite{zinkevich2008regret}. Inspired by lazy update, we further present a novel CFR variant, named Lazy-CFR. Compared to traversing $O(|\mathcal{I}|)$ information sets in vanilla CFR, Lazy-CFR needs only to traverse $O(\sqrt{|\mathcal{I}|})$ information sets per round while the regret bound almost keep the same, where $\mathcal{I}$ is the class of all information sets. As a result, Lazy-CFR shows better convergence result compared with vanilla CFR. Experimental results consistently show that Lazy-CFR outperforms the vanilla CFR significantly.
Next-Generation Multiple Access Based on NOMA with Power Level Modulation
Jul 27, 2021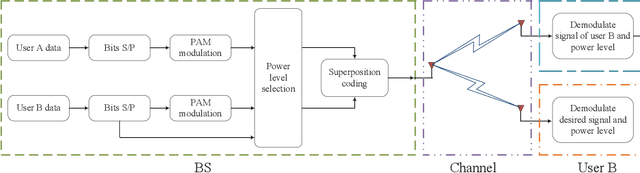
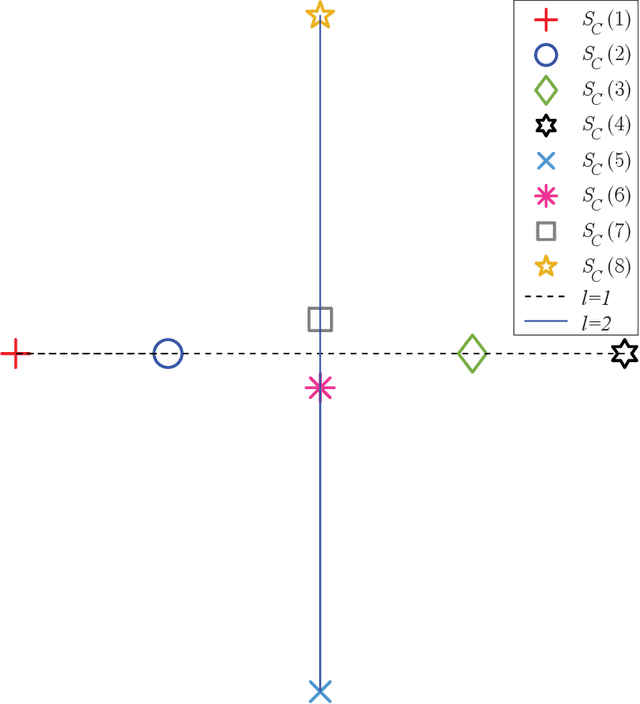
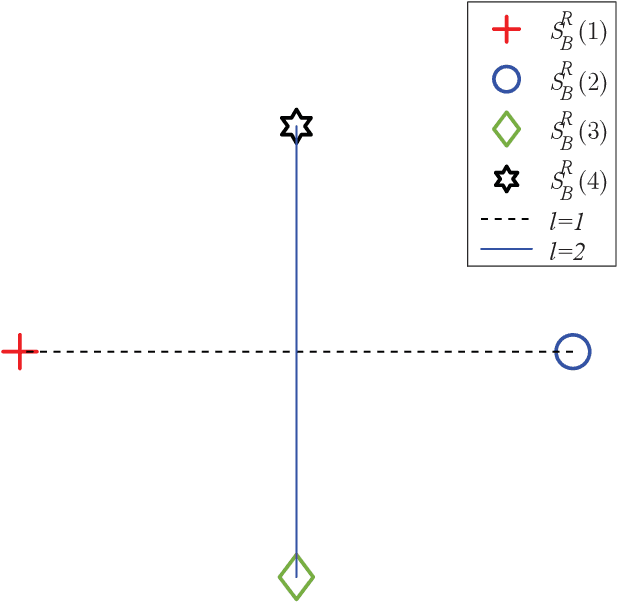
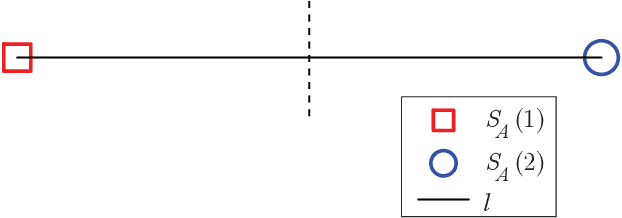
To cope with the explosive traffic growth of next-generation wireless communications, it is necessary to design next-generation multiple access techniques that can provide higher spectral efficiency as well as larger-scale connectivity. As a promising candidate, power-domain non-orthogonal multiple access (NOMA) has been widely studied. In conventional power-domain NOMA, multiple users are multiplexed in the same time and frequency band by different preset power levels, which, however, may limit the spectral efficiency under practical finite alphabet inputs. Inspired by the concept of spatial modulation, we propose to solve this problem by encoding extra information bits into the power levels, and exploit different signal constellations to help the receiver distinguish between them. To convey this idea, termed power selection (PS)-NOMA, clearly, we consider a simple downlink two-user NOMA system with finite input constellations. Assuming maximum-likelihood detection, we derive closed-form approximate bit error ratio (BER) expressions for both users. The achievable rates of both users are also derived in closed form. Simulation results verify the analysis and show that the proposed PS-NOMA outperforms conventional NOMA in terms of BER and achievable rate.
Incorporating Luminance, Depth and Color Information by Fusion-based Networks for Semantic Segmentation
Sep 24, 2018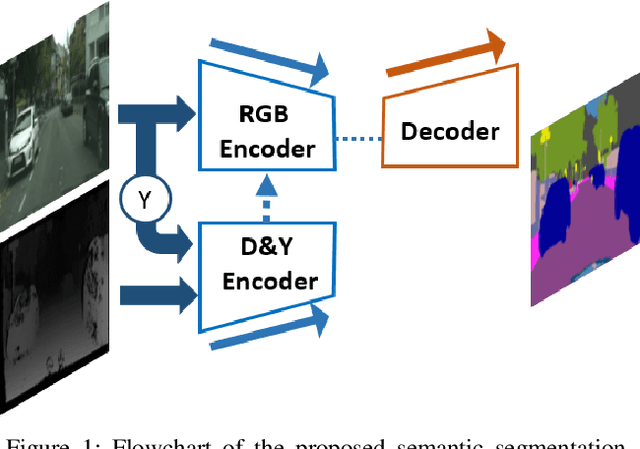
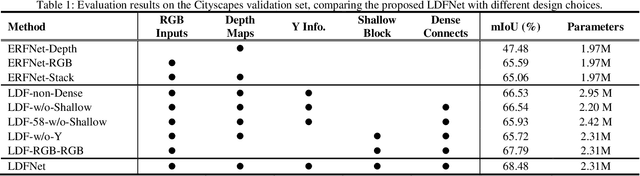
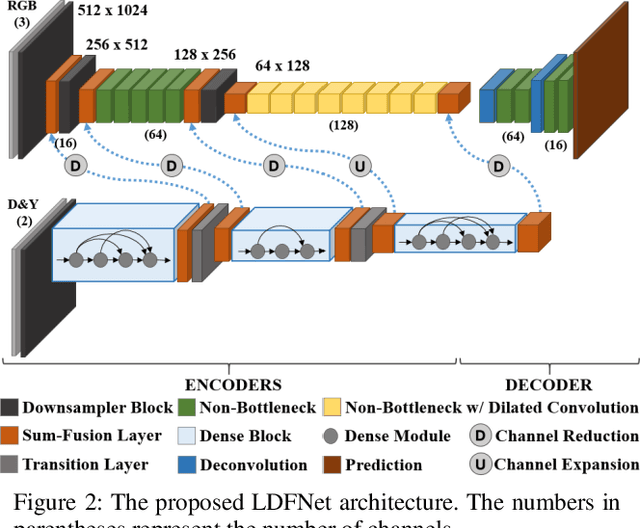
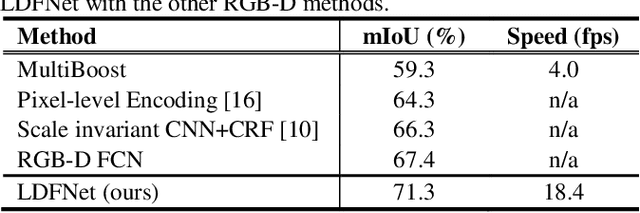
Semantic segmentation is paramount to accomplish many scene understanding applications such as autonomous driving. Although deep convolutional networks have already achieved encouraging results in semantic segmentation compared to traditional methods, there is still large room for further improvement. In this paper, we propose a preferred solution, which incorporates Luminance, Depth and color information by a Fusion-based network named LDFNet. It includes a distinctive encoder sub-network to process the depth maps and further employs the luminance images to assist the depth information in a process. LDFNet achieves very competitive results compared to the other state-of-art systems on the challenging Cityscapes dataset, while it maintains an inference speed faster than most of the existing top-performing networks. The experimental results show the effectiveness of the proposed information-fused approach and the potential of LDFNet for road scene understanding tasks.
CKConv: Learning Feature Voxelization for Point Cloud Analysis
Jul 27, 2021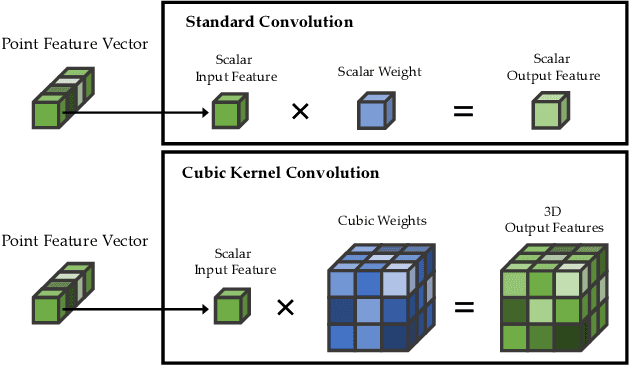
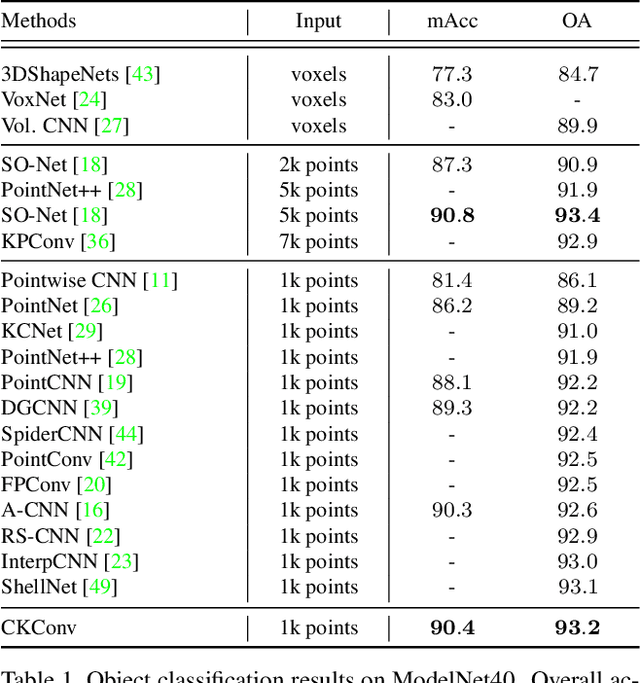
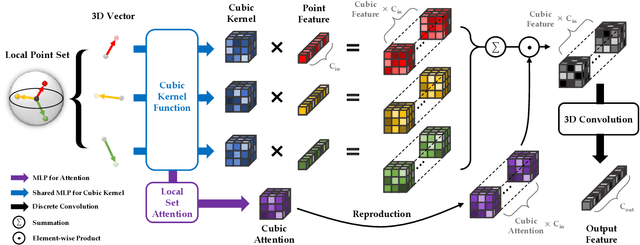
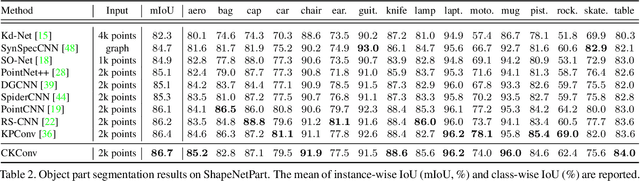
Despite the remarkable success of deep learning, optimal convolution operation on point cloud remains indefinite due to its irregular data structure. In this paper, we present Cubic Kernel Convolution (CKConv) that learns to voxelize the features of local points by exploiting both continuous and discrete convolutions. Our continuous convolution uniquely employs a 3D cubic form of kernel weight representation that splits a feature into voxels in embedding space. By consecutively applying discrete 3D convolutions on the voxelized features in a spatial manner, preceding continuous convolution is forced to learn spatial feature mapping, i.e., feature voxelization. In this way, geometric information can be detailed by encoding with subdivided features, and our 3D convolutions on these fixed structured data do not suffer from discretization artifacts thanks to voxelization in embedding space. Furthermore, we propose a spatial attention module, Local Set Attention (LSA), to provide comprehensive structure awareness within the local point set and hence produce representative features. By learning feature voxelization with LSA, CKConv can extract enriched features for effective point cloud analysis. We show that CKConv has great applicability to point cloud processing tasks including object classification, object part segmentation, and scene semantic segmentation with state-of-the-art results.
Effects of personality traits in predicting grade retention of Brazilian students
Jul 12, 2021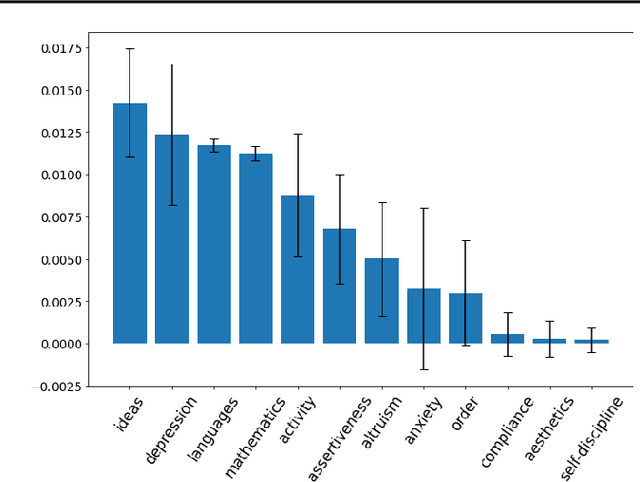
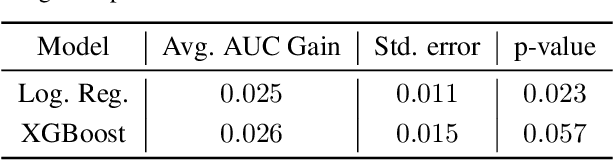
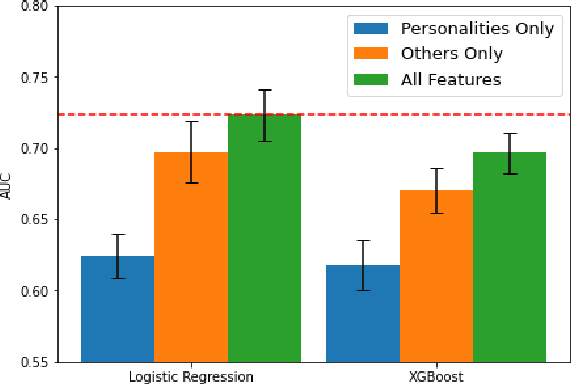
Student's grade retention is a key issue faced by many education systems, especially those in developing countries. In this paper, we seek to gauge the relevance of students' personality traits in predicting grade retention in Brazil. For that, we used data collected in 2012 and 2017, in the city of Sertaozinho, countryside of the state of Sao Paulo, Brazil. The surveys taken in Sertaozinho included several socioeconomic questions, standardized tests, and a personality test. Moreover, students were in grades 4, 5, and 6 in 2012. Our approach was based on training machine learning models on the surveys' data to predict grade retention between 2012 and 2017 using information from 2012 or before, and then using some strategies to quantify personality traits' predictive power. We concluded that, besides proving to be fairly better than a random classifier when isolated, personality traits contribute to prediction even when using socioeconomic variables and standardized tests results.
A DNN-based OTFS Transceiver with Delay-Doppler Channel Training and IQI Compensation
Jul 20, 2021
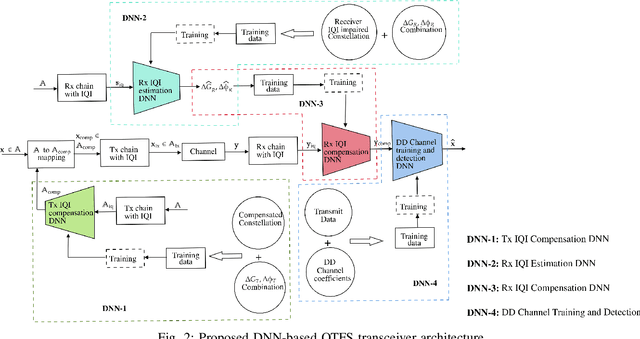
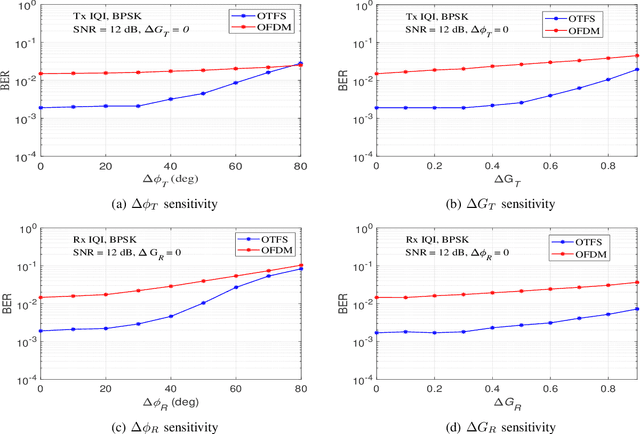
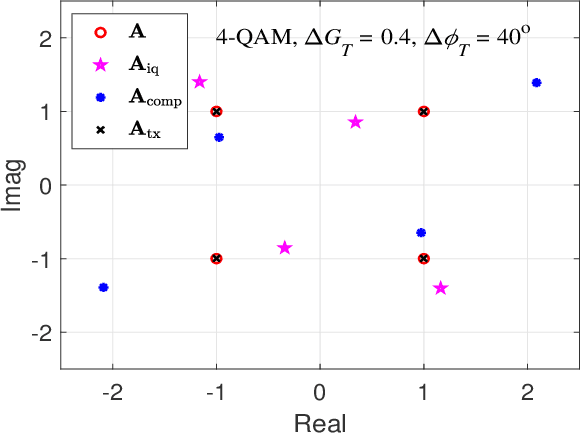
In this paper, we present a deep neural network (DNN) based transceiver architecture for delay-Doppler (DD) channel training and detection of orthogonal time frequency space (OTFS) modulation signals along with IQ imbalance (IQI) compensation. The proposed transceiver learns the DD channel over a spatial coherence interval and detects the information symbols using a single DNN trained for this purpose at the receiver. The proposed transceiver also learns the IQ imbalances present in the transmitter and receiver and effectively compensates them. The transmit IQI compensation is realized using a single DNN at the transmitter which learns and provides a compensating modulation alphabet (to pre-rotate the modulation symbols before sending through the transmitter) without explicitly estimating the transmit gain and phase imbalances. The receive IQI imbalance compensation is realized using two DNNs at the receiver, one DNN for explicit estimation of receive gain and phase imbalances and another DNN for compensation. Simulation results show that the proposed DNN-based architecture provides very good performance, making it as a promising approach for the design of practical OTFS transceivers.