 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Hyperspectral and Multispectral Classification for Coastal Wetland Using Depthwise Feature Interaction Network
Jul 12, 2021
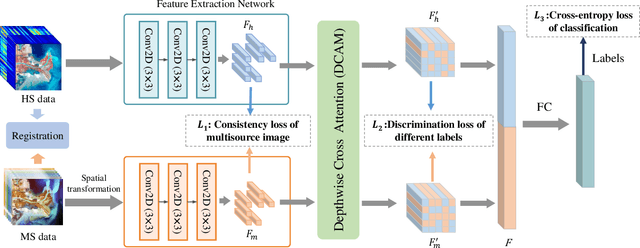
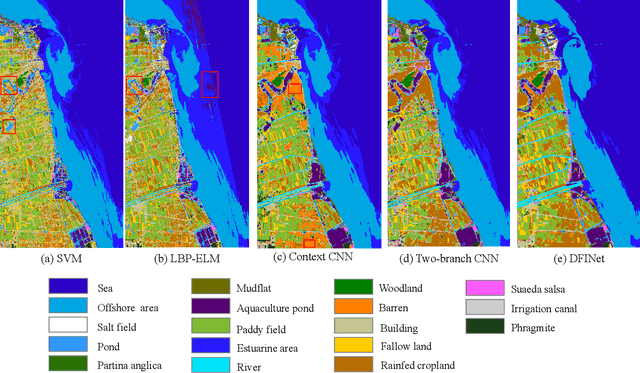
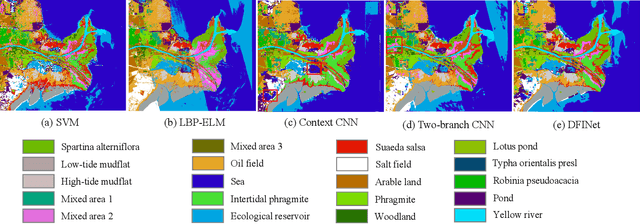
The monitoring of coastal wetlands is of great importance to the protection of marine and terrestrial ecosystems. However, due to the complex environment, severe vegetation mixture, and difficulty of access, it is impossible to accurately classify coastal wetlands and identify their species with traditional classifiers. Despite the integration of multisource remote sensing data for performance enhancement, there are still challenges with acquiring and exploiting the complementary merits from multisource data. In this paper, the Deepwise Feature Interaction Network (DFINet) is proposed for wetland classification. A depthwise cross attention module is designed to extract self-correlation and cross-correlation from multisource feature pairs. In this way, meaningful complementary information is emphasized for classification. DFINet is optimized by coordinating consistency loss, discrimination loss, and classification loss. Accordingly, DFINet reaches the standard solution-space under the regularity of loss functions, while the spatial consistency and feature discrimination are preserved. Comprehensive experimental results on two hyperspectral and multispectral wetland datasets demonstrate that the proposed DFINet outperforms other competitive methods in terms of overall accuracy.
Finding Concept-specific Biases in Form--Meaning Associations
Apr 29, 2021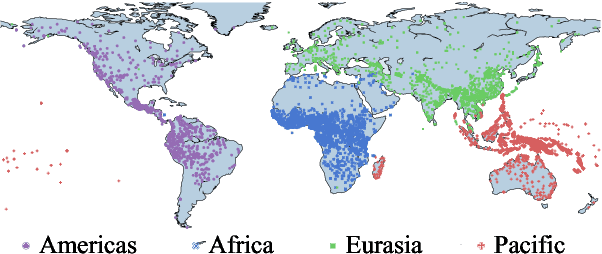
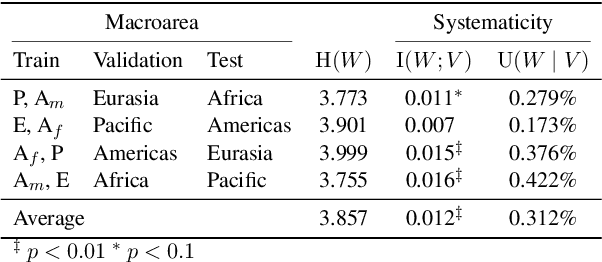
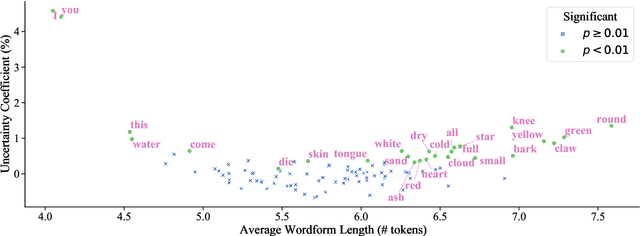
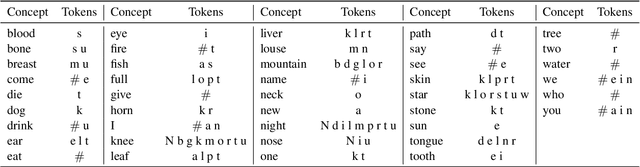
This work presents an information-theoretic operationalisation of cross-linguistic non-arbitrariness. It is not a new idea that there are small, cross-linguistic associations between the forms and meanings of words. For instance, it has been claimed (Blasi et al., 2016) that the word for "tongue" is more likely than chance to contain the phone [l]. By controlling for the influence of language family and geographic proximity within a very large concept-aligned, cross-lingual lexicon, we extend methods previously used to detect within language non-arbitrariness (Pimentel et al., 2019) to measure cross-linguistic associations. We find that there is a significant effect of non-arbitrariness, but it is unsurprisingly small (less than 0.5% on average according to our information-theoretic estimate). We also provide a concept-level analysis which shows that a quarter of the concepts considered in our work exhibit a significant level of cross-linguistic non-arbitrariness. In sum, the paper provides new methods to detect cross-linguistic associations at scale, and confirms their effects are minor.
End-to-End Learning of OFDM Waveforms with PAPR and ACLR Constraints
Jun 30, 2021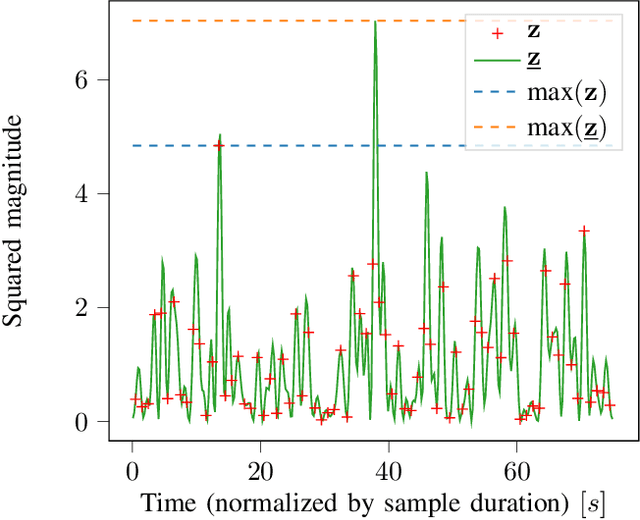
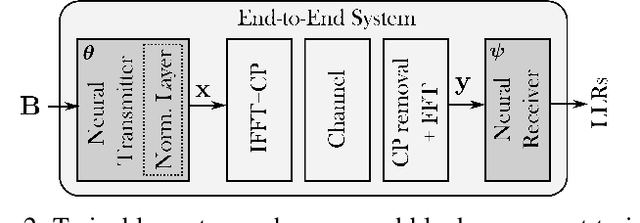
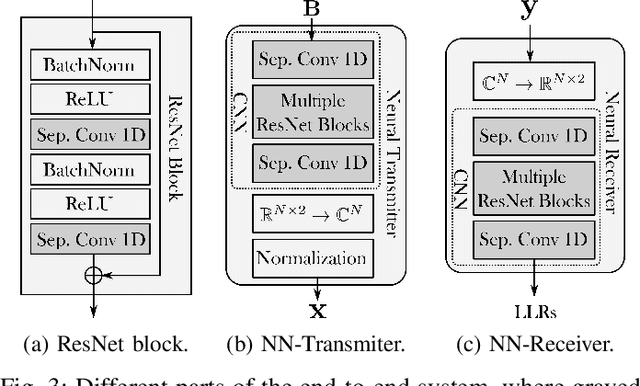
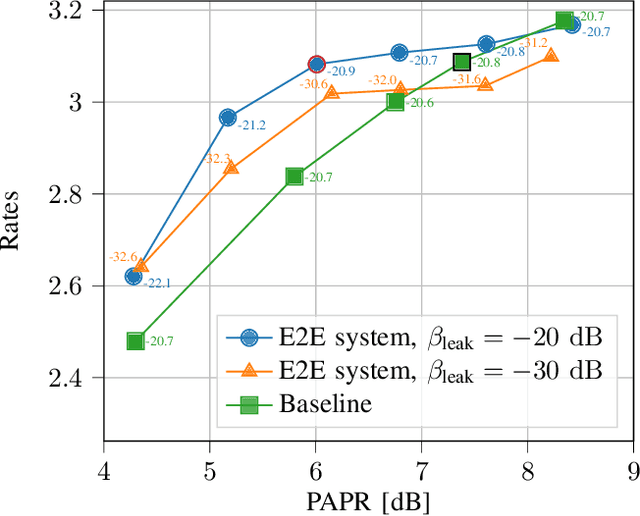
Orthogonal frequency-division multiplexing (OFDM) is widely used in modern wireless networks thanks to its efficient handling of multipath environment. However, it suffers from a poor peak-to-average power ratio (PAPR) which requires a large power backoff, degrading the power amplifier (PA) efficiency. In this work, we propose to use a neural network (NN) at the transmitter to learn a high-dimensional modulation scheme allowing to control the PAPR and adjacent channel leakage ratio (ACLR). On the receiver side, a NN-based receiver is implemented to carry out demapping of the transmitted bits. The two NNs operate on top of OFDM, and are jointly optimized in and end-to-end manner using a training algorithm that enforces constraints on the PAPR and ACLR. Simulation results show that the learned waveforms enable higher information rates than a tone reservation baseline, while satisfying predefined PAPR and ACLR targets.
SimpModeling: Sketching Implicit Field to Guide Mesh Modeling for 3D Animalmorphic Head Design
Aug 05, 2021

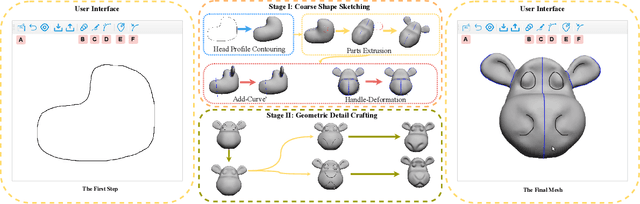
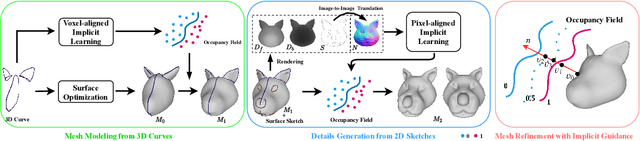
Head shapes play an important role in 3D character design. In this work, we propose SimpModeling, a novel sketch-based system for helping users, especially amateur users, easily model 3D animalmorphic heads - a prevalent kind of heads in character design. Although sketching provides an easy way to depict desired shapes, it is challenging to infer dense geometric information from sparse line drawings. Recently, deepnet-based approaches have been taken to address this challenge and try to produce rich geometric details from very few strokes. However, while such methods reduce users' workload, they would cause less controllability of target shapes. This is mainly due to the uncertainty of the neural prediction. Our system tackles this issue and provides good controllability from three aspects: 1) we separate coarse shape design and geometric detail specification into two stages and respectively provide different sketching means; 2) in coarse shape designing, sketches are used for both shape inference and geometric constraints to determine global geometry, and in geometric detail crafting, sketches are used for carving surface details; 3) in both stages, we use the advanced implicit-based shape inference methods, which have strong ability to handle the domain gap between freehand sketches and synthetic ones used for training. Experimental results confirm the effectiveness of our method and the usability of our interactive system. We also contribute to a dataset of high-quality 3D animal heads, which are manually created by artists.
Self-Attentive Ensemble Transformer: Representing Ensemble Interactions in Neural Networks for Earth System Models
Jun 21, 2021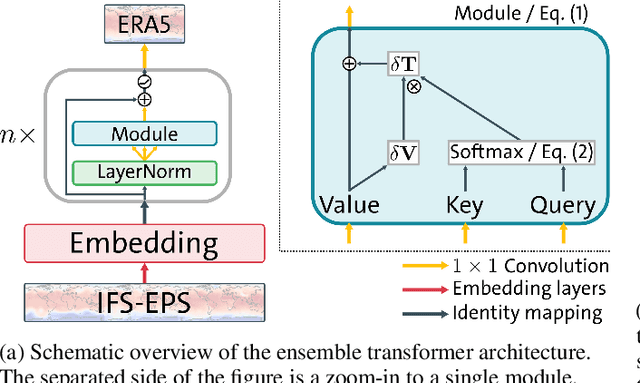
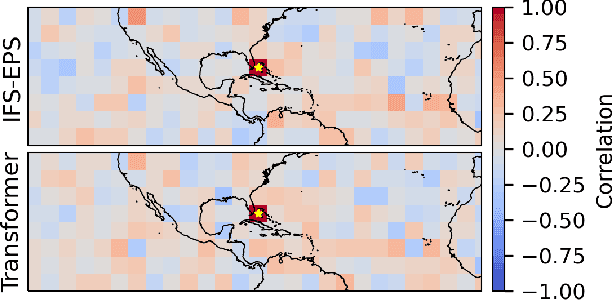
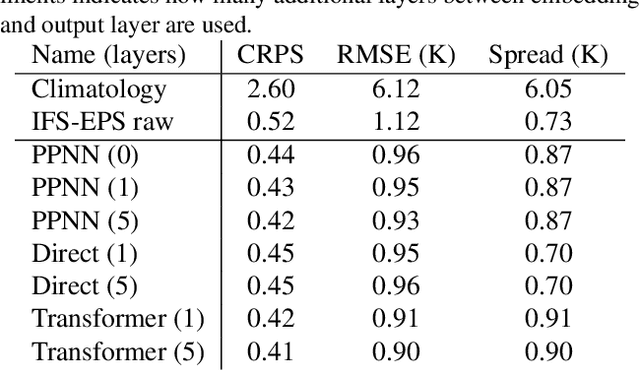

Ensemble data from Earth system models has to be calibrated and post-processed. I propose a novel member-by-member post-processing approach with neural networks. I bridge ideas from ensemble data assimilation with self-attention, resulting into the self-attentive ensemble transformer. Here, interactions between ensemble members are represented as additive and dynamic self-attentive part. As proof-of-concept, global ECMWF ensemble forecasts are regressed to 2-metre-temperature fields from the ERA5 reanalysis. I demonstrate that the ensemble transformer can calibrate the ensemble spread and extract additional information from the ensemble. Furthermore, the ensemble transformer directly outputs multivariate and spatially-coherent ensemble members. Therefore, self-attention and the transformer technique can be a missing piece for a member-by-member post-processing of ensemble data with neural networks.
Omnizart: A General Toolbox for Automatic Music Transcription
Jun 01, 2021We present and release Omnizart, a new Python library that provides a streamlined solution to automatic music transcription (AMT). Omnizart encompasses modules that construct the life-cycle of deep learning-based AMT, and is designed for ease of use with a compact command-line interface. To the best of our knowledge, Omnizart is the first transcription toolkit which offers models covering a wide class of instruments ranging from solo, instrument ensembles, percussion instruments to vocal, as well as models for chord recognition and beat/downbeat tracking, two music information retrieval (MIR) tasks highly related to AMT.
TBNet:Two-Stream Boundary-aware Network for Generic Image Manipulation Localization
Aug 10, 2021

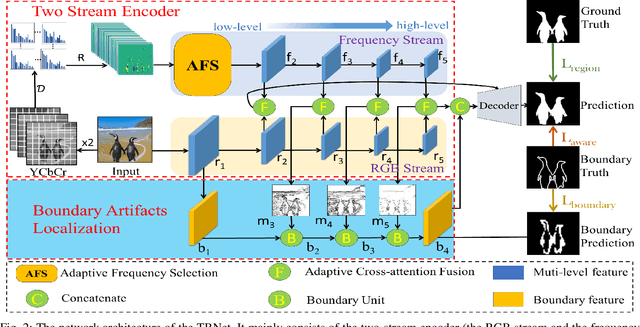
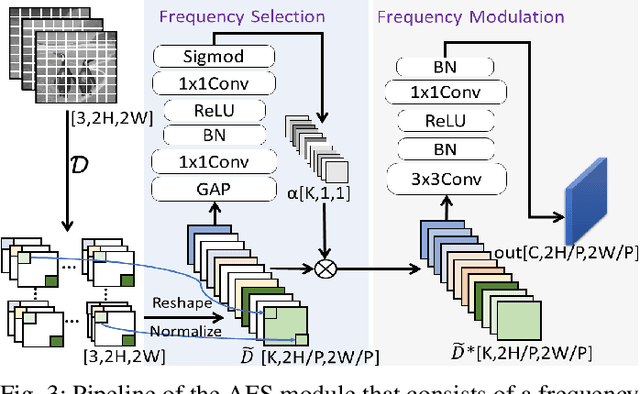
Finding tampered regions in images is a hot research topic in machine learning and computer vision. Although many image manipulation location algorithms have been proposed, most of them only focus on the RGB images with different color spaces, and the frequency information that contains the potential tampering clues is often ignored. In this work, a novel end-to-end two-stream boundary-aware network (abbreviated as TBNet) is proposed for generic image manipulation localization in which the RGB stream, the frequency stream, and the boundary artifact location are explored in a unified framework. Specifically, we first design an adaptive frequency selection module (AFS) to adaptively select the appropriate frequency to mine inconsistent statistics and eliminate the interference of redundant statistics. Then, an adaptive cross-attention fusion module (ACF) is proposed to adaptively fuse the RGB feature and the frequency feature. Finally, the boundary artifact location network (BAL) is designed to locate the boundary artifacts for which the parameters are jointly updated by the outputs of the ACF, and its results are further fed into the decoder. Thus, the parameters of the RGB stream, the frequency stream, and the boundary artifact location network are jointly optimized, and their latent complementary relationships are fully mined. The results of extensive experiments performed on four public benchmarks of the image manipulation localization task, namely, CASIA1.0, COVER, Carvalho, and In-The-Wild, demonstrate that the proposed TBNet can significantly outperform state-of-the-art generic image manipulation localization methods in terms of both MCC and F1.
Minimax Regret for Bandit Convex Optimisation of Ridge Functions
Jun 01, 2021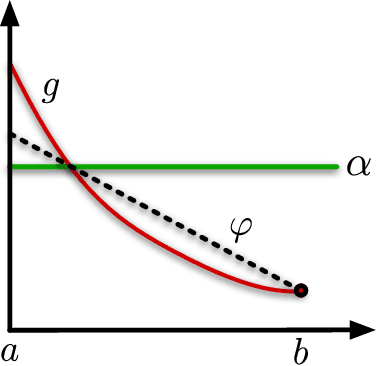
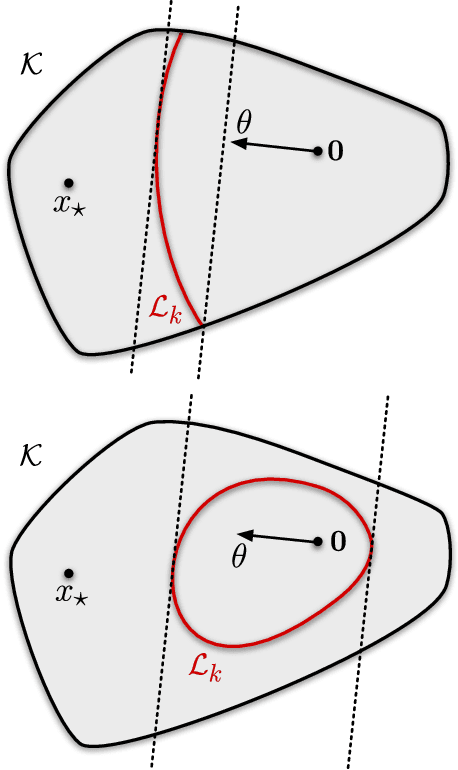
We analyse adversarial bandit convex optimisation with an adversary that is restricted to playing functions of the form $f(x) = g(\langle x, \theta\rangle)$ for convex $g : \mathbb R \to \mathbb R$ and $\theta \in \mathbb R^d$. We provide a short information-theoretic proof that the minimax regret is at most $O(d\sqrt{n} \log(\operatorname{diam}\mathcal K))$ where $n$ is the number of interactions, $d$ the dimension and $\operatorname{diam}(\mathcal K)$ is the diameter of the constraint set. Hence, this class of functions is at most logarithmically harder than the linear case.
Incorporating Domain Knowledge for Extractive Summarization of Legal Case Documents
Jun 30, 2021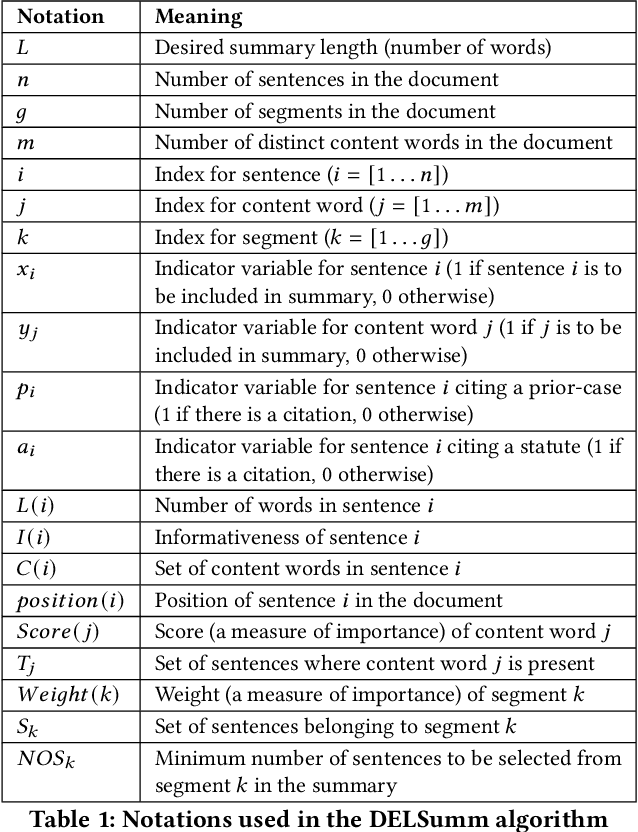
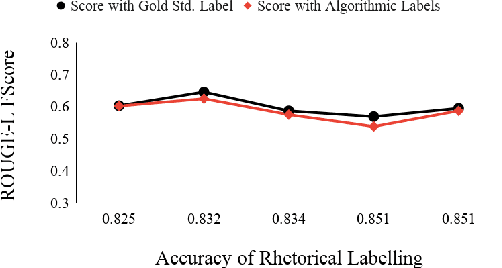

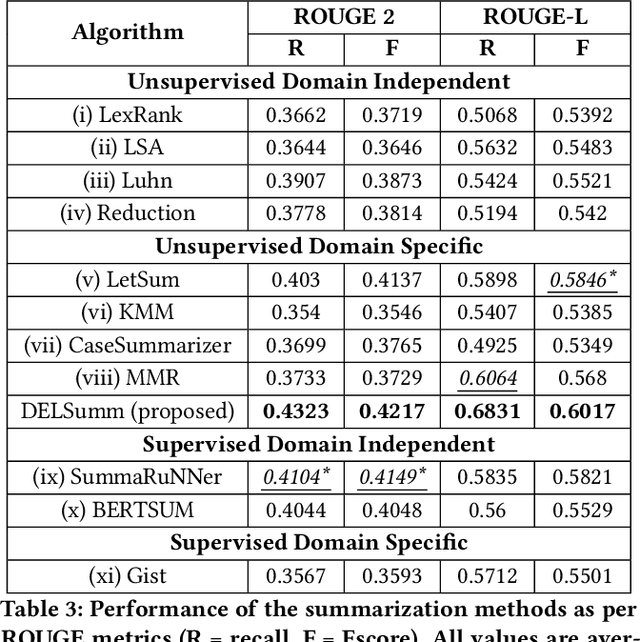
Automatic summarization of legal case documents is an important and practical challenge. Apart from many domain-independent text summarization algorithms that can be used for this purpose, several algorithms have been developed specifically for summarizing legal case documents. However, most of the existing algorithms do not systematically incorporate domain knowledge that specifies what information should ideally be present in a legal case document summary. To address this gap, we propose an unsupervised summarization algorithm DELSumm which is designed to systematically incorporate guidelines from legal experts into an optimization setup. We conduct detailed experiments over case documents from the Indian Supreme Court. The experiments show that our proposed unsupervised method outperforms several strong baselines in terms of ROUGE scores, including both general summarization algorithms and legal-specific ones. In fact, though our proposed algorithm is unsupervised, it outperforms several supervised summarization models that are trained over thousands of document-summary pairs.
Dual-Octave Convolution for Accelerated Parallel MR Image Reconstruction
Apr 12, 2021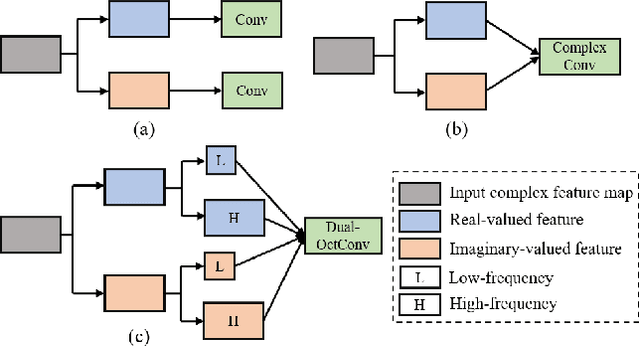
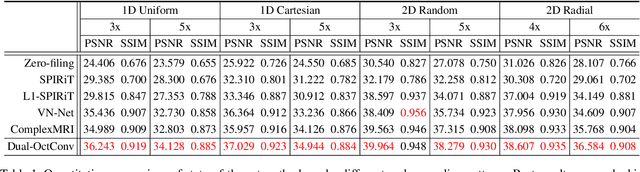
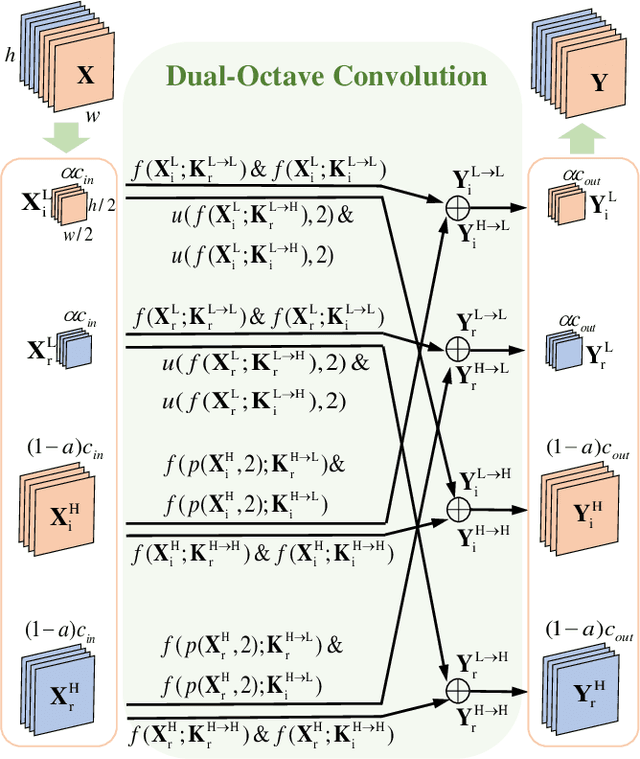
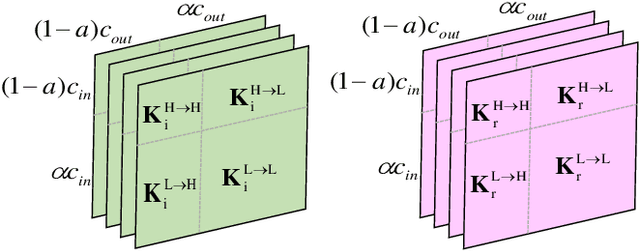
Magnetic resonance (MR) image acquisition is an inherently prolonged process, whose acceleration by obtaining multiple undersampled images simultaneously through parallel imaging has always been the subject of research. In this paper, we propose the Dual-Octave Convolution (Dual-OctConv), which is capable of learning multi-scale spatial-frequency features from both real and imaginary components, for fast parallel MR image reconstruction. By reformulating the complex operations using octave convolutions, our model shows a strong ability to capture richer representations of MR images, while at the same time greatly reducing the spatial redundancy. More specifically, the input feature maps and convolutional kernels are first split into two components (i.e., real and imaginary), which are then divided into four groups according to their spatial frequencies. Then, our Dual-OctConv conducts intra-group information updating and inter-group information exchange to aggregate the contextual information across different groups. Our framework provides two appealing benefits: (i) it encourages interactions between real and imaginary components at various spatial frequencies to achieve richer representational capacity, and (ii) it enlarges the receptive field by learning multiple spatial-frequency features of both the real and imaginary components. We evaluate the performance of the proposed model on the acceleration of multi-coil MR image reconstruction. Extensive experiments are conducted on an {in vivo} knee dataset under different undersampling patterns and acceleration factors. The experimental results demonstrate the superiority of our model in accelerated parallel MR image reconstruction. Our code is available at: github.com/chunmeifeng/Dual-OctConv.
* Proceedings of the 35th AAAI Conference on Artificial Intelligence (AAAI) 2021