 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Video Rescaling Networks with Joint Optimization Strategies for Downscaling and Upscaling
Mar 27, 2021
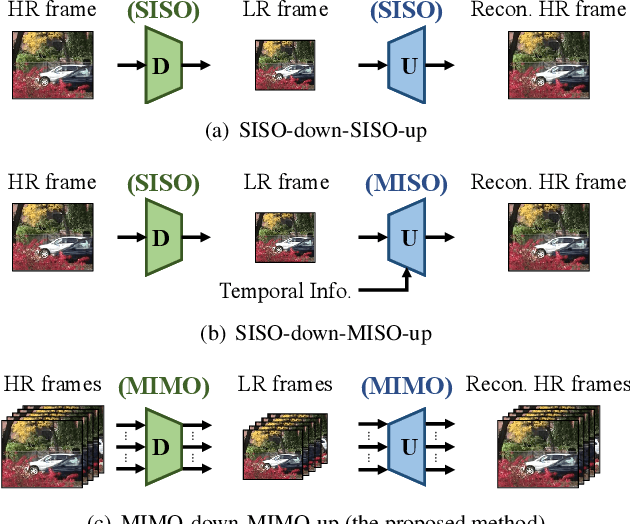
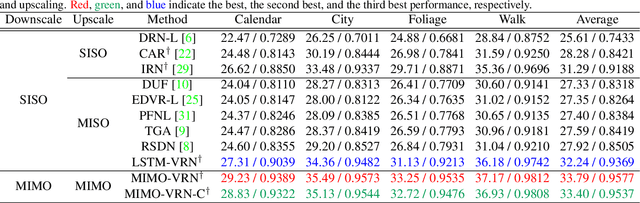
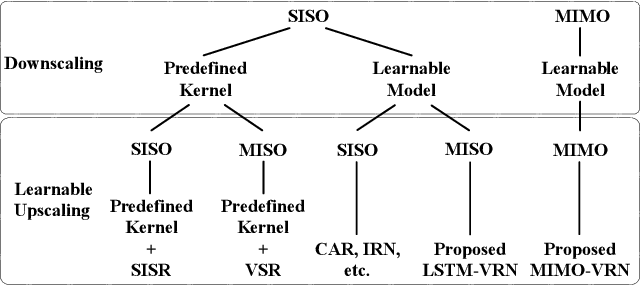
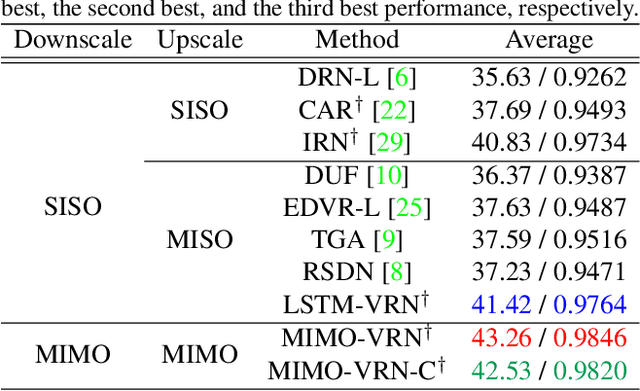
This paper addresses the video rescaling task, which arises from the needs of adapting the video spatial resolution to suit individual viewing devices. We aim to jointly optimize video downscaling and upscaling as a combined task. Most recent studies focus on image-based solutions, which do not consider temporal information. We present two joint optimization approaches based on invertible neural networks with coupling layers. Our Long Short-Term Memory Video Rescaling Network (LSTM-VRN) leverages temporal information in the low-resolution video to form an explicit prediction of the missing high-frequency information for upscaling. Our Multi-input Multi-output Video Rescaling Network (MIMO-VRN) proposes a new strategy for downscaling and upscaling a group of video frames simultaneously. Not only do they outperform the image-based invertible model in terms of quantitative and qualitative results, but also show much improved upscaling quality than the video rescaling methods without joint optimization. To our best knowledge, this work is the first attempt at the joint optimization of video downscaling and upscaling.
Deep Position-wise Interaction Network for CTR Prediction
Jun 10, 2021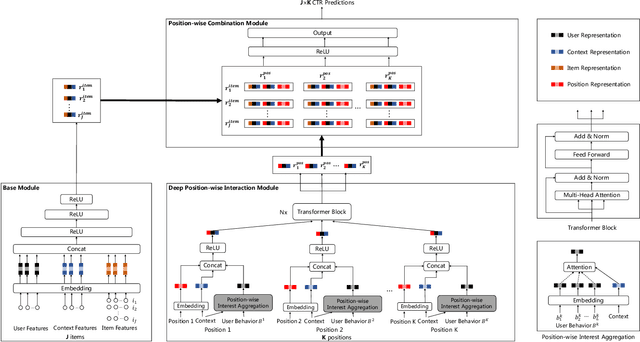
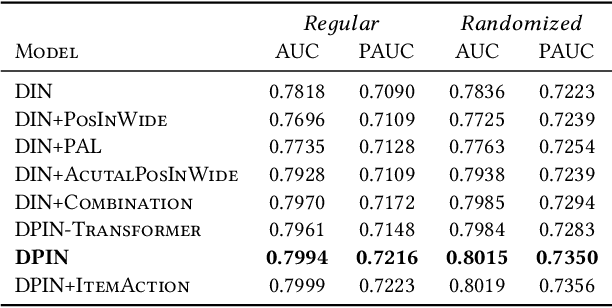
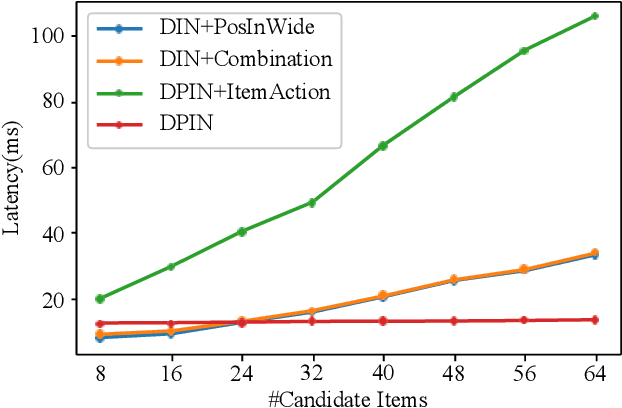
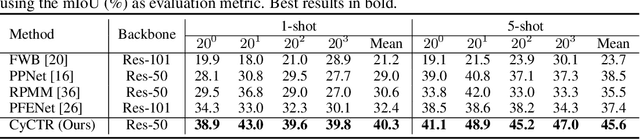
Click-through rate (CTR) prediction plays an important role in online advertising and recommender systems. In practice, the training of CTR models depends on click data which is intrinsically biased towards higher positions since higher position has higher CTR by nature. Existing methods such as actual position training with fixed position inference and inverse propensity weighted training with no position inference alleviate the bias problem to some extend. However, the different treatment of position information between training and inference will inevitably lead to inconsistency and sub-optimal online performance. Meanwhile, the basic assumption of these methods, i.e., the click probability is the product of examination probability and relevance probability, is oversimplified and insufficient to model the rich interaction between position and other information. In this paper, we propose a Deep Position-wise Interaction Network (DPIN) to efficiently combine all candidate items and positions for estimating CTR at each position, achieving consistency between offline and online as well as modeling the deep non-linear interaction among position, user, context and item under the limit of serving performance. Following our new treatment to the position bias in CTR prediction, we propose a new evaluation metrics named PAUC (position-wise AUC) that is suitable for measuring the ranking quality at a given position. Through extensive experiments on a real world dataset, we show empirically that our method is both effective and efficient in solving position bias problem. We have also deployed our method in production and observed statistically significant improvement over a highly optimized baseline in a rigorous A/B test.
Few-Shot Segmentation via Cycle-Consistent Transformer
Jun 04, 2021
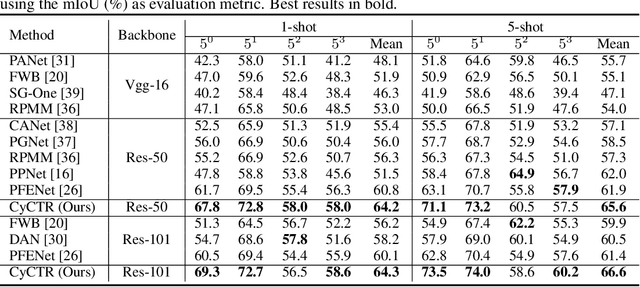
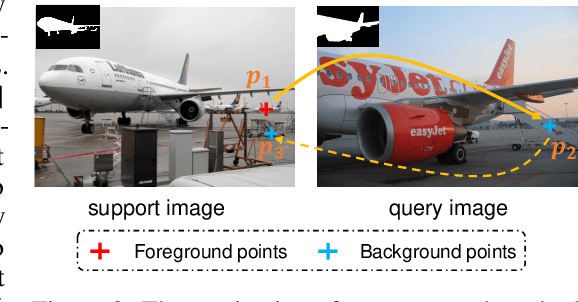
Few-shot segmentation aims to train a segmentation model that can fast adapt to novel classes with few exemplars. The conventional training paradigm is to learn to make predictions on query images conditioned on the features from support images. Previous methods only utilized the semantic-level prototypes of support images as the conditional information. These methods cannot utilize all pixel-wise support information for the query predictions, which is however critical for the segmentation task. In this paper, we focus on utilizing pixel-wise relationships between support and target images to facilitate the few-shot semantic segmentation task. We design a novel Cycle-Consistent Transformer (CyCTR) module to aggregate pixel-wise support features into query ones. CyCTR performs cross-attention between features from different images, i.e. support and query images. We observe that there may exist unexpected irrelevant pixel-level support features. Directly performing cross-attention may aggregate these features from support to query and bias the query features. Thus, we propose using a novel cycle-consistent attention mechanism to filter out possible harmful support features and encourage query features to attend to the most informative pixels from support images. Experiments on all few-shot segmentation benchmarks demonstrate that our proposed CyCTR leads to remarkable improvement compared to previous state-of-the-art methods. Specifically, on Pascal-$5^i$ and COCO-$20^i$ datasets, we achieve 66.6% and 45.6% mIoU for 5-shot segmentation, outperforming previous state-of-the-art by 4.6% and 7.1% respectively.
Mixture of Virtual-Kernel Experts for Multi-Objective User Profile Modeling
Jun 04, 2021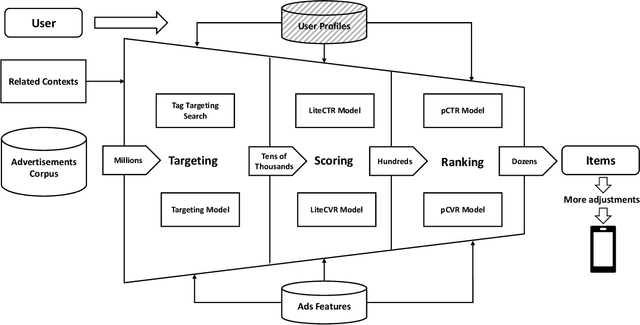

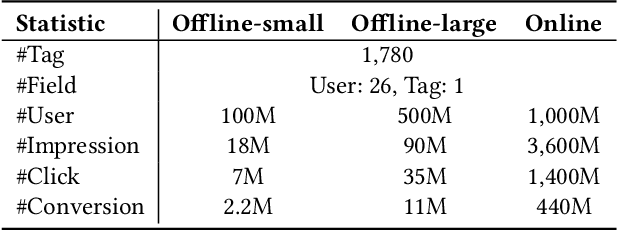
In many industrial applications like online advertising and recommendation systems, diverse and accurate user profiles can greatly help improve personalization. For building user profiles, deep learning is widely used to mine expressive tags to describe users' preferences from their historical actions. For example, tags mined from users' click-action history can represent the categories of ads that users are interested in, and they are likely to continue being clicked in the future. Traditional solutions usually introduce multiple independent Two-Tower models to mine tags from different actions, e.g., click, conversion. However, the models cannot learn complementarily and support effective training for data-sparse actions. Besides, limited by the lack of information fusion between the two towers, the model learning is insufficient to represent users' preferences on various topics well. This paper introduces a novel multi-task model called Mixture of Virtual-Kernel Experts (MVKE) to learn multiple topic-related user preferences based on different actions unitedly. In MVKE, we propose a concept of Virtual-Kernel Expert, which focuses on modeling one particular facet of the user's preference, and all of them learn coordinately. Besides, the gate-based structure used in MVKE builds an information fusion bridge between two towers, improving the model's capability much and maintaining high efficiency. We apply the model in Tencent Advertising System, where both online and offline evaluations show that our method has a significant improvement compared with the existing ones and brings about an obvious lift to actual advertising revenue.
Points2Sound: From mono to binaural audio using 3D point cloud scenes
Apr 26, 2021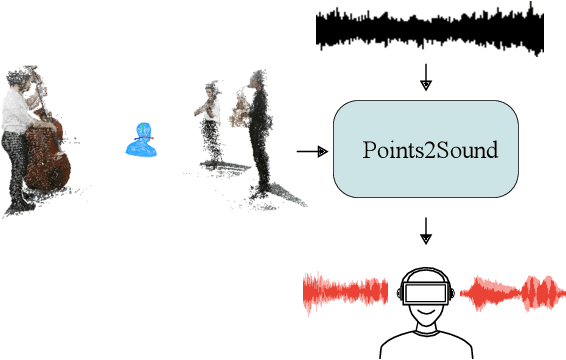
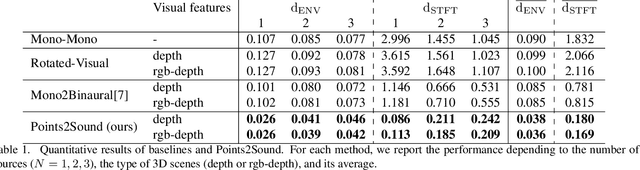
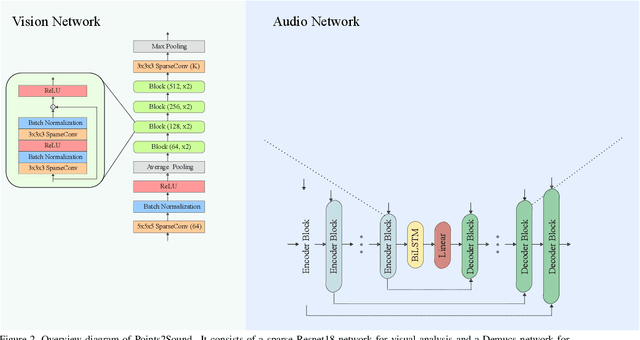
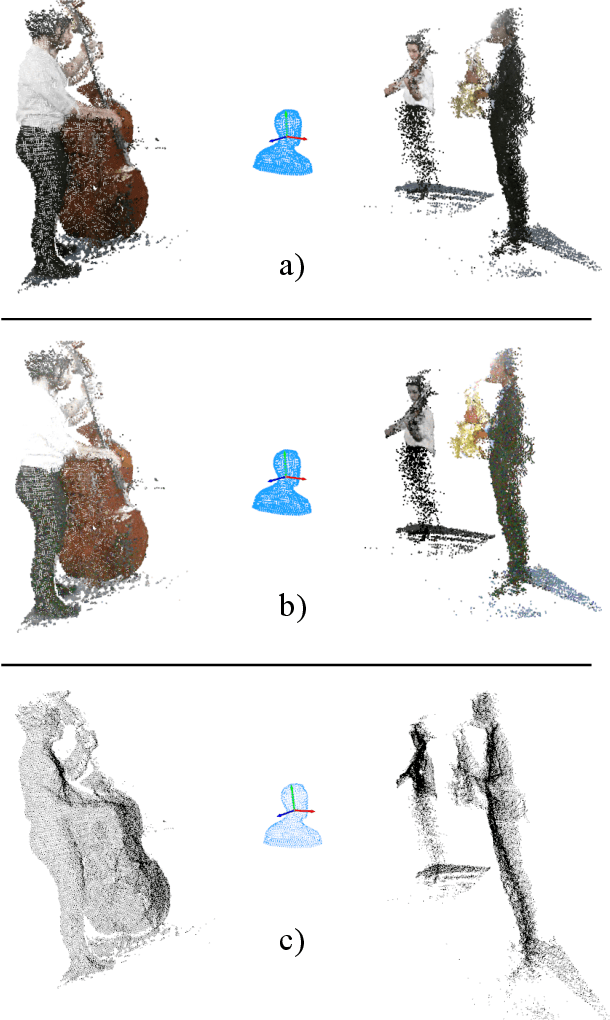
Binaural sound that matches the visual counterpart is crucial to bring meaningful and immersive experiences to people in augmented reality (AR) and virtual reality (VR) applications. Recent works have shown the possibility to generate binaural audio from mono using 2D visual information as guidance. Using 3D visual information may allow for a more accurate representation of a virtual audio scene for VR/AR applications. This paper proposes Points2Sound, a multi-modal deep learning model which generates a binaural version from mono audio using 3D point cloud scenes. Specifically, Points2Sound consist of a vision network which extracts visual features from the point cloud scene to condition an audio network, which operates in the waveform domain, to synthesize the binaural version. Both quantitative and perceptual evaluations indicate that our proposed model is preferred over a reference case, based on a recent 2D mono-to-binaural model.
A Deep Reinforcement Learning Approach for Traffic Signal Control Optimization
Jul 13, 2021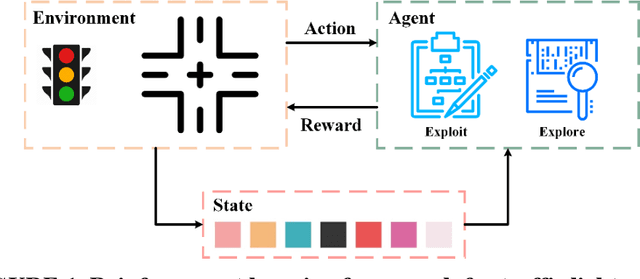
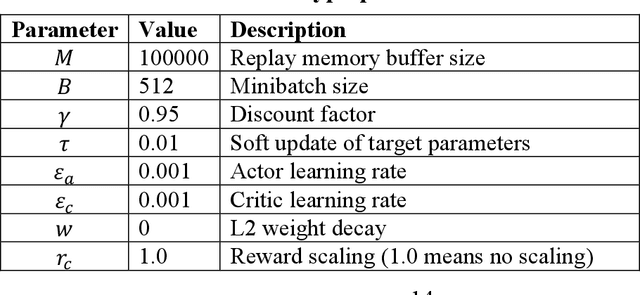
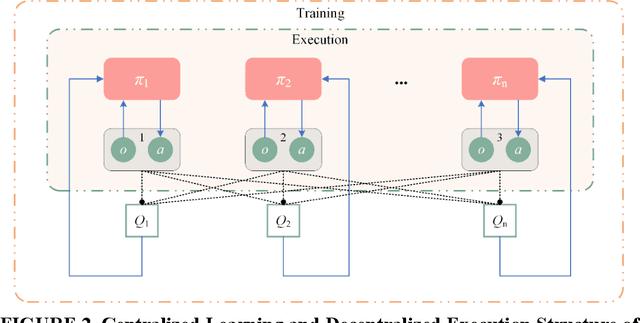
Inefficient traffic signal control methods may cause numerous problems, such as traffic congestion and waste of energy. Reinforcement learning (RL) is a trending data-driven approach for adaptive traffic signal control in complex urban traffic networks. Although the development of deep neural networks (DNN) further enhances its learning capability, there are still some challenges in applying deep RLs to transportation networks with multiple signalized intersections, including non-stationarity environment, exploration-exploitation dilemma, multi-agent training schemes, continuous action spaces, etc. In order to address these issues, this paper first proposes a multi-agent deep deterministic policy gradient (MADDPG) method by extending the actor-critic policy gradient algorithms. MADDPG has a centralized learning and decentralized execution paradigm in which critics use additional information to streamline the training process, while actors act on their own local observations. The model is evaluated via simulation on the Simulation of Urban MObility (SUMO) platform. Model comparison results show the efficiency of the proposed algorithm in controlling traffic lights.
Computation and Communication Co-Design for Real-Time Monitoring and Control in Multi-Agent Systems
Aug 09, 2021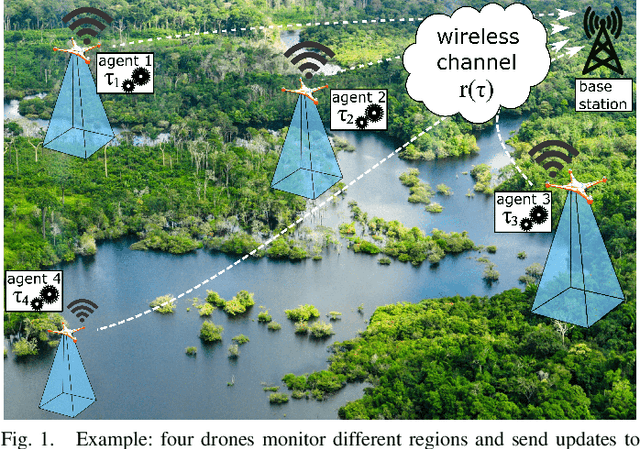
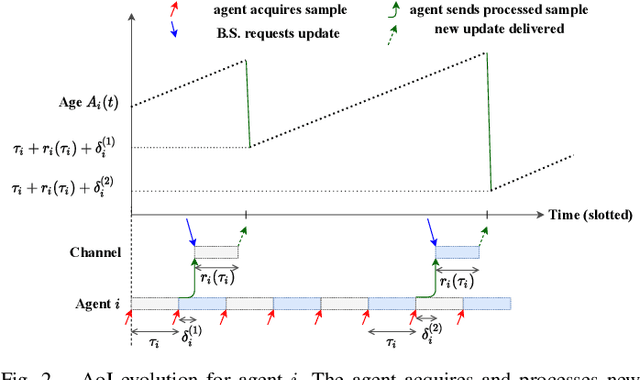
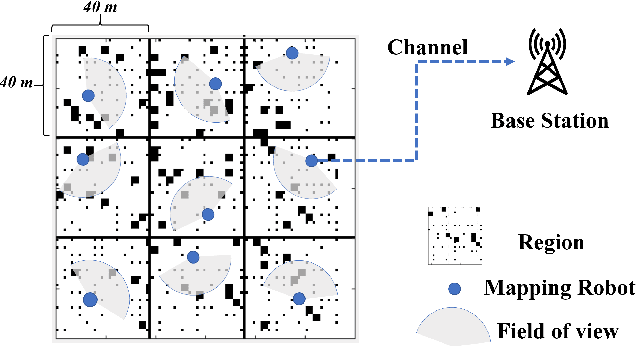
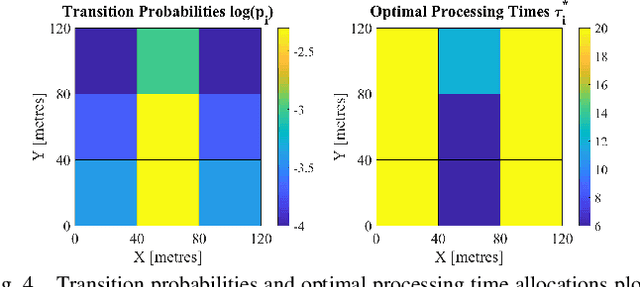
We investigate the problem of co-designing computation and communication in a multi-agent system (e.g. a sensor network or a multi-robot team). We consider the realistic setting where each agent acquires sensor data and is capable of local processing before sending updates to a base station, which is in charge of making decisions or monitoring phenomena of interest in real time. Longer processing at an agent leads to more informative updates but also larger delays, giving rise to a delay-accuracy-tradeoff in choosing the right amount of local processing at each agent. We assume that the available communication resources are limited due to interference, bandwidth, and power constraints. Thus, a scheduling policy needs to be designed to suitably share the communication channel among the agents. To that end, we develop a general formulation to jointly optimize the local processing at the agents and the scheduling of transmissions. Our novel formulation leverages the notion of Age of Information to quantify the freshness of data and capture the delays caused by computation and communication. We develop efficient resource allocation algorithms using the Whittle index approach and demonstrate our proposed algorithms in two practical applications: multi-agent occupancy grid mapping in time-varying environments, and ride sharing in autonomous vehicle networks. Our experiments show that the proposed co-design approach leads to a substantial performance improvement (18-82% in our tests).
Generating Superpixels for High-resolution Images with Decoupled Patch Calibration
Aug 19, 2021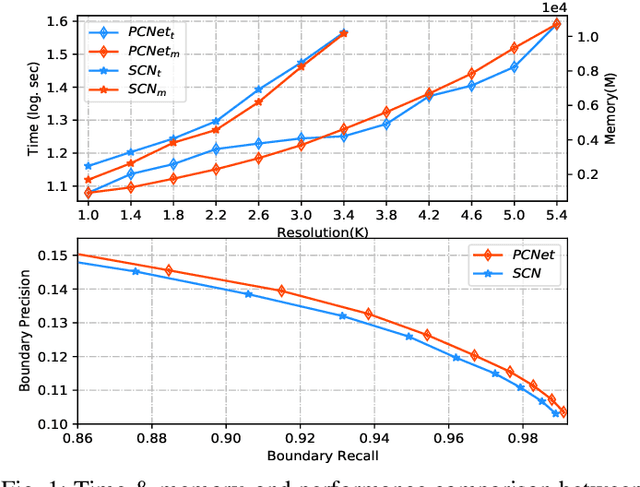
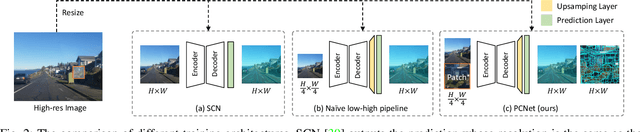
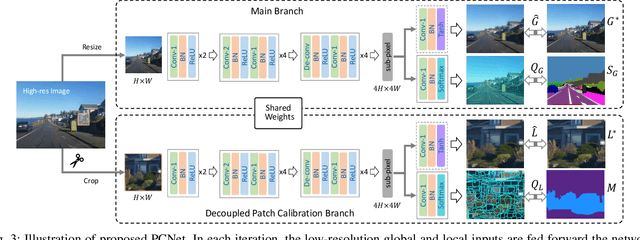
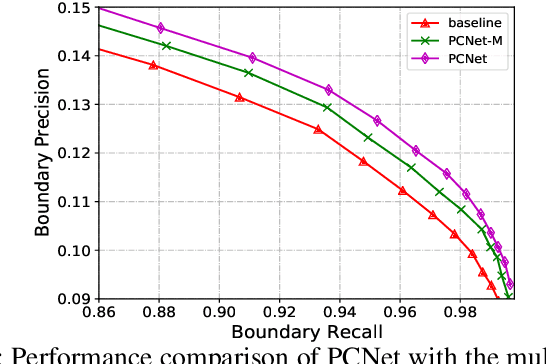
Superpixel segmentation has recently seen important progress benefiting from the advances in differentiable deep learning. However, the very high-resolution superpixel segmentation still remains challenging due to the expensive memory and computation cost, making the current advanced superpixel networks fail to process. In this paper, we devise Patch Calibration Networks (PCNet), aiming to efficiently and accurately implement high-resolution superpixel segmentation. PCNet follows the principle of producing high-resolution output from low-resolution input for saving GPU memory and relieving computation cost. To recall the fine details destroyed by the down-sampling operation, we propose a novel Decoupled Patch Calibration (DPC) branch for collaboratively augment the main superpixel generation branch. In particular, DPC takes a local patch from the high-resolution images and dynamically generates a binary mask to impose the network to focus on region boundaries. By sharing the parameters of DPC and main branches, the fine-detailed knowledge learned from high-resolution patches will be transferred to help calibrate the destroyed information. To the best of our knowledge, we make the first attempt to consider the deep-learning-based superpixel generation for high-resolution cases. To facilitate this research, we build evaluation benchmarks from two public datasets and one new constructed one, covering a wide range of diversities from fine-grained human parts to cityscapes. Extensive experiments demonstrate that our PCNet can not only perform favorably against the state-of-the-arts in the quantitative results but also improve the resolution upper bound from 3K to 5K on 1080Ti GPUs.
FedCM: Federated Learning with Client-level Momentum
Jun 21, 2021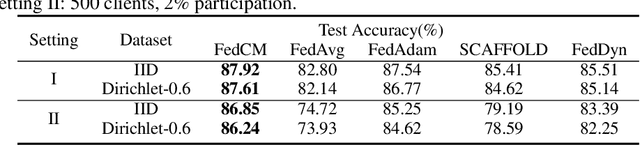
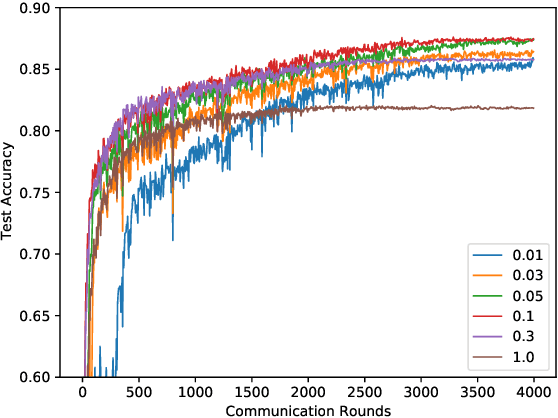
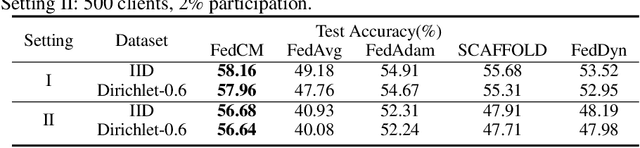
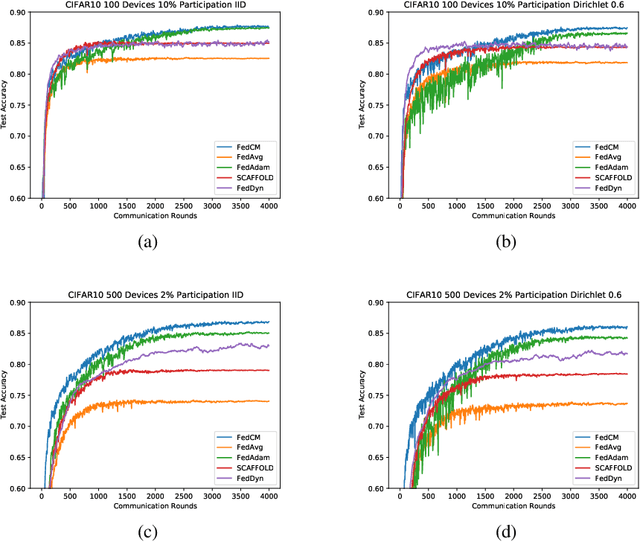
Federated Learning is a distributed machine learning approach which enables model training without data sharing. In this paper, we propose a new federated learning algorithm, Federated Averaging with Client-level Momentum (FedCM), to tackle problems of partial participation and client heterogeneity in real-world federated learning applications. FedCM aggregates global gradient information in previous communication rounds and modifies client gradient descent with a momentum-like term, which can effectively correct the bias and improve the stability of local SGD. We provide theoretical analysis to highlight the benefits of FedCM. We also perform extensive empirical studies and demonstrate that FedCM achieves superior performance in various tasks and is robust to different levels of client numbers, participation rate and client heterogeneity.
BUDA-SAGE with self-supervised denoising enables fast, distortion-free, high-resolution T2, T2*, para- and dia-magnetic susceptibility mapping
Aug 28, 2021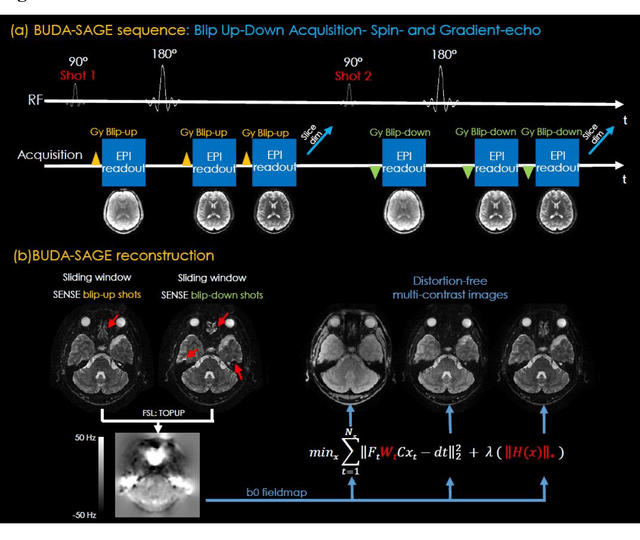
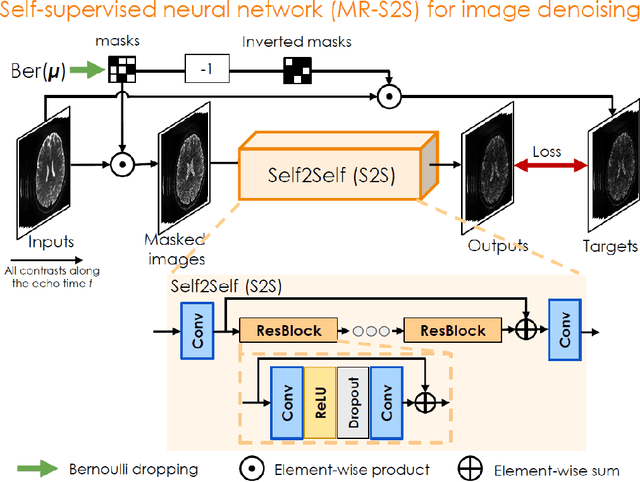

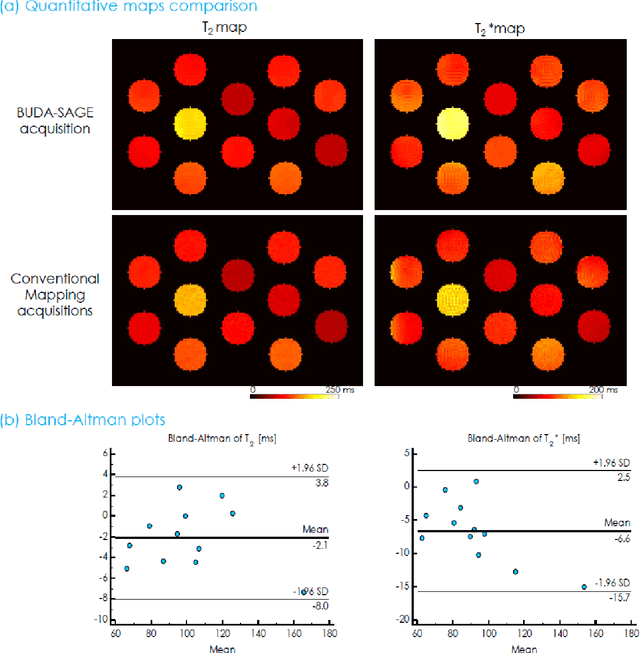
To rapidly obtain high resolution T2, T2* and quantitative susceptibility mapping (QSM) source separation maps with whole-brain coverage and high geometric fidelity. We propose Blip Up-Down Acquisition for Spin And Gradient Echo imaging (BUDA-SAGE), an efficient echo-planar imaging (EPI) sequence for quantitative mapping. The acquisition includes multiple T2*-, T2'- and T2-weighted contrasts. We alternate the phase-encoding polarities across the interleaved shots in this multi-shot navigator-free acquisition. A field map estimated from interim reconstructions was incorporated into the joint multi-shot EPI reconstruction with a structured low rank constraint to eliminate geometric distortion. A self-supervised MR-Self2Self (MR-S2S) neural network (NN) was utilized to perform denoising after BUDA reconstruction to boost SNR. Employing Slider encoding allowed us to reach 1 mm isotropic resolution by performing super-resolution reconstruction on BUDA-SAGE volumes acquired with 2 mm slice thickness. Quantitative T2 and T2* maps were obtained using Bloch dictionary matching on the reconstructed echoes. QSM was estimated using nonlinear dipole inversion (NDI) on the gradient echoes. Starting from the estimated R2 and R2* maps, R2' information was derived and used in source separation QSM reconstruction, which provided additional para- and dia-magnetic susceptibility maps. In vivo results demonstrate the ability of BUDA-SAGE to provide whole-brain, distortion-free, high-resolution multi-contrast images and quantitative T2 and T2* maps, as well as yielding para- and dia-magnetic susceptibility maps. Derived quantitative maps showed comparable values to conventional mapping methods in phantom and in vivo measurements. BUDA-SAGE acquisition with self-supervised denoising and Slider encoding enabled rapid, distortion-free, whole-brain T2, T2* mapping at 1 mm3 isotropic resolution in 90 seconds.