 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Focusing on Shadows for Predicting Heightmaps from Single Remotely Sensed RGB Images with Deep Learning
Apr 22, 2021
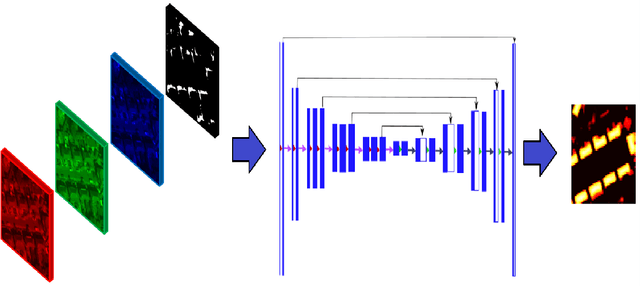

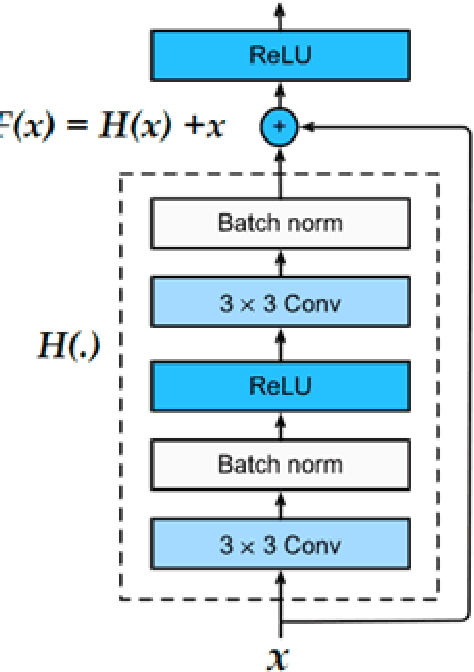
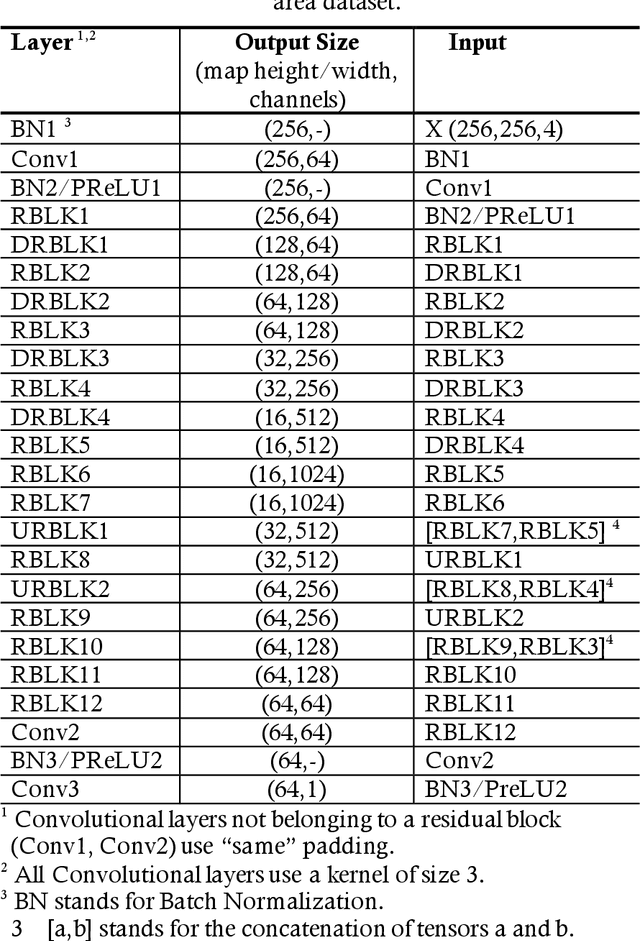
Estimating the heightmaps of buildings and vegetation in single remotely sensed images is a challenging problem. Effective solutions to this problem can comprise the stepping stone for solving complex and demanding problems that require 3D information of aerial imagery in the remote sensing discipline, which might be expensive or not feasible to require. We propose a task-focused Deep Learning (DL) model that takes advantage of the shadow map of a remotely sensed image to calculate its heightmap. The shadow is computed efficiently and does not add significant computation complexity. The model is trained with aerial images and their Lidar measurements, achieving superior performance on the task. We validate the model with a dataset covering a large area of Manchester, UK, as well as the 2018 IEEE GRSS Data Fusion Contest Lidar dataset. Our work suggests that the proposed DL architecture and the technique of injecting shadows information into the model are valuable for improving the heightmap estimation task for single remotely sensed imagery.
On Effects of Compression with Hyperdimensional Computing in Distributed Randomized Neural Networks
Jun 17, 2021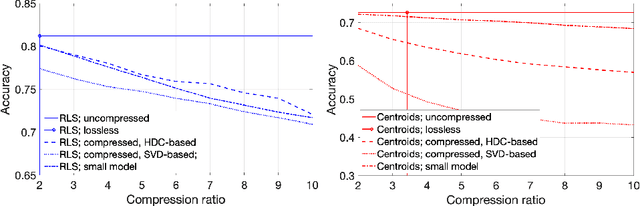
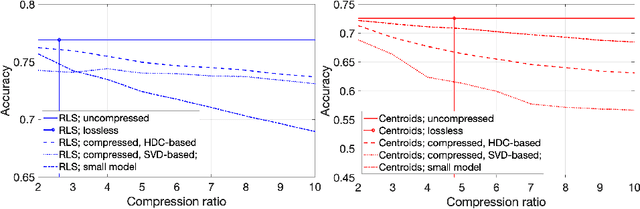
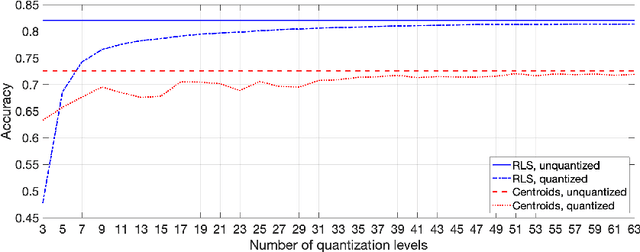
A change of the prevalent supervised learning techniques is foreseeable in the near future: from the complex, computational expensive algorithms to more flexible and elementary training ones. The strong revitalization of randomized algorithms can be framed in this prospect steering. We recently proposed a model for distributed classification based on randomized neural networks and hyperdimensional computing, which takes into account cost of information exchange between agents using compression. The use of compression is important as it addresses the issues related to the communication bottleneck, however, the original approach is rigid in the way the compression is used. Therefore, in this work, we propose a more flexible approach to compression and compare it to conventional compression algorithms, dimensionality reduction, and quantization techniques.
A Context-Dependent Gated Module for Incorporating Symbolic Semantics into Event Coreference Resolution
Apr 04, 2021
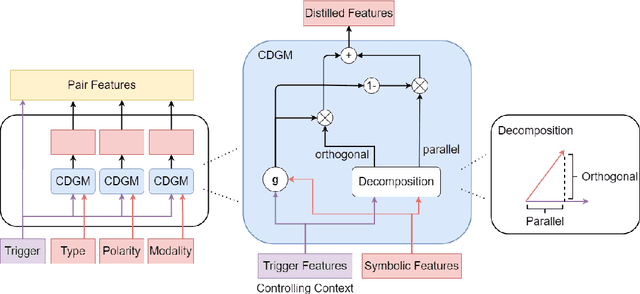
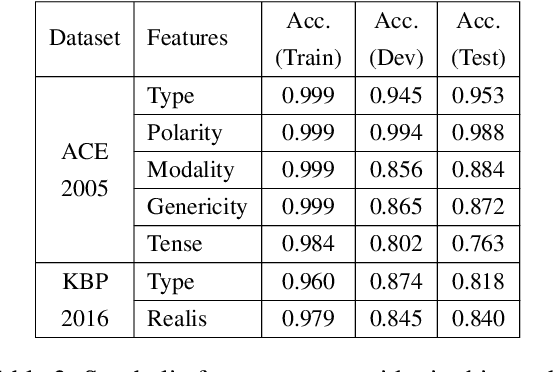
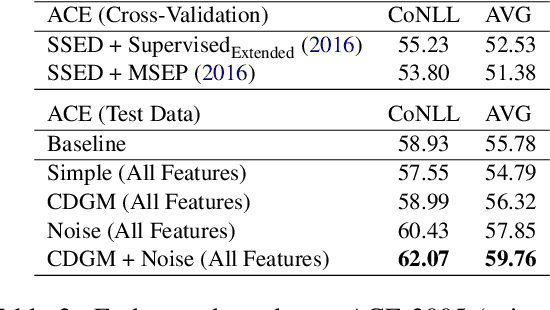
Event coreference resolution is an important research problem with many applications. Despite the recent remarkable success of pretrained language models, we argue that it is still highly beneficial to utilize symbolic features for the task. However, as the input for coreference resolution typically comes from upstream components in the information extraction pipeline, the automatically extracted symbolic features can be noisy and contain errors. Also, depending on the specific context, some features can be more informative than others. Motivated by these observations, we propose a novel context-dependent gated module to adaptively control the information flows from the input symbolic features. Combined with a simple noisy training method, our best models achieve state-of-the-art results on two datasets: ACE 2005 and KBP 2016.
Learning Fair Face Representation With Progressive Cross Transformer
Aug 11, 2021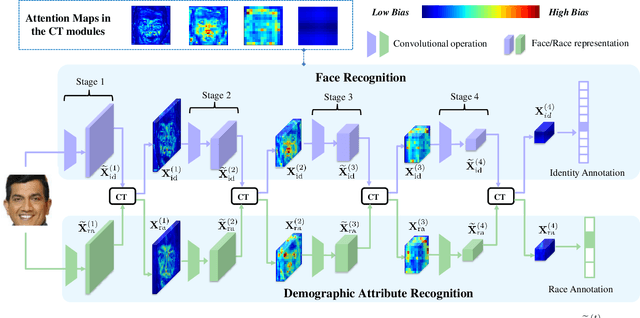
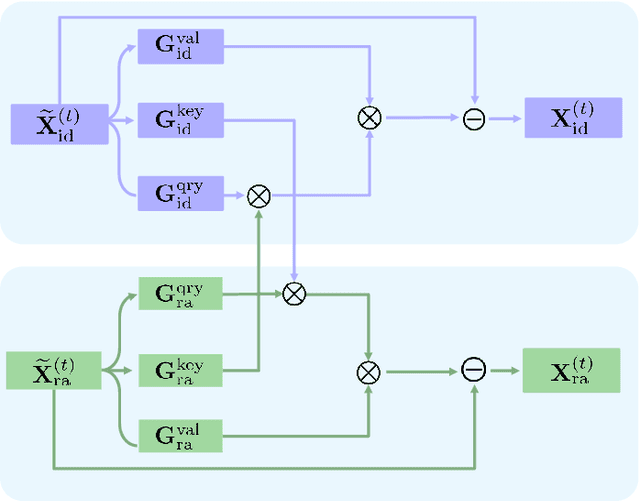
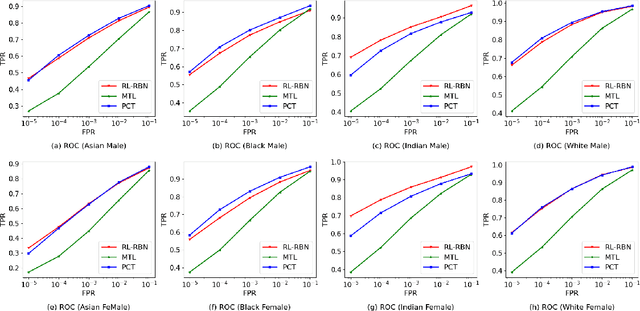
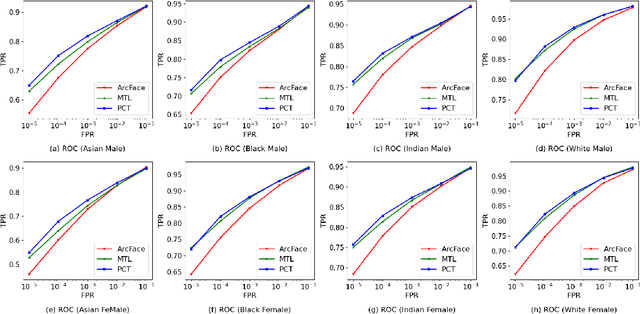
Face recognition (FR) has made extraordinary progress owing to the advancement of deep convolutional neural networks. However, demographic bias among different racial cohorts still challenges the practical face recognition system. The race factor has been proven to be a dilemma for fair FR (FFR) as the subject-related specific attributes induce the classification bias whilst carrying some useful cues for FR. To mitigate racial bias and meantime preserve robust FR, we abstract face identity-related representation as a signal denoising problem and propose a progressive cross transformer (PCT) method for fair face recognition. Originating from the signal decomposition theory, we attempt to decouple face representation into i) identity-related components and ii) noisy/identity-unrelated components induced by race. As an extension of signal subspace decomposition, we formulate face decoupling as a generalized functional expression model to cross-predict face identity and race information. The face expression model is further concretized by designing dual cross-transformers to distill identity-related components and suppress racial noises. In order to refine face representation, we take a progressive face decoupling way to learn identity/race-specific transformations, so that identity-unrelated components induced by race could be better disentangled. We evaluate the proposed PCT on the public fair face recognition benchmarks (BFW, RFW) and verify that PCT is capable of mitigating bias in face recognition while achieving state-of-the-art FR performance. Besides, visualization results also show that the attention maps in PCT can well reveal the race-related/biased facial regions.
Simple black-box universal adversarial attacks on medical image classification based on deep neural networks
Aug 11, 2021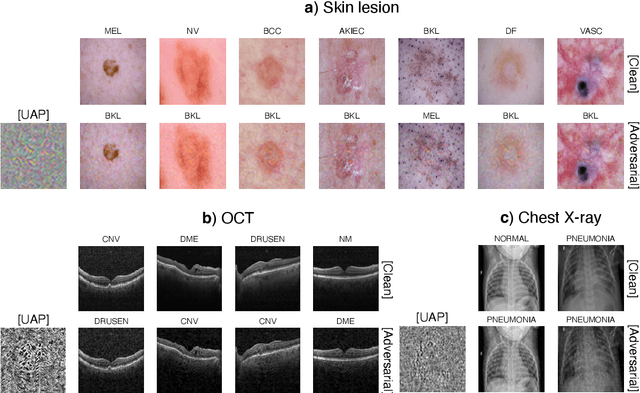
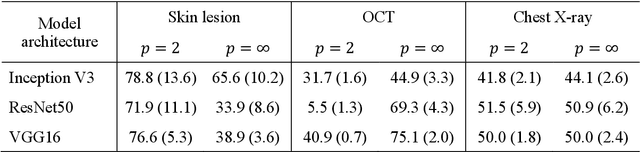
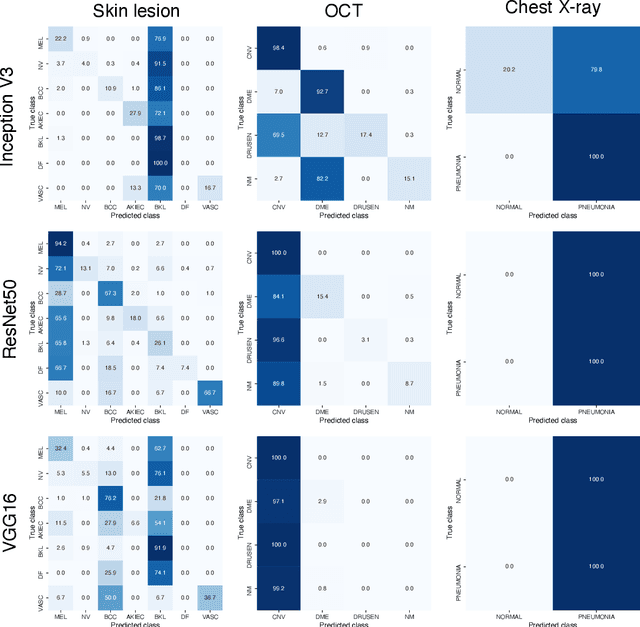
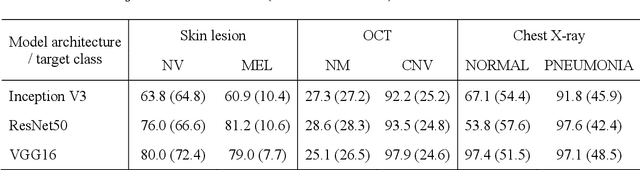
Universal adversarial attacks, which hinder most deep neural network (DNN) tasks using only a small single perturbation called a universal adversarial perturbation (UAP), is a realistic security threat to the practical application of a DNN. In particular, such attacks cause serious problems in medical imaging. Given that computer-based systems are generally operated under a black-box condition in which only queries on inputs are allowed and outputs are accessible, the impact of UAPs seems to be limited because well-used algorithms for generating UAPs are limited to a white-box condition in which adversaries can access the model weights and loss gradients. Nevertheless, we demonstrate that UAPs are easily generatable using a relatively small dataset under black-box conditions. In particular, we propose a method for generating UAPs using a simple hill-climbing search based only on DNN outputs and demonstrate the validity of the proposed method using representative DNN-based medical image classifications. Black-box UAPs can be used to conduct both non-targeted and targeted attacks. Overall, the black-box UAPs showed high attack success rates (40% to 90%), although some of them had relatively low success rates because the method only utilizes limited information to generate UAPs. The vulnerability of black-box UAPs was observed in several model architectures. The results indicate that adversaries can also generate UAPs through a simple procedure under the black-box condition to foil or control DNN-based medical image diagnoses, and that UAPs are a more realistic security threat.
AtrialGeneral: Domain Generalization for Left Atrial Segmentation of Multi-Center LGE MRIs
Jul 05, 2021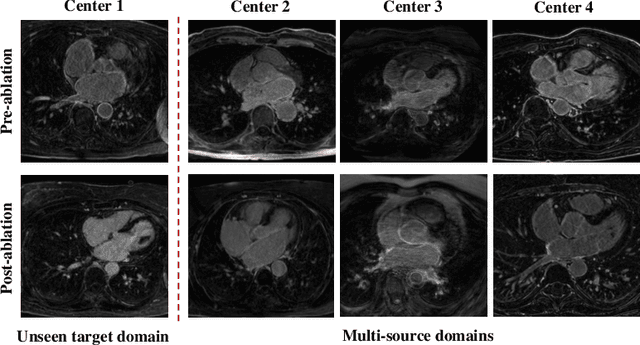

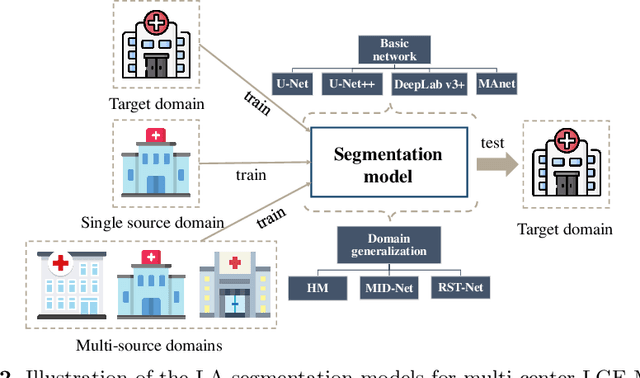
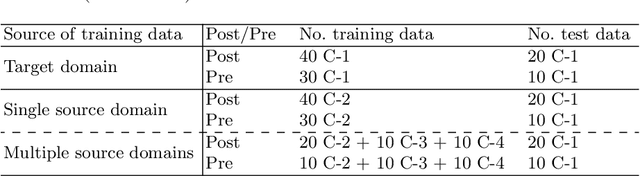
Left atrial (LA) segmentation from late gadolinium enhanced magnetic resonance imaging (LGE MRI) is a crucial step needed for planning the treatment of atrial fibrillation. However, automatic LA segmentation from LGE MRI is still challenging, due to the poor image quality, high variability in LA shapes, and unclear LA boundary. Though deep learning-based methods can provide promising LA segmentation results, they often generalize poorly to unseen domains, such as data from different scanners and/or sites. In this work, we collect 210 LGE MRIs from different centers with different levels of image quality. To evaluate the domain generalization ability of models on the LA segmentation task, we employ four commonly used semantic segmentation networks for the LA segmentation from multi-center LGE MRIs. Besides, we investigate three domain generalization strategies, i.e., histogram matching, mutual information based disentangled representation, and random style transfer, where a simple histogram matching is proved to be most effective.
Urban Traffic Surveillance (UTS): A fully probabilistic 3D tracking approach based on 2D detections
Jun 01, 2021
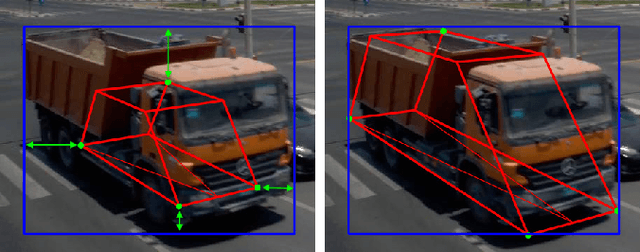


Urban Traffic Surveillance (UTS) is a surveillance system based on a monocular and calibrated video camera that detects vehicles in an urban traffic scenario with dense traffic on multiple lanes and vehicles performing sharp turning maneuvers. UTS then tracks the vehicles using a 3D bounding box representation and a physically reasonable 3D motion model relying on an unscented Kalman filter based approach. Since UTS recovers positions, shape and motion information in a three-dimensional world coordinate system, it can be employed to recognize diverse traffic violations or to supply intelligent vehicles with valuable traffic information. We build on YOLOv3 as a detector yielding 2D bounding boxes and class labels for each vehicle. A 2D detector renders our system much more independent to different camera perspectives as a variety of labeled training data is available. This allows for a good generalization while also being more hardware efficient. The task of 3D tracking based on 2D detections is supported by integrating class specific prior knowledge about the vehicle shape. We quantitatively evaluate UTS using self generated synthetic data and ground truth from the CARLA simulator, due to the non-existence of datasets with an urban vehicle surveillance setting and labeled 3D bounding boxes. Additionally, we give a qualitative impression of how UTS performs on real-world data. Our implementation is capable of operating in real time on a reasonably modern workstation. To the best of our knowledge, UTS is to date the only 3D vehicle tracking system in a surveillance scenario (static camera observing moving targets).
Gradient Forward-Propagation for Large-Scale Temporal Video Modelling
Jul 12, 2021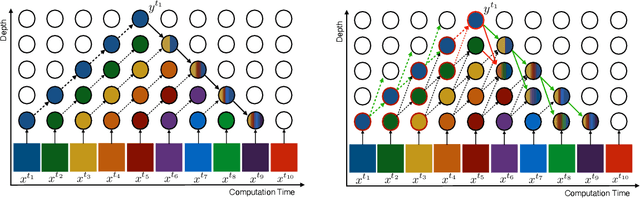
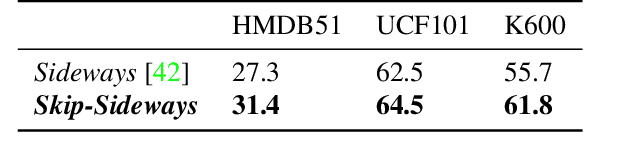
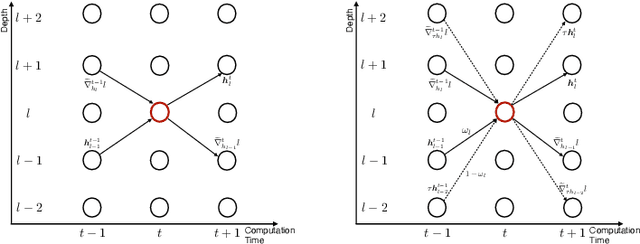

How can neural networks be trained on large-volume temporal data efficiently? To compute the gradients required to update parameters, backpropagation blocks computations until the forward and backward passes are completed. For temporal signals, this introduces high latency and hinders real-time learning. It also creates a coupling between consecutive layers, which limits model parallelism and increases memory consumption. In this paper, we build upon Sideways, which avoids blocking by propagating approximate gradients forward in time, and we propose mechanisms for temporal integration of information based on different variants of skip connections. We also show how to decouple computation and delegate individual neural modules to different devices, allowing distributed and parallel training. The proposed Skip-Sideways achieves low latency training, model parallelism, and, importantly, is capable of extracting temporal features, leading to more stable training and improved performance on real-world action recognition video datasets such as HMDB51, UCF101, and the large-scale Kinetics-600. Finally, we also show that models trained with Skip-Sideways generate better future frames than Sideways models, and hence they can better utilize motion cues.
An Attractor-Guided Neural Networks for Skeleton-Based Human Motion Prediction
May 20, 2021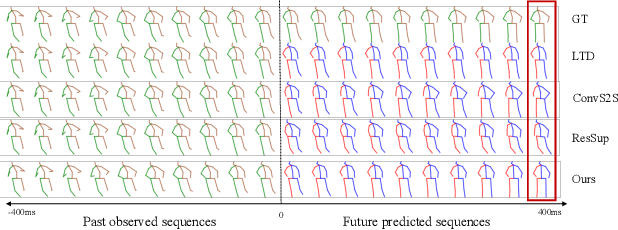
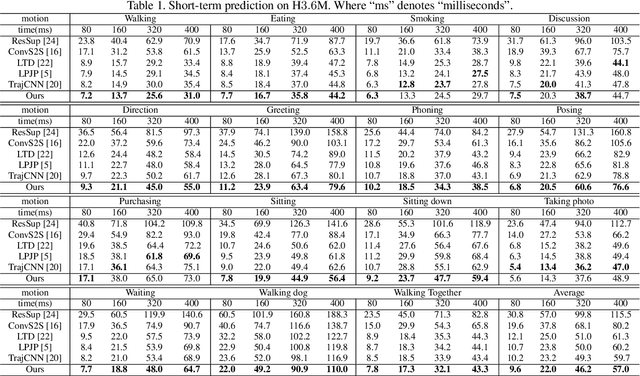
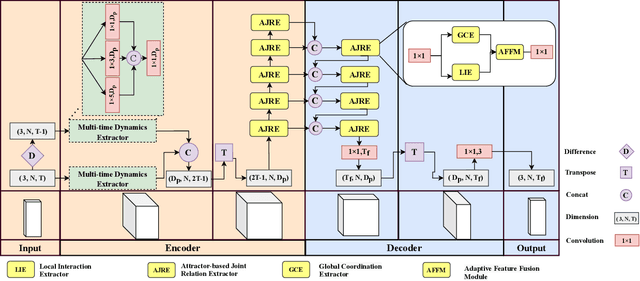
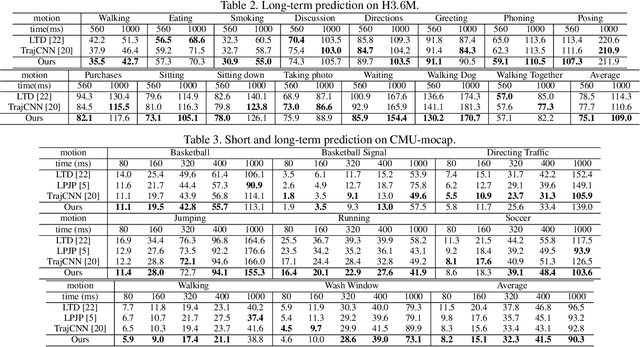
Joint relation modeling is a curial component in human motion prediction. Most existing methods tend to design skeletal-based graphs to build the relations among joints, where local interactions between joint pairs are well learned. However, the global coordination of all joints, which reflects human motion's balance property, is usually weakened because it is learned from part to whole progressively and asynchronously. Thus, the final predicted motions are sometimes unnatural. To tackle this issue, we learn a medium, called balance attractor (BA), from the spatiotemporal features of motion to characterize the global motion features, which is subsequently used to build new joint relations. Through the BA, all joints are related synchronously, and thus the global coordination of all joints can be better learned. Based on the BA, we propose our framework, referred to Attractor-Guided Neural Network, mainly including Attractor-Based Joint Relation Extractor (AJRE) and Multi-timescale Dynamics Extractor (MTDE). The AJRE mainly includes Global Coordination Extractor (GCE) and Local Interaction Extractor (LIE). The former presents the global coordination of all joints, and the latter encodes local interactions between joint pairs. The MTDE is designed to extract dynamic information from raw position information for effective prediction. Extensive experiments show that the proposed framework outperforms state-of-the-art methods in both short and long-term predictions in H3.6M, CMU-Mocap, and 3DPW.
Synthesizing MR Image Contrast Enhancement Using 3D High-resolution ConvNets
Apr 13, 2021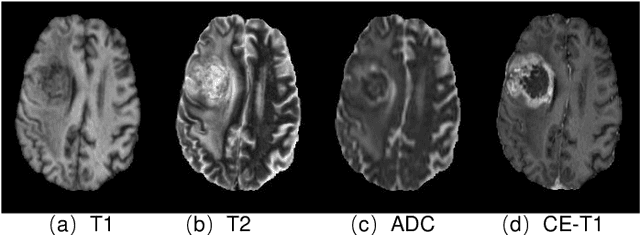
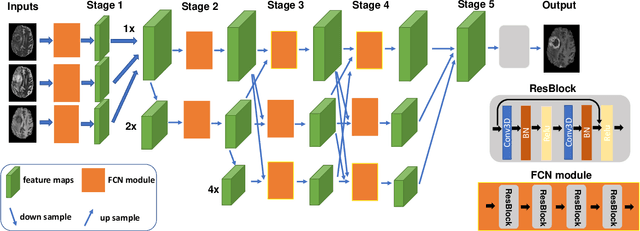
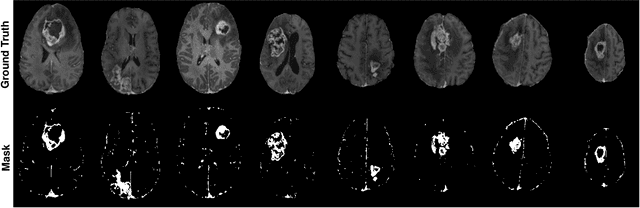
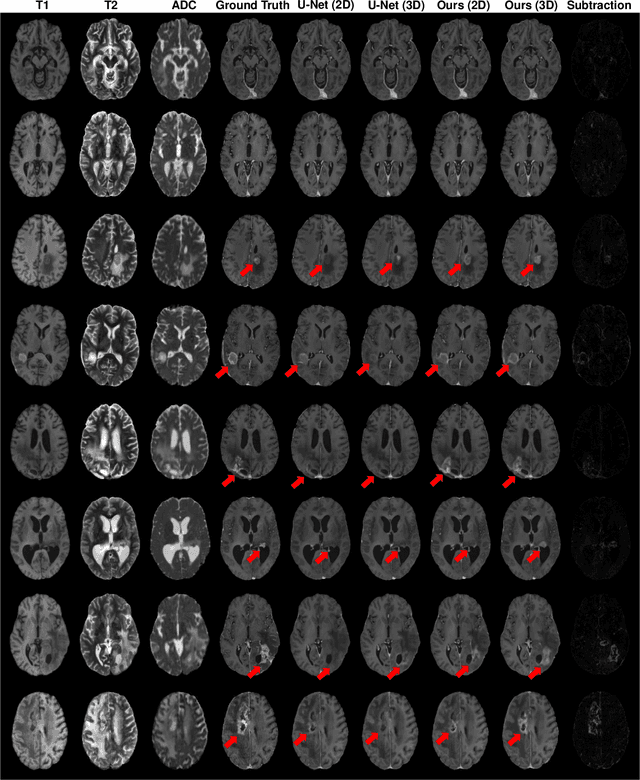
Gadolinium-based contrast agents (GBCAs) have been widely used to better visualize disease in brain magnetic resonance imaging (MRI). However, gadolinium deposition within the brain and body has raised safety concerns about the use of GBCAs. Therefore, the development of novel approaches that can decrease or even eliminate GBCA exposure while providing similar contrast information would be of significant use clinically. For brain tumor patients, standard-of-care includes repeated MRI with gadolinium-based contrast for disease monitoring, increasing the risk of gadolinium deposition. In this work, we present a deep learning based approach for contrast-enhanced T1 synthesis on brain tumor patients. A 3D high-resolution fully convolutional network (FCN), which maintains high resolution information through processing and aggregates multi-scale information in parallel, is designed to map pre-contrast MRI sequences to contrast-enhanced MRI sequences. Specifically, three pre-contrast MRI sequences, T1, T2 and apparent diffusion coefficient map (ADC), are utilized as inputs and the post-contrast T1 sequences are utilized as target output. To alleviate the data imbalance problem between normal tissues and the tumor regions, we introduce a local loss to improve the contribution of the tumor regions, which leads to better enhancement results on tumors. Extensive quantitative and visual assessments are performed, with our proposed model achieving a PSNR of 28.24dB in the brain and 21.2dB in tumor regions. Our results suggests the potential of substituting GBCAs with synthetic contrast images generated via deep learning.