 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
AdCOFE: Advanced Contextual Feature Extraction in Conversations for emotion classification
Apr 09, 2021
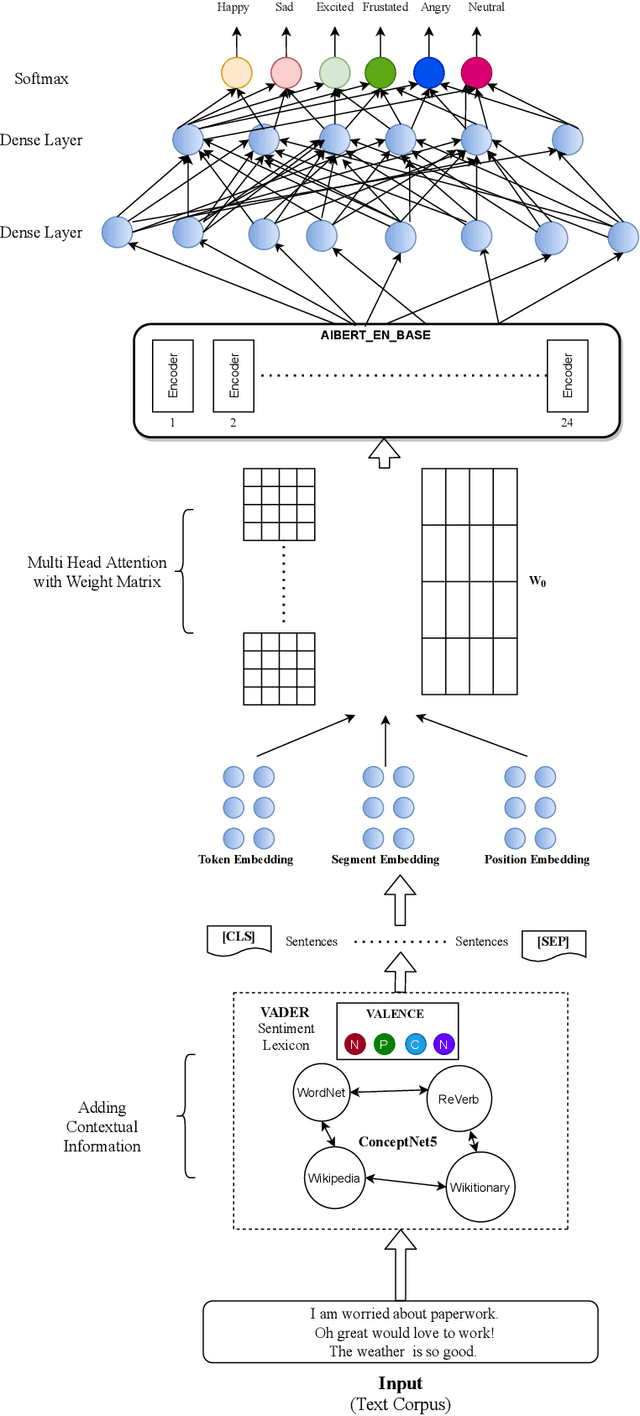
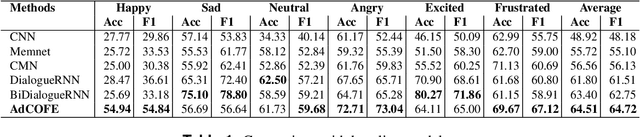
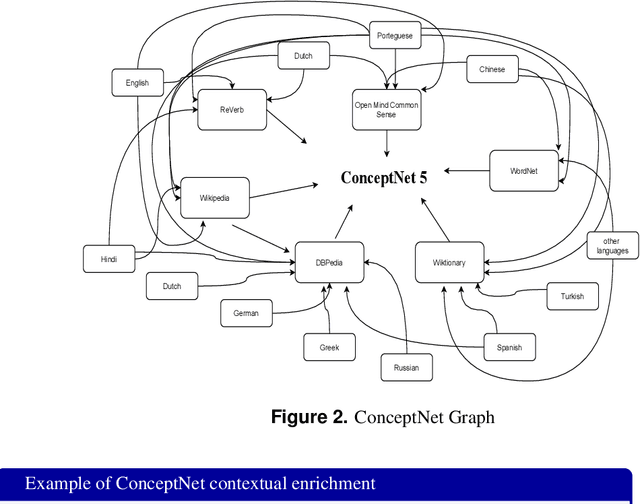
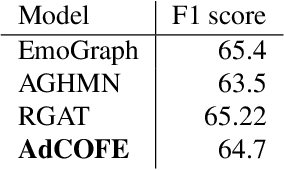
Emotion recognition in conversations is an important step in various virtual chat bots which require opinion-based feedback, like in social media threads, online support and many more applications. Current Emotion recognition in conversations models face issues like (a) loss of contextual information in between two dialogues of a conversation, (b) failure to give appropriate importance to significant tokens in each utterance and (c) inability to pass on the emotional information from previous utterances.The proposed model of Advanced Contextual Feature Extraction (AdCOFE) addresses these issues by performing unique feature extraction using knowledge graphs, sentiment lexicons and phrases of natural language at all levels (word and position embedding) of the utterances. Experiments on the Emotion recognition in conversations dataset show that AdCOFE is beneficial in capturing emotions in conversations.
AnyoneNet: Synchronized Speech and Talking Head Generation for Arbitrary Person
Aug 11, 2021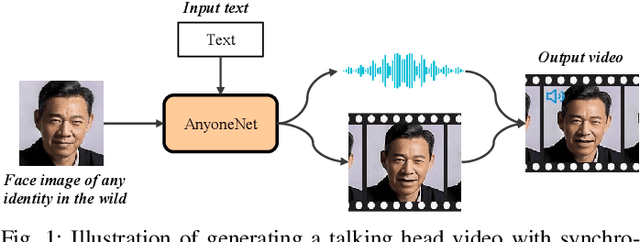
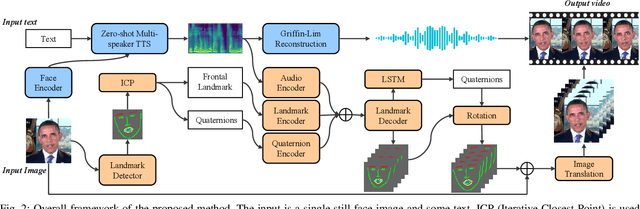
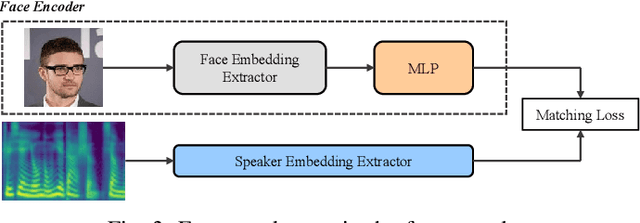
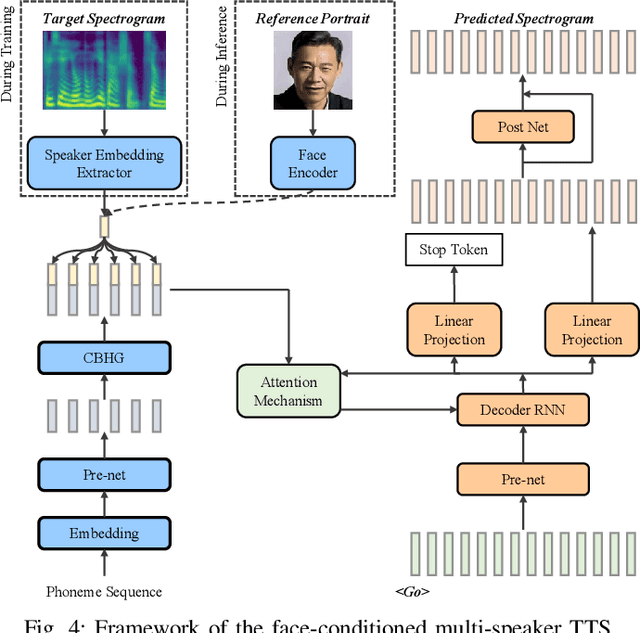
Automatically generating videos in which synthesized speech is synchronized with lip movements in a talking head has great potential in many human-computer interaction scenarios. In this paper, we present an automatic method to generate synchronized speech and talking-head videos on the basis of text and a single face image of an arbitrary person as input. In contrast to previous text-driven talking head generation methods, which can only synthesize the voice of a specific person, the proposed method is capable of synthesizing speech for any person that is inaccessible in the training stage. Specifically, the proposed method decomposes the generation of synchronized speech and talking head videos into two stages, i.e., a text-to-speech (TTS) stage and a speech-driven talking head generation stage. The proposed TTS module is a face-conditioned multi-speaker TTS model that gets the speaker identity information from face images instead of speech, which allows us to synthesize a personalized voice on the basis of the input face image. To generate the talking head videos from the face images, a facial landmark-based method that can predict both lip movements and head rotations is proposed. Extensive experiments demonstrate that the proposed method is able to generate synchronized speech and talking head videos for arbitrary persons and non-persons. Synthesized speech shows consistency with the given face regarding to the synthesized voice's timbre and one's appearance in the image, and the proposed landmark-based talking head method outperforms the state-of-the-art landmark-based method on generating natural talking head videos.
Asking Clarifying Questions Based on Negative Feedback in Conversational Search
Jul 12, 2021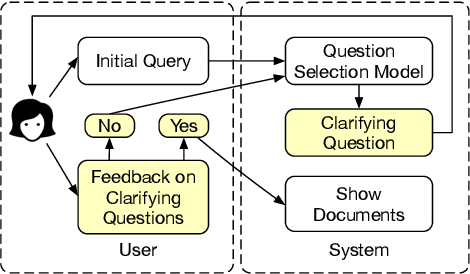
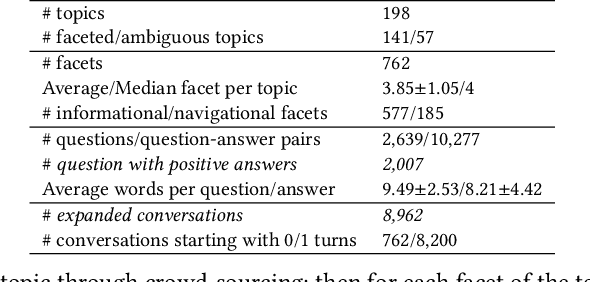
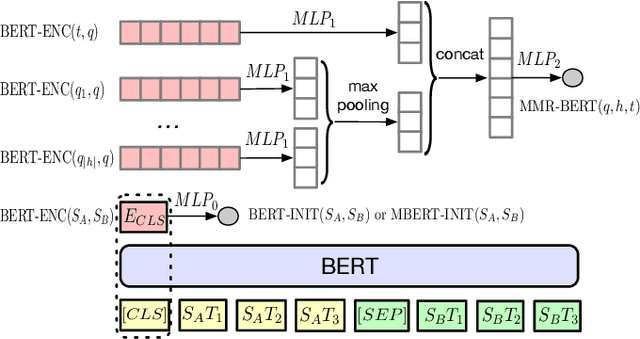
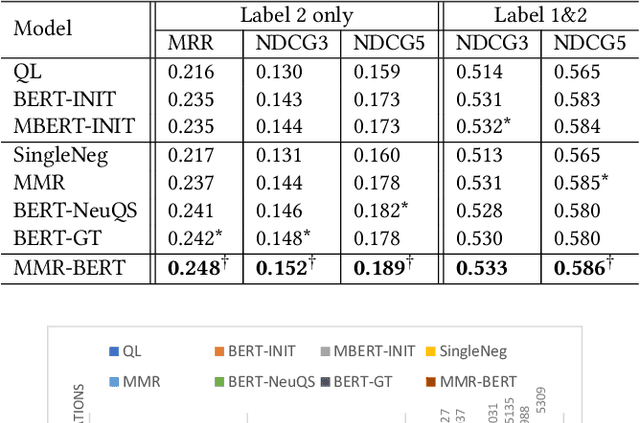
Users often need to look through multiple search result pages or reformulate queries when they have complex information-seeking needs. Conversational search systems make it possible to improve user satisfaction by asking questions to clarify users' search intents. This, however, can take significant effort to answer a series of questions starting with "what/why/how". To quickly identify user intent and reduce effort during interactions, we propose an intent clarification task based on yes/no questions where the system needs to ask the correct question about intents within the fewest conversation turns. In this task, it is essential to use negative feedback about the previous questions in the conversation history. To this end, we propose a Maximum-Marginal-Relevance (MMR) based BERT model (MMR-BERT) to leverage negative feedback based on the MMR principle for the next clarifying question selection. Experiments on the Qulac dataset show that MMR-BERT outperforms state-of-the-art baselines significantly on the intent identification task and the selected questions also achieve significantly better performance in the associated document retrieval tasks.
Knowledge-Aware Graph-Enhanced GPT-2 for Dialogue State Tracking
Apr 09, 2021
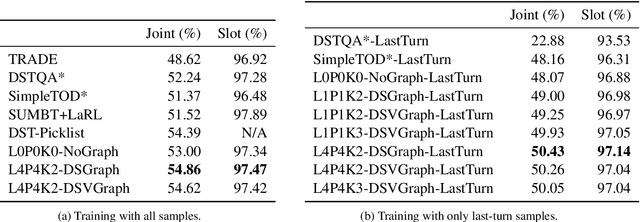
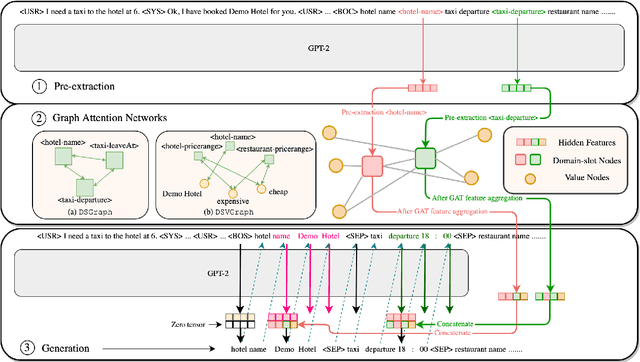

Dialogue State Tracking is a crucial part of multi-domain task-oriented dialogue systems, responsible for extracting information from user utterances. We present a novel architecture that utilizes the powerful generative model GPT-2 to generate slot values one by one causally, and at the same time utilizes Graph Attention Networks to enable inter-slot information exchanges, which exploits the inter-slot relations such as correlations. Our model achieves $54.86\%$ joint accuracy in MultiWOZ 2.0, and it retains a performance of up to $50.43\%$ in sparse supervision training, where only session-level annotations ($14.3\%$ of the full training set) are used. We conduct detailed analyses to demonstrate the significance of using graph models in this task, and show by experiments that the proposed graph modules indeed help to capture more inter-slot relations.
Variance-Aware Off-Policy Evaluation with Linear Function Approximation
Jun 22, 2021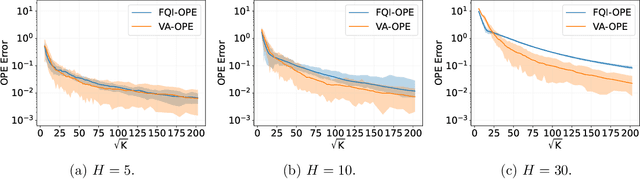
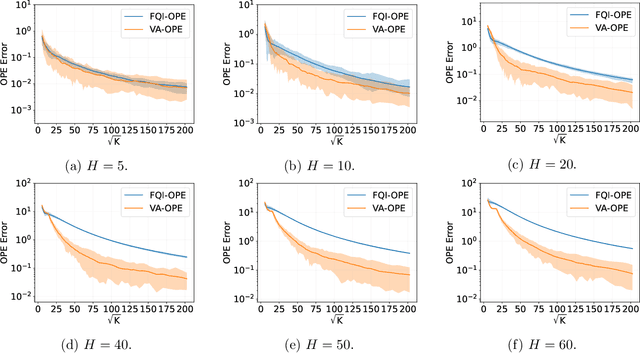
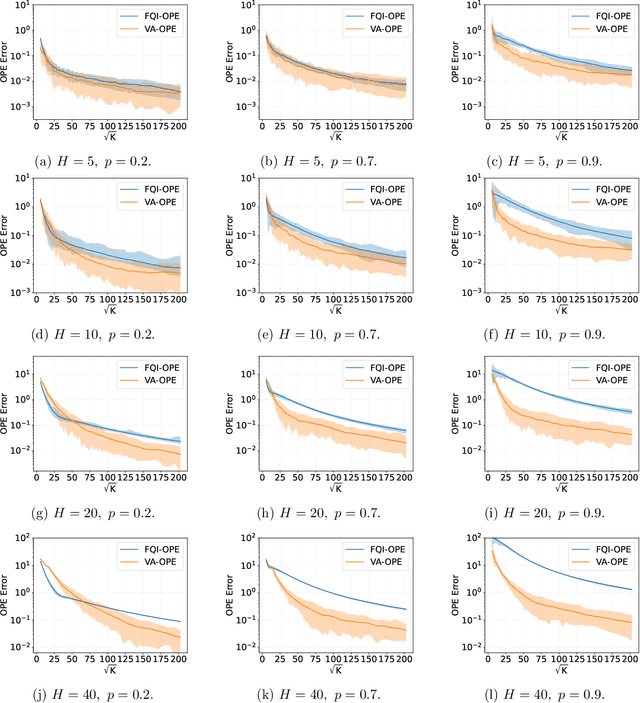
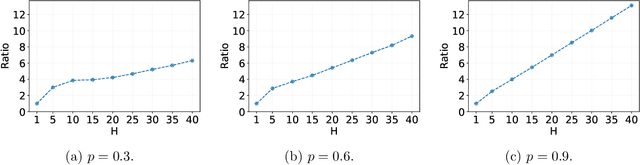
We study the off-policy evaluation (OPE) problem in reinforcement learning with linear function approximation, which aims to estimate the value function of a target policy based on the offline data collected by a behavior policy. We propose to incorporate the variance information of the value function to improve the sample efficiency of OPE. More specifically, for time-inhomogeneous episodic linear Markov decision processes (MDPs), we propose an algorithm, VA-OPE, which uses the estimated variance of the value function to reweight the Bellman residual in Fitted Q-Iteration. We show that our algorithm achieves a tighter error bound than the best-known result. We also provide a fine-grained characterization of the distribution shift between the behavior policy and the target policy. Extensive numerical experiments corroborate our theory.
Deep Open Snake Tracker for Vessel Tracing
Jul 19, 2021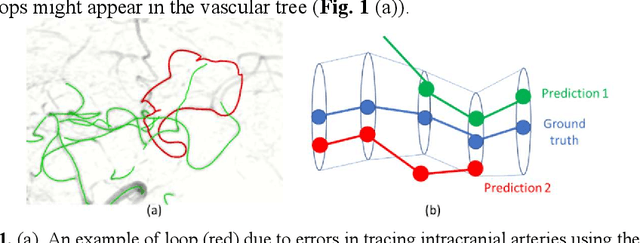
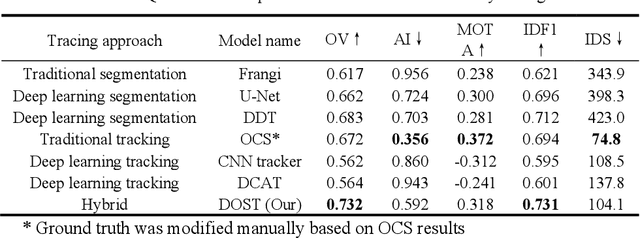
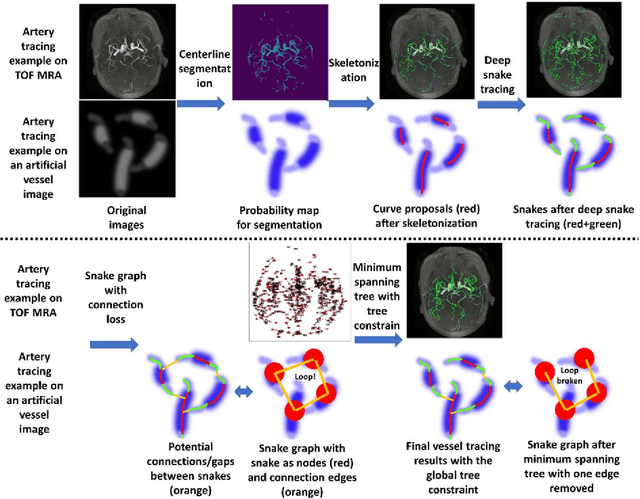
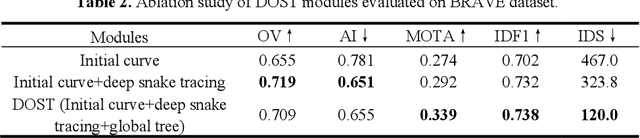
Vessel tracing by modeling vascular structures in 3D medical images with centerlines and radii can provide useful information for vascular health. Existing algorithms have been developed but there are certain persistent problems such as incomplete or inaccurate vessel tracing, especially in complicated vascular beds like the intracranial arteries. We propose here a deep learning based open curve active contour model (DOST) to trace vessels in 3D images. Initial curves were proposed from a centerline segmentation neural network. Then data-driven machine knowledge was used to predict the stretching direction and vessel radius of the initial curve, while the active contour model (as human knowledge) maintained smoothness and intensity fitness of curves. Finally, considering the nonloop topology of most vasculatures, individually traced vessels were connected into a tree topology by applying a minimum spanning tree algorithm on a global connection graph. We evaluated DOST on a Time-of-Flight (TOF) MRA intracranial artery dataset and demonstrated its superior performance over existing segmentation-based and tracking-based vessel tracing methods. In addition, DOST showed strong adaptability on different imaging modalities (CTA, MR T1 SPACE) and vascular beds (coronary arteries).
Information Recovery in Shuffled Graphs via Graph Matching
Sep 27, 2017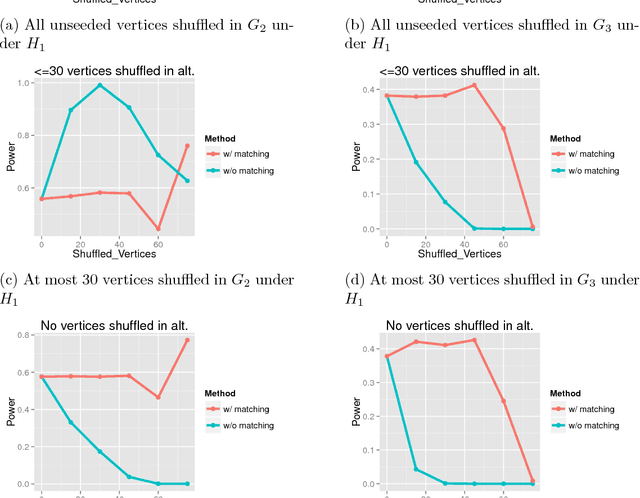
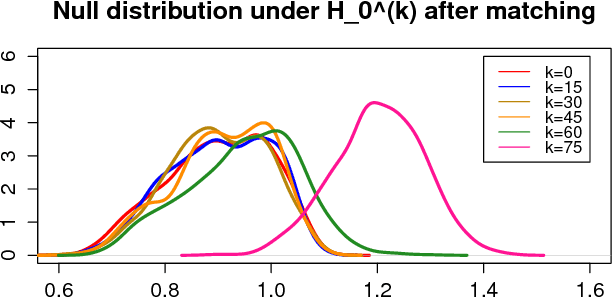
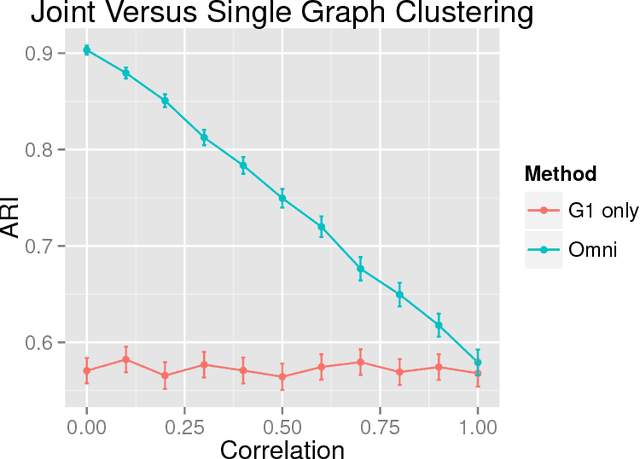
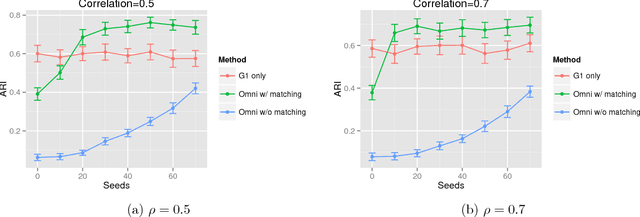
While many multiple graph inference methodologies operate under the implicit assumption that an explicit vertex correspondence is known across the vertex sets of the graphs, in practice these correspondences may only be partially or errorfully known. Herein, we provide an information theoretic foundation for understanding the practical impact that errorfully observed vertex correspondences can have on subsequent inference, and the capacity of graph matching methods to recover the lost vertex alignment and inferential performance. Working in the correlated stochastic blockmodel setting, we establish a duality between the loss of mutual information due to an errorfully observed vertex correspondence and the ability of graph matching algorithms to recover the true correspondence across graphs. In the process, we establish a phase transition for graph matchability in terms of the correlation across graphs, and we conjecture the analogous phase transition for the relative information loss due to shuffling vertex labels. We demonstrate the practical effect that graph shuffling---and matching---can have on subsequent inference, with examples from two sample graph hypothesis testing and joint spectral graph clustering.
Semiotic Aggregation in Deep Learning
Apr 22, 2021
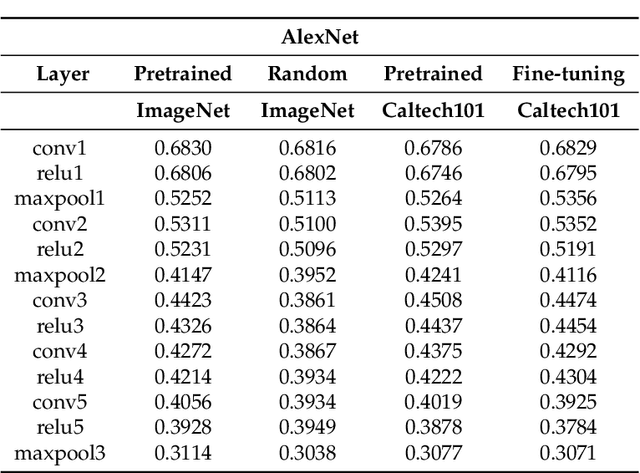
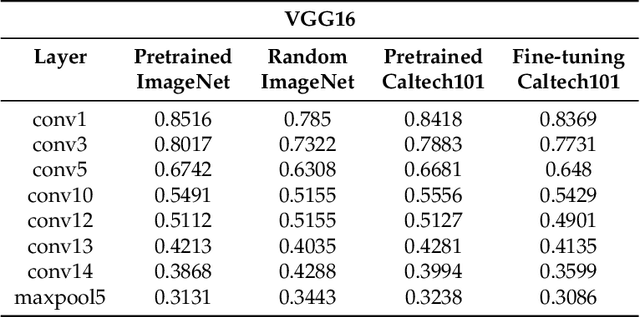
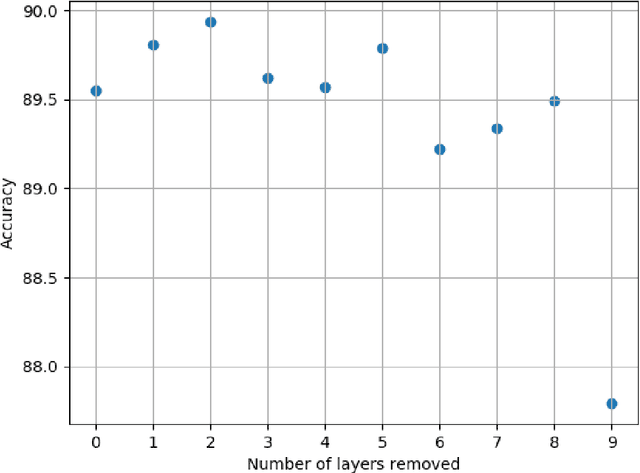
Convolutional neural networks utilize a hierarchy of neural network layers. The statistical aspects of information concentration in successive layers can bring an insight into the feature abstraction process. We analyze the saliency maps of these layers from the perspective of semiotics, also known as the study of signs and sign-using behavior. In computational semiotics, this aggregation operation (known as superization) is accompanied by a decrease of spatial entropy: signs are aggregated into supersign. Using spatial entropy, we compute the information content of the saliency maps and study the superization processes which take place between successive layers of the network. In our experiments, we visualize the superization process and show how the obtained knowledge can be used to explain the neural decision model. In addition, we attempt to optimize the architecture of the neural model employing a semiotic greedy technique. To the extent of our knowledge, this is the first application of computational semiotics in the analysis and interpretation of deep neural networks.
DIBS: Diversity inducing Information Bottleneck in Model Ensembles
Mar 10, 2020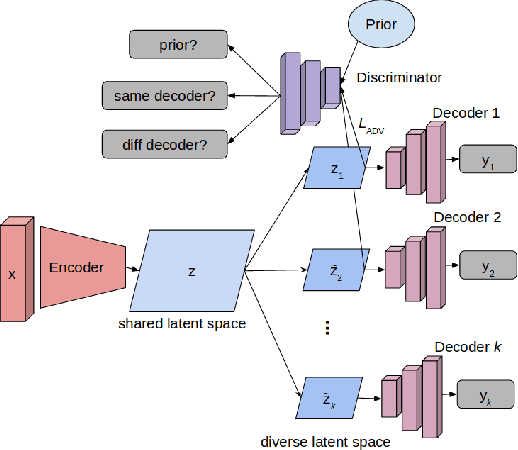
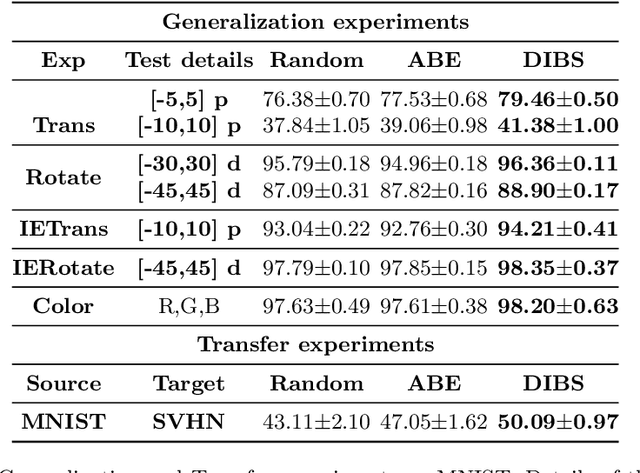
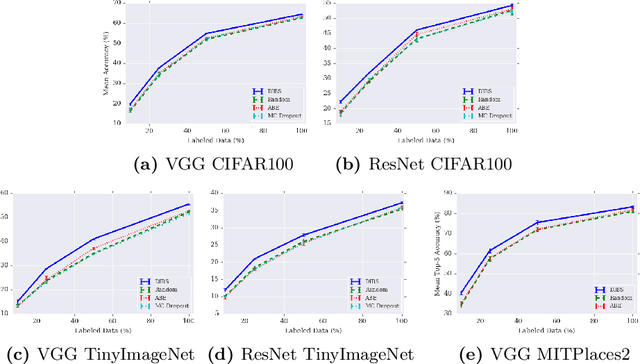
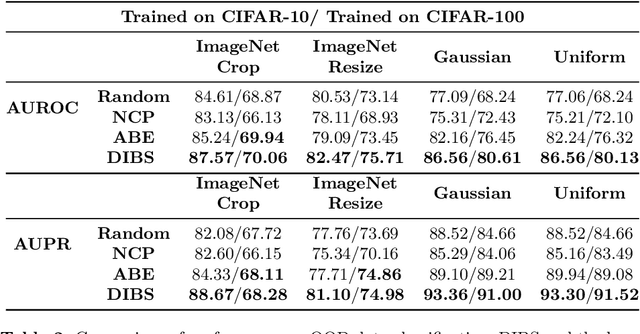
Although deep learning models have achieved state-of-the-art performance on a number of vision tasks, generalization over high dimensional multi-modal data, and reliable predictive uncertainty estimation are still active areas of research. Bayesian approaches including Bayesian Neural Nets (BNNs) do not scale well to modern computer vision tasks, as they are difficult to train, and have poor generalization under dataset-shift. This motivates the need for effective ensembles which can generalize and give reliable uncertainty estimates. In this paper, we target the problem of generating effective ensembles of neural networks by encouraging diversity in prediction. We explicitly optimize a diversity inducing adversarial loss for learning the stochastic latent variables and thereby obtain diversity in the output predictions necessary for modeling multi-modal data. We evaluate our method on benchmark datasets: MNIST, CIFAR100, TinyImageNet and MIT Places 2, and compared to the most competitive baselines show significant improvements in classification accuracy, under a shift in the data distribution and in out-of-distribution detection. Code will be released in this url https://github.com/rvl-lab-utoronto/dibs
DAGN: Discourse-Aware Graph Network for Logical Reasoning
Mar 26, 2021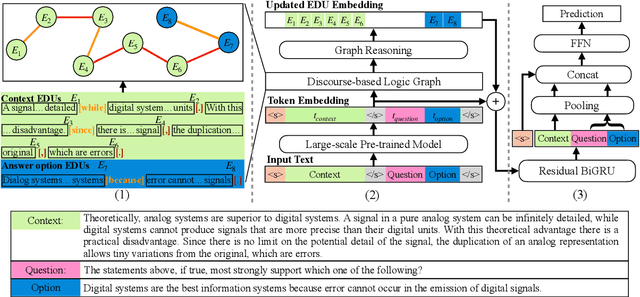
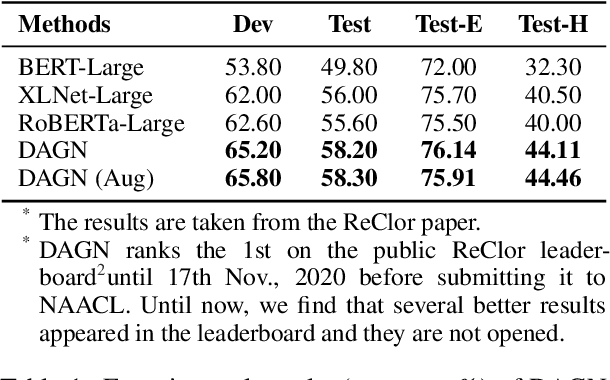
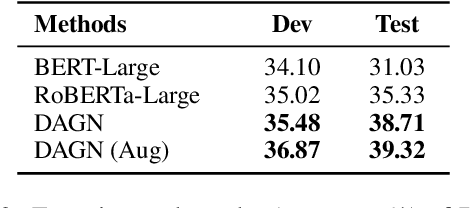

Recent QA with logical reasoning questions requires passage-level relations among the sentences. However, current approaches still focus on sentence-level relations interacting among tokens. In this work, we explore aggregating passage-level clues for solving logical reasoning QA by using discourse-based information. We propose a discourse-aware graph network (DAGN) that reasons relying on the discourse structure of the texts. The model encodes discourse information as a graph with elementary discourse units (EDUs) and discourse relations, and learns the discourse-aware features via a graph network for downstream QA tasks. Experiments are conducted on two logical reasoning QA datasets, ReClor and LogiQA, and our proposed DAGN achieves competitive results.