 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A highly scalable repository of waveform and vital signs data from bedside monitoring devices
Jun 07, 2021
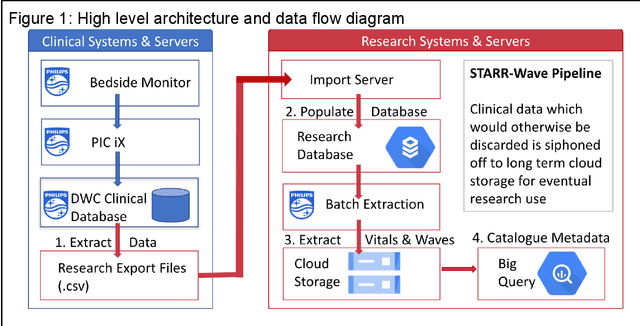
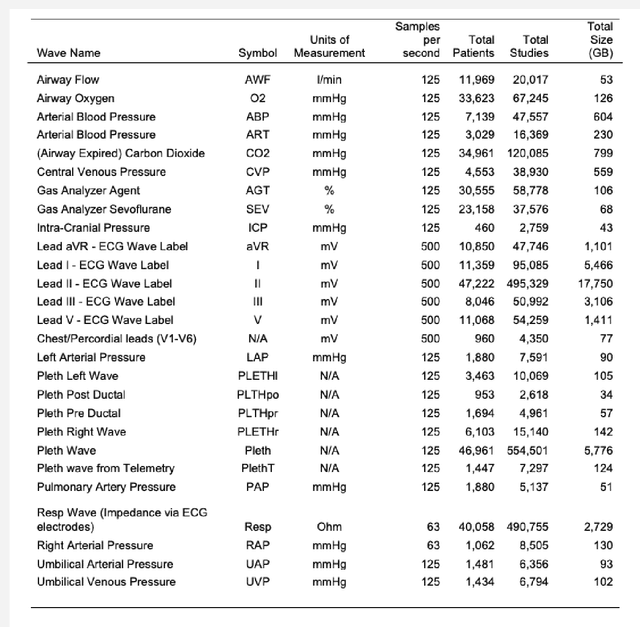
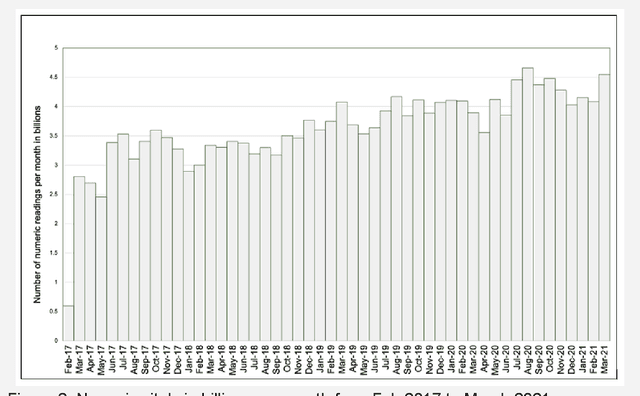
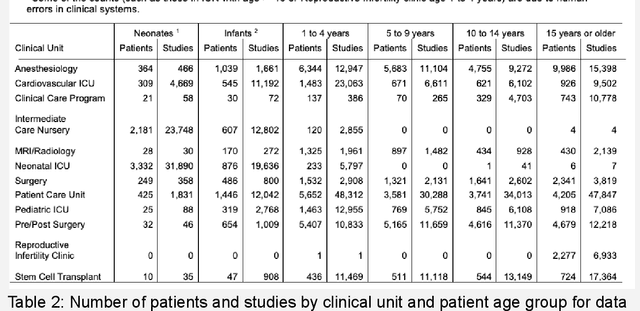
The advent of cost effective cloud computing over the past decade and ever-growing accumulation of high-fidelity clinical data in a modern hospital setting is leading to new opportunities for translational medicine. Machine learning is driving the appetite of the research community for various types of signal data such as patient vitals. Health care systems, however, are ill suited for massive processing of large volumes of data. In addition, due to the sheer magnitude of the data being collected, it is not feasible to retain all of the data in health care systems in perpetuity. This gold mine of information gets purged periodically thereby losing invaluable future research opportunities. We have developed a highly scalable solution that: a) siphons off patient vital data on a nightly basis from on-premises bio-medical systems to a cloud storage location as a permanent archive, b) reconstructs the database in the cloud, c) generates waveforms, alarms and numeric data in a research-ready format, and d) uploads the processed data to a storage location in the cloud ready for research. The data is de-identified and catalogued such that it can be joined with Electronic Medical Records (EMR) and other ancillary data types such as electroencephalogram (EEG), radiology, video monitoring etc. This technique eliminates the research burden from health care systems. This highly scalable solution is used to process high density patient monitoring data aggregated by the Philips Patient Information Center iX (PIC iX) hospital surveillance system for archival storage in the Philips Data Warehouse Connect enterprise-level database. The solution is part of a broader platform that supports a secure high performance clinical data science platform.
Semiotic Aggregation in Deep Learning
Apr 22, 2021
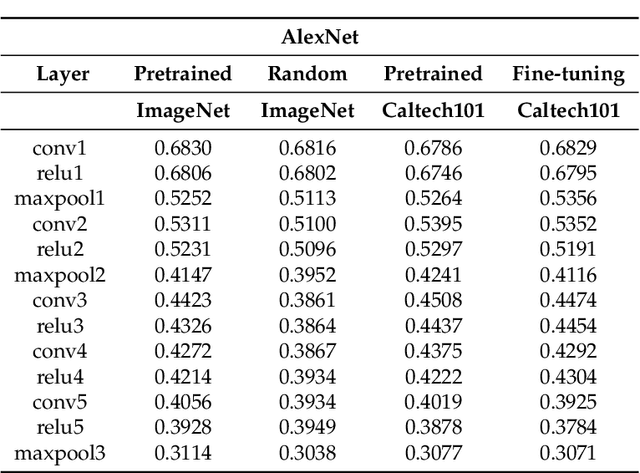
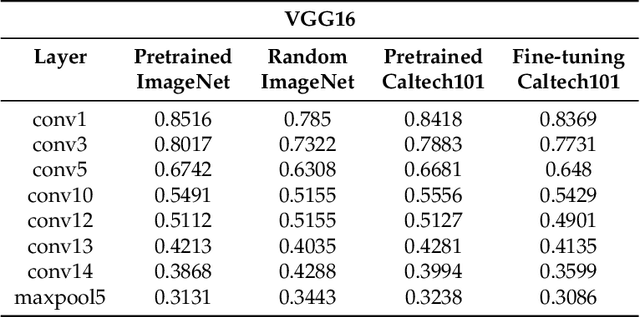
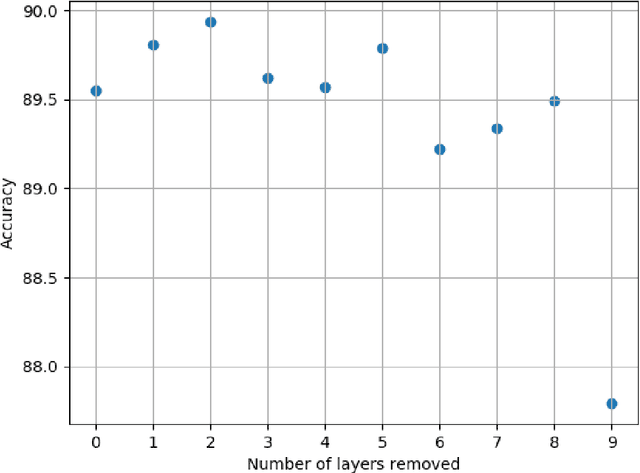
Convolutional neural networks utilize a hierarchy of neural network layers. The statistical aspects of information concentration in successive layers can bring an insight into the feature abstraction process. We analyze the saliency maps of these layers from the perspective of semiotics, also known as the study of signs and sign-using behavior. In computational semiotics, this aggregation operation (known as superization) is accompanied by a decrease of spatial entropy: signs are aggregated into supersign. Using spatial entropy, we compute the information content of the saliency maps and study the superization processes which take place between successive layers of the network. In our experiments, we visualize the superization process and show how the obtained knowledge can be used to explain the neural decision model. In addition, we attempt to optimize the architecture of the neural model employing a semiotic greedy technique. To the extent of our knowledge, this is the first application of computational semiotics in the analysis and interpretation of deep neural networks.
Rethinking InfoNCE: How Many Negative Samples Do You Need?
May 27, 2021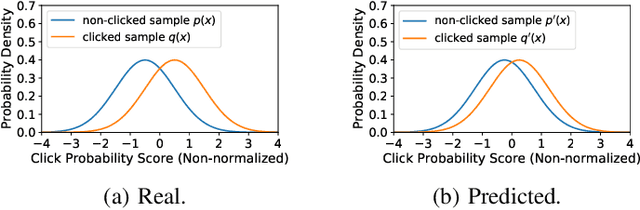
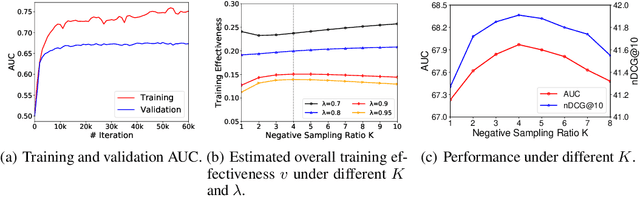
InfoNCE loss is a widely used loss function for contrastive model training. It aims to estimate the mutual information between a pair of variables by discriminating between each positive pair and its associated $K$ negative pairs. It is proved that when the sample labels are clean, the lower bound of mutual information estimation is tighter when more negative samples are incorporated, which usually yields better model performance. However, in many real-world tasks the labels often contain noise, and incorporating too many noisy negative samples for model training may be suboptimal. In this paper, we study how many negative samples are optimal for InfoNCE in different scenarios via a semi-quantitative theoretical framework. More specifically, we first propose a probabilistic model to analyze the influence of the negative sampling ratio $K$ on training sample informativeness. Then, we design a training effectiveness function to measure the overall influence of training samples on model learning based on their informativeness. We estimate the optimal negative sampling ratio using the $K$ value that maximizes the training effectiveness function. Based on our framework, we further propose an adaptive negative sampling method that can dynamically adjust the negative sampling ratio to improve InfoNCE based model training. Extensive experiments on different real-world datasets show our framework can accurately predict the optimal negative sampling ratio in different tasks, and our proposed adaptive negative sampling method can achieve better performance than the commonly used fixed negative sampling ratio strategy.
Overcoming Obstructions via Bandwidth-Limited Multi-Agent Spatial Handshaking
Jul 01, 2021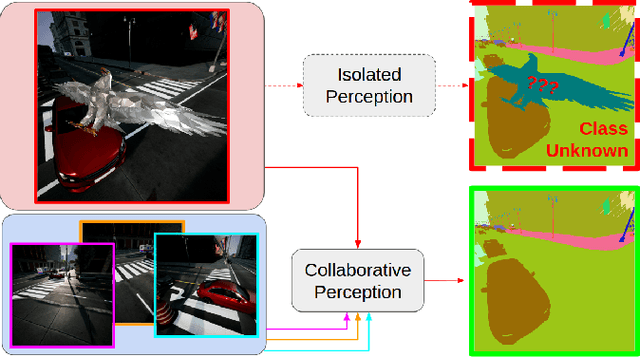
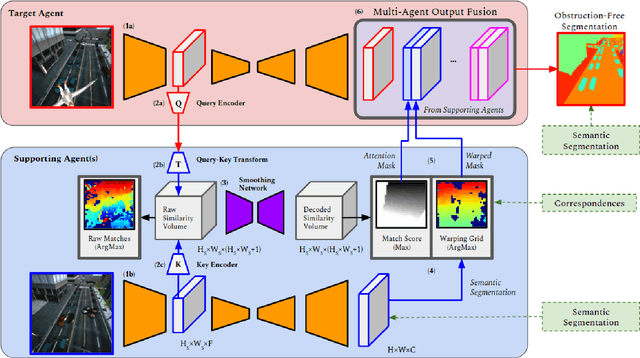
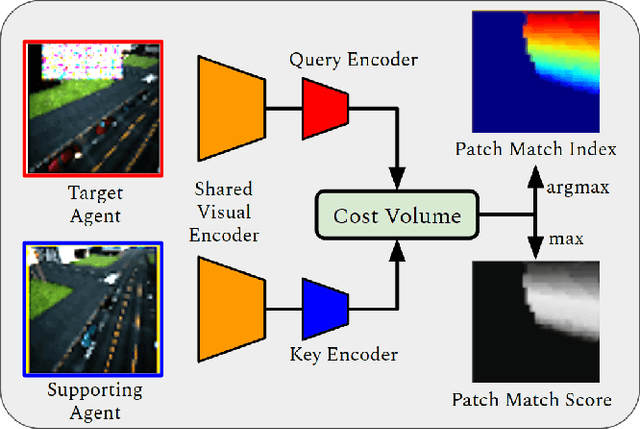
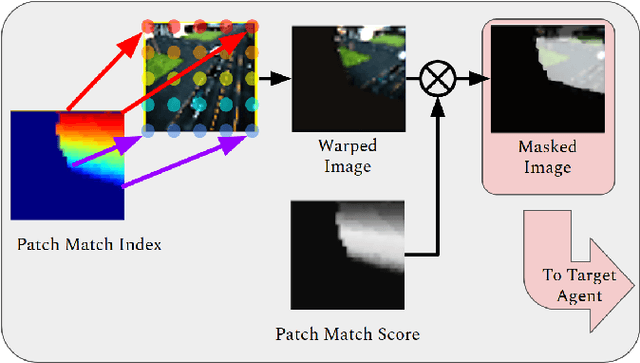
In this paper, we address bandwidth-limited and obstruction-prone collaborative perception, specifically in the context of multi-agent semantic segmentation. This setting presents several key challenges, including processing and exchanging unregistered robotic swarm imagery. To be successful, solutions must effectively leverage multiple non-static and intermittently-overlapping RGB perspectives, while heeding bandwidth constraints and overcoming unwanted foreground obstructions. As such, we propose an end-to-end learn-able Multi-Agent Spatial Handshaking network (MASH) to process, compress, and propagate visual information across a robotic swarm. Our distributed communication module operates directly (and exclusively) on raw image data, without additional input requirements such as pose, depth, or warping data. We demonstrate superior performance of our model compared against several baselines in a photo-realistic multi-robot AirSim environment, especially in the presence of image occlusions. Our method achieves an absolute 11% IoU improvement over strong baselines.
Focusing on Shadows for Predicting Heightmaps from Single Remotely Sensed RGB Images with Deep Learning
Apr 22, 2021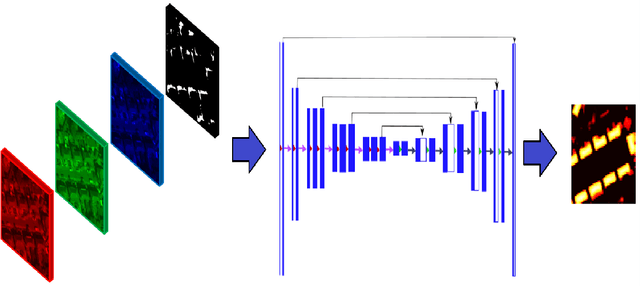

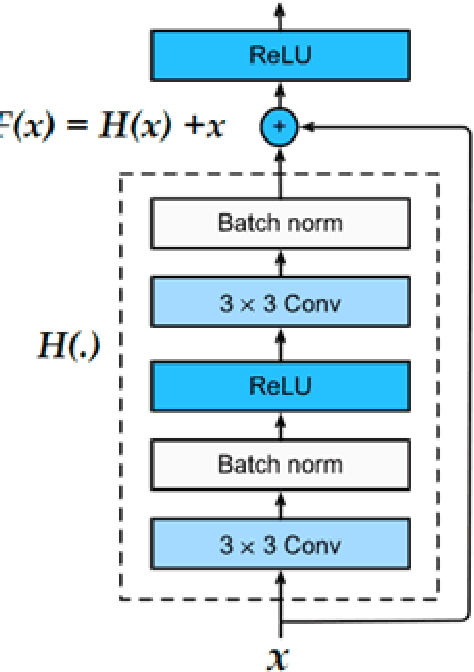
Estimating the heightmaps of buildings and vegetation in single remotely sensed images is a challenging problem. Effective solutions to this problem can comprise the stepping stone for solving complex and demanding problems that require 3D information of aerial imagery in the remote sensing discipline, which might be expensive or not feasible to require. We propose a task-focused Deep Learning (DL) model that takes advantage of the shadow map of a remotely sensed image to calculate its heightmap. The shadow is computed efficiently and does not add significant computation complexity. The model is trained with aerial images and their Lidar measurements, achieving superior performance on the task. We validate the model with a dataset covering a large area of Manchester, UK, as well as the 2018 IEEE GRSS Data Fusion Contest Lidar dataset. Our work suggests that the proposed DL architecture and the technique of injecting shadows information into the model are valuable for improving the heightmap estimation task for single remotely sensed imagery.
BoningKnife: Joint Entity Mention Detection and Typing for Nested NER via prior Boundary Knowledge
Jul 20, 2021
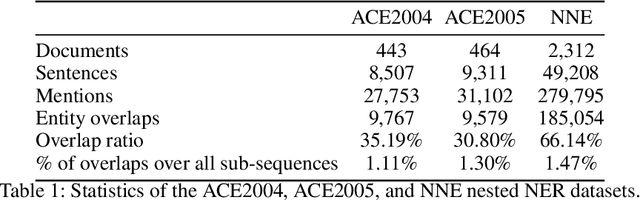
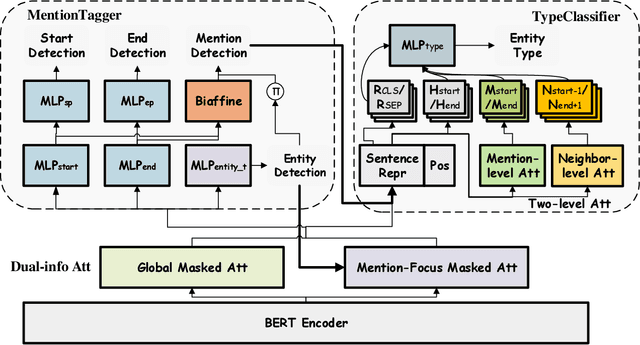
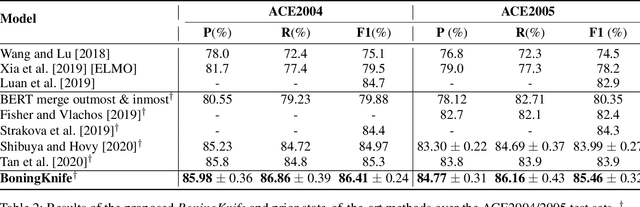
While named entity recognition (NER) is a key task in natural language processing, most approaches only target flat entities, ignoring nested structures which are common in many scenarios. Most existing nested NER methods traverse all sub-sequences which is both expensive and inefficient, and also don't well consider boundary knowledge which is significant for nested entities. In this paper, we propose a joint entity mention detection and typing model via prior boundary knowledge (BoningKnife) to better handle nested NER extraction and recognition tasks. BoningKnife consists of two modules, MentionTagger and TypeClassifier. MentionTagger better leverages boundary knowledge beyond just entity start/end to improve the handling of nesting levels and longer spans, while generating high quality mention candidates. TypeClassifier utilizes a two-level attention mechanism to decouple different nested level representations and better distinguish entity types. We jointly train both modules sharing a common representation and a new dual-info attention layer, which leads to improved representation focus on entity-related information. Experiments over different datasets show that our approach outperforms previous state of the art methods and achieves 86.41, 85.46, and 94.2 F1 scores on ACE2004, ACE2005, and NNE, respectively.
Network Representation Learning: From Traditional Feature Learning to Deep Learning
Mar 07, 2021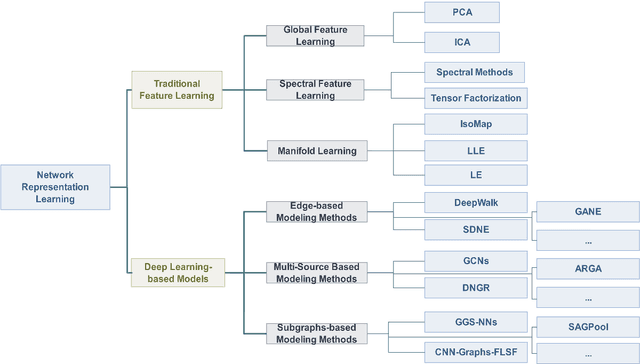
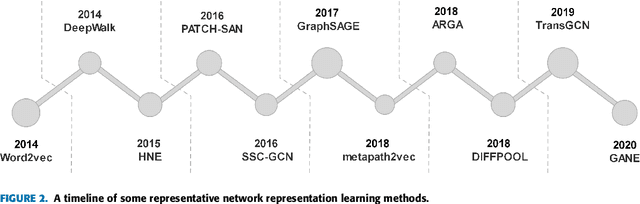
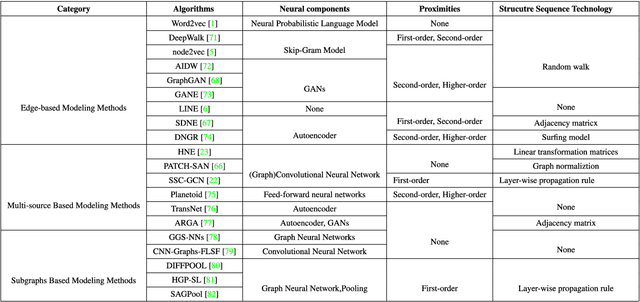
Network representation learning (NRL) is an effective graph analytics technique and promotes users to deeply understand the hidden characteristics of graph data. It has been successfully applied in many real-world tasks related to network science, such as social network data processing, biological information processing, and recommender systems. Deep Learning is a powerful tool to learn data features. However, it is non-trivial to generalize deep learning to graph-structured data since it is different from the regular data such as pictures having spatial information and sounds having temporal information. Recently, researchers proposed many deep learning-based methods in the area of NRL. In this survey, we investigate classical NRL from traditional feature learning method to the deep learning-based model, analyze relationships between them, and summarize the latest progress. Finally, we discuss open issues considering NRL and point out the future directions in this field.
Chinese-Japanese Unsupervised Neural Machine Translation Using Sub-character Level Information
Mar 01, 2019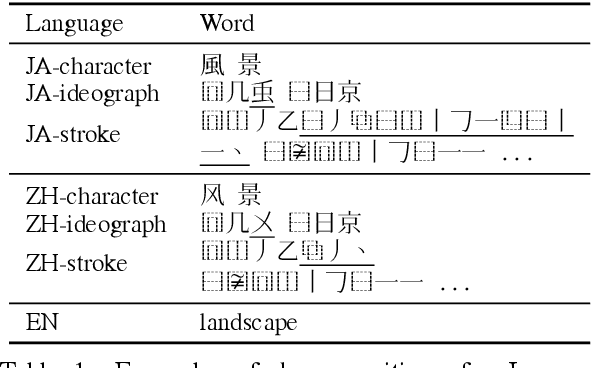
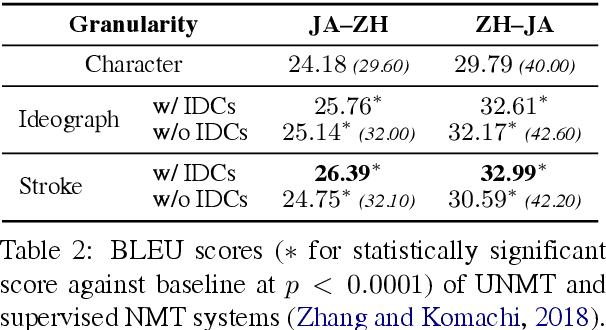
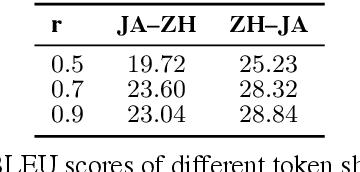

Unsupervised neural machine translation (UNMT) requires only monolingual data of similar language pairs during training and can produce bi-directional translation models with relatively good performance on alphabetic languages (Lample et al., 2018). However, no research has been done to logographic language pairs. This study focuses on Chinese-Japanese UNMT trained by data containing sub-character (ideograph or stroke) level information which is decomposed from character level data. BLEU scores of both character and sub-character level systems were compared against each other and the results showed that despite the effectiveness of UNMT on character level data, sub-character level data could further enhance the performance, in which the stroke level system outperformed the ideograph level system.
Near-optimal inference in adaptive linear regression
Jul 05, 2021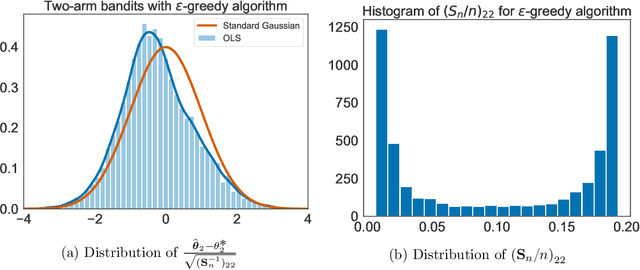
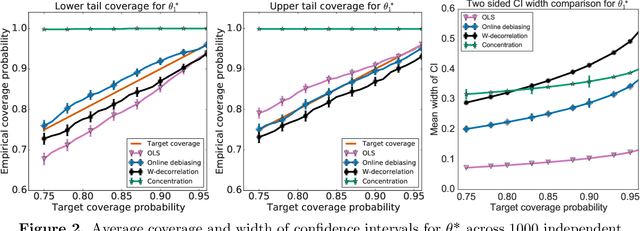
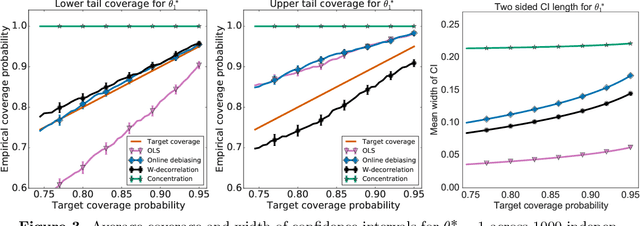
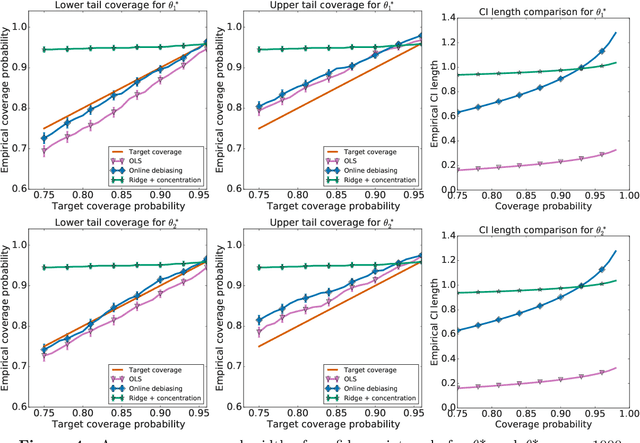
When data is collected in an adaptive manner, even simple methods like ordinary least squares can exhibit non-normal asymptotic behavior. As an undesirable consequence, hypothesis tests and confidence intervals based on asymptotic normality can lead to erroneous results. We propose an online debiasing estimator to correct these distributional anomalies in least squares estimation. Our proposed method takes advantage of the covariance structure present in the dataset and provides sharper estimates in directions for which more information has accrued. We establish an asymptotic normality property for our proposed online debiasing estimator under mild conditions on the data collection process, and provide asymptotically exact confidence intervals. We additionally prove a minimax lower bound for the adaptive linear regression problem, thereby providing a baseline by which to compare estimators. There are various conditions under which our proposed estimator achieves the minimax lower bound up to logarithmic factors. We demonstrate the usefulness of our theory via applications to multi-armed bandit, autoregressive time series estimation, and active learning with exploration.
Ontology-Assisted Generalisation of Robot Action Execution Knowledge
Jul 20, 2021
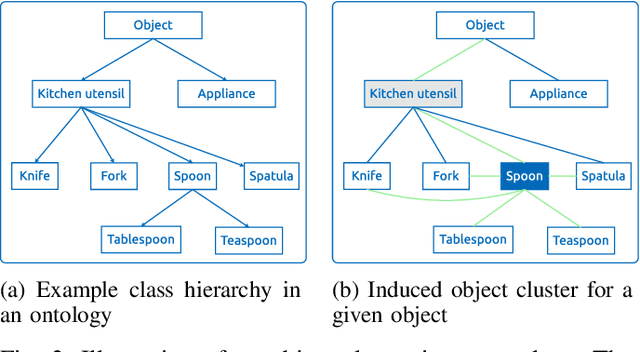


When an autonomous robot learns how to execute actions, it is of interest to know if and when the execution policy can be generalised to variations of the learning scenarios. This can inform the robot about the necessity of additional learning, as using incomplete or unsuitable policies can lead to execution failures. Generalisation is particularly relevant when a robot has to deal with a large variety of objects and in different contexts. In this paper, we propose and analyse a strategy for generalising parameterised execution models of manipulation actions over different objects based on an object ontology. In particular, a robot transfers a known execution model to objects of related classes according to the ontology, but only if there is no other evidence that the model may be unsuitable. This allows using ontological knowledge as prior information that is then refined by the robot's own experiences. We verify our algorithm for two actions - grasping and stowing everyday objects - such that we show that the robot can deduce cases in which an existing policy can generalise to other objects and when additional execution knowledge has to be acquired.