 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Neural Marching Cubes
Jun 21, 2021
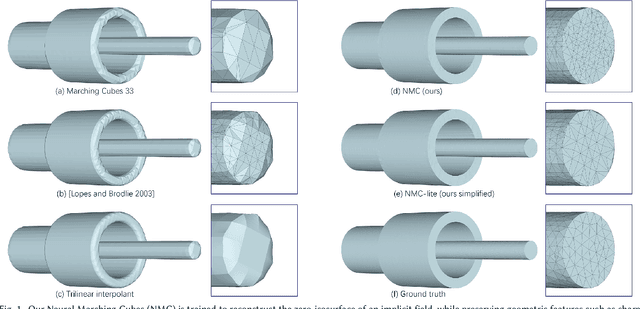
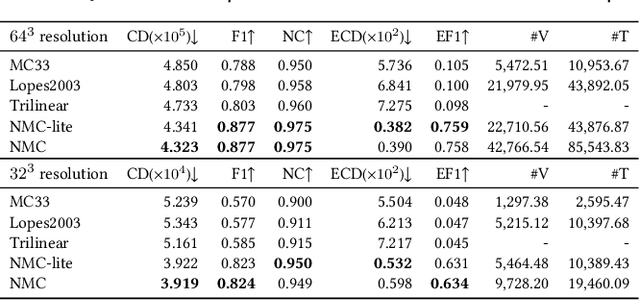
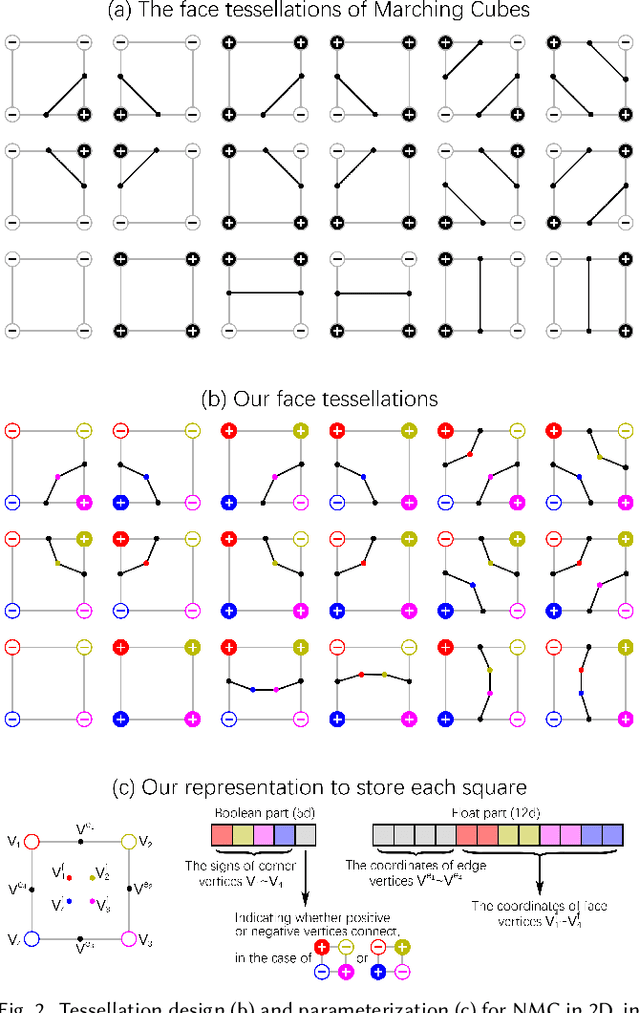
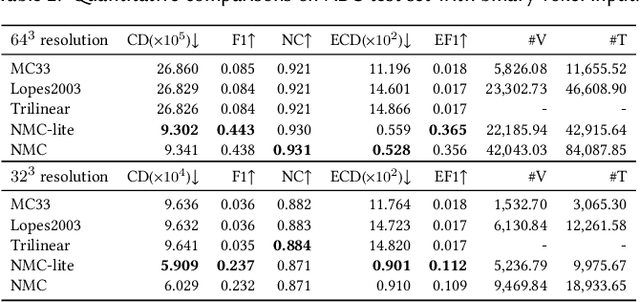
We introduce Neural Marching Cubes (NMC), a data-driven approach for extracting a triangle mesh from a discretized implicit field. Classical MC is defined by coarse tessellation templates isolated to individual cubes. While more refined tessellations have been proposed, they all make heuristic assumptions, such as trilinearity, when determining the vertex positions and local mesh topologies in each cube. In principle, none of these approaches can reconstruct geometric features that reveal coherence or dependencies between nearby cubes (e.g., a sharp edge), as such information is unaccounted for, resulting in poor estimates of the true underlying implicit field. To tackle these challenges, we re-cast MC from a deep learning perspective, by designing tessellation templates more apt at preserving geometric features, and learning the vertex positions and mesh topologies from training meshes, to account for contextual information from nearby cubes. We develop a compact per-cube parameterization to represent the output triangle mesh, while being compatible with neural processing, so that a simple 3D convolutional network can be employed for the training. We show that all topological cases in each cube that are applicable to our design can be easily derived using our representation, and the resulting tessellations can also be obtained naturally and efficiently by following a few design guidelines. In addition, our network learns local features with limited receptive fields, hence it generalizes well to new shapes and new datasets. We evaluate our neural MC approach by quantitative and qualitative comparisons to all well-known MC variants. In particular, we demonstrate the ability of our network to recover sharp features such as edges and corners, a long-standing issue of MC and its variants. Our network also reconstructs local mesh topologies more accurately than previous approaches.
Wideband photonic blind source separation with optical pulse sampling
Jul 21, 2021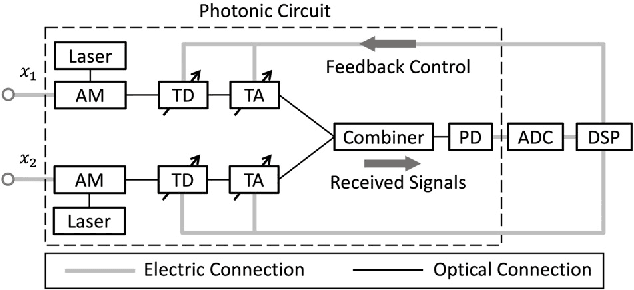
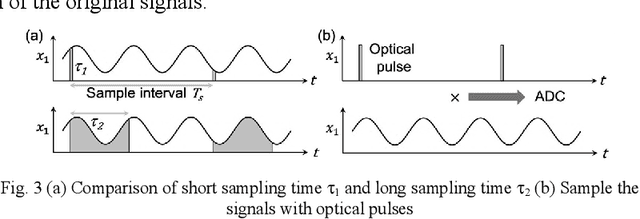
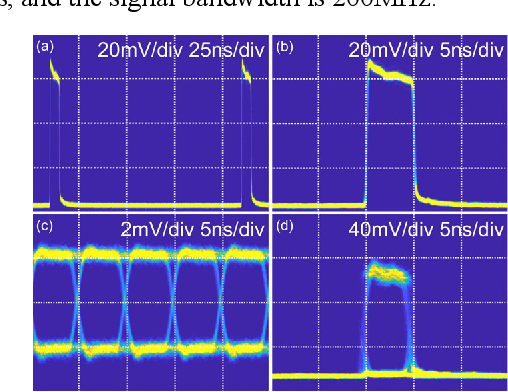
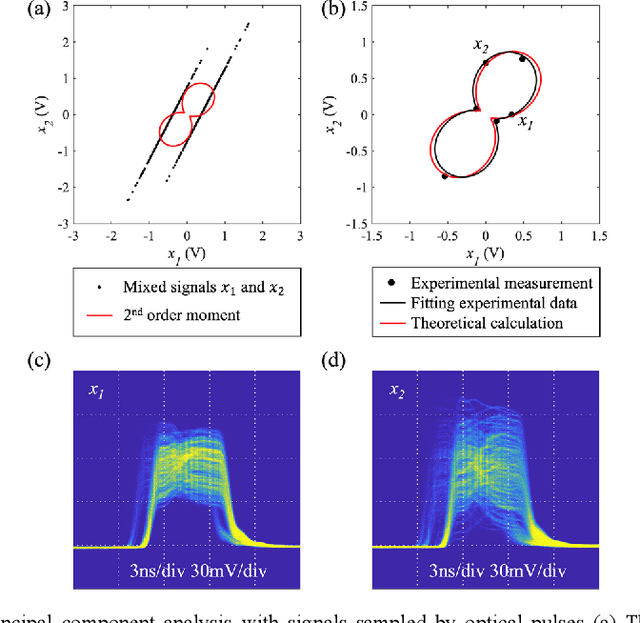
We propose and experimentally demonstrate an optical pulse sampling method for photonic blind source separation. The photonic system processes and separates wideband signals based on the statistical information of the mixed signals and thus the sampling frequency can be orders of magnitude lower than the bandwidth of the signals. The ultra-fast optical pulse functions as a tweezer that collects samples of the signals at very low sampling rates, and each sample is short enough to maintain the statistical properties of the signals. The low sampling frequency reduces the workloads of the analog to digital conversion and digital signal processing systems. In the meantime, the short pulse sampling maintains the accuracy of the sampled signals, so the statistical properties of the undersampling signals are the same as the statistical properties of the original signals. With the optical pulses generated from a mode-locked laser, the optical pulse sampling system is able to process and separate mixed signals with bandwidth over 100GHz and achieves a dynamic range of 30dB.
Winning the CVPR'2021 Kinetics-GEBD Challenge: Contrastive Learning Approach
Jun 22, 2021
Generic Event Boundary Detection (GEBD) is a newly introduced task that aims to detect "general" event boundaries that correspond to natural human perception. In this paper, we introduce a novel contrastive learning based approach to deal with the GEBD. Our intuition is that the feature similarity of the video snippet would significantly vary near the event boundaries, while remaining relatively the same in the remaining part of the video. In our model, Temporal Self-similarity Matrix (TSM) is utilized as an intermediate representation which takes on a role as an information bottleneck. With our model, we achieved significant performance boost compared to the given baselines. Our code is available at https://github.com/hello-jinwoo/LOVEU-CVPR2021.
Optimal Transport for Unsupervised Restoration Learning
Aug 04, 2021
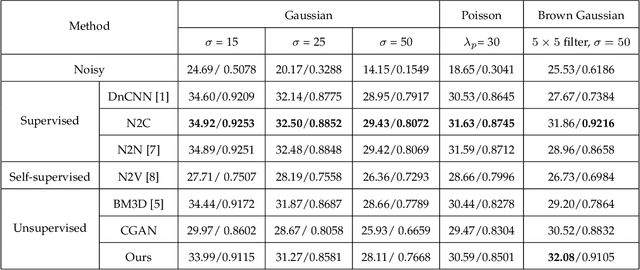
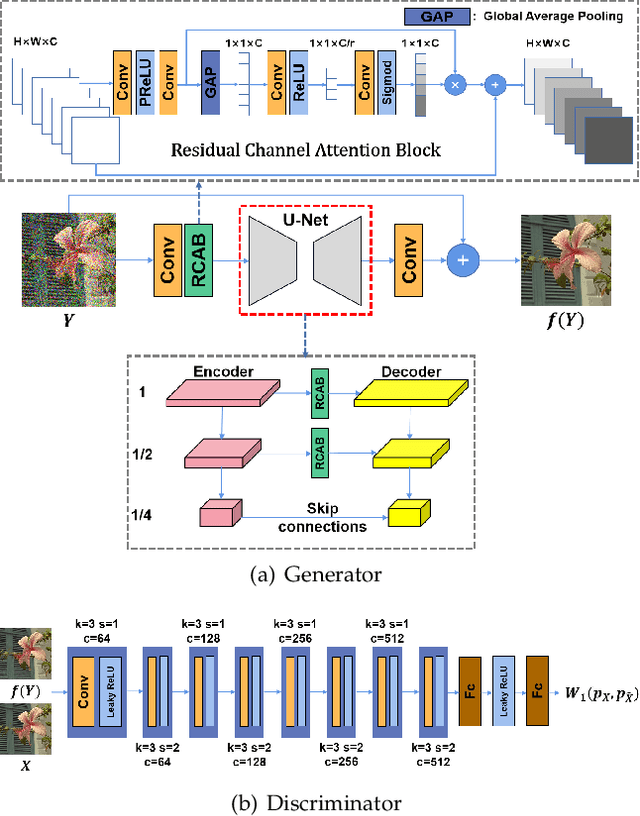

Recently, much progress has been made in unsupervised restoration learning. However, existing methods more or less rely on some assumptions on the signal and/or degradation model, which limits their practical performance. How to construct an optimal criterion for unsupervised restoration learning without any prior knowledge on the degradation model is still an open question. Toward answering this question, this work proposes a criterion for unsupervised restoration learning based on the optimal transport theory. This criterion has favorable properties, e.g., approximately maximal preservation of the information of the signal, whilst achieving perceptual reconstruction. Furthermore, though a relaxed unconstrained formulation is used in practical implementation, we show that the relaxed formulation in theory has the same solution as the original constrained formulation. Experiments on synthetic and real-world data, including realistic photographic, microscopy, depth, and raw depth images, demonstrate that the proposed method even compares favorably with supervised methods, e.g., approaching the PSNR of supervised methods while having better perceptual quality. Particularly, for spatially correlated noise and realistic microscopy images, the proposed method not only achieves better perceptual quality but also has higher PSNR than supervised methods. Besides, it shows remarkable superiority in harsh practical conditions with complex noise, e.g., raw depth images.
Decision Making Using Rough Set based Spanning Sets for a Decision System
Jul 21, 2021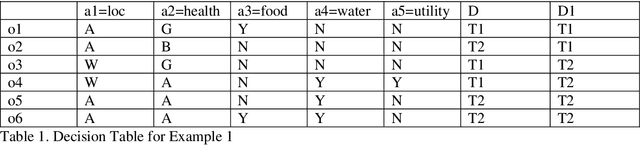
Rough Set based concepts of Span and Spanning Sets were recently proposed to deal with uncertainties in data. Here, this paper, presents novel concepts for generic decision-making process using Rough Set based span for a decision table. Majority of problems in Artificial Intelligence deal with decision making. This paper provides real life applications of proposed Rough Set based span for decision tables. Here, novel concept of span for a decision table is proposed, illustrated with real life example of flood relief and rescue team assignment. Its uses, applications and properties are explored. The key contribution of paper is primarily to study decision making using Rough Set based Span for a decision tables, as against an information system in prior works. Here, the main contribution is that decision classes are automatically learned by the technique of Rough Set based span, for a particular problem, hence automating the decision-making process. These decision-making tools based on span can guide an expert in taking decisions in tough and time-bound situations.
Unsupervised Remote Sensing Super-Resolution via Migration Image Prior
May 23, 2021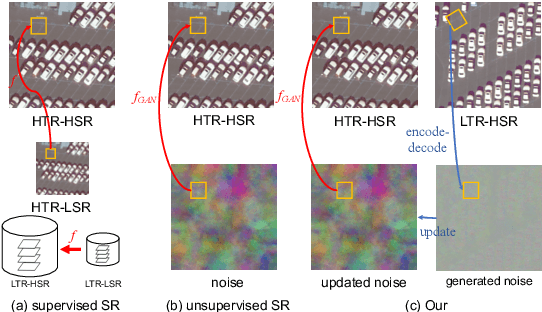
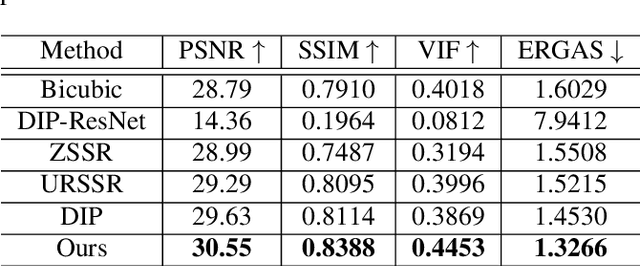
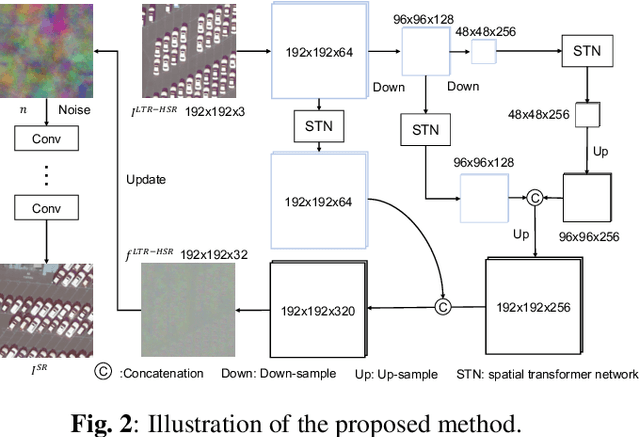
Recently, satellites with high temporal resolution have fostered wide attention in various practical applications. Due to limitations of bandwidth and hardware cost, however, the spatial resolution of such satellites is considerably low, largely limiting their potentials in scenarios that require spatially explicit information. To improve image resolution, numerous approaches based on training low-high resolution pairs have been proposed to address the super-resolution (SR) task. Despite their success, however, low/high spatial resolution pairs are usually difficult to obtain in satellites with a high temporal resolution, making such approaches in SR impractical to use. In this paper, we proposed a new unsupervised learning framework, called "MIP", which achieves SR tasks without low/high resolution image pairs. First, random noise maps are fed into a designed generative adversarial network (GAN) for reconstruction. Then, the proposed method converts the reference image to latent space as the migration image prior. Finally, we update the input noise via an implicit method, and further transfer the texture and structured information from the reference image. Extensive experimental results on the Draper dataset show that MIP achieves significant improvements over state-of-the-art methods both quantitatively and qualitatively. The proposed MIP is open-sourced at http://github.com/jiaming-wang/MIP.
Enhancing Fine-Grained Classification for Low Resolution Images
May 01, 2021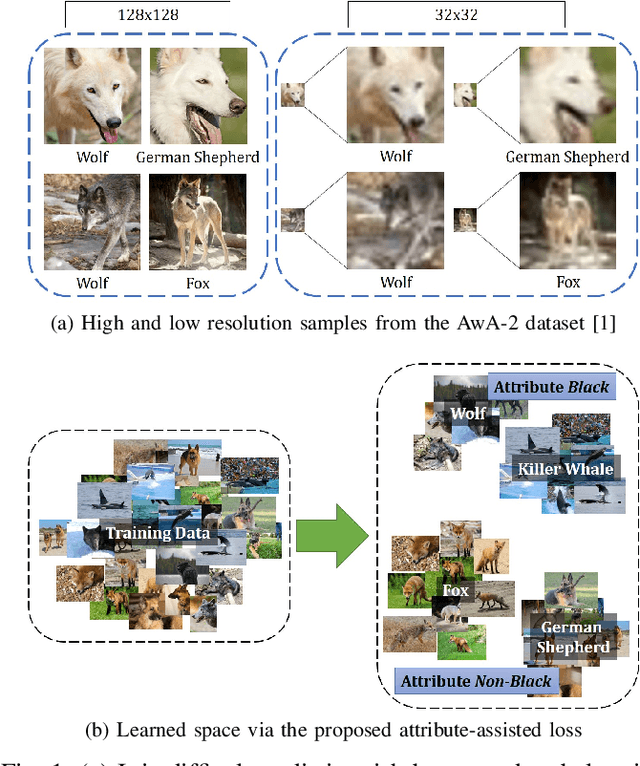
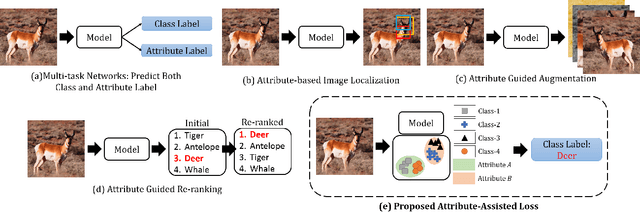

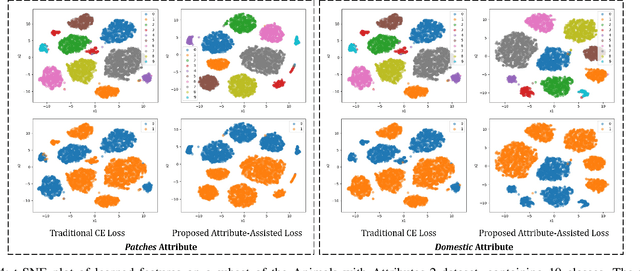
Low resolution fine-grained classification has widespread applicability for applications where data is captured at a distance such as surveillance and mobile photography. While fine-grained classification with high resolution images has received significant attention, limited attention has been given to low resolution images. These images suffer from the inherent challenge of limited information content and the absence of fine details useful for sub-category classification. This results in low inter-class variations across samples of visually similar classes. In order to address these challenges, this research proposes a novel attribute-assisted loss, which utilizes ancillary information to learn discriminative features for classification. The proposed loss function enables a model to learn class-specific discriminative features, while incorporating attribute-level separability. Evaluation is performed on multiple datasets with different models, for four resolutions varying from 32x32 to 224x224. Different experiments demonstrate the efficacy of the proposed attributeassisted loss for low resolution fine-grained classification.
Non-Recursive Graph Convolutional Networks
May 09, 2021
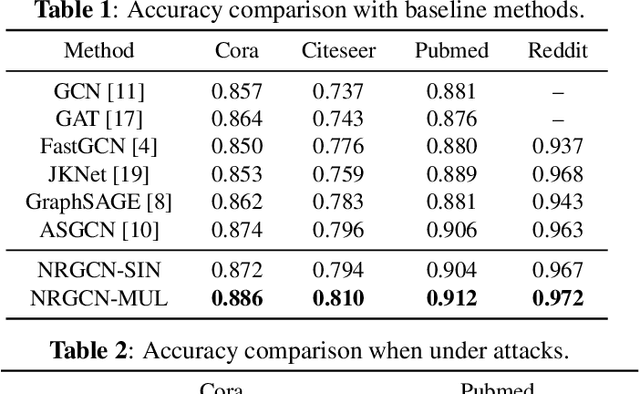
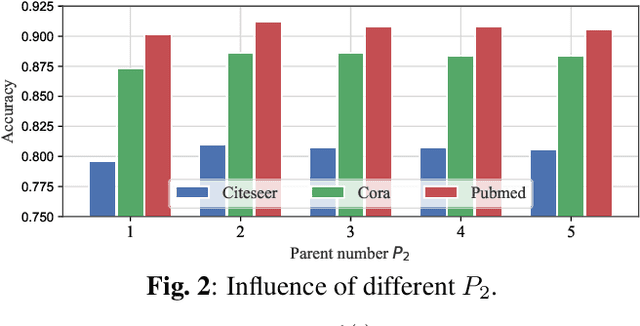
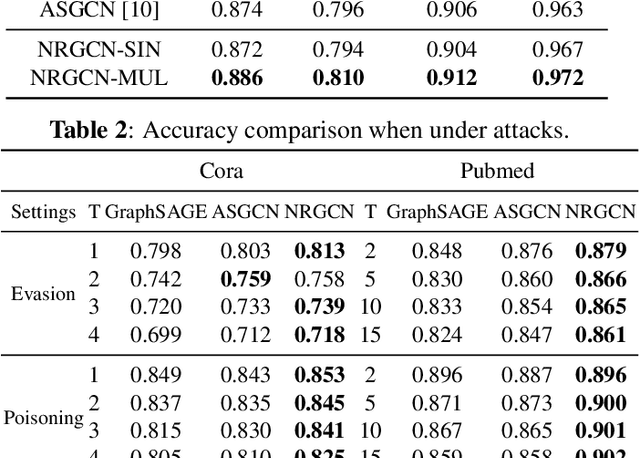
Graph Convolutional Networks (GCNs) are powerful models for node representation learning tasks. However, the node representation in existing GCN models is usually generated by performing recursive neighborhood aggregation across multiple graph convolutional layers with certain sampling methods, which may lead to redundant feature mixing, needless information loss, and extensive computations. Therefore, in this paper, we propose a novel architecture named Non-Recursive Graph Convolutional Network (NRGCN) to improve both the training efficiency and the learning performance of GCNs in the context of node classification. Specifically, NRGCN proposes to represent different hops of neighbors for each node based on inner-layer aggregation and layer-independent sampling. In this way, each node can be directly represented by concatenating the information extracted independently from each hop of its neighbors thereby avoiding the recursive neighborhood expansion across layers. Moreover, the layer-independent sampling and aggregation can be precomputed before the model training, thus the training process can be accelerated considerably. Extensive experiments on benchmark datasets verify that our NRGCN outperforms the state-of-the-art GCN models, in terms of the node classification performance and reliability.
Brain Surface Reconstruction from MRI Images Based on Segmentation Networks Applying Signed Distance Maps
Apr 09, 2021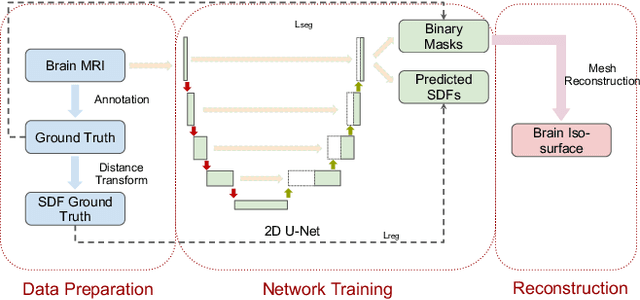

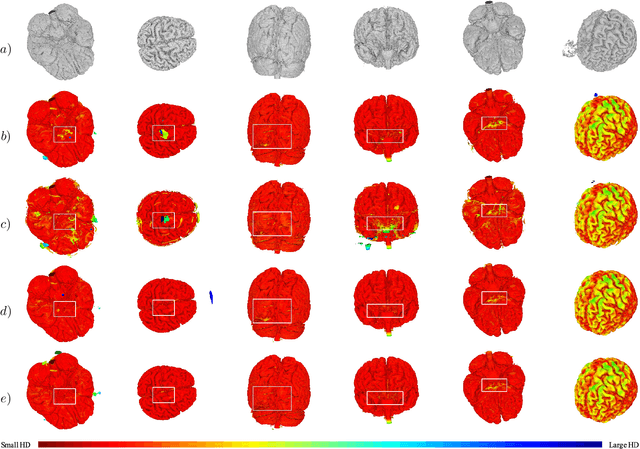
Whole-brain surface extraction is an essential topic in medical imaging systems as it provides neurosurgeons with a broader view of surgical planning and abnormality detection. To solve the problem confronted in current deep learning skull stripping methods lacking prior shape information, we propose a new network architecture that incorporates knowledge of signed distance fields and introduce an additional Laplacian loss to ensure that the prediction results retain shape information. We validated our newly proposed method by conducting experiments on our brain magnetic resonance imaging dataset (111 patients). The evaluation results demonstrate that our approach achieves comparable dice scores and also reduces the Hausdorff distance and average symmetric surface distance, thus producing more stable and smooth brain isosurfaces.
Spatio-Temporal Representation Factorization for Video-based Person Re-Identification
Aug 15, 2021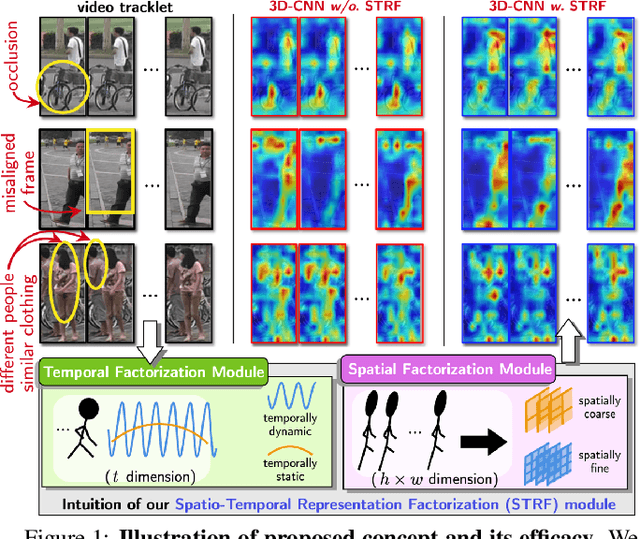
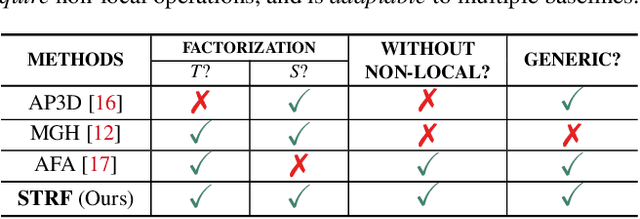

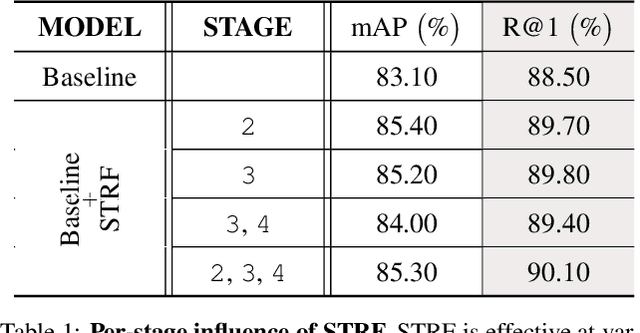
Despite much recent progress in video-based person re-identification (re-ID), the current state-of-the-art still suffers from common real-world challenges such as appearance similarity among various people, occlusions, and frame misalignment. To alleviate these problems, we propose Spatio-Temporal Representation Factorization (STRF), a flexible new computational unit that can be used in conjunction with most existing 3D convolutional neural network architectures for re-ID. The key innovations of STRF over prior work include explicit pathways for learning discriminative temporal and spatial features, with each component further factorized to capture complementary person-specific appearance and motion information. Specifically, temporal factorization comprises two branches, one each for static features (e.g., the color of clothes) that do not change much over time, and dynamic features (e.g., walking patterns) that change over time. Further, spatial factorization also comprises two branches to learn both global (coarse segments) as well as local (finer segments) appearance features, with the local features particularly useful in cases of occlusion or spatial misalignment. These two factorization operations taken together result in a modular architecture for our parameter-wise light STRF unit that can be plugged in between any two 3D convolutional layers, resulting in an end-to-end learning framework. We empirically show that STRF improves performance of various existing baseline architectures while demonstrating new state-of-the-art results using standard person re-ID evaluation protocols on three benchmarks.