 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Novel Time Domain Based Upper-Limb Prosthesis Control using Incremental Learning Approach
Aug 25, 2021
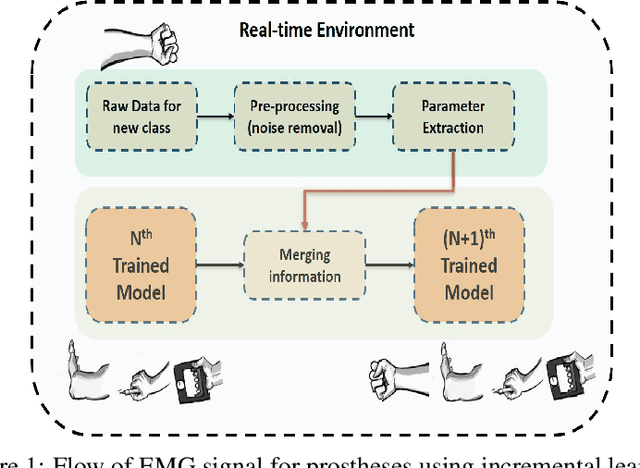
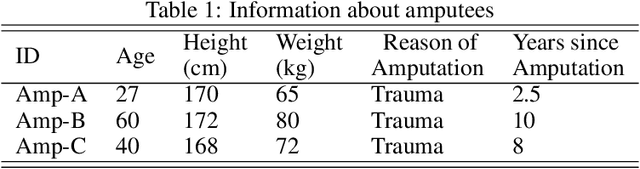
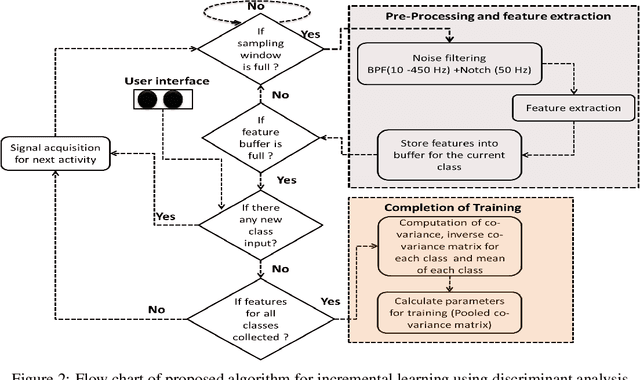
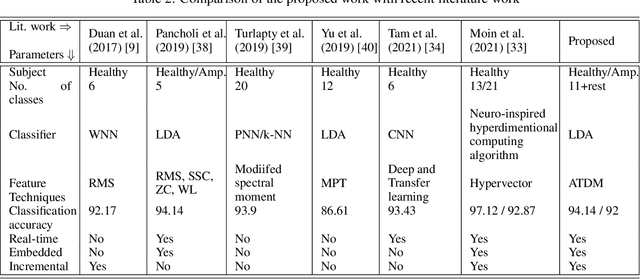
The upper limb of the body is a vital for various kind of activities for human. The complete or partial loss of the upper limb would lead to a significant impact on daily activities of the amputees. EMG carries important information of human physique which helps to decode the various functionalities of human arm. EMG signal based bionics and prosthesis have gained huge research attention over the past decade. Conventional EMG-PR based prosthesis struggles to give accurate performance due to off-line training used and incapability to compensate for electrode position shift and change in arm position. This work proposes online training and incremental learning based system for upper limb prosthetic application. This system consists of ADS1298 as AFE (analog front end) and a 32 bit arm cortex-m4 processor for DSP (digital signal processing). The system has been tested for both intact and amputated subjects. Time derivative moment based features have been implemented and utilized for effective pattern classification. Initially, system have been trained for four classes using the on-line training process later on the number of classes have been incremented on user demand till eleven, and system performance has been evaluated. The system yielded a completion rate of 100% for healthy and amputated subjects when four motions have been considered. Further 94.33% and 92% completion rate have been showcased by the system when the number of classes increased to eleven for healthy and amputees respectively. The motion efficacy test is also evaluated for all the subjects. The highest efficacy rate of 91.23% and 88.64% are observed for intact and amputated subjects respectively.
Adaptive Dilated Convolution For Human Pose Estimation
Jul 22, 2021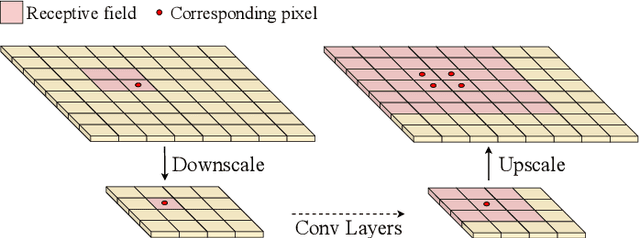
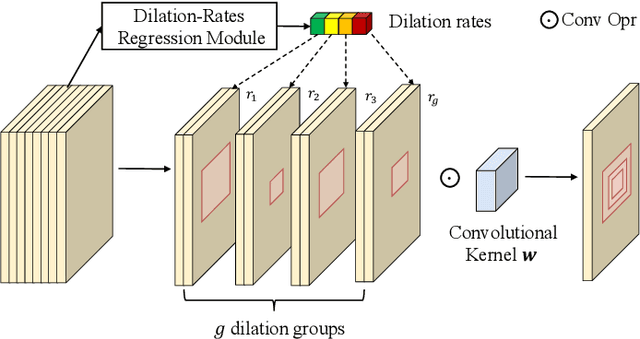

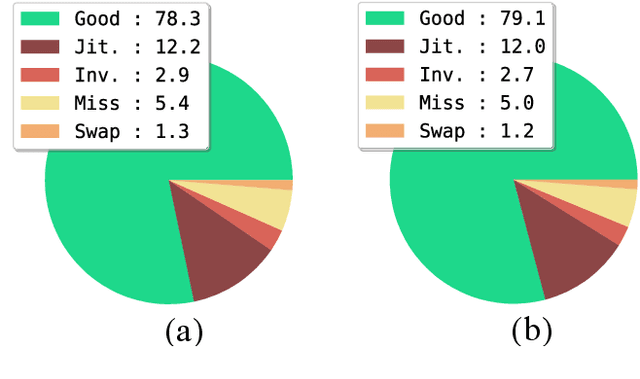
Most existing human pose estimation (HPE) methods exploit multi-scale information by fusing feature maps of four different spatial sizes, \ie $1/4$, $1/8$, $1/16$, and $1/32$ of the input image. There are two drawbacks of this strategy: 1) feature maps of different spatial sizes may be not well aligned spatially, which potentially hurts the accuracy of keypoint location; 2) these scales are fixed and inflexible, which may restrict the generalization ability over various human sizes. Towards these issues, we propose an adaptive dilated convolution (ADC). It can generate and fuse multi-scale features of the same spatial sizes by setting different dilation rates for different channels. More importantly, these dilation rates are generated by a regression module. It enables ADC to adaptively adjust the fused scales and thus ADC may generalize better to various human sizes. ADC can be end-to-end trained and easily plugged into existing methods. Extensive experiments show that ADC can bring consistent improvements to various HPE methods. The source codes will be released for further research.
Target-dependent UNITER: A Transformer-Based Multimodal Language Comprehension Model for Domestic Service Robots
Jul 02, 2021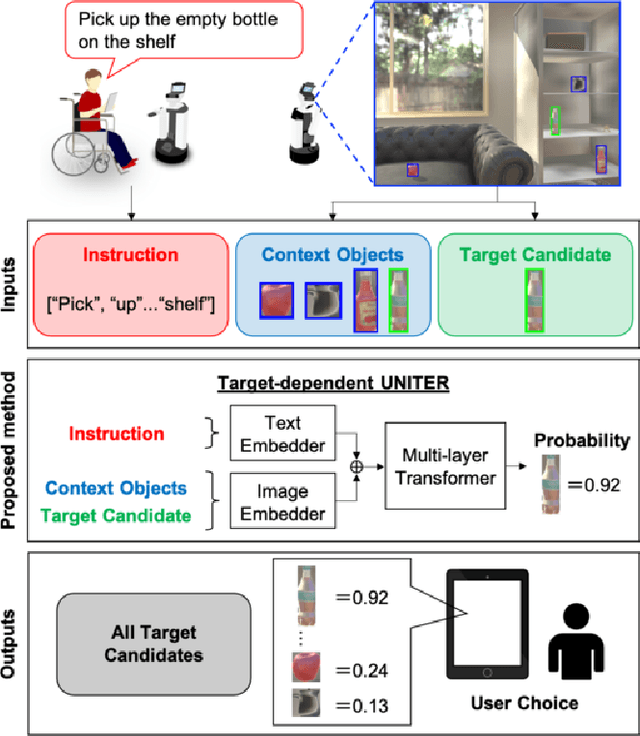

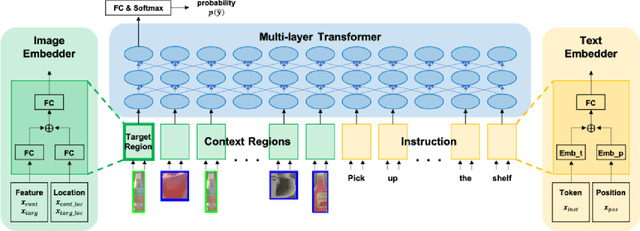
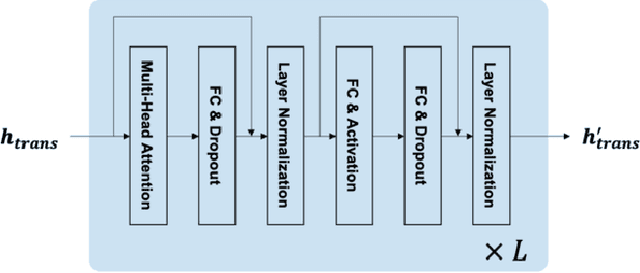
Currently, domestic service robots have an insufficient ability to interact naturally through language. This is because understanding human instructions is complicated by various ambiguities and missing information. In existing methods, the referring expressions that specify the relationships between objects are insufficiently modeled. In this paper, we propose Target-dependent UNITER, which learns the relationship between the target object and other objects directly by focusing on the relevant regions within an image, rather than the whole image. Our method is an extension of the UNITER-based Transformer that can be pretrained on general-purpose datasets. We extend the UNITER approach by introducing a new architecture for handling the target candidates. Our model is validated on two standard datasets, and the results show that Target-dependent UNITER outperforms the baseline method in terms of classification accuracy.
Trans4Trans: Efficient Transformer for Transparent Object and Semantic Scene Segmentation in Real-World Navigation Assistance
Aug 20, 2021

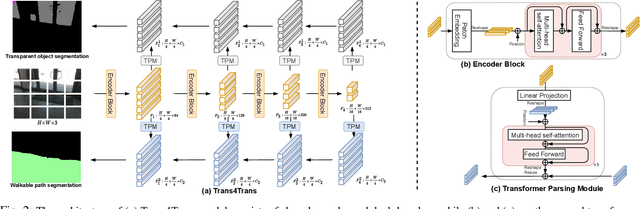
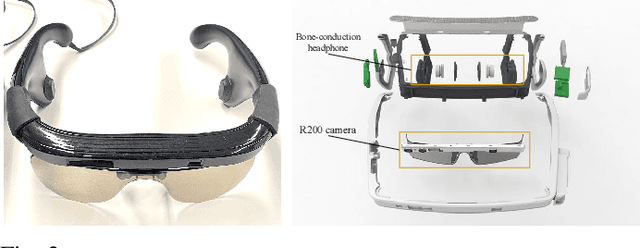
Transparent objects, such as glass walls and doors, constitute architectural obstacles hindering the mobility of people with low vision or blindness. For instance, the open space behind glass doors is inaccessible, unless it is correctly perceived and interacted with. However, traditional assistive technologies rarely cover the segmentation of these safety-critical transparent objects. In this paper, we build a wearable system with a novel dual-head Transformer for Transparency (Trans4Trans) perception model, which can segment general- and transparent objects. The two dense segmentation results are further combined with depth information in the system to help users navigate safely and assist them to negotiate transparent obstacles. We propose a lightweight Transformer Parsing Module (TPM) to perform multi-scale feature interpretation in the transformer-based decoder. Benefiting from TPM, the double decoders can perform joint learning from corresponding datasets to pursue robustness, meanwhile maintain efficiency on a portable GPU, with negligible calculation increase. The entire Trans4Trans model is constructed in a symmetrical encoder-decoder architecture, which outperforms state-of-the-art methods on the test sets of Stanford2D3D and Trans10K-v2 datasets, obtaining mIoU of 45.13% and 75.14%, respectively. Through a user study and various pre-tests conducted in indoor and outdoor scenes, the usability and reliability of our assistive system have been extensively verified. Meanwhile, the Tran4Trans model has outstanding performances on driving scene datasets. On Cityscapes, ACDC, and DADA-seg datasets corresponding to common environments, adverse weather, and traffic accident scenarios, mIoU scores of 81.5%, 76.3%, and 39.2% are obtained, demonstrating its high efficiency and robustness for real-world transportation applications.
AttWalk: Attentive Cross-Walks for Deep Mesh Analysis
Apr 23, 2021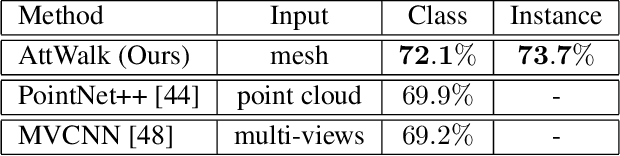
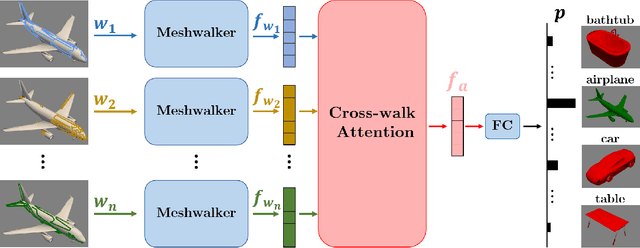
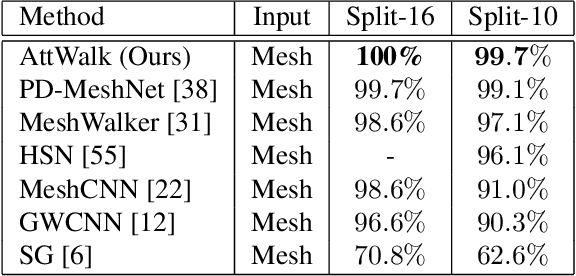
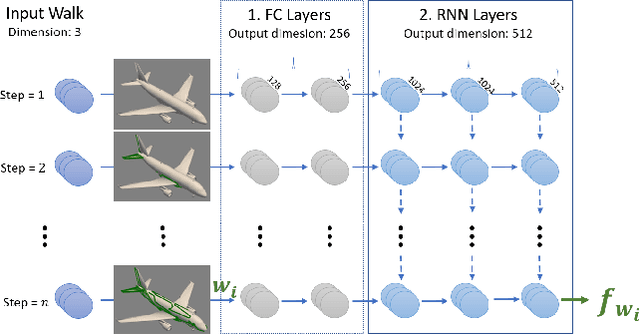
Mesh representation by random walks has been shown to benefit deep learning. Randomness is indeed a powerful concept. However, it comes with a price: some walks might wander around non-characteristic regions of the mesh, which might be harmful to shape analysis, especially when only a few walks are utilized. We propose a novel walk-attention mechanism that leverages the fact that multiple walks are used. The key idea is that the walks may provide each other with information regarding the meaningful (attentive) features of the mesh. We utilize this mutual information to extract a single descriptor of the mesh. This differs from common attention mechanisms that use attention to improve the representation of each individual descriptor. Our approach achieves SOTA results for two basic 3D shape analysis tasks: classification and retrieval. Even a handful of walks along a mesh suffice for learning.
Improve Learning from Crowds via Generative Augmentation
Jul 22, 2021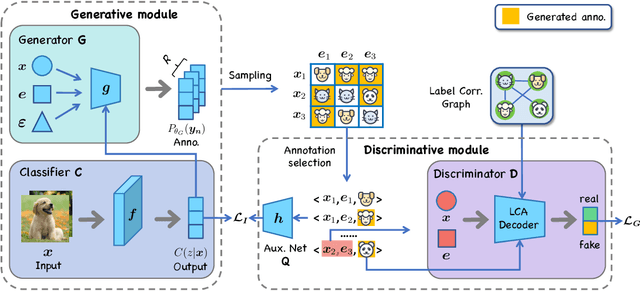
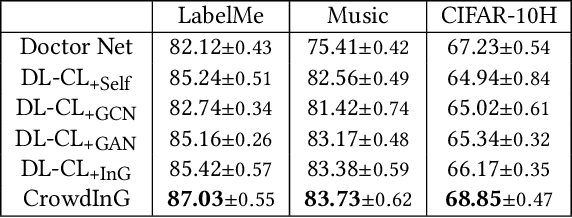
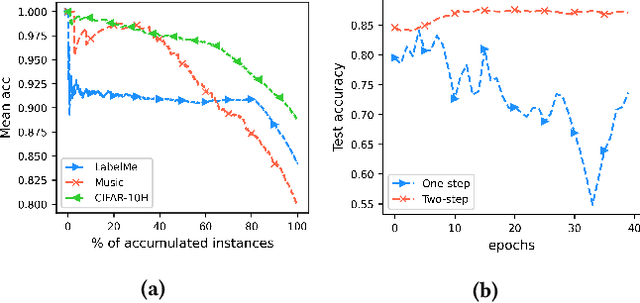
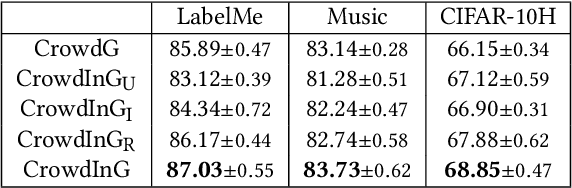
Crowdsourcing provides an efficient label collection schema for supervised machine learning. However, to control annotation cost, each instance in the crowdsourced data is typically annotated by a small number of annotators. This creates a sparsity issue and limits the quality of machine learning models trained on such data. In this paper, we study how to handle sparsity in crowdsourced data using data augmentation. Specifically, we propose to directly learn a classifier by augmenting the raw sparse annotations. We implement two principles of high-quality augmentation using Generative Adversarial Networks: 1) the generated annotations should follow the distribution of authentic ones, which is measured by a discriminator; 2) the generated annotations should have high mutual information with the ground-truth labels, which is measured by an auxiliary network. Extensive experiments and comparisons against an array of state-of-the-art learning from crowds methods on three real-world datasets proved the effectiveness of our data augmentation framework. It shows the potential of our algorithm for low-budget crowdsourcing in general.
Modeling long-term interactions to enhance action recognition
Apr 23, 2021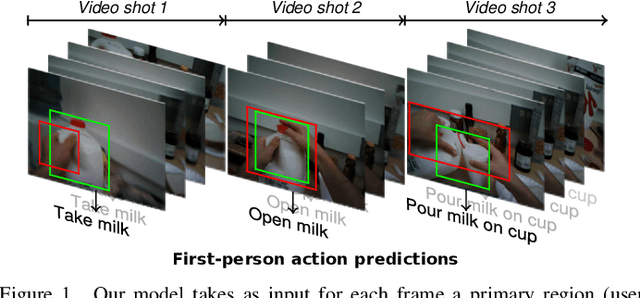

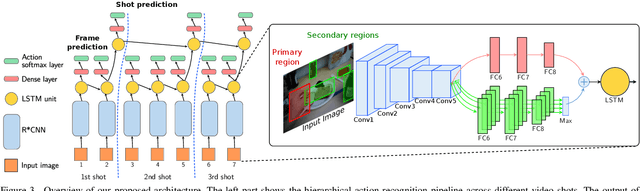
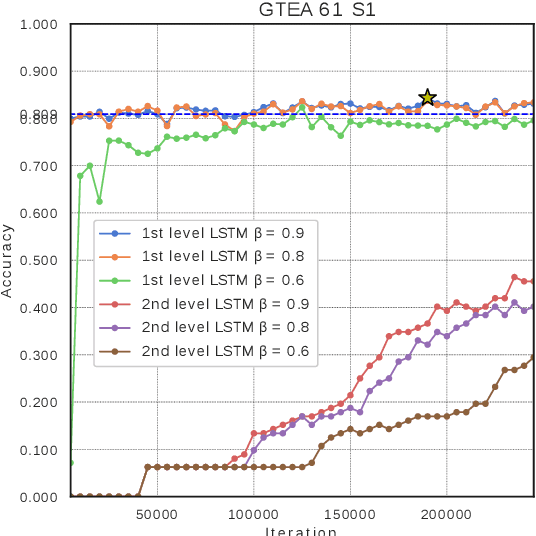
In this paper, we propose a new approach to under-stand actions in egocentric videos that exploits the semantics of object interactions at both frame and temporal levels. At the frame level, we use a region-based approach that takes as input a primary region roughly corresponding to the user hands and a set of secondary regions potentially corresponding to the interacting objects and calculates the action score through a CNN formulation. This information is then fed to a Hierarchical LongShort-Term Memory Network (HLSTM) that captures temporal dependencies between actions within and across shots. Ablation studies thoroughly validate the proposed approach, showing in particular that both levels of the HLSTM architecture contribute to performance improvement. Furthermore, quantitative comparisons show that the proposed approach outperforms the state-of-the-art in terms of action recognition on standard benchmarks,without relying on motion information
Tri-Branch Convolutional Neural Networks for Top-$k$ Focused Academic Performance Prediction
Jul 22, 2021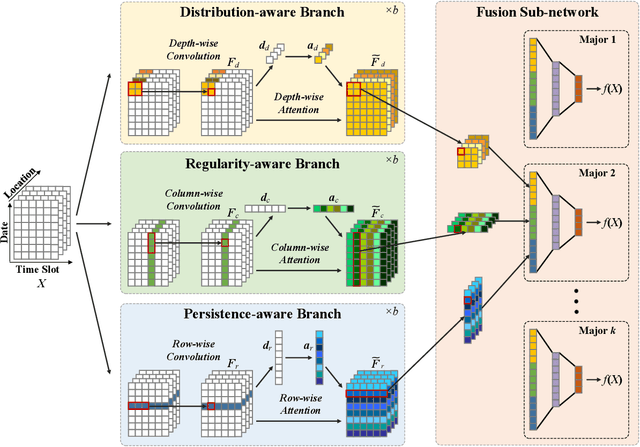
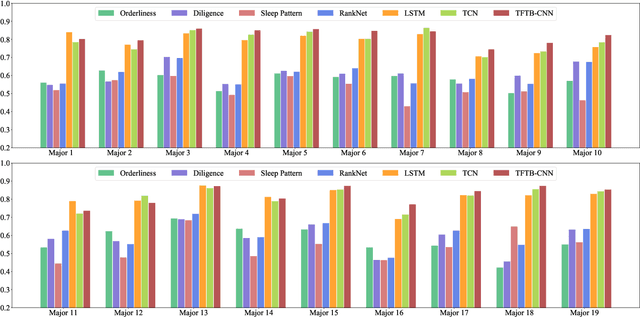
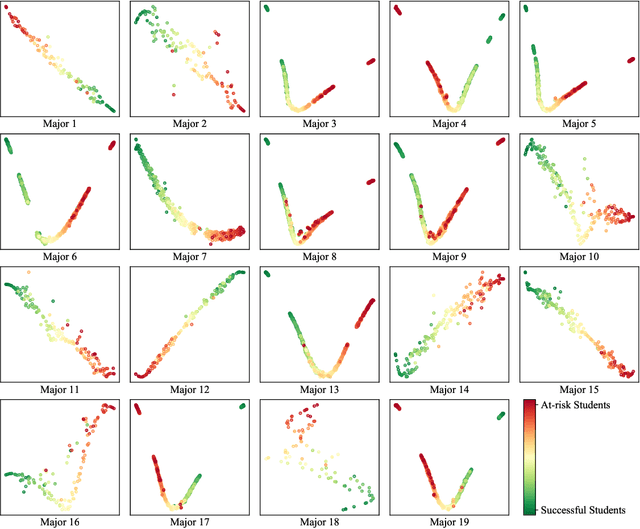

Academic performance prediction aims to leverage student-related information to predict their future academic outcomes, which is beneficial to numerous educational applications, such as personalized teaching and academic early warning. In this paper, we address the problem by analyzing students' daily behavior trajectories, which can be comprehensively tracked with campus smartcard records. Different from previous studies, we propose a novel Tri-Branch CNN architecture, which is equipped with row-wise, column-wise, and depth-wise convolution and attention operations, to capture the characteristics of persistence, regularity, and temporal distribution of student behavior in an end-to-end manner, respectively. Also, we cast academic performance prediction as a top-$k$ ranking problem, and introduce a top-$k$ focused loss to ensure the accuracy of identifying academically at-risk students. Extensive experiments were carried out on a large-scale real-world dataset, and we show that our approach substantially outperforms recently proposed methods for academic performance prediction. For the sake of reproducibility, our codes have been released at https://github.com/ZongJ1111/Academic-Performance-Prediction.
Comparing PCG metrics with Human Evaluation in Minecraft Settlement Generation
Jul 06, 2021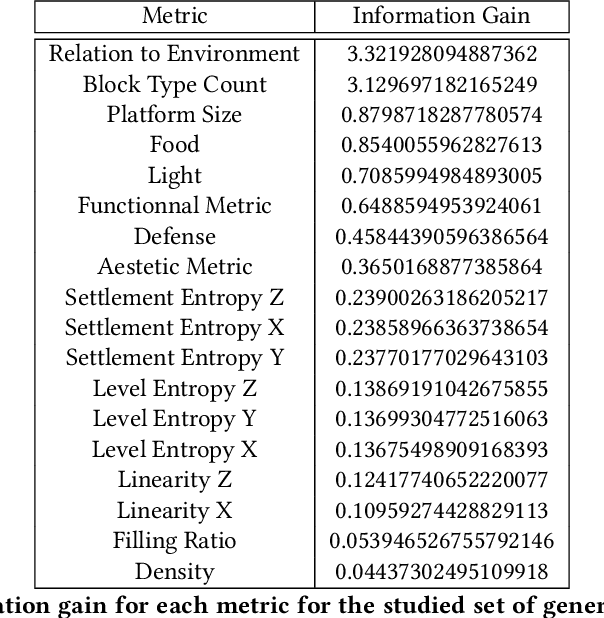
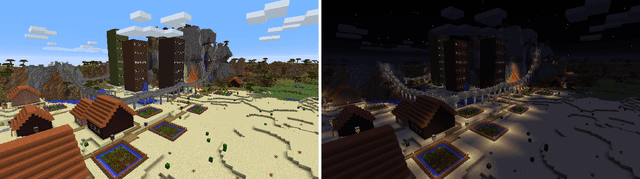
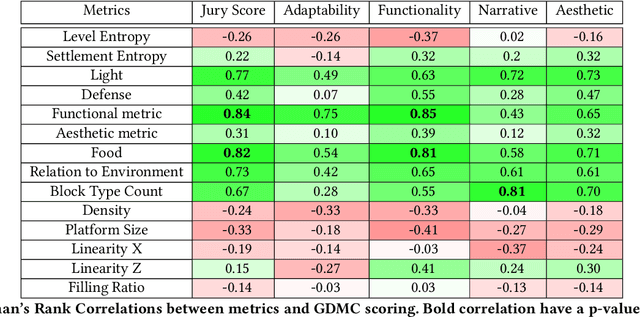
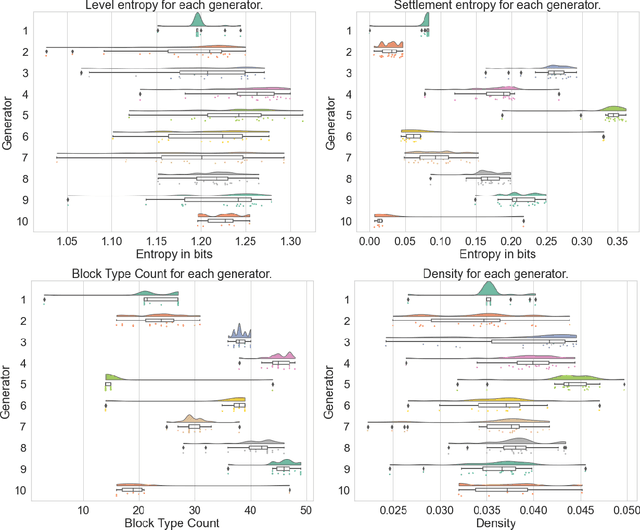
There are a range of metrics that can be applied to the artifacts produced by procedural content generation, and several of them come with qualitative claims. In this paper, we adapt a range of existing PCG metrics to generated Minecraft settlements, develop a few new metrics inspired by PCG literature, and compare the resulting measurements to existing human evaluations. The aim is to analyze how those metrics capture human evaluation scores in different categories, how the metrics generalize to another game domain, and how metrics deal with more complex artifacts. We provide an exploratory look at a variety of metrics and provide an information gain and several correlation analyses. We found some relationships between human scores and metrics counting specific elements, measuring the diversity of blocks and measuring the presence of crafting materials for the present complex blocks.
Fast approximations of the Jeffreys divergence between univariate Gaussian mixture models via exponential polynomial densities
Aug 04, 2021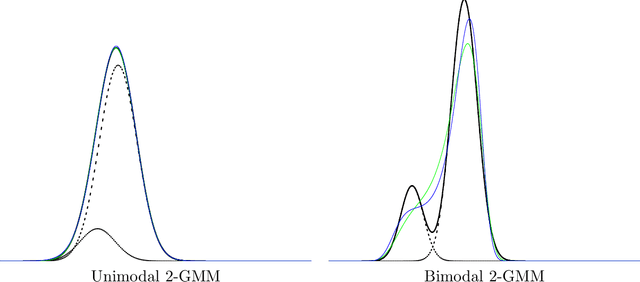
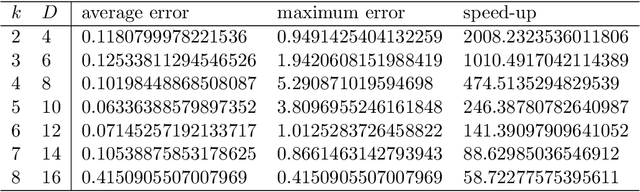
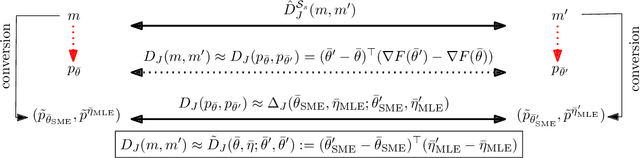

The Jeffreys divergence is a renown symmetrization of the statistical Kullback-Leibler divergence which is often used in statistics, machine learning, signal processing, and information sciences in general. Since the Jeffreys divergence between the ubiquitous Gaussian Mixture Models are not available in closed-form, many techniques with various pros and cons have been proposed in the literature to either (i) estimate, (ii) approximate, or (iii) lower and/or upper bound this divergence. In this work, we propose a simple yet fast heuristic to approximate the Jeffreys divergence between two univariate GMMs of arbitrary number of components. The heuristic relies on converting GMMs into pairs of dually parameterized probability densities belonging to exponential families. In particular, we consider Exponential-Polynomial Densities, and design a goodness-of-fit criterion to measure the dissimilarity between a GMM and a EPD which is a generalization of the Hyv\"arinen divergence. This criterion allows one to select the orders of the EPDs to approximate the GMMs. We demonstrate experimentally that the computational time of our heuristic improves over the stochastic Monte Carlo estimation baseline by several orders of magnitude while approximating reasonably well the Jeffreys divergence, specially when the univariate mixtures have a small number of modes.