 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Form 10-Q Itemization
Apr 23, 2021
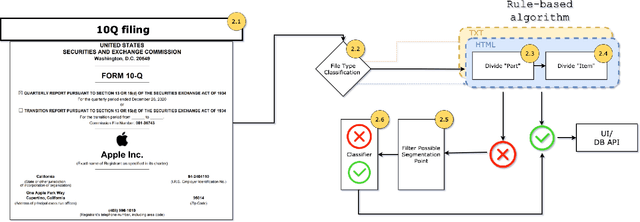


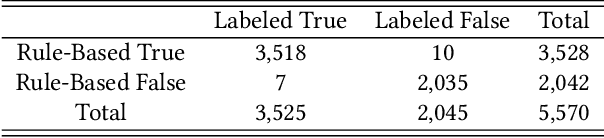
Form 10-Q, the quarterly financial statement, is one of the most crucial filings for US public firms to disclose their financial and other relevant business operation information. Due to the gigantic number of 10-Q filings prevailing in the market for each quarter and diverse variations in the implementation of format given company-specific nature, it has long been a problem in the field to provide a generalized way to dissect and retrieve the itemized information. In this paper, we create a tool to itemize 10-Q filings using multi-stage processes, blending a rule-based algorithm with a CNN deep learning model. The implementation is an integrated pipeline which provides a solution to the item retrieval on a large scale. This would enable cross sectional and longitudinal textual analysis on massive number of companies.
Sparse-to-dense Feature Matching: Intra and Inter domain Cross-modal Learning in Domain Adaptation for 3D Semantic Segmentation
Aug 04, 2021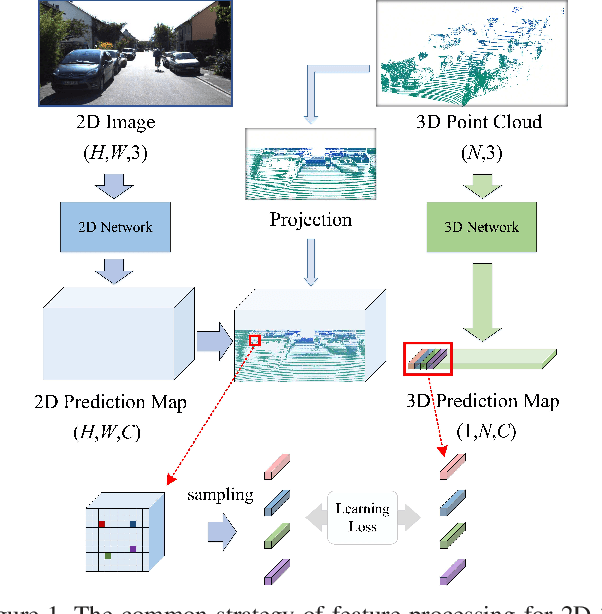
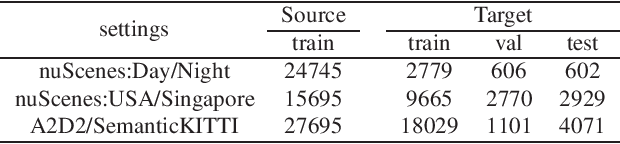
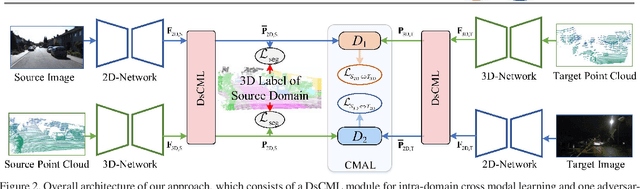
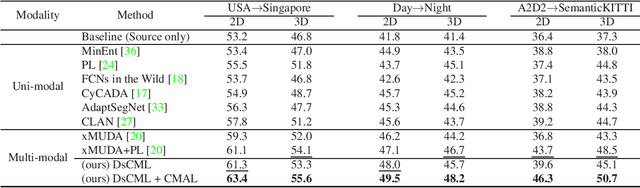
Domain adaptation is critical for success when confronting with the lack of annotations in a new domain. As the huge time consumption of labeling process on 3D point cloud, domain adaptation for 3D semantic segmentation is of great expectation. With the rise of multi-modal datasets, large amount of 2D images are accessible besides 3D point clouds. In light of this, we propose to further leverage 2D data for 3D domain adaptation by intra and inter domain cross modal learning. As for intra-domain cross modal learning, most existing works sample the dense 2D pixel-wise features into the same size with sparse 3D point-wise features, resulting in the abandon of numerous useful 2D features. To address this problem, we propose Dynamic sparse-to-dense Cross Modal Learning (DsCML) to increase the sufficiency of multi-modality information interaction for domain adaptation. For inter-domain cross modal learning, we further advance Cross Modal Adversarial Learning (CMAL) on 2D and 3D data which contains different semantic content aiming to promote high-level modal complementarity. We evaluate our model under various multi-modality domain adaptation settings including day-to-night, country-to-country and dataset-to-dataset, brings large improvements over both uni-modal and multi-modal domain adaptation methods on all settings.
Hyperparameter-free and Explainable Whole Graph Embedding
Aug 04, 2021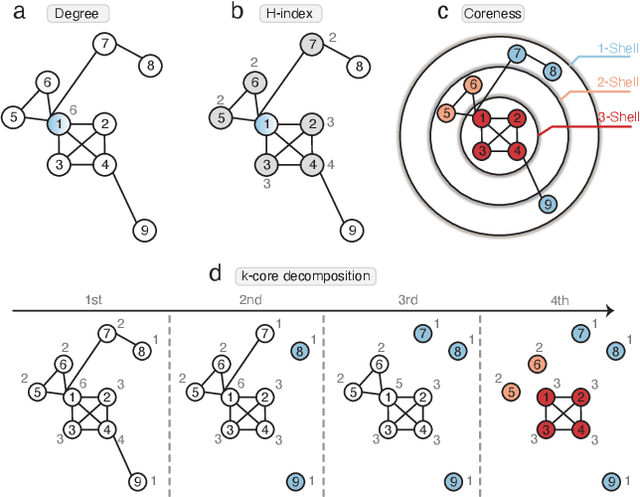
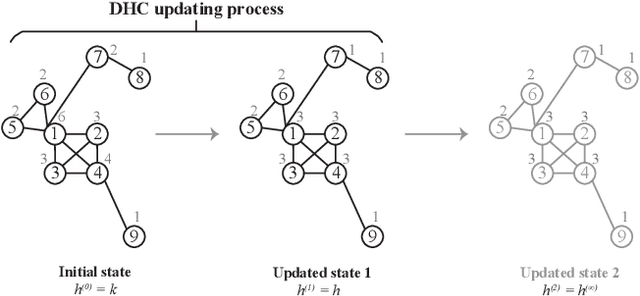
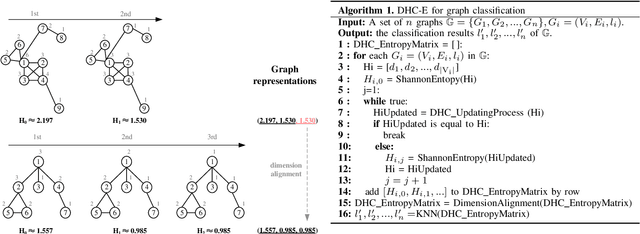
Many real-world complex systems can be described as graphs. For a large-scale graph with low sparsity, a node's adjacency vector is a long and sparse representation, limiting the practical utilization of existing machine learning methods on nodal features. In practice, graph embedding (graph representation learning) attempts to learn a lower-dimensional representation vector for each node or the whole graph while maintaining the most basic information of graph. Since various machine learning methods can efficiently process lower-dimensional vectors, graph embedding has recently attracted a lot of attention. However, most node embedding or whole graph embedding methods suffer from the problem of having more sophisticated methodology, hyperparameter optimization, and low explainability. This paper proposes a hyperparameter-free, extensible, and explainable whole graph embedding method, combining the DHC (Degree, H-index and Coreness) theorem and Shannon Entropy (E), abbreviated as DHC-E. The new whole graph embedding scheme can obtain a trade-off between the simplicity and the quality under some supervised classification learning tasks, using molecular, social, and brain networks. In addition, the proposed approach has a good performance in lower-dimensional graph visualization. The new methodology is overall simple, hyperparameter-free, extensible, and explainable for whole graph embedding with promising potential for exploring graph classification, prediction, and lower-dimensional graph visualization.
Human-In-The-Loop Document Layout Analysis
Aug 04, 2021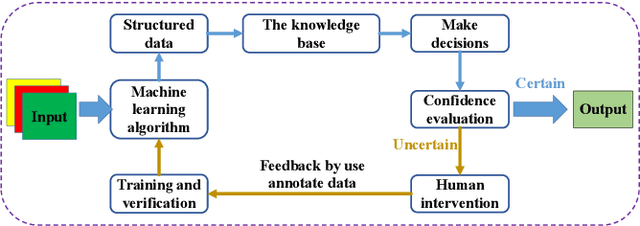
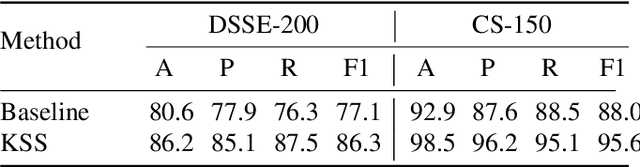
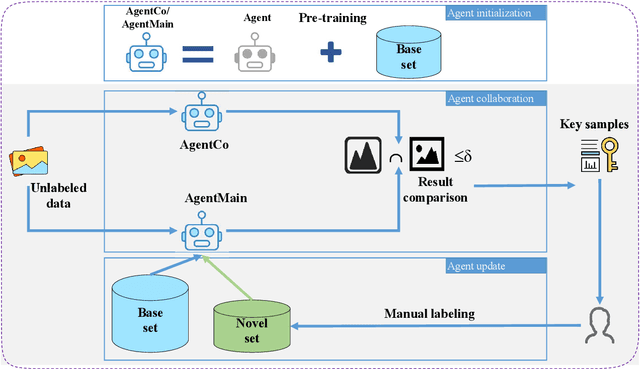
Document layout analysis (DLA) aims to divide a document image into different types of regions. DLA plays an important role in the document content understanding and information extraction systems. Exploring a method that can use less data for effective training contributes to the development of DLA. We consider a Human-in-the-loop (HITL) collaborative intelligence in the DLA. Our approach was inspired by the fact that the HITL push the model to learn from the unknown problems by adding a small amount of data based on knowledge. The HITL select key samples by using confidence. However, using confidence to find key samples is not suitable for DLA tasks. We propose the Key Samples Selection (KSS) method to find key samples in high-level tasks (semantic segmentation) more accurately through agent collaboration, effectively reducing costs. Once selected, these key samples are passed to human beings for active labeling, then the model will be updated with the labeled samples. Hence, we revisited the learning system from reinforcement learning and designed a sample-based agent update strategy, which effectively improves the agent's ability to accept new samples. It achieves significant improvement results in two benchmarks (DSSE-200 (from 77.1% to 86.3%) and CS-150 (from 88.0% to 95.6%)) by using 10% of labeled data.
CLSEBERT: Contrastive Learning for Syntax Enhanced Code Pre-Trained Model
Aug 10, 2021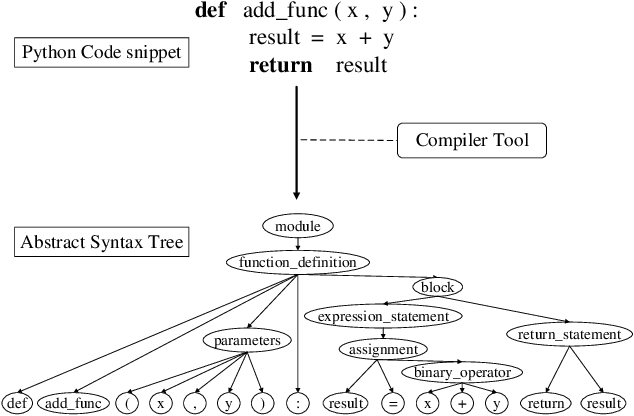
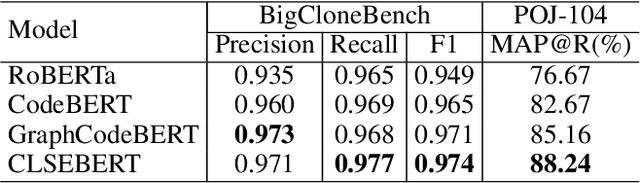


Pre-trained models for programming languages have proven their significant values in various code-related tasks, such as code search, code clone detection, and code translation. Currently, most pre-trained models treat a code snippet as a sequence of tokens or only focus on the data flow between code identifiers. However, rich code syntax and hierarchy are ignored which can provide important structure information and semantic rules of codes to help enhance code representations. In addition, although the BERT-based code pre-trained models achieve high performance on many downstream tasks, the native derived sequence representations of BERT are proven to be of low-quality, it performs poorly on code matching and similarity tasks. To address these problems, we propose CLSEBERT, a Constrastive Learning Framework for Syntax Enhanced Code Pre-Trained Model, to deal with various code intelligence tasks. In the pre-training stage, we consider the code syntax and hierarchy contained in the Abstract Syntax Tree (AST) and leverage the constrastive learning to learn noise-invariant code representations. Besides the masked language modeling (MLM), we also introduce two novel pre-training objectives. One is to predict the edges between nodes in the abstract syntax tree, and the other is to predict the types of code tokens. Through extensive experiments on four code intelligence tasks, we successfully show the effectiveness of our proposed model.
Deep Simultaneous Optimisation of Sampling and Reconstruction for Multi-contrast MRI
Mar 31, 2021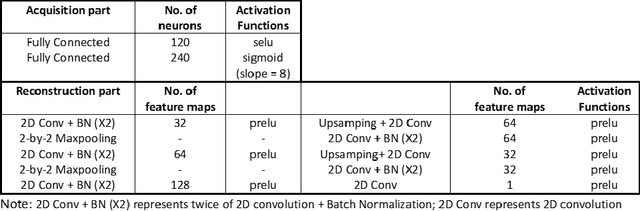
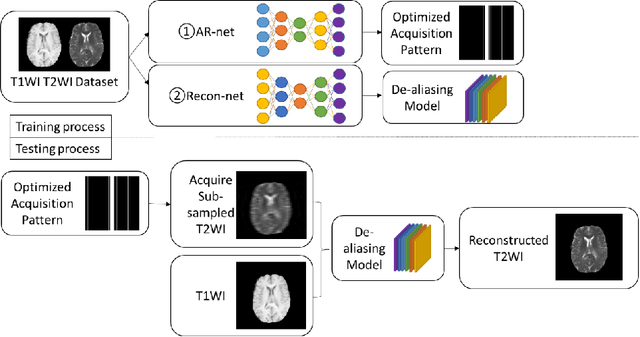
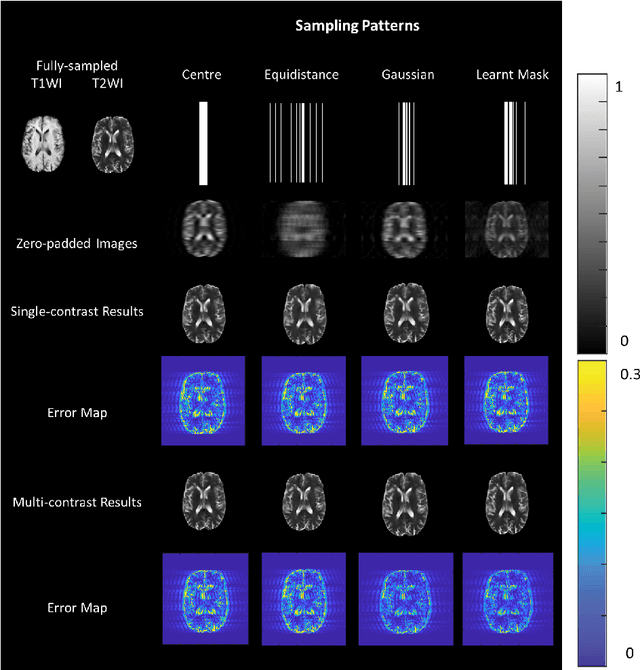
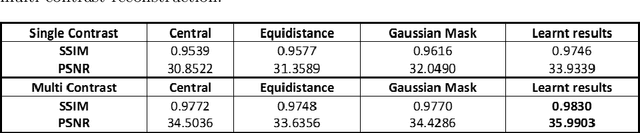
MRI images of the same subject in different contrasts contain shared information, such as the anatomical structure. Utilizing the redundant information amongst the contrasts to sub-sample and faithfully reconstruct multi-contrast images could greatly accelerate the imaging speed, improve image quality and shorten scanning protocols. We propose an algorithm that generates the optimised sampling pattern and reconstruction scheme of one contrast (e.g. T2-weighted image) when images with different contrast (e.g. T1-weighted image) have been acquired. The proposed algorithm achieves increased PSNR and SSIM with the resulting optimal sampling pattern compared to other acquisition patterns and single contrast methods.
Complexity Analysis of Stein Variational Gradient Descent Under Talagrand's Inequality T1
Jun 06, 2021
We study the complexity of Stein Variational Gradient Descent (SVGD), which is an algorithm to sample from $\pi(x) \propto \exp(-F(x))$ where $F$ smooth and nonconvex. We provide a clean complexity bound for SVGD in the population limit in terms of the Stein Fisher Information (or squared Kernelized Stein Discrepancy), as a function of the dimension of the problem $d$ and the desired accuracy $\varepsilon$. Unlike existing work, we do not make any assumption on the trajectory of the algorithm. Instead, our key assumption is that the target distribution satisfies Talagrand's inequality T1.
Study of sampling methods in sentiment analysis of imbalanced data
Jun 12, 2021
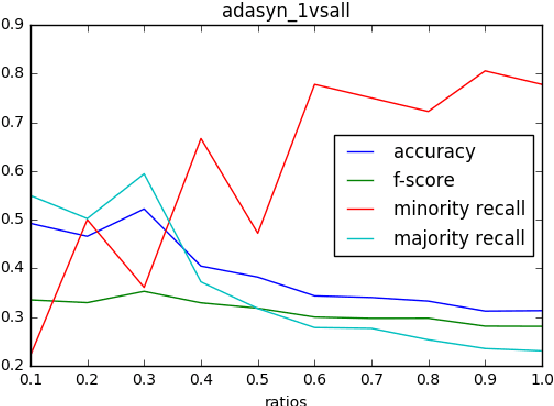

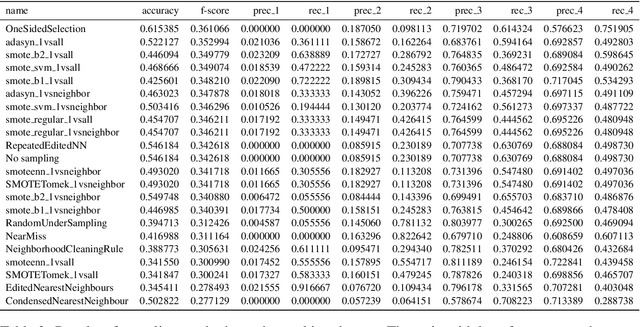
This work investigates the application of sampling methods for sentiment analysis on two different highly imbalanced datasets. One dataset contains online user reviews from the cooking platform Epicurious and the other contains comments given to the Planned Parenthood organization. In both these datasets, the classes of interest are rare. Word n-grams were used as features from these datasets. A feature selection technique based on information gain is first applied to reduce the number of features to a manageable space. A number of different sampling methods were then applied to mitigate the class imbalance problem which are then analyzed.
Incorporating Learnt Local and Global Embeddings into Monocular Visual SLAM
Aug 04, 2021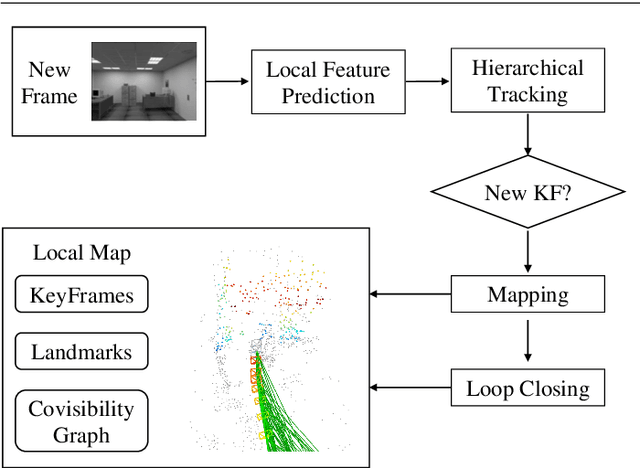
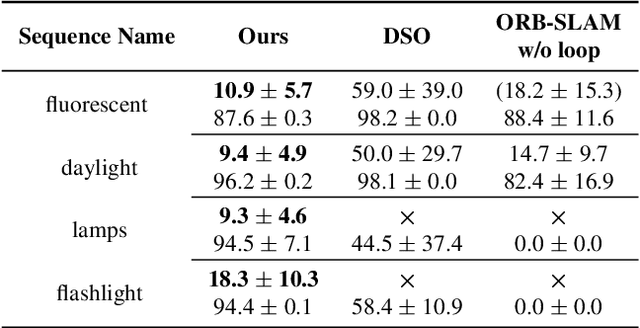
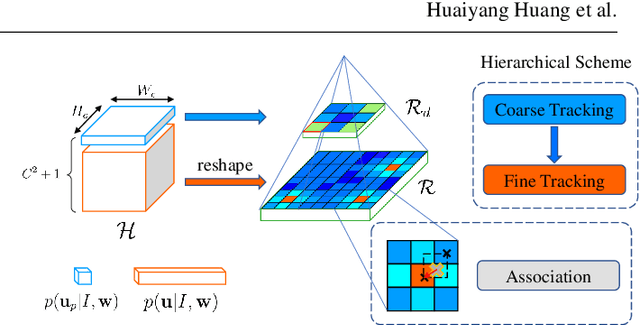
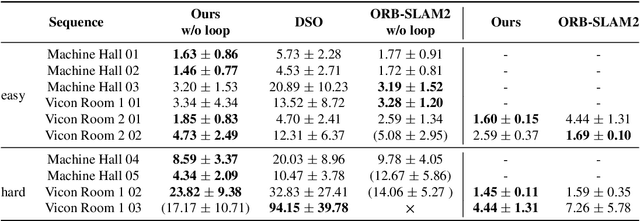
Traditional approaches for Visual Simultaneous Localization and Mapping (VSLAM) rely on low-level vision information for state estimation, such as handcrafted local features or the image gradient. While significant progress has been made through this track, under more challenging configuration for monocular VSLAM, e.g., varying illumination, the performance of state-of-the-art systems generally degrades. As a consequence, robustness and accuracy for monocular VSLAM are still widely concerned. This paper presents a monocular VSLAM system that fully exploits learnt features for better state estimation. The proposed system leverages both learnt local features and global embeddings at different modules of the system: direct camera pose estimation, inter-frame feature association, and loop closure detection. With a probabilistic explanation of keypoint prediction, we formulate the camera pose tracking in a direct manner and parameterize local features with uncertainty taken into account. To alleviate the quantization effect, we adapt the mapping module to generate 3D landmarks better to guarantee the system's robustness. Detecting temporal loop closure via deep global embeddings further improves the robustness and accuracy of the proposed system. The proposed system is extensively evaluated on public datasets (Tsukuba, EuRoC, and KITTI), and compared against the state-of-the-art methods. The competitive performance of camera pose estimation confirms the effectiveness of our method.
Effective and scalable clustering of SARS-CoV-2 sequences
Aug 25, 2021
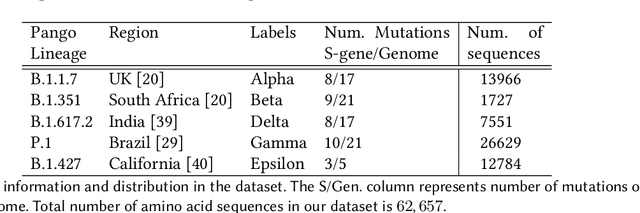
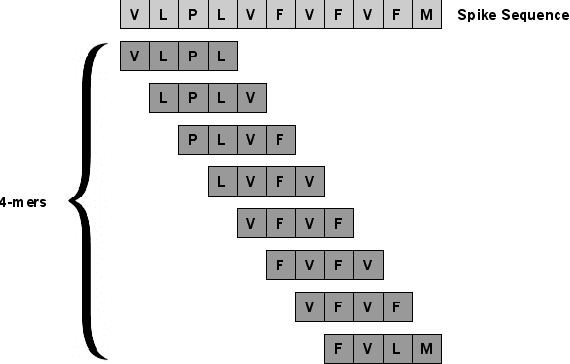
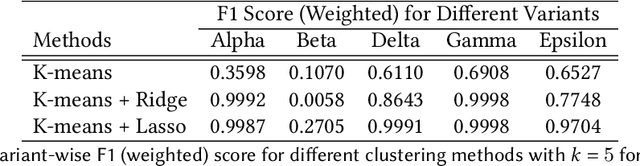
SARS-CoV-2, like any other virus, continues to mutate as it spreads, according to an evolutionary process. Unlike any other virus, the number of currently available sequences of SARS-CoV-2 in public databases such as GISAID is already several million. This amount of data has the potential to uncover the evolutionary dynamics of a virus like never before. However, a million is already several orders of magnitude beyond what can be processed by the traditional methods designed to reconstruct a virus's evolutionary history, such as those that build a phylogenetic tree. Hence, new and scalable methods will need to be devised in order to make use of the ever increasing number of viral sequences being collected. Since identifying variants is an important part of understanding the evolution of a virus, in this paper, we propose an approach based on clustering sequences to identify the current major SARS-CoV-2 variants. Using a $k$-mer based feature vector generation and efficient feature selection methods, our approach is effective in identifying variants, as well as being efficient and scalable to millions of sequences. Such a clustering method allows us to show the relative proportion of each variant over time, giving the rate of spread of each variant in different locations -- something which is important for vaccine development and distribution. We also compute the importance of each amino acid position of the spike protein in identifying a given variant in terms of information gain. Positions of high variant-specific importance tend to agree with those reported by the USA's Centers for Disease Control and Prevention (CDC), further demonstrating our approach.