 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Region-of-Interest Prioritised Sampling for Constrained Autonomous Exploration Systems
Jul 15, 2021



Goal oriented autonomous operation of space rovers has been known to increase scientific output of a mission. In this work we present an algorithm, called the RoI Prioritised Sampling (RPS), that prioritises Region-of-Interests (RoIs) in an exploration scenario in order to utilise the limited resources of the imaging instrument on the rover effectively. This prioritisation is based on an estimator that evaluates the change in information content at consecutive spatial scales of the RoIs without calculating the finer scale reconstruction. The estimator, called the Refinement Indicator, is motivated and derived. Multiscale acquisition approaches, based on classical and multi-level compressed sensing, with respect to the single pixel camera architecture are discussed. The performance of the algorithm is verified on airborne sensor images and compared with the state-of-the-art multi-resolution reconstruction algorithms. At the considered sub-sampling rates the RPS is shown to better utilise the system resources for reconstructing the RoIs.
Multi-Task Learning in Utterance-Level and Segmental-Level Spoof Detection
Jul 29, 2021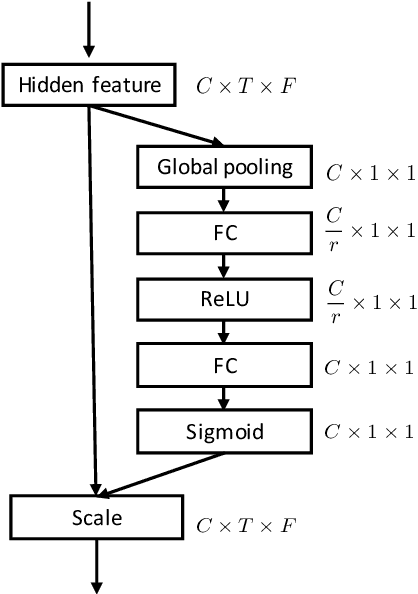
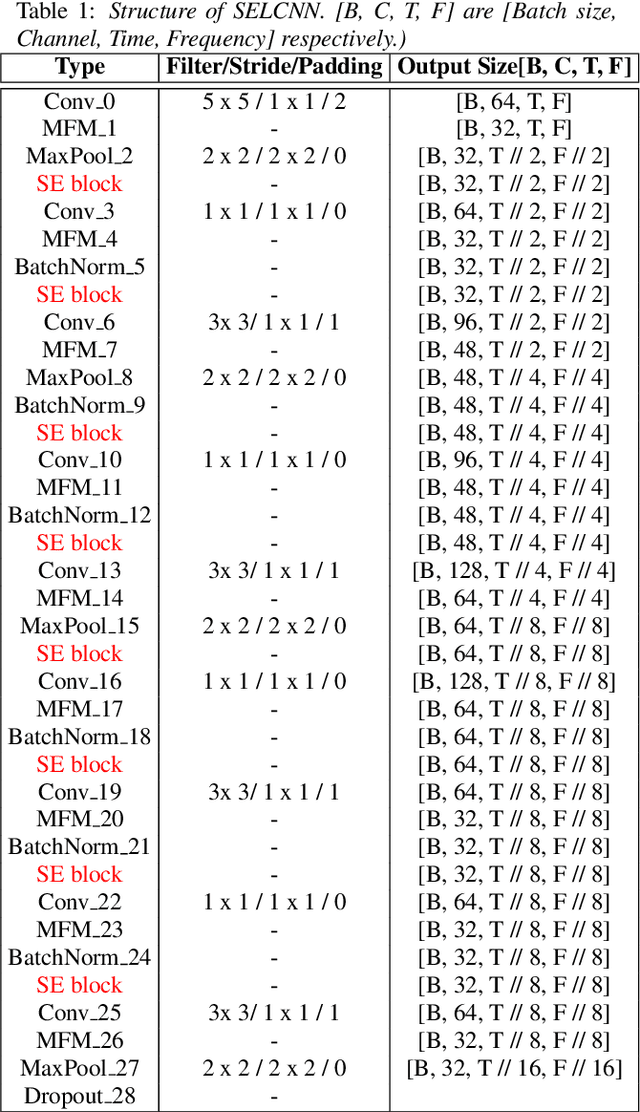

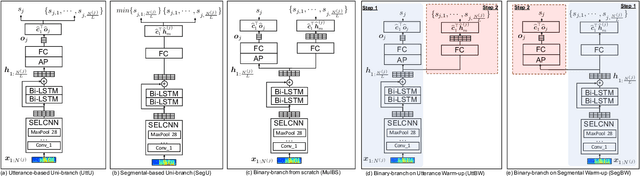
In this paper, we provide a series of multi-tasking benchmarks for simultaneously detecting spoofing at the segmental and utterance levels in the PartialSpoof database. First, we propose the SELCNN network, which inserts squeeze-and-excitation (SE) blocks into a light convolutional neural network (LCNN) to enhance the capacity of hidden feature selection. Then, we implement multi-task learning (MTL) frameworks with SELCNN followed by bidirectional long short-term memory (Bi-LSTM) as the basic model. We discuss MTL in PartialSpoof in terms of architecture (uni-branch/multi-branch) and training strategies (from-scratch/warm-up) step-by-step. Experiments show that the multi-task model performs better than single-task models. Also, in MTL, binary-branch architecture more adequately utilizes information from two levels than a uni-branch model. For the binary-branch architecture, fine-tuning a warm-up model works better than training from scratch. Models can handle both segment-level and utterance-level predictions simultaneously overall under binary-branch multi-task architecture. Furthermore, the multi-task model trained by fine-tuning a segmental warm-up model performs relatively better at both levels except on the evaluation set for segmental detection. Segmental detection should be explored further.
Minimax Regret for Bandit Convex Optimisation of Ridge Functions
Jun 06, 2021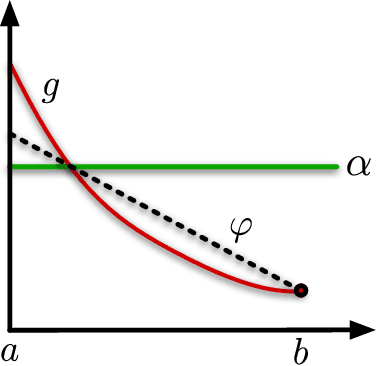
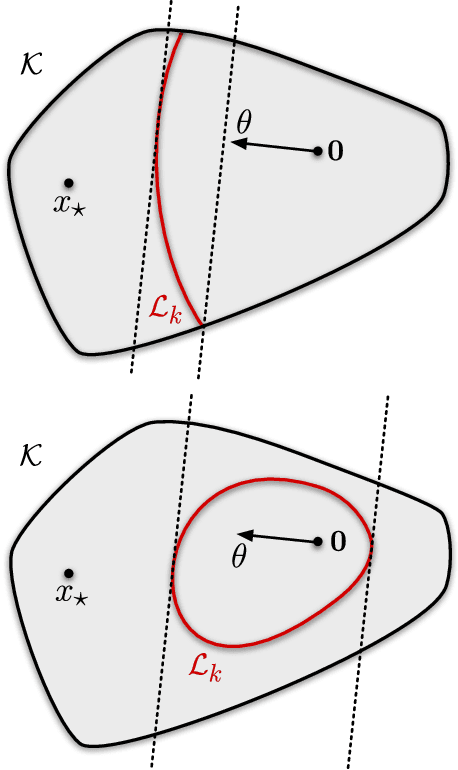
We analyse adversarial bandit convex optimisation with an adversary that is restricted to playing functions of the form $f_t(x) = g_t(\langle x, \theta\rangle)$ for convex $g_t : \mathbb R \to \mathbb R$ and unknown $\theta \in \mathbb R^d$ that is homogeneous over time. We provide a short information-theoretic proof that the minimax regret is at most $O(d \sqrt{n} \log(n \operatorname{diam}(\mathcal K)))$ where $n$ is the number of interactions, $d$ the dimension and $\operatorname{diam}(\mathcal K)$ is the diameter of the constraint set.
Neural Natural Language Processing for Unstructured Data in Electronic Health Records: a Review
Jul 07, 2021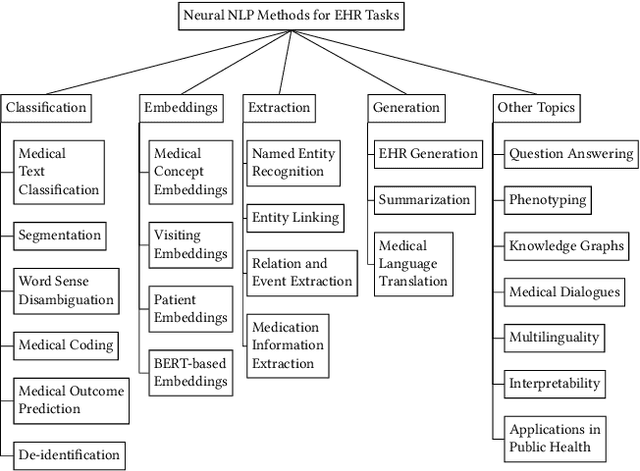

Electronic health records (EHRs), digital collections of patient healthcare events and observations, are ubiquitous in medicine and critical to healthcare delivery, operations, and research. Despite this central role, EHRs are notoriously difficult to process automatically. Well over half of the information stored within EHRs is in the form of unstructured text (e.g. provider notes, operation reports) and remains largely untapped for secondary use. Recently, however, newer neural network and deep learning approaches to Natural Language Processing (NLP) have made considerable advances, outperforming traditional statistical and rule-based systems on a variety of tasks. In this survey paper, we summarize current neural NLP methods for EHR applications. We focus on a broad scope of tasks, namely, classification and prediction, word embeddings, extraction, generation, and other topics such as question answering, phenotyping, knowledge graphs, medical dialogue, multilinguality, interpretability, etc.
A local approach to parameter space reduction for regression and classification tasks
Jul 22, 2021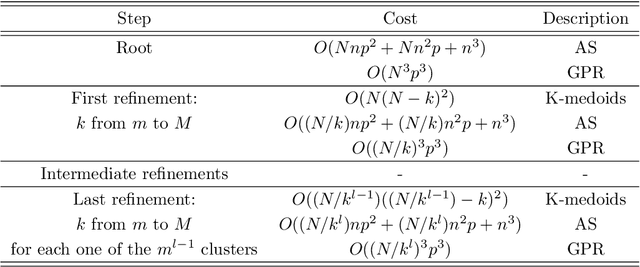
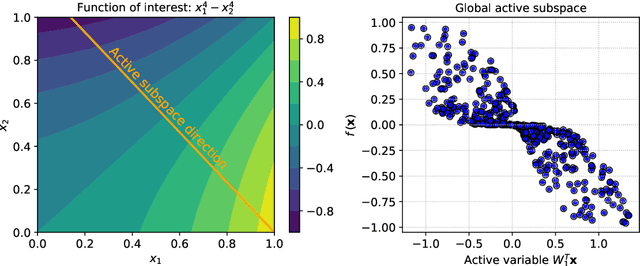
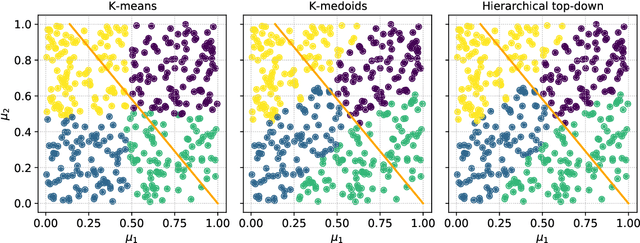
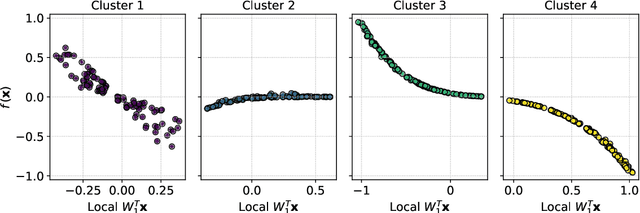
Frequently, the parameter space, chosen for shape design or other applications that involve the definition of a surrogate model, present subdomains where the objective function of interest is highly regular or well behaved. So, it could be approximated more accurately if restricted to those subdomains and studied separately. The drawback of this approach is the possible scarcity of data in some applications, but in those, where a quantity of data, moderately abundant considering the parameter space dimension and the complexity of the objective function, is available, partitioned or local studies are beneficial. In this work we propose a new method called local active subspaces (LAS), which explores the synergies of active subspaces with supervised clustering techniques in order to perform a more efficient dimension reduction in the parameter space for the design of accurate response surfaces. We also developed a procedure to exploit the local active subspace information for classification tasks. Using this technique as a preprocessing step onto the parameter space, or output space in case of vectorial outputs, brings remarkable results for the purpose of surrogate modelling.
CancerBERT: a BERT model for Extracting Breast Cancer Phenotypes from Electronic Health Records
Aug 25, 2021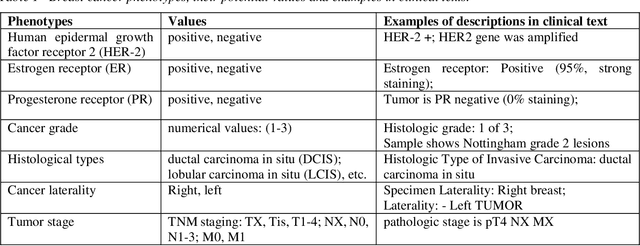

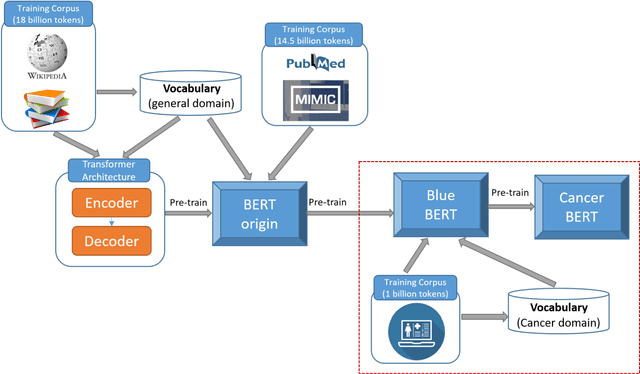
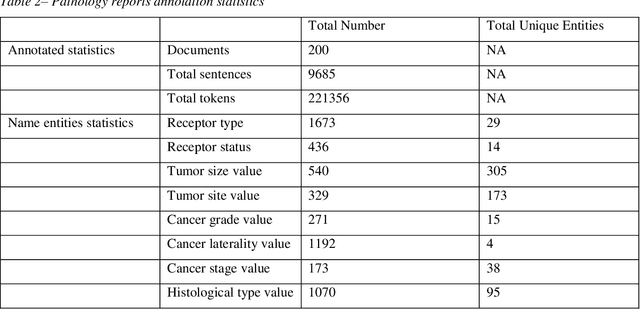
Accurate extraction of breast cancer patients' phenotypes is important for clinical decision support and clinical research. Current models do not take full advantage of cancer domain-specific corpus, whether pre-training Bidirectional Encoder Representations from Transformer model on cancer-specific corpus could improve the performances of extracting breast cancer phenotypes from texts data remains to be explored. The objective of this study is to develop and evaluate the CancerBERT model for extracting breast cancer phenotypes from clinical texts in electronic health records. This data used in the study included 21,291 breast cancer patients diagnosed from 2010 to 2020, patients' clinical notes and pathology reports were collected from the University of Minnesota Clinical Data Repository (UMN). Results: About 3 million clinical notes and pathology reports in electronic health records for 21,291 breast cancer patients were collected to train the CancerBERT model. 200 pathology reports and 50 clinical notes of breast cancer patients that contain 9,685 sentences and 221,356 tokens were manually annotated by two annotators. 20% of the annotated data was used as a test set. Our CancerBERT model achieved the best performance with macro F1 scores equal to 0.876 (95% CI, 0.896-0.902) for exact match and 0.904 (95% CI, 0.896-0.902) for the lenient match. The NER models we developed would facilitate the automated information extraction from clinical texts to further help clinical decision support. Conclusions and Relevance: In this study, we focused on the breast cancer-related concepts extraction from EHR data and obtained a comprehensive annotated dataset that contains 7 types of breast cancer-related concepts. The CancerBERT model with customized vocabulary could significantly improve the performance for extracting breast cancer phenotypes from clinical texts.
Federated Learning Versus Classical Machine Learning: A Convergence Comparison
Jul 22, 2021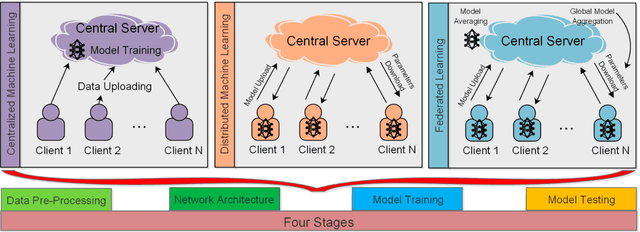
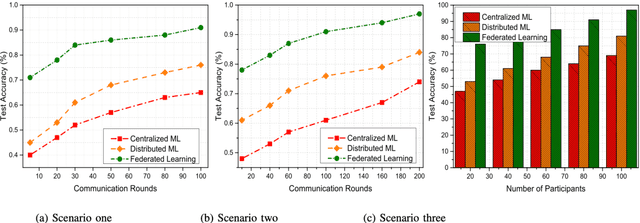
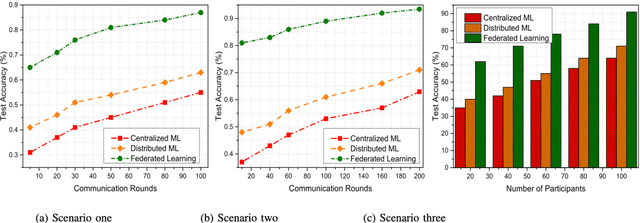
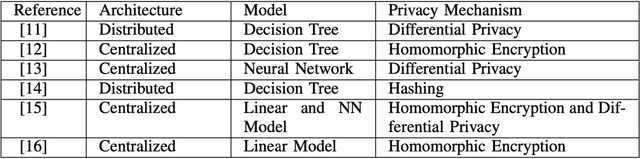
In the past few decades, machine learning has revolutionized data processing for large scale applications. Simultaneously, increasing privacy threats in trending applications led to the redesign of classical data training models. In particular, classical machine learning involves centralized data training, where the data is gathered, and the entire training process executes at the central server. Despite significant convergence, this training involves several privacy threats on participants' data when shared with the central cloud server. To this end, federated learning has achieved significant importance over distributed data training. In particular, the federated learning allows participants to collaboratively train the local models on local data without revealing their sensitive information to the central cloud server. In this paper, we perform a convergence comparison between classical machine learning and federated learning on two publicly available datasets, namely, logistic-regression-MNIST dataset and image-classification-CIFAR-10 dataset. The simulation results demonstrate that federated learning achieves higher convergence within limited communication rounds while maintaining participants' anonymity. We hope that this research will show the benefits and help federated learning to be implemented widely.
Going Full-TILT Boogie on Document Understanding with Text-Image-Layout Transformer
Mar 02, 2021We address the challenging problem of Natural Language Comprehension beyond plain-text documents by introducing the TILT neural network architecture which simultaneously learns layout information, visual features, and textual semantics. Contrary to previous approaches, we rely on a decoder capable of unifying a variety of problems involving natural language. The layout is represented as an attention bias and complemented with contextualized visual information, while the core of our model is a pretrained encoder-decoder Transformer. Our novel approach achieves state-of-the-art results in extracting information from documents and answering questions which demand layout understanding (DocVQA, CORD, WikiOps, SROIE). At the same time, we simplify the process by employing an end-to-end model.
Predicting Twitter User Socioeconomic Attributes with Network and Language Information
Apr 11, 2018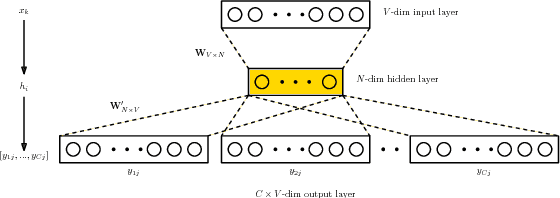
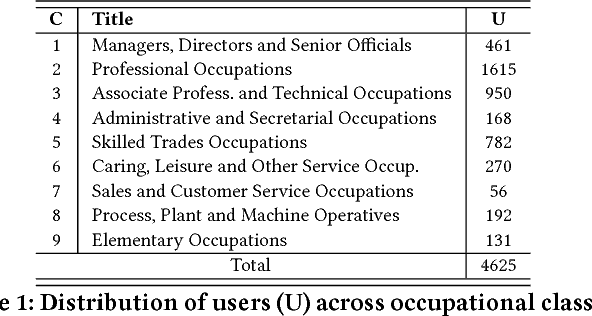
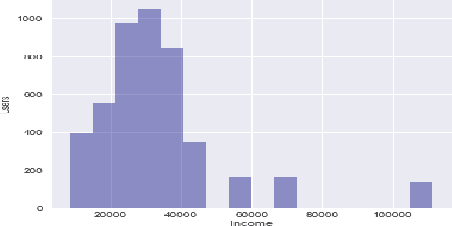
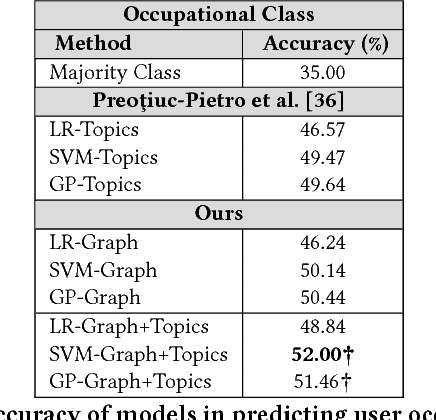
Inferring socioeconomic attributes of social media users such as occupation and income is an important problem in computational social science. Automated inference of such characteristics has applications in personalised recommender systems, targeted computational advertising and online political campaigning. While previous work has shown that language features can reliably predict socioeconomic attributes on Twitter, employing information coming from users' social networks has not yet been explored for such complex user characteristics. In this paper, we describe a method for predicting the occupational class and the income of Twitter users given information extracted from their extended networks by learning a low-dimensional vector representation of users, i.e. graph embeddings. We use this representation to train predictive models for occupational class and income. Results on two publicly available datasets show that our method consistently outperforms the state-of-the-art methods in both tasks. We also obtain further significant improvements when we combine graph embeddings with textual features, demonstrating that social network and language information are complementary.
Breaking the Limit of Graph Neural Networks by Improving the Assortativity of Graphs with Local Mixing Patterns
Jun 11, 2021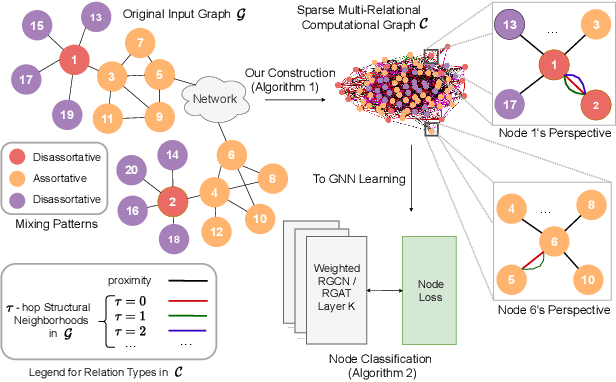
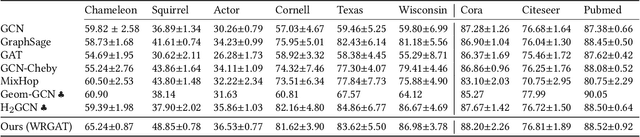
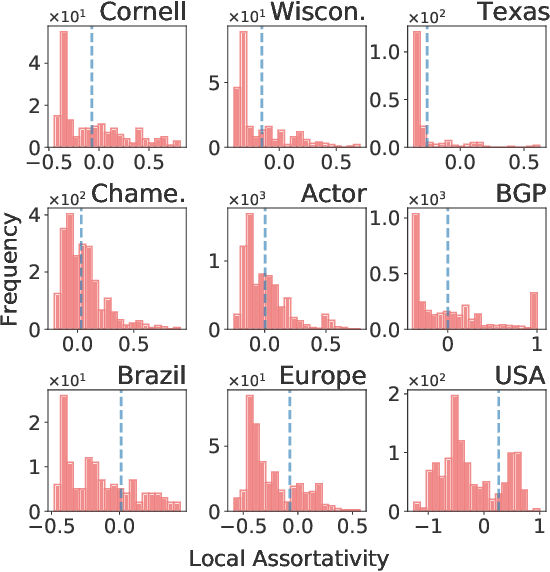
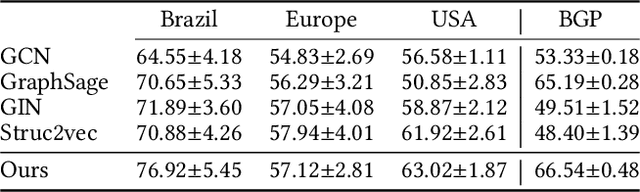
Graph neural networks (GNNs) have achieved tremendous success on multiple graph-based learning tasks by fusing network structure and node features. Modern GNN models are built upon iterative aggregation of neighbor's/proximity features by message passing. Its prediction performance has been shown to be strongly bounded by assortative mixing in the graph, a key property wherein nodes with similar attributes mix/connect with each other. We observe that real world networks exhibit heterogeneous or diverse mixing patterns and the conventional global measurement of assortativity, such as global assortativity coefficient, may not be a representative statistic in quantifying this mixing. We adopt a generalized concept, node-level assortativity, one that is based at the node level to better represent the diverse patterns and accurately quantify the learnability of GNNs. We find that the prediction performance of a wide range of GNN models is highly correlated with the node level assortativity. To break this limit, in this work, we focus on transforming the input graph into a computation graph which contains both proximity and structural information as distinct type of edges. The resulted multi-relational graph has an enhanced level of assortativity and, more importantly, preserves rich information from the original graph. We then propose to run GNNs on this computation graph and show that adaptively choosing between structure and proximity leads to improved performance under diverse mixing. Empirically, we show the benefits of adopting our transformation framework for semi-supervised node classification task on a variety of real world graph learning benchmarks.