 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
The Benchmark Lottery
Jul 14, 2021
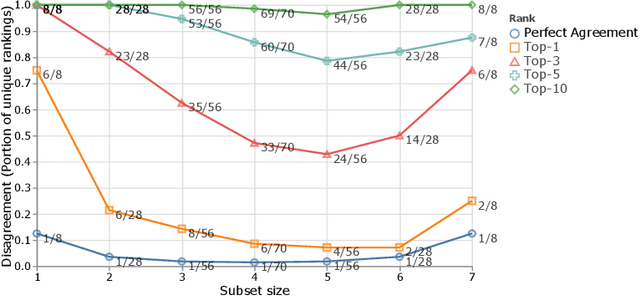

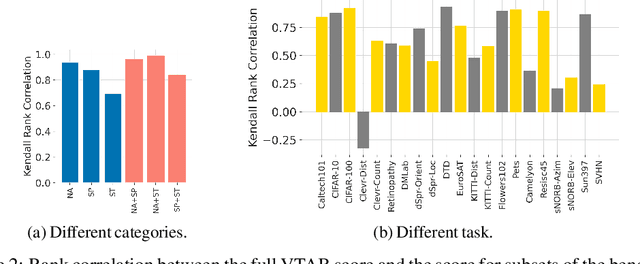
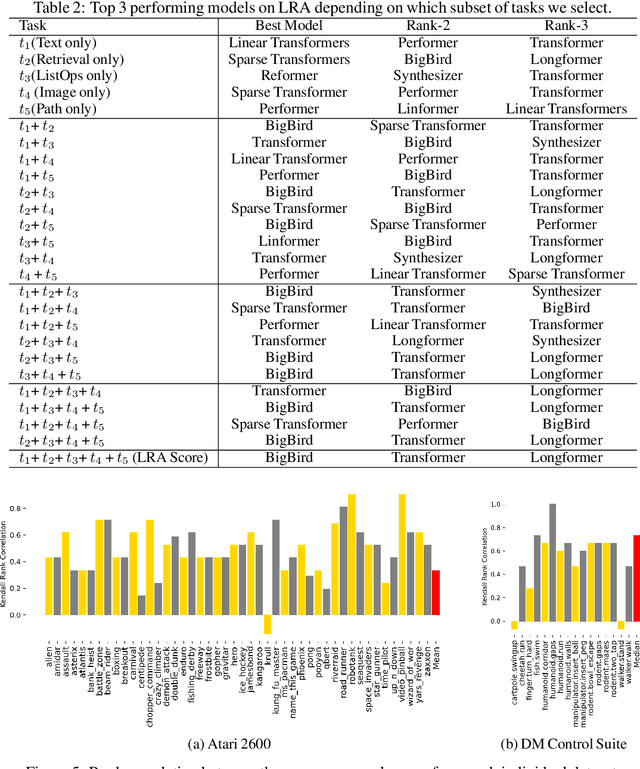
The world of empirical machine learning (ML) strongly relies on benchmarks in order to determine the relative effectiveness of different algorithms and methods. This paper proposes the notion of "a benchmark lottery" that describes the overall fragility of the ML benchmarking process. The benchmark lottery postulates that many factors, other than fundamental algorithmic superiority, may lead to a method being perceived as superior. On multiple benchmark setups that are prevalent in the ML community, we show that the relative performance of algorithms may be altered significantly simply by choosing different benchmark tasks, highlighting the fragility of the current paradigms and potential fallacious interpretation derived from benchmarking ML methods. Given that every benchmark makes a statement about what it perceives to be important, we argue that this might lead to biased progress in the community. We discuss the implications of the observed phenomena and provide recommendations on mitigating them using multiple machine learning domains and communities as use cases, including natural language processing, computer vision, information retrieval, recommender systems, and reinforcement learning.
Global Aggregation then Local Distribution for Scene Parsing
Jul 28, 2021
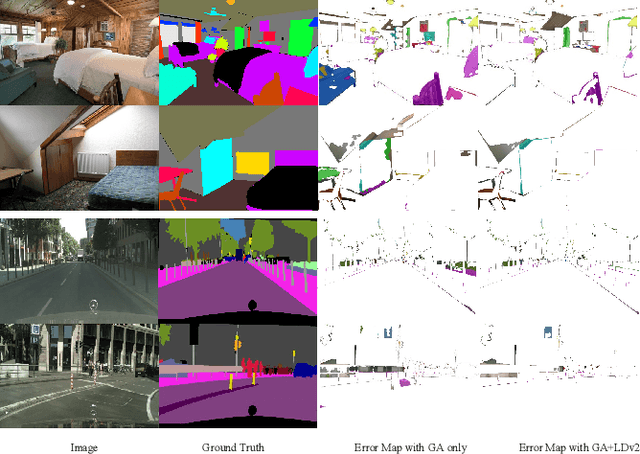

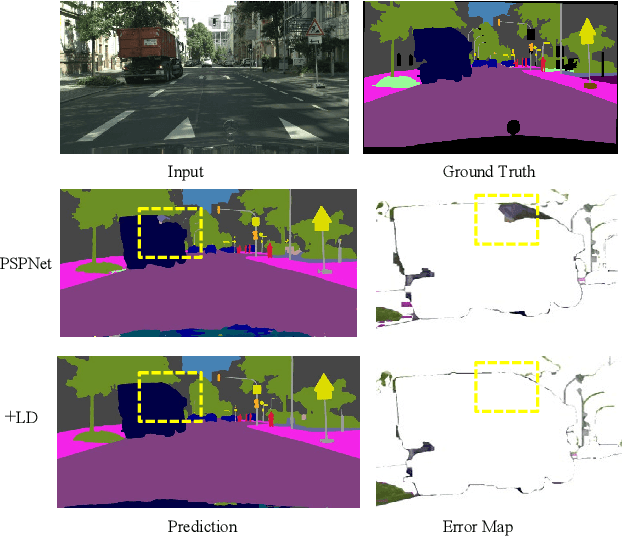
Modelling long-range contextual relationships is critical for pixel-wise prediction tasks such as semantic segmentation. However, convolutional neural networks (CNNs) are inherently limited to model such dependencies due to the naive structure in its building modules (\eg, local convolution kernel). While recent global aggregation methods are beneficial for long-range structure information modelling, they would oversmooth and bring noise to the regions containing fine details (\eg,~boundaries and small objects), which are very much cared for the semantic segmentation task. To alleviate this problem, we propose to explore the local context for making the aggregated long-range relationship being distributed more accurately in local regions. In particular, we design a novel local distribution module which models the affinity map between global and local relationship for each pixel adaptively. Integrating existing global aggregation modules, we show that our approach can be modularized as an end-to-end trainable block and easily plugged into existing semantic segmentation networks, giving rise to the \emph{GALD} networks. Despite its simplicity and versatility, our approach allows us to build new state of the art on major semantic segmentation benchmarks including Cityscapes, ADE20K, Pascal Context, Camvid and COCO-stuff. Code and trained models are released at \url{https://github.com/lxtGH/GALD-DGCNet} to foster further research.
Self-Supervised Learning of Event-Based Optical Flow with Spiking Neural Networks
Jun 03, 2021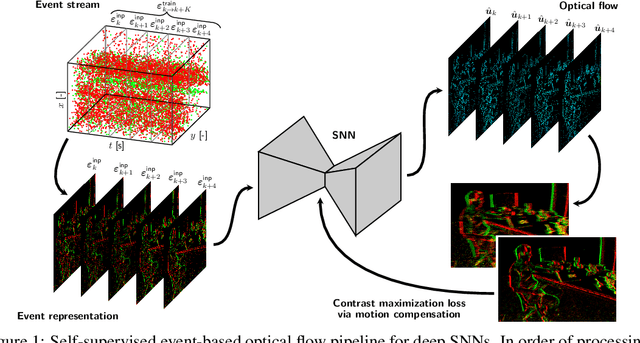
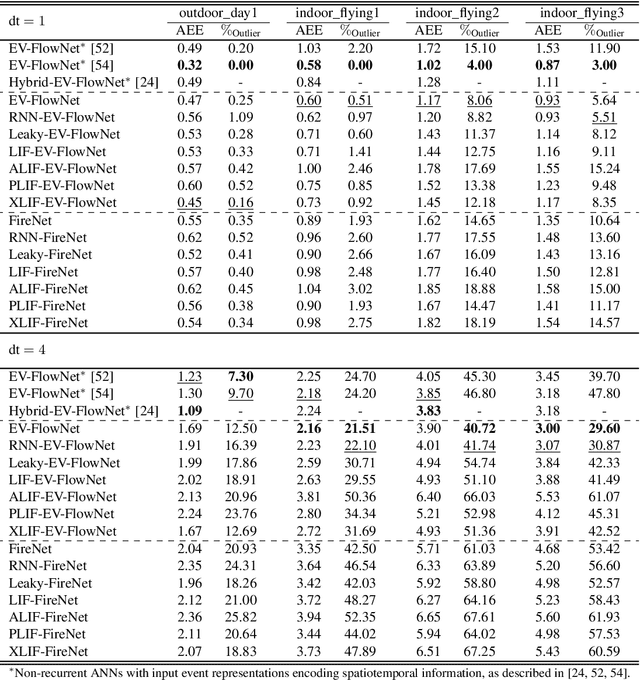
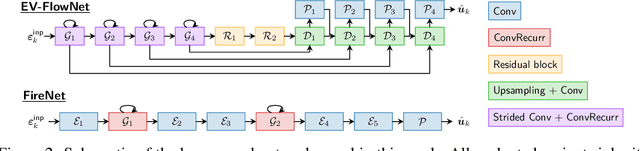

Neuromorphic sensing and computing hold a promise for highly energy-efficient and high-bandwidth-sensor processing. A major challenge for neuromorphic computing is that learning algorithms for traditional artificial neural networks (ANNs) do not transfer directly to spiking neural networks (SNNs) due to the discrete spikes and more complex neuronal dynamics. As a consequence, SNNs have not yet been successfully applied to complex, large-scale tasks. In this article, we focus on the self-supervised learning problem of optical flow estimation from event-based camera inputs, and investigate the changes that are necessary to the state-of-the-art ANN training pipeline in order to successfully tackle it with SNNs. More specifically, we first modify the input event representation to encode a much smaller time slice with minimal explicit temporal information. Consequently, we make the network's neuronal dynamics and recurrent connections responsible for integrating information over time. Moreover, we reformulate the self-supervised loss function for event-based optical flow to improve its convexity. We perform experiments with various types of recurrent ANNs and SNNs using the proposed pipeline. Concerning SNNs, we investigate the effects of elements such as parameter initialization and optimization, surrogate gradient shape, and adaptive neuronal mechanisms. We find that initialization and surrogate gradient width play a crucial part in enabling learning with sparse inputs, while the inclusion of adaptivity and learnable neuronal parameters can improve performance. We show that the performance of the proposed ANNs and SNNs are on par with that of the current state-of-the-art ANNs trained in a self-supervised manner.
Increasing Faithfulness in Knowledge-Grounded Dialogue with Controllable Features
Jul 14, 2021
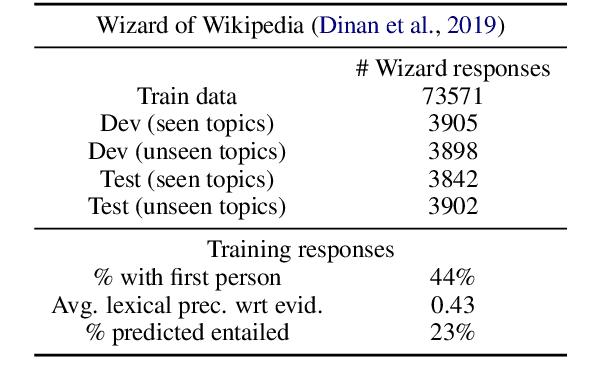
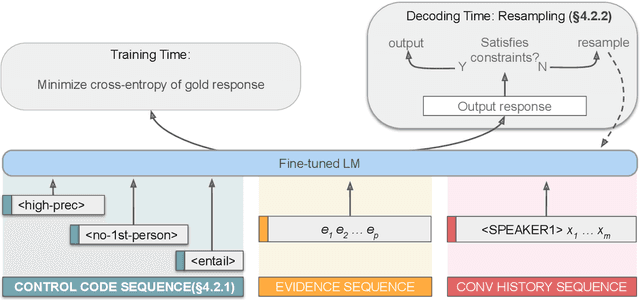
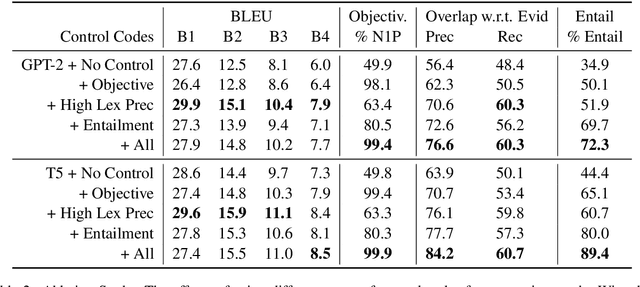
Knowledge-grounded dialogue systems are intended to convey information that is based on evidence provided in a given source text. We discuss the challenges of training a generative neural dialogue model for such systems that is controlled to stay faithful to the evidence. Existing datasets contain a mix of conversational responses that are faithful to selected evidence as well as more subjective or chit-chat style responses. We propose different evaluation measures to disentangle these different styles of responses by quantifying the informativeness and objectivity. At training time, additional inputs based on these evaluation measures are given to the dialogue model. At generation time, these additional inputs act as stylistic controls that encourage the model to generate responses that are faithful to the provided evidence. We also investigate the usage of additional controls at decoding time using resampling techniques. In addition to automatic metrics, we perform a human evaluation study where raters judge the output of these controlled generation models to be generally more objective and faithful to the evidence compared to baseline dialogue systems.
Hierarchical Representations and Explicit Memory: Learning Effective Navigation Policies on 3D Scene Graphs using Graph Neural Networks
Aug 02, 2021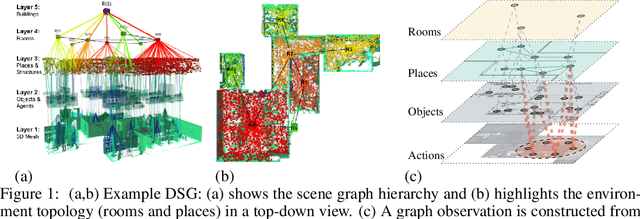
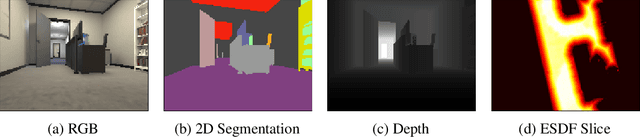
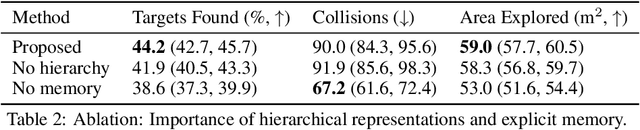
Representations are crucial for a robot to learn effective navigation policies. Recent work has shown that mid-level perceptual abstractions, such as depth estimates or 2D semantic segmentation, lead to more effective policies when provided as observations in place of raw sensor data (e.g., RGB images). However, such policies must still learn latent three-dimensional scene properties from mid-level abstractions. In contrast, high-level, hierarchical representations such as 3D scene graphs explicitly provide a scene's geometry, topology, and semantics, making them compelling representations for navigation. In this work, we present a reinforcement learning framework that leverages high-level hierarchical representations to learn navigation policies. Towards this goal, we propose a graph neural network architecture and show how to embed a 3D scene graph into an agent-centric feature space, which enables the robot to learn policies for low-level action in an end-to-end manner. For each node in the scene graph, our method uses features that capture occupancy and semantic content, while explicitly retaining memory of the robot trajectory. We demonstrate the effectiveness of our method against commonly used visuomotor policies in a challenging object search task. These experiments and supporting ablation studies show that our method leads to more effective object search behaviors, exhibits improved long-term memory, and successfully leverages hierarchical information to guide its navigation objectives.
Analysis of the robustness of NMF algorithms
Jun 04, 2021
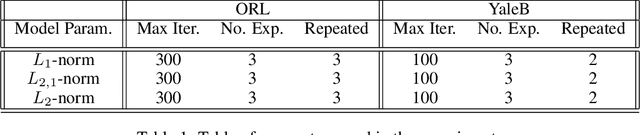

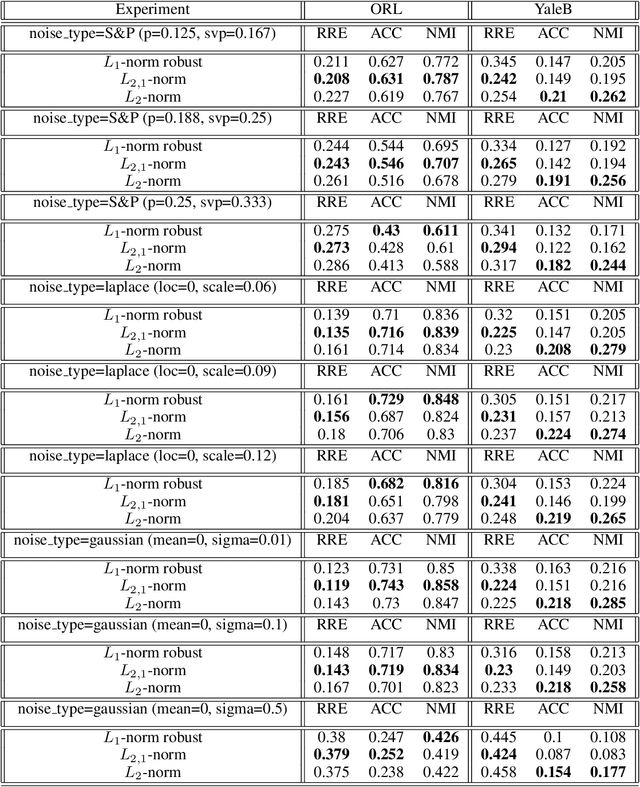
We examine three non-negative matrix factorization techniques; L2-norm, L1-norm, and L2,1-norm. Our aim is to establish the performance of these different approaches, and their robustness in real-world applications such as feature selection while managing computational complexity, sensitivity to noise and more. We thoroughly examine each approach from a theoretical perspective, and examine the performance of each using a series of experiments drawing on both the ORL and YaleB datasets. We examine the Relative Reconstruction Errors (RRE), Average Accuracy and Normalized Mutual Information (NMI) as criteria under a range of simulated noise scenarios.
A Missing Information Loss function for implicit feedback datasets
Aug 16, 2018
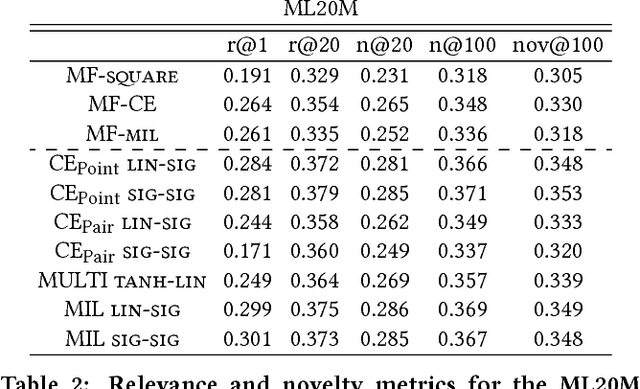
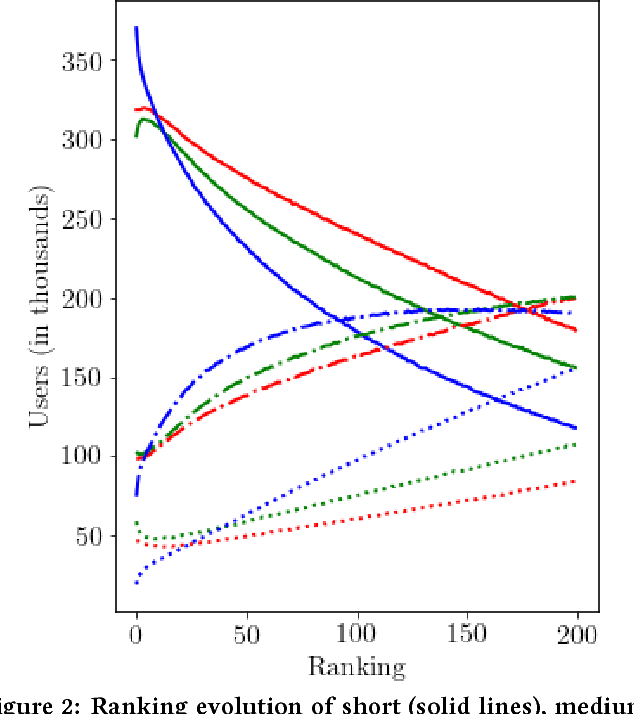
Latent factor models for Recommender Systems with implicit feedback typically treat unobserved user-item interactions (i.e. missing information) as negative feedback. This is frequently done either through negative sampling (point--wise loss) or with a ranking loss function (pair-- or list--wise estimation). Since a zero preference recommendation is a valid solution for most common objective functions, regarding unknown values as actual zeros results in users having a zero preference recommendation for most of the available items. In this paper we propose a novel objective function, the \emph{Missing Information Loss} (MIL), that explicitly forbids treating unobserved user-item interactions as positive or negative feedback. We apply this loss to both traditional Matrix Factorization and user--based Denoising Autoencoder, and compare it with other established objective functions such as cross-entropy (both point- and pair-wise) or the recently proposed multinomial log-likelihood. MIL achieves competitive performance in ranking-aware metrics when applied to three datasets. Furthermore, we show that such a relevance in the recommendation is obtained while displaying popular items less frequently (up to a $20 \%$ decrease with respect to the best competing method). This debiasing from the recommendation of popular items favours the appearance of infrequent items (up to a $50 \%$ increase of long-tail recommendations), a valuable feature for Recommender Systems with a large catalogue of products.
Next Generation Reservoir Computing
Jun 14, 2021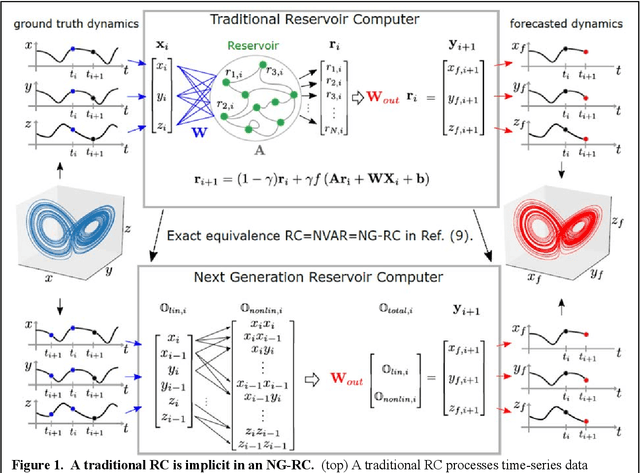
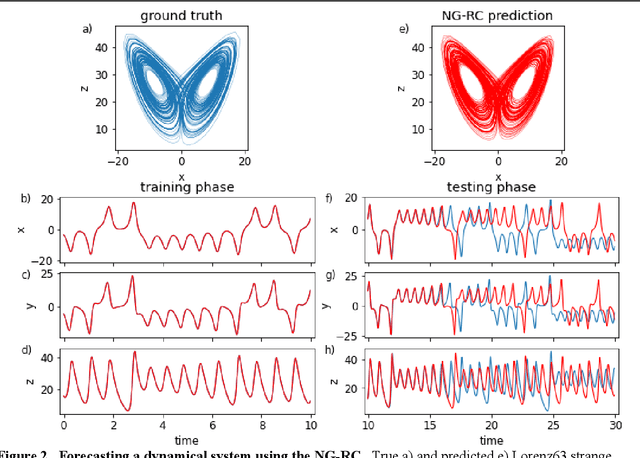
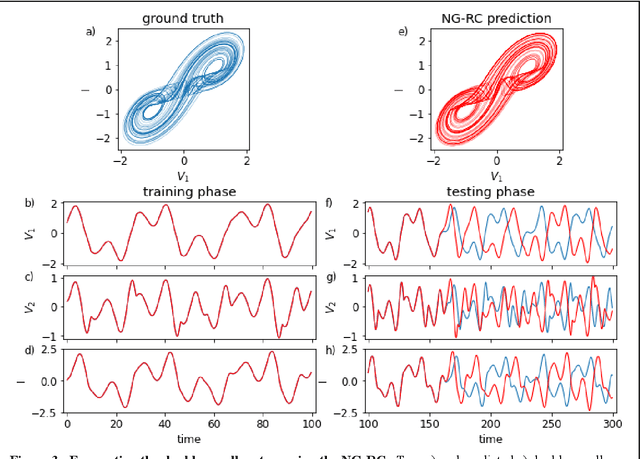
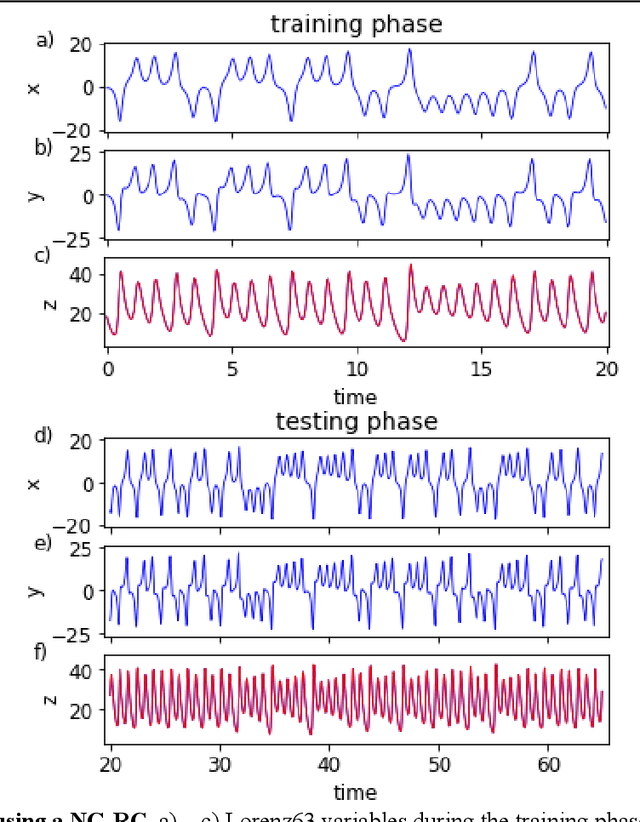
Reservoir computing is a best-in-class machine learning algorithm for processing information generated by dynamical systems using observed time-series data. Importantly, it requires very small training data sets, uses linear optimization, and thus requires minimal computing resources. However, the algorithm uses randomly sampled matrices to define the underlying recurrent neural network and has a multitude of metaparameters that must be optimized. Recent results demonstrate the equivalence of reservoir computing to nonlinear vector autoregression, which requires no random matrices, fewer metaparameters, and provides interpretable results. Here, we demonstrate that nonlinear vector autoregression excels at reservoir computing benchmark tasks and requires even shorter training data sets and training time, heralding the next generation of reservoir computing.
VisualBackProp for learning using privileged information with CNNs
May 24, 2018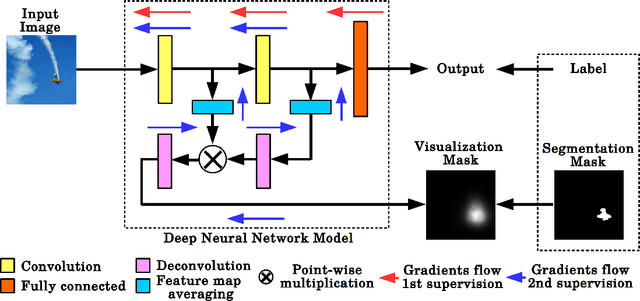
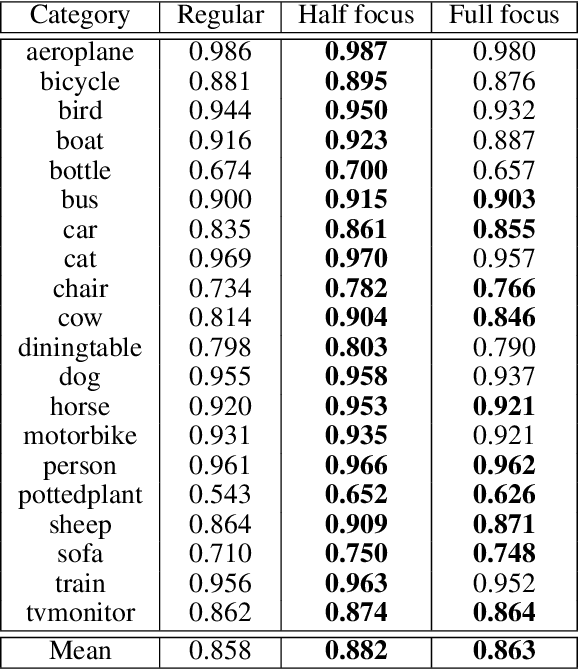

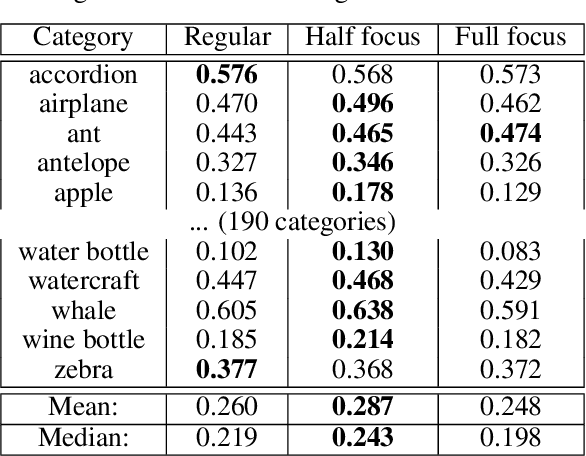
In many machine learning applications, from medical diagnostics to autonomous driving, the availability of prior knowledge can be used to improve the predictive performance of learning algorithms and incorporate `physical,' `domain knowledge,' or `common sense' concepts into training of machine learning systems as well as verify constraints/properties of the systems. We explore the learning using privileged information paradigm and show how to incorporate the privileged information, such as segmentation mask available along with the classification label of each example, into the training stage of convolutional neural networks. This is done by augmenting the CNN model with an architectural component that effectively focuses model's attention on the desired region of the input image during the training process and that is transparent to the network's label prediction mechanism at testing. This component effectively corresponds to the visualization strategy for identifying the parts of the input, often referred to as visualization mask, that most contribute to the prediction, yet uses this strategy in reverse to the classical setting in order to enforce the desired visualization mask instead. We verify our proposed algorithms through exhaustive experiments on benchmark ImageNet and PASCAL VOC data sets and achieve improvements in the performance of $2.4\%$ and $2.7\%$ over standard single-supervision model training. Finally, we confirm the effectiveness of our approach on skin lesion classification problem.
Few Shots Is All You Need: A Progressive Few Shot Learning Approach for Low Resource Handwriting Recognition
Jul 21, 2021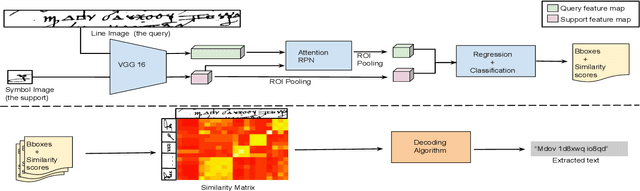
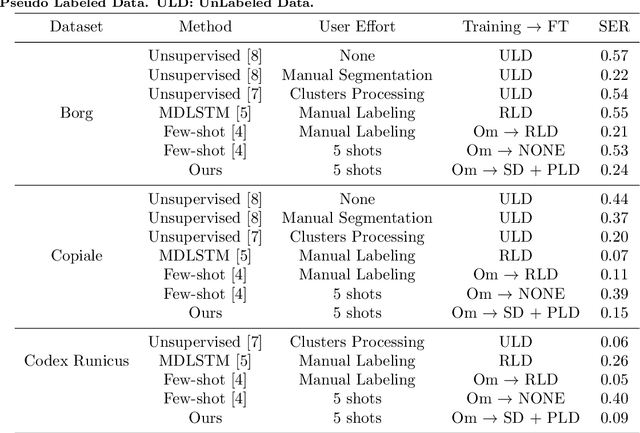
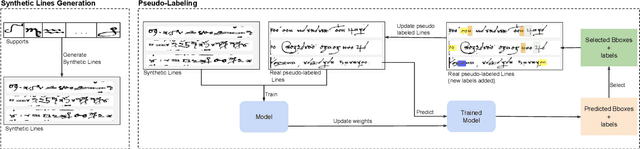
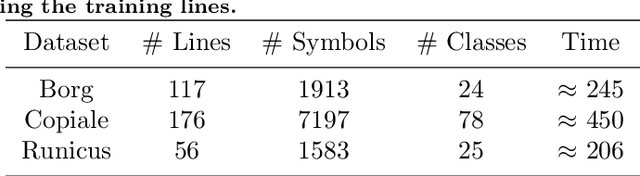
Handwritten text recognition in low resource scenarios, such as manuscripts with rare alphabets, is a challenging problem. The main difficulty comes from the very few annotated data and the limited linguistic information (e.g. dictionaries and language models). Thus, we propose a few-shot learning-based handwriting recognition approach that significantly reduces the human labor annotation process, requiring only few images of each alphabet symbol. First, our model detects all symbols of a given alphabet in a textline image, then a decoding step maps the symbol similarity scores to the final sequence of transcribed symbols. Our model is first pretrained on synthetic line images generated from any alphabet, even though different from the target domain. A second training step is then applied to diminish the gap between the source and target data. Since this retraining would require annotation of thousands of handwritten symbols together with their bounding boxes, we propose to avoid such human effort through an unsupervised progressive learning approach that automatically assigns pseudo-labels to the non-annotated data. The evaluation on different manuscript datasets show that our model can lead to competitive results with a significant reduction in human effort.