 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Determining the Credibility of Science Communication
May 30, 2021


Most work on scholarly document processing assumes that the information processed is trustworthy and factually correct. However, this is not always the case. There are two core challenges, which should be addressed: 1) ensuring that scientific publications are credible -- e.g. that claims are not made without supporting evidence, and that all relevant supporting evidence is provided; and 2) that scientific findings are not misrepresented, distorted or outright misreported when communicated by journalists or the general public. I will present some first steps towards addressing these problems and outline remaining challenges.
Long Short-Term Transformer for Online Action Detection
Jul 07, 2021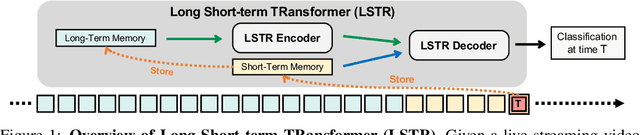
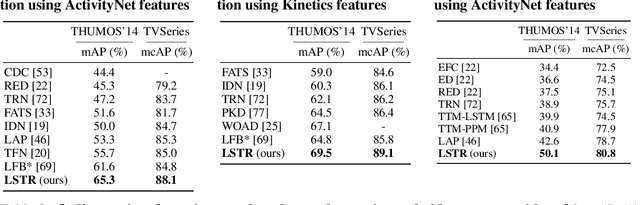
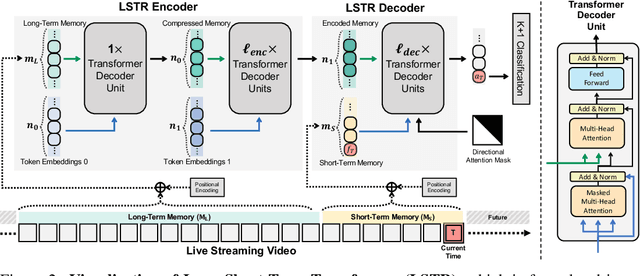
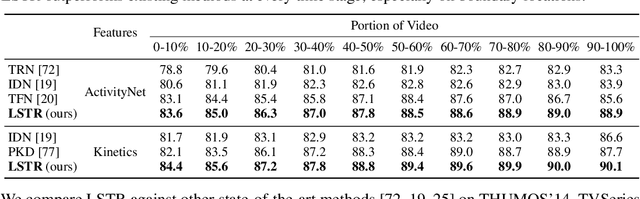
In this paper, we present Long Short-term TRansformer (LSTR), a new temporal modeling algorithm for online action detection, by employing a long- and short-term memories mechanism that is able to model prolonged sequence data. It consists of an LSTR encoder that is capable of dynamically exploiting coarse-scale historical information from an extensively long time window (e.g., 2048 long-range frames of up to 8 minutes), together with an LSTR decoder that focuses on a short time window (e.g., 32 short-range frames of 8 seconds) to model the fine-scale characterization of the ongoing event. Compared to prior work, LSTR provides an effective and efficient method to model long videos with less heuristic algorithm design. LSTR achieves significantly improved results on standard online action detection benchmarks, THUMOS'14, TVSeries, and HACS Segment, over the existing state-of-the-art approaches. Extensive empirical analysis validates the setup of the long- and short-term memories and the design choices of LSTR.
Neural Graph Matching based Collaborative Filtering
May 10, 2021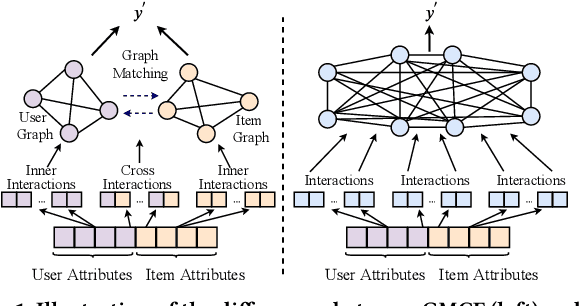
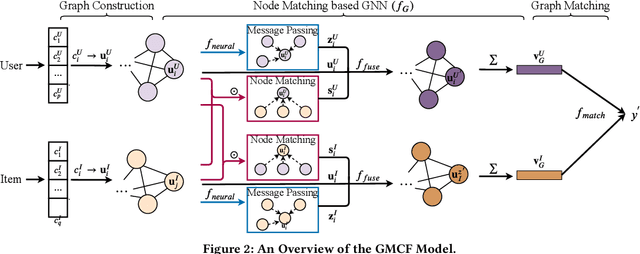
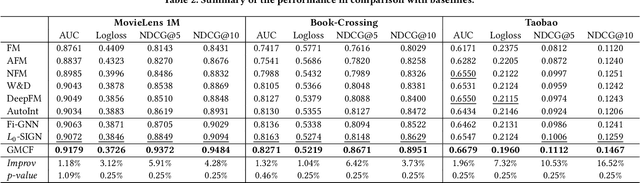
User and item attributes are essential side-information; their interactions (i.e., their co-occurrence in the sample data) can significantly enhance prediction accuracy in various recommender systems. We identify two different types of attribute interactions, inner interactions and cross interactions: inner interactions are those between only user attributes or those between only item attributes; cross interactions are those between user attributes and item attributes. Existing models do not distinguish these two types of attribute interactions, which may not be the most effective way to exploit the information carried by the interactions. To address this drawback, we propose a neural Graph Matching based Collaborative Filtering model (GMCF), which effectively captures the two types of attribute interactions through modeling and aggregating attribute interactions in a graph matching structure for recommendation. In our model, the two essential recommendation procedures, characteristic learning and preference matching, are explicitly conducted through graph learning (based on inner interactions) and node matching (based on cross interactions), respectively. Experimental results show that our model outperforms state-of-the-art models. Further studies verify the effectiveness of GMCF in improving the accuracy of recommendation.
GBLinks: GNN-Based Beam Selection and Link Activation for Ultra-dense D2D mmWave Networks
Jul 28, 2021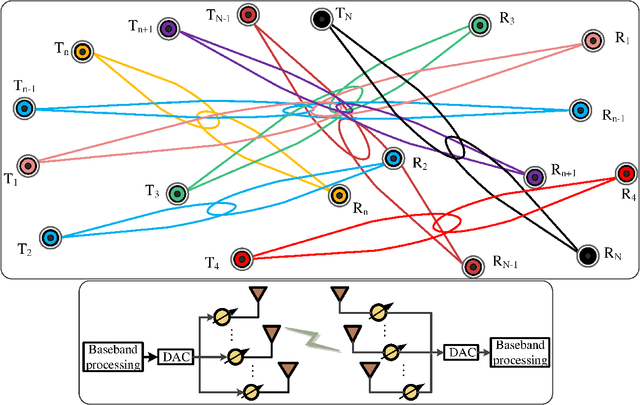
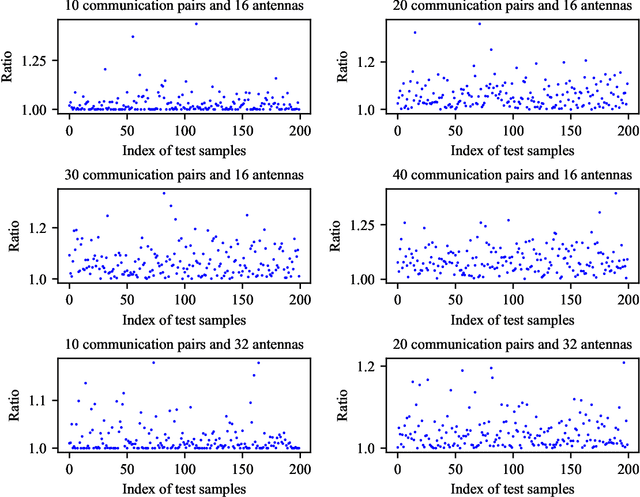
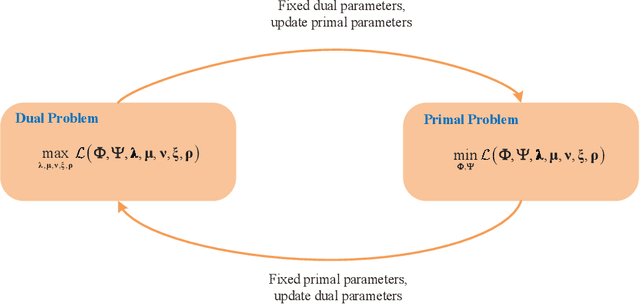
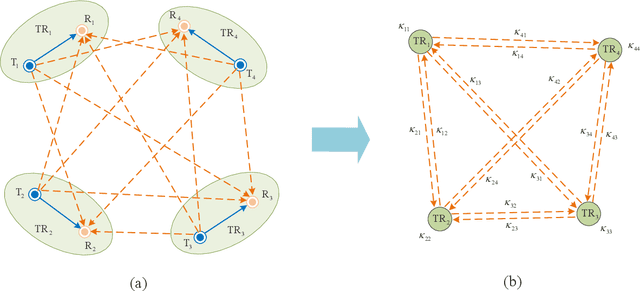
In this paper, we consider the problem of joint beam selection and link activation across a set of communication pairs to effectively control the interference between communication pairs via inactivating part communication pairs in ultra-dense device-to-device (D2D) mmWave communication networks. The resulting optimization problem is formulated as an integer programming problem that is nonconvex and NP-hard problem. Consequently, the global optimal solution, even the local optimal solution, cannot be generally obtained. To overcome this challenge, this paper resorts to design a deep learning architecture based on graph neural network to finish the joint beam selection and link activation, with taking the network topology information into account. Meanwhile, we present an unsupervised Lagrangian dual learning framework to train the parameters of GBLinks model. Numerical results show that the proposed GBLinks model can converges to a stable point with the number of iterations increases, in terms of the sum rate. Furthermore, the GBLinks model can reach near-optimal solution through comparing with the exhaustive search scheme in small-scale ultra-dense D2D mmWave communication networks and outperforms GreedyNoSched and the SCA-based method. It also shows that the GBLinks model can generalize to varying scales and densities of ultra-dense D2D mmWave communication networks.
Analytic Study of Families of Spurious Minima in Two-Layer ReLU Neural Networks
Jul 21, 2021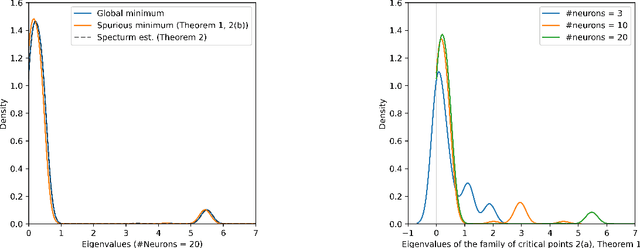

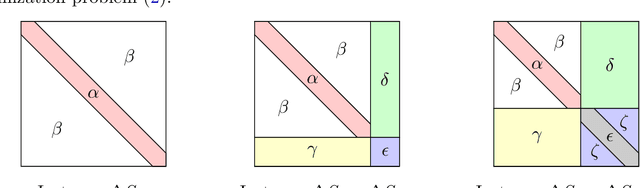
We study the optimization problem associated with fitting two-layer ReLU neural networks with respect to the squared loss, where labels are generated by a target network. We make use of the rich symmetry structure to develop a novel set of tools for studying families of spurious minima. In contrast to existing approaches which operate in limiting regimes, our technique directly addresses the nonconvex loss landscape for a finite number of inputs $d$ and neurons $k$, and provides analytic, rather than heuristic, information. In particular, we derive analytic estimates for the loss at different minima, and prove that modulo $O(d^{-1/2})$-terms the Hessian spectrum concentrates near small positive constants, with the exception of $\Theta(d)$ eigenvalues which grow linearly with~$d$. We further show that the Hessian spectrum at global and spurious minima coincide to $O(d^{-1/2})$-order, thus challenging our ability to argue about statistical generalization through local curvature. Lastly, our technique provides the exact \emph{fractional} dimensionality at which families of critical points turn from saddles into spurious minima. This makes possible the study of the creation and the annihilation of spurious minima using powerful tools from equivariant bifurcation theory.
Large Scale Long-tailed Product Recognition System at Alibaba
Feb 09, 2021

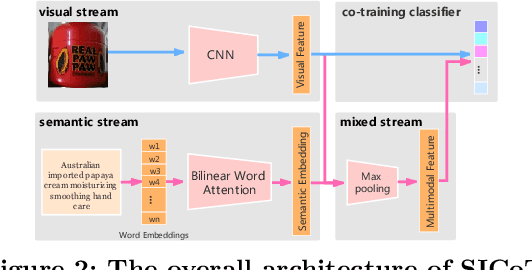
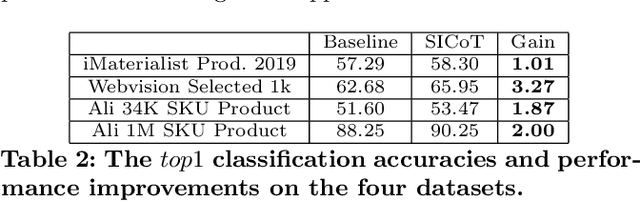
A practical large scale product recognition system suffers from the phenomenon of long-tailed imbalanced training data under the E-commercial circumstance at Alibaba. Besides product images at Alibaba, plenty of image related side information (e.g. title, tags) reveal rich semantic information about images. Prior works mainly focus on addressing the long tail problem in visual perspective only, but lack of consideration of leveraging the side information. In this paper, we present a novel side information based large scale visual recognition co-training~(SICoT) system to deal with the long tail problem by leveraging the image related side information. In the proposed co-training system, we firstly introduce a bilinear word attention module aiming to construct a semantic embedding over the noisy side information. A visual feature and semantic embedding co-training scheme is then designed to transfer knowledge from classes with abundant training data (head classes) to classes with few training data (tail classes) in an end-to-end fashion. Extensive experiments on four challenging large scale datasets, whose numbers of classes range from one thousand to one million, demonstrate the scalable effectiveness of the proposed SICoT system in alleviating the long tail problem. In the visual search platform Pailitao\footnote{http://www.pailitao.com} at Alibaba, we settle a practical large scale product recognition application driven by the proposed SICoT system, and achieve a significant gain of unique visitor~(UV) conversion rate.
* Acccepted by CIKM 2020
Shape Controllable Virtual Try-on for Underwear Models
Jul 28, 2021
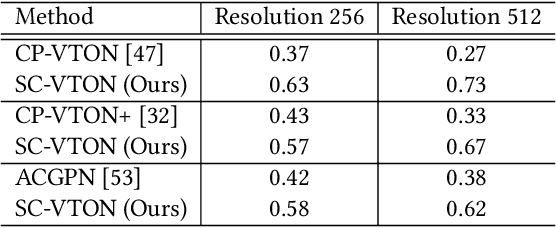
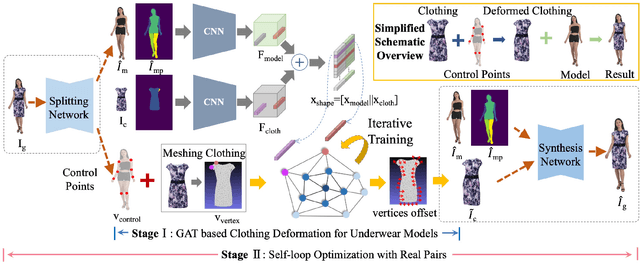
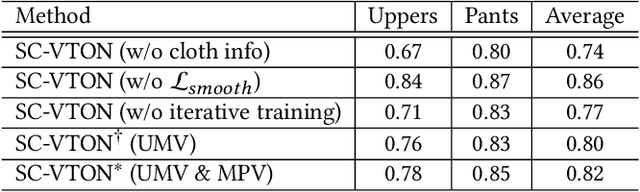
Image virtual try-on task has abundant applications and has become a hot research topic recently. Existing 2D image-based virtual try-on methods aim to transfer a target clothing image onto a reference person, which has two main disadvantages: cannot control the size and length precisely; unable to accurately estimate the user's figure in the case of users wearing thick clothes, resulting in inaccurate dressing effect. In this paper, we put forward an akin task that aims to dress clothing for underwear models. %, which is also an urgent need in e-commerce scenarios. To solve the above drawbacks, we propose a Shape Controllable Virtual Try-On Network (SC-VTON), where a graph attention network integrates the information of model and clothing to generate the warped clothing image. In addition, the control points are incorporated into SC-VTON for the desired clothing shape. Furthermore, by adding a Splitting Network and a Synthesis Network, we can use clothing/model pair data to help optimize the deformation module and generalize the task to the typical virtual try-on task. Extensive experiments show that the proposed method can achieve accurate shape control. Meanwhile, compared with other methods, our method can generate high-resolution results with detailed textures.
Global Aggregation then Local Distribution for Scene Parsing
Jul 28, 2021
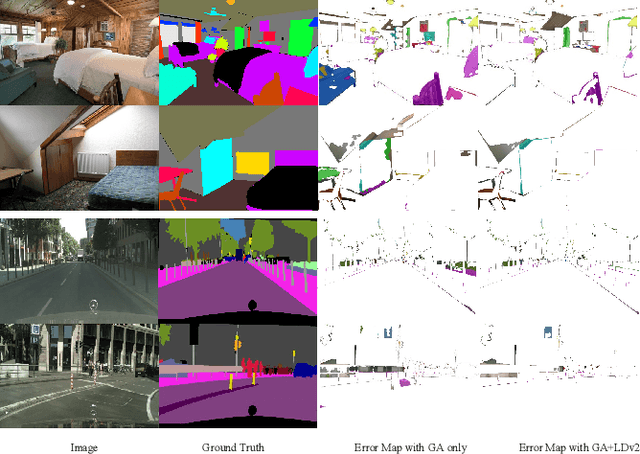

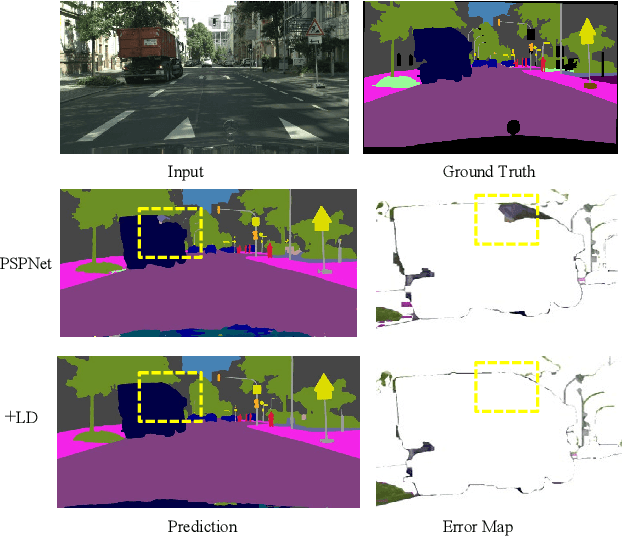
Modelling long-range contextual relationships is critical for pixel-wise prediction tasks such as semantic segmentation. However, convolutional neural networks (CNNs) are inherently limited to model such dependencies due to the naive structure in its building modules (\eg, local convolution kernel). While recent global aggregation methods are beneficial for long-range structure information modelling, they would oversmooth and bring noise to the regions containing fine details (\eg,~boundaries and small objects), which are very much cared for the semantic segmentation task. To alleviate this problem, we propose to explore the local context for making the aggregated long-range relationship being distributed more accurately in local regions. In particular, we design a novel local distribution module which models the affinity map between global and local relationship for each pixel adaptively. Integrating existing global aggregation modules, we show that our approach can be modularized as an end-to-end trainable block and easily plugged into existing semantic segmentation networks, giving rise to the \emph{GALD} networks. Despite its simplicity and versatility, our approach allows us to build new state of the art on major semantic segmentation benchmarks including Cityscapes, ADE20K, Pascal Context, Camvid and COCO-stuff. Code and trained models are released at \url{https://github.com/lxtGH/GALD-DGCNet} to foster further research.
UPRec: User-Aware Pre-training for Recommender Systems
Feb 22, 2021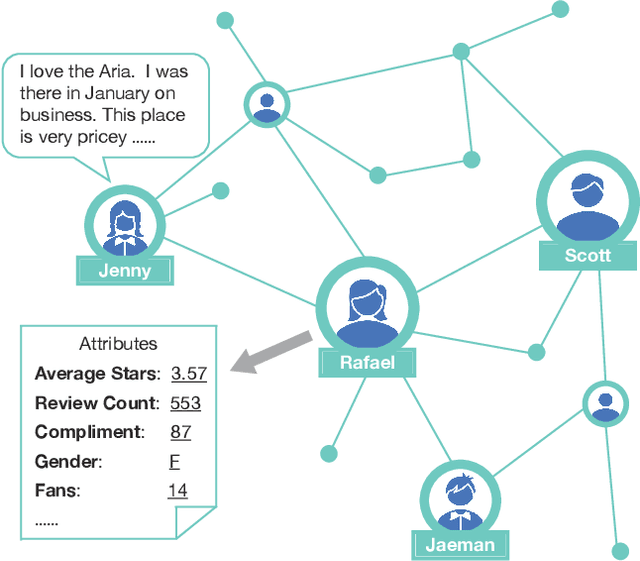

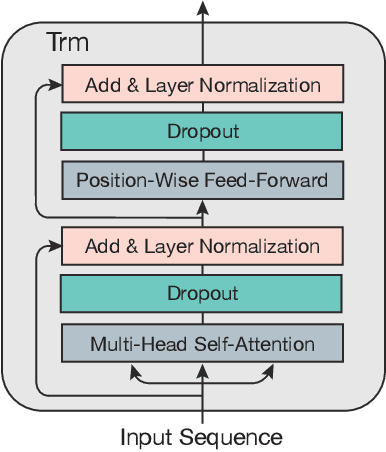

Existing sequential recommendation methods rely on large amounts of training data and usually suffer from the data sparsity problem. To tackle this, the pre-training mechanism has been widely adopted, which attempts to leverage large-scale data to perform self-supervised learning and transfer the pre-trained parameters to downstream tasks. However, previous pre-trained models for recommendation focus on leverage universal sequence patterns from user behaviour sequences and item information, whereas ignore capturing personalized interests with the heterogeneous user information, which has been shown effective in contributing to personalized recommendation. In this paper, we propose a method to enhance pre-trained models with heterogeneous user information, called User-aware Pre-training for Recommendation (UPRec). Specifically, UPRec leverages the user attributes andstructured social graphs to construct self-supervised objectives in the pre-training stage and proposes two user-aware pre-training tasks. Comprehensive experimental results on several real-world large-scale recommendation datasets demonstrate that UPRec can effectively integrate user information into pre-trained models and thus provide more appropriate recommendations for users.
Experimental Evidence that Empowerment May Drive Exploration in Sparse-Reward Environments
Jul 14, 2021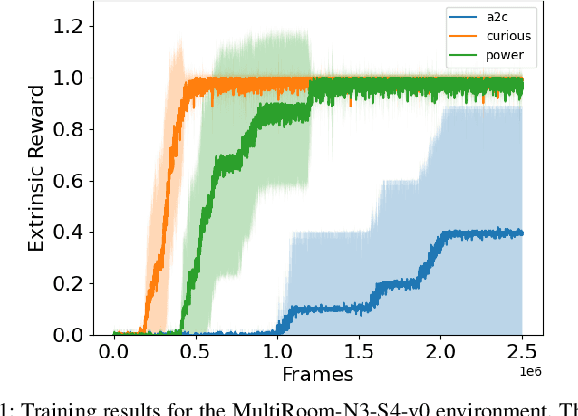
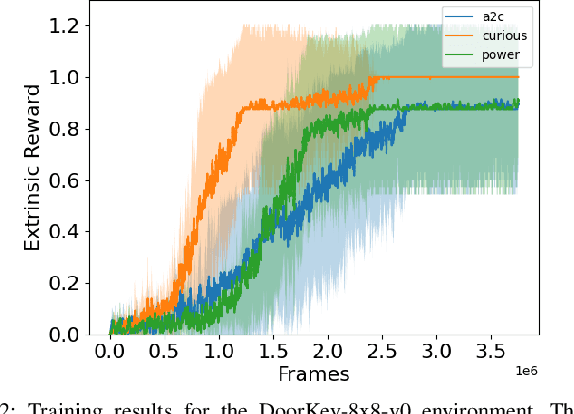
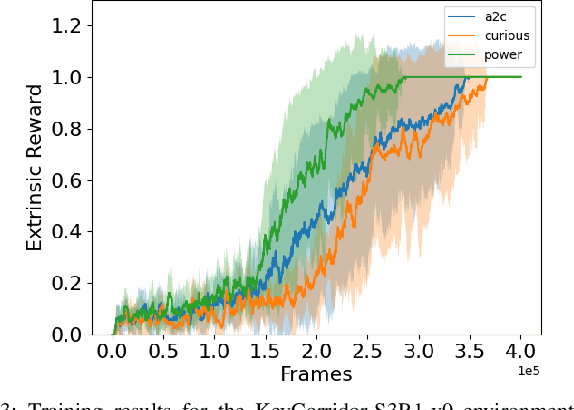

Reinforcement Learning (RL) is known to be often unsuccessful in environments with sparse extrinsic rewards. A possible countermeasure is to endow RL agents with an intrinsic reward function, or 'intrinsic motivation', which rewards the agent based on certain features of the current sensor state. An intrinsic reward function based on the principle of empowerment assigns rewards proportional to the amount of control the agent has over its own sensors. We implemented a variation on a recently proposed intrinsically motivated agent, which we refer to as the 'curious' agent, and an empowerment-inspired agent. The former leverages sensor state encoding with a variational autoencoder, while the latter predicts the next sensor state via a variational information bottleneck. We compared the performance of both agents to that of an advantage actor-critic baseline in four sparse reward grid worlds. Both the empowerment agent and its curious competitor seem to benefit to similar extents from their intrinsic rewards. This provides some experimental support to the conjecture that empowerment can be used to drive exploration.