 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Self-supervised Discriminative Feature Learning for Multi-view Clustering
Mar 28, 2021
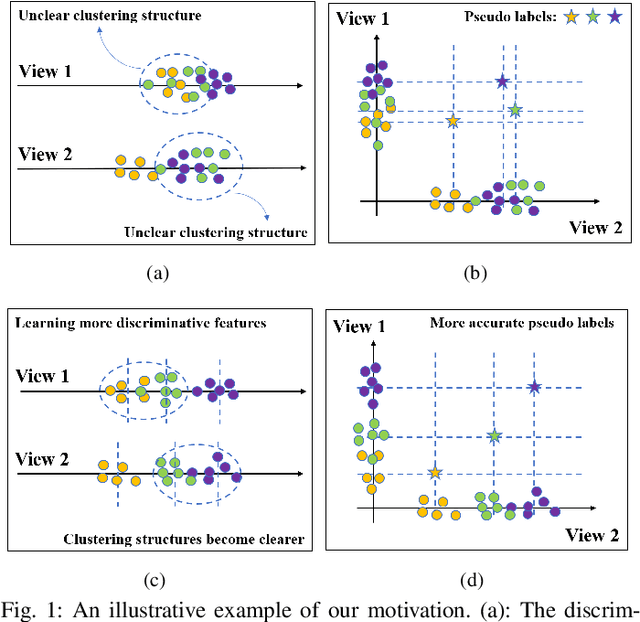
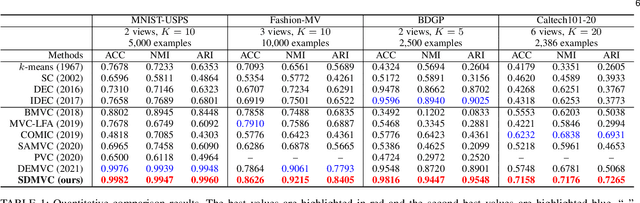
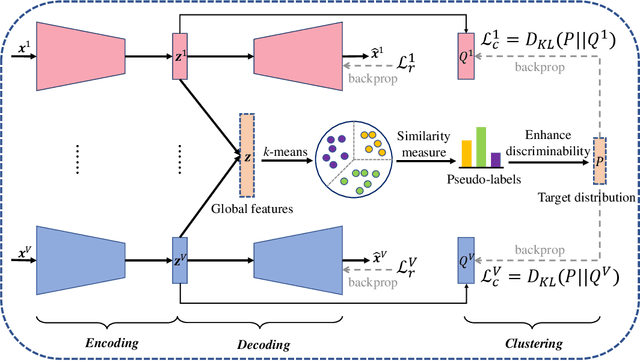
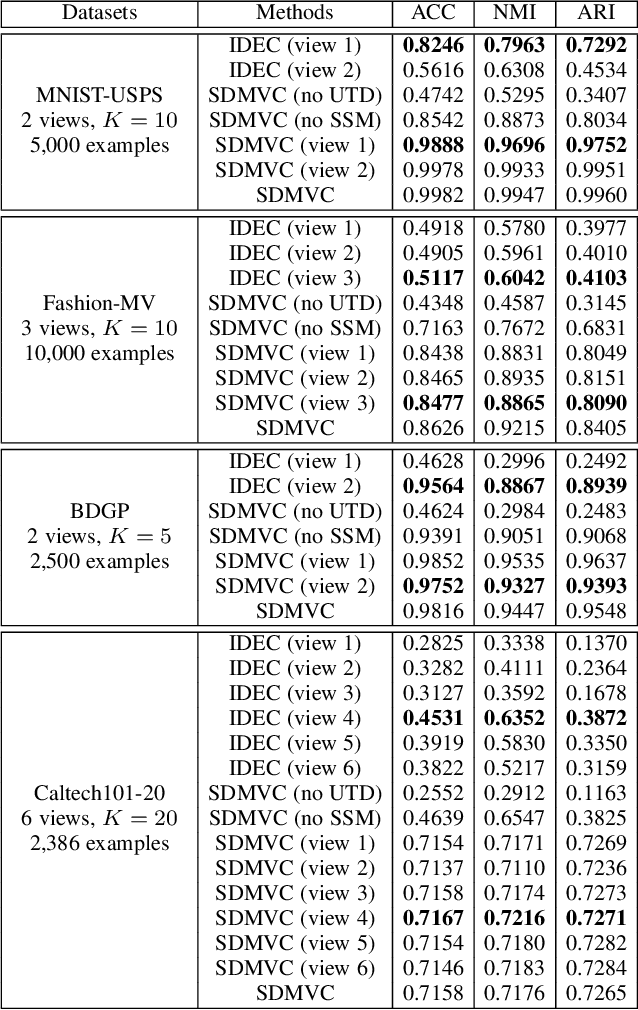
Multi-view clustering is an important research topic due to its capability to utilize complementary information from multiple views. However, there are few methods to consider the negative impact caused by certain views with unclear clustering structures, resulting in poor multi-view clustering performance. To address this drawback, we propose self-supervised discriminative feature learning for multi-view clustering (SDMVC). Concretely, deep autoencoders are applied to learn embedded features for each view independently. To leverage the multi-view complementary information, we concatenate all views' embedded features to form the global features, which can overcome the negative impact of some views' unclear clustering structures. In a self-supervised manner, pseudo-labels are obtained to build a unified target distribution to perform multi-view discriminative feature learning. During this process, global discriminative information can be mined to supervise all views to learn more discriminative features, which in turn are used to update the target distribution. Besides, this unified target distribution can make SDMVC learn consistent cluster assignments, which accomplishes the clustering consistency of multiple views while preserving their features' diversity. Experiments on various types of multi-view datasets show that SDMVC achieves state-of-the-art performance.
Neural Graph Matching based Collaborative Filtering
May 10, 2021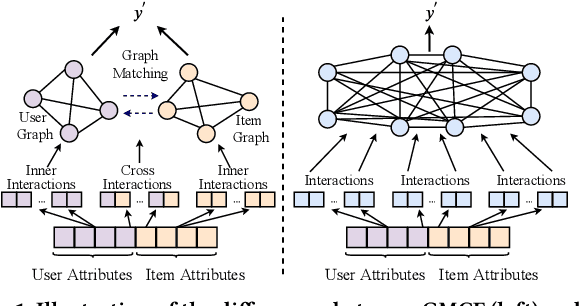
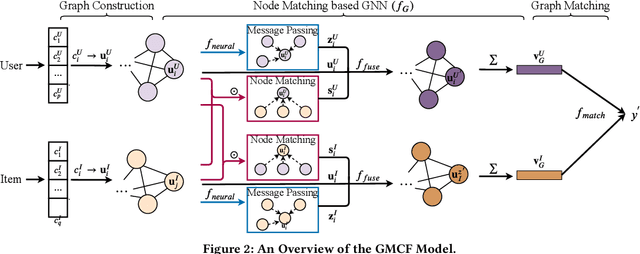
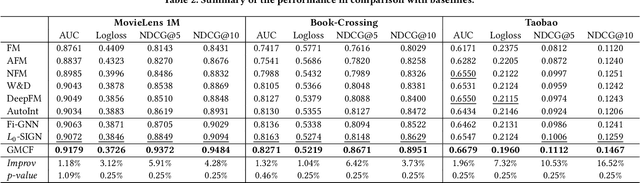
User and item attributes are essential side-information; their interactions (i.e., their co-occurrence in the sample data) can significantly enhance prediction accuracy in various recommender systems. We identify two different types of attribute interactions, inner interactions and cross interactions: inner interactions are those between only user attributes or those between only item attributes; cross interactions are those between user attributes and item attributes. Existing models do not distinguish these two types of attribute interactions, which may not be the most effective way to exploit the information carried by the interactions. To address this drawback, we propose a neural Graph Matching based Collaborative Filtering model (GMCF), which effectively captures the two types of attribute interactions through modeling and aggregating attribute interactions in a graph matching structure for recommendation. In our model, the two essential recommendation procedures, characteristic learning and preference matching, are explicitly conducted through graph learning (based on inner interactions) and node matching (based on cross interactions), respectively. Experimental results show that our model outperforms state-of-the-art models. Further studies verify the effectiveness of GMCF in improving the accuracy of recommendation.
On Pairwise Clustering with Side Information
Jun 19, 2017
Pairwise clustering, in general, partitions a set of items via a known similarity function. In our treatment, clustering is modeled as a transductive prediction problem. Thus rather than beginning with a known similarity function, the function instead is hidden and the learner only receives a random sample consisting of a subset of the pairwise similarities. An additional set of pairwise side-information may be given to the learner, which then determines the inductive bias of our algorithms. We measure performance not based on the recovery of the hidden similarity function, but instead on how well we classify each item. We give tight bounds on the number of misclassifications. We provide two algorithms. The first algorithm SACA is a simple agglomerative clustering algorithm which runs in near linear time, and which serves as a baseline for our analyses. Whereas the second algorithm, RGCA, enables the incorporation of side-information which may lead to improved bounds at the cost of a longer running time.
Boosting Crowd Counting with Transformers
May 23, 2021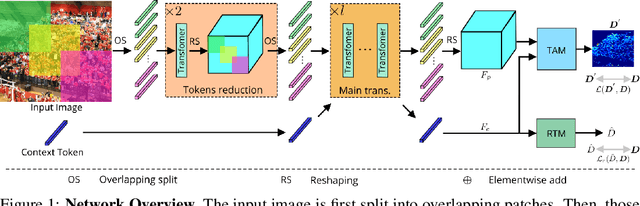
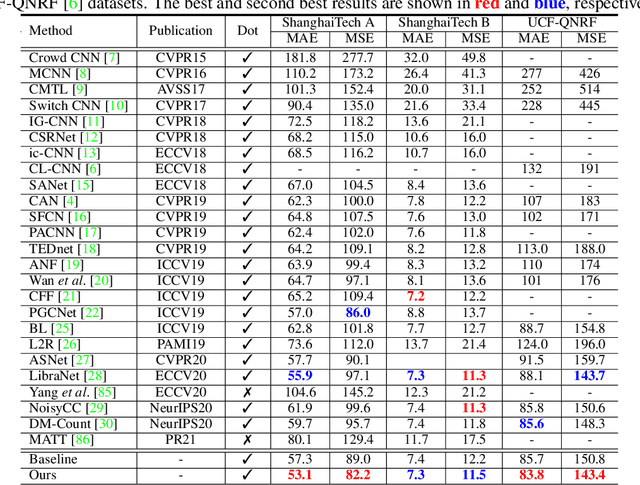
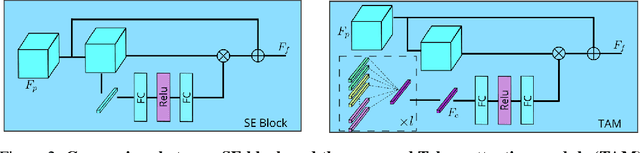
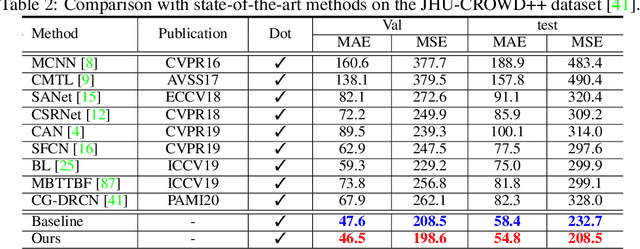
Significant progress on the crowd counting problem has been achieved by integrating larger context into convolutional neural networks (CNNs). This indicates that global scene context is essential, despite the seemingly bottom-up nature of the problem. This may be explained by the fact that context knowledge can adapt and improve local feature extraction to a given scene. In this paper, we therefore investigate the role of global context for crowd counting. Specifically, a pure transformer is used to extract features with global information from overlapping image patches. Inspired by classification, we add a context token to the input sequence, to facilitate information exchange with tokens corresponding to image patches throughout transformer layers. Due to the fact that transformers do not explicitly model the tried-and-true channel-wise interactions, we propose a token-attention module (TAM) to recalibrate encoded features through channel-wise attention informed by the context token. Beyond that, it is adopted to predict the total person count of the image through regression-token module (RTM). Extensive experiments demonstrate that our method achieves state-of-the-art performance on various datasets, including ShanghaiTech, UCF-QNRF, JHU-CROWD++ and NWPU. On the large-scale JHU-CROWD++ dataset, our method improves over the previous best results by 26.9% and 29.9% in terms of MAE and MSE, respectively.
Determining the Credibility of Science Communication
May 30, 2021

Most work on scholarly document processing assumes that the information processed is trustworthy and factually correct. However, this is not always the case. There are two core challenges, which should be addressed: 1) ensuring that scientific publications are credible -- e.g. that claims are not made without supporting evidence, and that all relevant supporting evidence is provided; and 2) that scientific findings are not misrepresented, distorted or outright misreported when communicated by journalists or the general public. I will present some first steps towards addressing these problems and outline remaining challenges.
Majorization Minimization Methods for Distributed Pose Graph Optimization
Aug 03, 2021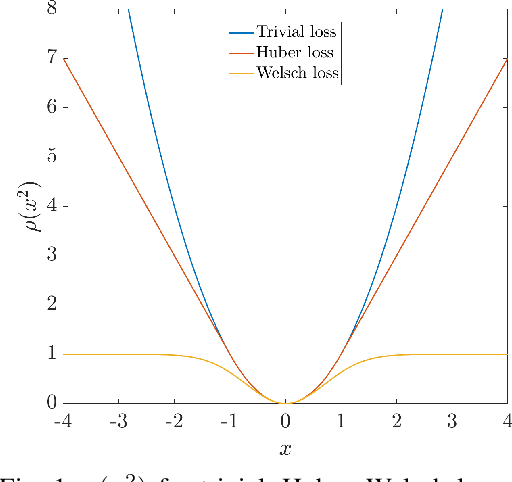
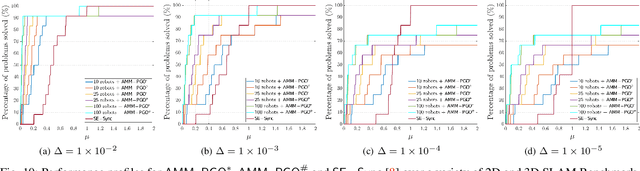
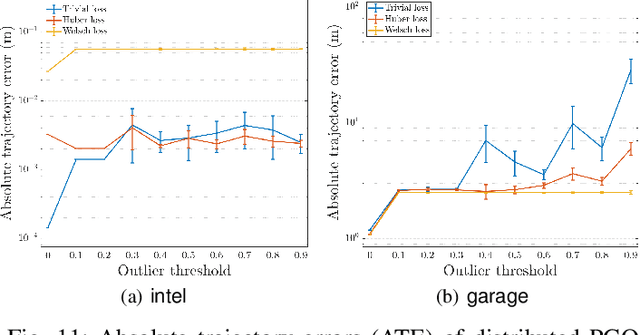

We consider the problem of distributed pose graph optimization (PGO) that has important applications in multi-robot simultaneous localization and mapping (SLAM). We propose the majorization minimization (MM) method for distributed PGO ($\mathsf{MM\!\!-\!\!PGO}$) that applies to a broad class of robust loss kernels. The $\mathsf{MM\!\!-\!\!PGO}$ method is guaranteed to converge to first-order critical points under mild conditions. Furthermore, noting that the $\mathsf{MM\!\!-\!\!PGO}$ method is reminiscent of proximal methods, we leverage Nesterov's method and adopt adaptive restarts to accelerate convergence. The resulting accelerated MM methods for distributed PGO -- both with a master node in the network ($\mathsf{AMM\!\!-\!\!PGO}^*$) and without ($\mathsf{AMM\!\!-\!\!PGO}^{\#}$) -- have faster convergence in contrast to the $\mathsf{MM\!\!-\!\!PGO}$ method without sacrificing theoretical guarantees. In particular, the $\mathsf{AMM\!\!-\!\!PGO}^{\#}$ method, which needs no master node and is fully decentralized, features a novel adaptive restart scheme and has a rate of convergence comparable to that of the $\mathsf{AMM\!\!-\!\!PGO}^*$ method using a master node to aggregate information from all the other nodes. The efficacy of this work is validated through extensive applications to 2D and 3D SLAM benchmark datasets and comprehensive comparisons against existing state-of-the-art methods, indicating that our MM methods converge faster and result in better solutions to distributed PGO.
PGT: A Progressive Method for Training Models on Long Videos
Mar 21, 2021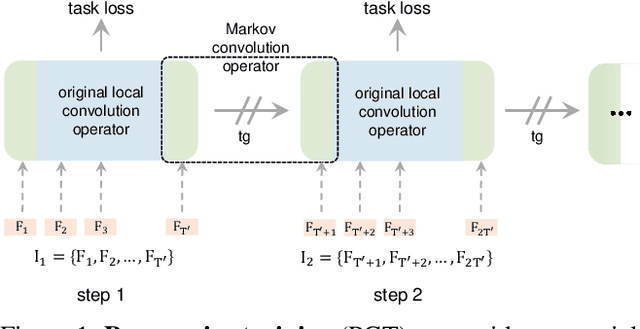
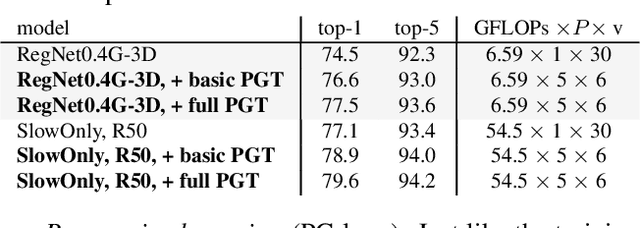
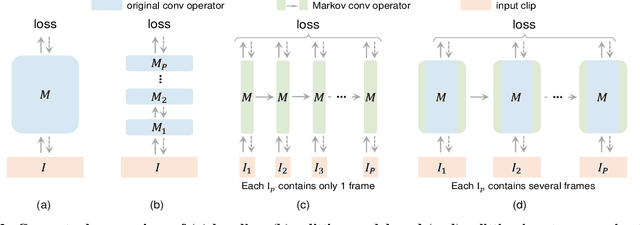
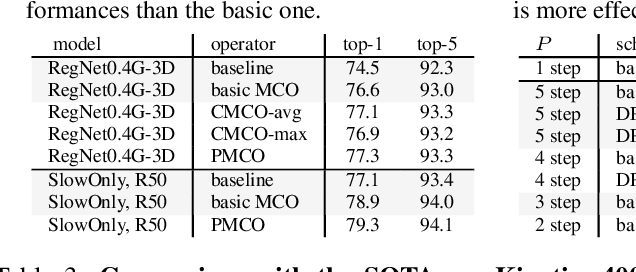
Convolutional video models have an order of magnitude larger computational complexity than their counterpart image-level models. Constrained by computational resources, there is no model or training method that can train long video sequences end-to-end. Currently, the main-stream method is to split a raw video into clips, leading to incomplete fragmentary temporal information flow. Inspired by natural language processing techniques dealing with long sentences, we propose to treat videos as serial fragments satisfying Markov property, and train it as a whole by progressively propagating information through the temporal dimension in multiple steps. This progressive training (PGT) method is able to train long videos end-to-end with limited resources and ensures the effective transmission of information. As a general and robust training method, we empirically demonstrate that it yields significant performance improvements on different models and datasets. As an illustrative example, the proposed method improves SlowOnly network by 3.7 mAP on Charades and 1.9 top-1 accuracy on Kinetics with negligible parameter and computation overhead. Code is available at https://github.com/BoPang1996/PGT.
* CVPR21, Oral
Selective Pseudo-label Clustering
Jul 22, 2021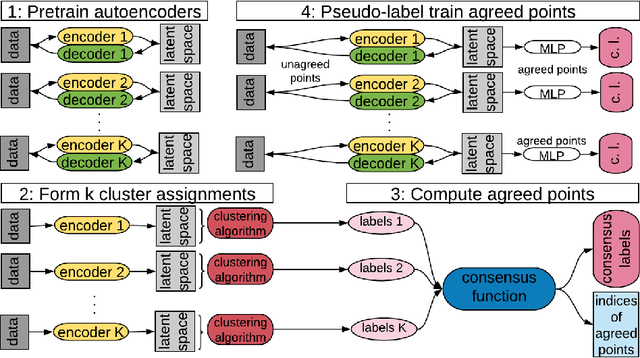
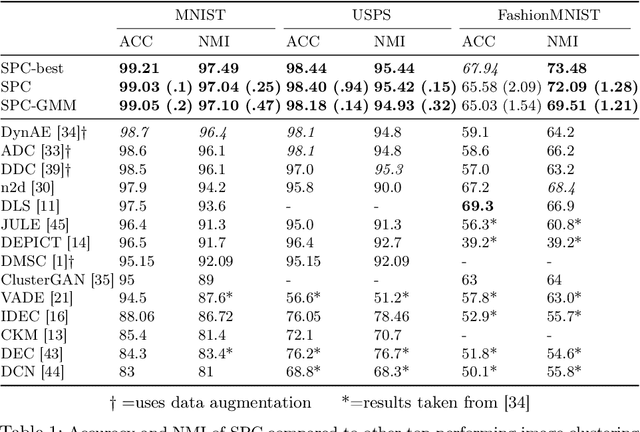
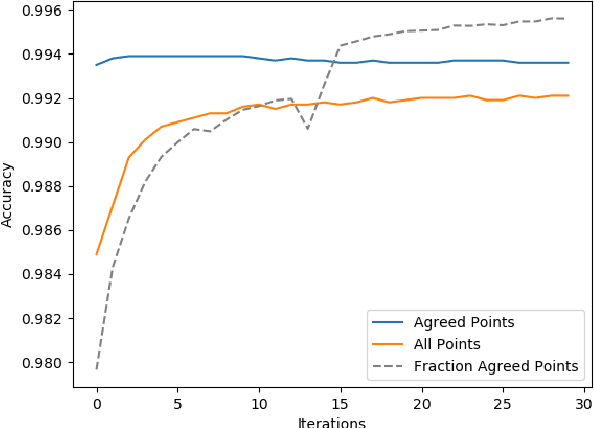
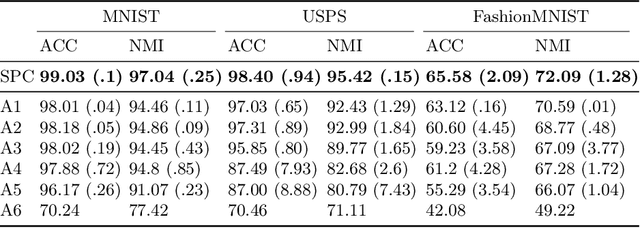
Deep neural networks (DNNs) offer a means of addressing the challenging task of clustering high-dimensional data. DNNs can extract useful features, and so produce a lower dimensional representation, which is more amenable to clustering techniques. As clustering is typically performed in a purely unsupervised setting, where no training labels are available, the question then arises as to how the DNN feature extractor can be trained. The most accurate existing approaches combine the training of the DNN with the clustering objective, so that information from the clustering process can be used to update the DNN to produce better features for clustering. One problem with this approach is that these ``pseudo-labels'' produced by the clustering algorithm are noisy, and any errors that they contain will hurt the training of the DNN. In this paper, we propose selective pseudo-label clustering, which uses only the most confident pseudo-labels for training the~DNN. We formally prove the performance gains under certain conditions. Applied to the task of image clustering, the new approach achieves a state-of-the-art performance on three popular image datasets. Code is available at https://github.com/Lou1sM/clustering.
Innovations Autoencoder and its Application in One-class Anomalous Sequence Detection
Jul 15, 2021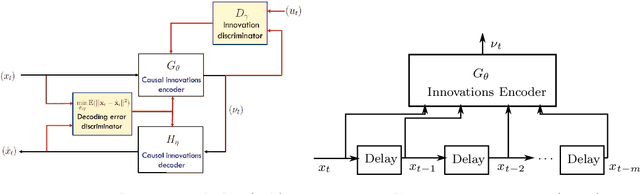


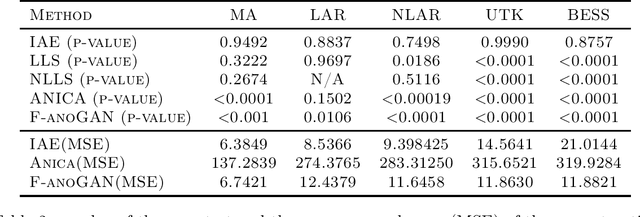
An innovations sequence of a time series is a sequence of independent and identically distributed random variables with which the original time series has a causal representation. The innovation at a time is statistically independent of the history of the time series. As such, it represents the new information contained at present but not in the past. Because of its simple probability structure, an innovations sequence is the most efficient signature of the original. Unlike the principle or independent component analysis representations, an innovations sequence preserves not only the complete statistical properties but also the temporal order of the original time series. An long-standing open problem is to find a computationally tractable way to extract an innovations sequence of non-Gaussian processes. This paper presents a deep learning approach, referred to as Innovations Autoencoder (IAE), that extracts innovations sequences using a causal convolutional neural network. An application of IAE to the one-class anomalous sequence detection problem with unknown anomaly and anomaly-free models is also presented.
IDOL-Net: An Interactive Dual-Domain Parallel Network for CT Metal Artifact Reduction
Apr 03, 2021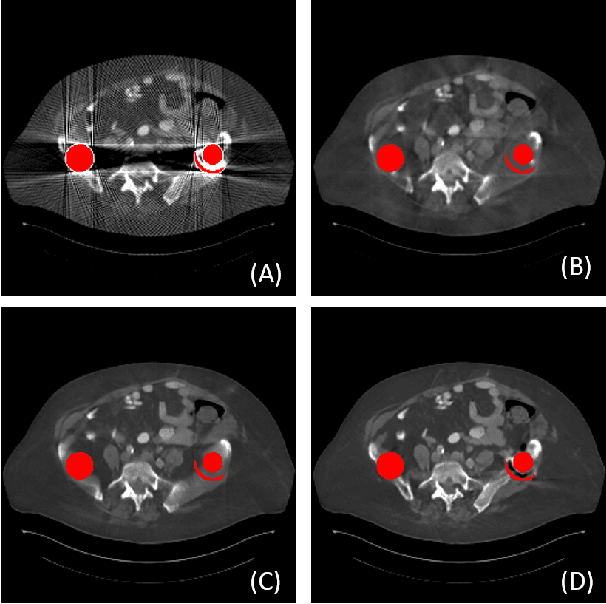
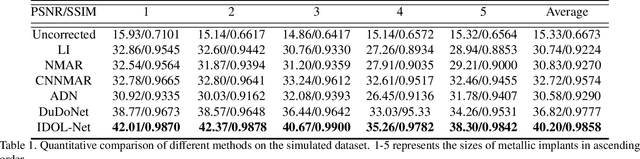
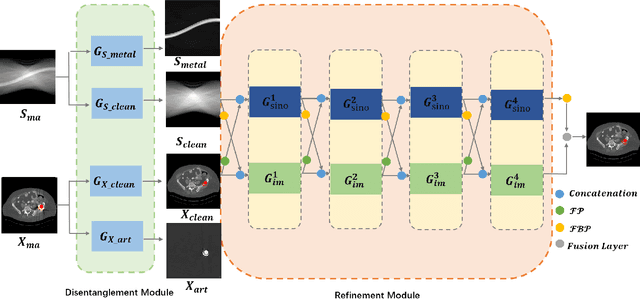

Due to the presence of metallic implants, the imaging quality of computed tomography (CT) would be heavily degraded. With the rapid development of deep learning, several network models have been proposed for metal artifact reduction (MAR). Since the dual-domain MAR methods can leverage the hybrid information from both sinogram and image domains, they have significantly improved the performance compared to single-domain methods. However,current dual-domain methods usually operate on both domains in a specific order, which implicitly imposes a certain priority prior into MAR and may ignore the latent information interaction between both domains. To address this problem, in this paper, we propose a novel interactive dualdomain parallel network for CT MAR, dubbed as IDOLNet. Different from existing dual-domain methods, the proposed IDOL-Net is composed of two modules. The disentanglement module is utilized to generate high-quality prior sinogram and image as the complementary inputs. The follow-up refinement module consists of two parallel and interactive branches that simultaneously operate on image and sinogram domain, fully exploiting the latent information interaction between both domains. The simulated and clinical results demonstrate that the proposed IDOL-Net outperforms several state-of-the-art models in both qualitative and quantitative aspects.