 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Tip of the Tongue Known-Item Retrieval: A Case Study in Movie Identification
Jan 18, 2021
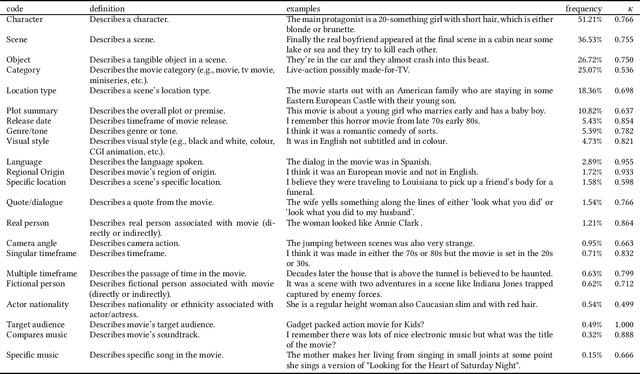
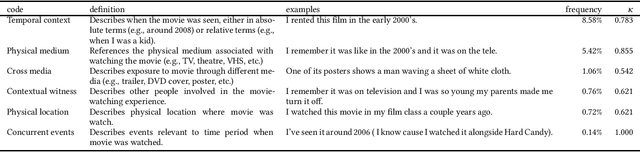


While current information retrieval systems are effective for known-item retrieval where the searcher provides a precise name or identifier for the item being sought, systems tend to be much less effective for cases where the searcher is unable to express a precise name or identifier. We refer to this as tip of the tongue (TOT) known-item retrieval, named after the cognitive state of not being able to retrieve an item from memory. Using movie search as a case study, we explore the characteristics of questions posed by searchers in TOT states in a community question answering website. We analyze how searchers express their information needs during TOT states in the movie domain. Specifically, what information do searchers remember about the item being sought and how do they convey this information? Our results suggest that searchers use a combination of information about: (1) the content of the item sought, (2) the context in which they previously engaged with the item, and (3) previous attempts to find the item using other resources (e.g., search engines). Additionally, searchers convey information by sometimes expressing uncertainty (i.e., hedging), opinions, emotions, and by performing relative (vs. absolute) comparisons with attributes of the item. As a result of our analysis, we believe that searchers in TOT states may require specialized query understanding methods or document representations. Finally, our preliminary retrieval experiments show the impact of each information type presented in information requests on retrieval performance.
A Meta Reinforcement Learning-based Approach for Self-Adaptive System
May 11, 2021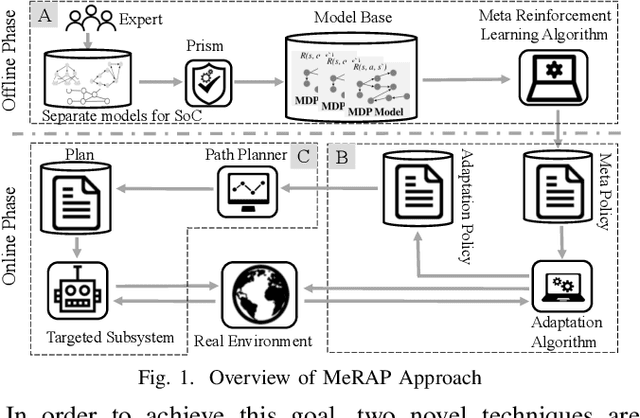
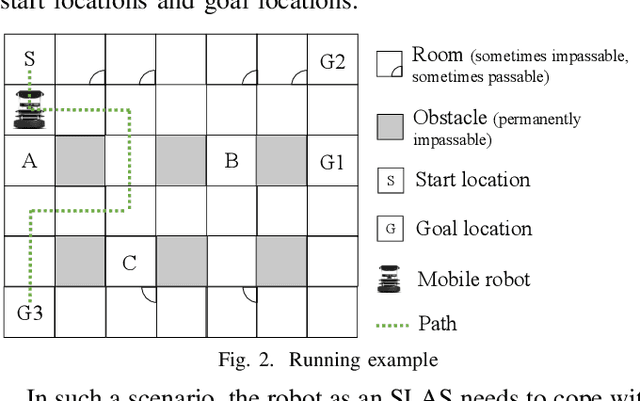
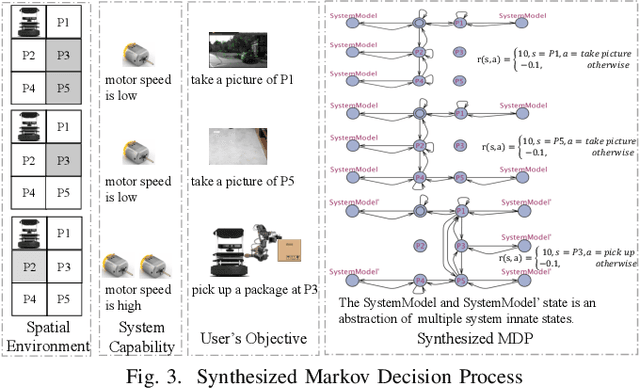
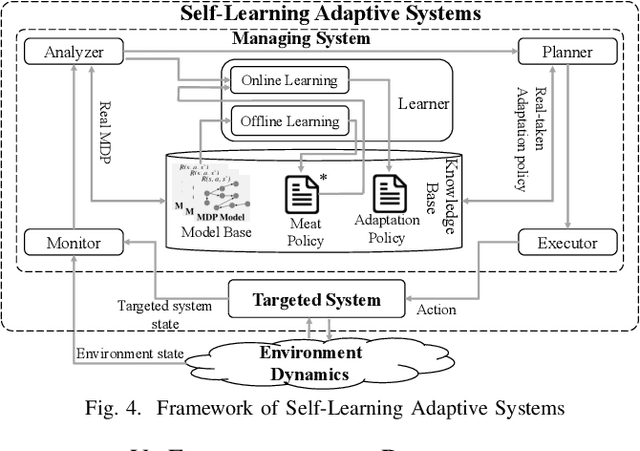
A self-learning adaptive system (SLAS) uses machine learning to enable and enhance its adaptability. Such systems are expected to perform well in dynamic situations. For learning high-performance adaptation policy, some assumptions must be made on the environment-system dynamics when information about the real situation is incomplete. However, these assumptions cannot be expected to be always correct, and yet it is difficult to enumerate all possible assumptions. This leads to the problem of incomplete-information learning. We consider this problem as multiple model problem in terms of finding the adaptation policy that can cope with multiple models of environment-system dynamics. This paper proposes a novel approach to engineering the online adaptation of SLAS. It separates three concerns that are related to the adaptation policy and presents the modeling and synthesis process, with the goal of achieving higher model construction efficiency. In addition, it designs a meta-reinforcement learning algorithm for learning the meta policy over the multiple models, so that the meta policy can quickly adapt to the real environment-system dynamics. At last, it reports the case study on a robotic system to evaluate the adaptability of the approach.
Manipulating Identical Filter Redundancy for Efficient Pruning on Deep and Complicated CNN
Jul 30, 2021
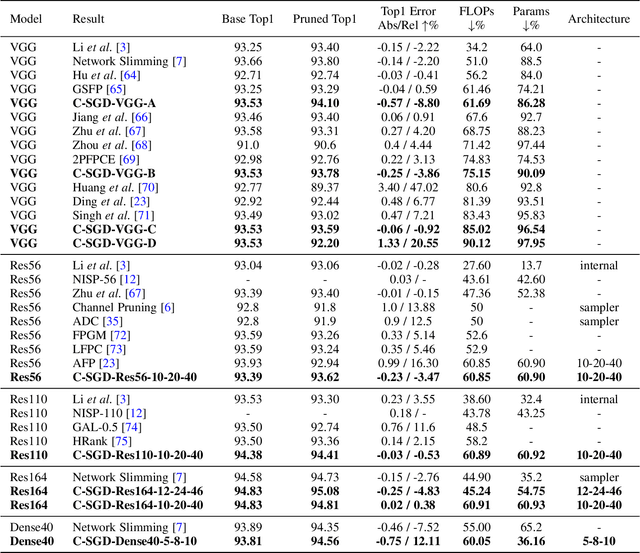
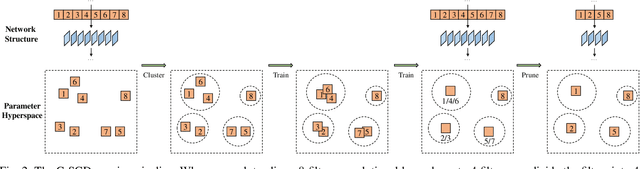
The existence of redundancy in Convolutional Neural Networks (CNNs) enables us to remove some filters/channels with acceptable performance drops. However, the training objective of CNNs usually tends to minimize an accuracy-related loss function without any attention paid to the redundancy, making the redundancy distribute randomly on all the filters, such that removing any of them may trigger information loss and accuracy drop, necessitating a following finetuning step for recovery. In this paper, we propose to manipulate the redundancy during training to facilitate network pruning. To this end, we propose a novel Centripetal SGD (C-SGD) to make some filters identical, resulting in ideal redundancy patterns, as such filters become purely redundant due to their duplicates; hence removing them does not harm the network. As shown on CIFAR and ImageNet, C-SGD delivers better performance because the redundancy is better organized, compared to the existing methods. The efficiency also characterizes C-SGD because it is as fast as regular SGD, requires no finetuning, and can be conducted simultaneously on all the layers even in very deep CNNs. Besides, C-SGD can improve the accuracy of CNNs by first training a model with the same architecture but wider layers then squeezing it into the original width.
Advice from the Oracle: Really Intelligent Information Retrieval
Jan 02, 2018What is "intelligent" information retrieval? Essentially this is asking what is intelligence, in this article I will attempt to show some of the aspects of human intelligence, as related to information retrieval. I will do this by the device of a semi-imaginary Oracle. Every Observatory has an oracle, someone who is a distinguished scientist, has great administrative responsibilities, acts as mentor to a number of less senior people, and as trusted advisor to even the most accomplished scientists, and knows essentially everyone in the field. In an appendix I will present a brief summary of the Statistical Factor Space method for text indexing and retrieval, and indicate how it will be used in the Astrophysics Data System Abstract Service. 2018 Keywords: Personal Digital Assistant; Supervised Topic Models
* Author copy; published 25 years ago at the beginning of the Astrophysics Data System; 2018 keywords added
DeepHyperion: Exploring the Feature Space of Deep Learning-Based Systems through Illumination Search
Jul 05, 2021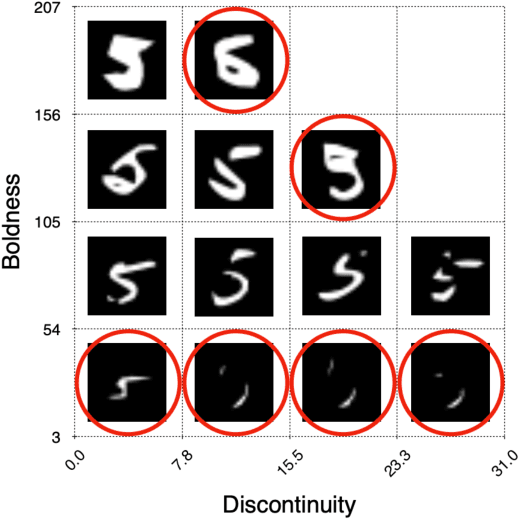
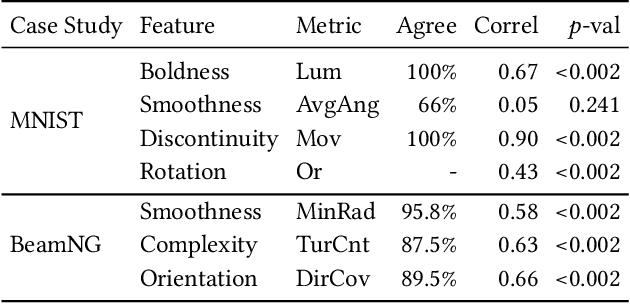
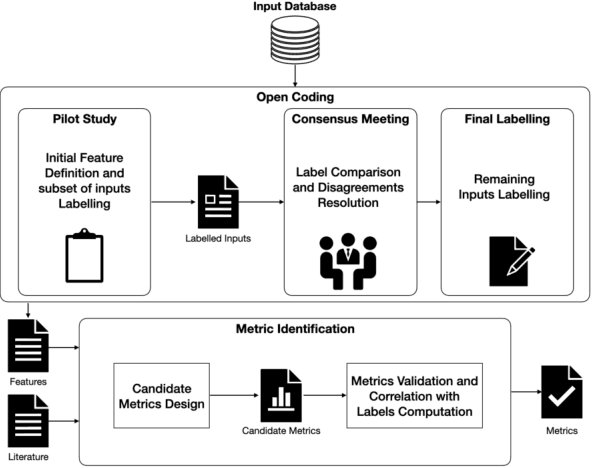
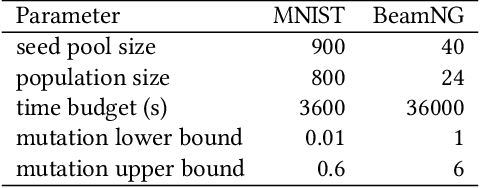
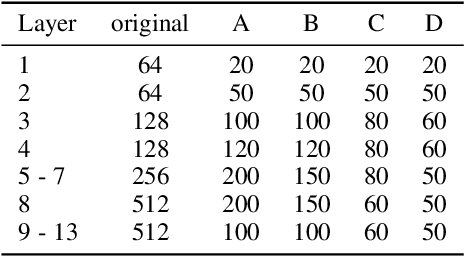
Deep Learning (DL) has been successfully applied to a wide range of application domains, including safety-critical ones. Several DL testing approaches have been recently proposed in the literature but none of them aims to assess how different interpretable features of the generated inputs affect the system's behaviour. In this paper, we resort to Illumination Search to find the highest-performing test cases (i.e., misbehaving and closest to misbehaving), spread across the cells of a map representing the feature space of the system. We introduce a methodology that guides the users of our approach in the tasks of identifying and quantifying the dimensions of the feature space for a given domain. We developed DeepHyperion, a search-based tool for DL systems that illuminates, i.e., explores at large, the feature space, by providing developers with an interpretable feature map where automatically generated inputs are placed along with information about the exposed behaviours.
Enhancing Social Relation Inference with Concise Interaction Graph and Discriminative Scene Representation
Jul 30, 2021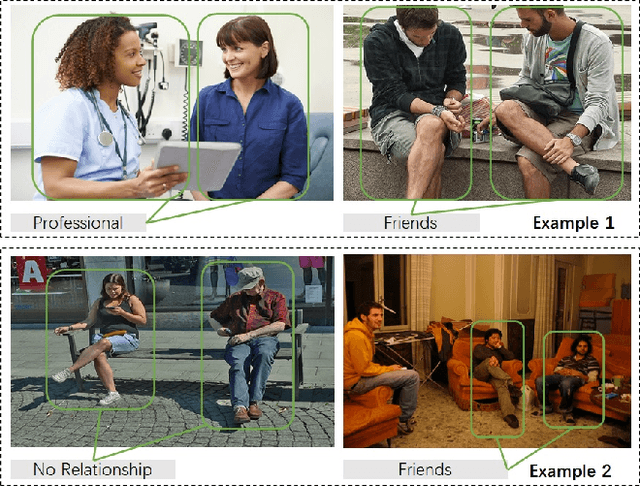
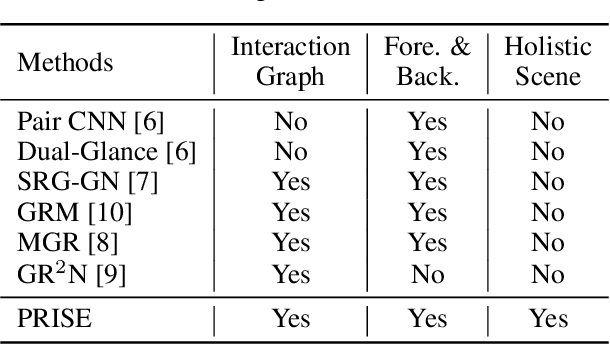
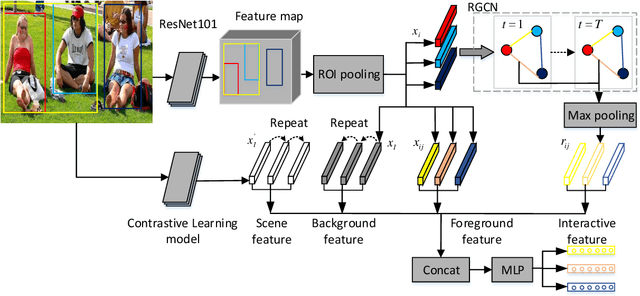
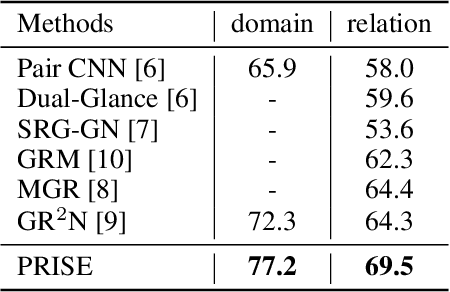
There has been a recent surge of research interest in attacking the problem of social relation inference based on images. Existing works classify social relations mainly by creating complicated graphs of human interactions, or learning the foreground and/or background information of persons and objects, but ignore holistic scene context. The holistic scene refers to the functionality of a place in images, such as dinning room, playground and office. In this paper, by mimicking human understanding on images, we propose an approach of \textbf{PR}actical \textbf{I}nference in \textbf{S}ocial r\textbf{E}lation (PRISE), which concisely learns interactive features of persons and discriminative features of holistic scenes. Technically, we develop a simple and fast relational graph convolutional network to capture interactive features of all persons in one image. To learn the holistic scene feature, we elaborately design a contrastive learning task based on image scene classification. To further boost the performance in social relation inference, we collect and distribute a new large-scale dataset, which consists of about 240 thousand unlabeled images. The extensive experimental results show that our novel learning framework significantly beats the state-of-the-art methods, e.g., PRISE achieves 6.8$\%$ improvement for domain classification in PIPA dataset.
MoCL: Contrastive Learning on Molecular Graphs with Multi-level Domain Knowledge
Jun 05, 2021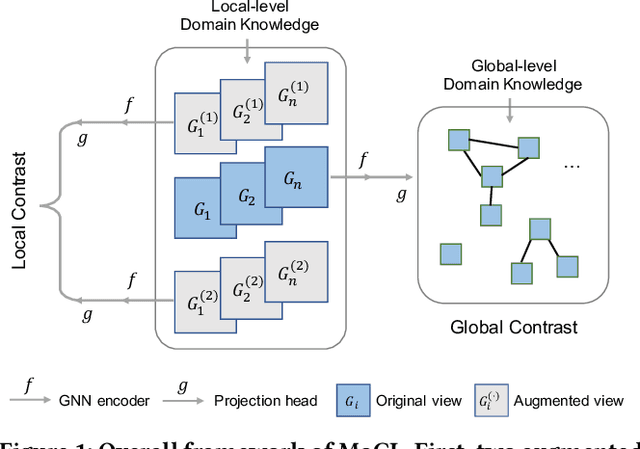
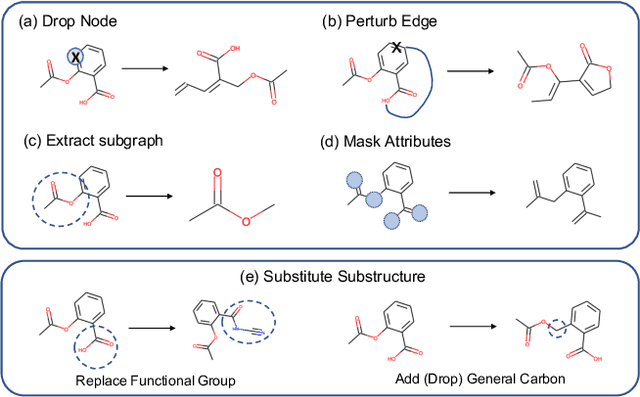
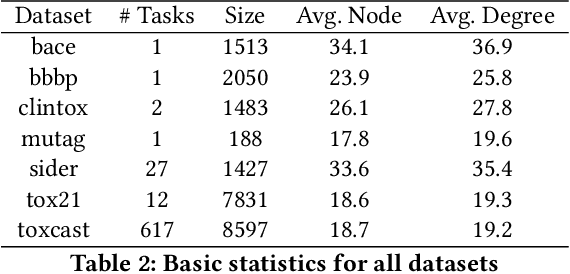
Recent years have seen a rapid growth of utilizing graph neural networks (GNNs) in the biomedical domain for tackling drug-related problems. However, like any other deep architectures, GNNs are data hungry. While requiring labels in real world is often expensive, pretraining GNNs in an unsupervised manner has been actively explored. Among them, graph contrastive learning, by maximizing the mutual information between paired graph augmentations, has been shown to be effective on various downstream tasks. However, the current graph contrastive learning framework has two limitations. First, the augmentations are designed for general graphs and thus may not be suitable or powerful enough for certain domains. Second, the contrastive scheme only learns representations that are invariant to local perturbations and thus does not consider the global structure of the dataset, which may also be useful for downstream tasks. Therefore, in this paper, we study graph contrastive learning in the context of biomedical domain, where molecular graphs are present. We propose a novel framework called MoCL, which utilizes domain knowledge at both local- and global-level to assist representation learning. The local-level domain knowledge guides the augmentation process such that variation is introduced without changing graph semantics. The global-level knowledge encodes the similarity information between graphs in the entire dataset and helps to learn representations with richer semantics. The entire model is learned through a double contrast objective. We evaluate MoCL on various molecular datasets under both linear and semi-supervised settings and results show that MoCL achieves state-of-the-art performance.
3-D Deployment of UAV Swarm for Massive MIMO Communications
May 03, 2021
We consider the uplink transmission between a multi-antenna ground station and an unmanned aerial vehicle (UAV) swarm. The UAVs are assumed as intelligent agents, which can explore their optimal three dimensional (3-D) deployment to maximize the channel capacity of the multiple input multiple output (MIMO) system. Specifically, considering the limitations of each UAV in accessing the global information of the network, we focus on a decentralized control strategy by noting that each UAV in the swarm can only utilize the local information to achieve the optimal 3-D deployment. In this case, the optimization problem can be divided into several optimization sub-problems with respect to the rank function. Due to the non-convex nature of the rank function and the fact that the optimization sub-problems are coupled, the original problem is NP-hard and, thus, cannot be solved with standard convex optimization solvers. Interestingly, we can relax the constraint condition of each sub-problem and solve the optimization problem by a formulated UAVs channel capacity maximization game. We analyze such game according to the designed reward function and the potential function. Then, we discuss the existence of the pure Nash equilibrium in the game. To achieve the best Nash equilibrium of the MIMO system, we develop a decentralized learning algorithm, namely decentralized UAVs channel capacity learning. The details of the algorithm are provided, and then, the convergence, the effectiveness and the computational complexity are analyzed, respectively. Moreover, we give some insightful remarks based on the proofs and the theoretical analysis. Also, extensive simulations illustrate that the developed learning algorithm can achieve a high MIMO channel capacity by optimizing the 3-D UAV swarm deployment with the local information.
Beyond Farthest Point Sampling in Point-Wise Analysis
Jul 09, 2021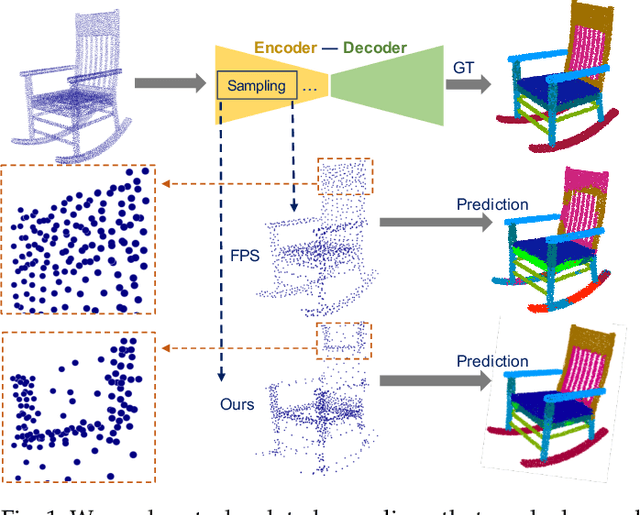
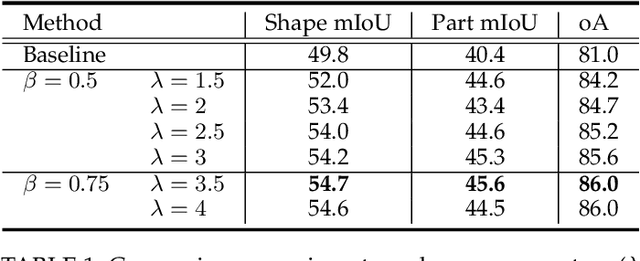
Sampling, grouping, and aggregation are three important components in the multi-scale analysis of point clouds. In this paper, we present a novel data-driven sampler learning strategy for point-wise analysis tasks. Unlike the widely used sampling technique, Farthest Point Sampling (FPS), we propose to learn sampling and downstream applications jointly. Our key insight is that uniform sampling methods like FPS are not always optimal for different tasks: sampling more points around boundary areas can make the point-wise classification easier for segmentation. Towards the end, we propose a novel sampler learning strategy that learns sampling point displacement supervised by task-related ground truth information and can be trained jointly with the underlying tasks. We further demonstrate our methods in various point-wise analysis architectures, including semantic part segmentation, point cloud completion, and keypoint detection. Our experiments show that jointly learning of the sampler and task brings remarkable improvement over previous baseline methods.
Self-Supervised Regional and Temporal Auxiliary Tasks for Facial Action Unit Recognition
Jul 30, 2021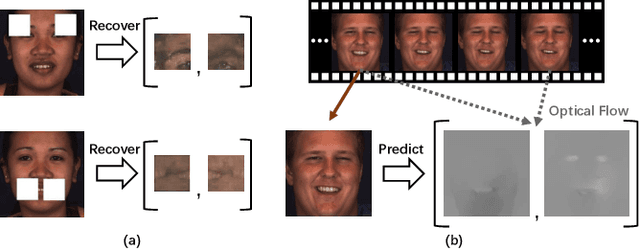
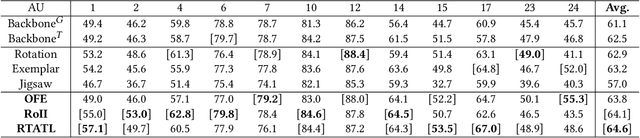
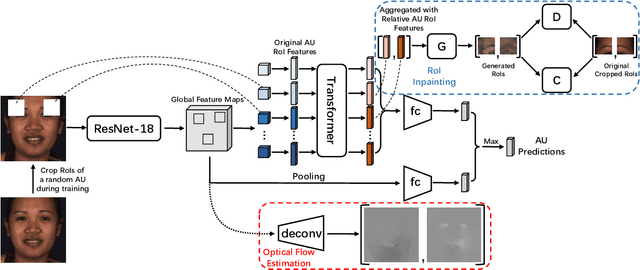
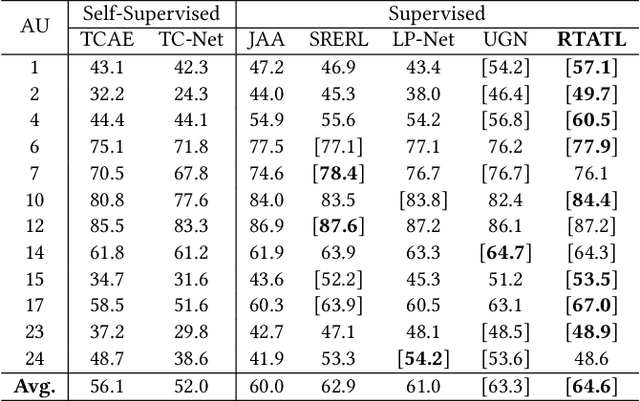
Automatic facial action unit (AU) recognition is a challenging task due to the scarcity of manual annotations. To alleviate this problem, a large amount of efforts has been dedicated to exploiting various methods which leverage numerous unlabeled data. However, many aspects with regard to some unique properties of AUs, such as the regional and relational characteristics, are not sufficiently explored in previous works. Motivated by this, we take the AU properties into consideration and propose two auxiliary AU related tasks to bridge the gap between limited annotations and the model performance in a self-supervised manner via the unlabeled data. Specifically, to enhance the discrimination of regional features with AU relation embedding, we design a task of RoI inpainting to recover the randomly cropped AU patches. Meanwhile, a single image based optical flow estimation task is proposed to leverage the dynamic change of facial muscles and encode the motion information into the global feature representation. Based on these two self-supervised auxiliary tasks, local features, mutual relation and motion cues of AUs are better captured in the backbone network with the proposed regional and temporal based auxiliary task learning (RTATL) framework. Extensive experiments on BP4D and DISFA demonstrate the superiority of our method and new state-of-the-art performances are achieved.