 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Enhancing Knowledge Tracing via Adversarial Training
Aug 10, 2021
We study the problem of knowledge tracing (KT) where the goal is to trace the students' knowledge mastery over time so as to make predictions on their future performance. Owing to the good representation capacity of deep neural networks (DNNs), recent advances on KT have increasingly concentrated on exploring DNNs to improve the performance of KT. However, we empirically reveal that the DNNs based KT models may run the risk of overfitting, especially on small datasets, leading to limited generalization. In this paper, by leveraging the current advances in adversarial training (AT), we propose an efficient AT based KT method (ATKT) to enhance KT model's generalization and thus push the limit of KT. Specifically, we first construct adversarial perturbations and add them on the original interaction embeddings as adversarial examples. The original and adversarial examples are further used to jointly train the KT model, forcing it is not only to be robust to the adversarial examples, but also to enhance the generalization over the original ones. To better implement AT, we then present an efficient attentive-LSTM model as KT backbone, where the key is a proposed knowledge hidden state attention module that adaptively aggregates information from previous knowledge hidden states while simultaneously highlighting the importance of current knowledge hidden state to make a more accurate prediction. Extensive experiments on four public benchmark datasets demonstrate that our ATKT achieves new state-of-the-art performance. Code is available at: \color{blue} {\url{https://github.com/xiaopengguo/ATKT}}.
Simplified Data Wrangling with ir_datasets
Mar 03, 2021


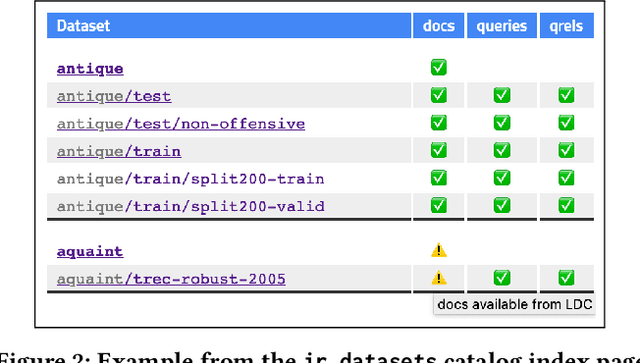
Managing the data for Information Retrieval (IR) experiments can be challenging. Dataset documentation is scattered across the Internet and once one obtains a copy of the data, there are numerous different data formats to work with. Even basic formats can have subtle dataset-specific nuances that need to be considered for proper use. To help mitigate these challenges, we introduce a new robust and lightweight tool (ir_datases) for acquiring, managing, and performing typical operations over datasets used in IR. We primarily focus on textual datasets used for ad-hoc search. This tool provides both a python and command line interface to numerous IR datasets and benchmarks. To our knowledge, this is the most extensive tool of its kind. Integrations with popular IR indexing and experimentation toolkits demonstrate the tool's utility. We also provide documentation of these datasets through the ir_datasets catalog: https://ir-datasets.com/. The catalog acts as a hub for information on datasets used in IR, providing core information about what data each benchmark provides as well as links to more detailed information. We welcome community contributions and intend to continue to maintain and grow this tool.
Learning Heterogeneous Temporal Patterns of User Preference for Timely Recommendation
Apr 29, 2021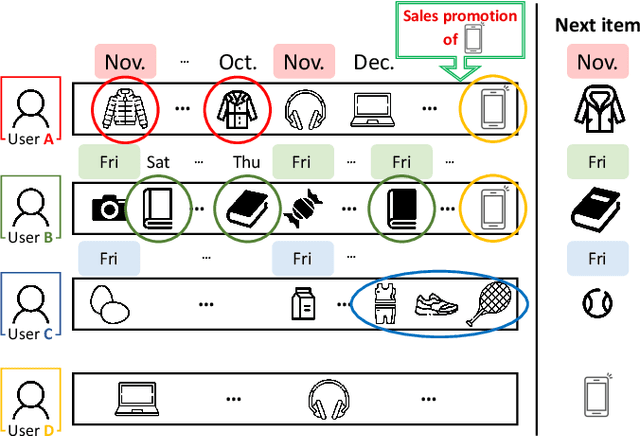
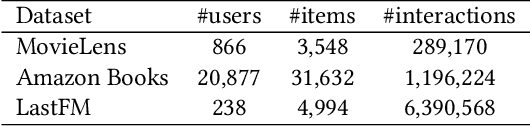
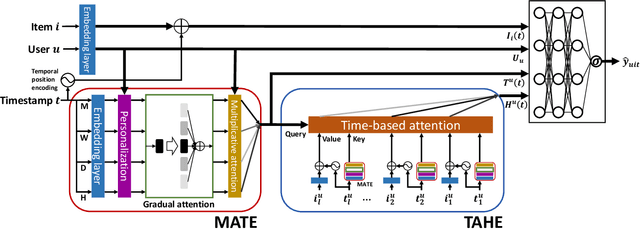
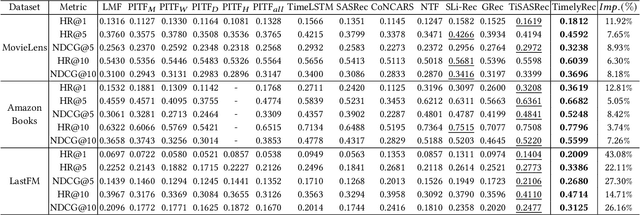
Recommender systems have achieved great success in modeling user's preferences on items and predicting the next item the user would consume. Recently, there have been many efforts to utilize time information of users' interactions with items to capture inherent temporal patterns of user behaviors and offer timely recommendations at a given time. Existing studies regard the time information as a single type of feature and focus on how to associate it with user preferences on items. However, we argue they are insufficient for fully learning the time information because the temporal patterns of user preference are usually heterogeneous. A user's preference for a particular item may 1) increase periodically or 2) evolve over time under the influence of significant recent events, and each of these two kinds of temporal pattern appears with some unique characteristics. In this paper, we first define the unique characteristics of the two kinds of temporal pattern of user preference that should be considered in time-aware recommender systems. Then we propose a novel recommender system for timely recommendations, called TimelyRec, which jointly learns the heterogeneous temporal patterns of user preference considering all of the defined characteristics. In TimelyRec, a cascade of two encoders captures the temporal patterns of user preference using a proposed attention module for each encoder. Moreover, we introduce an evaluation scenario that evaluates the performance on predicting an interesting item and when to recommend the item simultaneously in top-K recommendation (i.e., item-timing recommendation). Our extensive experiments on a scenario for item recommendation and the proposed scenario for item-timing recommendation on real-world datasets demonstrate the superiority of TimelyRec and the proposed attention modules.
LiDAR-based Recurrent 3D Semantic Segmentation with Temporal Memory Alignment
Mar 03, 2021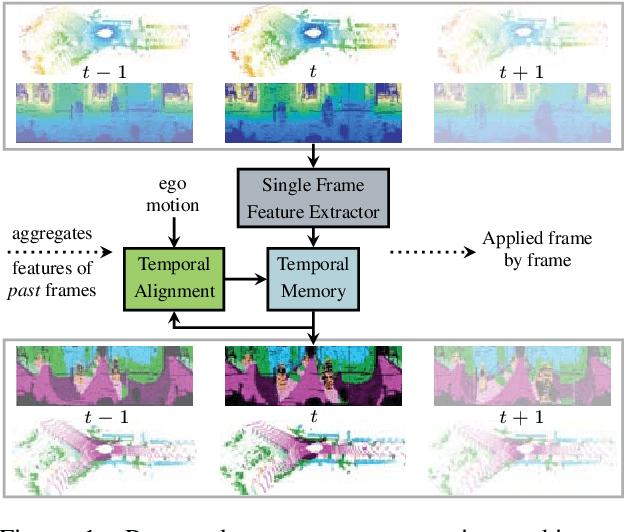
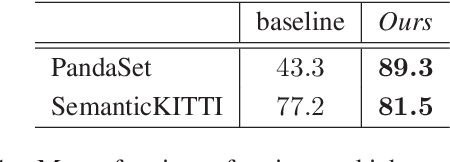
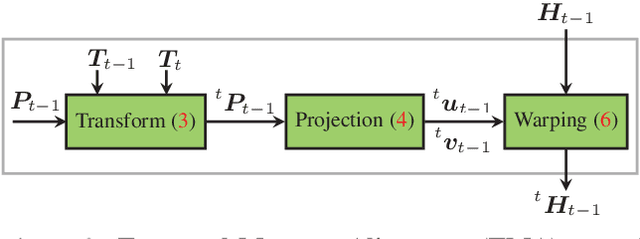
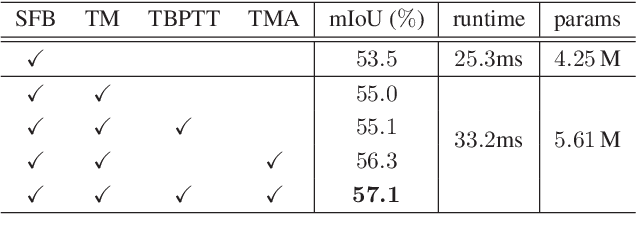
Understanding and interpreting a 3d environment is a key challenge for autonomous vehicles. Semantic segmentation of 3d point clouds combines 3d information with semantics and thereby provides a valuable contribution to this task. In many real-world applications, point clouds are generated by lidar sensors in a consecutive fashion. Working with a time series instead of single and independent frames enables the exploitation of temporal information. We therefore propose a recurrent segmentation architecture (RNN), which takes a single range image frame as input and exploits recursively aggregated temporal information. An alignment strategy, which we call Temporal Memory Alignment, uses ego motion to temporally align the memory between consecutive frames in feature space. A Residual Network and ConvGRU are investigated for the memory update. We demonstrate the benefits of the presented approach on two large-scale datasets and compare it to several stateof-the-art methods. Our approach ranks first on the SemanticKITTI multiple scan benchmark and achieves state-of-the-art performance on the single scan benchmark. In addition, the evaluation shows that the exploitation of temporal information significantly improves segmentation results compared to a single frame approach.
Unsupervised Domain Adaptive 3D Detection with Multi-Level Consistency
Jul 23, 2021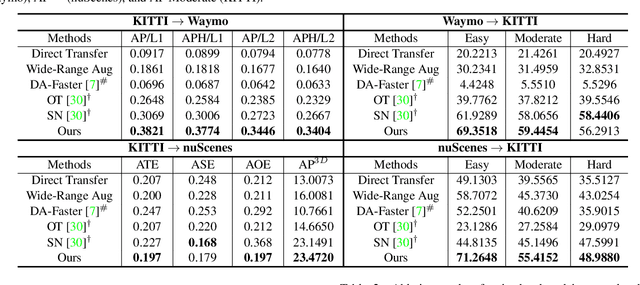
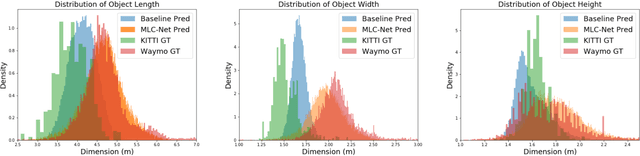
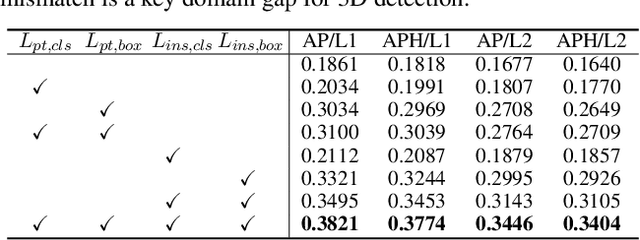
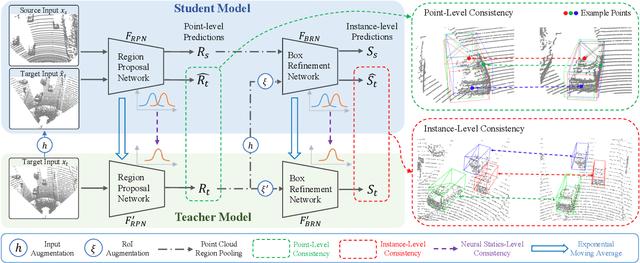
Deep learning-based 3D object detection has achieved unprecedented success with the advent of large-scale autonomous driving datasets. However, drastic performance degradation remains a critical challenge for cross-domain deployment. In addition, existing 3D domain adaptive detection methods often assume prior access to the target domain annotations, which is rarely feasible in the real world. To address this challenge, we study a more realistic setting, unsupervised 3D domain adaptive detection, which only utilizes source domain annotations. 1) We first comprehensively investigate the major underlying factors of the domain gap in 3D detection. Our key insight is that geometric mismatch is the key factor of domain shift. 2) Then, we propose a novel and unified framework, Multi-Level Consistency Network (MLC-Net), which employs a teacher-student paradigm to generate adaptive and reliable pseudo-targets. MLC-Net exploits point-, instance- and neural statistics-level consistency to facilitate cross-domain transfer. Extensive experiments demonstrate that MLC-Net outperforms existing state-of-the-art methods (including those using additional target domain information) on standard benchmarks. Notably, our approach is detector-agnostic, which achieves consistent gains on both single- and two-stage 3D detectors.
rx-anon -- A Novel Approach on the De-Identification of Heterogeneous Data based on a Modified Mondrian Algorithm
May 18, 2021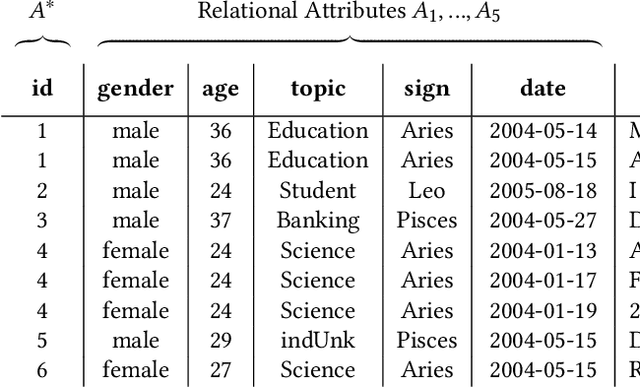
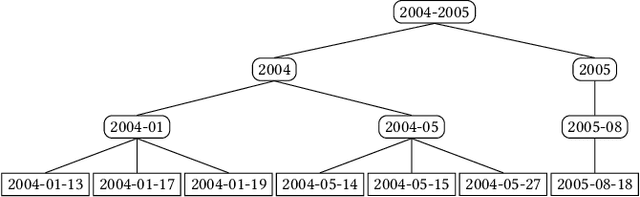
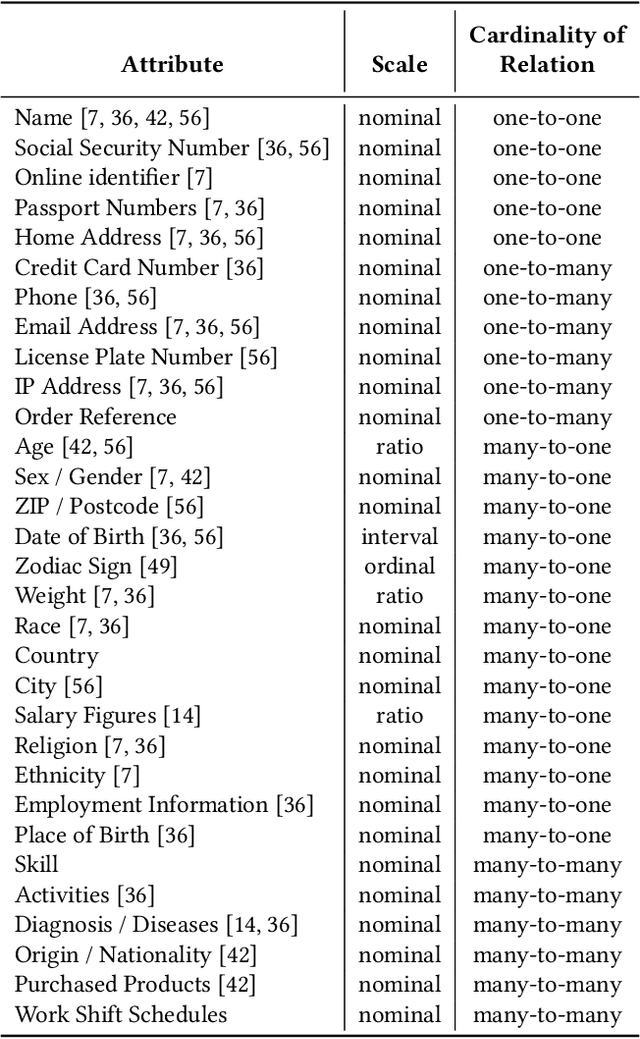
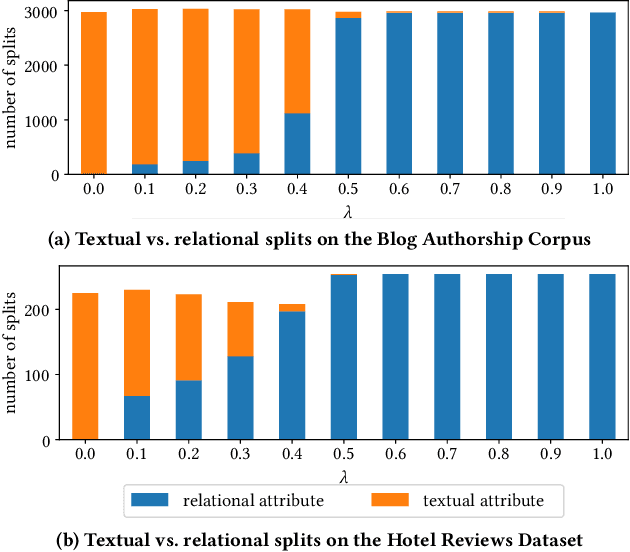
Traditional approaches for data anonymization consider relational data and textual data independently. We propose rx-anon, an anonymization approach for heterogeneous semi-structured documents composed of relational and textual attributes. We map sensitive terms extracted from the text to the structured data. This allows us to use concepts like k-anonymity to generate a joined, privacy-preserved version of the heterogeneous data input. We introduce the concept of redundant sensitive information to consistently anonymize the heterogeneous data. To control the influence of anonymization over unstructured textual data versus structured data attributes, we introduce a modified, parameterized Mondrian algorithm. The parameter $\lambda$ allows to give different weight on the relational and textual attributes during the anonymization process. We evaluate our approach with two real-world datasets using a Normalized Certainty Penalty score, adapted to the problem of jointly anonymizing relational and textual data. The results show that our approach is capable of reducing information loss by using the tuning parameter to control the Mondrian partitioning while guaranteeing k-anonymity for relational attributes as well as for sensitive terms. As rx-anon is a framework approach, it can be reused and extended by other anonymization algorithms, privacy models, and textual similarity metrics.
OpenSync: An opensource platform for synchronizing multiple measures in neuroscience experiments
Jul 29, 2021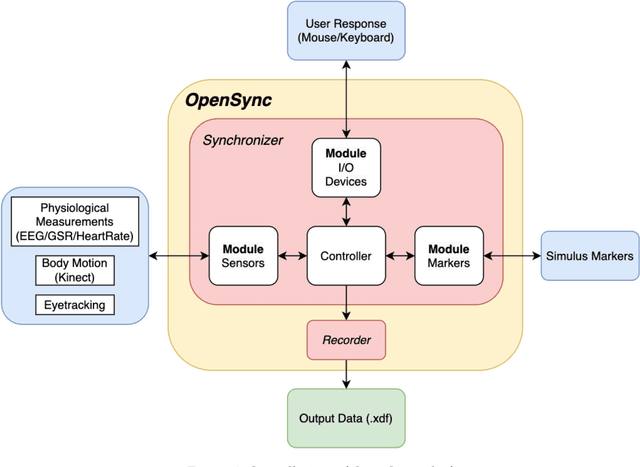


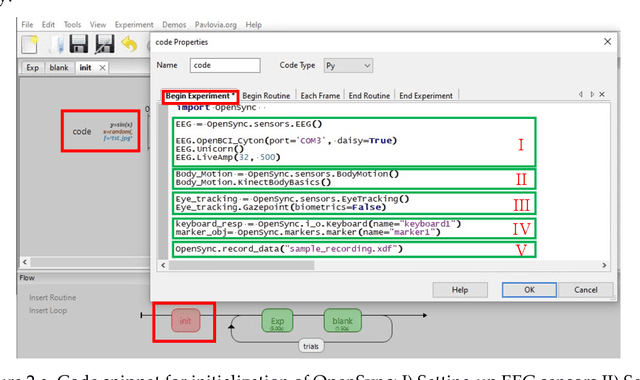
Background: The human mind is multimodal. Yet most behavioral studies rely on century-old measures such as task accuracy and latency. To create a better understanding of human behavior and brain functionality, we should introduce other measures and analyze behavior from various aspects. However, it is technically complex and costly to design and implement the experiments that record multiple measures. To address this issue, a platform that allows synchronizing multiple measures from human behavior is needed. Method: This paper introduces an opensource platform named OpenSync, which can be used to synchronize multiple measures in neuroscience experiments. This platform helps to automatically integrate, synchronize and record physiological measures (e.g., electroencephalogram (EEG), galvanic skin response (GSR), eye-tracking, body motion, etc.), user input response (e.g., from mouse, keyboard, joystick, etc.), and task-related information (stimulus markers). In this paper, we explain the structure and details of OpenSync, provide two case studies in PsychoPy and Unity. Comparison with existing tools: Unlike proprietary systems (e.g., iMotions), OpenSync is free and it can be used inside any opensource experiment design software (e.g., PsychoPy, OpenSesame, Unity, etc., https://pypi.org/project/OpenSync/ and https://github.com/moeinrazavi/OpenSync_Unity). Results: Our experimental results show that the OpenSync platform is able to synchronize multiple measures with microsecond resolution.
Perceptual Indistinguishability-Net (PI-Net): Facial Image Obfuscation with Manipulable Semantics
Apr 05, 2021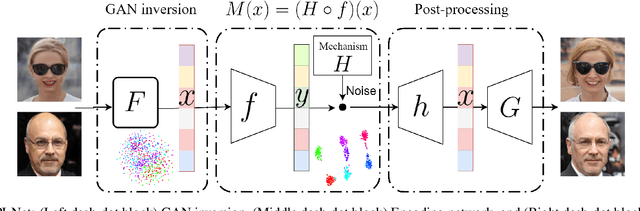
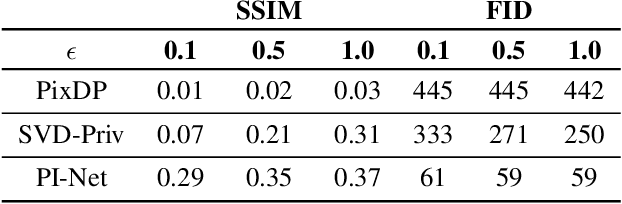

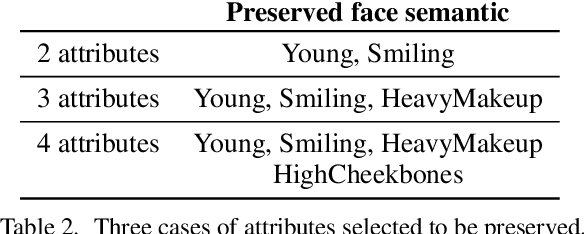
With the growing use of camera devices, the industry has many image datasets that provide more opportunities for collaboration between the machine learning community and industry. However, the sensitive information in the datasets discourages data owners from releasing these datasets. Despite recent research devoted to removing sensitive information from images, they provide neither meaningful privacy-utility trade-off nor provable privacy guarantees. In this study, with the consideration of the perceptual similarity, we propose perceptual indistinguishability (PI) as a formal privacy notion particularly for images. We also propose PI-Net, a privacy-preserving mechanism that achieves image obfuscation with PI guarantee. Our study shows that PI-Net achieves significantly better privacy utility trade-off through public image data.
How could Neural Networks understand Programs?
May 31, 2021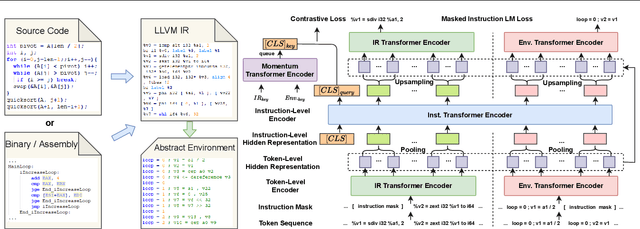
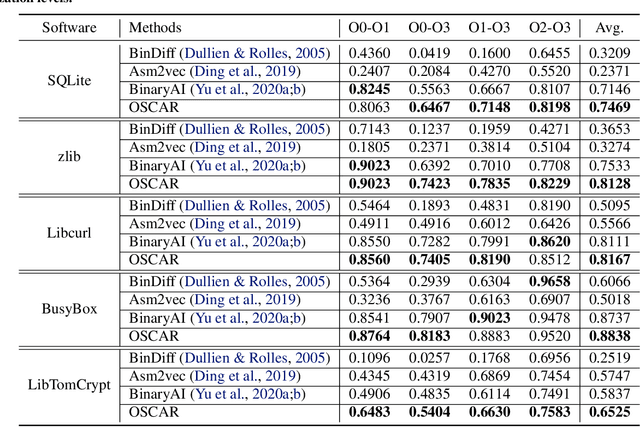


Semantic understanding of programs is a fundamental problem for programming language processing (PLP). Recent works that learn representations of code based on pre-training techniques in NLP have pushed the frontiers in this direction. However, the semantics of PL and NL have essential differences. These being ignored, we believe it is difficult to build a model to better understand programs, by either directly applying off-the-shelf NLP pre-training techniques to the source code, or adding features to the model by the heuristic. In fact, the semantics of a program can be rigorously defined by formal semantics in PL theory. For example, the operational semantics, describes the meaning of a valid program as updating the environment (i.e., the memory address-value function) through fundamental operations, such as memory I/O and conditional branching. Inspired by this, we propose a novel program semantics learning paradigm, that the model should learn from information composed of (1) the representations which align well with the fundamental operations in operational semantics, and (2) the information of environment transition, which is indispensable for program understanding. To validate our proposal, we present a hierarchical Transformer-based pre-training model called OSCAR to better facilitate the understanding of programs. OSCAR learns from intermediate representation (IR) and an encoded representation derived from static analysis, which are used for representing the fundamental operations and approximating the environment transitions respectively. OSCAR empirically shows the outstanding capability of program semantics understanding on many practical software engineering tasks.
DeepHyperion: Exploring the Feature Space of Deep Learning-Based Systems through Illumination Search
Jul 05, 2021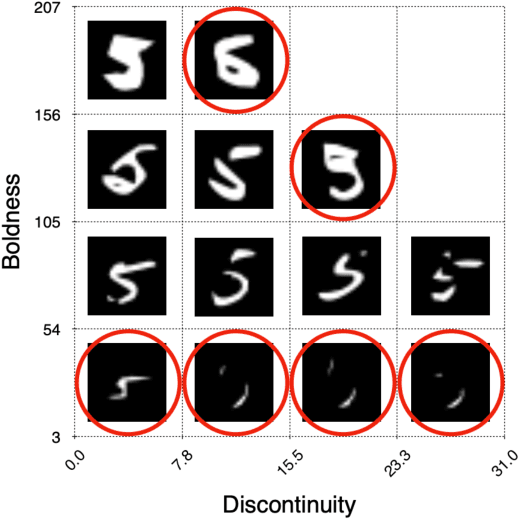
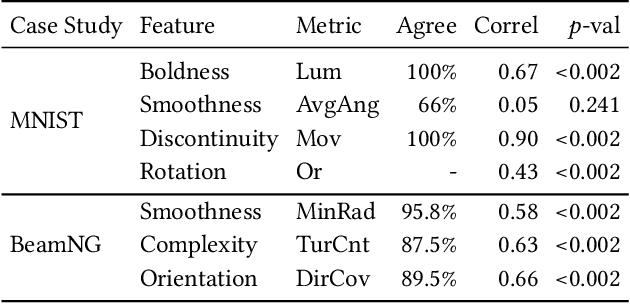
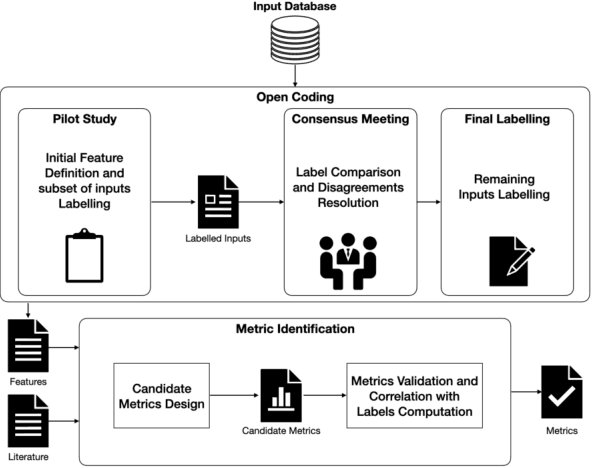
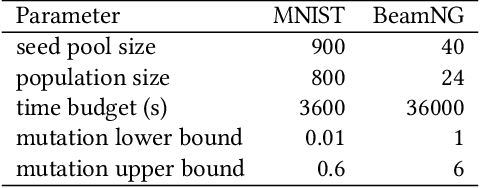
Deep Learning (DL) has been successfully applied to a wide range of application domains, including safety-critical ones. Several DL testing approaches have been recently proposed in the literature but none of them aims to assess how different interpretable features of the generated inputs affect the system's behaviour. In this paper, we resort to Illumination Search to find the highest-performing test cases (i.e., misbehaving and closest to misbehaving), spread across the cells of a map representing the feature space of the system. We introduce a methodology that guides the users of our approach in the tasks of identifying and quantifying the dimensions of the feature space for a given domain. We developed DeepHyperion, a search-based tool for DL systems that illuminates, i.e., explores at large, the feature space, by providing developers with an interpretable feature map where automatically generated inputs are placed along with information about the exposed behaviours.