 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Featurized Density Ratio Estimation
Jul 05, 2021
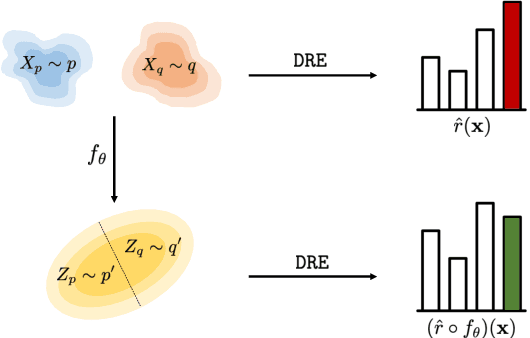

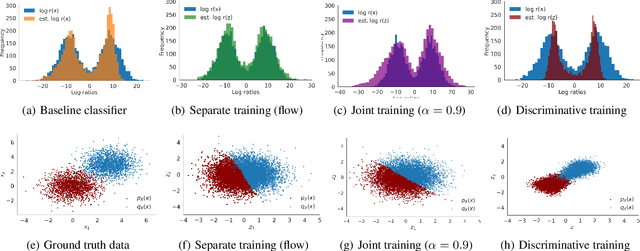
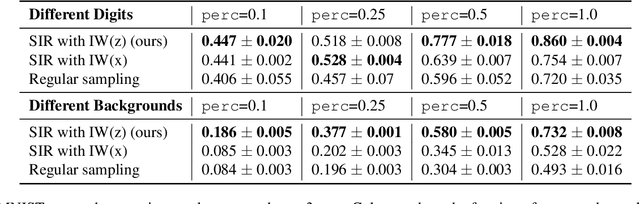
Density ratio estimation serves as an important technique in the unsupervised machine learning toolbox. However, such ratios are difficult to estimate for complex, high-dimensional data, particularly when the densities of interest are sufficiently different. In our work, we propose to leverage an invertible generative model to map the two distributions into a common feature space prior to estimation. This featurization brings the densities closer together in latent space, sidestepping pathological scenarios where the learned density ratios in input space can be arbitrarily inaccurate. At the same time, the invertibility of our feature map guarantees that the ratios computed in feature space are equivalent to those in input space. Empirically, we demonstrate the efficacy of our approach in a variety of downstream tasks that require access to accurate density ratios such as mutual information estimation, targeted sampling in deep generative models, and classification with data augmentation.
Conditional Identity Disentanglement for Differential Face Morph Detection
Jul 05, 2021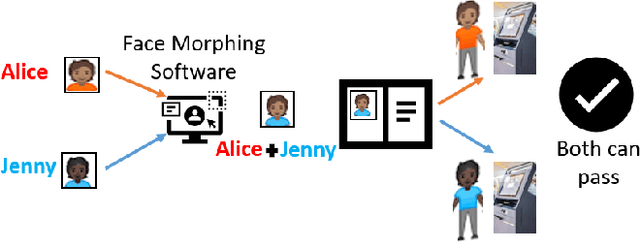
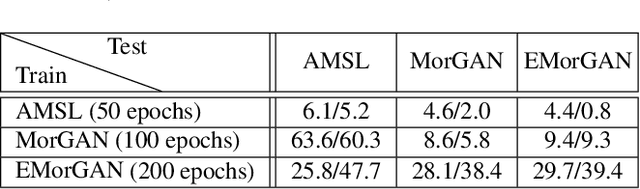

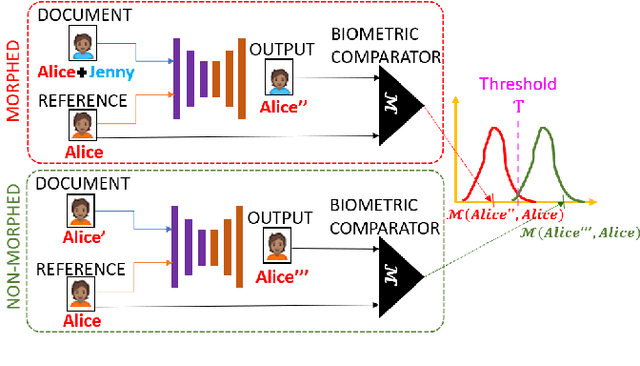
We present the task of differential face morph attack detection using a conditional generative network (cGAN). To determine whether a face image in an identification document, such as a passport, is morphed or not, we propose an algorithm that learns to implicitly disentangle identities from the morphed image conditioned on the trusted reference image using the cGAN. Furthermore, the proposed method can also recover some underlying information about the second subject used in generating the morph. We performed experiments on AMSL face morph, MorGAN, and EMorGAN datasets to demonstrate the effectiveness of the proposed method. We also conducted cross-dataset and cross-attack detection experiments. We obtained promising results of 3% BPCER @ 10% APCER on intra-dataset evaluation, which is comparable to existing methods; and 4.6% BPCER @ 10% APCER on cross-dataset evaluation, which outperforms state-of-the-art methods by at least 13.9%.
Manipulating Identical Filter Redundancy for Efficient Pruning on Deep and Complicated CNN
Jul 30, 2021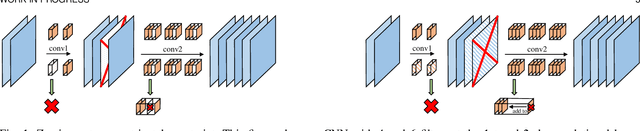
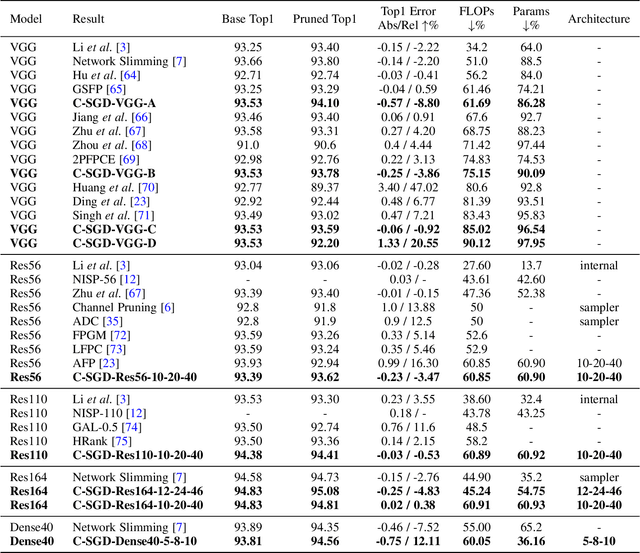
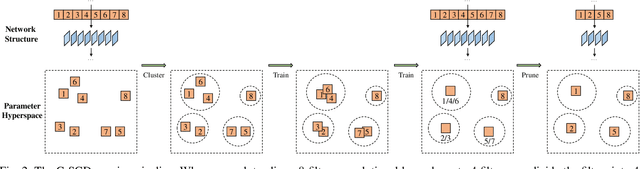
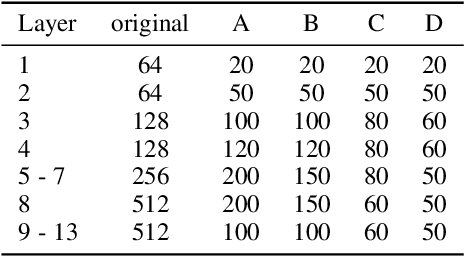
The existence of redundancy in Convolutional Neural Networks (CNNs) enables us to remove some filters/channels with acceptable performance drops. However, the training objective of CNNs usually tends to minimize an accuracy-related loss function without any attention paid to the redundancy, making the redundancy distribute randomly on all the filters, such that removing any of them may trigger information loss and accuracy drop, necessitating a following finetuning step for recovery. In this paper, we propose to manipulate the redundancy during training to facilitate network pruning. To this end, we propose a novel Centripetal SGD (C-SGD) to make some filters identical, resulting in ideal redundancy patterns, as such filters become purely redundant due to their duplicates; hence removing them does not harm the network. As shown on CIFAR and ImageNet, C-SGD delivers better performance because the redundancy is better organized, compared to the existing methods. The efficiency also characterizes C-SGD because it is as fast as regular SGD, requires no finetuning, and can be conducted simultaneously on all the layers even in very deep CNNs. Besides, C-SGD can improve the accuracy of CNNs by first training a model with the same architecture but wider layers then squeezing it into the original width.
Simplified Data Wrangling with ir_datasets
Mar 03, 2021


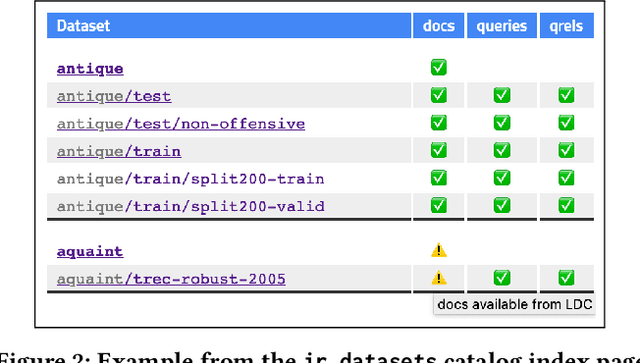
Managing the data for Information Retrieval (IR) experiments can be challenging. Dataset documentation is scattered across the Internet and once one obtains a copy of the data, there are numerous different data formats to work with. Even basic formats can have subtle dataset-specific nuances that need to be considered for proper use. To help mitigate these challenges, we introduce a new robust and lightweight tool (ir_datases) for acquiring, managing, and performing typical operations over datasets used in IR. We primarily focus on textual datasets used for ad-hoc search. This tool provides both a python and command line interface to numerous IR datasets and benchmarks. To our knowledge, this is the most extensive tool of its kind. Integrations with popular IR indexing and experimentation toolkits demonstrate the tool's utility. We also provide documentation of these datasets through the ir_datasets catalog: https://ir-datasets.com/. The catalog acts as a hub for information on datasets used in IR, providing core information about what data each benchmark provides as well as links to more detailed information. We welcome community contributions and intend to continue to maintain and grow this tool.
Tackling COVID-19 Infodemic using Deep Learning
Jul 01, 2021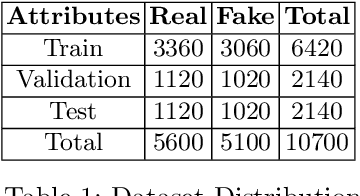

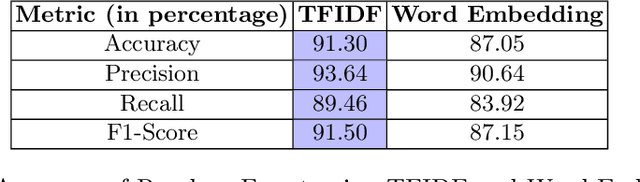
Humanity is battling one of the most deleterious virus in modern history, the COVID-19 pandemic, but along with the pandemic there's an infodemic permeating the pupil and society with misinformation which exacerbates the current malady. We try to detect and classify fake news on online media to detect fake information relating to COVID-19 and coronavirus. The dataset contained fake posts, articles and news gathered from fact checking websites like politifact whereas real tweets were taken from verified twitter handles. We incorporated multiple conventional classification techniques like Naive Bayes, KNN, Gradient Boost and Random Forest along with Deep learning approaches, specifically CNN, RNN, DNN and the ensemble model RMDL. We analyzed these approaches with two feature extraction techniques, TF-IDF and GloVe Word Embeddings which would provide deeper insights into the dataset containing COVID-19 info on online media.
Bayesian Error-in-Variables Models for the Identification of Power Networks
Jul 09, 2021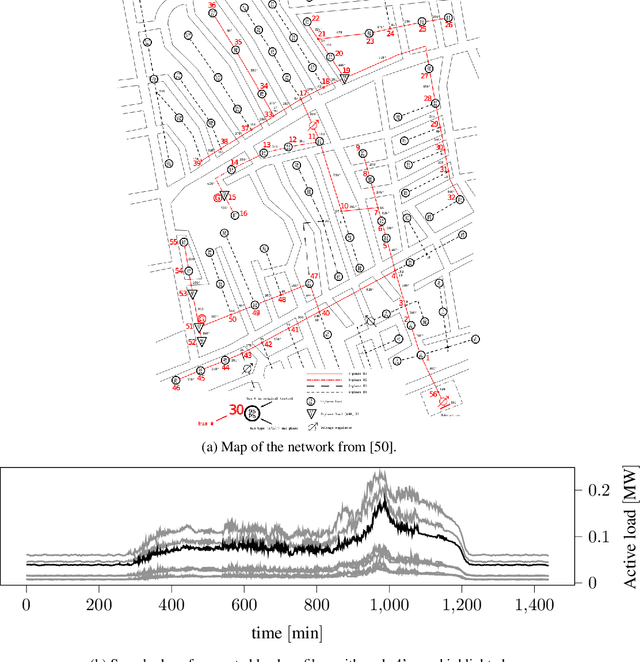

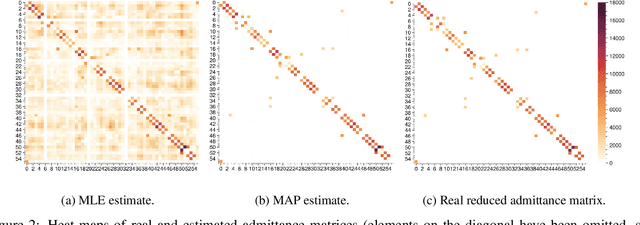
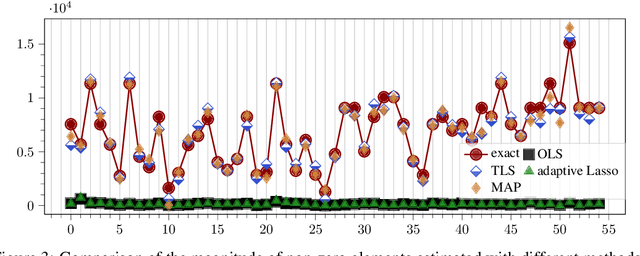
The increasing integration of intermittent renewable generation, especially at the distribution level,necessitates advanced planning and optimisation methodologies contingent on the knowledge of thegrid, specifically the admittance matrix capturing the topology and line parameters of an electricnetwork. However, a reliable estimate of the admittance matrix may either be missing or quicklybecome obsolete for temporally varying grids. In this work, we propose a data-driven identificationmethod utilising voltage and current measurements collected from micro-PMUs. More precisely,we first present a maximum likelihood approach and then move towards a Bayesian framework,leveraging the principles of maximum a posteriori estimation. In contrast with most existing con-tributions, our approach not only factors in measurement noise on both voltage and current data,but is also capable of exploiting available a priori information such as sparsity patterns and knownline parameters. Simulations conducted on benchmark cases demonstrate that, compared to otheralgorithms, our method can achieve significantly greater accuracy.
LiDAR-based Recurrent 3D Semantic Segmentation with Temporal Memory Alignment
Mar 03, 2021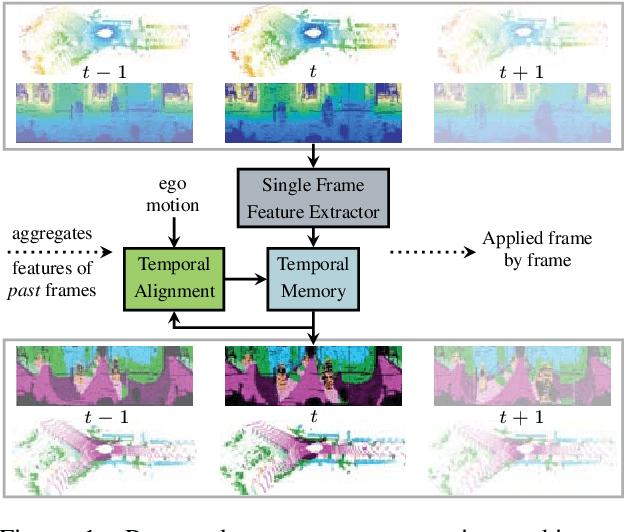
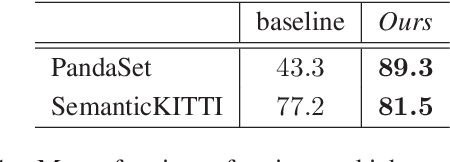
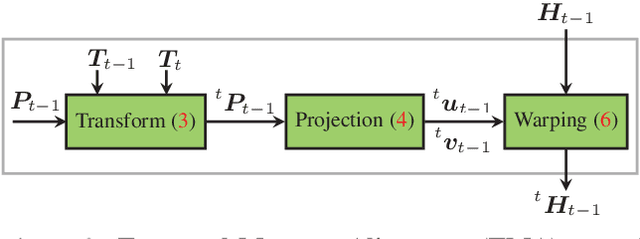
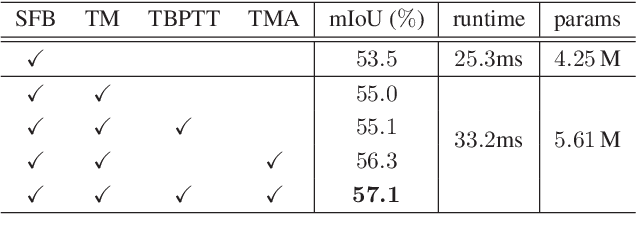
Understanding and interpreting a 3d environment is a key challenge for autonomous vehicles. Semantic segmentation of 3d point clouds combines 3d information with semantics and thereby provides a valuable contribution to this task. In many real-world applications, point clouds are generated by lidar sensors in a consecutive fashion. Working with a time series instead of single and independent frames enables the exploitation of temporal information. We therefore propose a recurrent segmentation architecture (RNN), which takes a single range image frame as input and exploits recursively aggregated temporal information. An alignment strategy, which we call Temporal Memory Alignment, uses ego motion to temporally align the memory between consecutive frames in feature space. A Residual Network and ConvGRU are investigated for the memory update. We demonstrate the benefits of the presented approach on two large-scale datasets and compare it to several stateof-the-art methods. Our approach ranks first on the SemanticKITTI multiple scan benchmark and achieves state-of-the-art performance on the single scan benchmark. In addition, the evaluation shows that the exploitation of temporal information significantly improves segmentation results compared to a single frame approach.
Enhancing Social Relation Inference with Concise Interaction Graph and Discriminative Scene Representation
Jul 30, 2021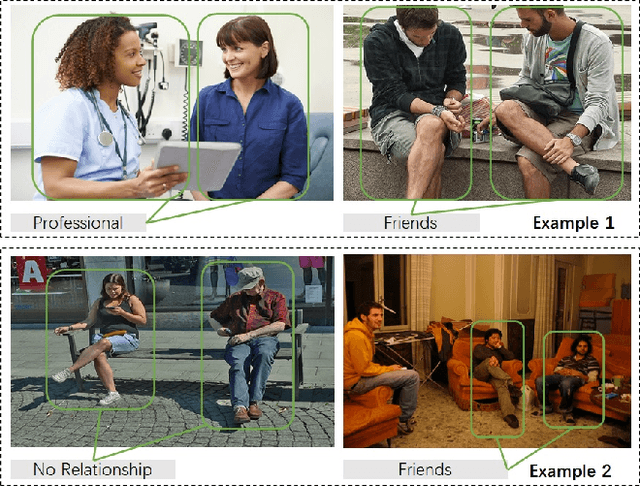
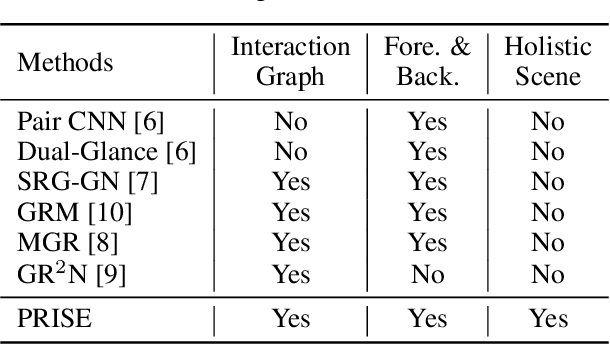
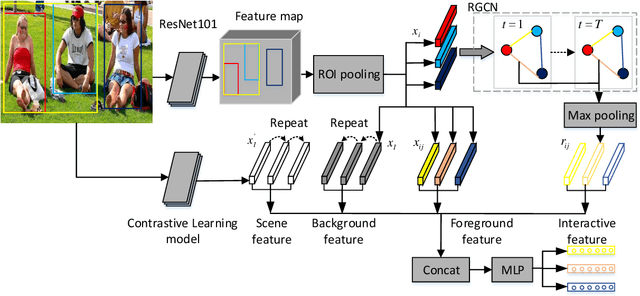
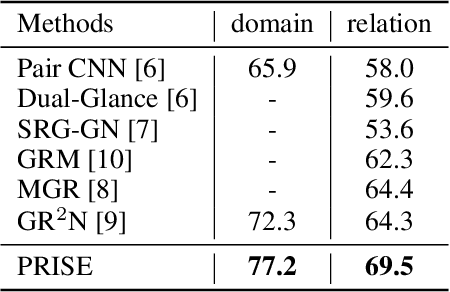
There has been a recent surge of research interest in attacking the problem of social relation inference based on images. Existing works classify social relations mainly by creating complicated graphs of human interactions, or learning the foreground and/or background information of persons and objects, but ignore holistic scene context. The holistic scene refers to the functionality of a place in images, such as dinning room, playground and office. In this paper, by mimicking human understanding on images, we propose an approach of \textbf{PR}actical \textbf{I}nference in \textbf{S}ocial r\textbf{E}lation (PRISE), which concisely learns interactive features of persons and discriminative features of holistic scenes. Technically, we develop a simple and fast relational graph convolutional network to capture interactive features of all persons in one image. To learn the holistic scene feature, we elaborately design a contrastive learning task based on image scene classification. To further boost the performance in social relation inference, we collect and distribute a new large-scale dataset, which consists of about 240 thousand unlabeled images. The extensive experimental results show that our novel learning framework significantly beats the state-of-the-art methods, e.g., PRISE achieves 6.8$\%$ improvement for domain classification in PIPA dataset.
On Parameter Optimization and Reach Enhancement for the Improved Soft-Aided Staircase Decoder
May 12, 2021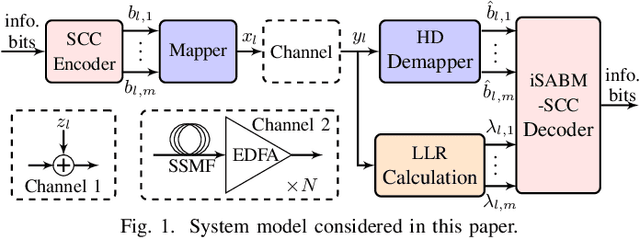
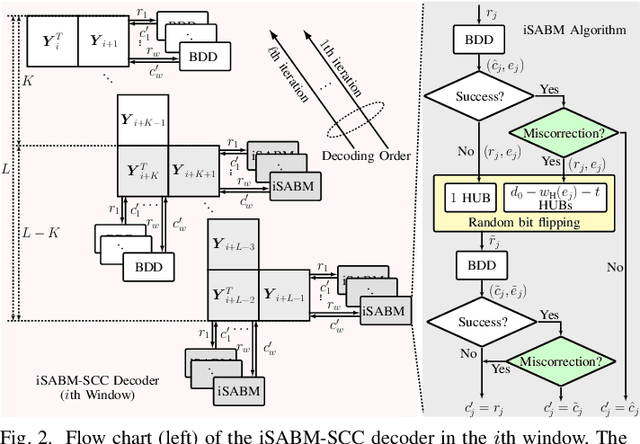
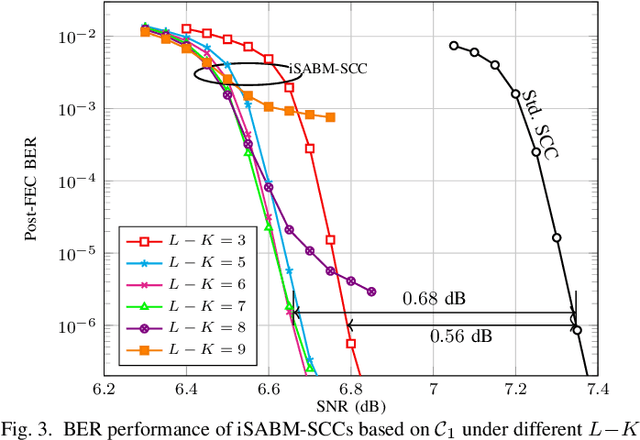
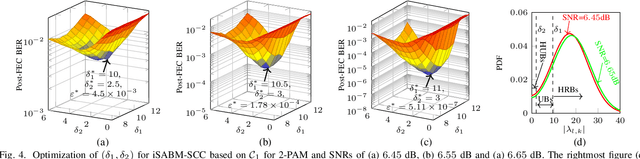
The so-called improved soft-aided bit-marking algorithm was recently proposed for staircase codes (SCCs) in the context of fiber optical communications. This algorithm is known as iSABM-SCC. With the help of channel soft information, the iSABM-SCC decoder marks bits via thresholds to deal with both miscorrections and failures of hard-decision (HD) decoding. In this paper, we study iSABM-SCC focusing on the parameter optimization of the algorithm and its performance analysis, in terms of the gap to the achievable information rates (AIRs) of HD codes and the fiber reach enhancement. We show in this paper that the marking thresholds and the number of modified component decodings heavily affect the performance of iSABM-SCC, and thus, they need to be carefully optimized. By replacing standard decoding with the optimized iSABM-SCC decoding, the gap to the AIRs of HD codes can be reduced to 0.26-1.02 dB for code rates of 0.74-0.87 in the additive white Gaussian noise channel with 8-ary pulse amplitude modulation. The obtained reach increase is up to 22% for data rates between 401 Gbps and 468 Gbps in an optical fiber channel.
Understanding the Distributions of Aggregation Layers in Deep Neural Networks
Jul 09, 2021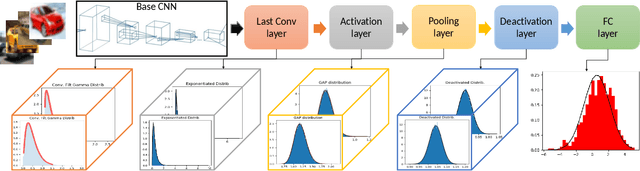

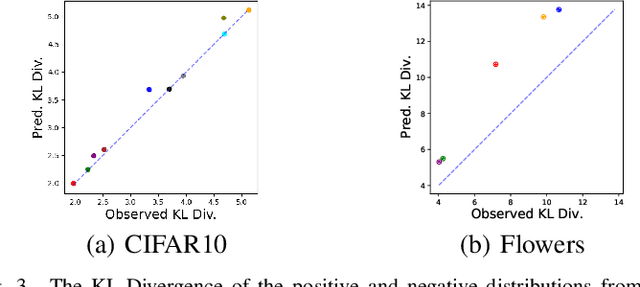
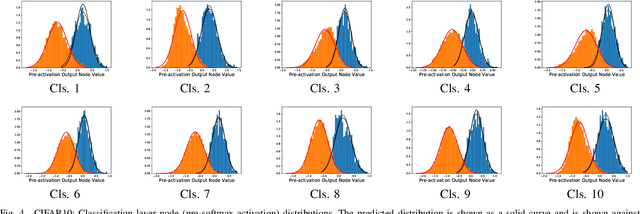
The process of aggregation is ubiquitous in almost all deep nets models. It functions as an important mechanism for consolidating deep features into a more compact representation, whilst increasing robustness to overfitting and providing spatial invariance in deep nets. In particular, the proximity of global aggregation layers to the output layers of DNNs mean that aggregated features have a direct influence on the performance of a deep net. A better understanding of this relationship can be obtained using information theoretic methods. However, this requires the knowledge of the distributions of the activations of aggregation layers. To achieve this, we propose a novel mathematical formulation for analytically modelling the probability distributions of output values of layers involved with deep feature aggregation. An important outcome is our ability to analytically predict the KL-divergence of output nodes in a DNN. We also experimentally verify our theoretical predictions against empirical observations across a range of different classification tasks and datasets.