 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Novel Deep ML Architecture by Integrating Visual Simultaneous Localization and Mapping (vSLAM) into Mask R-CNN for Real-time Surgical Video Analysis
Mar 31, 2021
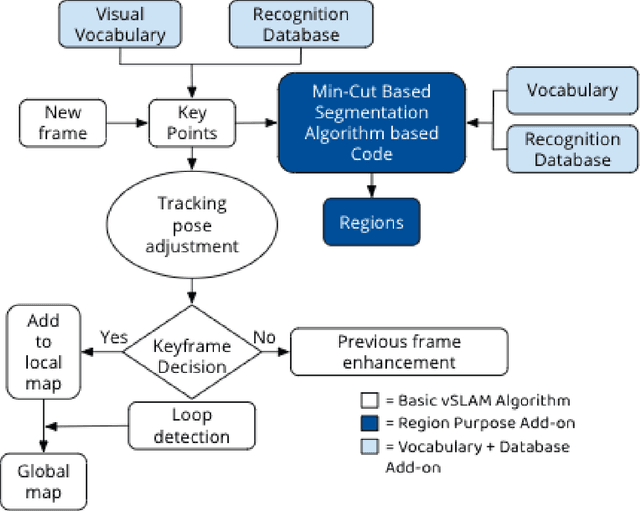
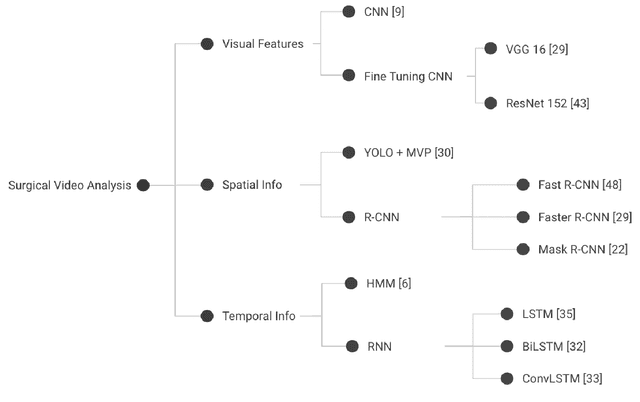
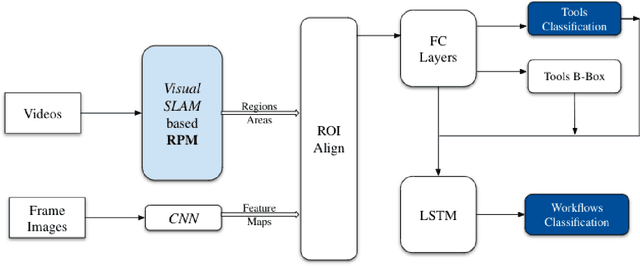
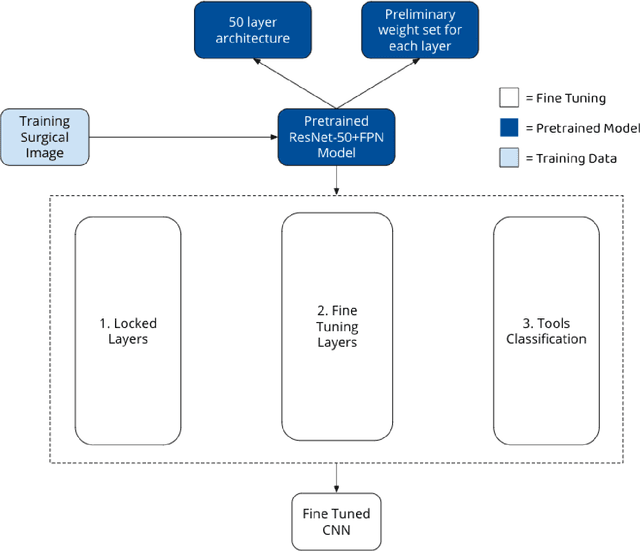
Seven million people suffer complications after surgery each year. With sufficient surgical training and feedback, half of these complications could be prevented. Automatic surgical video analysis, especially for minimally invasive surgery, plays a key role in training and review, with increasing interests from recent studies on tool and workflow detection. In this research, a novel machine learning architecture, RPM-CNN, is created to perform real-time surgical video analysis. This architecture, for the first time, integrates visual simultaneous localization and mapping (vSLAM) into Mask R-CNN. Spatio-temporal information, in addition to the visual features, is utilized to increase the accuracy to 96.8 mAP for tool detection and 97.5 mean Jaccard for workflow detection, surpassing all previous works via the same benchmark dataset. As a real-time prediction, the RPM-CNN model reaches a 50 FPS runtime performance speed, 10x faster than region based CNN, by modeling the spatio-temporal information directly from surgical videos during the vSLAM 3D mapping. Additionally, this novel Region Proposal Module (RPM) replaces the region proposal network (RPN) in Mask R-CNN, accurately placing bounding-boxes and lessening the annotation requirement. In principle, this architecture integrates the best of both worlds, inclusive of 1) vSLAM on object detection, through focusing on geometric information for region proposals and 2) CNN on object recognition, through focusing on semantic information for image classification; the integration of these two technologies into one joint training process opens a new door in computer vision. Furthermore, to apply RPM-CNN's real-time top performance to the real world, a Microsoft HoloLens 2 application is developed to provide an augmented reality (AR) based solution for both surgical training and assistance.
Hybrid Reasoning Network for Video-based Commonsense Captioning
Aug 05, 2021The task of video-based commonsense captioning aims to generate event-wise captions and meanwhile provide multiple commonsense descriptions (e.g., attribute, effect and intention) about the underlying event in the video. Prior works explore the commonsense captions by using separate networks for different commonsense types, which is time-consuming and lacks mining the interaction of different commonsense. In this paper, we propose a Hybrid Reasoning Network (HybridNet) to endow the neural networks with the capability of semantic-level reasoning and word-level reasoning. Firstly, we develop multi-commonsense learning for semantic-level reasoning by jointly training different commonsense types in a unified network, which encourages the interaction between the clues of multiple commonsense descriptions, event-wise captions and videos. Then, there are two steps to achieve the word-level reasoning: (1) a memory module records the history predicted sequence from the previous generation processes; (2) a memory-routed multi-head attention (MMHA) module updates the word-level attention maps by incorporating the history information from the memory module into the transformer decoder for word-level reasoning. Moreover, the multimodal features are used to make full use of diverse knowledge for commonsense reasoning. Experiments and abundant analysis on the large-scale Video-to-Commonsense benchmark show that our HybridNet achieves state-of-the-art performance compared with other methods.
High-resolution Depth Maps Imaging via Attention-based Hierarchical Multi-modal Fusion
Apr 13, 2021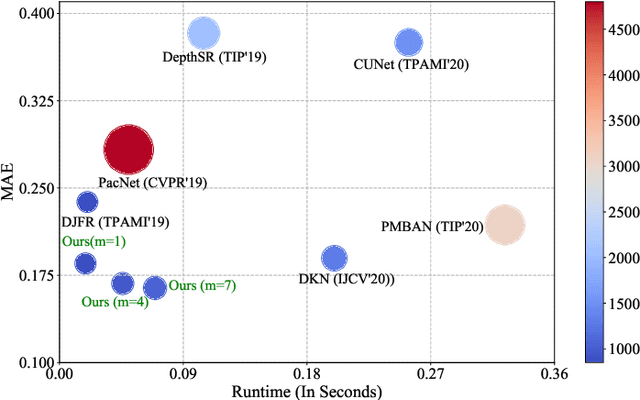

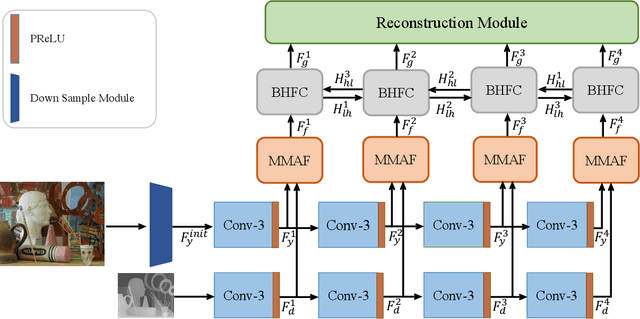
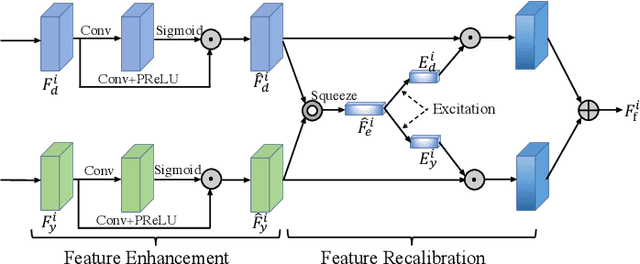
Depth map records distance between the viewpoint and objects in the scene, which plays a critical role in many real-world applications. However, depth map captured by consumer-grade RGB-D cameras suffers from low spatial resolution. Guided depth map super-resolution (DSR) is a popular approach to address this problem, which attempts to restore a high-resolution (HR) depth map from the input low-resolution (LR) depth and its coupled HR RGB image that serves as the guidance. The most challenging problems for guided DSR are how to correctly select consistent structures and propagate them, and properly handle inconsistent ones. In this paper, we propose a novel attention-based hierarchical multi-modal fusion (AHMF) network for guided DSR. Specifically, to effectively extract and combine relevant information from LR depth and HR guidance, we propose a multi-modal attention based fusion (MMAF) strategy for hierarchical convolutional layers, including a feature enhance block to select valuable features and a feature recalibration block to unify the similarity metrics of modalities with different appearance characteristics. Furthermore, we propose a bi-directional hierarchical feature collaboration (BHFC) module to fully leverage low-level spatial information and high-level structure information among multi-scale features. Experimental results show that our approach outperforms state-of-the-art methods in terms of reconstruction accuracy, running speed and memory efficiency.
Analysing Errors of Open Information Extraction Systems
Jul 24, 2017
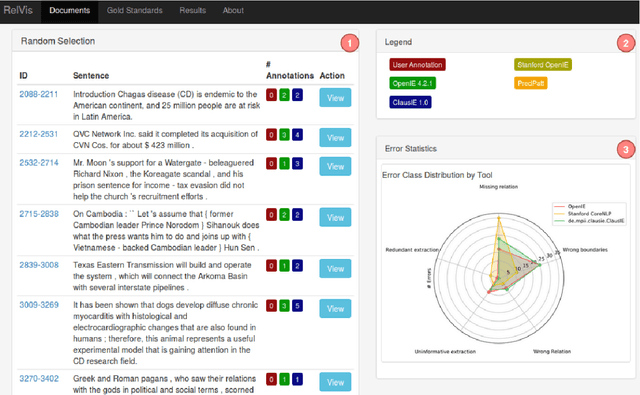
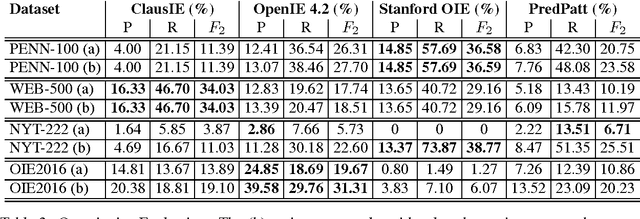
We report results on benchmarking Open Information Extraction (OIE) systems using RelVis, a toolkit for benchmarking Open Information Extraction systems. Our comprehensive benchmark contains three data sets from the news domain and one data set from Wikipedia with overall 4522 labeled sentences and 11243 binary or n-ary OIE relations. In our analysis on these data sets we compared the performance of four popular OIE systems, ClausIE, OpenIE 4.2, Stanford OpenIE and PredPatt. In addition, we evaluated the impact of five common error classes on a subset of 749 n-ary tuples. From our deep analysis we unreveal important research directions for a next generation of OIE systems.
Evading the Simplicity Bias: Training a Diverse Set of Models Discovers Solutions with Superior OOD Generalization
May 12, 2021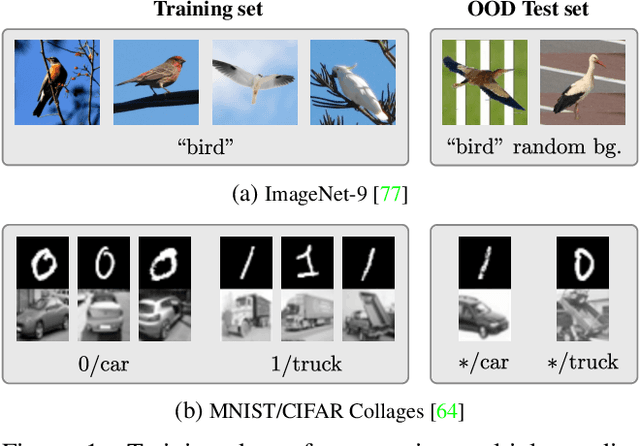
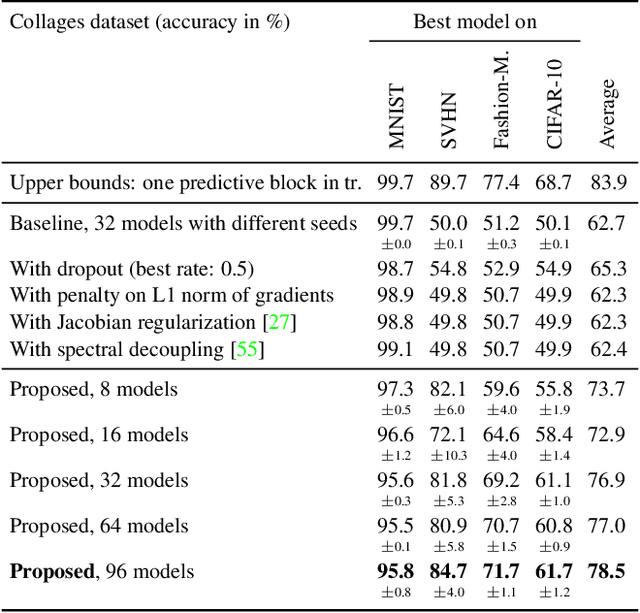
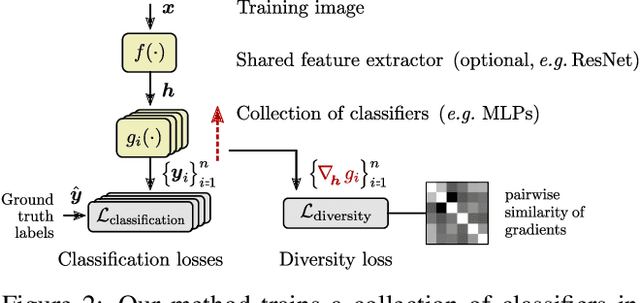
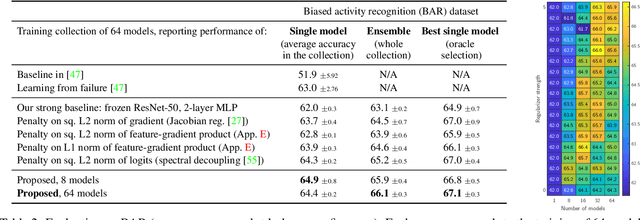
Neural networks trained with SGD were recently shown to rely preferentially on linearly-predictive features and can ignore complex, equally-predictive ones. This simplicity bias can explain their lack of robustness out of distribution (OOD). The more complex the task to learn, the more likely it is that statistical artifacts (i.e. selection biases, spurious correlations) are simpler than the mechanisms to learn. We demonstrate that the simplicity bias can be mitigated and OOD generalization improved. We train a set of similar models to fit the data in different ways using a penalty on the alignment of their input gradients. We show theoretically and empirically that this induces the learning of more complex predictive patterns. OOD generalization fundamentally requires information beyond i.i.d. examples, such as multiple training environments, counterfactual examples, or other side information. Our approach shows that we can defer this requirement to an independent model selection stage. We obtain SOTA results in visual recognition on biased data and generalization across visual domains. The method - the first to evade the simplicity bias - highlights the need for a better understanding and control of inductive biases in deep learning.
One Backward from Ten Forward, Subsampling for Large-Scale Deep Learning
Apr 27, 2021
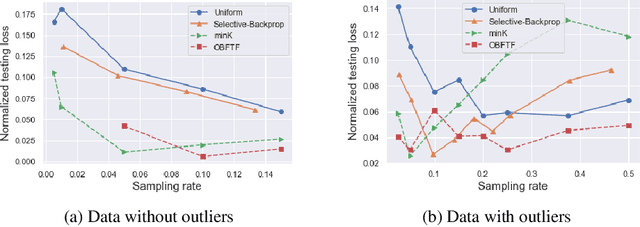

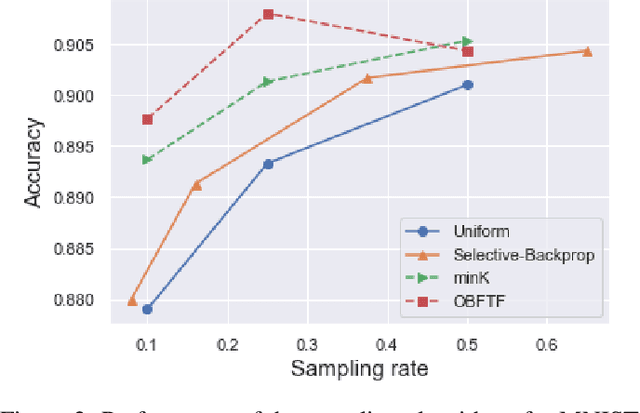
Deep learning models in large-scale machine learning systems are often continuously trained with enormous data from production environments. The sheer volume of streaming training data poses a significant challenge to real-time training subsystems and ad-hoc sampling is the standard practice. Our key insight is that these deployed ML systems continuously perform forward passes on data instances during inference, but ad-hoc sampling does not take advantage of this substantial computational effort. Therefore, we propose to record a constant amount of information per instance from these forward passes. The extra information measurably improves the selection of which data instances should participate in forward and backward passes. A novel optimization framework is proposed to analyze this problem and we provide an efficient approximation algorithm under the framework of Mini-batch gradient descent as a practical solution. We also demonstrate the effectiveness of our framework and algorithm on several large-scale classification and regression tasks, when compared with competitive baselines widely used in industry.
Active Visual SLAM with independently rotating camera
May 19, 2021
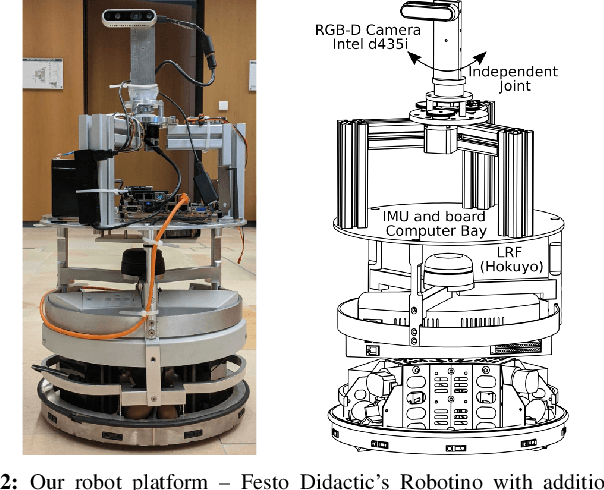
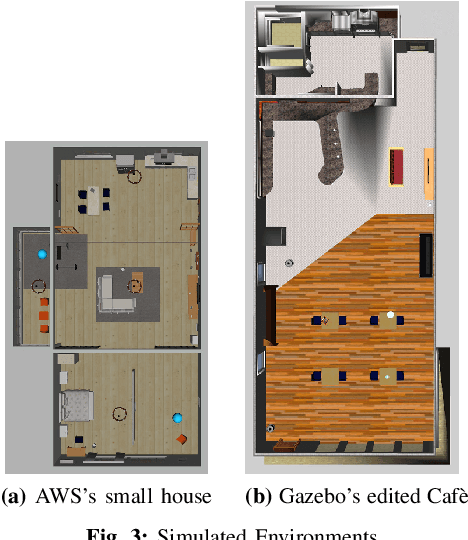
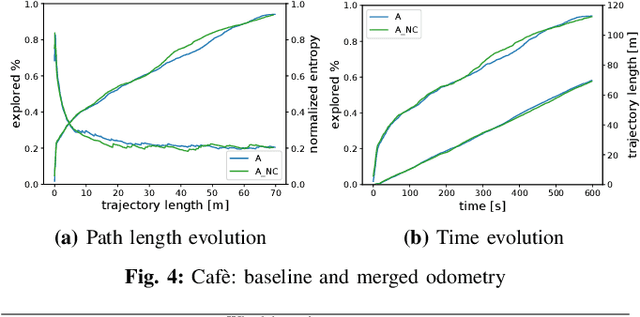
In active Visual-SLAM (V-SLAM), a robot relies on the information retrieved by its cameras to control its own movements for autonomous mapping of the environment. Cameras are usually statically linked to the robot's body, limiting the extra degrees of freedom for visual information acquisition. In this work, we overcome the aforementioned problem by introducing and leveraging an independently rotating camera on the robot base. This enables us to continuously control the heading of the camera, obtaining the desired optimal orientation for active V-SLAM, without rotating the robot itself. However, this additional degree of freedom introduces additional estimation uncertainties, which need to be accounted for. We do this by extending our robot's state estimate to include the camera state and jointly estimate the uncertainties. We develop our method based on a state-of-the-art active V-SLAM approach for omnidirectional robots, and evaluate it through rigorous simulation and real robot experiments. We obtain more accurate maps, with lower energy consumption, while maintaining the benefits of the active approach with respect to the baseline. We also demonstrate how our method easily generalizes to other non-omnidirectional robotic platforms, which was a limitation of the previous approach. Code and implementation details are provided as open-source.
Money on the Table: Statistical information ignored by Softmax can improve classifier accuracy
Jan 26, 2019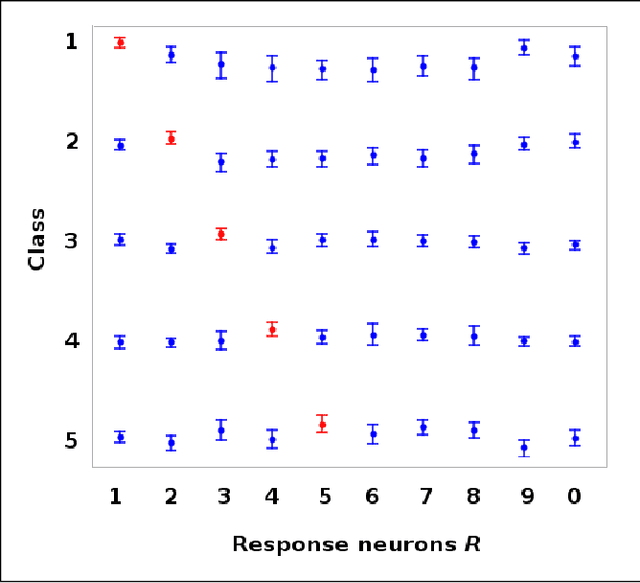
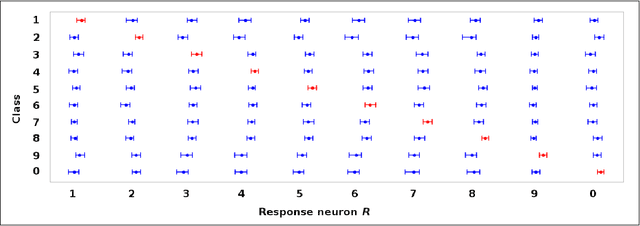
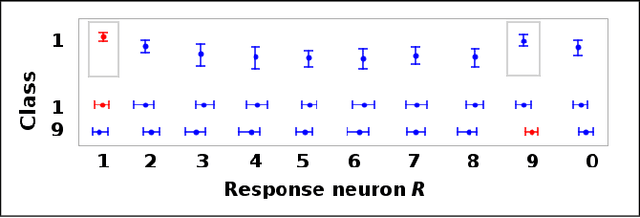
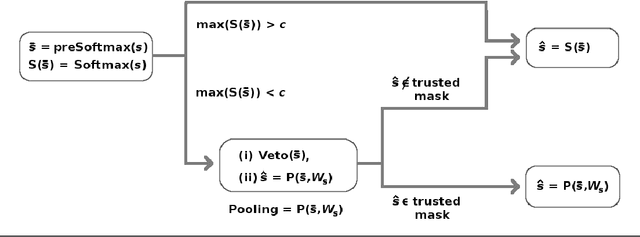
Softmax is a standard final layer used in Neural Nets (NNs) to summarize information encoded in the trained NN and return a prediction. However, Softmax leverages only a subset of the class-specific structure encoded in the trained model and ignores potentially valuable information: During training, models encode an array $D$ of class response distributions, where $D_{ij}$ is the distribution of the $j^{th}$ pre-Softmax readout neuron's responses to the $i^{th}$ class. Given a test sample, Softmax implicitly uses only the row of this array $D$ that corresponds to the readout neurons' responses to the sample's true class. Leveraging more of this array $D$ can improve classifier accuracy, because the likelihoods of two competing classes can be encoded in other rows of $D$. To explore this potential resource, we develop a hybrid classifier (Softmax-Pooling Hybrid, $SPH$) that uses Softmax on high-scoring samples, but on low-scoring samples uses a log-likelihood method that pools the information from the full array $D$. We apply $SPH$ to models trained on a vectorized MNIST dataset to varying levels of accuracy. $SPH$ replaces only the final Softmax layer in the trained NN, at test time only. All training is the same as for Softmax. Because the pooling classifier performs better than Softmax on low-scoring samples, $SPH$ reduces test set error by 6% to 23%, using the exact same trained model, whatever the baseline Softmax accuracy. This reduction in error reflects hidden capacity of the trained NN that is left unused by Softmax.
Featurized Density Ratio Estimation
Jul 05, 2021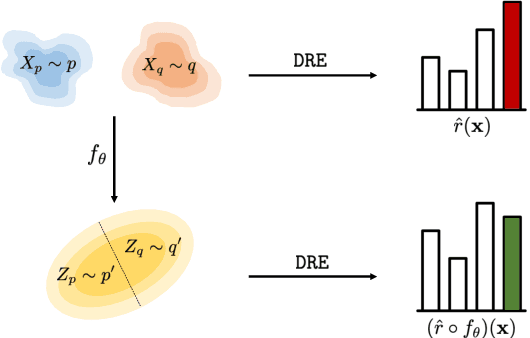

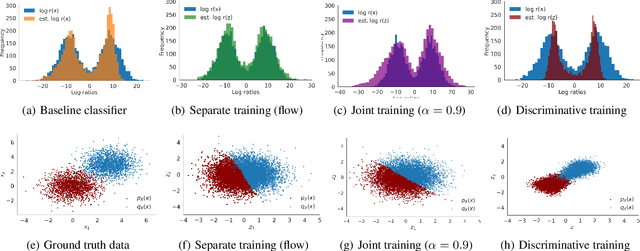
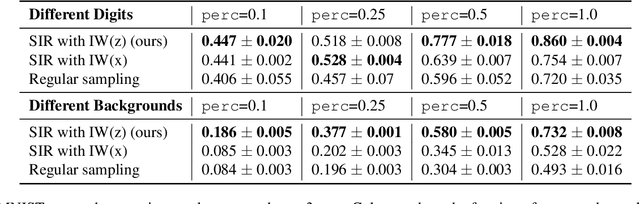
Density ratio estimation serves as an important technique in the unsupervised machine learning toolbox. However, such ratios are difficult to estimate for complex, high-dimensional data, particularly when the densities of interest are sufficiently different. In our work, we propose to leverage an invertible generative model to map the two distributions into a common feature space prior to estimation. This featurization brings the densities closer together in latent space, sidestepping pathological scenarios where the learned density ratios in input space can be arbitrarily inaccurate. At the same time, the invertibility of our feature map guarantees that the ratios computed in feature space are equivalent to those in input space. Empirically, we demonstrate the efficacy of our approach in a variety of downstream tasks that require access to accurate density ratios such as mutual information estimation, targeted sampling in deep generative models, and classification with data augmentation.
Manipulating Identical Filter Redundancy for Efficient Pruning on Deep and Complicated CNN
Jul 30, 2021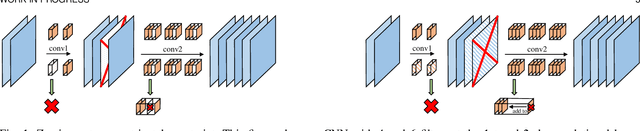
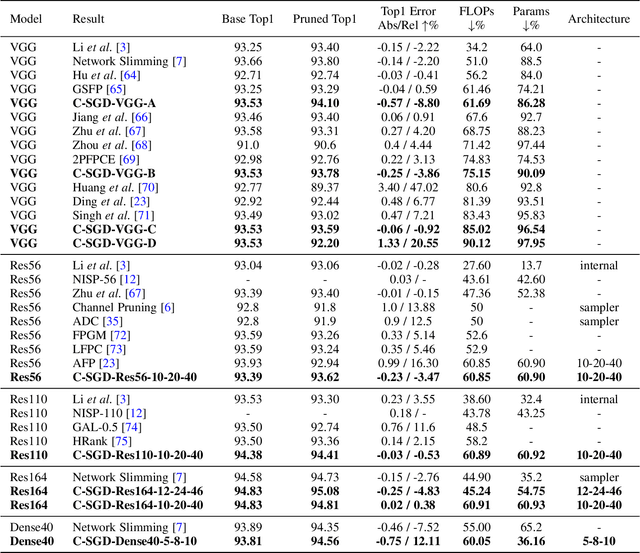
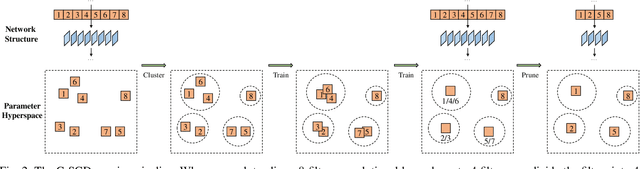
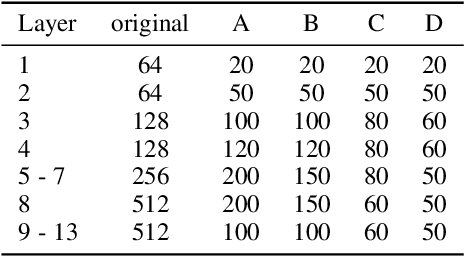
The existence of redundancy in Convolutional Neural Networks (CNNs) enables us to remove some filters/channels with acceptable performance drops. However, the training objective of CNNs usually tends to minimize an accuracy-related loss function without any attention paid to the redundancy, making the redundancy distribute randomly on all the filters, such that removing any of them may trigger information loss and accuracy drop, necessitating a following finetuning step for recovery. In this paper, we propose to manipulate the redundancy during training to facilitate network pruning. To this end, we propose a novel Centripetal SGD (C-SGD) to make some filters identical, resulting in ideal redundancy patterns, as such filters become purely redundant due to their duplicates; hence removing them does not harm the network. As shown on CIFAR and ImageNet, C-SGD delivers better performance because the redundancy is better organized, compared to the existing methods. The efficiency also characterizes C-SGD because it is as fast as regular SGD, requires no finetuning, and can be conducted simultaneously on all the layers even in very deep CNNs. Besides, C-SGD can improve the accuracy of CNNs by first training a model with the same architecture but wider layers then squeezing it into the original width.