 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A maximum entropy model of bounded rational decision-making with prior beliefs and market feedback
Feb 18, 2021
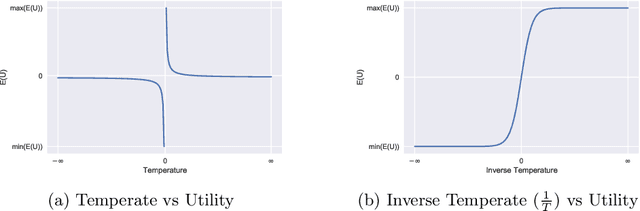
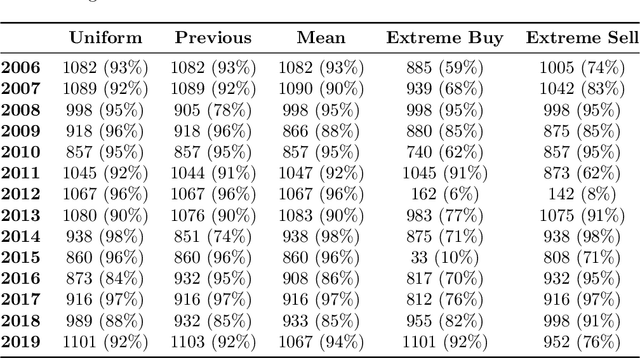
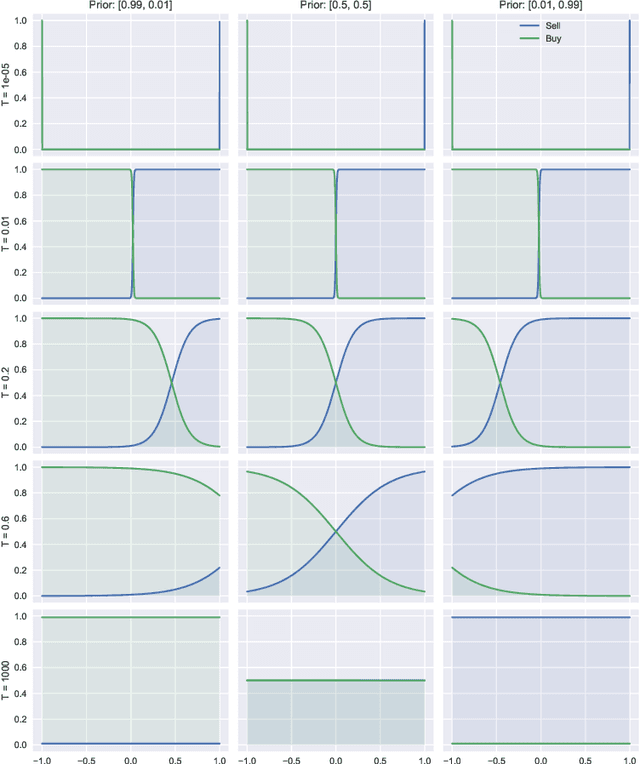
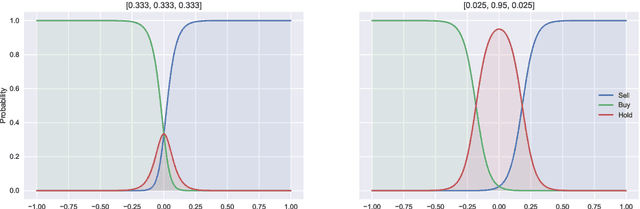
Bounded rationality is an important consideration stemming from the fact that agents often have limits on their processing abilities, making the assumption of perfect rationality inapplicable to many real tasks. We propose an information-theoretic approach to the inference of agent decisions under Smithian competition. The model explicitly captures the boundedness of agents (limited in their information-processing capacity) as the cost of information acquisition for expanding their prior beliefs. The expansion is measured as the Kullblack-Leibler divergence between posterior decisions and prior beliefs. When information acquisition is free, the \textit{homo economicus} agent is recovered, while in cases when information acquisition becomes costly, agents instead revert to their prior beliefs. The maximum entropy principle is used to infer least-biased decisions, based upon the notion of Smithian competition formalised within the Quantal Response Statistical Equilibrium framework. The incorporation of prior beliefs into such a framework allowed us to systematically explore the effects of prior beliefs on decision-making, in the presence of market feedback. We verified the proposed model using Australian housing market data, showing how the incorporation of prior knowledge alters the resulting agent decisions. Specifically, it allowed for the separation (and analysis) of past beliefs and utility maximisation behaviour of the agent.
Multi-modal Residual Perceptron Network for Audio-Video Emotion Recognition
Jul 30, 2021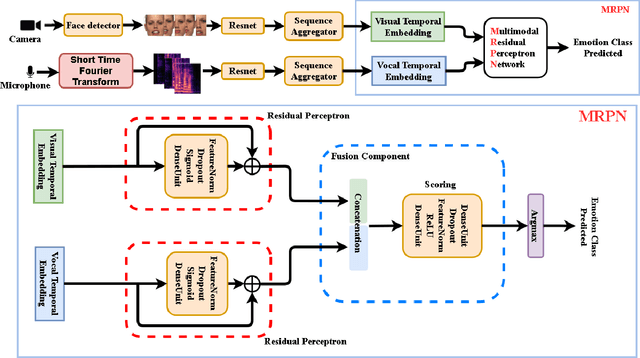
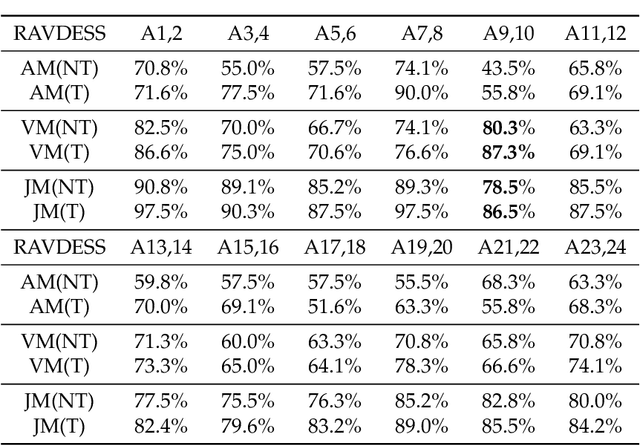

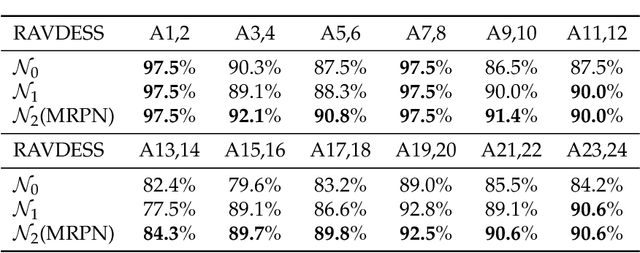
Audio-Video Emotion Recognition is now attacked with Deep Neural Network modeling tools. In published papers, as a rule, the authors show only cases of the superiority in multi-modality over audio-only or video-only modality. However, there are cases superiority in uni-modality can be found. In our research, we hypothesize that for fuzzy categories of emotional events, the within-modal and inter-modal noisy information represented indirectly in the parameters of the modeling neural network impedes better performance in the existing late fusion and end-to-end multi-modal network training strategies. To take advantage and overcome the deficiencies in both solutions, we define a Multi-modal Residual Perceptron Network which performs end-to-end learning from multi-modal network branches, generalizing better multi-modal feature representation. For the proposed Multi-modal Residual Perceptron Network and the novel time augmentation for streaming digital movies, the state-of-art average recognition rate was improved to 91.4% for The Ryerson Audio-Visual Database of Emotional Speech and Song dataset and to 83.15% for Crowd-sourced Emotional multi-modal Actors dataset. Moreover, the Multi-modal Residual Perceptron Network concept shows its potential for multi-modal applications dealing with signal sources not only of optical and acoustical types.
Learning Hierarchical Graph Neural Networks for Image Clustering
Jul 17, 2021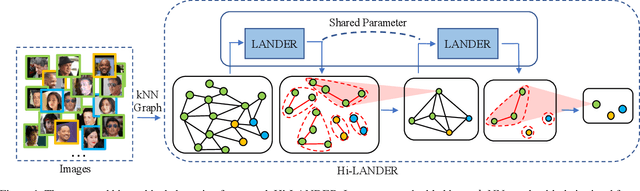
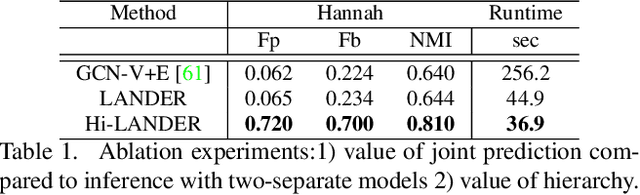
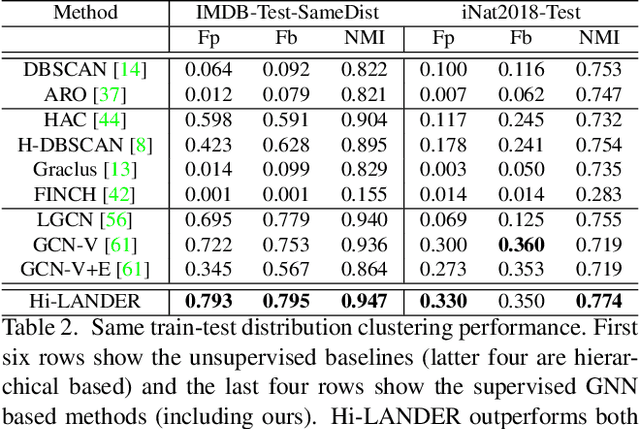
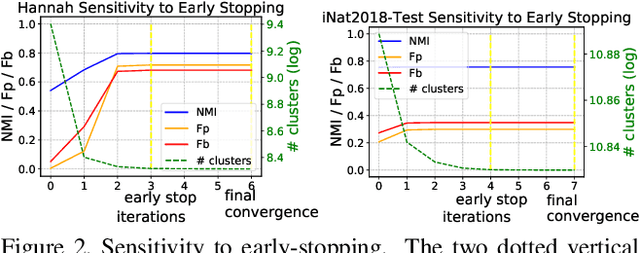
We propose a hierarchical graph neural network (GNN) model that learns how to cluster a set of images into an unknown number of identities using a training set of images annotated with labels belonging to a disjoint set of identities. Our hierarchical GNN uses a novel approach to merge connected components predicted at each level of the hierarchy to form a new graph at the next level. Unlike fully unsupervised hierarchical clustering, the choice of grouping and complexity criteria stems naturally from supervision in the training set. The resulting method, Hi-LANDER, achieves an average of 54% improvement in F-score and 8% increase in Normalized Mutual Information (NMI) relative to current GNN-based clustering algorithms. Additionally, state-of-the-art GNN-based methods rely on separate models to predict linkage probabilities and node densities as intermediate steps of the clustering process. In contrast, our unified framework achieves a seven-fold decrease in computational cost. We release our training and inference code at https://github.com/dmlc/dgl/tree/master/examples/pytorch/hilander.
DS-TransUNet:Dual Swin Transformer U-Net for Medical Image Segmentation
Jun 12, 2021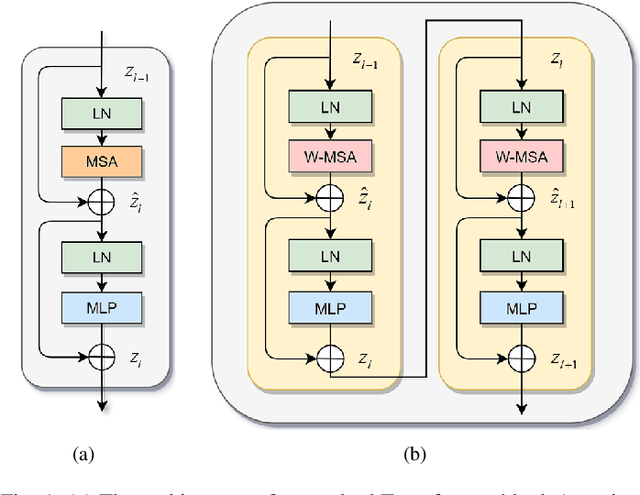
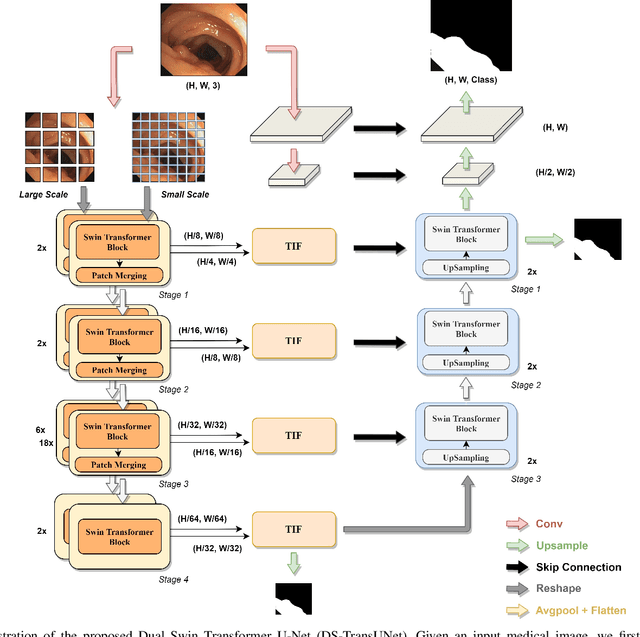
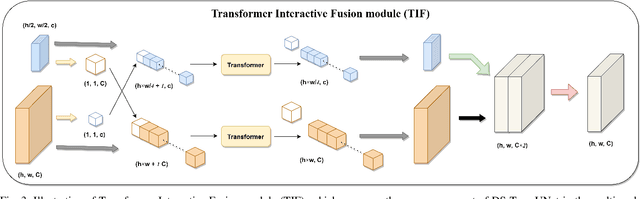

Automatic medical image segmentation has made great progress benefit from the development of deep learning. However, most existing methods are based on convolutional neural networks (CNNs), which fail to build long-range dependencies and global context connections due to the limitation of receptive field in convolution operation. Inspired by the success of Transformer in modeling the long-range contextual information, some researchers have expended considerable efforts in designing the robust variants of Transformer-based U-Net. Moreover, the patch division used in vision transformers usually ignores the pixel-level intrinsic structural features inside each patch. To alleviate these problems, we propose a novel deep medical image segmentation framework called Dual Swin Transformer U-Net (DS-TransUNet), which might be the first attempt to concurrently incorporate the advantages of hierarchical Swin Transformer into both encoder and decoder of the standard U-shaped architecture to enhance the semantic segmentation quality of varying medical images. Unlike many prior Transformer-based solutions, the proposed DS-TransUNet first adopts dual-scale encoder subnetworks based on Swin Transformer to extract the coarse and fine-grained feature representations of different semantic scales. As the core component for our DS-TransUNet, a well-designed Transformer Interactive Fusion (TIF) module is proposed to effectively establish global dependencies between features of different scales through the self-attention mechanism. Furthermore, we also introduce the Swin Transformer block into decoder to further explore the long-range contextual information during the up-sampling process. Extensive experiments across four typical tasks for medical image segmentation demonstrate the effectiveness of DS-TransUNet, and show that our approach significantly outperforms the state-of-the-art methods.
Efficient Vision Transformers via Fine-Grained Manifold Distillation
Jul 06, 2021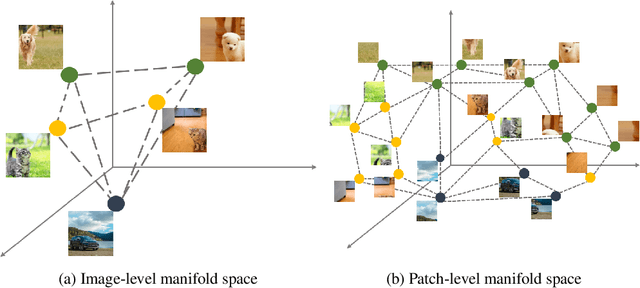
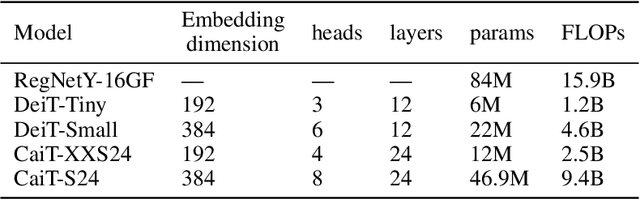
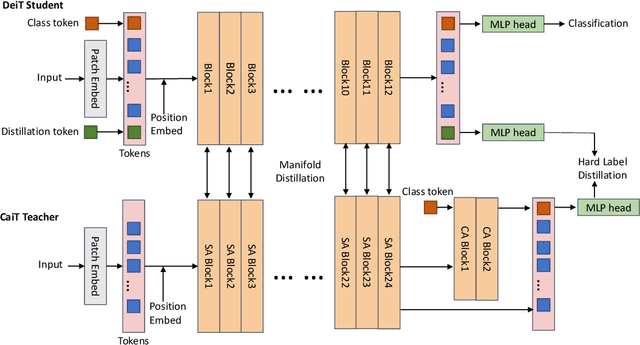
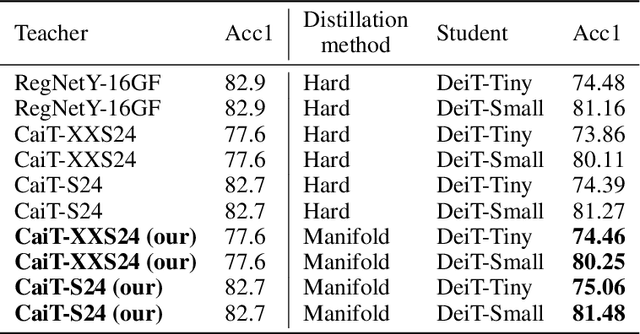
This paper studies the model compression problem of vision transformers. Benefit from the self-attention module, transformer architectures have shown extraordinary performance on many computer vision tasks. Although the network performance is boosted, transformers are often required more computational resources including memory usage and the inference complexity. Compared with the existing knowledge distillation approaches, we propose to excavate useful information from the teacher transformer through the relationship between images and the divided patches. We then explore an efficient fine-grained manifold distillation approach that simultaneously calculates cross-images, cross-patch, and random-selected manifolds in teacher and student models. Experimental results conducted on several benchmarks demonstrate the superiority of the proposed algorithm for distilling portable transformer models with higher performance. For example, our approach achieves 75.06% Top-1 accuracy on the ImageNet-1k dataset for training a DeiT-Tiny model, which outperforms other ViT distillation methods.
LSPnet: A 2D Localization-oriented Spacecraft Pose Estimation Neural Network
Apr 19, 2021
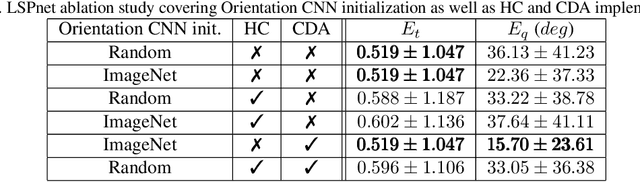
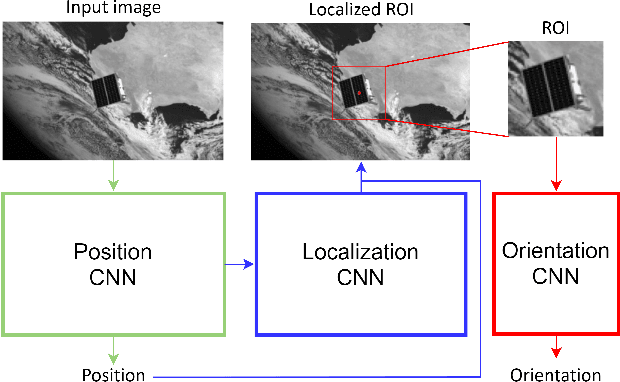
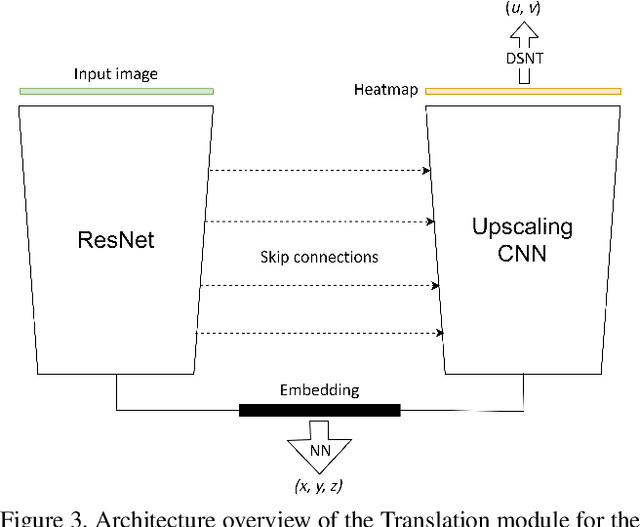
Being capable of estimating the pose of uncooperative objects in space has been proposed as a key asset for enabling safe close-proximity operations such as space rendezvous, in-orbit servicing and active debris removal. Usual approaches for pose estimation involve classical computer vision-based solutions or the application of Deep Learning (DL) techniques. This work explores a novel DL-based methodology, using Convolutional Neural Networks (CNNs), for estimating the pose of uncooperative spacecrafts. Contrary to other approaches, the proposed CNN directly regresses poses without needing any prior 3D information. Moreover, bounding boxes of the spacecraft in the image are predicted in a simple, yet efficient manner. The performed experiments show how this work competes with the state-of-the-art in uncooperative spacecraft pose estimation, including works which require 3D information as well as works which predict bounding boxes through sophisticated CNNs.
Learning Open Information Extraction of Implicit Relations from Reading Comprehension Datasets
May 15, 2019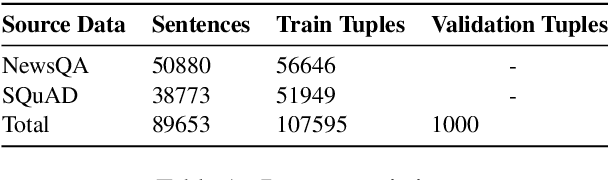
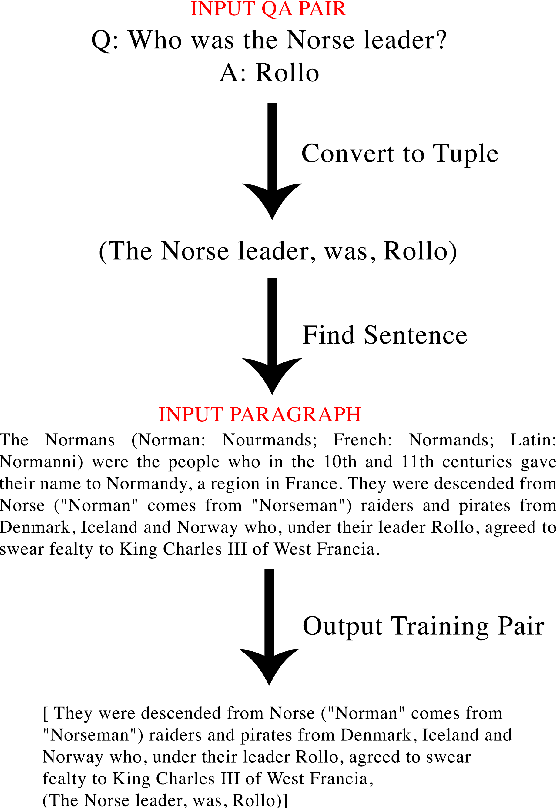
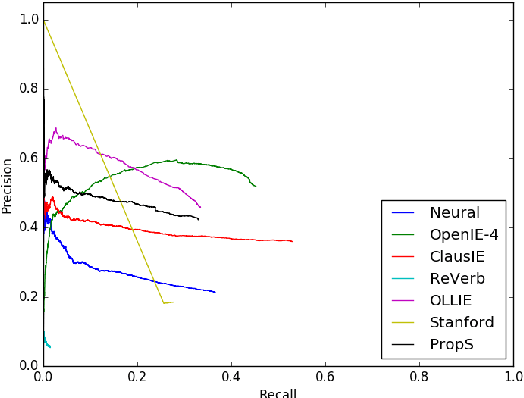
The relationship between two entities in a sentence is often implied by word order and common sense, rather than an explicit predicate. For example, it is evident that "Fed chair Powell indicates rate hike" implies (Powell, is a, Fed chair) and (Powell, works for, Fed). These tuples are just as significant as the explicit-predicate tuple (Powell, indicates, rate hike), but have much lower recall under traditional Open Information Extraction (OpenIE) systems. Implicit tuples are our term for this type of extraction where the relation is not present in the input sentence. There is very little OpenIE training data available relative to other NLP tasks and none focused on implicit relations. We develop an open source, parse-based tool for converting large reading comprehension datasets to OpenIE datasets and release a dataset 35x larger than previously available by sentence count. A baseline neural model trained on this data outperforms previous methods on the implicit extraction task.
BasicVSR++: Improving Video Super-Resolution with Enhanced Propagation and Alignment
Apr 27, 2021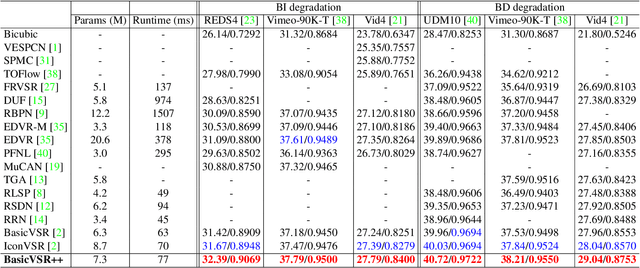
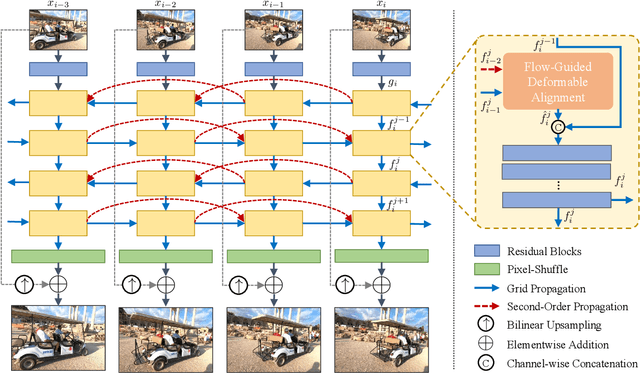

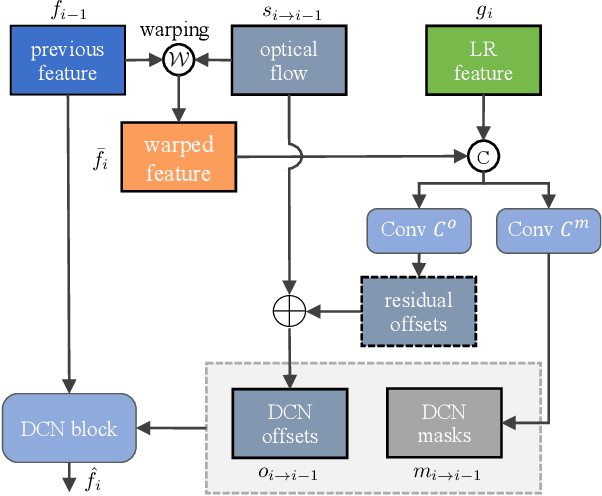
A recurrent structure is a popular framework choice for the task of video super-resolution. The state-of-the-art method BasicVSR adopts bidirectional propagation with feature alignment to effectively exploit information from the entire input video. In this study, we redesign BasicVSR by proposing second-order grid propagation and flow-guided deformable alignment. We show that by empowering the recurrent framework with the enhanced propagation and alignment, one can exploit spatiotemporal information across misaligned video frames more effectively. The new components lead to an improved performance under a similar computational constraint. In particular, our model BasicVSR++ surpasses BasicVSR by 0.82 dB in PSNR with similar number of parameters. In addition to video super-resolution, BasicVSR++ generalizes well to other video restoration tasks such as compressed video enhancement. In NTIRE 2021, BasicVSR++ obtains three champions and one runner-up in the Video Super-Resolution and Compressed Video Enhancement Challenges. Codes and models will be released to MMEditing.
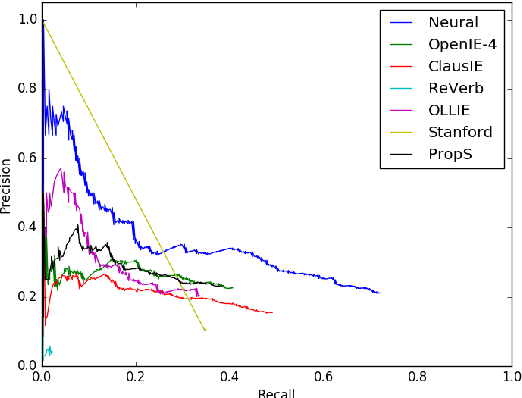
Analysing Errors of Open Information Extraction Systems
Jul 24, 2017
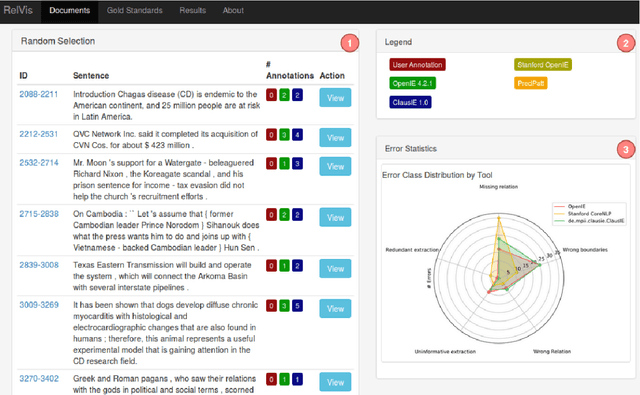
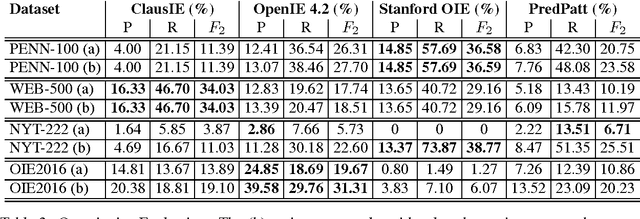
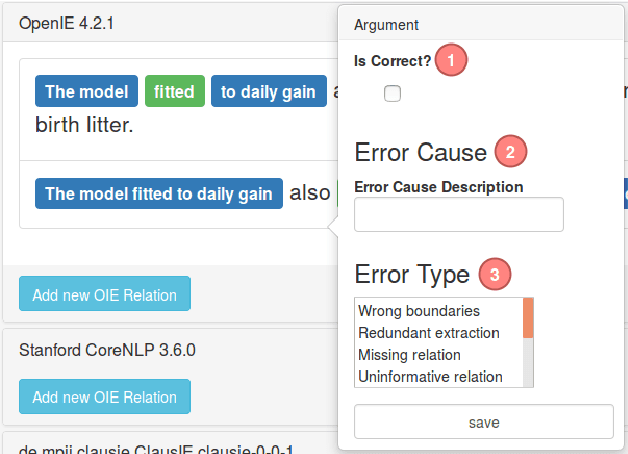
We report results on benchmarking Open Information Extraction (OIE) systems using RelVis, a toolkit for benchmarking Open Information Extraction systems. Our comprehensive benchmark contains three data sets from the news domain and one data set from Wikipedia with overall 4522 labeled sentences and 11243 binary or n-ary OIE relations. In our analysis on these data sets we compared the performance of four popular OIE systems, ClausIE, OpenIE 4.2, Stanford OpenIE and PredPatt. In addition, we evaluated the impact of five common error classes on a subset of 749 n-ary tuples. From our deep analysis we unreveal important research directions for a next generation of OIE systems.
A Novel Deep ML Architecture by Integrating Visual Simultaneous Localization and Mapping (vSLAM) into Mask R-CNN for Real-time Surgical Video Analysis
Mar 31, 2021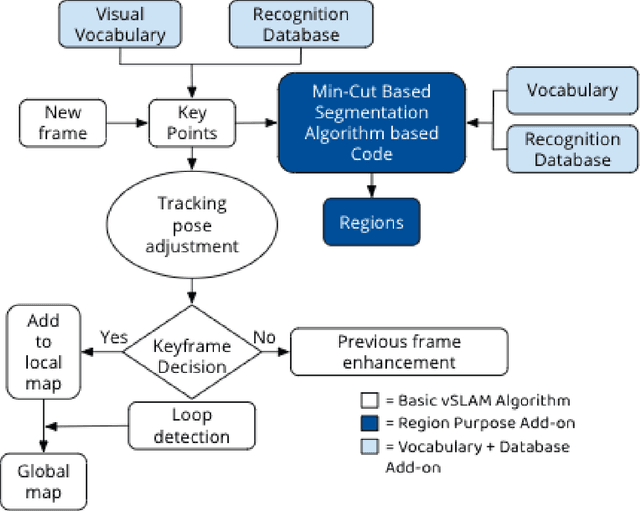
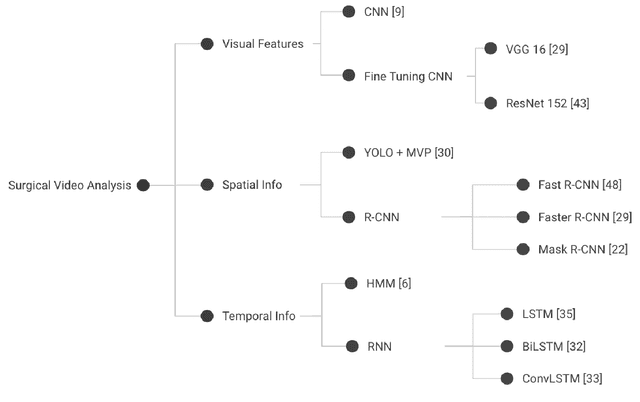
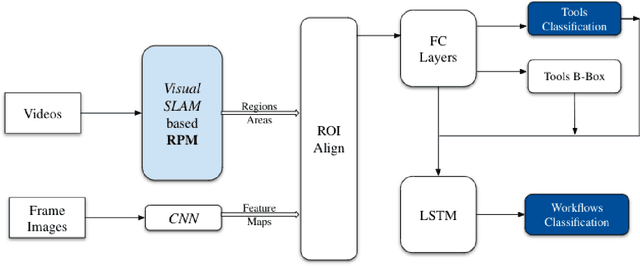
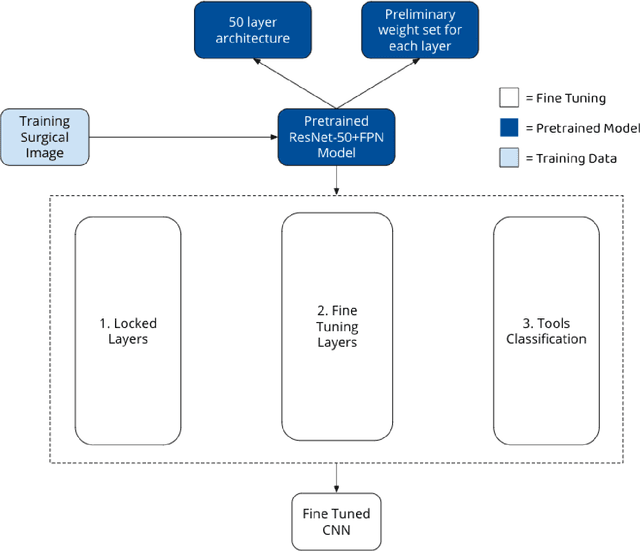
Seven million people suffer complications after surgery each year. With sufficient surgical training and feedback, half of these complications could be prevented. Automatic surgical video analysis, especially for minimally invasive surgery, plays a key role in training and review, with increasing interests from recent studies on tool and workflow detection. In this research, a novel machine learning architecture, RPM-CNN, is created to perform real-time surgical video analysis. This architecture, for the first time, integrates visual simultaneous localization and mapping (vSLAM) into Mask R-CNN. Spatio-temporal information, in addition to the visual features, is utilized to increase the accuracy to 96.8 mAP for tool detection and 97.5 mean Jaccard for workflow detection, surpassing all previous works via the same benchmark dataset. As a real-time prediction, the RPM-CNN model reaches a 50 FPS runtime performance speed, 10x faster than region based CNN, by modeling the spatio-temporal information directly from surgical videos during the vSLAM 3D mapping. Additionally, this novel Region Proposal Module (RPM) replaces the region proposal network (RPN) in Mask R-CNN, accurately placing bounding-boxes and lessening the annotation requirement. In principle, this architecture integrates the best of both worlds, inclusive of 1) vSLAM on object detection, through focusing on geometric information for region proposals and 2) CNN on object recognition, through focusing on semantic information for image classification; the integration of these two technologies into one joint training process opens a new door in computer vision. Furthermore, to apply RPM-CNN's real-time top performance to the real world, a Microsoft HoloLens 2 application is developed to provide an augmented reality (AR) based solution for both surgical training and assistance.