 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Exploring the Diversity and Invariance in Yourself for Visual Pre-Training Task
Jun 01, 2021

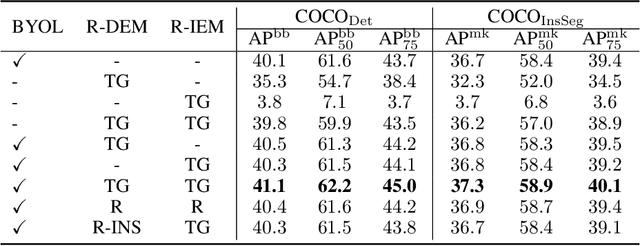
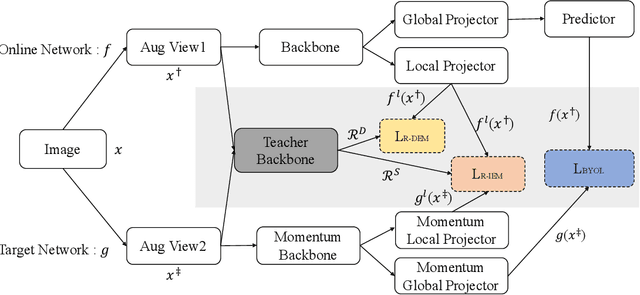
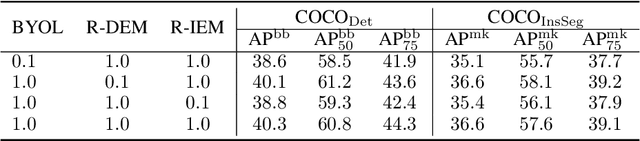
Recently, self-supervised learning methods have achieved remarkable success in visual pre-training task. By simply pulling the different augmented views of each image together or other novel mechanisms, they can learn much unsupervised knowledge and significantly improve the transfer performance of pre-training models. However, these works still cannot avoid the representation collapse problem, i.e., they only focus on limited regions or the extracted features on totally different regions inside each image are nearly the same. Generally, this problem makes the pre-training models cannot sufficiently describe the multi-grained information inside images, which further limits the upper bound of their transfer performance. To alleviate this issue, this paper introduces a simple but effective mechanism, called Exploring the Diversity and Invariance in Yourself E-DIY. By simply pushing the most different regions inside each augmented view away, E-DIY can preserve the diversity of extracted region-level features. By pulling the most similar regions from different augmented views of the same image together, E-DIY can ensure the robustness of region-level features. Benefited from the above diversity and invariance exploring mechanism, E-DIY maximally extracts the multi-grained visual information inside each image. Extensive experiments on downstream tasks demonstrate the superiority of our proposed approach, e.g., there are 2.1% improvements compared with the strong baseline BYOL on COCO while fine-tuning Mask R-CNN with the R50-C4 backbone and 1X learning schedule.
Configuring Antenna System to Enhance the Downlink Performance of High Velocity Users in 5G MU-MIMO Networks
Aug 05, 2021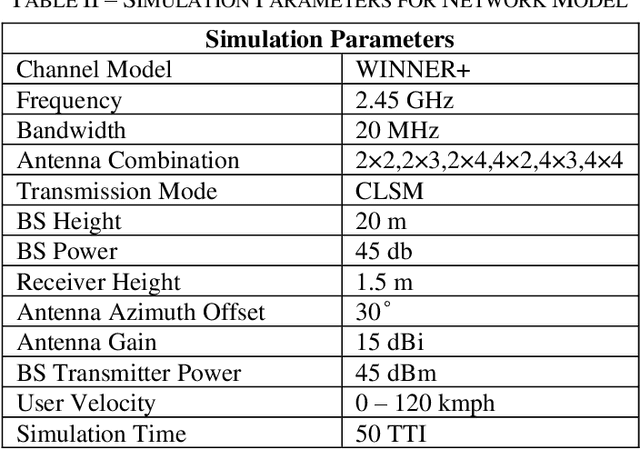
An exponential increase in the data rate demand prompted several technical innovations. Multi User Multiple Input Multiple Output (MU-MIMO) is one of the most promising schemes. This has been evolved into Massive MIMO technology in 5G to further stretch the network throughput. Massive MIMO tackles the rising data rate with the increase in the number of antenna. This comes at the price of a higher energy consumption. Moreover the high velocity users in MU-MIMO scheme experiences a frequent unpredictable change in the channel condition that degrade its downlink performance. Therefore a proper number of antenna selection is of paramount importance. This issue has been addressed using machine learning techniques and Channel State Information (CSI) but only for static users. In this study we propose to introduce antenna diversity in spatial multiplexing MU-MIMO transmission scheme by operating more number of reception antenna compare to the number of transmission antenna. The diversity improves the downlink performance of high velocity users. In general our results can be interpreted for large scale antenna systems like Massive MIMO. The proposed method can be easily implemented in the existing network architectures with minimal complexity. Also it has the potential for solving real-life problems like call drops and low data rate to be experienced by cellular users traveling through high-speed transportation systems like Dhaka MRT project
Uncertainty Maximization in Partially Observable Domains: A Cognitive Perspective
Mar 10, 2021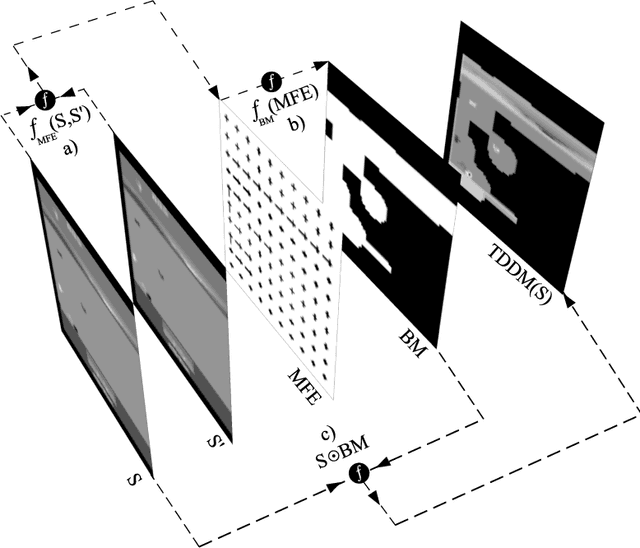
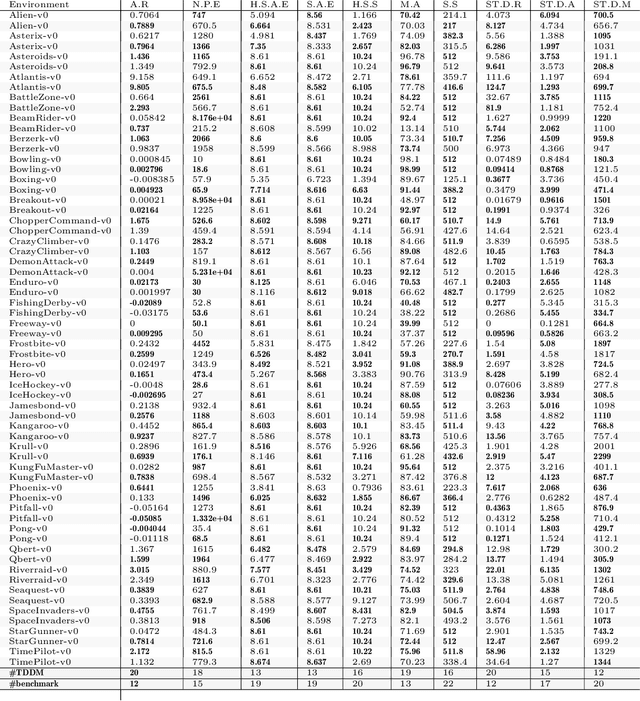

Faced with an ever-increasing complexity of their domains of application, artificial learning agents are now able to scale up in their ability to process an overwhelming amount of information coming from their interaction with an environment. However, this process of scaling does come with a cost of encoding and processing an increasing amount of redundant information that is not necessarily beneficial to the learning process itself. This work exploits the properties of the learning systems defined over partially observable domains by selectively focusing on the specific type of information that is more likely to express the causal interaction among the transitioning states of the environment. Adaptive masking of the observation space based on the $\textit{temporal difference displacement}$ criterion enabled a significant improvement in convergence of temporal difference algorithms defined over a partially observable Markov process.
Wiki-Reliability: A Large Scale Dataset for Content Reliability on Wikipedia
Jun 01, 2021

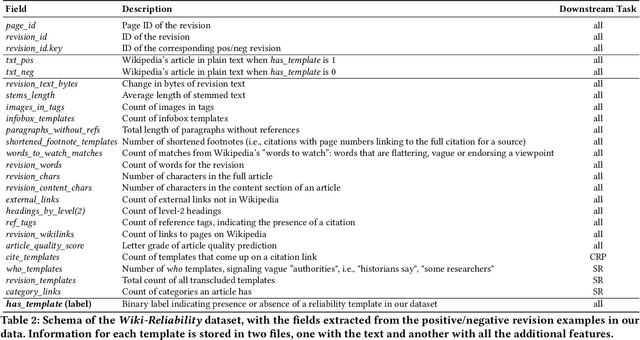
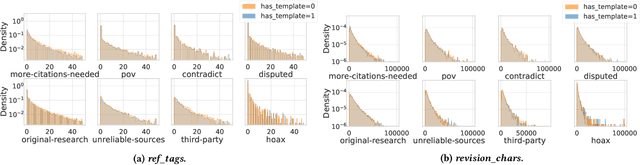
Wikipedia is the largest online encyclopedia, used by algorithms and web users as a central hub of reliable information on the web. The quality and reliability of Wikipedia content is maintained by a community of volunteer editors. Machine learning and information retrieval algorithms could help scale up editors' manual efforts around Wikipedia content reliability. However, there is a lack of large-scale data to support the development of such research. To fill this gap, in this paper, we propose Wiki-Reliability, the first dataset of English Wikipedia articles annotated with a wide set of content reliability issues. To build this dataset, we rely on Wikipedia "templates". Templates are tags used by expert Wikipedia editors to indicate content issues, such as the presence of "non-neutral point of view" or "contradictory articles", and serve as a strong signal for detecting reliability issues in a revision. We select the 10 most popular reliability-related templates on Wikipedia, and propose an effective method to label almost 1M samples of Wikipedia article revisions as positive or negative with respect to each template. Each positive/negative example in the dataset comes with the full article text and 20 features from the revision's metadata. We provide an overview of the possible downstream tasks enabled by such data, and show that Wiki-Reliability can be used to train large-scale models for content reliability prediction. We release all data and code for public use.
R2U3D: Recurrent Residual 3D U-Net for Lung Segmentation
May 05, 2021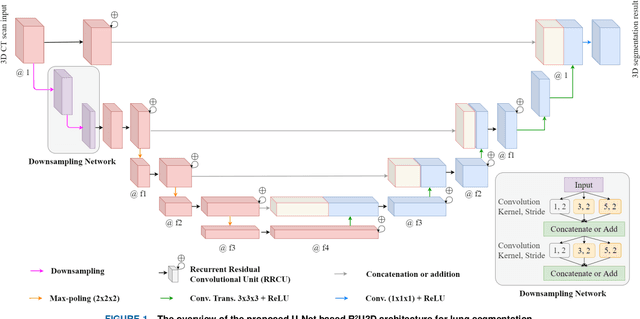
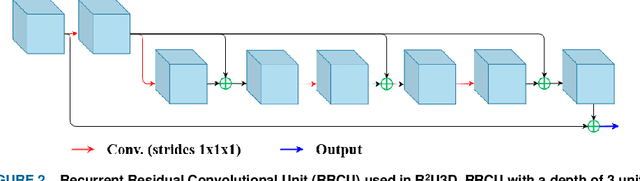
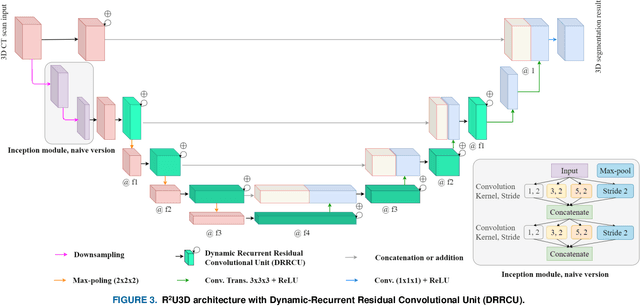
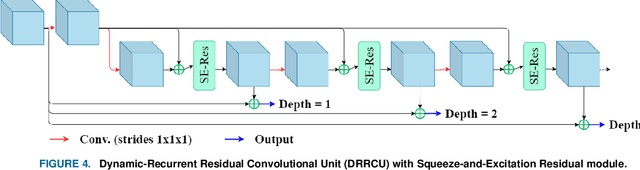
3D lung segmentation is essential since it processes the volumetric information of the lungs, removes the unnecessary areas of the scan, and segments the actual area of the lungs in a 3D volume. Recently, the deep learning model, such as U-Net outperforms other network architectures for biomedical image segmentation. In this paper, we propose a novel model, namely, Recurrent Residual 3D U-Net (R2U3D), for the 3D lung segmentation task. In particular, the proposed model integrates 3D convolution into the Recurrent Residual Neural Network based on U-Net. It helps learn spatial dependencies in 3D and increases the propagation of 3D volumetric information. The proposed R2U3D network is trained on the publicly available dataset LUNA16 and it achieves state-of-the-art performance on both LUNA16 (testing set) and VESSEL12 dataset. In addition, we show that training the R2U3D model with a smaller number of CT scans, i.e., 100 scans, without applying data augmentation achieves an outstanding result in terms of Soft Dice Similarity Coefficient (Soft-DSC) of 0.9920.
Lazy-CFR: a fast regret minimization algorithm for extensive games with imperfect information
Oct 10, 2018
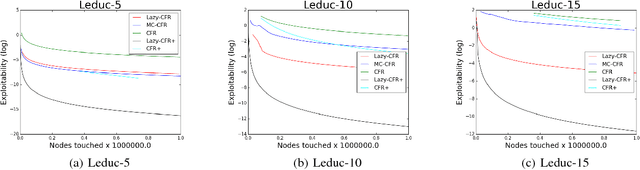
In this paper, we focus on solving two-player zero-sum extensive games with imperfect information. Counterfactual regret minimization (CFR) is the most popular algorithm on solving such games and achieves state-of-the-art performance in practice. However, the performance of CFR is not fully understood, since empirical results on the regret are much better than the upper bound proved in \cite{zinkevich2008regret}. Another issue of CFR is that CFR has to traverse the whole game tree in each round, which is not tolerable in large scale games. In this paper, we present a novel technique, lazy update, which can avoid traversing the whole game tree in CFR. Further, we present a novel analysis on the CFR with lazy update. Our analysis can also be applied to the vanilla CFR, which results in a much tighter regret bound than that proved in \cite{zinkevich2008regret}. Inspired by lazy update, we further present a novel CFR variant, named Lazy-CFR. Compared to traversing $O(|\mathcal{I}|)$ information sets in vanilla CFR, Lazy-CFR needs only to traverse $O(\sqrt{|\mathcal{I}|})$ information sets per round while the regret bound almost keep the same, where $\mathcal{I}$ is the class of all information sets. As a result, Lazy-CFR shows better convergence result compared with vanilla CFR. Experimental results consistently show that Lazy-CFR outperforms the vanilla CFR significantly.
Facial Information Recovery from Heavily Damaged Images using Generative Adversarial Network- PART 1
Aug 27, 2018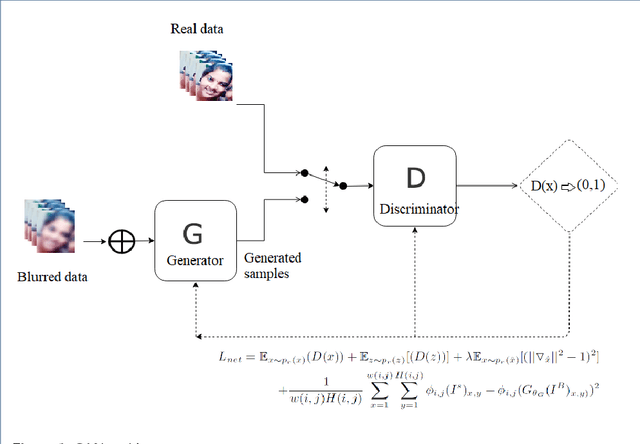
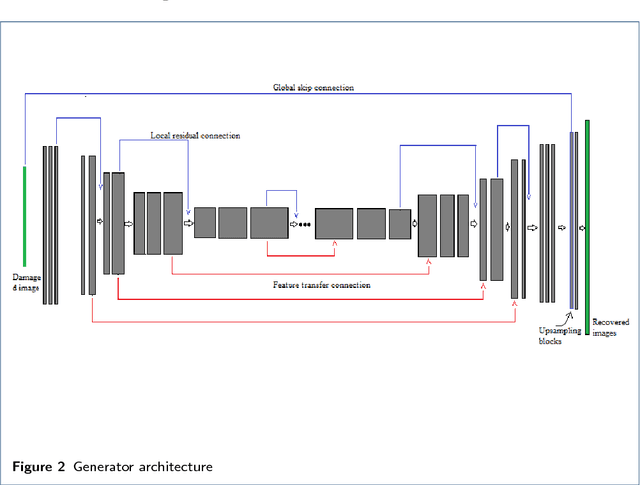
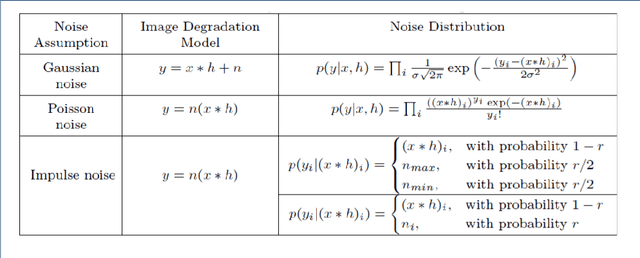
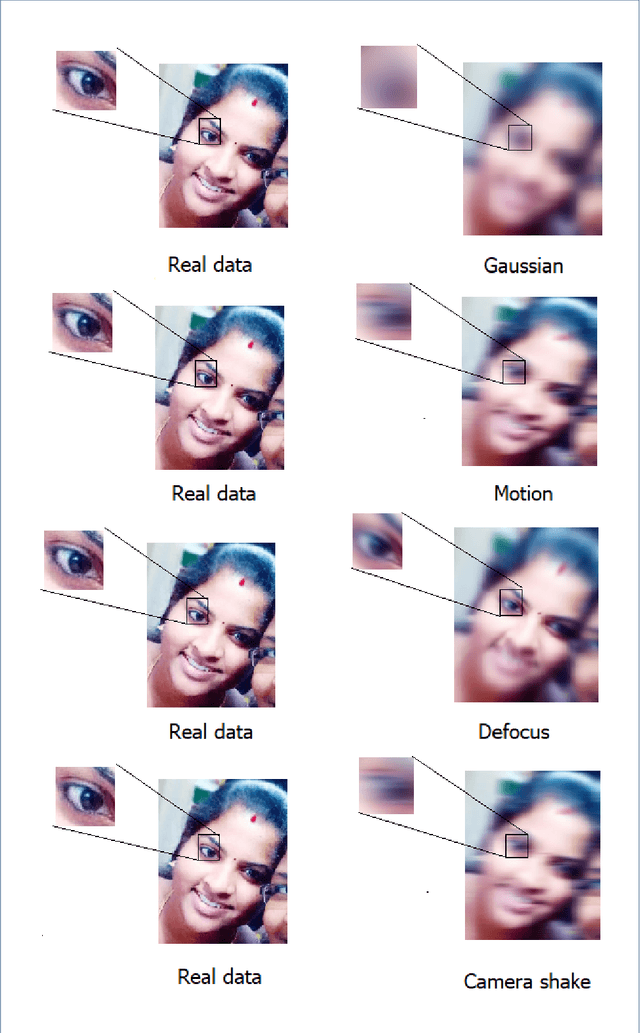
Over the past decades, a large number of techniques have emerged in modern imaging systems to capture the exact information of the original scene regardless of shake, motion, lighting conditions and etc., These developments have progressively addressed the acquisition of images in high speed and high resolutions. However, the various ineradicable real-time factors cause the degradation of the information and the quality of the acquired images. The available techniques are not intelligent enough to generalize this complex phenomenon. Hence, it is necessary to develop an intellectual framework to recover the possible information presented in the original scene. In this article, we propose a kernel free framework based on conditional-GAN to recover the information from the heavily damaged images. The degradation of images is assumed to be occurred by the combination of a various blur. Learning parameter of the cGAN is optimized by multi-component loss function that includes improved wasserstein loss with regression loss function. The generator module of this network is developed by using U-Net architecture with local Residual connections and global skip connection. Local connections and a global skip connection are implemented for the utilization of all stages of features. Generated images show that the network has the potential to recover the probable information of blurred images from the learned features. This research work is carried out as a part of our IOP studio software 'Facial recognition module'.
Multi-modal Residual Perceptron Network for Audio-Video Emotion Recognition
Jul 30, 2021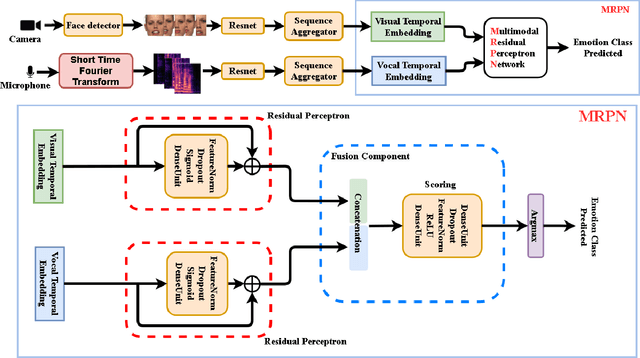
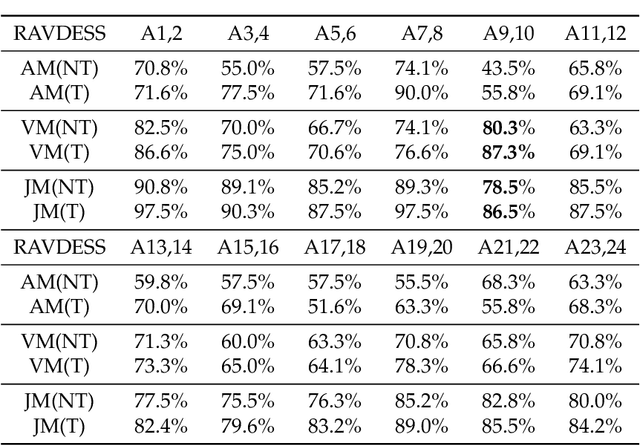

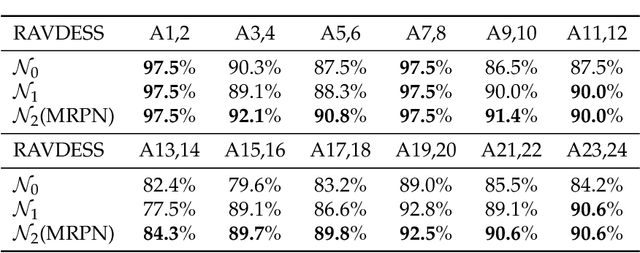
Audio-Video Emotion Recognition is now attacked with Deep Neural Network modeling tools. In published papers, as a rule, the authors show only cases of the superiority in multi-modality over audio-only or video-only modality. However, there are cases superiority in uni-modality can be found. In our research, we hypothesize that for fuzzy categories of emotional events, the within-modal and inter-modal noisy information represented indirectly in the parameters of the modeling neural network impedes better performance in the existing late fusion and end-to-end multi-modal network training strategies. To take advantage and overcome the deficiencies in both solutions, we define a Multi-modal Residual Perceptron Network which performs end-to-end learning from multi-modal network branches, generalizing better multi-modal feature representation. For the proposed Multi-modal Residual Perceptron Network and the novel time augmentation for streaming digital movies, the state-of-art average recognition rate was improved to 91.4% for The Ryerson Audio-Visual Database of Emotional Speech and Song dataset and to 83.15% for Crowd-sourced Emotional multi-modal Actors dataset. Moreover, the Multi-modal Residual Perceptron Network concept shows its potential for multi-modal applications dealing with signal sources not only of optical and acoustical types.
Learning Hierarchical Graph Neural Networks for Image Clustering
Jul 17, 2021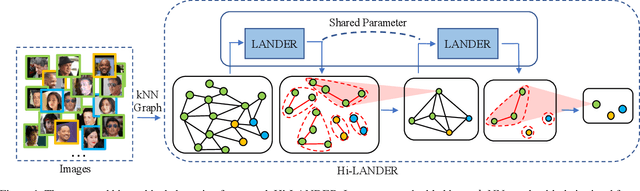
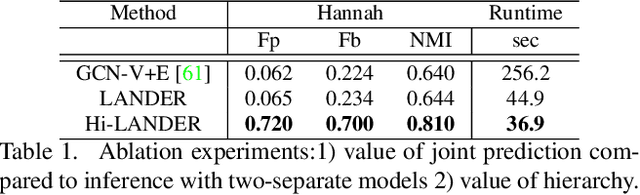
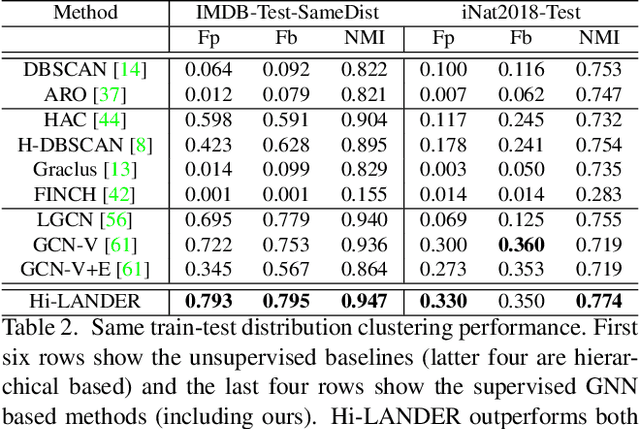
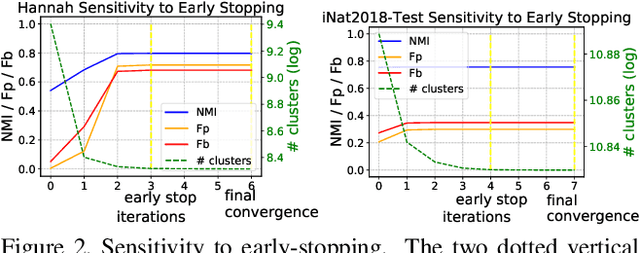
We propose a hierarchical graph neural network (GNN) model that learns how to cluster a set of images into an unknown number of identities using a training set of images annotated with labels belonging to a disjoint set of identities. Our hierarchical GNN uses a novel approach to merge connected components predicted at each level of the hierarchy to form a new graph at the next level. Unlike fully unsupervised hierarchical clustering, the choice of grouping and complexity criteria stems naturally from supervision in the training set. The resulting method, Hi-LANDER, achieves an average of 54% improvement in F-score and 8% increase in Normalized Mutual Information (NMI) relative to current GNN-based clustering algorithms. Additionally, state-of-the-art GNN-based methods rely on separate models to predict linkage probabilities and node densities as intermediate steps of the clustering process. In contrast, our unified framework achieves a seven-fold decrease in computational cost. We release our training and inference code at https://github.com/dmlc/dgl/tree/master/examples/pytorch/hilander.
A maximum entropy model of bounded rational decision-making with prior beliefs and market feedback
Feb 18, 2021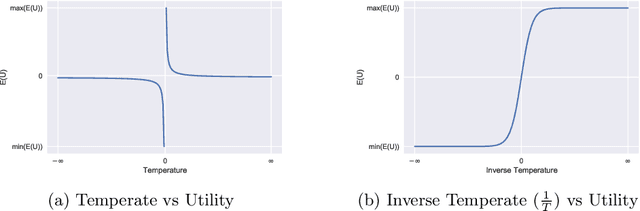
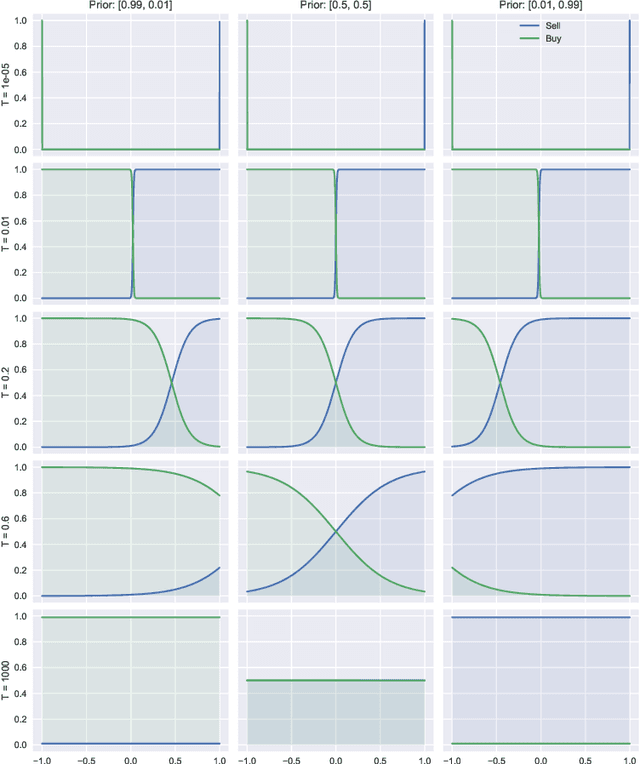
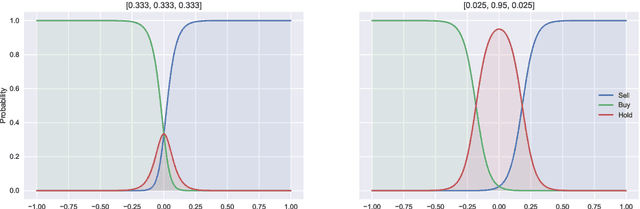
Bounded rationality is an important consideration stemming from the fact that agents often have limits on their processing abilities, making the assumption of perfect rationality inapplicable to many real tasks. We propose an information-theoretic approach to the inference of agent decisions under Smithian competition. The model explicitly captures the boundedness of agents (limited in their information-processing capacity) as the cost of information acquisition for expanding their prior beliefs. The expansion is measured as the Kullblack-Leibler divergence between posterior decisions and prior beliefs. When information acquisition is free, the \textit{homo economicus} agent is recovered, while in cases when information acquisition becomes costly, agents instead revert to their prior beliefs. The maximum entropy principle is used to infer least-biased decisions, based upon the notion of Smithian competition formalised within the Quantal Response Statistical Equilibrium framework. The incorporation of prior beliefs into such a framework allowed us to systematically explore the effects of prior beliefs on decision-making, in the presence of market feedback. We verified the proposed model using Australian housing market data, showing how the incorporation of prior knowledge alters the resulting agent decisions. Specifically, it allowed for the separation (and analysis) of past beliefs and utility maximisation behaviour of the agent.