 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Enhancing Cross-Sectional Currency Strategies by Ranking Refinement with Transformer-based Architectures
May 20, 2021
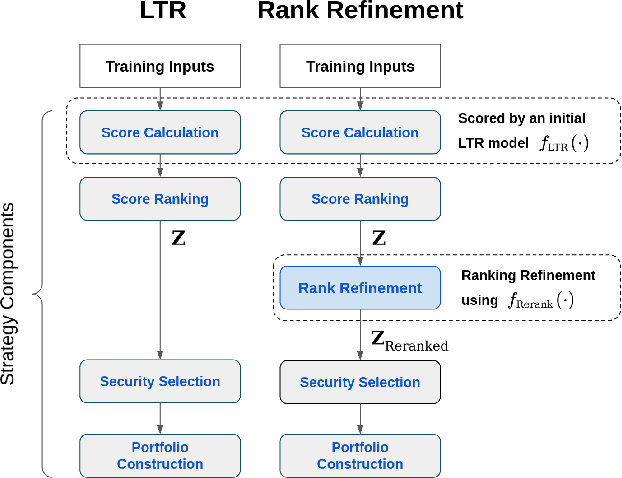
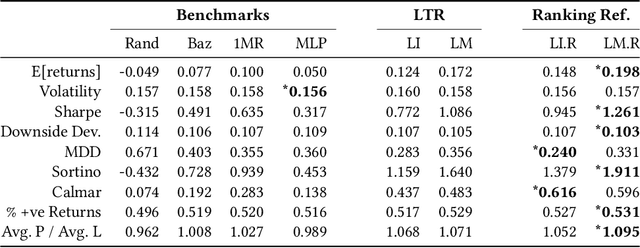
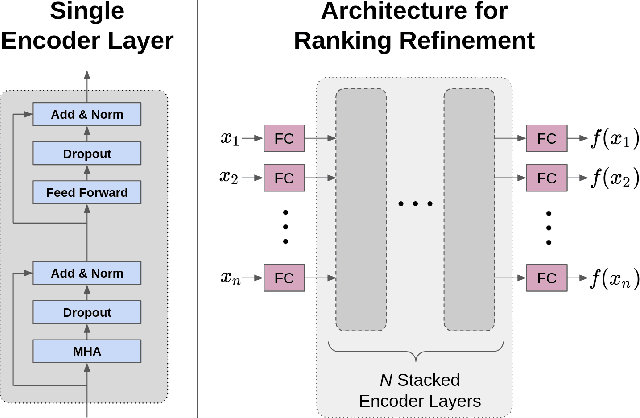
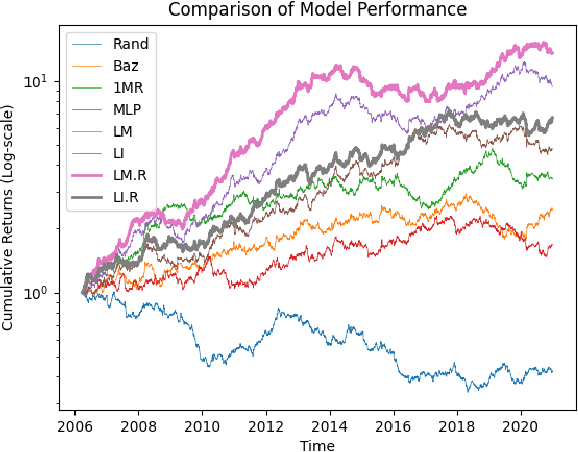
The performance of a cross-sectional currency strategy depends crucially on accurately ranking instruments prior to portfolio construction. While this ranking step is traditionally performed using heuristics, or by sorting outputs produced by pointwise regression or classification models, Learning to Rank algorithms have recently presented themselves as competitive and viable alternatives. Despite improving ranking accuracy on average however, these techniques do not account for the possibility that assets positioned at the extreme ends of the ranked list -- which are ultimately used to construct the long/short portfolios -- can assume different distributions in the input space, and thus lead to sub-optimal strategy performance. Drawing from research in Information Retrieval that demonstrates the utility of contextual information embedded within top-ranked documents to learn the query's characteristics to improve ranking, we propose an analogous approach: exploiting the features of both out- and under-performing instruments to learn a model for refining the original ranked list. Under a re-ranking framework, we adapt the Transformer architecture to encode the features of extreme assets for refining our selection of long/short instruments obtained with an initial retrieval. Backtesting on a set of 31 currencies, our proposed methodology significantly boosts Sharpe ratios -- by approximately 20% over the original LTR algorithms and double that of traditional baselines.
Sparse Flows: Pruning Continuous-depth Models
Jun 24, 2021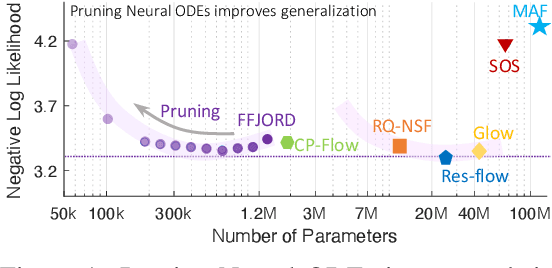
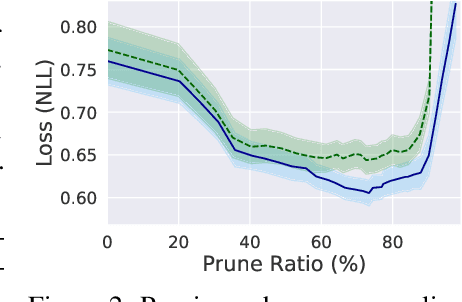
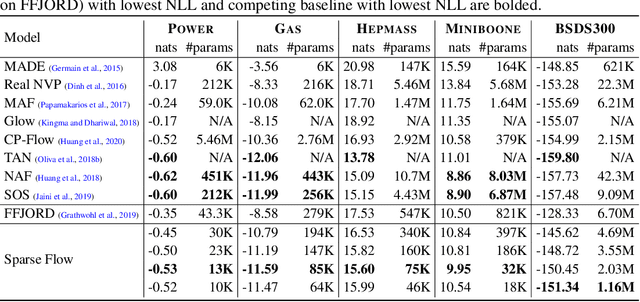
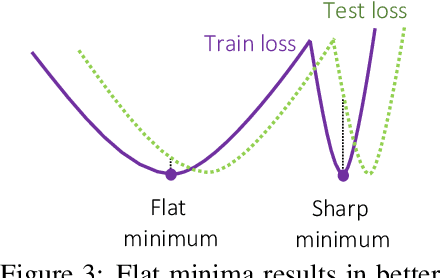
Continuous deep learning architectures enable learning of flexible probabilistic models for predictive modeling as neural ordinary differential equations (ODEs), and for generative modeling as continuous normalizing flows. In this work, we design a framework to decipher the internal dynamics of these continuous depth models by pruning their network architectures. Our empirical results suggest that pruning improves generalization for neural ODEs in generative modeling. Moreover, pruning finds minimal and efficient neural ODE representations with up to 98\% less parameters compared to the original network, without loss of accuracy. Finally, we show that by applying pruning we can obtain insightful information about the design of better neural ODEs.We hope our results will invigorate further research into the performance-size trade-offs of modern continuous-depth models.
Generalized Visual Information Analysis via Tensorial Algebra
Jan 31, 2020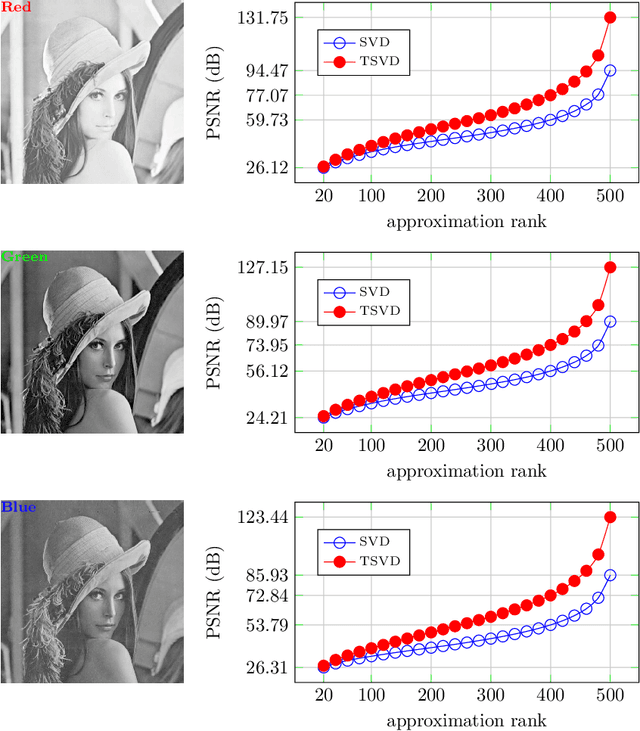
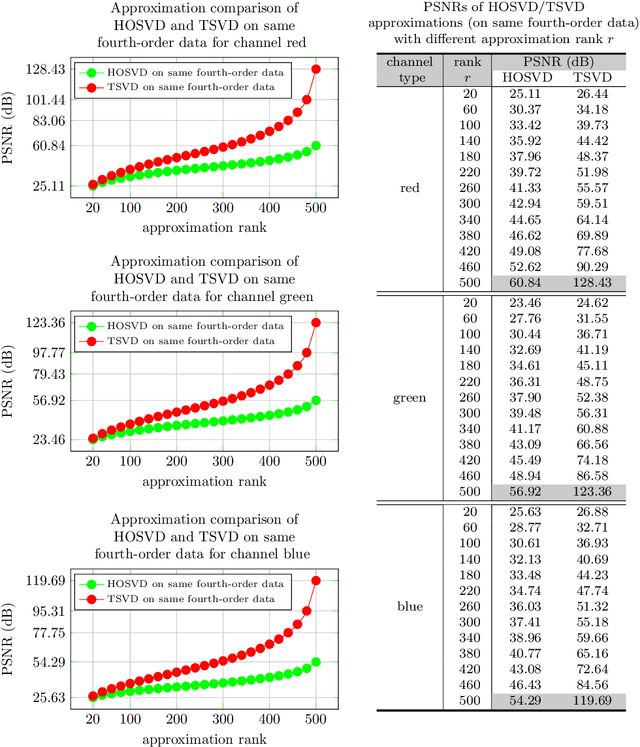
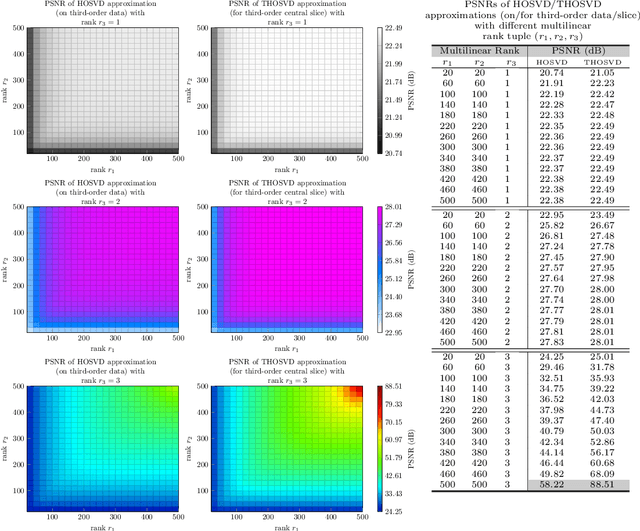
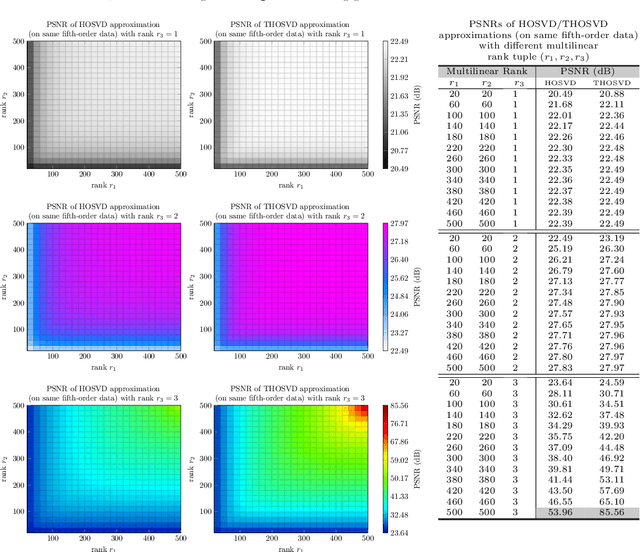
High order data is modeled using matrices whose entries are numerical arrays of a fixed size. These arrays, called t-scalars, form a commutative ring under the convolution product. Matrices with elements in the ring of t-scalars are referred to as t-matrices. The t-matrices can be scaled, added and multiplied in the usual way. There are t-matrix generalizations of positive matrices, orthogonal matrices and Hermitian symmetric matrices. With the t-matrix model, it is possible to generalize many well-known matrix algorithms. In particular, the t-matrices are used to generalize the SVD (Singular Value Decomposition), HOSVD (High Order SVD), PCA (Principal Component Analysis), 2DPCA (Two Dimensional PCA) and GCA (Grassmannian Component Analysis). The generalized t-matrix algorithms, namely TSVD, THOSVD,TPCA, T2DPCA and TGCA, are applied to low-rank approximation, reconstruction,and supervised classification of images. Experiments show that the t-matrix algorithms compare favorably with standard matrix algorithms.
Semantic Attention and Scale Complementary Network for Instance Segmentation in Remote Sensing Images
Jul 25, 2021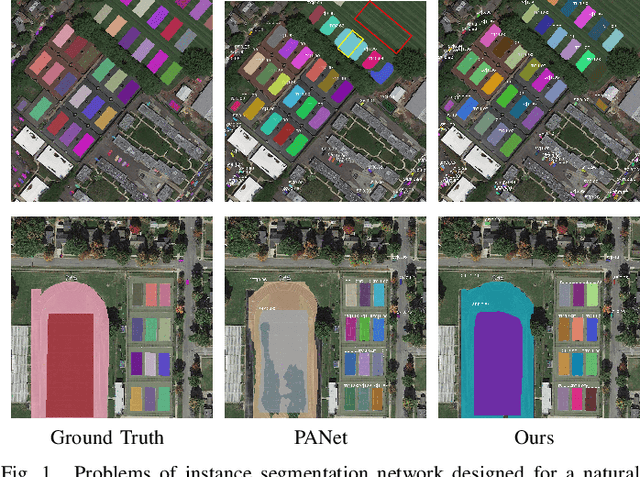

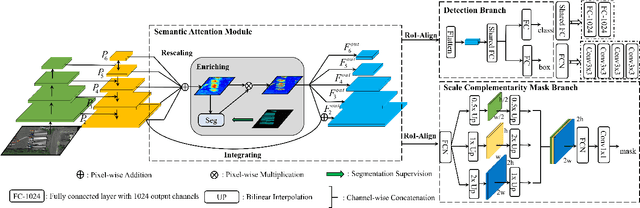
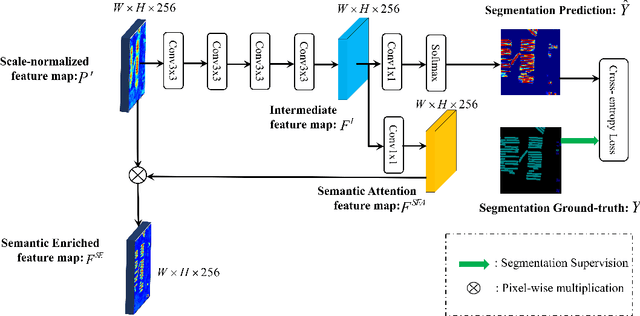
In this paper, we focus on the challenging multicategory instance segmentation problem in remote sensing images (RSIs), which aims at predicting the categories of all instances and localizing them with pixel-level masks. Although many landmark frameworks have demonstrated promising performance in instance segmentation, the complexity in the background and scale variability instances still remain challenging for instance segmentation of RSIs. To address the above problems, we propose an end-to-end multi-category instance segmentation model, namely Semantic Attention and Scale Complementary Network, which mainly consists of a Semantic Attention (SEA) module and a Scale Complementary Mask Branch (SCMB). The SEA module contains a simple fully convolutional semantic segmentation branch with extra supervision to strengthen the activation of interest instances on the feature map and reduce the background noise's interference. To handle the under-segmentation of geospatial instances with large varying scales, we design the SCMB that extends the original single mask branch to trident mask branches and introduces complementary mask supervision at different scales to sufficiently leverage the multi-scale information. We conduct comprehensive experiments to evaluate the effectiveness of our proposed method on the iSAID dataset and the NWPU Instance Segmentation dataset and achieve promising performance.
Clinical Relation Extraction Using Transformer-based Models
Aug 16, 2021
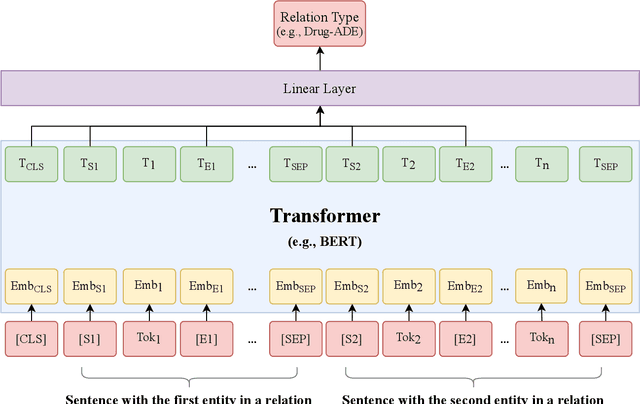
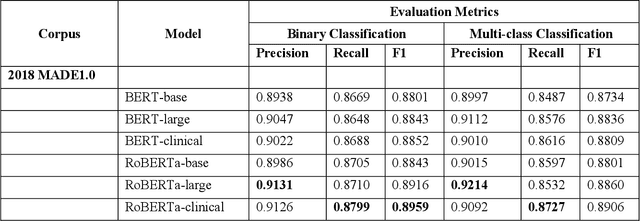
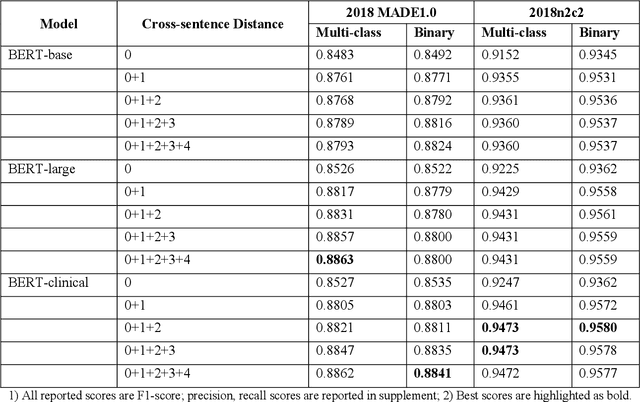
The newly emerged transformer technology has a tremendous impact on NLP research. In the general English domain, transformer-based models have achieved state-of-the-art performances on various NLP benchmarks. In the clinical domain, researchers also have investigated transformer models for clinical applications. The goal of this study is to systematically explore three widely used transformer-based models (i.e., BERT, RoBERTa, and XLNet) for clinical relation extraction and develop an open-source package with clinical pre-trained transformer-based models to facilitate information extraction in the clinical domain. We developed a series of clinical RE models based on three transformer architectures, namely BERT, RoBERTa, and XLNet. We evaluated these models using 2 publicly available datasets from 2018 MADE1.0 and 2018 n2c2 challenges. We compared two classification strategies (binary vs. multi-class classification) and investigated two approaches to generate candidate relations in different experimental settings. In this study, we compared three transformer-based (BERT, RoBERTa, and XLNet) models for relation extraction. We demonstrated that the RoBERTa-clinical RE model achieved the best performance on the 2018 MADE1.0 dataset with an F1-score of 0.8958. On the 2018 n2c2 dataset, the XLNet-clinical model achieved the best F1-score of 0.9610. Our results indicated that the binary classification strategy consistently outperformed the multi-class classification strategy for clinical relation extraction. Our methods and models are publicly available at https://github.com/uf-hobi-informatics-lab/ClinicalTransformerRelationExtraction. We believe this work will improve current practice on clinical relation extraction and other related NLP tasks in the biomedical domain.
Inpainting Transformer for Anomaly Detection
Apr 28, 2021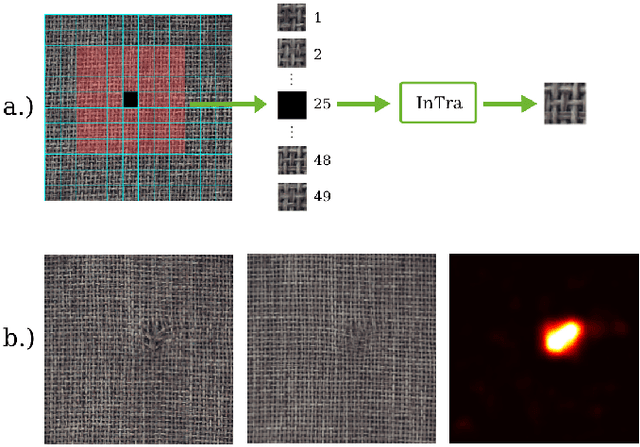
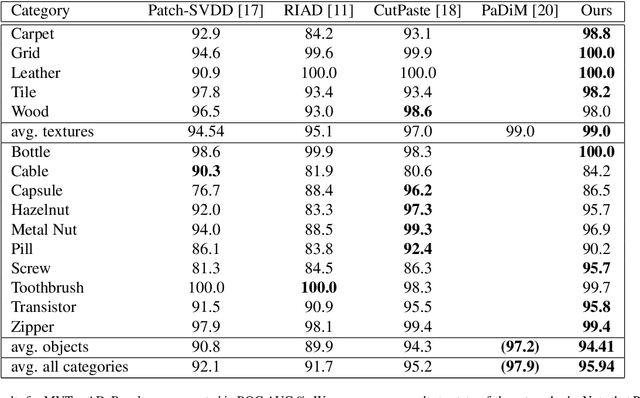
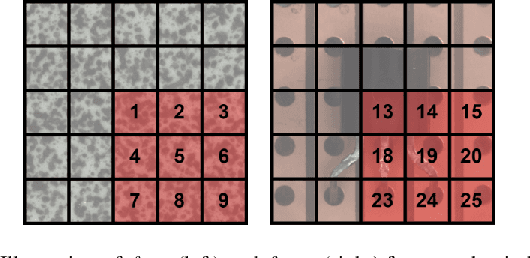
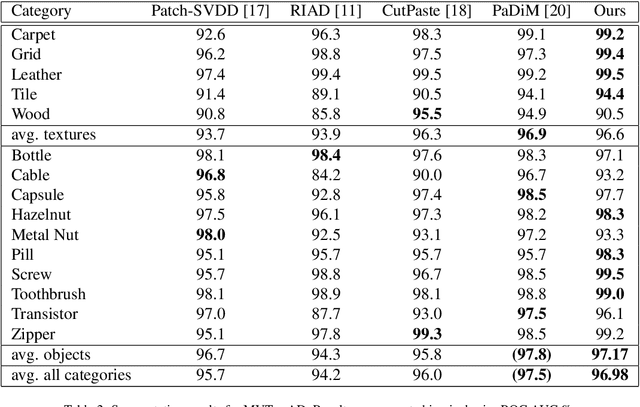
Anomaly detection in computer vision is the task of identifying images which deviate from a set of normal images. A common approach is to train deep convolutional autoencoders to inpaint covered parts of an image and compare the output with the original image. By training on anomaly-free samples only, the model is assumed to not being able to reconstruct anomalous regions properly. For anomaly detection by inpainting we suggest it to be beneficial to incorporate information from potentially distant regions. In particular we pose anomaly detection as a patch-inpainting problem and propose to solve it with a purely self-attention based approach discarding convolutions. The proposed Inpainting Transformer (InTra) is trained to inpaint covered patches in a large sequence of image patches, thereby integrating information across large regions of the input image. When learning from scratch, InTra achieves better than state-of-the-art results on the MVTec AD [1] dataset for detection and localization.
EDITS: Modeling and Mitigating Data Bias for Graph Neural Networks
Aug 11, 2021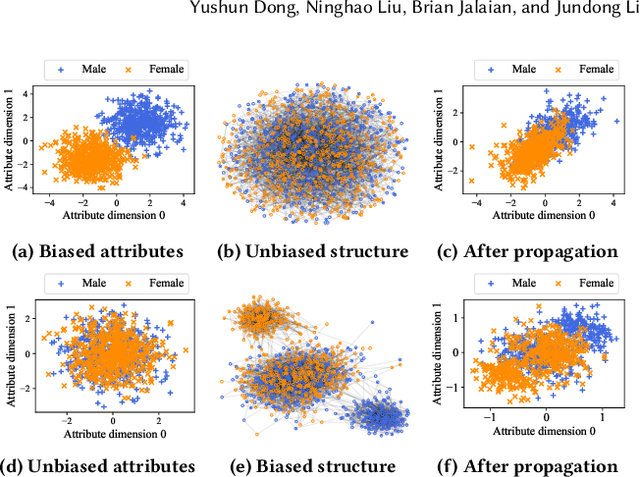
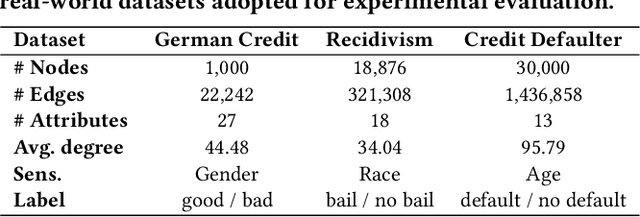
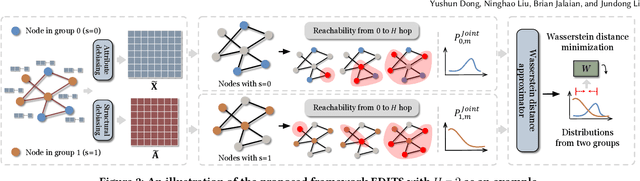
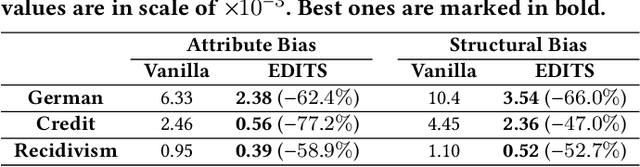
Graph Neural Networks (GNNs) have recently demonstrated superior capability of tackling graph analytical problems in various applications. Nevertheless, with the wide-spreading practice of GNNs in high-stake decision-making processes, there is an increasing societal concern that GNNs could make discriminatory decisions that may be illegal towards certain demographic groups. Although some explorations have been made towards developing fair GNNs, existing approaches are tailored for a specific GNN model. However, in practical scenarios, myriads of GNN variants have been proposed for different tasks, and it is costly to train and fine-tune existing debiasing models for different GNNs. Also, bias in a trained model could originate from training data, while how to mitigate bias in the graph data is usually overlooked. In this work, different from existing work, we first propose novel definitions and metrics to measure the bias in an attributed network, which leads to the optimization objective to mitigate bias. Based on the optimization objective, we develop a framework named EDITS to mitigate the bias in attributed networks while preserving useful information. EDITS works in a model-agnostic manner, which means that it is independent of the specific GNNs applied for downstream tasks. Extensive experiments on both synthetic and real-world datasets demonstrate the validity of the proposed bias metrics and the superiority of EDITS on both bias mitigation and utility maintenance. Open-source implementation: https://github.com/yushundong/EDITS.
RoFormer: Enhanced Transformer with Rotary Position Embedding
Apr 20, 2021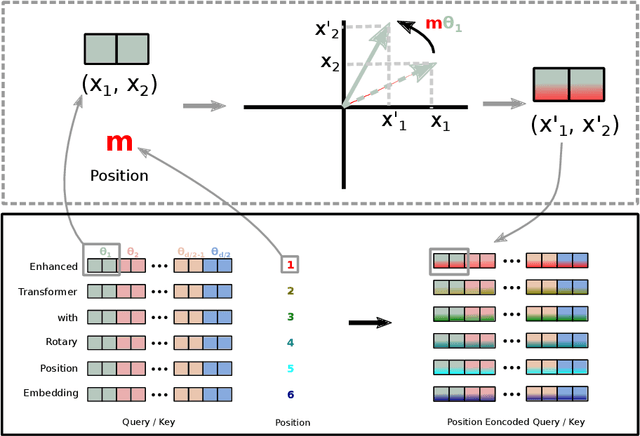
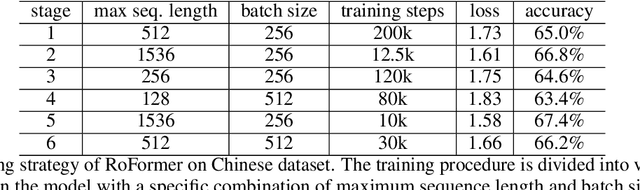
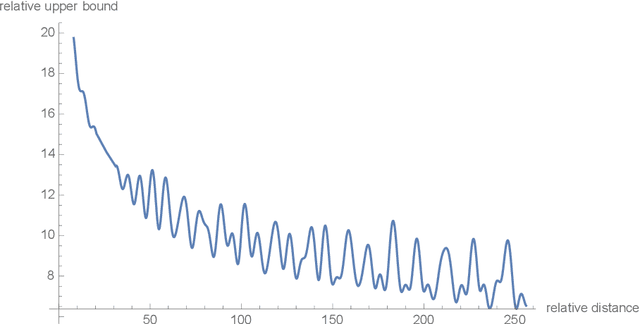
Position encoding in transformer architecture provides supervision for dependency modeling between elements at different positions in the sequence. We investigate various methods to encode positional information in transformer-based language models and propose a novel implementation named Rotary Position Embedding(RoPE). The proposed RoPE encodes absolute positional information with rotation matrix and naturally incorporates explicit relative position dependency in self-attention formulation. Notably, RoPE comes with valuable properties such as flexibility of being expand to any sequence lengths, decaying inter-token dependency with increasing relative distances, and capability of equipping the linear self-attention with relative position encoding. As a result, the enhanced transformer with rotary position embedding, or RoFormer, achieves superior performance in tasks with long texts. We release the theoretical analysis along with some preliminary experiment results on Chinese data. The undergoing experiment for English benchmark will soon be updated.
Ranking Clarifying Questions Based on Predicted User Engagement
Mar 18, 2021
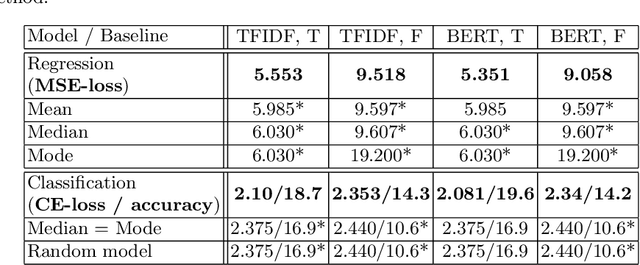
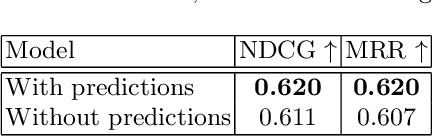
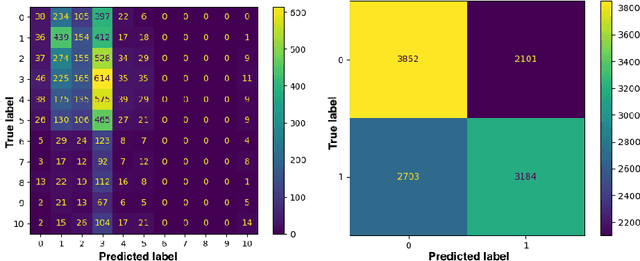
To improve online search results, clarification questions can be used to elucidate the information need of the user. This research aims to predict the user engagement with the clarification pane as an indicator of relevance based on the lexical information: query, question, and answers. Subsequently, the predicted user engagement can be used as a feature to rank the clarification panes. Regression and classification are applied for predicting user engagement and compared to naive heuristic baselines (e.g. mean) on the new MIMICS dataset [20]. An ablation study is carried out using a RankNet model to determine whether the predicted user engagement improves clarification pane ranking performance. The prediction models were able to improve significantly upon the naive baselines, and the predicted user engagement feature significantly improved the RankNet results in terms of NDCG and MRR. This research demonstrates the potential for ranking clarification panes based on lexical information only and can serve as a first neural baseline for future research to improve on. The code is available online.
Explaining COVID-19 and Thoracic Pathology Model Predictions by Identifying Informative Input Features
Apr 01, 2021
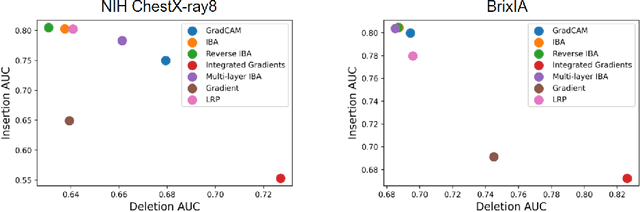
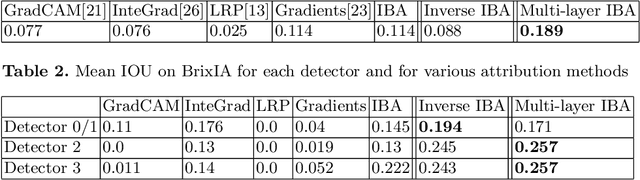
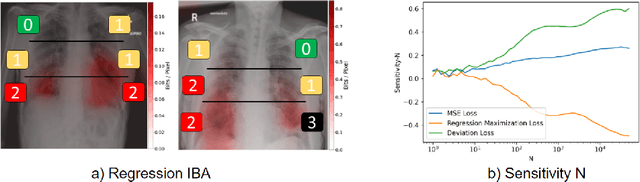
Neural networks have demonstrated remarkable performance in classification and regression tasks on chest X-rays. In order to establish trust in the clinical routine, the networks' prediction mechanism needs to be interpretable. One principal approach to interpretation is feature attribution. Feature attribution methods identify the importance of input features for the output prediction. Building on Information Bottleneck Attribution (IBA) method, for each prediction we identify the chest X-ray regions that have high mutual information with the network's output. Original IBA identifies input regions that have sufficient predictive information. We propose Inverse IBA to identify all informative regions. Thus all predictive cues for pathologies are highlighted on the X-rays, a desirable property for chest X-ray diagnosis. Moreover, we propose Regression IBA for explaining regression models. Using Regression IBA we observe that a model trained on cumulative severity score labels implicitly learns the severity of different X-ray regions. Finally, we propose Multi-layer IBA to generate higher resolution and more detailed attribution/saliency maps. We evaluate our methods using both human-centric (ground-truth-based) interpretability metrics, and human-independent feature importance metrics on NIH Chest X-ray8 and BrixIA datasets. The Code is publicly available.