 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Learning Sparse Latent Representations with the Deep Copula Information Bottleneck
Apr 19, 2018
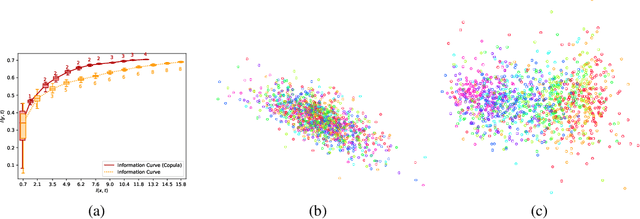
Deep latent variable models are powerful tools for representation learning. In this paper, we adopt the deep information bottleneck model, identify its shortcomings and propose a model that circumvents them. To this end, we apply a copula transformation which, by restoring the invariance properties of the information bottleneck method, leads to disentanglement of the features in the latent space. Building on that, we show how this transformation translates to sparsity of the latent space in the new model. We evaluate our method on artificial and real data.
* Published as a conference paper at ICLR 2018. Aleksander Wieczorek and Mario Wieser contributed equally to this work
Entropy methods for the confidence assessment of probabilistic classification models
Mar 28, 2021
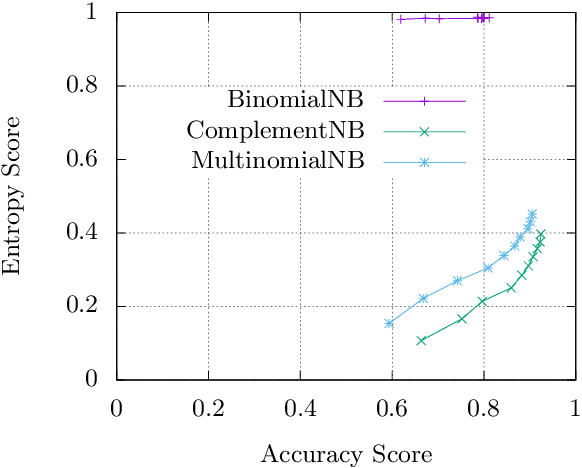
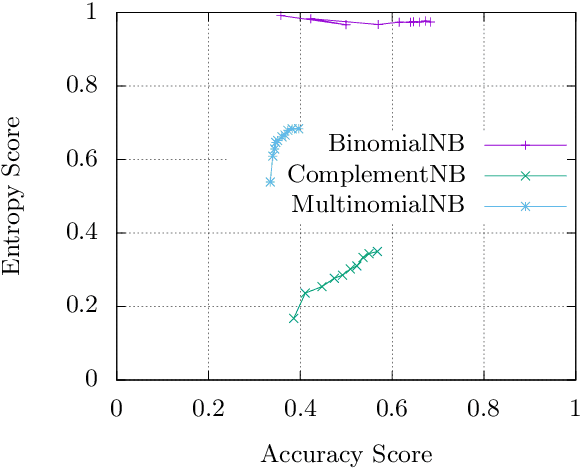
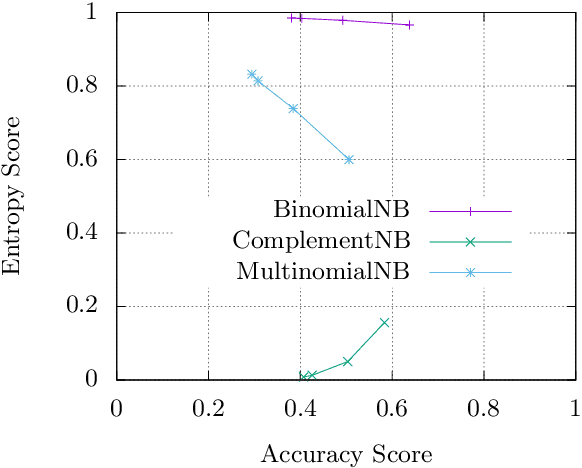
Many classification models produce a probability distribution as the outcome of a prediction. This information is generally compressed down to the single class with the highest associated probability. In this paper, we argue that part of the information that is discarded in this process can be in fact used to further evaluate the goodness of models, and in particular the confidence with which each prediction is made. As an application of the ideas presented in this paper, we provide a theoretical explanation of a confidence degradation phenomenon observed in the complement approach to the (Bernoulli) Naive Bayes generative model.
Segmentation of Shoulder Muscle MRI Using a New Region and Edge based Deep Auto-Encoder
Aug 26, 2021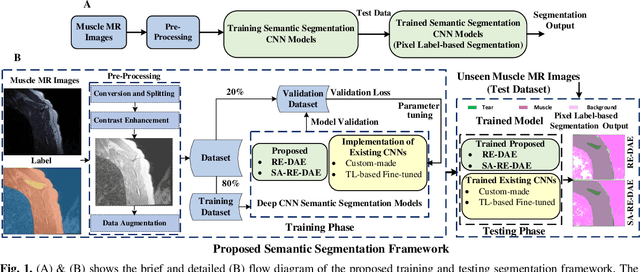
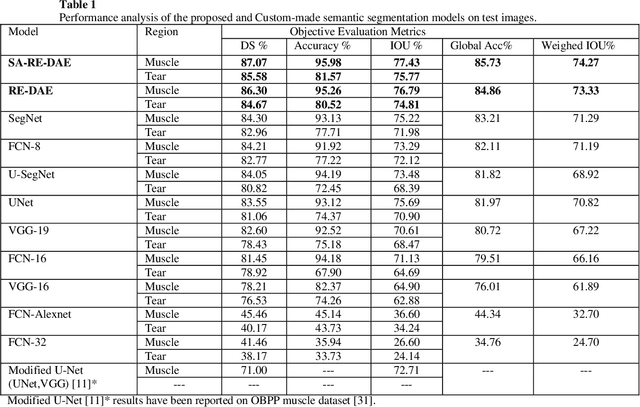
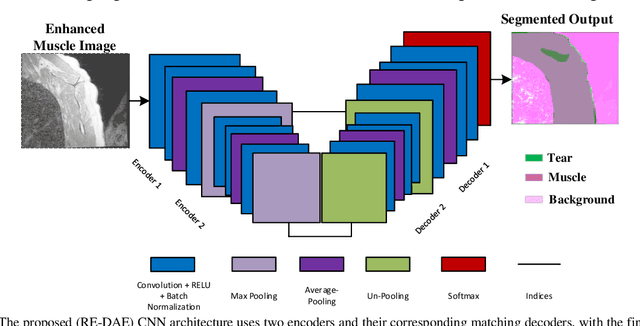
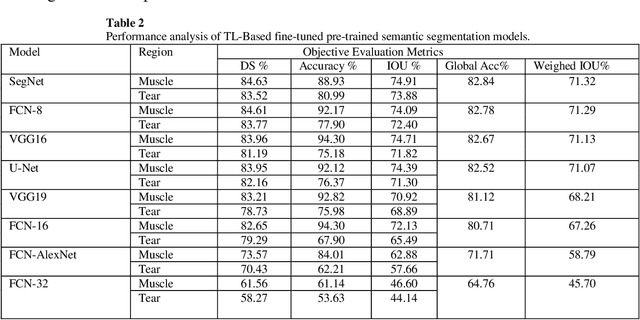
Automatic segmentation of shoulder muscle MRI is challenging due to the high variation in muscle size, shape, texture, and spatial position of tears. Manual segmentation of tear and muscle portion is hard, time-consuming, and subjective to pathological expertise. This work proposes a new Region and Edge-based Deep Auto-Encoder (RE-DAE) for shoulder muscle MRI segmentation. The proposed RE-DAE harmoniously employs average and max-pooling operation in the encoder and decoder blocks of the Convolutional Neural Network (CNN). Region-based segmentation incorporated in the Deep Auto-Encoder (DAE) encourages the network to extract smooth and homogenous regions. In contrast, edge-based segmentation tries to learn the boundary and anatomical information. These two concepts, systematically combined in a DAE, generate a discriminative and sparse hybrid feature space (exploiting both region homogeneity and boundaries). Moreover, the concept of static attention is exploited in the proposed RE-DAE that helps in effectively learning the tear region. The performances of the proposed MRI segmentation based DAE architectures have been tested using a 3D MRI shoulder muscle dataset using the hold-out cross-validation technique. The MRI data has been collected from the Korea University Anam Hospital, Seoul, South Korea. Experimental comparisons have been conducted by employing innovative custom-made and existing pre-trained CNN architectures both using transfer learning and fine-tuning. Objective evaluation on the muscle datasets using the proposed SA-RE-DAE showed a dice similarity of 85.58% and 87.07%, an accuracy of 81.57% and 95.58% for tear and muscle regions, respectively. The high visual quality and the objective result suggest that the proposed SA-RE-DAE is able to correctly segment tear and muscle regions in shoulder muscle MRI for better clinical decisions.
SHADE: Information Based Regularization for Deep Learning
May 22, 2018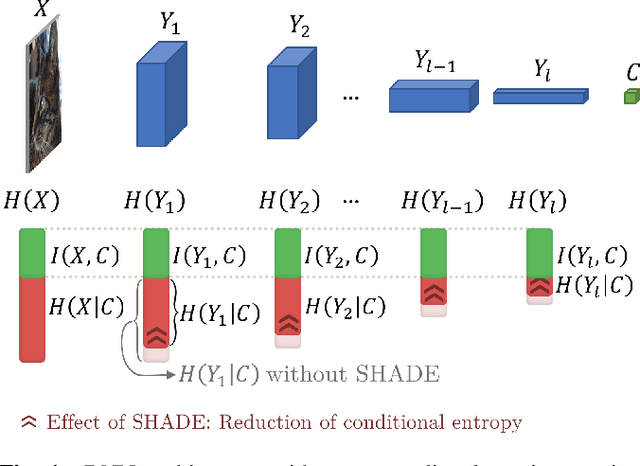
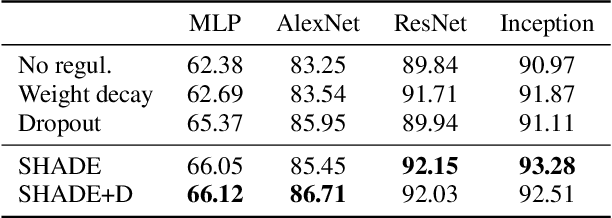
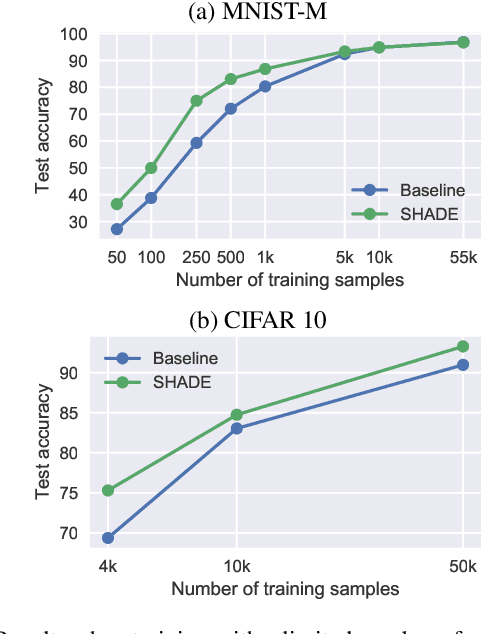

Regularization is a big issue for training deep neural networks. In this paper, we propose a new information-theory-based regularization scheme named SHADE for SHAnnon DEcay. The originality of the approach is to define a prior based on conditional entropy, which explicitly decouples the learning of invariant representations in the regularizer and the learning of correlations between inputs and labels in the data fitting term. Our second contribution is to derive a stochastic version of the regularizer compatible with deep learning, resulting in a tractable training scheme. We empirically validate the efficiency of our approach to improve classification performances compared to common regularization schemes on several standard architectures.
Locate and Label: A Two-stage Identifier for Nested Named Entity Recognition
May 14, 2021
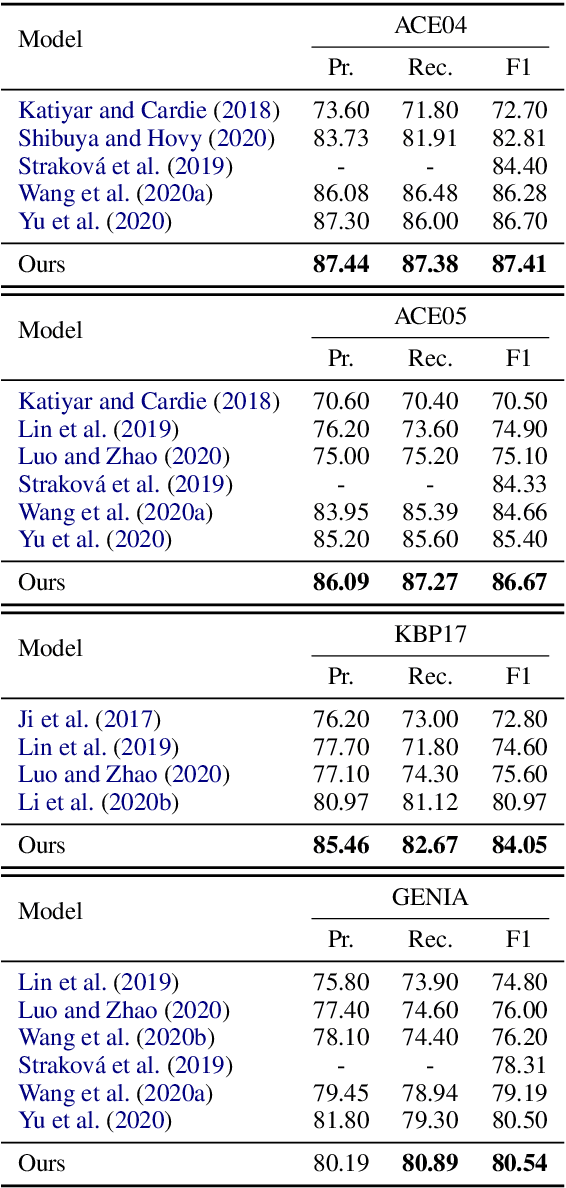
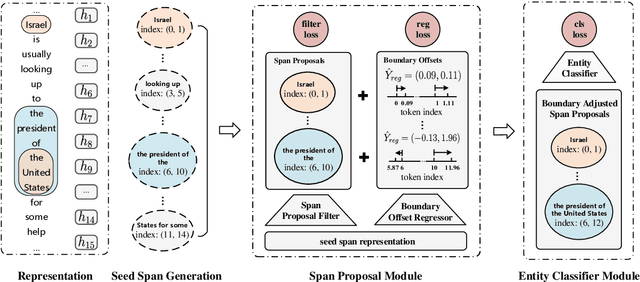
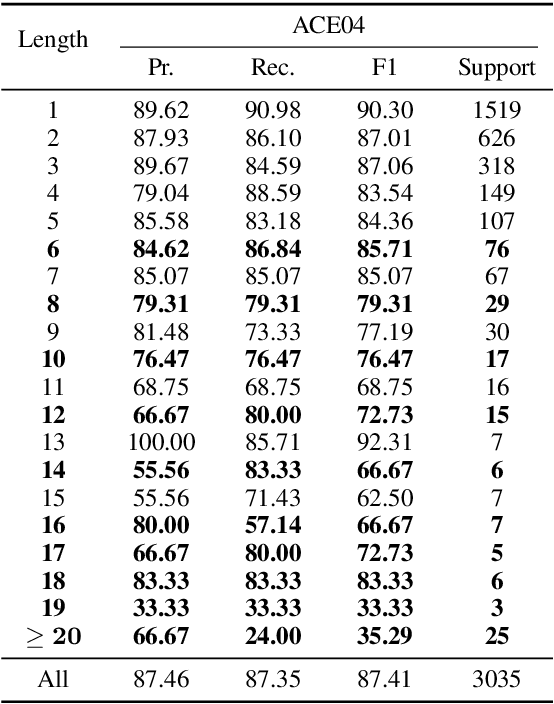
Named entity recognition (NER) is a well-studied task in natural language processing. Traditional NER research only deals with flat entities and ignores nested entities. The span-based methods treat entity recognition as a span classification task. Although these methods have the innate ability to handle nested NER, they suffer from high computational cost, ignorance of boundary information, under-utilization of the spans that partially match with entities, and difficulties in long entity recognition. To tackle these issues, we propose a two-stage entity identifier. First we generate span proposals by filtering and boundary regression on the seed spans to locate the entities, and then label the boundary-adjusted span proposals with the corresponding categories. Our method effectively utilizes the boundary information of entities and partially matched spans during training. Through boundary regression, entities of any length can be covered theoretically, which improves the ability to recognize long entities. In addition, many low-quality seed spans are filtered out in the first stage, which reduces the time complexity of inference. Experiments on nested NER datasets demonstrate that our proposed method outperforms previous state-of-the-art models.
Computer-assisted construct classification of organizational performance concerning different stakeholder groups
Jul 11, 2021
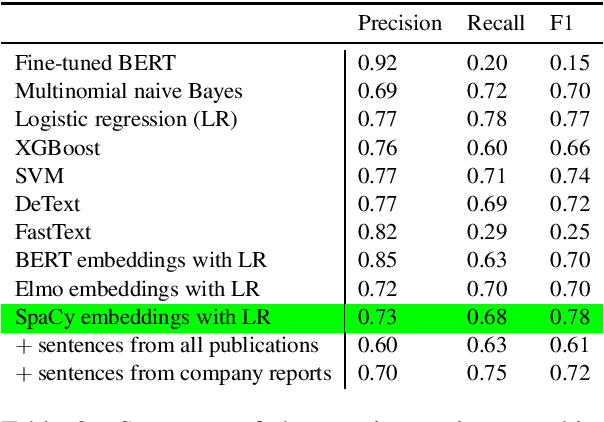
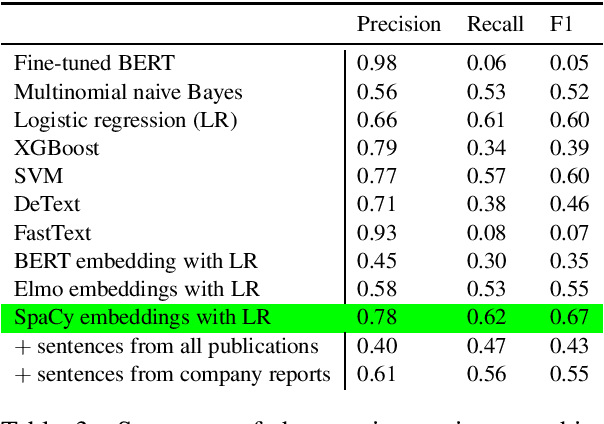
The number of research articles in business and management has dramatically increased along with terminology, constructs, and measures. Proper classification of organizational performance constructs from research articles plays an important role in categorizing the literature and understanding to whom its research implications may be relevant. In this work, we classify constructs (i.e., concepts and terminology used to capture different aspects of organizational performance) in research articles into a three-level categorization: (a) performance and non-performance categories (Level 0); (b) for performance constructs, stakeholder group-level of performance concerning investors, customers, employees, and the society (community and natural environment) (Level 1); and (c) for each stakeholder group-level, subcategories of different ways of measurement (Level 2). We observed that increasing contextual information with features extracted from surrounding sentences and external references improves classification of disaggregate-level labels, given limited training data. Our research has implications for computer-assisted construct identification and classification - an essential step for research synthesis.
A Fast Evidential Approach for Stock Forecasting
Apr 12, 2021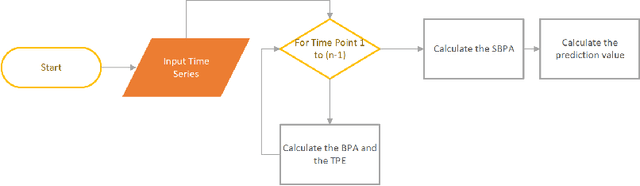

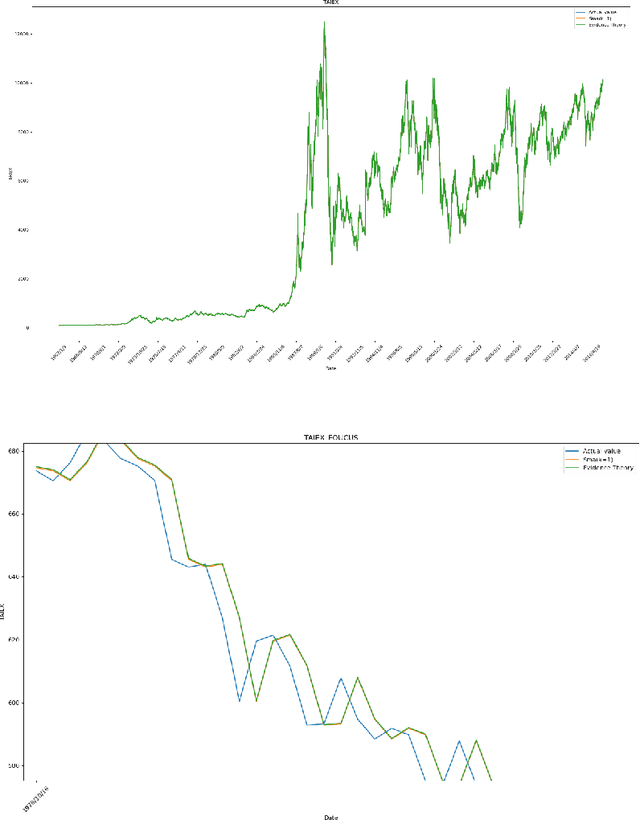

In the framework of evidence theory, data fusion combines the confidence functions of multiple different information sources to obtain a combined confidence function. Stock price prediction is the focus of economics. Stock price forecasts can provide reference data. The Dempster combination rule is a classic method of fusing different information. By using the Dempster combination rule and confidence function based on the entire time series fused at each time point and future time points, and the preliminary forecast value obtained through the time relationship, the accurate forecast value can be restored. This article will introduce the prediction method of evidence theory. This method has good running performance, can make a rapid response on a large amount of stock price data, and has far-reaching significance.
Multimodal Remote Sensing Benchmark Datasets for Land Cover Classification with A Shared and Specific Feature Learning Model
May 21, 2021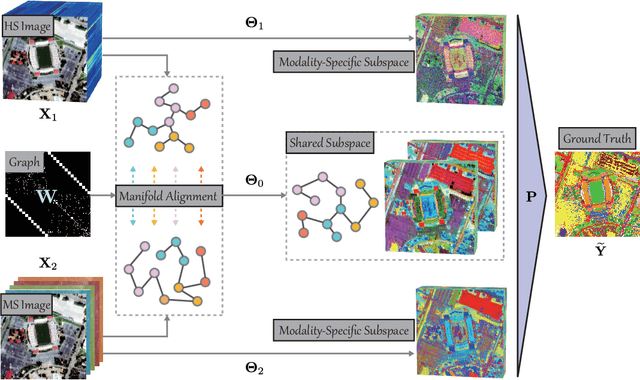

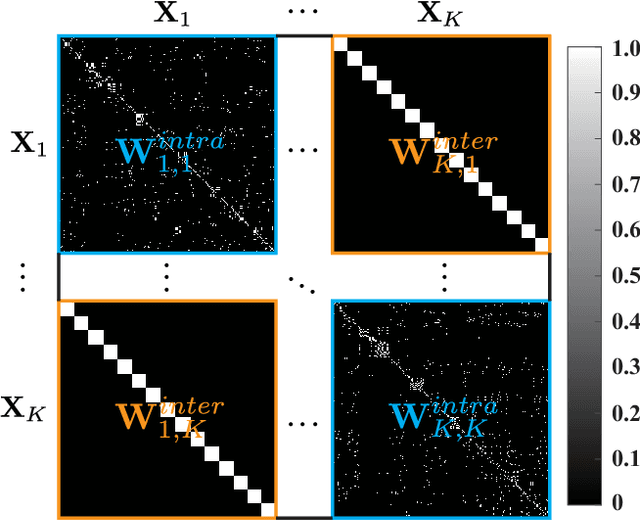
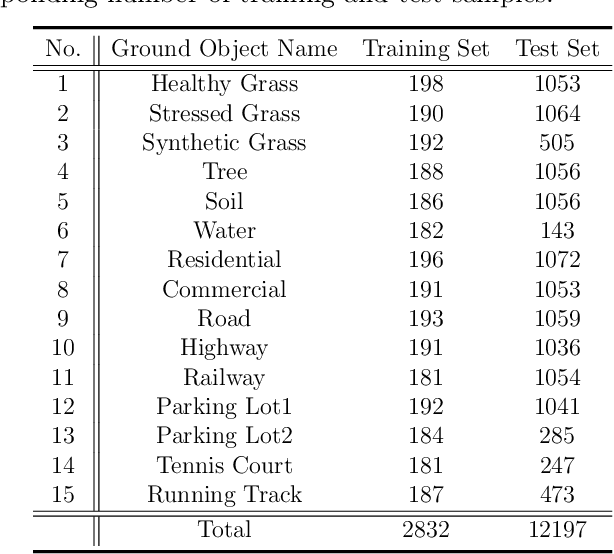
As remote sensing (RS) data obtained from different sensors become available largely and openly, multimodal data processing and analysis techniques have been garnering increasing interest in the RS and geoscience community. However, due to the gap between different modalities in terms of imaging sensors, resolutions, and contents, embedding their complementary information into a consistent, compact, accurate, and discriminative representation, to a great extent, remains challenging. To this end, we propose a shared and specific feature learning (S2FL) model. S2FL is capable of decomposing multimodal RS data into modality-shared and modality-specific components, enabling the information blending of multi-modalities more effectively, particularly for heterogeneous data sources. Moreover, to better assess multimodal baselines and the newly-proposed S2FL model, three multimodal RS benchmark datasets, i.e., Houston2013 -- hyperspectral and multispectral data, Berlin -- hyperspectral and synthetic aperture radar (SAR) data, Augsburg -- hyperspectral, SAR, and digital surface model (DSM) data, are released and used for land cover classification. Extensive experiments conducted on the three datasets demonstrate the superiority and advancement of our S2FL model in the task of land cover classification in comparison with previously-proposed state-of-the-art baselines. Furthermore, the baseline codes and datasets used in this paper will be made available freely at https://github.com/danfenghong/ISPRS_S2FL.
Variational Quantum Classifiers Through the Lens of the Hessian
May 21, 2021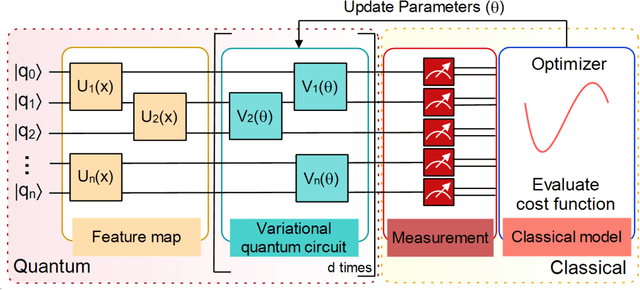
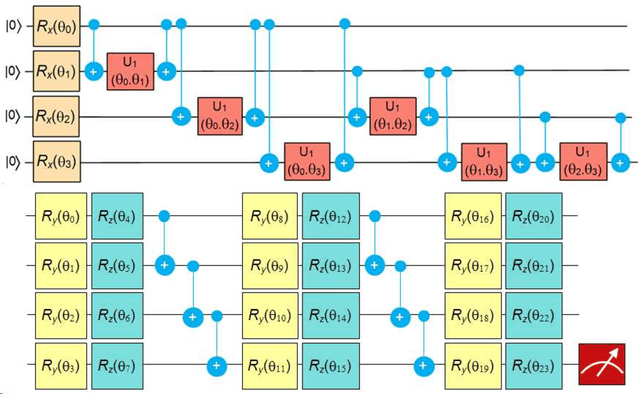
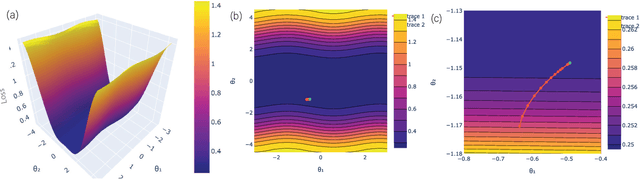
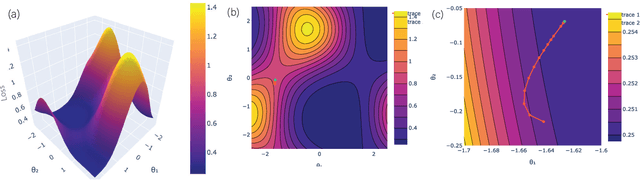
In quantum computing, the variational quantum algorithms (VQAs) are well suited for finding optimal combinations of things in specific applications ranging from chemistry all the way to finance. The training of VQAs with gradient descent optimization algorithm has shown a good convergence. At an early stage, the simulation of variational quantum circuits on noisy intermediate-scale quantum (NISQ) devices suffers from noisy outputs. Just like classical deep learning, it also suffers from vanishing gradient problems. It is a realistic goal to study the topology of loss landscape, to visualize the curvature information and trainability of these circuits in the existence of vanishing gradients. In this paper, we calculated the Hessian and visualized the loss landscape of variational quantum classifiers at different points in parameter space. The curvature information of variational quantum classifiers (VQC) is interpreted and the loss function's convergence is shown. It helps us better understand the behavior of variational quantum circuits to tackle optimization problems efficiently. We investigated the variational quantum classifiers via Hessian on quantum computers, started with a simple 4-bit parity problem to gain insight into the practical behavior of Hessian, then thoroughly analyzed the behavior of Hessian's eigenvalues on training the variational quantum classifier for the Diabetes dataset.
Hierarchical Reinforcement Learning via Advantage-Weighted Information Maximization
Jan 05, 2019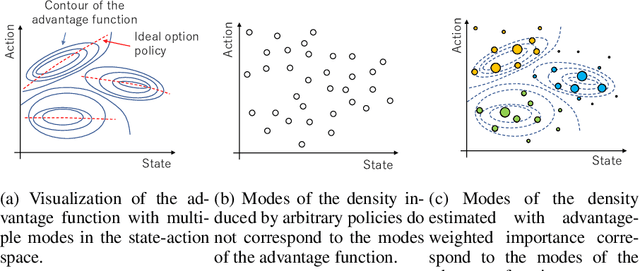
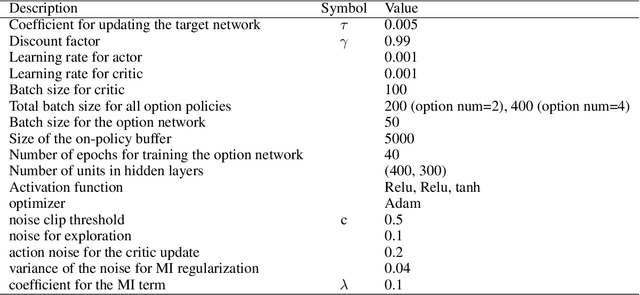


Real-world tasks are often highly structured. Hierarchical reinforcement learning (HRL) has attracted research interest as an approach for leveraging the hierarchical structure of a given task in reinforcement learning (RL). However, identifying the hierarchical policy structure that enhances the performance of RL is not a trivial task. In this paper, we propose an HRL method that learns a latent variable of a hierarchical policy using mutual information maximization. Our approach can be interpreted as a way to learn a discrete and latent representation of the state-action space. To learn option policies that correspond to modes of the advantage function, we introduce advantage-weighted importance sampling. In our HRL method, the gating policy learns to select option policies based on an option-value function, and these option policies are optimized based on the deterministic policy gradient method. This framework is derived by leveraging the analogy between a monolithic policy in standard RL and a hierarchical policy in HRL by using a deterministic option policy. Experimental results indicate that our HRL approach can learn a diversity of options and that it can enhance the performance of RL in continuous control tasks.