 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
What Does TERRA-REF's High Resolution, Multi Sensor Plant Sensing Public Domain Data Offer the Computer Vision Community?
Aug 18, 2021

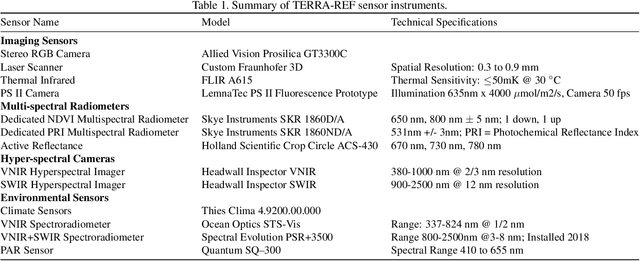


A core objective of the TERRA-REF project was to generate an open-access reference dataset for the evaluation of sensing technologies to study plants under field conditions. The TERRA-REF program deployed a suite of high-resolution, cutting edge technology sensors on a gantry system with the aim of scanning 1 hectare (10$^4$) at around 1 mm$^2$ spatial resolution multiple times per week. The system contains co-located sensors including a stereo-pair RGB camera, a thermal imager, a laser scanner to capture 3D structure, and two hyperspectral cameras covering wavelengths of 300-2500nm. This sensor data is provided alongside over sixty types of traditional plant phenotype measurements that can be used to train new machine learning models. Associated weather and environmental measurements, information about agronomic management and experimental design, and the genomic sequences of hundreds of plant varieties have been collected and are available alongside the sensor and plant phenotype data. Over the course of four years and ten growing seasons, the TERRA-REF system generated over 1 PB of sensor data and almost 45 million files. The subset that has been released to the public domain accounts for two seasons and about half of the total data volume. This provides an unprecedented opportunity for investigations far beyond the core biological scope of the project. The focus of this paper is to provide the Computer Vision and Machine Learning communities an overview of the available data and some potential applications of this one of a kind data.
Low-Rank Projections of GCNs Laplacian
Jun 04, 2021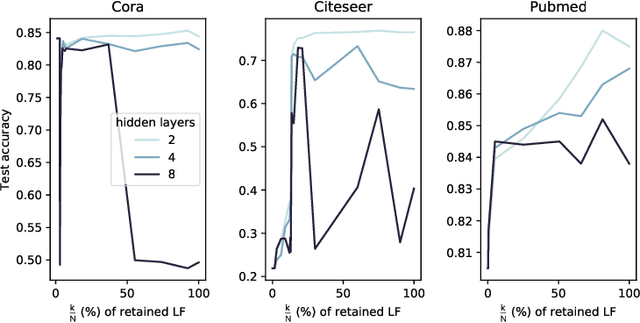
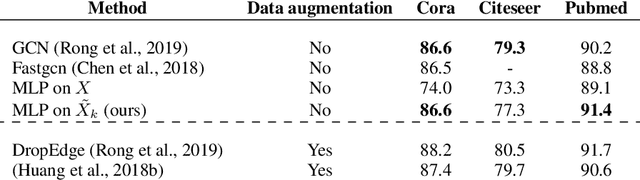
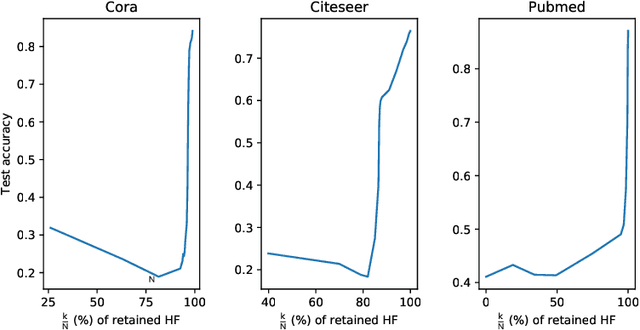

In this work, we study the behavior of standard models for community detection under spectral manipulations. Through various ablation experiments, we evaluate the impact of bandpass filtering on the performance of a GCN: we empirically show that most of the necessary and used information for nodes classification is contained in the low-frequency domain, and thus contrary to images, high frequencies are less crucial to community detection. In particular, it is sometimes possible to obtain accuracies at a state-of-the-art level with simple classifiers that rely only on a few low frequencies.
A Dataset for Answering Time-Sensitive Questions
Aug 17, 2021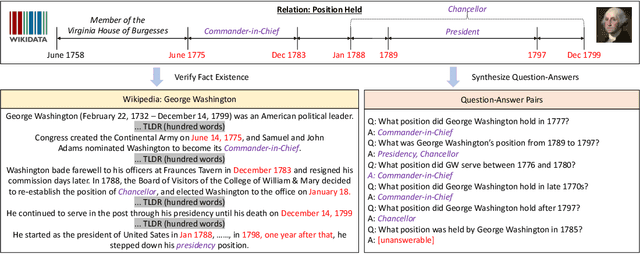
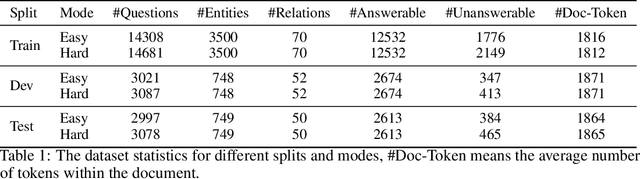
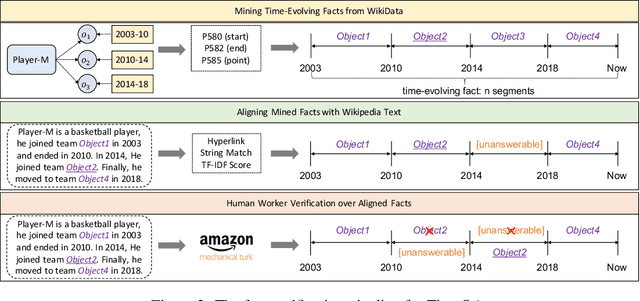
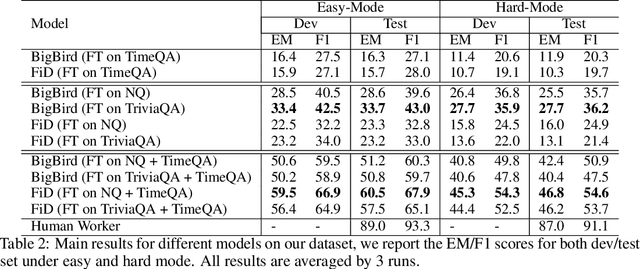
Time is an important dimension in our physical world. Lots of facts can evolve with respect to time. For example, the U.S. President might change every four years. Therefore, it is important to consider the time dimension and empower the existing QA models to reason over time. However, the existing QA datasets contain rather few time-sensitive questions, hence not suitable for diagnosing or benchmarking the model's temporal reasoning capability. In order to promote research in this direction, we propose to construct a time-sensitive QA dataset. The dataset is constructed by 1) mining time-evolving facts from WikiData and align them to their corresponding Wikipedia page, 2) employing crowd workers to verify and calibrate these noisy facts, 3) generating question-answer pairs based on the annotated time-sensitive facts. Our dataset poses two novel challenges: 1) the model needs to understand both explicit and implicit mention of time information in the long document, 2) the model needs to perform temporal reasoning like comparison, addition, subtraction. We evaluate different SoTA long-document QA systems like BigBird and FiD on our dataset. The best-performing model FiD can only achieve 46\% accuracy, still far behind the human performance of 87\%. We demonstrate that these models are still lacking the ability to perform robust temporal understanding and reasoning. Therefore, we believe that our dataset could serve as a benchmark to empower future studies in temporal reasoning. The dataset and code are released in~\url{https://github.com/wenhuchen/Time-Sensitive-QA}.
Exploiting the relationship between visual and textual features in social networks for image classification with zero-shot deep learning
Jul 08, 2021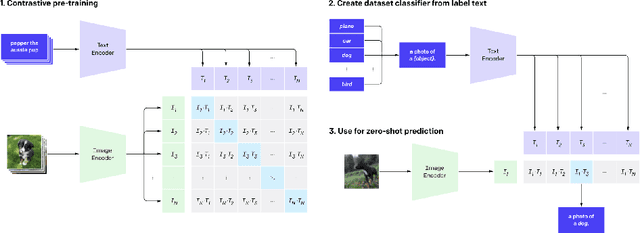


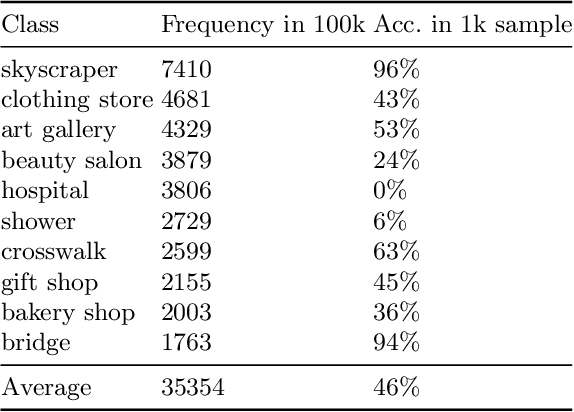
One of the main issues related to unsupervised machine learning is the cost of processing and extracting useful information from large datasets. In this work, we propose a classifier ensemble based on the transferable learning capabilities of the CLIP neural network architecture in multimodal environments (image and text) from social media. For this purpose, we used the InstaNY100K dataset and proposed a validation approach based on sampling techniques. Our experiments, based on image classification tasks according to the labels of the Places dataset, are performed by first considering only the visual part, and then adding the associated texts as support. The results obtained demonstrated that trained neural networks such as CLIP can be successfully applied to image classification with little fine-tuning, and considering the associated texts to the images can help to improve the accuracy depending on the goal. The results demonstrated what seems to be a promising research direction.
EditSpeech: A Text Based Speech Editing System Using Partial Inference and Bidirectional Fusion
Jul 04, 2021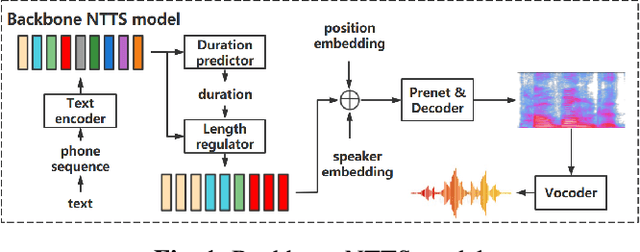
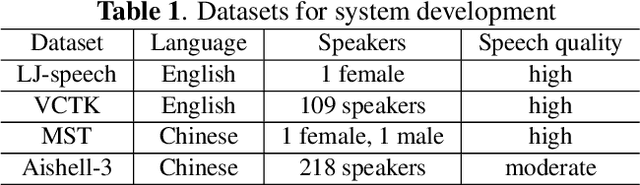
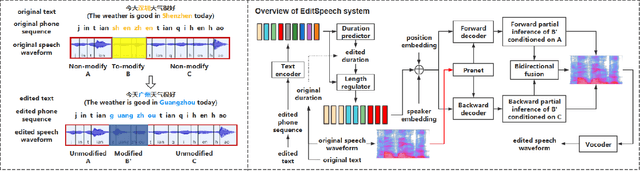
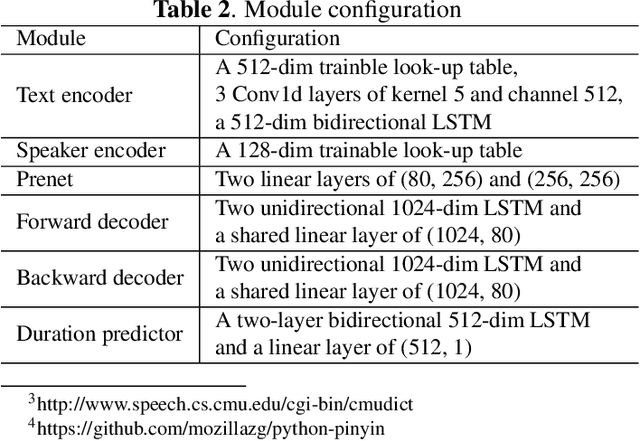
This paper presents the design, implementation and evaluation of a speech editing system, named EditSpeech, which allows a user to perform deletion, insertion and replacement of words in a given speech utterance, without causing audible degradation in speech quality and naturalness. The EditSpeech system is developed upon a neural text-to-speech (NTTS) synthesis framework. Partial inference and bidirectional fusion are proposed to effectively incorporate the contextual information related to the edited region and achieve smooth transition at both left and right boundaries. Distortion introduced to the unmodified parts of the utterance is alleviated. The EditSpeech system is developed and evaluated on English and Chinese in multi-speaker scenarios. Objective and subjective evaluation demonstrate that EditSpeech outperforms a few baseline systems in terms of low spectral distortion and preferred speech quality. Audio samples are available online for demonstration https://daxintan-cuhk.github.io/EditSpeech/ .
Contextual Argument Component Classification for Class Discussions
Feb 20, 2021
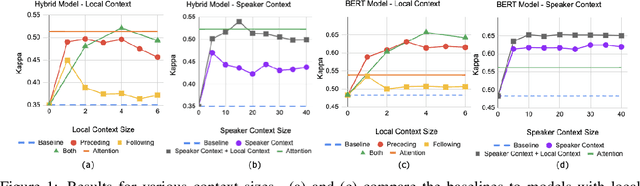
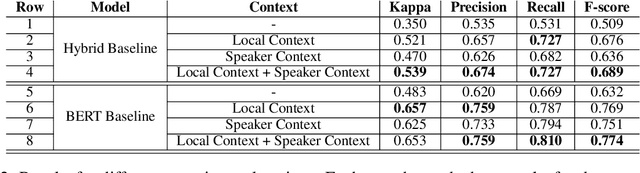
Argument mining systems often consider contextual information, i.e. information outside of an argumentative discourse unit, when trained to accomplish tasks such as argument component identification, classification, and relation extraction. However, prior work has not carefully analyzed the utility of different contextual properties in context-aware models. In this work, we show how two different types of contextual information, local discourse context and speaker context, can be incorporated into a computational model for classifying argument components in multi-party classroom discussions. We find that both context types can improve performance, although the improvements are dependent on context size and position.
Local2Global: Scaling global representation learning on graphs via local training
Jul 26, 2021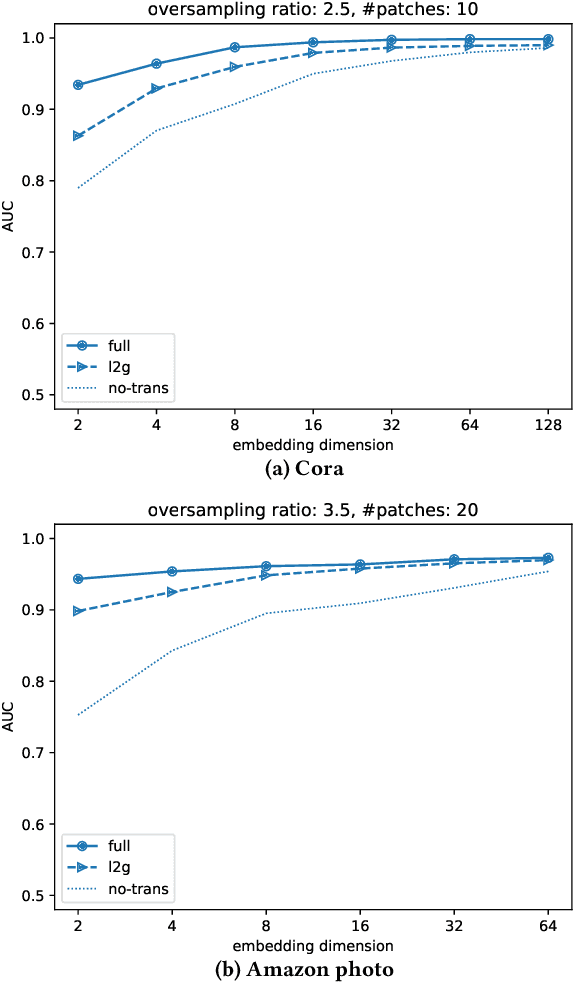
We propose a decentralised "local2global" approach to graph representation learning, that one can a-priori use to scale any embedding technique. Our local2global approach proceeds by first dividing the input graph into overlapping subgraphs (or "patches") and training local representations for each patch independently. In a second step, we combine the local representations into a globally consistent representation by estimating the set of rigid motions that best align the local representations using information from the patch overlaps, via group synchronization. A key distinguishing feature of local2global relative to existing work is that patches are trained independently without the need for the often costly parameter synchronisation during distributed training. This allows local2global to scale to large-scale industrial applications, where the input graph may not even fit into memory and may be stored in a distributed manner. Preliminary results on medium-scale data sets (up to $\sim$7K nodes and $\sim$200K edges) are promising, with a graph reconstruction performance for local2global that is comparable to that of globally trained embeddings. A thorough evaluation of local2global on large scale data and applications to downstream tasks, such as node classification and link prediction, constitutes ongoing work.
Video Rescaling Networks with Joint Optimization Strategies for Downscaling and Upscaling
Mar 27, 2021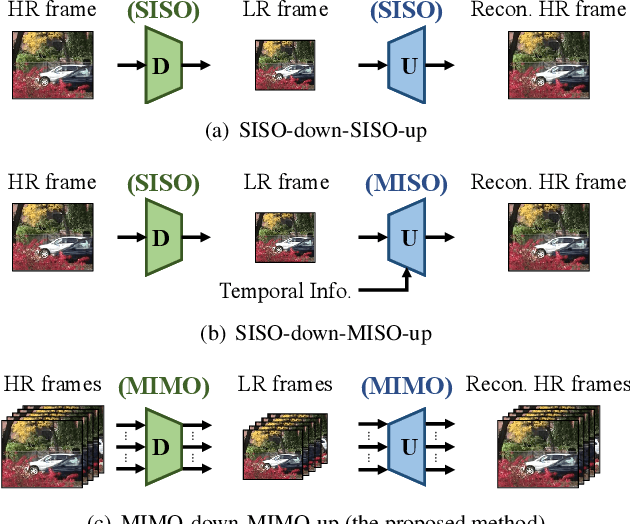
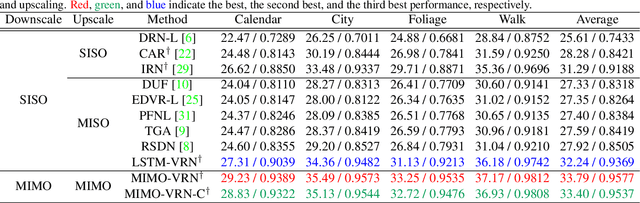
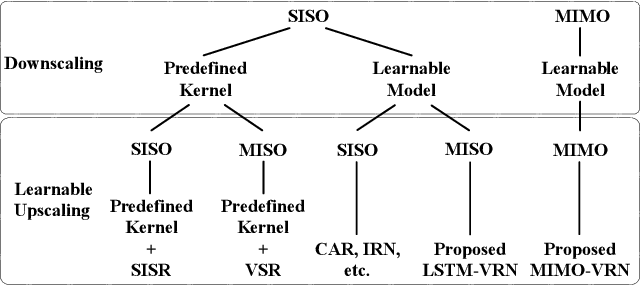
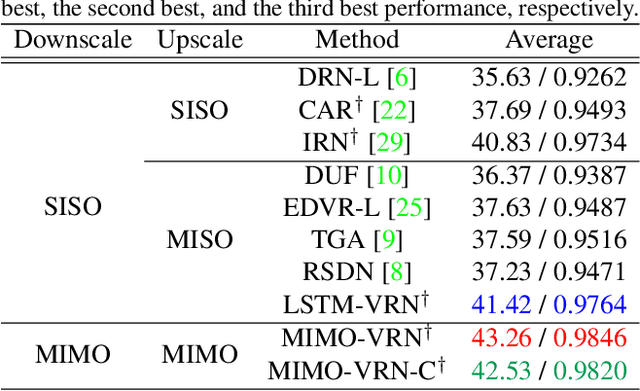
This paper addresses the video rescaling task, which arises from the needs of adapting the video spatial resolution to suit individual viewing devices. We aim to jointly optimize video downscaling and upscaling as a combined task. Most recent studies focus on image-based solutions, which do not consider temporal information. We present two joint optimization approaches based on invertible neural networks with coupling layers. Our Long Short-Term Memory Video Rescaling Network (LSTM-VRN) leverages temporal information in the low-resolution video to form an explicit prediction of the missing high-frequency information for upscaling. Our Multi-input Multi-output Video Rescaling Network (MIMO-VRN) proposes a new strategy for downscaling and upscaling a group of video frames simultaneously. Not only do they outperform the image-based invertible model in terms of quantitative and qualitative results, but also show much improved upscaling quality than the video rescaling methods without joint optimization. To our best knowledge, this work is the first attempt at the joint optimization of video downscaling and upscaling.
BigGraphVis: Leveraging Streaming Algorithms and GPU Acceleration for Visualizing Big Graphs
Aug 01, 2021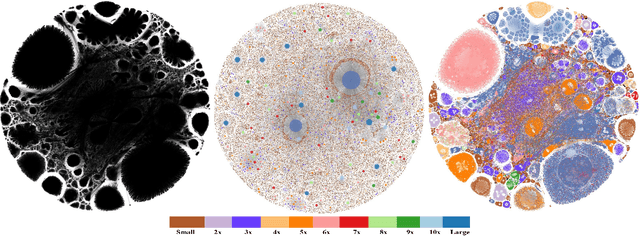
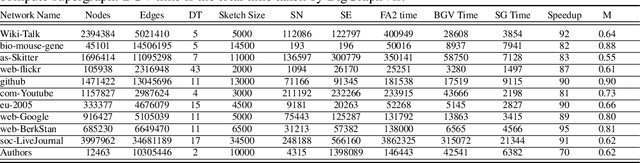
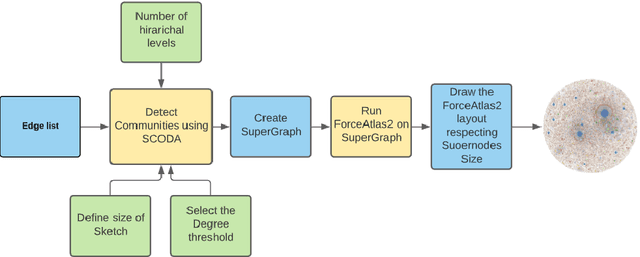
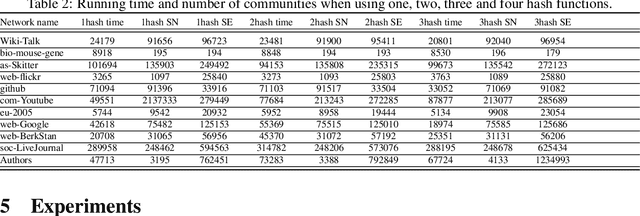
Graph layouts are key to exploring massive graphs. An enormous number of nodes and edges do not allow network analysis software to produce meaningful visualization of the pervasive networks. Long computation time, memory and display limitations encircle the software's ability to explore massive graphs. This paper introduces BigGraphVis, a new parallel graph visualization method that uses GPU parallel processing and community detection algorithm to visualize graph communities. We combine parallelized streaming community detection algorithm and probabilistic data structure to leverage parallel processing of Graphics Processing Unit (GPU). To the best of our knowledge, this is the first attempt to combine the power of streaming algorithms coupled with GPU computing to tackle big graph visualization challenges. Our method extracts community information in a few passes on the edge list, and renders the community structures using the ForceAtlas2 algorithm. Our experiment with massive real-life graphs indicates that about 70 to 95 percent speedup can be achieved by visualizing graph communities, and the visualization appears to be meaningful and reliable. The biggest graph that we examined contains above 3 million nodes and 34 million edges, and the layout computation took about five minutes. We also observed that the BigGraphVis coloring strategy can be successfully applied to produce a more informative ForceAtlas2 layout.
Subgraph-aware Few-Shot Inductive Link Prediction via Meta-Learning
Jul 26, 2021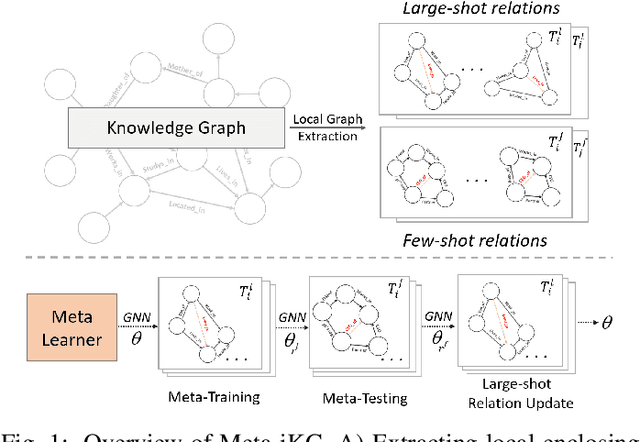
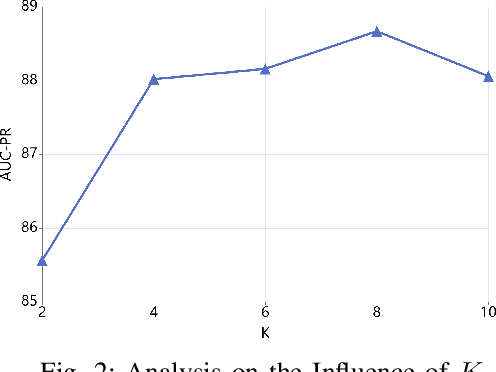


Link prediction for knowledge graphs aims to predict missing connections between entities. Prevailing methods are limited to a transductive setting and hard to process unseen entities. The recent proposed subgraph-based models provided alternatives to predict links from the subgraph structure surrounding a candidate triplet. However, these methods require abundant known facts of training triplets and perform poorly on relationships that only have a few triplets. In this paper, we propose Meta-iKG, a novel subgraph-based meta-learner for few-shot inductive relation reasoning. Meta-iKG utilizes local subgraphs to transfer subgraph-specific information and learn transferable patterns faster via meta gradients. In this way, we find the model can quickly adapt to few-shot relationships using only a handful of known facts with inductive settings. Moreover, we introduce a large-shot relation update procedure to traditional meta-learning to ensure that our model can generalize well both on few-shot and large-shot relations. We evaluate Meta-iKG on inductive benchmarks sampled from NELL and Freebase, and the results show that Meta-iKG outperforms the current state-of-the-art methods both in few-shot scenarios and standard inductive settings.