 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Privacy-Preserving Image Acquisition Using Trainable Optical Kernel
Jun 28, 2021
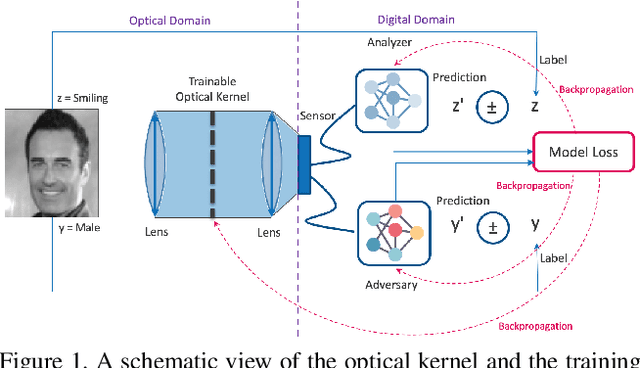
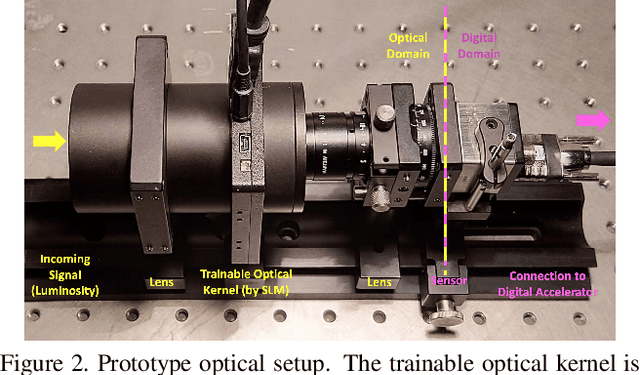
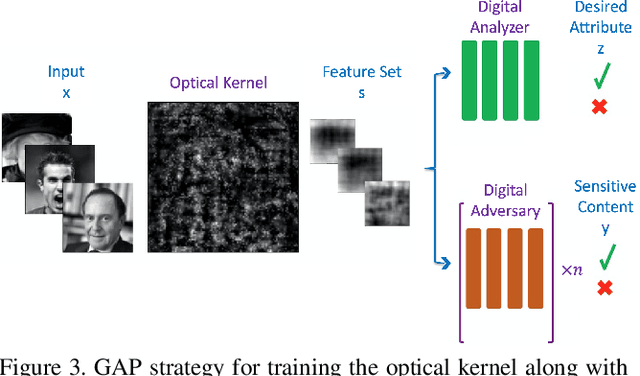

Preserving privacy is a growing concern in our society where sensors and cameras are ubiquitous. In this work, for the first time, we propose a trainable image acquisition method that removes the sensitive identity revealing information in the optical domain before it reaches the image sensor. The method benefits from a trainable optical convolution kernel which transmits the desired information while filters out the sensitive content. As the sensitive content is suppressed before it reaches the image sensor, it does not enter the digital domain therefore is unretrievable by any sort of privacy attack. This is in contrast with the current digital privacy-preserving methods that are all vulnerable to direct access attack. Also, in contrast with the previous optical privacy-preserving methods that cannot be trained, our method is data-driven and optimized for the specific application at hand. Moreover, there is no additional computation, memory, or power burden on the acquisition system since this processing happens passively in the optical domain and can even be used together and on top of the fully digital privacy-preserving systems. The proposed approach is adaptable to different digital neural networks and content. We demonstrate it for several scenarios such as smile detection as the desired attribute while the gender is filtered out as the sensitive content. We trained the optical kernel in conjunction with two adversarial neural networks where the analysis network tries to detect the desired attribute and the adversarial network tries to detect the sensitive content. We show that this method can reduce 65.1% of sensitive content when it is selected to be the gender and it only loses 7.3% of the desired content. Moreover, we reconstruct the original faces using the deep reconstruction method that confirms the ineffectiveness of reconstruction attacks to obtain the sensitive content.
CarveMix: A Simple Data Augmentation Method for Brain Lesion Segmentation
Aug 16, 2021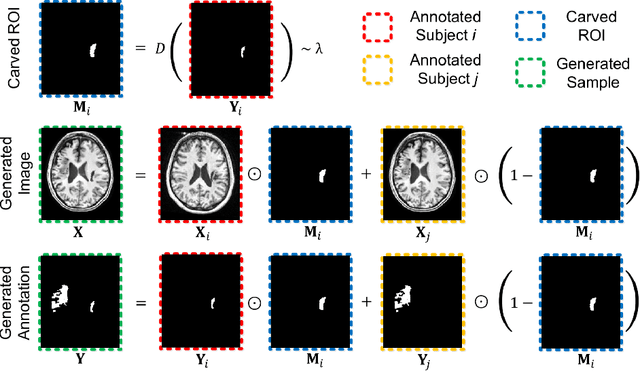

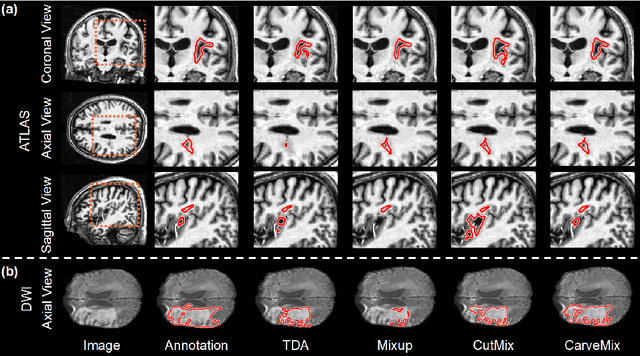
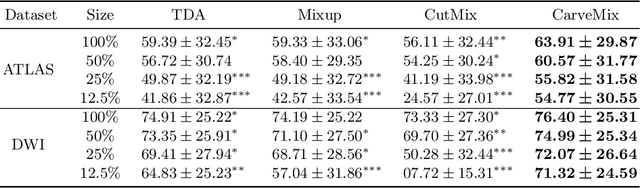
Brain lesion segmentation provides a valuable tool for clinical diagnosis, and convolutional neural networks (CNNs) have achieved unprecedented success in the task. Data augmentation is a widely used strategy that improves the training of CNNs, and the design of the augmentation method for brain lesion segmentation is still an open problem. In this work, we propose a simple data augmentation approach, dubbed as CarveMix, for CNN-based brain lesion segmentation. Like other "mix"-based methods, such as Mixup and CutMix, CarveMix stochastically combines two existing labeled images to generate new labeled samples. Yet, unlike these augmentation strategies based on image combination, CarveMix is lesion-aware, where the combination is performed with an attention on the lesions and a proper annotation is created for the generated image. Specifically, from one labeled image we carve a region of interest (ROI) according to the lesion location and geometry, and the size of the ROI is sampled from a probability distribution. The carved ROI then replaces the corresponding voxels in a second labeled image, and the annotation of the second image is replaced accordingly as well. In this way, we generate new labeled images for network training and the lesion information is preserved. To evaluate the proposed method, experiments were performed on two brain lesion datasets. The results show that our method improves the segmentation accuracy compared with other simple data augmentation approaches.
Feedback Free Distributed Transmit Beamforming using Guided Directionality
Aug 04, 2021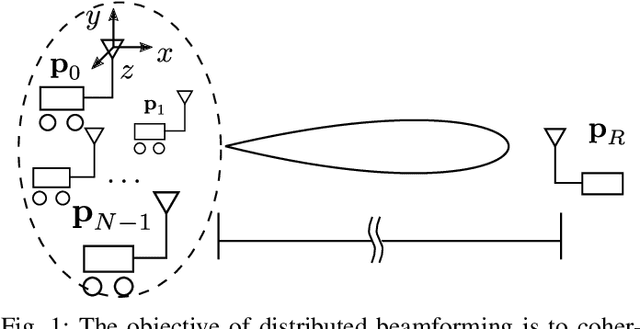

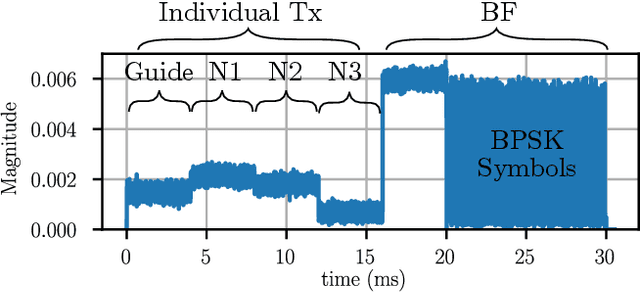

Distributed transmit beamforming enables cooperative radios to act as one virtual antenna array, extending their communications' range beyond the capabilities of a single radio. Most existing distributed beamforming approaches rely on the destination radio sending feedback to adjust the transmitters' signals for coherent combining. However, relying on the destination radio's feedback limits the communications range to that of a single radio. Existing feedback free approaches rely on phase synchronization and knowing the node locations with sub-wavelength accuracy, which becomes impractical for radios mounted on high-mobility platforms like UAVs. In this work, we propose and demonstrate a feedback free distributed beamforming approach that leverages the radio's mobility and coarse location information in a dominant line-of-sight channel. In the proposed approach, one radio acts as a guide and moves to point the beam of the remaining radios towards the destination. We specify the radios' position requirements and verify their relation to the combined signal at the destination using simulations. A proof of concept demo was implemented using software defined radios, showing up to 9dB SNR improvement in the beamforming direction just by relying on the coarse placement of four radios.
Normalization Matters in Weakly Supervised Object Localization
Jul 28, 2021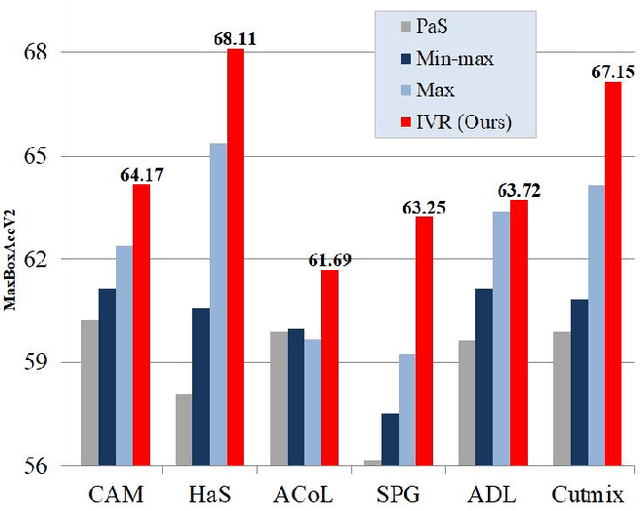
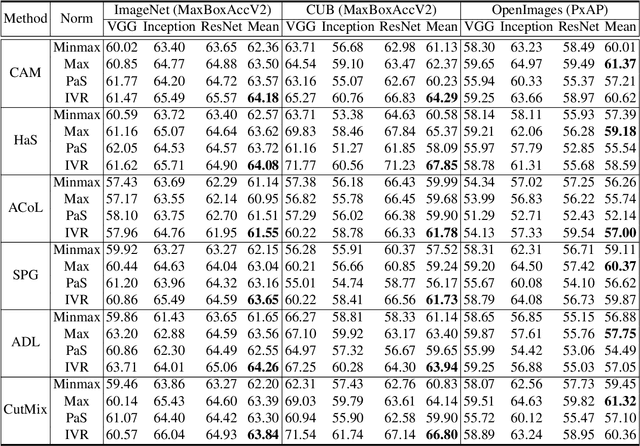
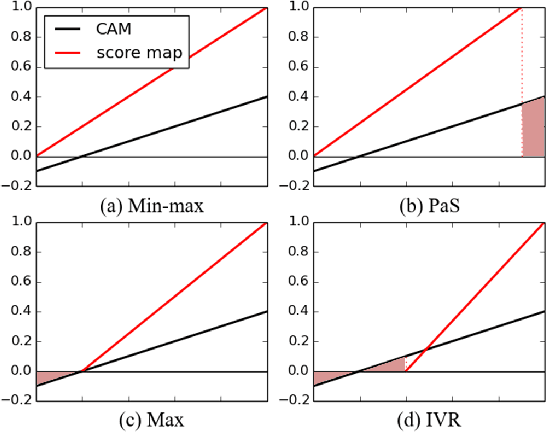
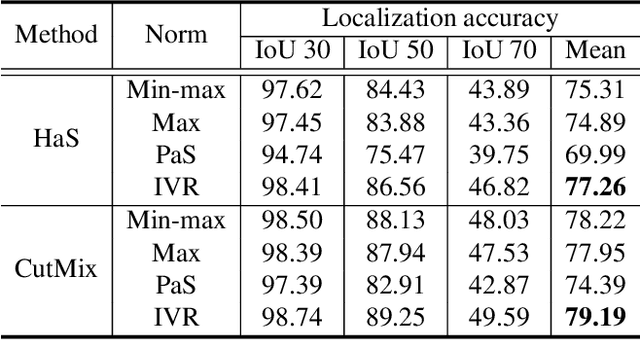
Weakly-supervised object localization (WSOL) enables finding an object using a dataset without any localization information. By simply training a classification model using only image-level annotations, the feature map of the model can be utilized as a score map for localization. In spite of many WSOL methods proposing novel strategies, there has not been any de facto standard about how to normalize the class activation map (CAM). Consequently, many WSOL methods have failed to fully exploit their own capacity because of the misuse of a normalization method. In this paper, we review many existing normalization methods and point out that they should be used according to the property of the given dataset. Additionally, we propose a new normalization method which substantially enhances the performance of any CAM-based WSOL methods. Using the proposed normalization method, we provide a comprehensive evaluation over three datasets (CUB, ImageNet and OpenImages) on three different architectures and observe significant performance gains over the conventional min-max normalization method in all the evaluated cases.
Deformed2Self: Self-Supervised Denoising for Dynamic Medical Imaging
Jun 23, 2021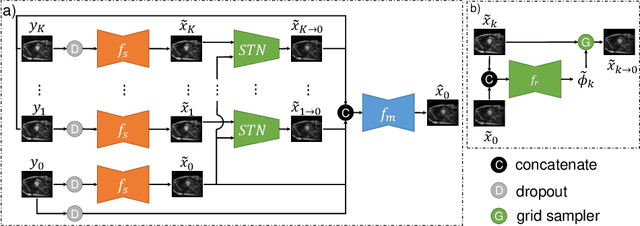
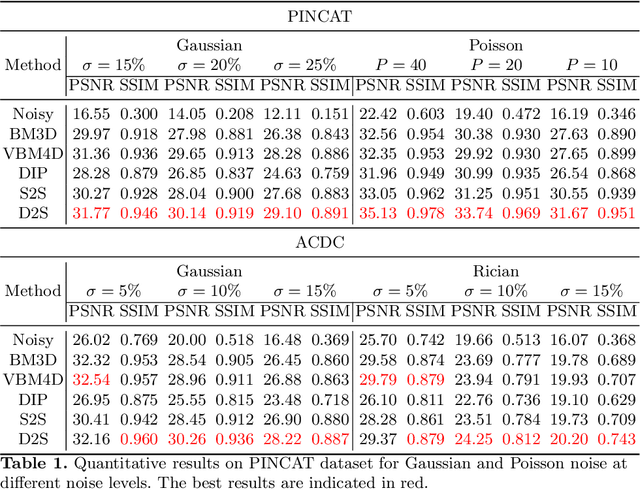
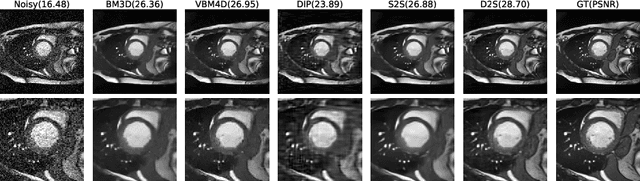
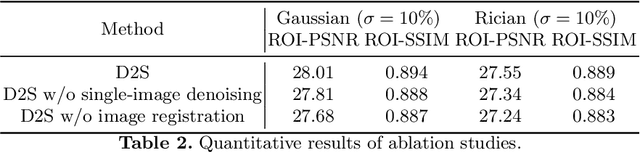
Image denoising is of great importance for medical imaging system, since it can improve image quality for disease diagnosis and downstream image analyses. In a variety of applications, dynamic imaging techniques are utilized to capture the time-varying features of the subject, where multiple images are acquired for the same subject at different time points. Although signal-to-noise ratio of each time frame is usually limited by the short acquisition time, the correlation among different time frames can be exploited to improve denoising results with shared information across time frames. With the success of neural networks in computer vision, supervised deep learning methods show prominent performance in single-image denoising, which rely on large datasets with clean-vs-noisy image pairs. Recently, several self-supervised deep denoising models have been proposed, achieving promising results without needing the pairwise ground truth of clean images. In the field of multi-image denoising, however, very few works have been done on extracting correlated information from multiple slices for denoising using self-supervised deep learning methods. In this work, we propose Deformed2Self, an end-to-end self-supervised deep learning framework for dynamic imaging denoising. It combines single-image and multi-image denoising to improve image quality and use a spatial transformer network to model motion between different slices. Further, it only requires a single noisy image with a few auxiliary observations at different time frames for training and inference. Evaluations on phantom and in vivo data with different noise statistics show that our method has comparable performance to other state-of-the-art unsupervised or self-supervised denoising methods and outperforms under high noise levels.
Deformation Recovery Control and Post-Impact Trajectory Replanning for Collision-Resilient Mobile Robots
Aug 04, 2021
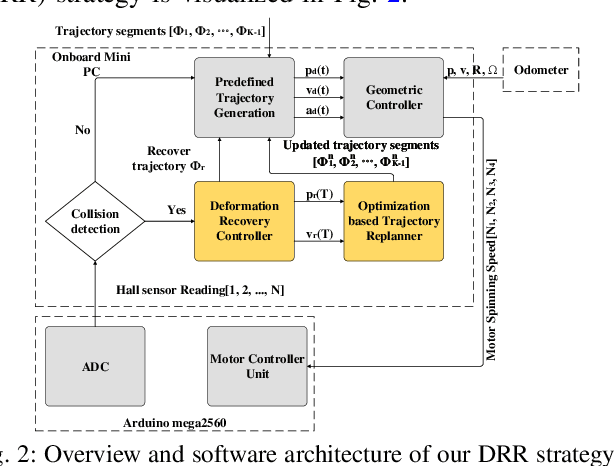

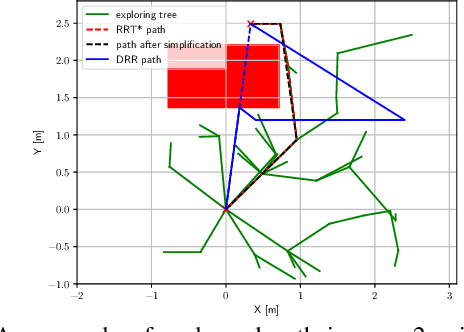
The paper focuses on collision-inclusive motion planning for impact-resilient mobile robots. We propose a new deformation recovery and replanning strategy to handle collisions that may occur at run-time. Contrary to collision avoidance methods that generate trajectories only in conservative local space or require collision checking that has high computational cost, our method directly generates (local) trajectories with imposing only waypoint constraints. If a collision occurs, our method then estimates the post-impact state and computes from there an intermediate waypoint to recover from the collision. To achieve so, we develop two novel components: 1) a deformation recovery controller that optimizes the robot's states during post-impact recovery phase, and 2) a post-impact trajectory replanner that adjusts the next waypoint with the information from the collision for the robot to pass through and generates a polynomial-based minimum effort trajectory. The proposed strategy is evaluated experimentally with an omni-directional impact-resilient wheeled robot. The robot is designed in house, and it can perceive collisions with the aid of Hall effect sensors embodied between the robot's main chassis and a surrounding deflection ring-like structure.
A Comparison of Methods for OOV-word Recognition on a New Public Dataset
Jul 16, 2021
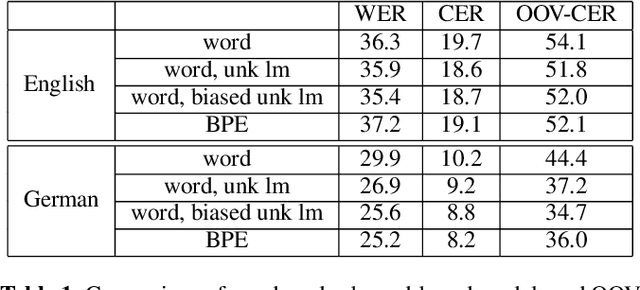
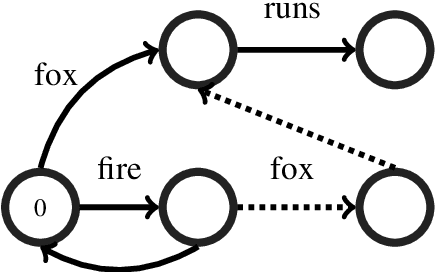
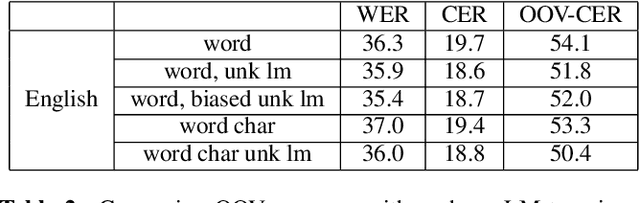
A common problem for automatic speech recognition systems is how to recognize words that they did not see during training. Currently there is no established method of evaluating different techniques for tackling this problem. We propose using the CommonVoice dataset to create test sets for multiple languages which have a high out-of-vocabulary (OOV) ratio relative to a training set and release a new tool for calculating relevant performance metrics. We then evaluate, within the context of a hybrid ASR system, how much better subword models are at recognizing OOVs, and how much benefit one can get from incorporating OOV-word information into an existing system by modifying WFSTs. Additionally, we propose a new method for modifying a subword-based language model so as to better recognize OOV-words. We showcase very large improvements in OOV-word recognition and make both the data and code available.
Partially-Observed Decoupled Data-based Control (POD2C) for Complex Robotic Systems
Jul 16, 2021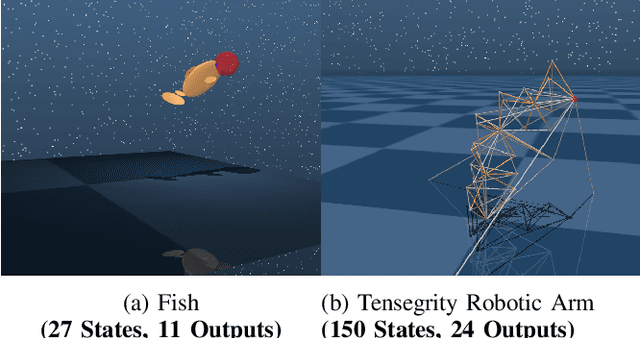
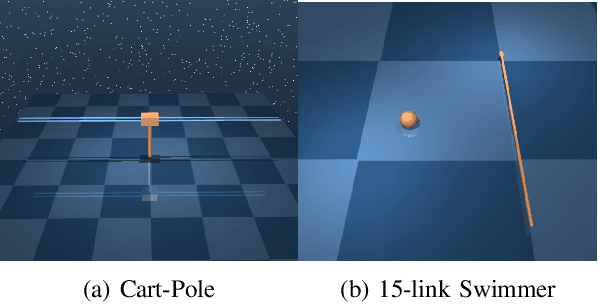
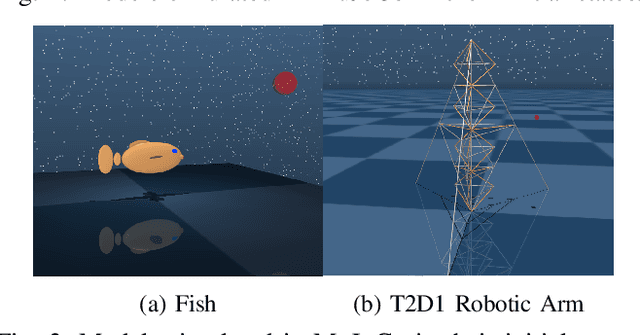
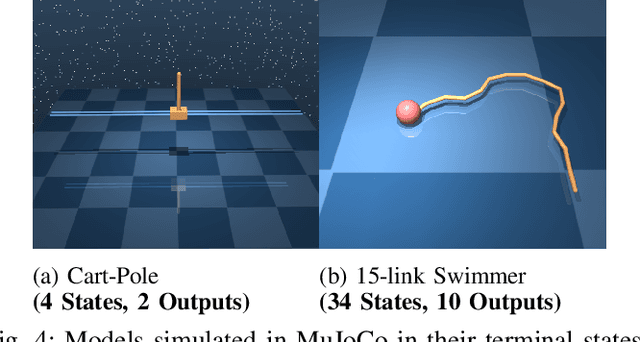
This paper develops a systematic data-based approach to the closed-loop feedback control of high-dimensional robotic systems using only partial state observation. We first develop a model-free generalization of the iterative Linear Quadratic Regulator (iLQR) to partially-observed systems using an Autoregressive Moving Average (ARMA) model, that is generated using only the input-output data. The ARMA model results in an information state, which has dimension less than or equal to the underlying actual state dimension. This open-loop trajectory optimization solution is then used to design a local feedback control law, and the composite law then provides a solution to the partially observed feedback design problem. The efficacy of the developed method is shown by controlling complex high dimensional nonlinear robotic systems in the presence of model and sensing uncertainty and for which analytical models are either unavailable or inaccurate.
Deep Sequence Learning with Auxiliary Information for Traffic Prediction
Jun 13, 2018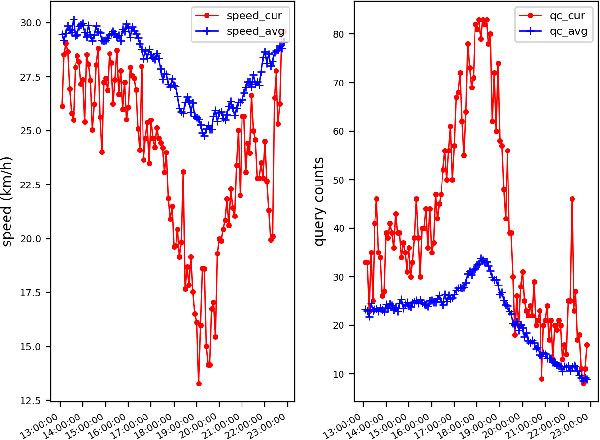

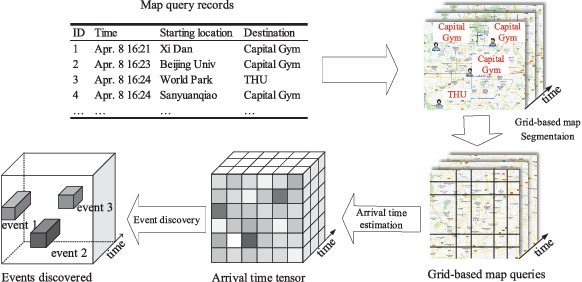
Predicting traffic conditions from online route queries is a challenging task as there are many complicated interactions over the roads and crowds involved. In this paper, we intend to improve traffic prediction by appropriate integration of three kinds of implicit but essential factors encoded in auxiliary information. We do this within an encoder-decoder sequence learning framework that integrates the following data: 1) offline geographical and social attributes. For example, the geographical structure of roads or public social events such as national celebrations; 2) road intersection information. In general, traffic congestion occurs at major junctions; 3) online crowd queries. For example, when many online queries issued for the same destination due to a public performance, the traffic around the destination will potentially become heavier at this location after a while. Qualitative and quantitative experiments on a real-world dataset from Baidu have demonstrated the effectiveness of our framework.
Deep Position-wise Interaction Network for CTR Prediction
Jun 17, 2021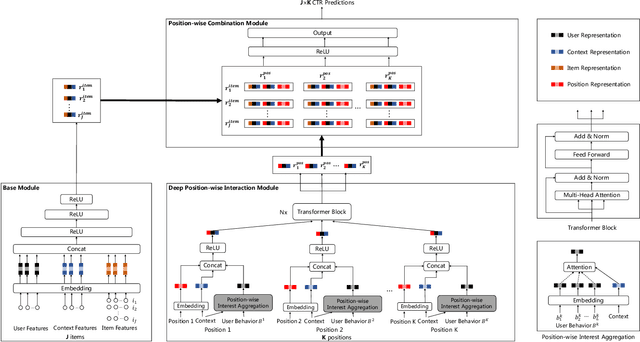
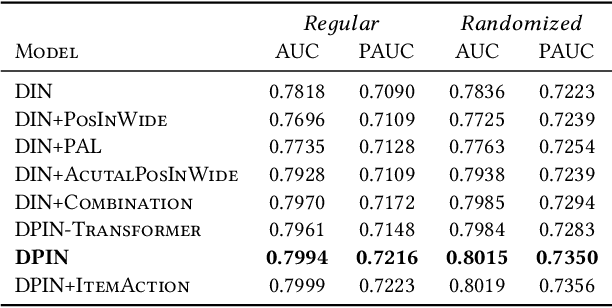
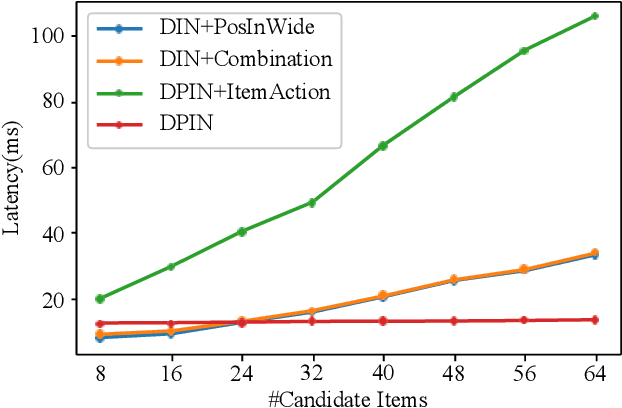
Click-through rate (CTR) prediction plays an important role in online advertising and recommender systems. In practice, the training of CTR models depends on click data which is intrinsically biased towards higher positions since higher position has higher CTR by nature. Existing methods such as actual position training with fixed position inference and inverse propensity weighted training with no position inference alleviate the bias problem to some extend. However, the different treatment of position information between training and inference will inevitably lead to inconsistency and sub-optimal online performance. Meanwhile, the basic assumption of these methods, i.e., the click probability is the product of examination probability and relevance probability, is oversimplified and insufficient to model the rich interaction between position and other information. In this paper, we propose a Deep Position-wise Interaction Network (DPIN) to efficiently combine all candidate items and positions for estimating CTR at each position, achieving consistency between offline and online as well as modeling the deep non-linear interaction among position, user, context and item under the limit of serving performance. Following our new treatment to the position bias in CTR prediction, we propose a new evaluation metrics named PAUC (position-wise AUC) that is suitable for measuring the ranking quality at a given position. Through extensive experiments on a real world dataset, we show empirically that our method is both effective and efficient in solving position bias problem. We have also deployed our method in production and observed statistically significant improvement over a highly optimized baseline in a rigorous A/B test.