 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Video Rescaling Networks with Joint Optimization Strategies for Downscaling and Upscaling
Mar 27, 2021
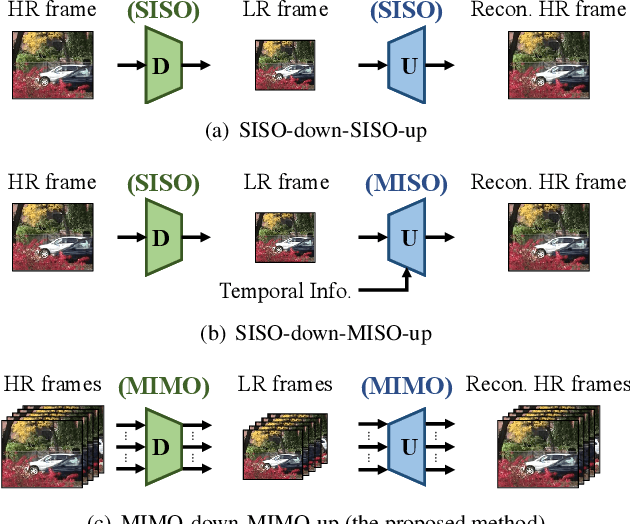
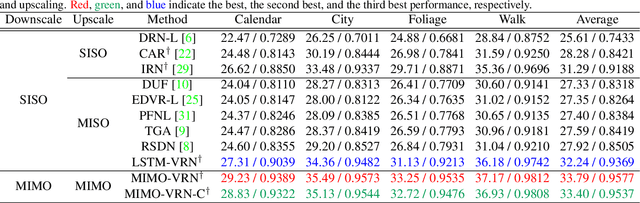
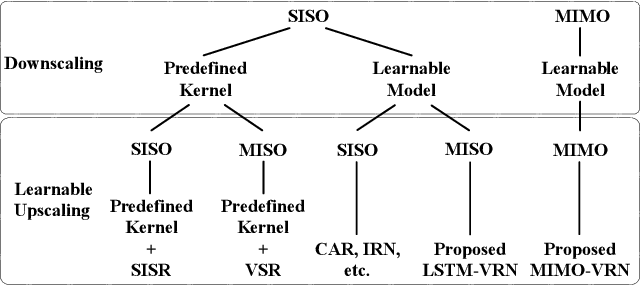
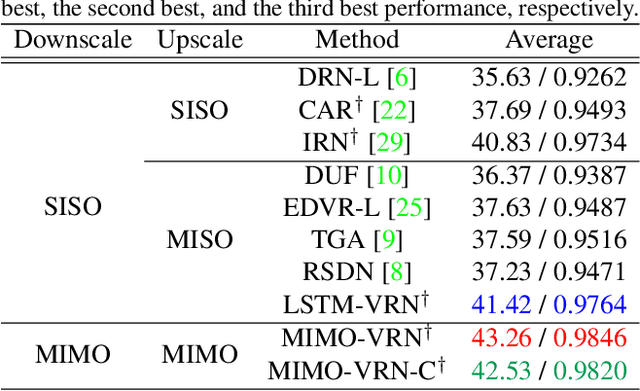
This paper addresses the video rescaling task, which arises from the needs of adapting the video spatial resolution to suit individual viewing devices. We aim to jointly optimize video downscaling and upscaling as a combined task. Most recent studies focus on image-based solutions, which do not consider temporal information. We present two joint optimization approaches based on invertible neural networks with coupling layers. Our Long Short-Term Memory Video Rescaling Network (LSTM-VRN) leverages temporal information in the low-resolution video to form an explicit prediction of the missing high-frequency information for upscaling. Our Multi-input Multi-output Video Rescaling Network (MIMO-VRN) proposes a new strategy for downscaling and upscaling a group of video frames simultaneously. Not only do they outperform the image-based invertible model in terms of quantitative and qualitative results, but also show much improved upscaling quality than the video rescaling methods without joint optimization. To our best knowledge, this work is the first attempt at the joint optimization of video downscaling and upscaling.
Investigating Attention Mechanism in 3D Point Cloud Object Detection
Aug 02, 2021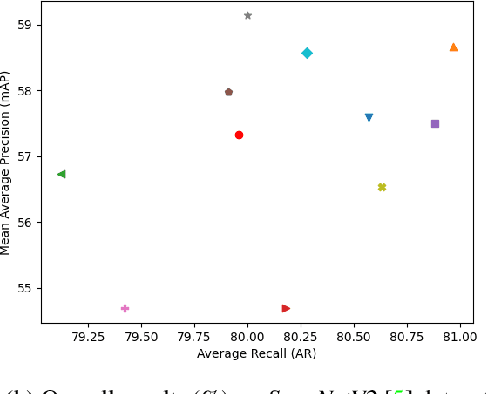
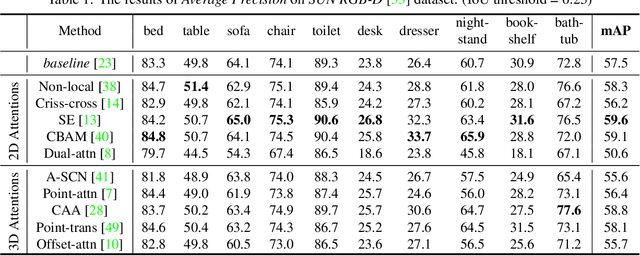
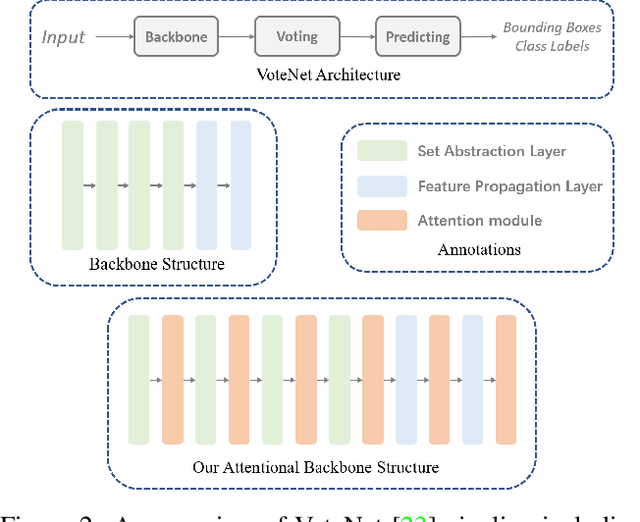
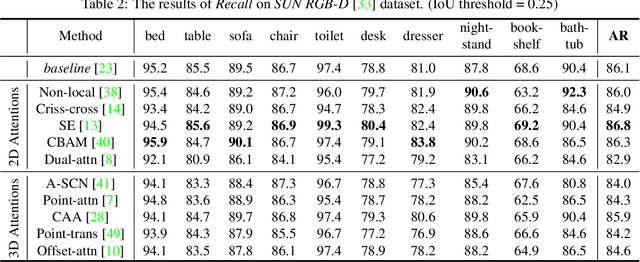
Object detection in three-dimensional (3D) space attracts much interest from academia and industry since it is an essential task in AI-driven applications such as robotics, autonomous driving, and augmented reality. As the basic format of 3D data, the point cloud can provide detailed geometric information about the objects in the original 3D space. However, due to 3D data's sparsity and unorderedness, specially designed networks and modules are needed to process this type of data. Attention mechanism has achieved impressive performance in diverse computer vision tasks; however, it is unclear how attention modules would affect the performance of 3D point cloud object detection and what sort of attention modules could fit with the inherent properties of 3D data. This work investigates the role of the attention mechanism in 3D point cloud object detection and provides insights into the potential of different attention modules. To achieve that, we comprehensively investigate classical 2D attentions, novel 3D attentions, including the latest point cloud transformers on SUN RGB-D and ScanNetV2 datasets. Based on the detailed experiments and analysis, we conclude the effects of different attention modules. This paper is expected to serve as a reference source for benefiting attention-embedded 3D point cloud object detection. The code and trained models are available at: https://github.com/ShiQiu0419/attentions_in_3D_detection.
Accurate Signal Recovery in UHF Band Reuse-1 Cellular OFDMA Downlinks
Aug 02, 2021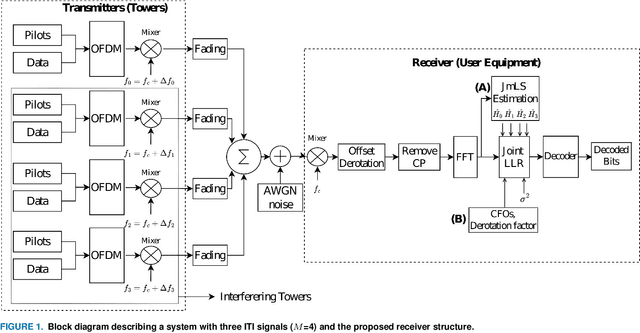
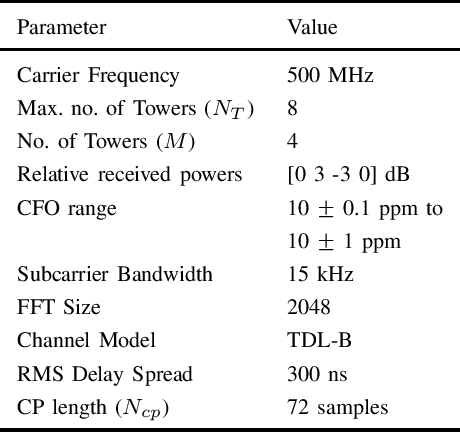
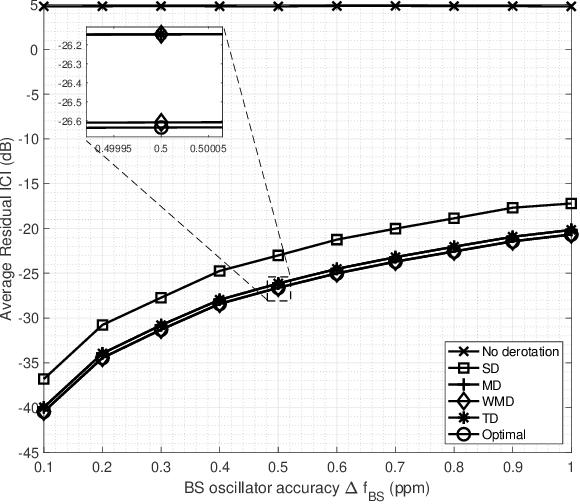

Accurate signal recovery is challenging for non-co-located transmit antennae deployments due to Inter Tower Interference (ITI) in reuse-1 cellular OFDMA networks. In the sub-1 GHz UHF band where only SISO deployment is possible, interference aware receiver algorithms are essential to mitigate the ITI. In this work, we develop a Joint Modified Least Squares (JmLS) algorithm for channel estimation in the presence of ITI. Firstly, it is shown that the JmLS algorithm achieves the Cramer-Rao lower bound. Next, an approach to managing the possibly distinct carrier frequency offsets of the different co-channel signals of interest is proposed. This improves the quality of the bit-level Joint Log-Likelihood Ratio. Finally, the impact of the choice of pilot sub-carrier information in the block modulated air-interface on the coded block error rate performance is studied. In particular, a comparison is made between (i) frequency orthogonal pilots from the different sectors, vis-a-vis, (ii) a pilot-on-pilot arrangement using pseudo-orthogonal sequences. The study indicates that based on the extent of frequency selectivity and the number of interferers being considered, (ii) is advantageous when the set of ITI pilots incident on a receiver is small when compared to the set of all possible pilots.
Frequency support Scheme based on parametrized power curve for de-loaded Wind Turbine under various wind speed
Aug 02, 2021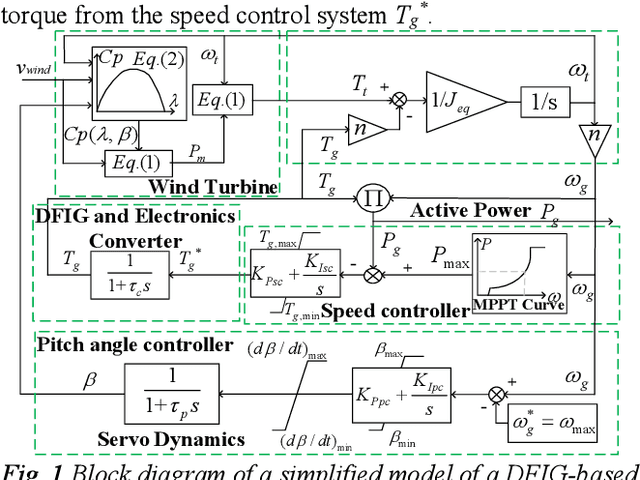
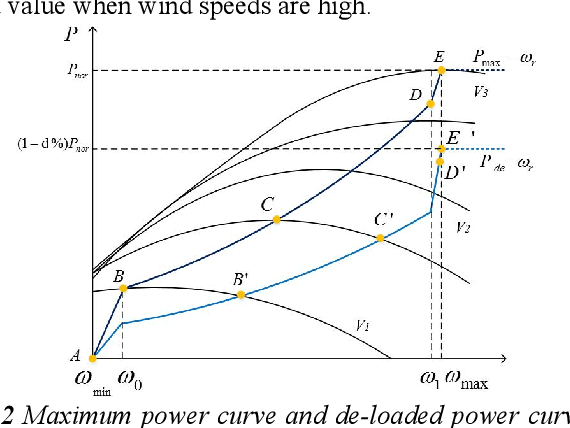
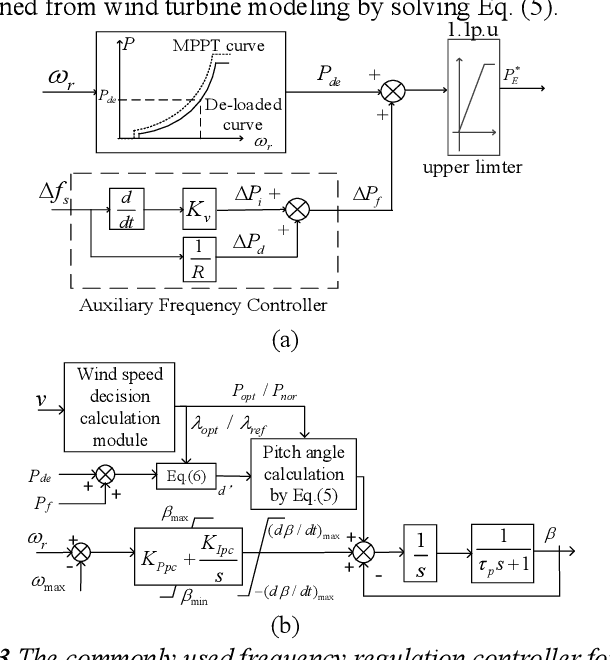
With increased wind power penetration in modern power systems, wind plants are required to provide frequency support similar to conventional plants. However, for the existing frequency regulation scheme of wind turbines, the control gains in the auxiliary frequency controller are difficult to set because of the compromise of the frequency regulation performance and the stable operation of wind turbines, especially when the wind speed remains variable. This paper proposes a novel frequency regulation scheme (FRS) for de-loaded wind turbines. Instead of an auxiliary frequency controller, frequency support is provided by modifying the parametrized power versus rotor speed curve, including the inertia power versus rotor speed curve and the droop power versus rotor speed curve. The advantage of the proposed scheme is that it does not contain any control gains and generally adapts to different wind speeds. Further, the proposed scheme can work for the whole section of wind speed without wind speed measurement information. The compared simulation results demonstrate the scheme improves the system frequency response while ensuring the stable operation of doubly-fed induction generators (DFIGs)-based variable-speed wind turbines (VSWTs) under various wind conditions. Furthermore, the scheme prevents rotor speed overdeceleration even when the wind speed decreases during frequency regulation control.
Exploiting the relationship between visual and textual features in social networks for image classification with zero-shot deep learning
Jul 08, 2021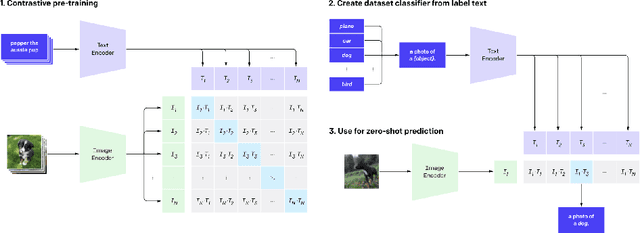


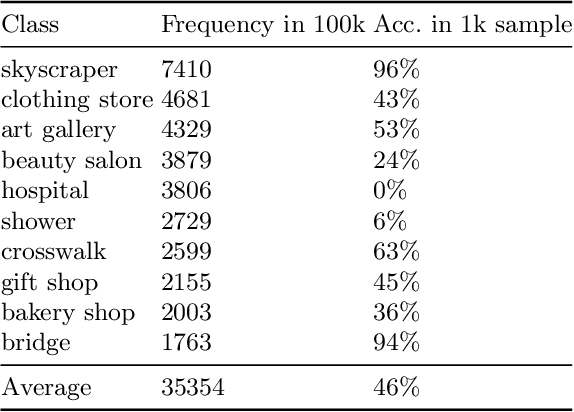
One of the main issues related to unsupervised machine learning is the cost of processing and extracting useful information from large datasets. In this work, we propose a classifier ensemble based on the transferable learning capabilities of the CLIP neural network architecture in multimodal environments (image and text) from social media. For this purpose, we used the InstaNY100K dataset and proposed a validation approach based on sampling techniques. Our experiments, based on image classification tasks according to the labels of the Places dataset, are performed by first considering only the visual part, and then adding the associated texts as support. The results obtained demonstrated that trained neural networks such as CLIP can be successfully applied to image classification with little fine-tuning, and considering the associated texts to the images can help to improve the accuracy depending on the goal. The results demonstrated what seems to be a promising research direction.
EditSpeech: A Text Based Speech Editing System Using Partial Inference and Bidirectional Fusion
Jul 04, 2021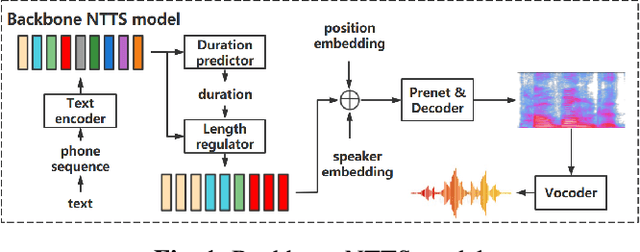
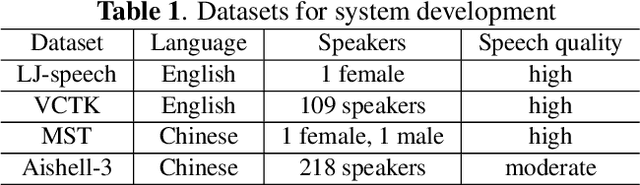
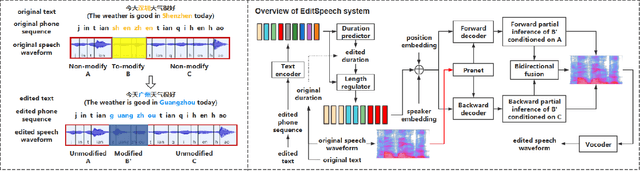
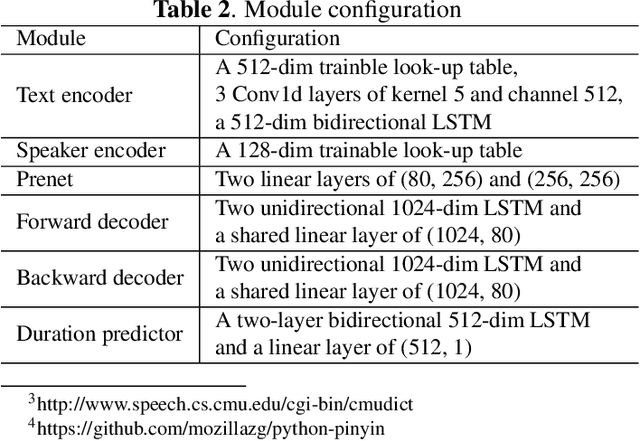
This paper presents the design, implementation and evaluation of a speech editing system, named EditSpeech, which allows a user to perform deletion, insertion and replacement of words in a given speech utterance, without causing audible degradation in speech quality and naturalness. The EditSpeech system is developed upon a neural text-to-speech (NTTS) synthesis framework. Partial inference and bidirectional fusion are proposed to effectively incorporate the contextual information related to the edited region and achieve smooth transition at both left and right boundaries. Distortion introduced to the unmodified parts of the utterance is alleviated. The EditSpeech system is developed and evaluated on English and Chinese in multi-speaker scenarios. Objective and subjective evaluation demonstrate that EditSpeech outperforms a few baseline systems in terms of low spectral distortion and preferred speech quality. Audio samples are available online for demonstration https://daxintan-cuhk.github.io/EditSpeech/ .
What Does TERRA-REF's High Resolution, Multi Sensor Plant Sensing Public Domain Data Offer the Computer Vision Community?
Aug 18, 2021
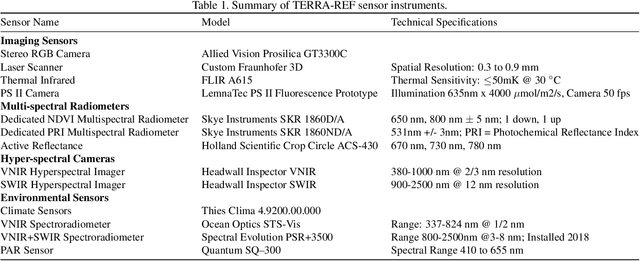


A core objective of the TERRA-REF project was to generate an open-access reference dataset for the evaluation of sensing technologies to study plants under field conditions. The TERRA-REF program deployed a suite of high-resolution, cutting edge technology sensors on a gantry system with the aim of scanning 1 hectare (10$^4$) at around 1 mm$^2$ spatial resolution multiple times per week. The system contains co-located sensors including a stereo-pair RGB camera, a thermal imager, a laser scanner to capture 3D structure, and two hyperspectral cameras covering wavelengths of 300-2500nm. This sensor data is provided alongside over sixty types of traditional plant phenotype measurements that can be used to train new machine learning models. Associated weather and environmental measurements, information about agronomic management and experimental design, and the genomic sequences of hundreds of plant varieties have been collected and are available alongside the sensor and plant phenotype data. Over the course of four years and ten growing seasons, the TERRA-REF system generated over 1 PB of sensor data and almost 45 million files. The subset that has been released to the public domain accounts for two seasons and about half of the total data volume. This provides an unprecedented opportunity for investigations far beyond the core biological scope of the project. The focus of this paper is to provide the Computer Vision and Machine Learning communities an overview of the available data and some potential applications of this one of a kind data.
A Dataset for Answering Time-Sensitive Questions
Aug 17, 2021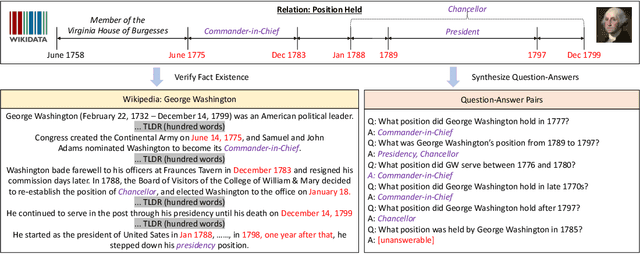
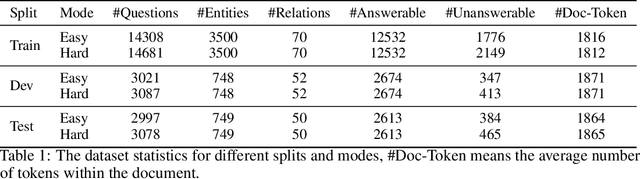
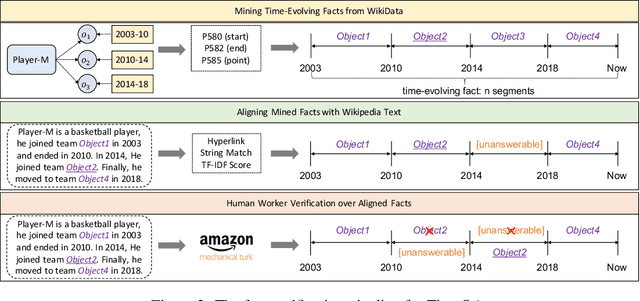
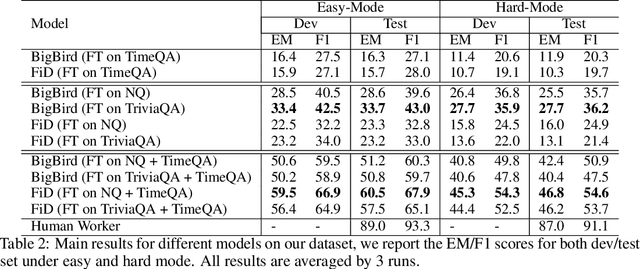
Time is an important dimension in our physical world. Lots of facts can evolve with respect to time. For example, the U.S. President might change every four years. Therefore, it is important to consider the time dimension and empower the existing QA models to reason over time. However, the existing QA datasets contain rather few time-sensitive questions, hence not suitable for diagnosing or benchmarking the model's temporal reasoning capability. In order to promote research in this direction, we propose to construct a time-sensitive QA dataset. The dataset is constructed by 1) mining time-evolving facts from WikiData and align them to their corresponding Wikipedia page, 2) employing crowd workers to verify and calibrate these noisy facts, 3) generating question-answer pairs based on the annotated time-sensitive facts. Our dataset poses two novel challenges: 1) the model needs to understand both explicit and implicit mention of time information in the long document, 2) the model needs to perform temporal reasoning like comparison, addition, subtraction. We evaluate different SoTA long-document QA systems like BigBird and FiD on our dataset. The best-performing model FiD can only achieve 46\% accuracy, still far behind the human performance of 87\%. We demonstrate that these models are still lacking the ability to perform robust temporal understanding and reasoning. Therefore, we believe that our dataset could serve as a benchmark to empower future studies in temporal reasoning. The dataset and code are released in~\url{https://github.com/wenhuchen/Time-Sensitive-QA}.
Dynamic Graph Neural Networks for Sequential Recommendation
Apr 15, 2021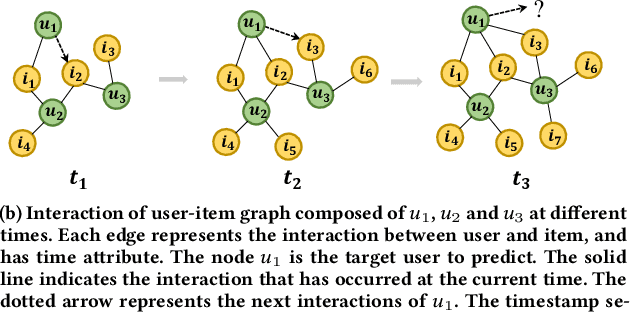
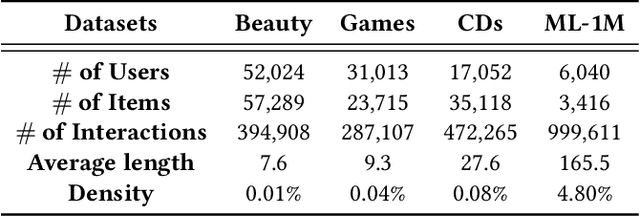
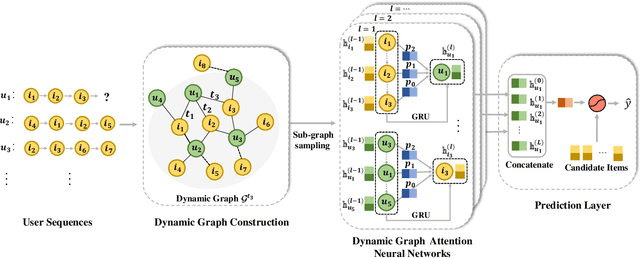
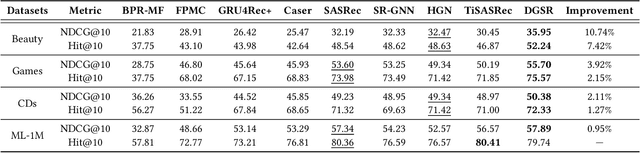
Modeling users' preference from his historical sequences is one of the core problem of sequential recommendation. Existing methods in such fields are widely distributed from conventional methods to deep learning methods. However, most of them only model users' interests within their own sequences and ignore the fine-grained utilization of dynamic collaborative signals among different user sequences, making them insufficient to explore users' preferences. We take inspiration from dynamic graph neural networks to cope with this challenge, unifying the user sequence modeling and dynamic interaction information among users into one framework. We propose a new method named \emph{Dynamic Graph Neural Network for Sequential Recommendation} (DGSR), which connects the sequence of different users through a dynamic graph structure, exploring the interactive behavior of users and items with time and order information. Furthermore, we design a Dynamic Graph Attention Neural Network to achieve the information propagation and aggregation among different users and their sequences in the dynamic graph. Consequently, the next-item prediction task in sequential recommendation is converted into a link prediction task for the user node to the item node in a dynamic graph. Extensive experiments on four public benchmarks show that DGSR outperforms several state-of-the-art methods. Further studies demonstrate the rationality and effectiveness of modeling user sequences through a dynamic graph.
Local2Global: Scaling global representation learning on graphs via local training
Jul 26, 2021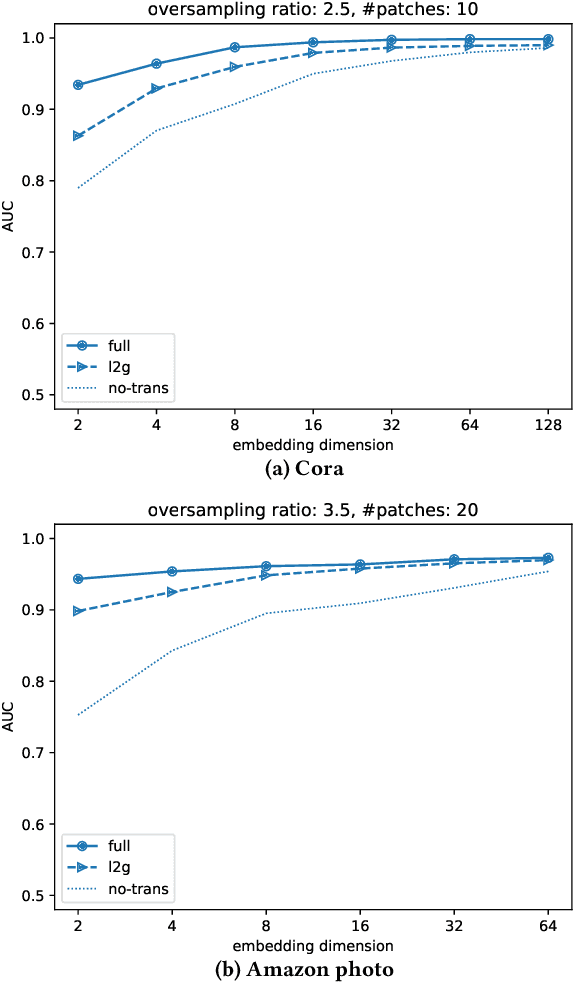
We propose a decentralised "local2global" approach to graph representation learning, that one can a-priori use to scale any embedding technique. Our local2global approach proceeds by first dividing the input graph into overlapping subgraphs (or "patches") and training local representations for each patch independently. In a second step, we combine the local representations into a globally consistent representation by estimating the set of rigid motions that best align the local representations using information from the patch overlaps, via group synchronization. A key distinguishing feature of local2global relative to existing work is that patches are trained independently without the need for the often costly parameter synchronisation during distributed training. This allows local2global to scale to large-scale industrial applications, where the input graph may not even fit into memory and may be stored in a distributed manner. Preliminary results on medium-scale data sets (up to $\sim$7K nodes and $\sim$200K edges) are promising, with a graph reconstruction performance for local2global that is comparable to that of globally trained embeddings. A thorough evaluation of local2global on large scale data and applications to downstream tasks, such as node classification and link prediction, constitutes ongoing work.