 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Deep Portrait Lighting Enhancement with 3D Guidance
Aug 04, 2021
Despite recent breakthroughs in deep learning methods for image lighting enhancement, they are inferior when applied to portraits because 3D facial information is ignored in their models. To address this, we present a novel deep learning framework for portrait lighting enhancement based on 3D facial guidance. Our framework consists of two stages. In the first stage, corrected lighting parameters are predicted by a network from the input bad lighting image, with the assistance of a 3D morphable model and a differentiable renderer. Given the predicted lighting parameter, the differentiable renderer renders a face image with corrected shading and texture, which serves as the 3D guidance for learning image lighting enhancement in the second stage. To better exploit the long-range correlations between the input and the guidance, in the second stage, we design an image-to-image translation network with a novel transformer architecture, which automatically produces a lighting-enhanced result. Experimental results on the FFHQ dataset and in-the-wild images show that the proposed method outperforms state-of-the-art methods in terms of both quantitative metrics and visual quality. We will publish our dataset along with more results on https://cassiepython.github.io/egsr/index.html.
* {\dag} for equal conribution. Accepted to CGF. Project page: https://cassiepython.github.io/egsr/index.html
Learned upper bounds for the Time-Dependent Travelling Salesman Problem
Jul 28, 2021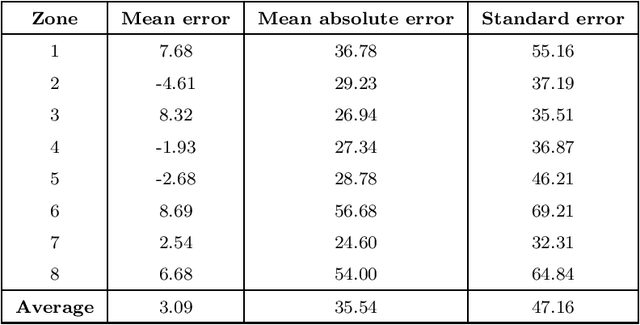
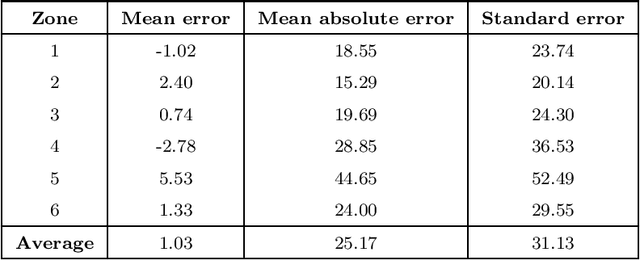
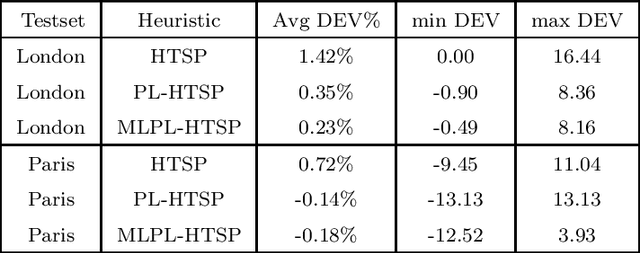
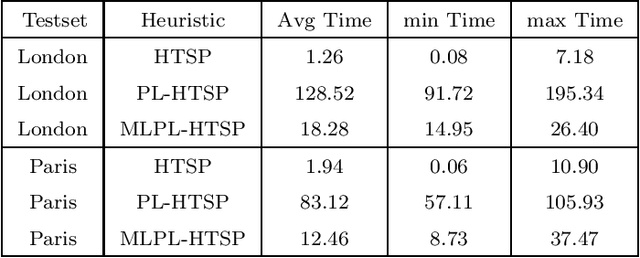
Given a graph whose arc traversal times vary over time, the Time-Dependent Travelling Salesman Problem consists in finding a Hamiltonian tour of least total duration covering the vertices of the graph. The main goal of this work is to define tight upper bounds for this problem by reusing the information gained when solving instances with similar features. This is customary in distribution management, where vehicle routes have to be generated over and over again with similar input data. To this aim, we devise an upper bounding technique based on the solution of a classical (and simpler) time-independent Asymmetric Travelling Salesman Problem, where the constant arc costs are suitably defined by the combined use of a Linear Program and a mix of unsupervised and supervised Machine Learning techniques. The effectiveness of this approach has been assessed through a computational campaign on the real travel time functions of two European cities: Paris and London. The overall average gap between our heuristic and the best-known solutions is about 0.001\%. For 31 instances, new best solutions have been obtained.
Barycenteric distribution alignment and manifold-restricted invertibility for domain generalization
Sep 04, 2021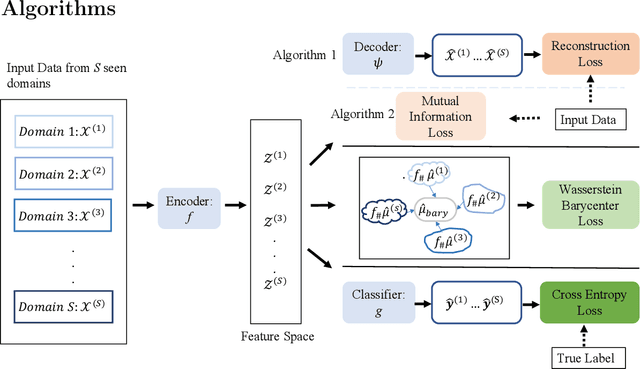
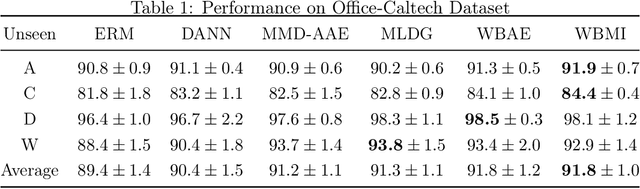
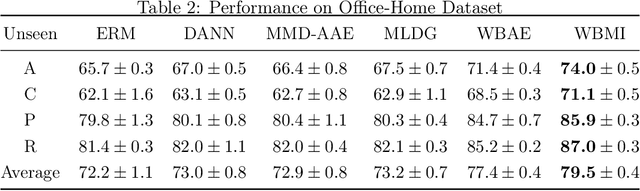
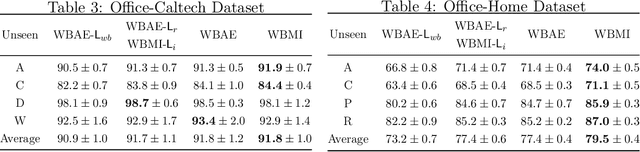
For the Domain Generalization (DG) problem where the hypotheses are composed of a common representation function followed by a labeling function, we point out a shortcoming in existing approaches that fail to explicitly optimize for a term, appearing in a well-known and widely adopted upper bound to the risk on the unseen domain, that is dependent on the representation to be learned. To this end, we first derive a novel upper bound to the prediction risk. We show that imposing a mild assumption on the representation to be learned, namely manifold restricted invertibility, is sufficient to deal with this issue. Further, unlike existing approaches, our novel upper bound doesn't require the assumption of Lipschitzness of the loss function. In addition, the distributional discrepancy in the representation space is handled via the Wasserstein-2 barycenter cost. In this context, we creatively leverage old and recent transport inequalities, which link various optimal transport metrics, in particular the $L^1$ distance (also known as the total variation distance) and the Wasserstein-2 distances, with the Kullback-Liebler divergence. These analyses and insights motivate a new representation learning cost for DG that additively balances three competing objectives: 1) minimizing classification error across seen domains via cross-entropy, 2) enforcing domain-invariance in the representation space via the Wasserstein-2 barycenter cost, and 3) promoting non-degenerate, nearly-invertible representation via one of two mechanisms, viz., an autoencoder-based reconstruction loss or a mutual information loss. It is to be noted that the proposed algorithms completely bypass the use of any adversarial training mechanism that is typical of many current domain generalization approaches. Simulation results on several standard datasets demonstrate superior performance compared to several well-known DG algorithms.
Continual Distributed Learning for Crisis Management
Apr 26, 2021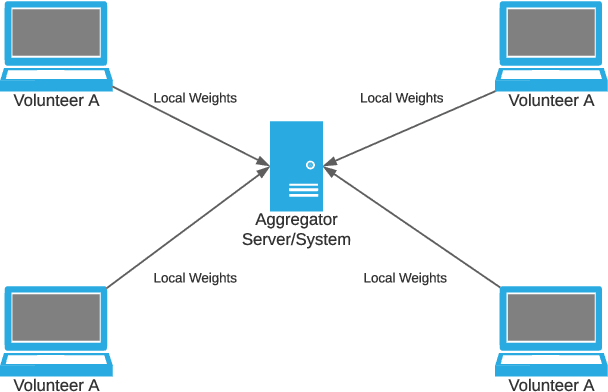
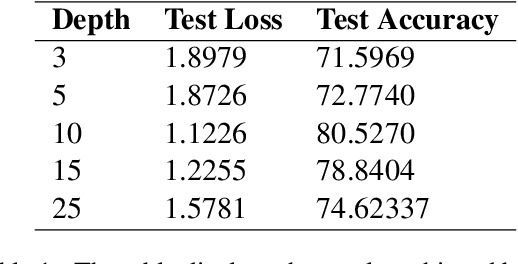
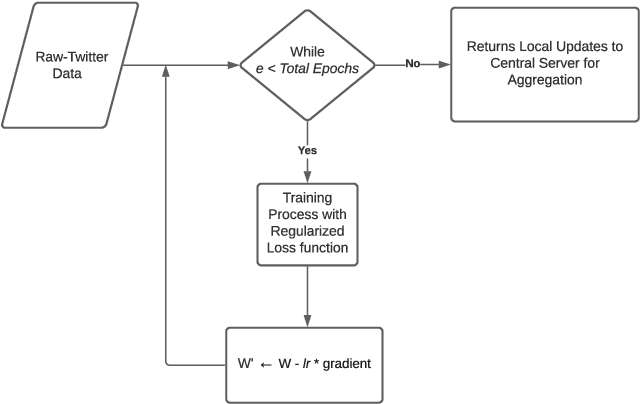
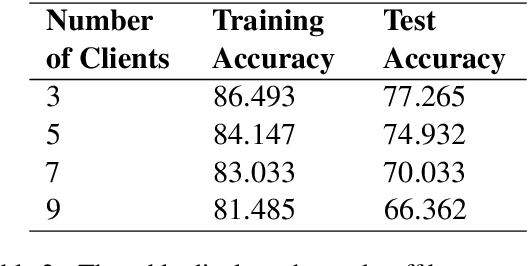
Social media platforms such as Twitter provide an excellent resource for mobile communication during emergency events. During the sudden onset of a natural or artificial disaster, important information may be posted on Twitter or similar web forums. This information can be used for disaster response and crisis management if processed accurately. However, the data present in such situations is ever-changing, and considerable resources during such crisis may not be readily available. Therefore, a low resource, continually learning system must be developed to incorporate and make NLP models robust against noisy and unordered data. We utilise regularisation to alleviate catastrophic forgetting in the target neural networks while taking a distributed approach to enable learning on resource-constrained devices. We employ federated learning for distributed learning and aggregation of the central model for continual deployment.
Orthogonal Time Frequency Space Modulation: A Discrete Zak Transform Approach
Jun 24, 2021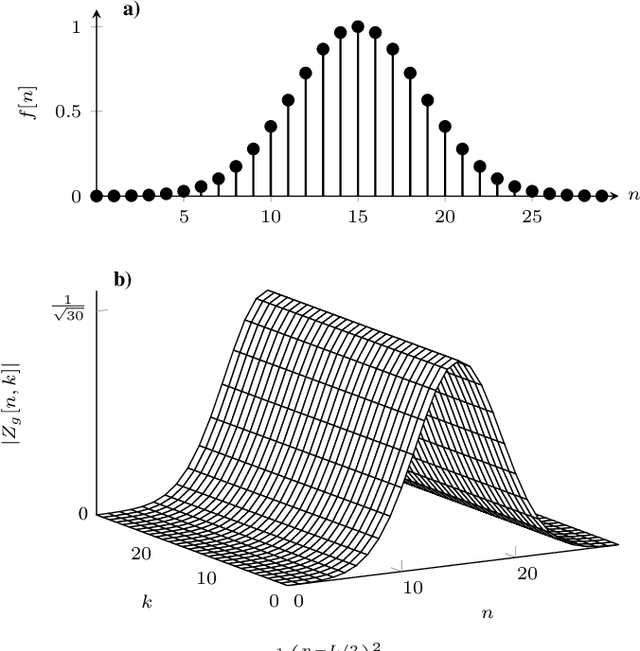
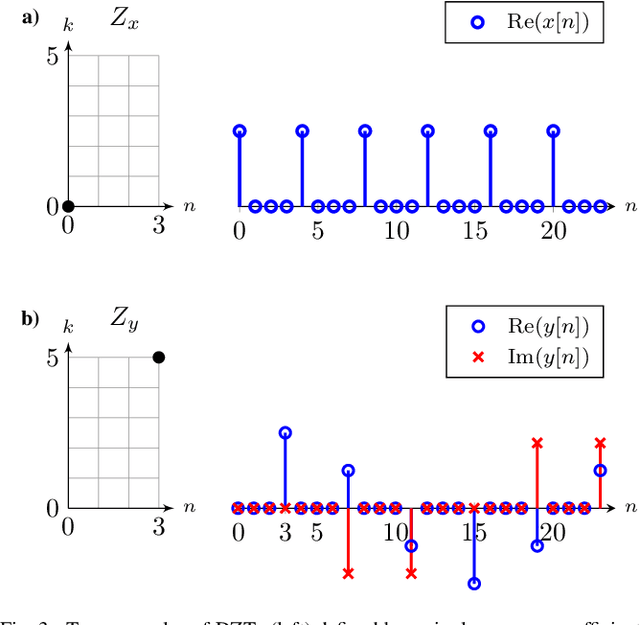
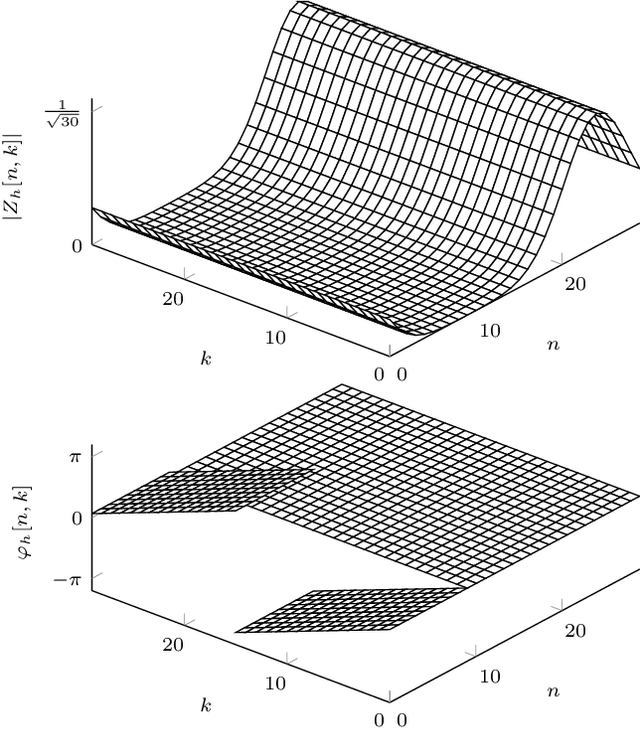
In orthogonal time frequency space (OTFS) modulation, information-carrying symbols reside in the delay-Doppler (DD) domain. By operating in the DD domain, an appealing property for communication arises: time-frequency (TF) dispersive channels encountered in high mobility environments become time-invariant. The time-invariance of the channel in the DD domain enables efficient equalizers for time-frequency dispersive channels. In this paper, we propose an OTFS system based on the discrete Zak transform. The presented formulation not only allows an efficient implementation of OTFS but also simplifies the derivation and analysis of the input-output relation of TF dispersive channel in the DD domain.
ReLMM: Practical RL for Learning Mobile Manipulation Skills Using Only Onboard Sensors
Jul 28, 2021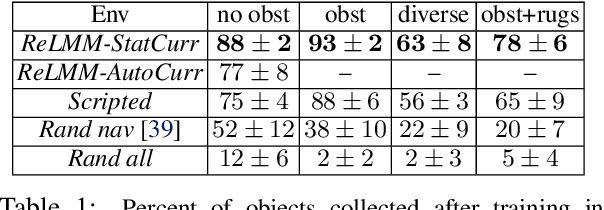
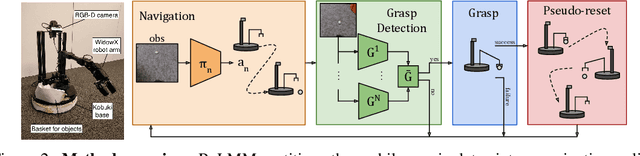

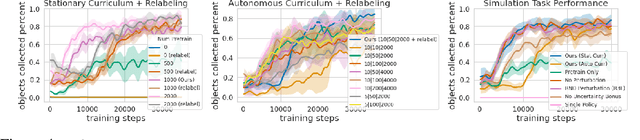
In this paper, we study how robots can autonomously learn skills that require a combination of navigation and grasping. Learning robotic skills in the real world remains challenging without large-scale data collection and supervision. Our aim is to devise a robotic reinforcement learning system for learning navigation and manipulation together, in an \textit{autonomous} way without human intervention, enabling continual learning under realistic assumptions. Specifically, our system, ReLMM, can learn continuously on a real-world platform without any environment instrumentation, without human intervention, and without access to privileged information, such as maps, objects positions, or a global view of the environment. Our method employs a modularized policy with components for manipulation and navigation, where uncertainty over the manipulation success drives exploration for the navigation controller, and the manipulation module provides rewards for navigation. We evaluate our method on a room cleanup task, where the robot must navigate to and pick up items of scattered on the floor. After a grasp curriculum training phase, ReLMM can learn navigation and grasping together fully automatically, in around 40 hours of real-world training.
Focused Attention Improves Document-Grounded Generation
Apr 26, 2021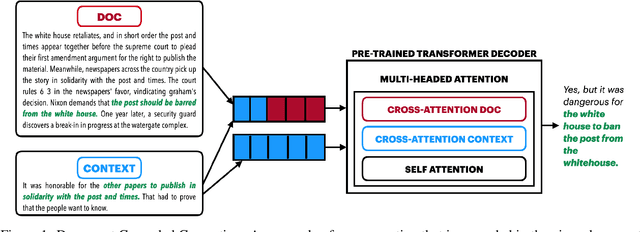
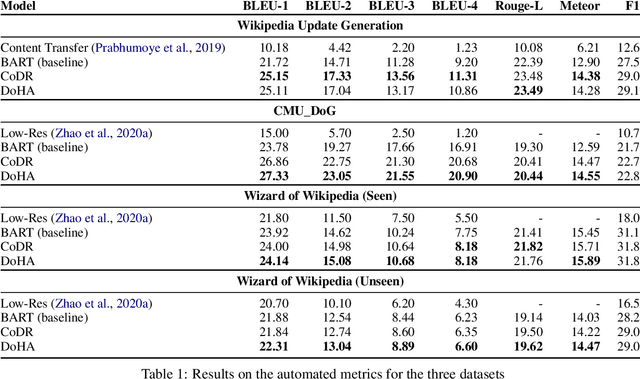
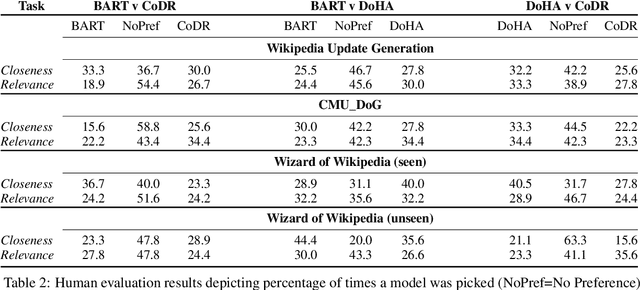
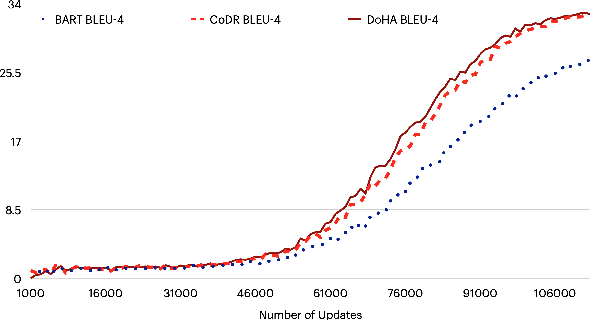
Document grounded generation is the task of using the information provided in a document to improve text generation. This work focuses on two different document grounded generation tasks: Wikipedia Update Generation task and Dialogue response generation. Our work introduces two novel adaptations of large scale pre-trained encoder-decoder models focusing on building context driven representation of the document and enabling specific attention to the information in the document. Additionally, we provide a stronger BART baseline for these tasks. Our proposed techniques outperform existing methods on both automated (at least 48% increase in BLEU-4 points) and human evaluation for closeness to reference and relevance to the document. Furthermore, we perform comprehensive manual inspection of the generated output and categorize errors to provide insights into future directions in modeling these tasks.
COVID-19 Multidimensional Kaggle Literature Organization
Jul 17, 2021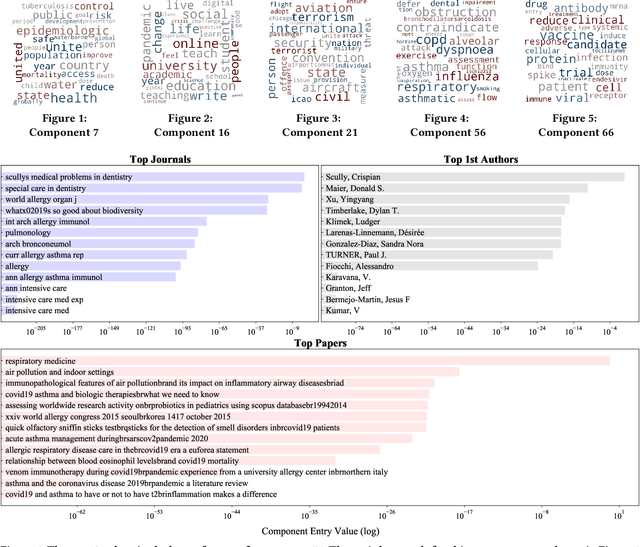
The unprecedented outbreak of Severe Acute Respiratory Syndrome Coronavirus-2 (SARS-CoV-2), or COVID-19, continues to be a significant worldwide problem. As a result, a surge of new COVID-19 related research has followed suit. The growing number of publications requires document organization methods to identify relevant information. In this paper, we expand upon our previous work with clustering the CORD-19 dataset by applying multi-dimensional analysis methods. Tensor factorization is a powerful unsupervised learning method capable of discovering hidden patterns in a document corpus. We show that a higher-order representation of the corpus allows for the simultaneous grouping of similar articles, relevant journals, authors with similar research interests, and topic keywords. These groupings are identified within and among the latent components extracted via tensor decomposition. We further demonstrate the application of this method with a publicly available interactive visualization of the dataset.
I Know What You Would Like to Drink: Benefits and Detriments of Sharing Personal Info with a Bartender Robot
Mar 25, 2021This paper introduces benefits and detriments of a robot bartender that is capable of adapting the interaction with human users according to their preferences in drinks, music, and hobbies. We believe that a personalised experience during a human-robot interaction increases the human user's engagement with the robot and that such information will be used by the robot during the interaction. However, this implies that the users need to share several personal information with the robot. In this paper, we introduce the research topic and our approach to evaluate people's perceptions and consideration of their privacy with a robot. We present a within-subject study in which participants interacted twice with a robot that firstly had not any previous info about the users, and, then, having a knowledge of their preferences. We observed that less than 60\% of the participants were not concerned about sharing personal information with the robot.
How to Query Language Models?
Aug 04, 2021
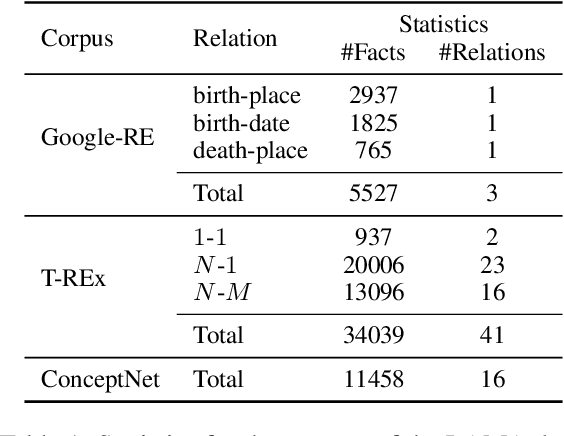

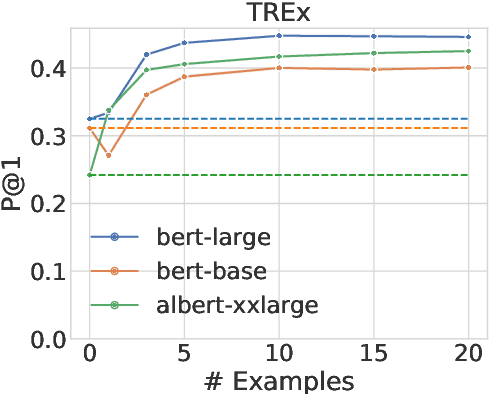
Large pre-trained language models (LMs) are capable of not only recovering linguistic but also factual and commonsense knowledge. To access the knowledge stored in mask-based LMs, we can use cloze-style questions and let the model fill in the blank. The flexibility advantage over structured knowledge bases comes with the drawback of finding the right query for a certain information need. Inspired by human behavior to disambiguate a question, we propose to query LMs by example. To clarify the ambivalent question "Who does Neuer play for?", a successful strategy is to demonstrate the relation using another subject, e.g., "Ronaldo plays for Portugal. Who does Neuer play for?". We apply this approach of querying by example to the LAMA probe and obtain substantial improvements of up to 37.8% for BERT-large on the T-REx data when providing only 10 demonstrations--even outperforming a baseline that queries the model with up to 40 paraphrases of the question. The examples are provided through the model's context and thus require neither fine-tuning nor an additional forward pass. This suggests that LMs contain more factual and commonsense knowledge than previously assumed--if we query the model in the right way.