 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Goal-driven text descriptions for images
Aug 28, 2021


A big part of achieving Artificial General Intelligence(AGI) is to build a machine that can see and listen like humans. Much work has focused on designing models for image classification, video classification, object detection, pose estimation, speech recognition, etc., and has achieved significant progress in recent years thanks to deep learning. However, understanding the world is not enough. An AI agent also needs to know how to talk, especially how to communicate with a human. While perception (vision, for example) is more common across animal species, the use of complicated language is unique to humans and is one of the most important aspects of intelligence. In this thesis, we focus on generating textual output given visual input. In Chapter 3, we focus on generating the referring expression, a text description for an object in the image so that a receiver can infer which object is being described. We use a comprehension machine to directly guide the generated referring expressions to be more discriminative. In Chapter 4, we introduce a method that encourages discriminability in image caption generation. We show that more discriminative captioning models generate more descriptive captions. In Chapter 5, we study how training objectives and sampling methods affect the models' ability to generate diverse captions. We find that a popular captioning training strategy will be detrimental to the diversity of generated captions. In Chapter 6, we propose a model that can control the length of generated captions. By changing the desired length, one can influence the style and descriptiveness of the captions. Finally, in Chapter 7, we rank/generate informative image tags according to their information utility. The proposed method better matches what humans think are the most important tags for the images.
Characterization Multimodal Connectivity of Brain Network by Hypergraph GAN for Alzheimer's Disease Analysis
Jul 21, 2021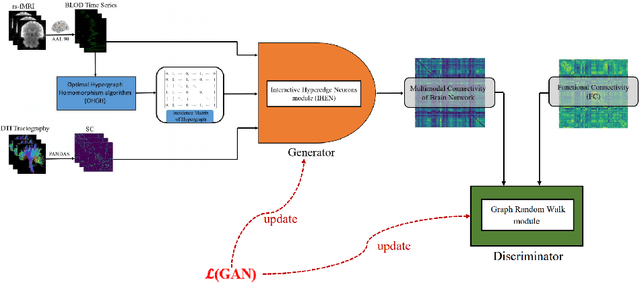
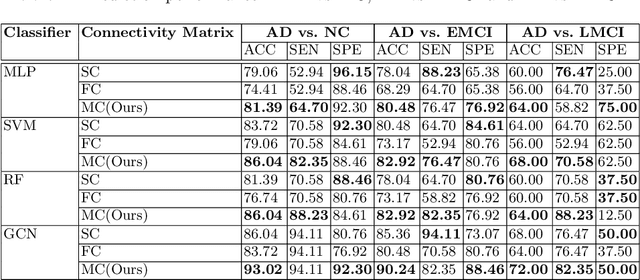
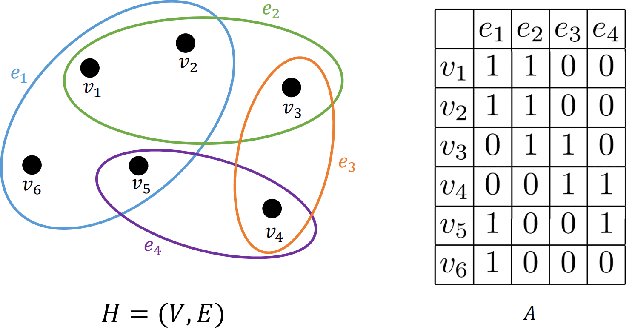
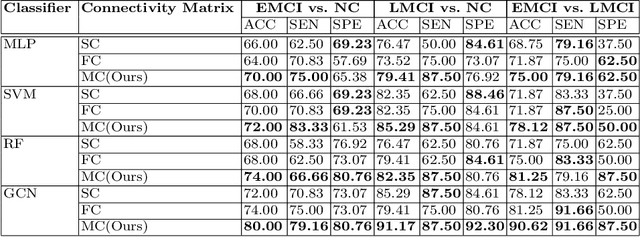
Using multimodal neuroimaging data to characterize brain network is currently an advanced technique for Alzheimer's disease(AD) Analysis. Over recent years the neuroimaging community has made tremendous progress in the study of resting-state functional magnetic resonance imaging (rs-fMRI) derived from blood-oxygen-level-dependent (BOLD) signals and Diffusion Tensor Imaging (DTI) derived from white matter fiber tractography. However, Due to the heterogeneity and complexity between BOLD signals and fiber tractography, Most existing multimodal data fusion algorithms can not sufficiently take advantage of the complementary information between rs-fMRI and DTI. To overcome this problem, a novel Hypergraph Generative Adversarial Networks(HGGAN) is proposed in this paper, which utilizes Interactive Hyperedge Neurons module (IHEN) and Optimal Hypergraph Homomorphism algorithm(OHGH) to generate multimodal connectivity of Brain Network from rs-fMRI combination with DTI. To evaluate the performance of this model, We use publicly available data from the ADNI database to demonstrate that the proposed model not only can identify discriminative brain regions of AD but also can effectively improve classification performance.
Computation and Communication Co-Design for Real-Time Monitoring and Control in Multi-Agent Systems
Aug 09, 2021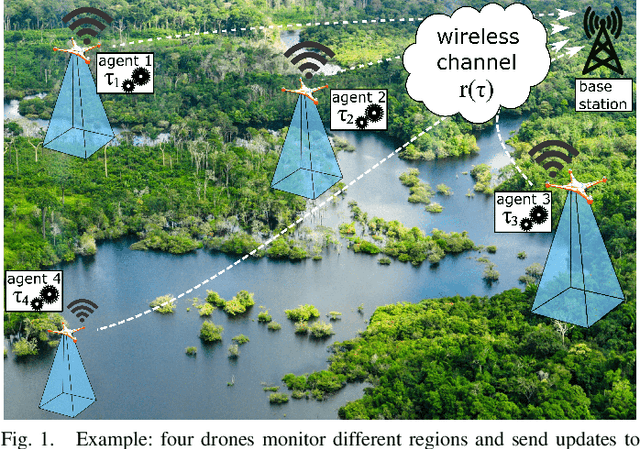
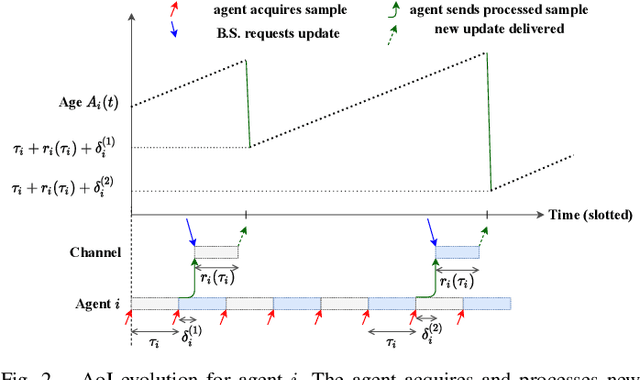
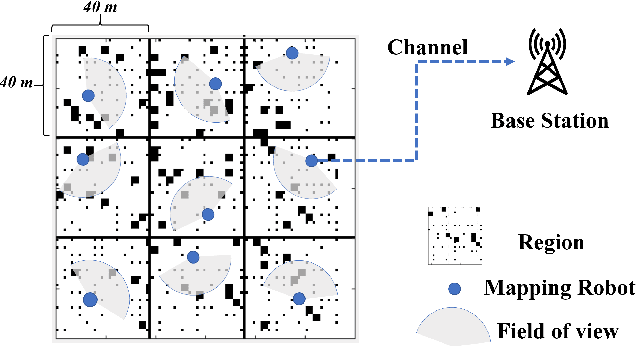
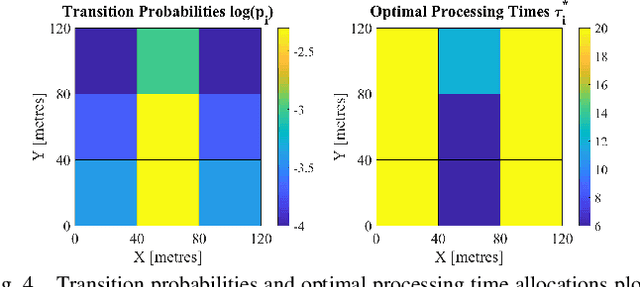
We investigate the problem of co-designing computation and communication in a multi-agent system (e.g. a sensor network or a multi-robot team). We consider the realistic setting where each agent acquires sensor data and is capable of local processing before sending updates to a base station, which is in charge of making decisions or monitoring phenomena of interest in real time. Longer processing at an agent leads to more informative updates but also larger delays, giving rise to a delay-accuracy-tradeoff in choosing the right amount of local processing at each agent. We assume that the available communication resources are limited due to interference, bandwidth, and power constraints. Thus, a scheduling policy needs to be designed to suitably share the communication channel among the agents. To that end, we develop a general formulation to jointly optimize the local processing at the agents and the scheduling of transmissions. Our novel formulation leverages the notion of Age of Information to quantify the freshness of data and capture the delays caused by computation and communication. We develop efficient resource allocation algorithms using the Whittle index approach and demonstrate our proposed algorithms in two practical applications: multi-agent occupancy grid mapping in time-varying environments, and ride sharing in autonomous vehicle networks. Our experiments show that the proposed co-design approach leads to a substantial performance improvement (18-82% in our tests).
CycleGAN-based Non-parallel Speech Enhancement with an Adaptive Attention-in-attention Mechanism
Jul 28, 2021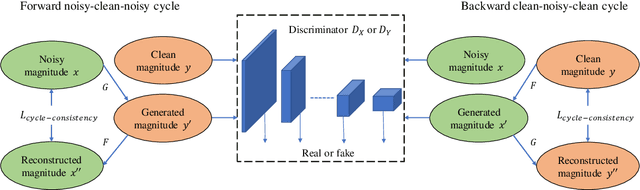
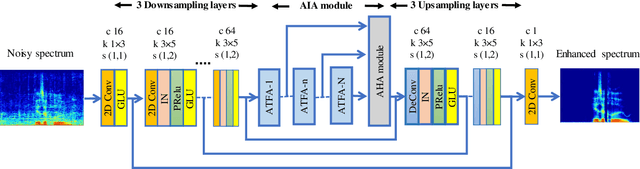
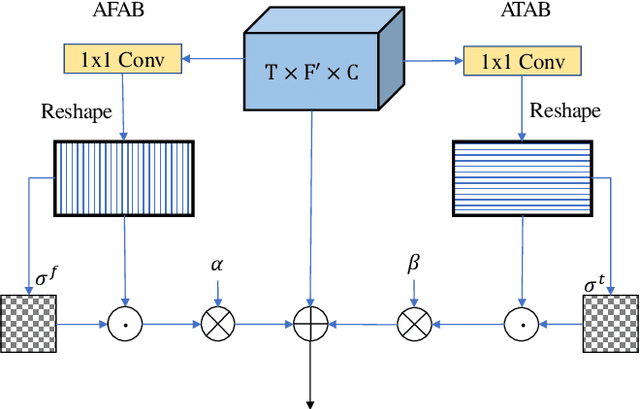
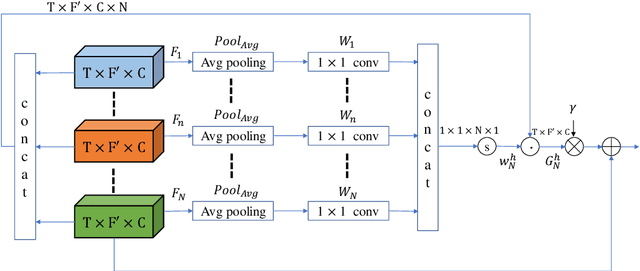
Non-parallel training is a difficult but essential task for DNN-based speech enhancement methods, for the lack of adequate noisy and paired clean speech corpus in many real scenarios. In this paper, we propose a novel adaptive attention-in-attention CycleGAN (AIA-CycleGAN) for non-parallel speech enhancement. In previous CycleGAN-based non-parallel speech enhancement methods, the limited mapping ability of the generator may cause performance degradation and insufficient feature learning. To alleviate this degradation, we propose an integration of adaptive time-frequency attention (ATFA) and adaptive hierarchical attention (AHA) to form an attention-in-attention (AIA) module for more flexible feature learning during the mapping procedure. More specifically, ATFA can capture the long-range temporal-spectral contextual information for more effective feature representations, while AHA can flexibly aggregate different intermediate feature maps by weights depending on the global context. Numerous experimental results demonstrate that the proposed approach achieves consistently more superior performance over previous GAN-based and CycleGAN-based methods in non-parallel training. Moreover, experiments in parallel training verify that the proposed AIA-CycleGAN also outperforms most advanced GAN-based speech enhancement approaches, especially in maintaining speech integrity and reducing speech distortion.
Tourbillon: a Physically Plausible Neural Architecture
Jul 13, 2021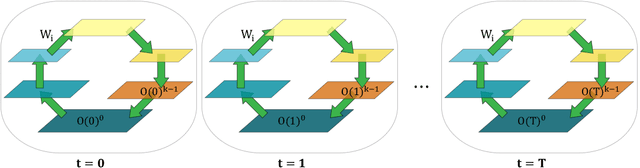
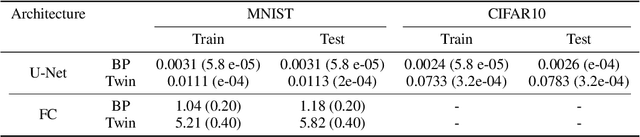
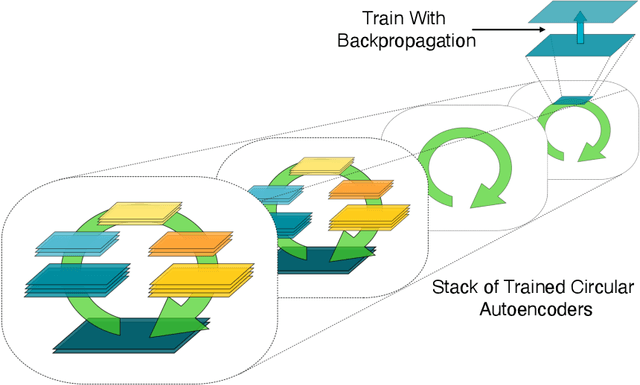
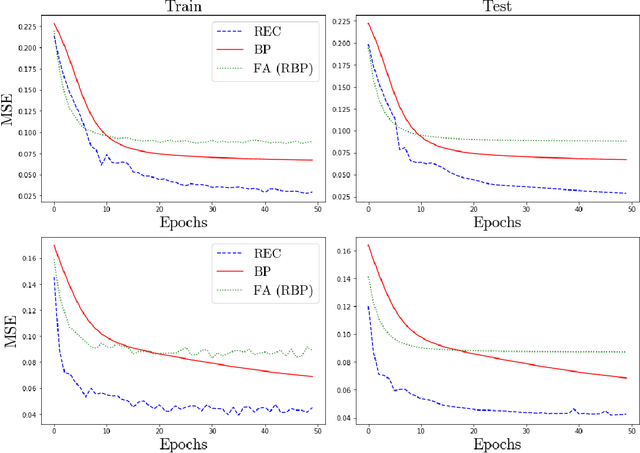
In a physical neural system, backpropagation is faced with a number of obstacles including: the need for labeled data, the violation of the locality learning principle, the need for symmetric connections, and the lack of modularity. Tourbillon is a new architecture that addresses all these limitations. At its core, it consists of a stack of circular autoencoders followed by an output layer. The circular autoencoders are trained in self-supervised mode by recirculation algorithms and the top layer in supervised mode by stochastic gradient descent, with the option of propagating error information through the entire stack using non-symmetric connections. While the Tourbillon architecture is meant primarily to address physical constraints, and not to improve current engineering applications of deep learning, we demonstrate its viability on standard benchmark datasets including MNIST, Fashion MNIST, and CIFAR10. We show that Tourbillon can achieve comparable performance to models trained with backpropagation and outperform models that are trained with other physically plausible algorithms, such as feedback alignment.
Multimodal Representations Learning and Adversarial Hypergraph Fusion for Early Alzheimer's Disease Prediction
Jul 21, 2021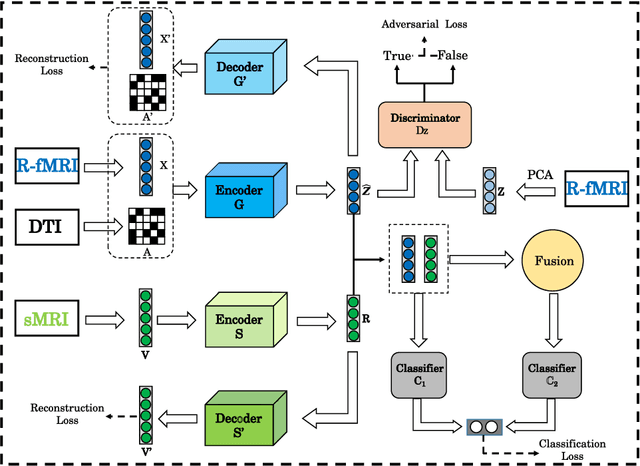

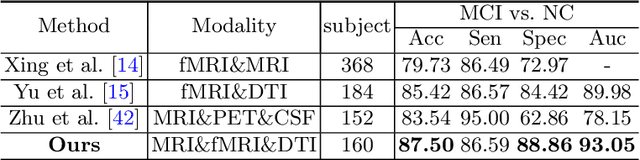
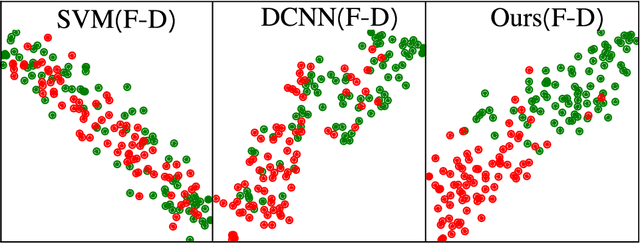
Multimodal neuroimage can provide complementary information about the dementia, but small size of complete multimodal data limits the ability in representation learning. Moreover, the data distribution inconsistency from different modalities may lead to ineffective fusion, which fails to sufficiently explore the intra-modal and inter-modal interactions and compromises the disease diagnosis performance. To solve these problems, we proposed a novel multimodal representation learning and adversarial hypergraph fusion (MRL-AHF) framework for Alzheimer's disease diagnosis using complete trimodal images. First, adversarial strategy and pre-trained model are incorporated into the MRL to extract latent representations from multimodal data. Then two hypergraphs are constructed from the latent representations and the adversarial network based on graph convolution is employed to narrow the distribution difference of hyperedge features. Finally, the hyperedge-invariant features are fused for disease prediction by hyperedge convolution. Experiments on the public Alzheimer's Disease Neuroimaging Initiative(ADNI) database demonstrate that our model achieves superior performance on Alzheimer's disease detection compared with other related models and provides a possible way to understand the underlying mechanisms of disorder's progression by analyzing the abnormal brain connections.
Adversarial Continual Learning for Multi-Domain Hippocampal Segmentation
Jul 21, 2021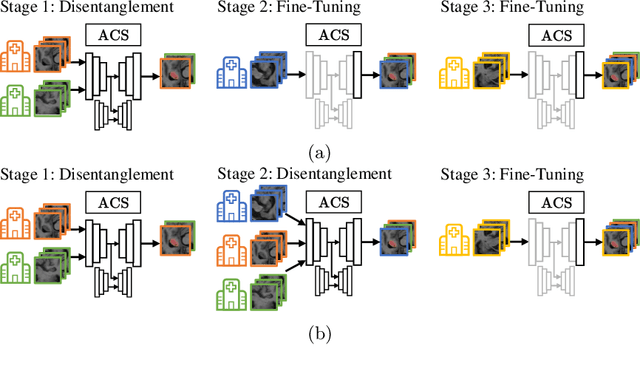
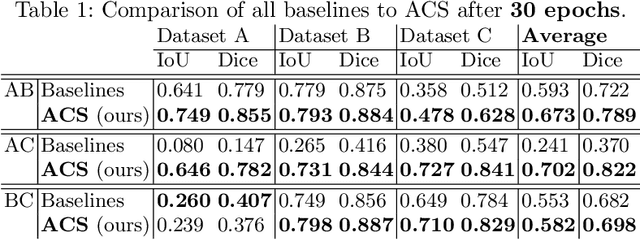
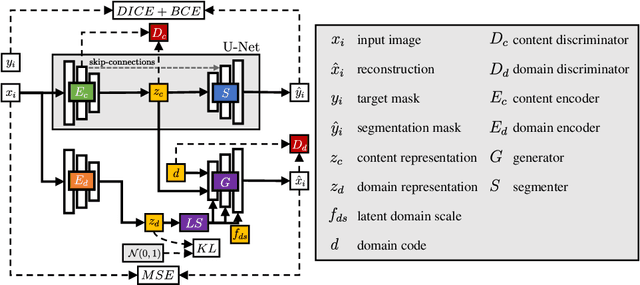
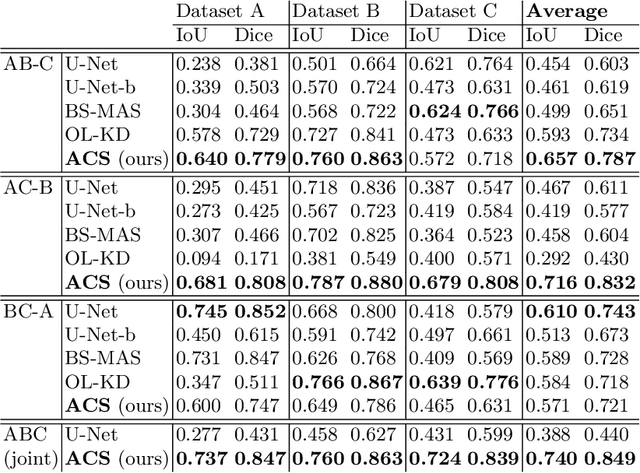
Deep learning for medical imaging suffers from temporal and privacy-related restrictions on data availability. To still obtain viable models, continual learning aims to train in sequential order, as and when data is available. The main challenge that continual learning methods face is to prevent catastrophic forgetting, i.e., a decrease in performance on the data encountered earlier. This issue makes continuous training of segmentation models for medical applications extremely difficult. Yet, often, data from at least two different domains is available which we can exploit to train the model in a way that it disregards domain-specific information. We propose an architecture that leverages the simultaneous availability of two or more datasets to learn a disentanglement between the content and domain in an adversarial fashion. The domain-invariant content representation then lays the base for continual semantic segmentation. Our approach takes inspiration from domain adaptation and combines it with continual learning for hippocampal segmentation in brain MRI. We showcase that our method reduces catastrophic forgetting and outperforms state-of-the-art continual learning methods.
Semantically-Aware Strategies for Stereo-Visual Robotic Obstacle Avoidance
Jul 13, 2021

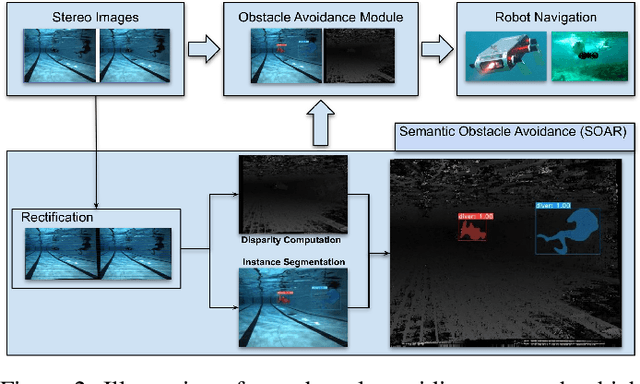
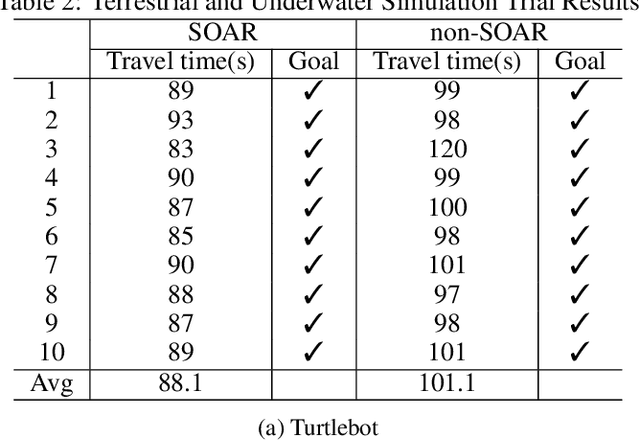
Mobile robots in unstructured, mapless environments must rely on an obstacle avoidance module to navigate safely. The standard avoidance techniques estimate the locations of obstacles with respect to the robot but are unaware of the obstacles' identities. Consequently, the robot cannot take advantage of semantic information about obstacles when making decisions about how to navigate. We propose an obstacle avoidance module that combines visual instance segmentation with a depth map to classify and localize objects in the scene. The system avoids obstacles differentially, based on the identity of the objects: for example, the system is more cautious in response to unpredictable objects such as humans. The system can also navigate closer to harmless obstacles and ignore obstacles that pose no collision danger, enabling it to navigate more efficiently. We validate our approach in two simulated environments: one terrestrial and one underwater. Results indicate that our approach is feasible and can enable more efficient navigation strategies.
Few-Shot Meta-Learning on Point Cloud for Semantic Segmentation
Apr 11, 2021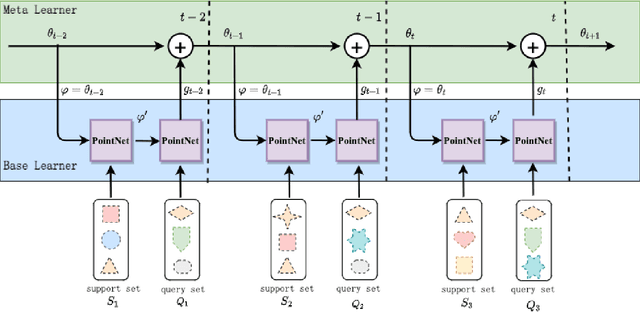
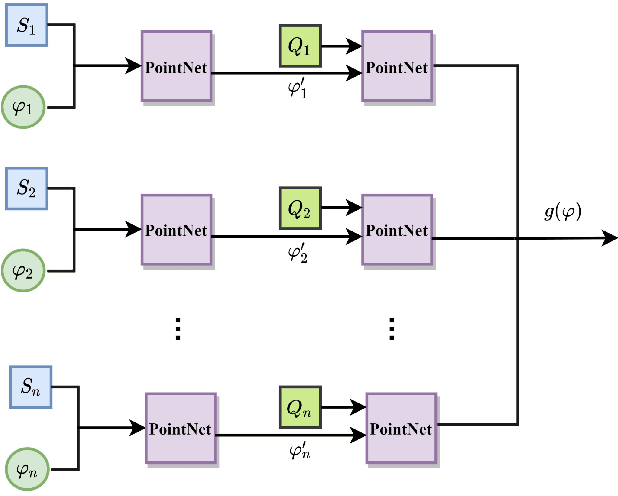
The promotion of construction robots can solve the problem of human resource shortage and improve the quality of decoration. To help the construction robots obtain environmental information, we need to use 3D point cloud, which is widely used in robotics, autonomous driving, and so on. With a good understanding of environmental information, construction robots can work better. However, the dynamic changes of 3D point cloud data may bring difficulties for construction robots to understand environmental information, such as when construction robots renovate houses. The paper proposes a semantic segmentation method for point cloud based on meta-learning. The method includes a basic learning module and a meta-learning module. The basic learning module is responsible for learning data features and evaluating the model, while the meta-learning module is responsible for updating the parameters of the model and improving the model generalization ability. In our work, we pioneered the method of producing datasets for meta-learning in 3D scenes, as well as demonstrated that the Model-Agnostic Meta-Learning (MAML) algorithm can be applied to process 3D point cloud data. At the same time, experiments show that our method can allow the model to be quickly applied to new environments with a few samples. Our method has important applications.
Inferring Missing Categorical Information in Noisy and Sparse Web Markup
Mar 01, 2018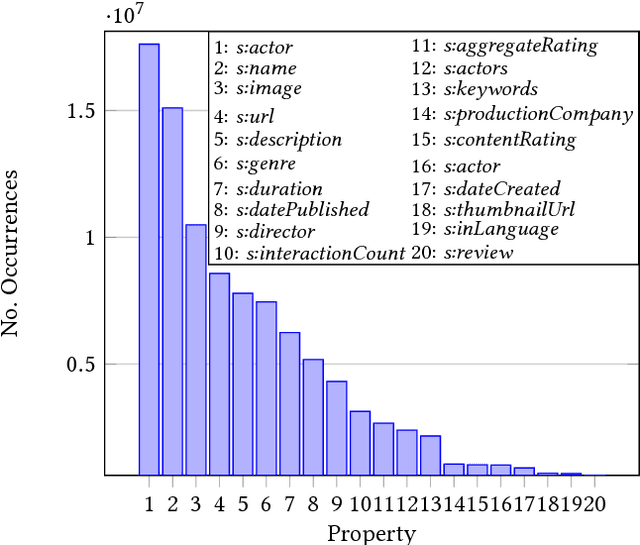

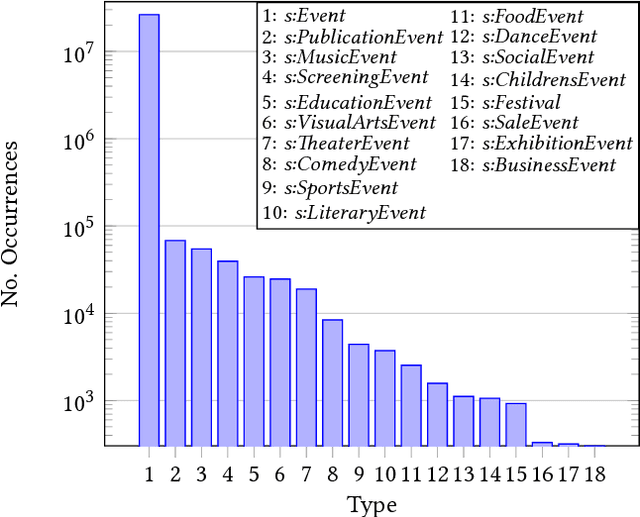
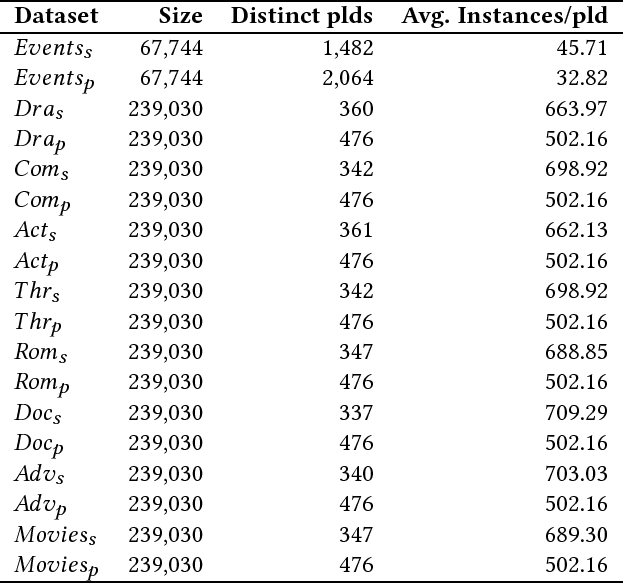
Embedded markup of Web pages has seen widespread adoption throughout the past years driven by standards such as RDFa and Microdata and initiatives such as schema.org, where recent studies show an adoption by 39% of all Web pages already in 2016. While this constitutes an important information source for tasks such as Web search, Web page classification or knowledge graph augmentation, individual markup nodes are usually sparsely described and often lack essential information. For instance, from 26 million nodes describing events within the Common Crawl in 2016, 59% of nodes provide less than six statements and only 257,000 nodes (0.96%) are typed with more specific event subtypes. Nevertheless, given the scale and diversity of Web markup data, nodes that provide missing information can be obtained from the Web in large quantities, in particular for categorical properties. Such data constitutes potential training data for inferring missing information to significantly augment sparsely described nodes. In this work, we introduce a supervised approach for inferring missing categorical properties in Web markup. Our experiments, conducted on properties of events and movies, show a performance of 79% and 83% F1 score correspondingly, significantly outperforming existing baselines.