 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
3DRIMR: 3D Reconstruction and Imaging via mmWave Radar based on Deep Learning
Aug 05, 2021
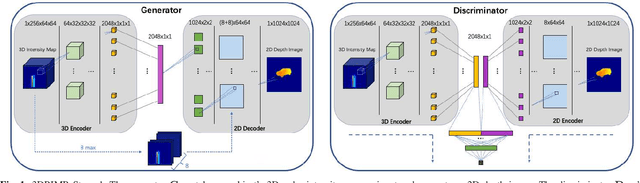
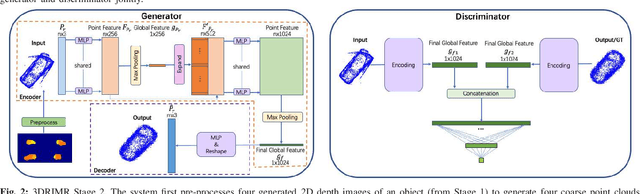
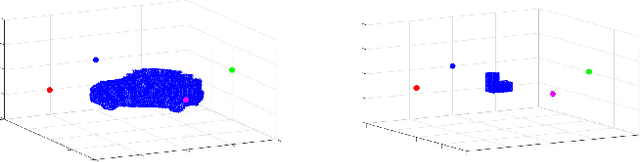
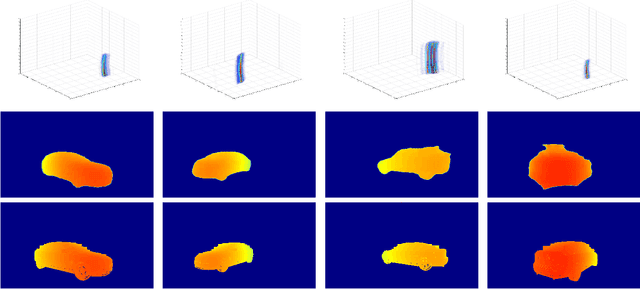
mmWave radar has been shown as an effective sensing technique in low visibility, smoke, dusty, and dense fog environment. However tapping the potential of radar sensing to reconstruct 3D object shapes remains a great challenge, due to the characteristics of radar data such as sparsity, low resolution, specularity, high noise, and multi-path induced shadow reflections and artifacts. In this paper we propose 3D Reconstruction and Imaging via mmWave Radar (3DRIMR), a deep learning based architecture that reconstructs 3D shape of an object in dense detailed point cloud format, based on sparse raw mmWave radar intensity data. The architecture consists of two back-to-back conditional GAN deep neural networks: the first generator network generates 2D depth images based on raw radar intensity data, and the second generator network outputs 3D point clouds based on the results of the first generator. The architecture exploits both convolutional neural network's convolutional operation (that extracts local structure neighborhood information) and the efficiency and detailed geometry capture capability of point clouds (other than costly voxelization of 3D space or distance fields). Our experiments have demonstrated 3DRIMR's effectiveness in reconstructing 3D objects, and its performance improvement over standard techniques.
WOVe: Incorporating Word Order in GloVe Word Embeddings
May 18, 2021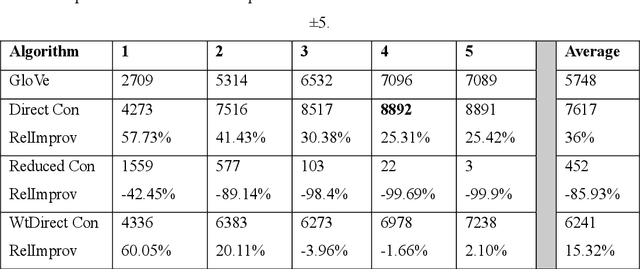
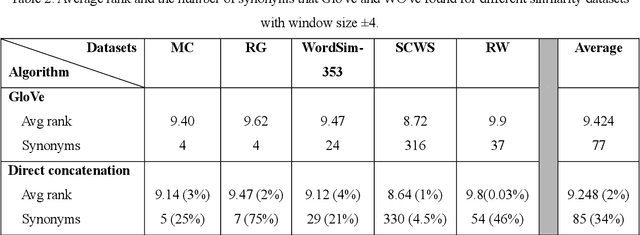
Word vector representations open up new opportunities to extract useful information from unstructured text. Defining a word as a vector made it easy for the machine learning algorithms to understand a text and extract information from. Word vector representations have been used in many applications such word synonyms, word analogy, syntactic parsing, and many others. GloVe, based on word contexts and matrix vectorization, is an ef-fective vector-learning algorithm. It improves on previous vector-learning algorithms. However, the GloVe model fails to explicitly consider the order in which words appear within their contexts. In this paper, multiple methods of incorporating word order in GloVe word embeddings are proposed. Experimental results show that our Word Order Vector (WOVe) word embeddings approach outperforms unmodified GloVe on the natural lan-guage tasks of analogy completion and word similarity. WOVe with direct concatenation slightly outperformed GloVe on the word similarity task, increasing average rank by 2%. However, it greatly improved on the GloVe baseline on a word analogy task, achieving an average 36.34% improvement in accuracy.
Non-local Channel Aggregation Network for Single Image Rain Removal
Mar 03, 2021



Rain streaks showing in images or videos would severely degrade the performance of computer vision applications. Thus, it is of vital importance to remove rain streaks and facilitate our vision systems. While recent convolutinal neural network based methods have shown promising results in single image rain removal (SIRR), they fail to effectively capture long-range location dependencies or aggregate convolutional channel information simultaneously. However, as SIRR is a highly illposed problem, these spatial and channel information are very important clues to solve SIRR. First, spatial information could help our model to understand the image context by gathering long-range dependency location information hidden in the image. Second, aggregating channels could help our model to concentrate on channels more related to image background instead of rain streaks. In this paper, we propose a non-local channel aggregation network (NCANet) to address the SIRR problem. NCANet models 2D rainy images as sequences of vectors in three directions, namely vertical direction, transverse direction and channel direction. Recurrently aggregating information from all three directions enables our model to capture the long-range dependencies in both channels and spaitials locations. Extensive experiments on both heavy and light rain image data sets demonstrate the effectiveness of the proposed NCANet model.
Group-aware Contrastive Regression for Action Quality Assessment
Aug 17, 2021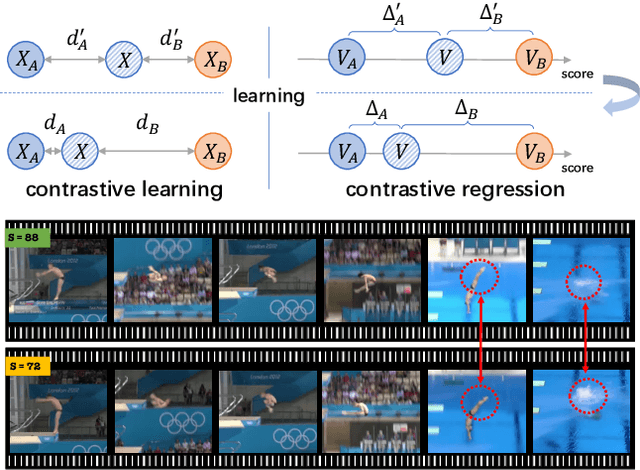
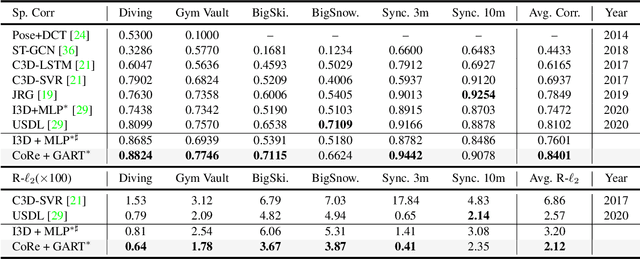
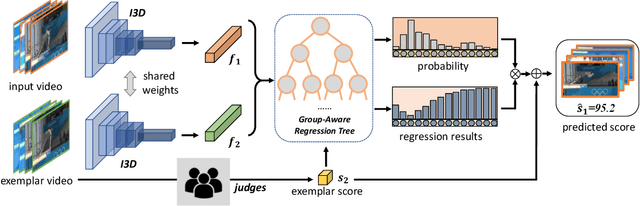

Assessing action quality is challenging due to the subtle differences between videos and large variations in scores. Most existing approaches tackle this problem by regressing a quality score from a single video, suffering a lot from the large inter-video score variations. In this paper, we show that the relations among videos can provide important clues for more accurate action quality assessment during both training and inference. Specifically, we reformulate the problem of action quality assessment as regressing the relative scores with reference to another video that has shared attributes (e.g., category and difficulty), instead of learning unreferenced scores. Following this formulation, we propose a new Contrastive Regression (CoRe) framework to learn the relative scores by pair-wise comparison, which highlights the differences between videos and guides the models to learn the key hints for assessment. In order to further exploit the relative information between two videos, we devise a group-aware regression tree to convert the conventional score regression into two easier sub-problems: coarse-to-fine classification and regression in small intervals. To demonstrate the effectiveness of CoRe, we conduct extensive experiments on three mainstream AQA datasets including AQA-7, MTL-AQA and JIGSAWS. Our approach outperforms previous methods by a large margin and establishes new state-of-the-art on all three benchmarks.
Self-Contrastive Learning
Jul 14, 2021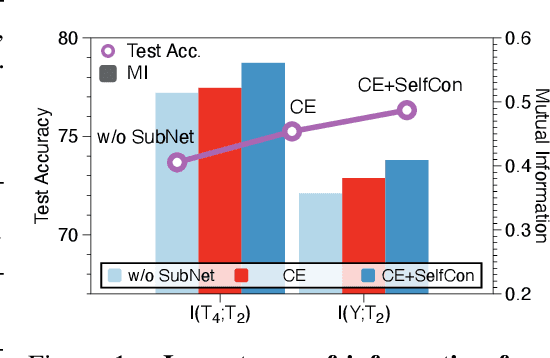
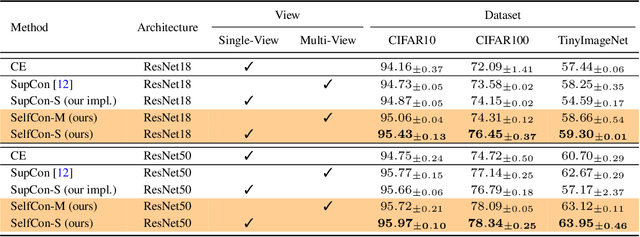
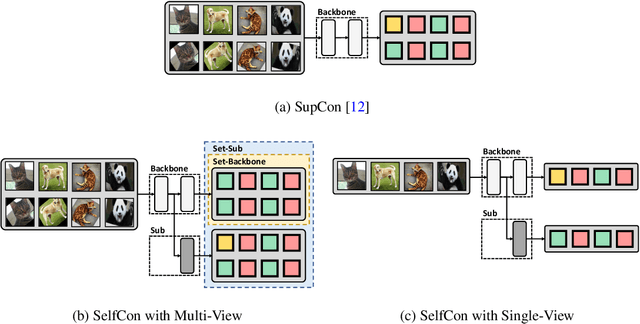
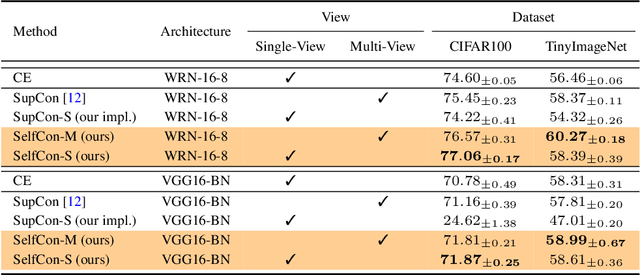
This paper proposes a novel contrastive learning framework, coined as Self-Contrastive (SelfCon) Learning, that self-contrasts within multiple outputs from the different levels of a network. We confirmed that SelfCon loss guarantees the lower bound of mutual information (MI) between the intermediate and last representations. Besides, we empirically showed, via various MI estimators, that SelfCon loss highly correlates to the increase of MI and better classification performance. In our experiments, SelfCon surpasses supervised contrastive (SupCon) learning without the need for a multi-viewed batch and with the cheaper computational cost. Especially on ResNet-18, we achieved top-1 classification accuracy of 76.45% for the CIFAR-100 dataset, which is 2.87% and 4.36% higher than SupCon and cross-entropy loss, respectively. We found that mitigating both vanishing gradient and overfitting issue makes our method outperform the counterparts.
Using transfer learning to study burned area dynamics: A case study of refugee settlements in West Nile, Northern Uganda
Jul 29, 2021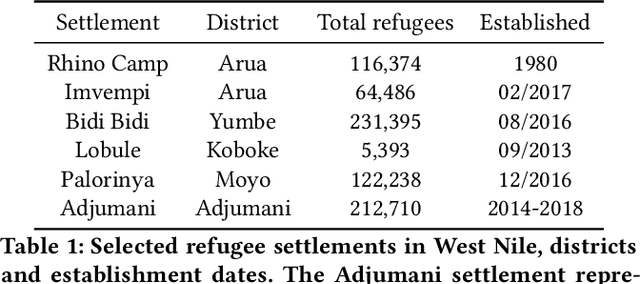
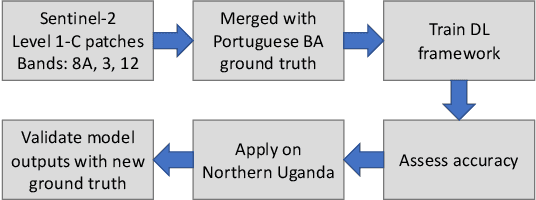
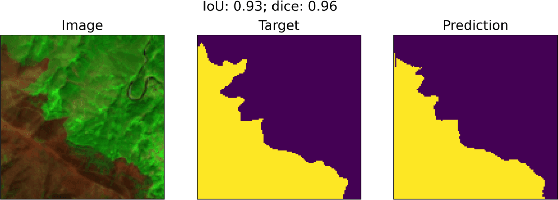

With the global refugee crisis at a historic high, there is a growing need to assess the impact of refugee settlements on their hosting countries and surrounding environments. Because fires are an important land management practice in smallholder agriculture in sub-Saharan Africa, burned area (BA) mappings can help provide information about the impacts of land management practices on local environments. However, a lack of BA ground-truth data in much of sub-Saharan Africa limits the use of highly scalable deep learning (DL) techniques for such BA mappings. In this work, we propose a scalable transfer learning approach to study BA dynamics in areas with little to no ground-truth data such as the West Nile region in Northern Uganda. We train a deep learning model on BA ground-truth data in Portugal and propose the application of that model on refugee-hosting districts in West Nile between 2015 and 2020. By comparing the district-level BA dynamic with the wider West Nile region, we aim to add understanding of the land management impacts of refugee settlements on their surrounding environments.
Integrating Propositional and Relational Label Side Information for Hierarchical Zero-Shot Image Classification
Feb 14, 2019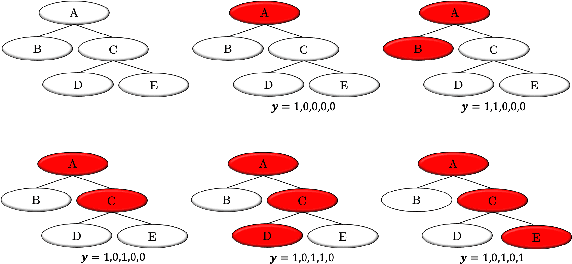
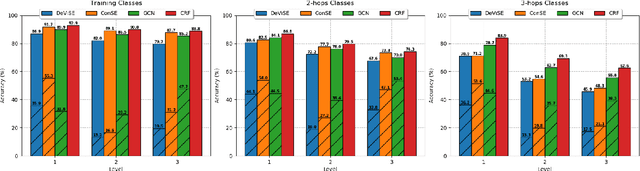

Zero-shot learning (ZSL) is one of the most extreme forms of learning from scarce labeled data. It enables predicting that images belong to classes for which no labeled training instances are available. In this paper, we present a new ZSL framework that leverages both label attribute side information and a semantic label hierarchy. We present two methods, lifted zero-shot prediction and a custom conditional random field (CRF) model, that integrate both forms of side information. We propose benchmark tasks for this framework that focus on making predictions across a range of semantic levels. We show that lifted zero-shot prediction can dramatically outperform baseline methods when making predictions within specified semantic levels, and that the probability distribution provided by the CRF model can be leveraged to yield further performance improvements when making unconstrained predictions over the hierarchy.
Low-level Pose Control of Tilting Multirotor for Wall Perching Tasks Using Reinforcement Learning
Aug 11, 2021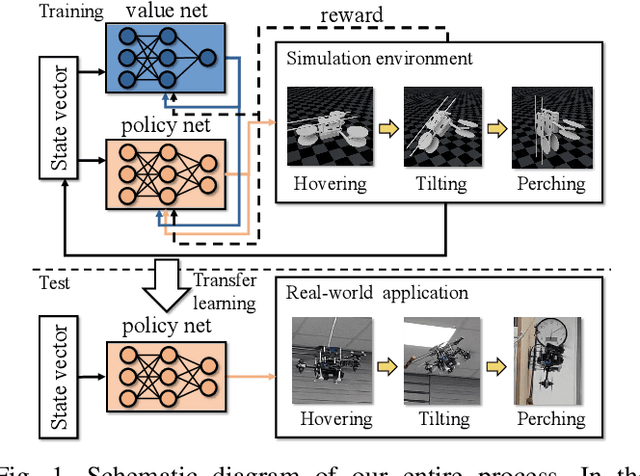
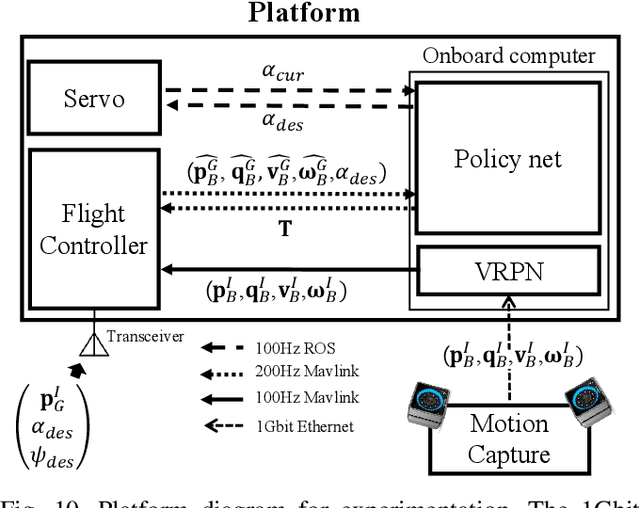
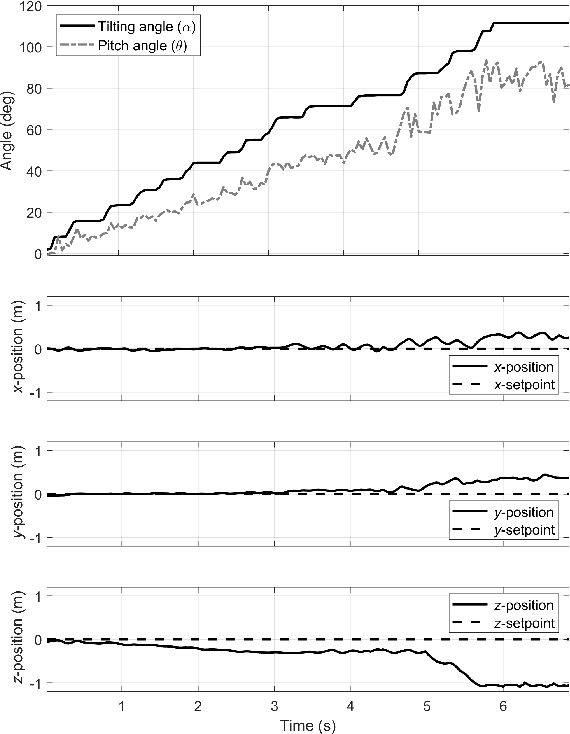
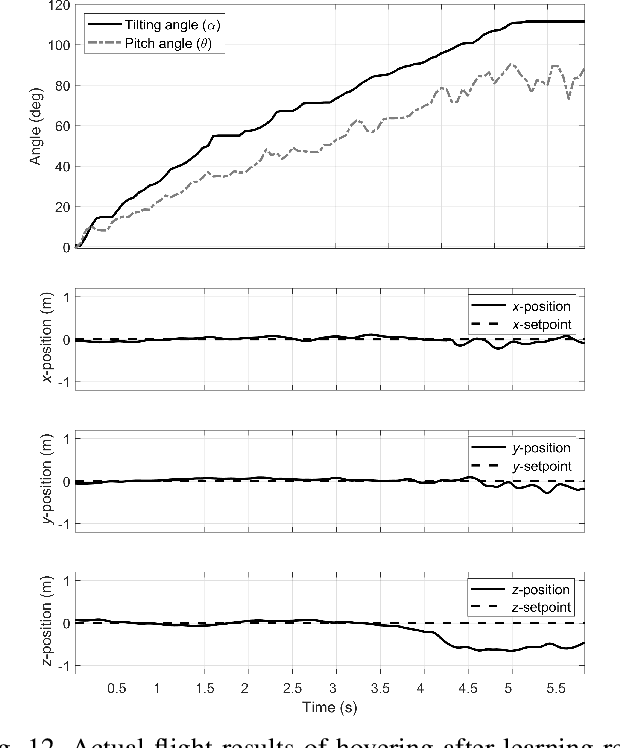
Recently, needs for unmanned aerial vehicles (UAVs) that are attachable to the wall have been highlighted. As one of the ways to address the need, researches on various tilting multirotors that can increase maneuverability has been employed. Unfortunately, existing studies on the tilting multirotors require considerable amounts of prior information on the complex dynamic model. Meanwhile, reinforcement learning on quadrotors has been studied to mitigate this issue. Yet, these are only been applied to standard quadrotors, whose systems are less complex than those of tilting multirotors. In this paper, a novel reinforcement learning-based method is proposed to control a tilting multirotor on real-world applications, which is the first attempt to apply reinforcement learning to a tilting multirotor. To do so, we propose a novel reward function for a neural network model that takes power efficiency into account. The model is initially trained over a simulated environment and then fine-tuned using real-world data in order to overcome the sim-to-real gap issue. Furthermore, a novel, efficient state representation with respect to the goal frame that helps the network learn optimal policy better is proposed. As verified on real-world experiments, our proposed method shows robust controllability by overcoming the complex dynamics of tilting multirotors.
Data Considerations in Graph Representation Learning for Supply Chain Networks
Jul 22, 2021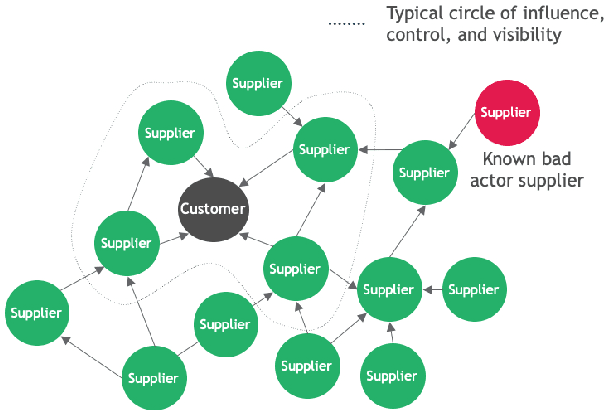


Supply chain network data is a valuable asset for businesses wishing to understand their ethical profile, security of supply, and efficiency. Possession of a dataset alone however is not a sufficient enabler of actionable decisions due to incomplete information. In this paper, we present a graph representation learning approach to uncover hidden dependency links that focal companies may not be aware of. To the best of our knowledge, our work is the first to represent a supply chain as a heterogeneous knowledge graph with learnable embeddings. We demonstrate that our representation facilitates state-of-the-art performance on link prediction of a global automotive supply chain network using a relational graph convolutional network. It is anticipated that our method will be directly applicable to businesses wishing to sever links with nefarious entities and mitigate risk of supply failure. More abstractly, it is anticipated that our method will be useful to inform representation learning of supply chain networks for downstream tasks beyond link prediction.
Continental-Scale Building Detection from High Resolution Satellite Imagery
Jul 29, 2021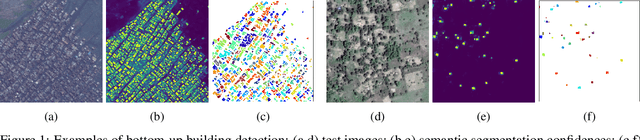
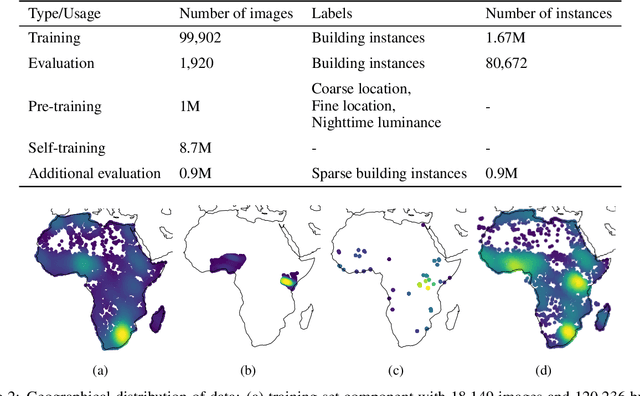

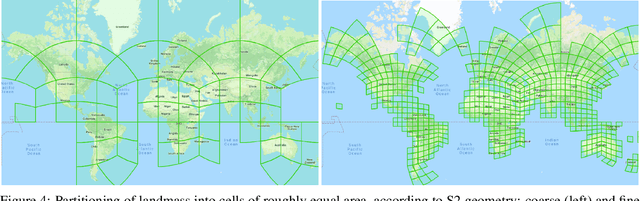
Identifying the locations and footprints of buildings is vital for many practical and scientific purposes. Such information can be particularly useful in developing regions where alternative data sources may be scarce. In this work, we describe a model training pipeline for detecting buildings across the entire continent of Africa, using 50 cm satellite imagery. Starting with the U-Net model, widely used in satellite image analysis, we study variations in architecture, loss functions, regularization, pre-training, self-training and post-processing that increase instance segmentation performance. Experiments were carried out using a dataset of 100k satellite images across Africa containing 1.75M manually labelled building instances, and further datasets for pre-training and self-training. We report novel methods for improving performance of building detection with this type of model, including the use of mixup (mAP +0.12) and self-training with soft KL loss (mAP +0.06). The resulting pipeline obtains good results even on a wide variety of challenging rural and urban contexts, and was used to create the Open Buildings dataset of 516M Africa-wide detected footprints.