 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Automatic classification of eclipsing binary stars using deep learning methods
Aug 03, 2021
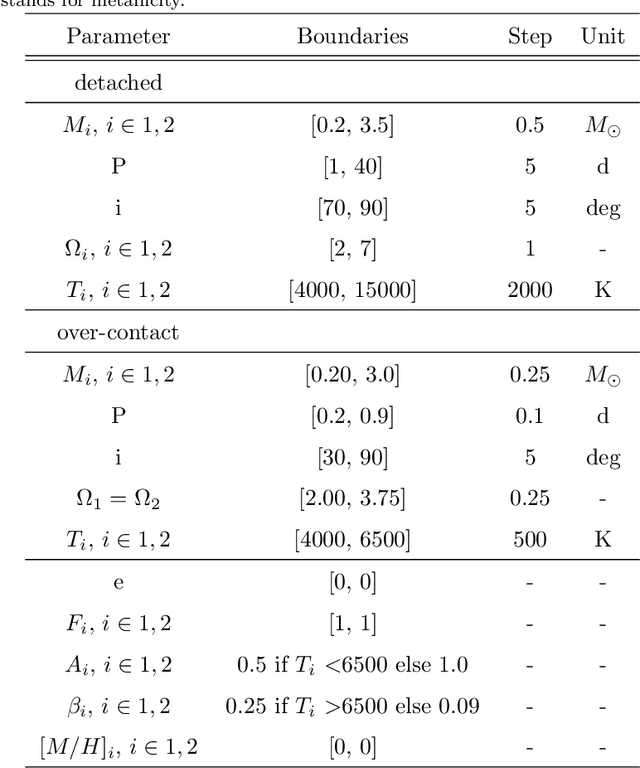
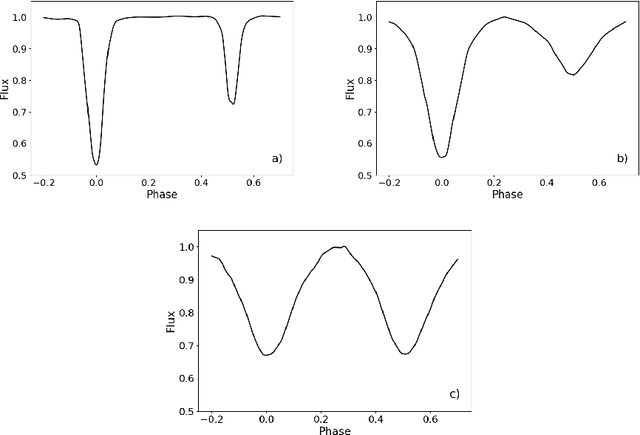
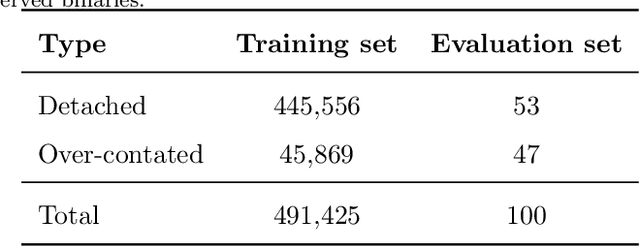
In the last couple of decades, tremendous progress has been achieved in developing robotic telescopes and, as a result, sky surveys (both terrestrial and space) have become the source of a substantial amount of new observational data. These data contain a lot of information about binary stars, hidden in their light curves. With the huge amount of astronomical data gathered, it is not reasonable to expect all the data to be manually processed and analyzed. Therefore, in this paper, we focus on the automatic classification of eclipsing binary stars using deep learning methods. Our classifier provides a tool for the categorization of light curves of binary stars into two classes: detached and over-contact. We used the ELISa software to obtain synthetic data, which we then used for the training of the classifier. For evaluation purposes, we collected 100 light curves of observed binary stars, in order to evaluate a number of classifiers. We evaluated semi-detached eclipsing binary stars as detached. The best-performing classifier combines bidirectional Long Short-Term Memory (LSTM) and a one-dimensional convolutional neural network, which achieved 98% accuracy on the evaluation set. Omitting semi-detached eclipsing binary stars, we could obtain 100% accuracy in classification.
DESYR: Definition and Syntactic Representation Based Claim Detection on the Web
Aug 19, 2021
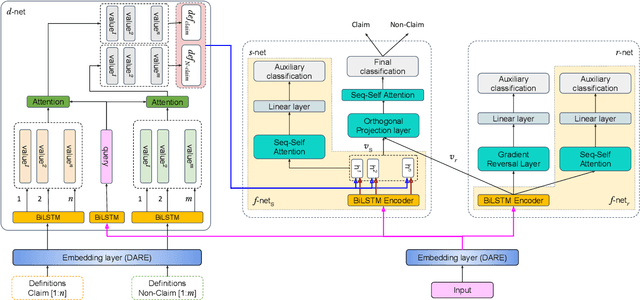
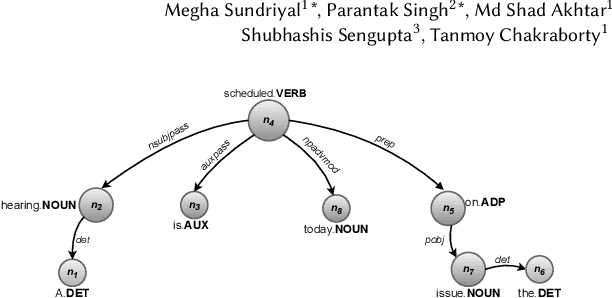

The formulation of a claim rests at the core of argument mining. To demarcate between a claim and a non-claim is arduous for both humans and machines, owing to latent linguistic variance between the two and the inadequacy of extensive definition-based formalization. Furthermore, the increase in the usage of online social media has resulted in an explosion of unsolicited information on the web presented as informal text. To account for the aforementioned, in this paper, we proposed DESYR. It is a framework that intends on annulling the said issues for informal web-based text by leveraging a combination of hierarchical representation learning (dependency-inspired Poincare embedding), definition-based alignment, and feature projection. We do away with fine-tuning computer-heavy language models in favor of fabricating a more domain-centric but lighter approach. Experimental results indicate that DESYR builds upon the state-of-the-art system across four benchmark claim datasets, most of which were constructed with informal texts. We see an increase of 3 claim-F1 points on the LESA-Twitter dataset, an increase of 1 claim-F1 point and 9 macro-F1 points on the Online Comments(OC) dataset, an increase of 24 claim-F1 points and 17 macro-F1 points on the Web Discourse(WD) dataset, and an increase of 8 claim-F1 points and 5 macro-F1 points on the Micro Texts(MT) dataset. We also perform an extensive analysis of the results. We make a 100-D pre-trained version of our Poincare-variant along with the source code.
Study of sampling methods in sentiment analysis of imbalanced data
Jun 12, 2021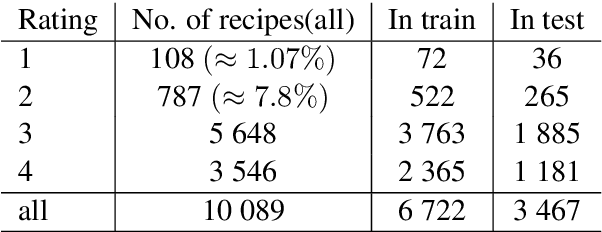
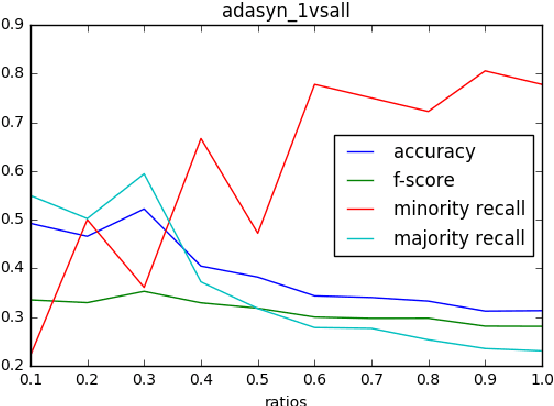

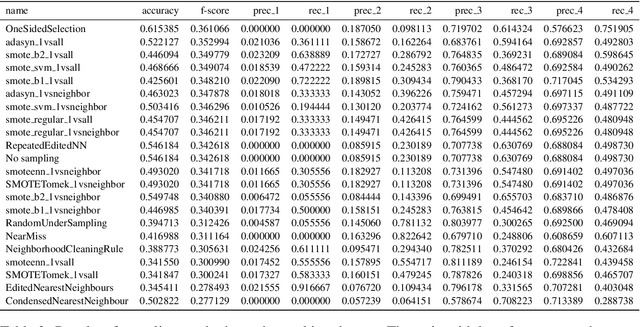
This work investigates the application of sampling methods for sentiment analysis on two different highly imbalanced datasets. One dataset contains online user reviews from the cooking platform Epicurious and the other contains comments given to the Planned Parenthood organization. In both these datasets, the classes of interest are rare. Word n-grams were used as features from these datasets. A feature selection technique based on information gain is first applied to reduce the number of features to a manageable space. A number of different sampling methods were then applied to mitigate the class imbalance problem which are then analyzed.
TRAPDOOR: Repurposing backdoors to detect dataset bias in machine learning-based genomic analysis
Aug 14, 2021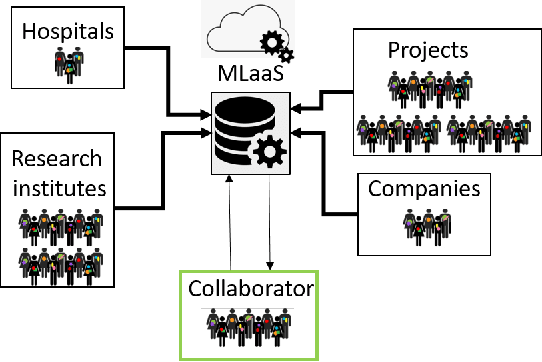

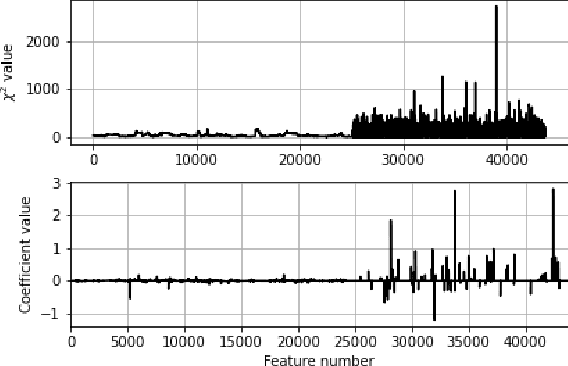
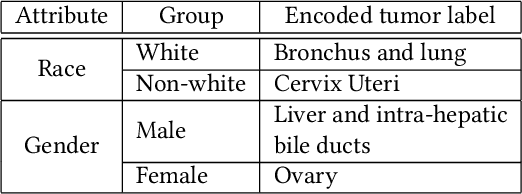
Machine Learning (ML) has achieved unprecedented performance in several applications including image, speech, text, and data analysis. Use of ML to understand underlying patterns in gene mutations (genomics) has far-reaching results, not only in overcoming diagnostic pitfalls, but also in designing treatments for life-threatening diseases like cancer. Success and sustainability of ML algorithms depends on the quality and diversity of data collected and used for training. Under-representation of groups (ethnic groups, gender groups, etc.) in such a dataset can lead to inaccurate predictions for certain groups, which can further exacerbate systemic discrimination issues. In this work, we propose TRAPDOOR, a methodology for identification of biased datasets by repurposing a technique that has been mostly proposed for nefarious purposes: Neural network backdoors. We consider a typical collaborative learning setting of the genomics supply chain, where data may come from hospitals, collaborative projects, or research institutes to a central cloud without awareness of bias against a sensitive group. In this context, we develop a methodology to leak potential bias information of the collective data without hampering the genuine performance using ML backdooring catered for genomic applications. Using a real-world cancer dataset, we analyze the dataset with the bias that already existed towards white individuals and also introduced biases in datasets artificially, and our experimental result show that TRAPDOOR can detect the presence of dataset bias with 100% accuracy, and furthermore can also extract the extent of bias by recovering the percentage with a small error.
Modularity in Reinforcement Learning via Algorithmic Independence in Credit Assignment
Jul 21, 2021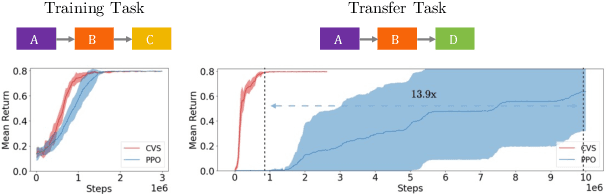
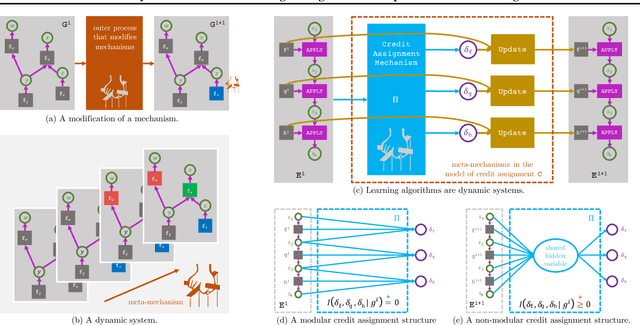
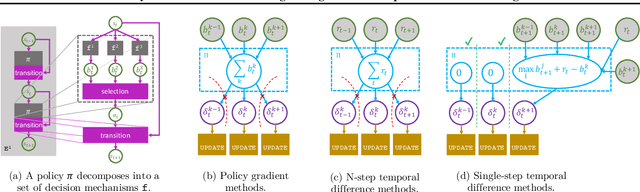
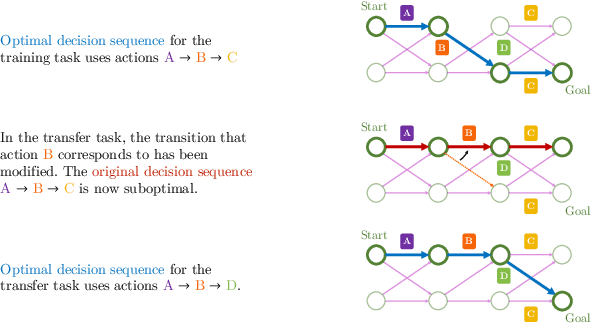
Many transfer problems require re-using previously optimal decisions for solving new tasks, which suggests the need for learning algorithms that can modify the mechanisms for choosing certain actions independently of those for choosing others. However, there is currently no formalism nor theory for how to achieve this kind of modular credit assignment. To answer this question, we define modular credit assignment as a constraint on minimizing the algorithmic mutual information among feedback signals for different decisions. We introduce what we call the modularity criterion for testing whether a learning algorithm satisfies this constraint by performing causal analysis on the algorithm itself. We generalize the recently proposed societal decision-making framework as a more granular formalism than the Markov decision process to prove that for decision sequences that do not contain cycles, certain single-step temporal difference action-value methods meet this criterion while all policy-gradient methods do not. Empirical evidence suggests that such action-value methods are more sample efficient than policy-gradient methods on transfer problems that require only sparse changes to a sequence of previously optimal decisions.
Rain Removal and Illumination Enhancement Done in One Go
Aug 09, 2021

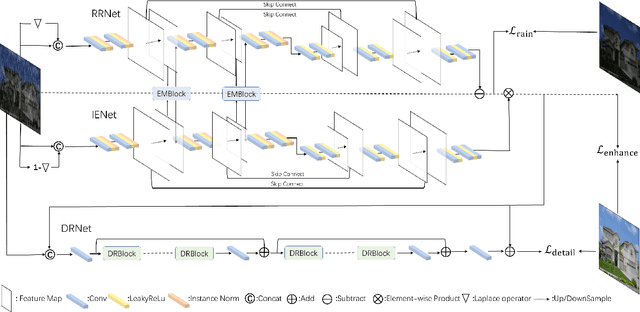
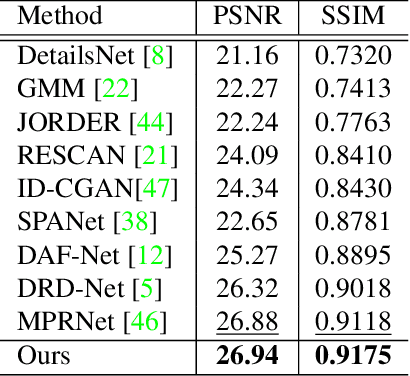
Rain removal plays an important role in the restoration of degraded images. Recently, data-driven methods have achieved remarkable success. However, these approaches neglect that the appearance of rain is often accompanied by low light conditions, which will further degrade the image quality. Therefore, it is very indispensable to jointly remove the rain and enhance the light for real-world rain image restoration. In this paper, we aim to address this problem from two aspects. First, we proposed a novel entangled network, namely EMNet, which can remove the rain and enhance illumination in one go. Specifically, two encoder-decoder networks interact complementary information through entanglement structure, and parallel rain removal and illumination enhancement. Considering that the encoder-decoder structure is unreliable in preserving spatial details, we employ a detail recovery network to restore the desired fine texture. Second, we present a new synthetic dataset, namely DarkRain, to boost the development of rain image restoration algorithms in practical scenarios. DarkRain not only contains different degrees of rain, but also considers different lighting conditions, and more realistically simulates the rainfall in the real world. EMNet is extensively evaluated on the proposed benchmark and achieves state-of-the-art results. In addition, after a simple transformation, our method outshines existing methods in both rain removal and low-light image enhancement. The source code and dataset will be made publicly available later.
Complexity Analysis of Stein Variational Gradient Descent Under Talagrand's Inequality T1
Jun 06, 2021
We study the complexity of Stein Variational Gradient Descent (SVGD), which is an algorithm to sample from $\pi(x) \propto \exp(-F(x))$ where $F$ smooth and nonconvex. We provide a clean complexity bound for SVGD in the population limit in terms of the Stein Fisher Information (or squared Kernelized Stein Discrepancy), as a function of the dimension of the problem $d$ and the desired accuracy $\varepsilon$. Unlike existing work, we do not make any assumption on the trajectory of the algorithm. Instead, our key assumption is that the target distribution satisfies Talagrand's inequality T1.
Peer Selection with Noisy Assessments
Jul 21, 2021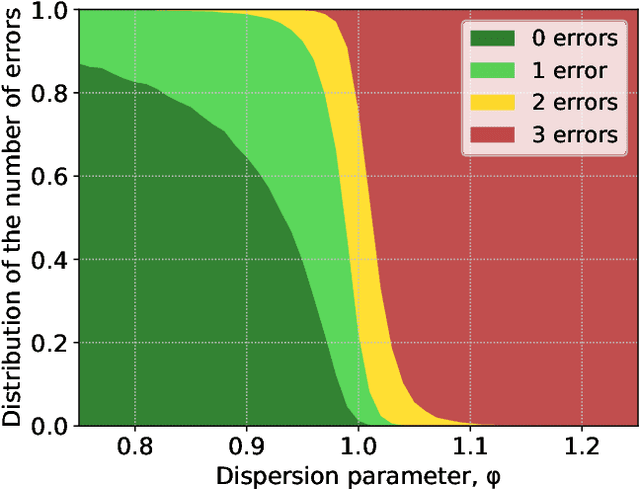

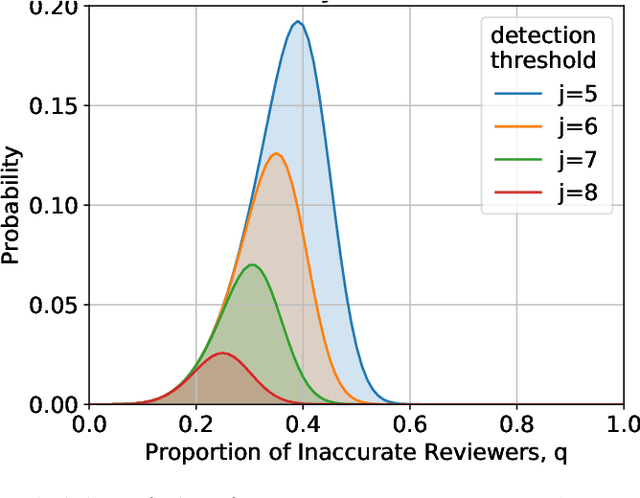
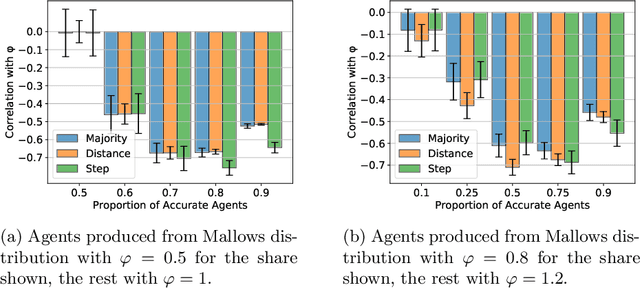
In the peer selection problem a group of agents must select a subset of themselves as winners for, e.g., peer-reviewed grants or prizes. Here, we take a Condorcet view of this aggregation problem, i.e., that there is a ground-truth ordering over the agents and we wish to select the best set of agents, subject to the noisy assessments of the peers. Given this model, some agents may be unreliable, while others might be self-interested, attempting to influence the outcome in their favour. In this paper we extend PeerNomination, the most accurate peer reviewing algorithm to date, into WeightedPeerNomination, which is able to handle noisy and inaccurate agents. To do this, we explicitly formulate assessors' reliability weights in a way that does not violate strategyproofness, and use this information to reweight their scores. We show analytically that a weighting scheme can improve the overall accuracy of the selection significantly. Finally, we implement several instances of reweighting methods and show empirically that our methods are robust in the face of noisy assessments.
Neural Marching Cubes
Jun 21, 2021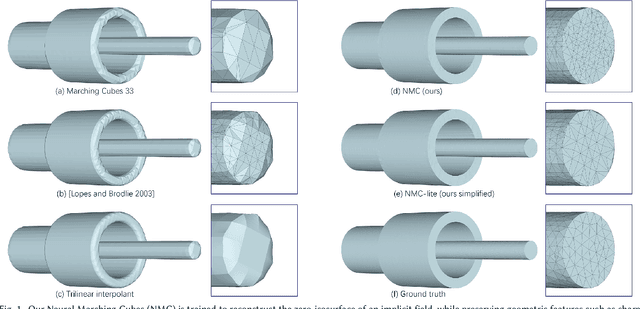
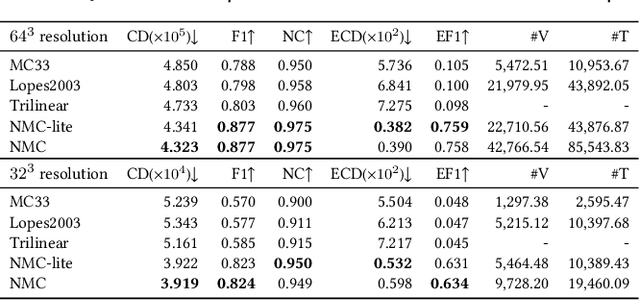
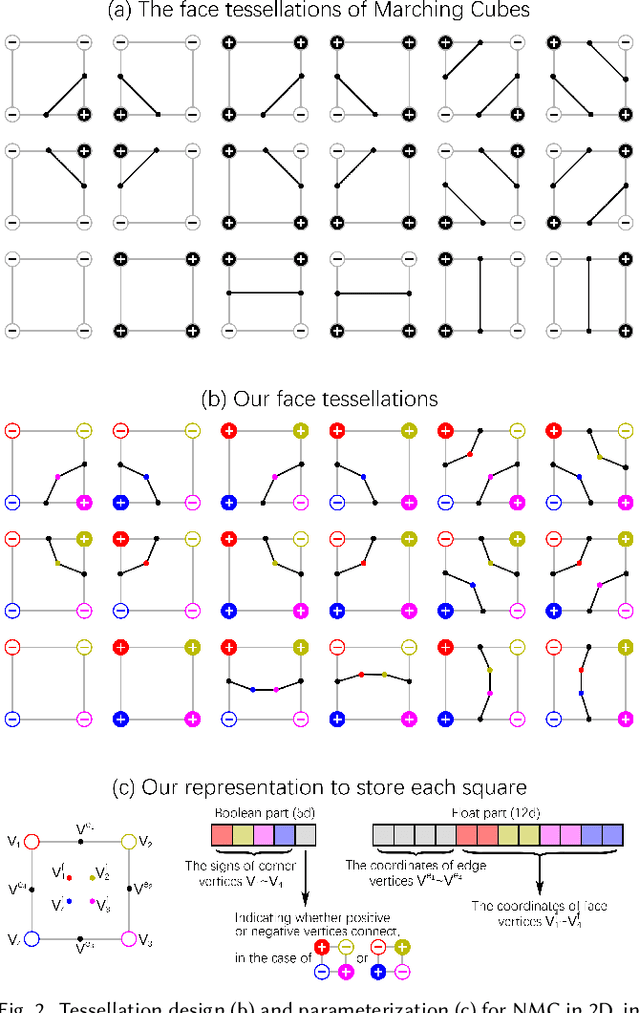
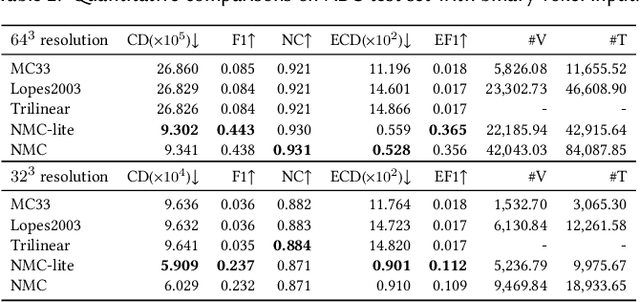
We introduce Neural Marching Cubes (NMC), a data-driven approach for extracting a triangle mesh from a discretized implicit field. Classical MC is defined by coarse tessellation templates isolated to individual cubes. While more refined tessellations have been proposed, they all make heuristic assumptions, such as trilinearity, when determining the vertex positions and local mesh topologies in each cube. In principle, none of these approaches can reconstruct geometric features that reveal coherence or dependencies between nearby cubes (e.g., a sharp edge), as such information is unaccounted for, resulting in poor estimates of the true underlying implicit field. To tackle these challenges, we re-cast MC from a deep learning perspective, by designing tessellation templates more apt at preserving geometric features, and learning the vertex positions and mesh topologies from training meshes, to account for contextual information from nearby cubes. We develop a compact per-cube parameterization to represent the output triangle mesh, while being compatible with neural processing, so that a simple 3D convolutional network can be employed for the training. We show that all topological cases in each cube that are applicable to our design can be easily derived using our representation, and the resulting tessellations can also be obtained naturally and efficiently by following a few design guidelines. In addition, our network learns local features with limited receptive fields, hence it generalizes well to new shapes and new datasets. We evaluate our neural MC approach by quantitative and qualitative comparisons to all well-known MC variants. In particular, we demonstrate the ability of our network to recover sharp features such as edges and corners, a long-standing issue of MC and its variants. Our network also reconstructs local mesh topologies more accurately than previous approaches.
ROC: An Ontology for Country Responses towards COVID-19
Apr 15, 2021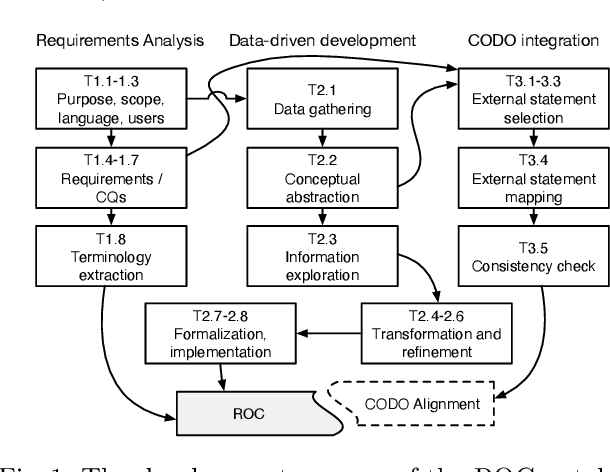
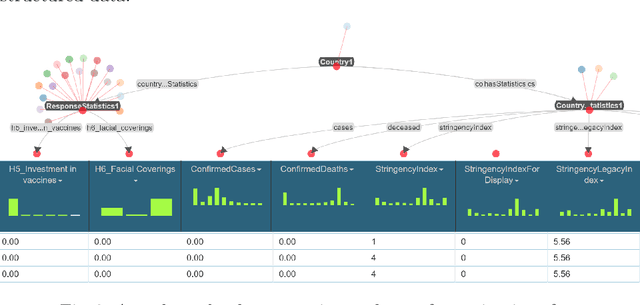

The ROC ontology for country responses to COVID-19 provides a model for collecting, linking and sharing data on the COVID-19 pandemic. It follows semantic standardization (W3C standards RDF, OWL, SPARQL) for the representation of concepts and creation of vocabularies. ROC focuses on country measures and enables the integration of data from heterogeneous data sources. The proposed ontology is intended to facilitate statistical analysis to study and evaluate the effectiveness and side effects of government responses to COVID-19 in different countries. The ontology contains data collected by OxCGRT from publicly available information. This data has been compiled from information provided by ECDC for most countries, as well as from various repositories used to collect data on COVID-19.
* 10 pages, 3 figures